{
"cells": [
{
"cell_type": "markdown",
"id": "f884f549",
"metadata": {},
"source": [
"## Predictor Monitoring enables you to monitor effectiveness over time\n",
"\n",
"We are excited to announce that Amazon Forecast now offers a new feature called Predictor Monitoring that enables customers to automatically evaluate their trained predictor's performance over time. Think of an [Amazon Forecast Predictor](https://docs.aws.amazon.com/forecast/latest/dg/howitworks-predictor.html) as a saved machine learning model used to generate predictions based on a set of training data. Once a predictor is created, it can be used for days, weeks or potentially months to generate new forecasted data points without change -- every customer's data and use case is different.\n",
"\n",
"Over time, a variety of factors can cause the performance of a predictor to change such as external factors (supply chain) or changes in consumer preferences. New products, items and services may be created and the distribution of data may change too. Eventually, a new predictor will be needed to ensure high quality predictions continue to be made.\n",
"\n",
"Once you enable monitoring for a predictor and then import new data and produce a new forecast, the monitor will collect statistics automatically. You may use these statistics to decide when it's the right time to train a new predictor.\n",
"\n",
"This notebook provides an anecdotal series of steps to illustrate what may happen in the real-world as multiple datasets are imported and forecasted over time. The provided notebook is saved in an executed state, so you may review outputs without having to run each cell, unless you choose to do so.\n",
"\n",
"This notebook introduces you to the Predictor Monitoring concept and does not require a complete set of data. For this exercise, we will use a very small slice of the yellow taxi trip records from [NYC Taxi and Limousine Commission (TLC)](https://www1.nyc.gov/site/tlc/about/tlc-trip-record-data.page)."
]
},
{
"cell_type": "markdown",
"id": "42892551",
"metadata": {},
"source": [
"\n",
"## Table of Contents\n",
"* [Initial Setup](#setup)\n",
"* Step 1: [Prepare a set of time-sliced sample data](#prepare)\n",
"* Step 2: [Create an initial predictor & forecast](#initial)\n",
"* Step 3: [Demonstrate the Predictor Monitoring Lifecycle](#lifecycle)\n",
"* Step 4: [View the Predictor Monitor Evaluation](#evaluation)\n",
"* Step 5: [Cleanup](#cleanup)\n"
]
},
{
"cell_type": "markdown",
"id": "d68cb189",
"metadata": {},
"source": [
"# Initial Setup\n",
"\n",
"### Upgrade boto3\n",
"\n",
"Before proceeding, ensure you have upgraded boto3."
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "da77edcd",
"metadata": {},
"outputs": [],
"source": [
"!pip install boto3 --upgrade"
]
},
{
"cell_type": "markdown",
"id": "9abffdaf",
"metadata": {},
"source": [
"### Setup Imports"
]
},
{
"cell_type": "code",
"execution_count": 1,
"id": "3ee87f2b",
"metadata": {},
"outputs": [],
"source": [
"import boto3\n",
"from time import sleep\n",
"import subprocess\n",
"import sys\n",
"import os\n",
"import pandas as pd\n",
"\n",
"sys.path.insert( 0, os.path.abspath(\"../../common\") )\n",
"\n",
"import json\n",
"import util"
]
},
{
"cell_type": "markdown",
"id": "2c320ad2",
"metadata": {},
"source": [
"### Function to supressing printing account numbers"
]
},
{
"cell_type": "code",
"execution_count": 2,
"id": "fc1fba1e",
"metadata": {},
"outputs": [],
"source": [
"import re\n",
"\n",
"def mask_arn(input_string):\n",
"\n",
" mask_regex = re.compile(':[0-9]{12}:')\n",
" mask = mask_regex.search(input_string)\n",
" \n",
" while mask:\n",
" input_string = input_string.replace(mask.group(),'X'*12)\n",
" mask = mask_regex.search(input_string) \n",
" \n",
" return input_string"
]
},
{
"cell_type": "markdown",
"id": "727b751b",
"metadata": {},
"source": [
"### Create an instance of AWS SDK client for Amazon Forecast"
]
},
{
"cell_type": "code",
"execution_count": 3,
"id": "c2bb63b5",
"metadata": {},
"outputs": [],
"source": [
"# Set your region accordingly, us-east-1 as shown\n",
"region = 'us-east-1'\n",
"session = boto3.Session(region_name=region) \n",
"forecast = session.client(service_name='forecast')\n",
"\n",
"# Checking to make sure we can communicate with Amazon Forecast\n",
"assert forecast.list_monitors()"
]
},
{
"cell_type": "markdown",
"id": "7383cefe",
"metadata": {},
"source": [
"### Setup IAM Role used by Amazon Forecast to access your data"
]
},
{
"cell_type": "code",
"execution_count": 5,
"id": "8c3485b5",
"metadata": {},
"outputs": [],
"source": [
"role_name = \"ForecastNotebookRole-Basic\"\n",
"print(f\"Creating Role {mask_arn(role_name)}...\")\n",
"role_arn = util.get_or_create_iam_role( role_name = role_name )\n",
"\n",
"# echo user inputs without account\n",
"print(f\"Success! Created role = {mask_arn(role_arn).split('/')[1]}\")"
]
},
{
"cell_type": "markdown",
"id": "ef3dc6aa",
"metadata": {},
"source": [
"# Step 1: Prepare a set of time-sliced sample data\n",
"\n",
"In this step, a small dataset is available in the file taxi_sample_data.csv. \n",
"\n",
"The dataset has the following 3 columns:\n",
"- timestamp: Timetamp at which pick-ups are requested.\n",
"- item_id: Pick-up location ID.\n",
"- target_value: Number of pick-ups requested around the timestamp at the pick-up location.\n",
"\n",
"First, the routine below uses a single input file to create a small seed file of 100k rows, representing something you might use to train an initial predictor.\n",
"\n",
"Next, the routine creates four additional data files, t1 to t4 respectively. Each file contains 25k more data rows than the prior file, which simulates the passing of time with more ground truth data being avaialble. This simulates what might happen in the real-world where, as time lapses, more ground truth target time series data will be available. Later in this notebook, we'll import and forecast these files and see the metrics produced by predictor monitoring.\n",
"\n",
"Note: As delivered, this uses the sample file in the data folder relative to this notebook. Please take care to ensure this file is available to your notebook."
]
},
{
"cell_type": "markdown",
"id": "650c498c",
"metadata": {},
"source": [
"### Create cumulative time-sliced files to demonstrate predictor monitoring over time"
]
},
{
"cell_type": "code",
"execution_count": 6,
"id": "ba01f4ec",
"metadata": {},
"outputs": [],
"source": [
"!head -100000 ./data/taxi_sample_data.csv > ./data/TAXI_TTS_seed.csv\n",
"!head -125000 ./data/taxi_sample_data.csv > ./data/TAXI_TTS_t1.csv\n",
"!head -150000 ./data/taxi_sample_data.csv > ./data/TAXI_TTS_t2.csv\n",
"!head -175000 ./data/taxi_sample_data.csv > ./data/TAXI_TTS_t3.csv\n",
"!head -200000 ./data/taxi_sample_data.csv > ./data/TAXI_TTS_t4.csv"
]
},
{
"cell_type": "markdown",
"id": "9d4e94df",
"metadata": {},
"source": [
"### Upload files to S3"
]
},
{
"cell_type": "code",
"execution_count": 8,
"id": "bede38b1",
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"\n",
"Enter S3 bucket name for uploading the data and hit ENTER key:forecast-us-east-1-XXXXXXXXXXXX\n",
"TAXI_TTS_seed.csv\n",
"TAXI_TTS_t2.csv\n",
"TAXI_TTS_t4.csv\n",
"TAXI_TTS_t1.csv\n",
"TAXI_TTS_t3.csv\n"
]
}
],
"source": [
"bucket_name = input(\"\\nEnter S3 bucket name for uploading the data and hit ENTER key:\")\n",
"\n",
"s3 = boto3.resource('s3')\n",
"for file in os.listdir('./data'):\n",
" if file.endswith(\".csv\") and file.startswith('TAXI_TTS_'):\n",
" print(file)\n",
" s3.meta.client.upload_file('./data/'+file, bucket_name, file)"
]
},
{
"cell_type": "markdown",
"id": "8377b4c1",
"metadata": {},
"source": [
"# Step 2: Create an initial predictor & forecast\n",
"\n",
"In step 2, we will \n",
"- create a new dataset\n",
"- import an initial seed data file into the dataset\n",
"- create a new dataset group, which is the container for the new dataset\n",
"- create a new auto predictor model, with predictor monitoring enabled\n",
"- create a new forecast\n",
"\n",
"All of these steps represent an initial state of a production system at the start. From here, time moves on and new data is recorded, allowing future forecasts to predict further out into the horizon as the ground truth horizon advances.\n",
"\n",
"To prepare you for what's ahead, Step 3 below will simulate processing real-world data over time allowing you to review the Predictor Monitoring results over time."
]
},
{
"cell_type": "markdown",
"id": "9eafff13",
"metadata": {},
"source": [
"### Create Dataset"
]
},
{
"cell_type": "code",
"execution_count": 9,
"id": "c7cc51a4",
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Dataset ARN arn:aws:forecast:us-west-2XXXXXXXXXXXXdataset/TAXI_PREDICTOR_MONITOR_DEMO is now ACTIVE.\n"
]
}
],
"source": [
"DATASET_FREQUENCY = \"H\"\n",
"TS_DATASET_NAME = \"TAXI_PREDICTOR_MONITOR_DEMO\"\n",
"TS_SCHEMA = {\n",
" \"Attributes\":[\n",
" {\n",
" \"AttributeName\":\"timestamp\",\n",
" \"AttributeType\":\"timestamp\"\n",
" },\n",
" {\n",
" \"AttributeName\":\"item_id\",\n",
" \"AttributeType\":\"string\"\n",
" },\n",
" {\n",
" \"AttributeName\":\"target_value\",\n",
" \"AttributeType\":\"integer\"\n",
" }\n",
" ]\n",
"} \n",
"\n",
"create_dataset_response = forecast.create_dataset(Domain=\"CUSTOM\",\n",
" DatasetType='TARGET_TIME_SERIES',\n",
" DatasetName=TS_DATASET_NAME,\n",
" DataFrequency=DATASET_FREQUENCY,\n",
" Schema=TS_SCHEMA)\n",
"\n",
"ts_dataset_arn = create_dataset_response['DatasetArn']\n",
"describe_dataset_response = forecast.describe_dataset(DatasetArn=ts_dataset_arn)\n",
"\n",
"print(f\"Dataset ARN {mask_arn(ts_dataset_arn)} is now {describe_dataset_response['Status']}.\")"
]
},
{
"cell_type": "markdown",
"id": "8ca5abdc",
"metadata": {},
"source": [
"### Import the initial seed data file"
]
},
{
"cell_type": "code",
"execution_count": 10,
"id": "639de050",
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Waiting for Dataset Import Job with ARN arn:aws:forecast:us-west-2XXXXXXXXXXXXdataset-import-job/TAXI_PREDICTOR_MONITOR_DEMO/TAXI_TTS_seed to become ACTIVE.\n",
"\n",
"Current Status:\n",
"\n",
"CREATE_PENDING \n",
"CREATE_IN_PROGRESS \n",
"ACTIVE \n"
]
}
],
"source": [
"TS_IMPORT_JOB_NAME = 'TAXI_TTS_seed'\n",
"TIMESTAMP_FORMAT = \"yyyy-MM-dd hh:mm:ss\"\n",
"ts_s3_path = f\"s3://{bucket_name}/{TS_IMPORT_JOB_NAME}.csv\"\n",
"TIMEZONE = \"EST\"\n",
"\n",
"#frequency of poll event from API to check status of tasks\n",
"sleep_duration=300\n",
"\n",
"\n",
"ts_dataset_import_job_response = \\\n",
" forecast.create_dataset_import_job(DatasetImportJobName=TS_IMPORT_JOB_NAME,\n",
" DatasetArn=ts_dataset_arn,\n",
" DataSource= {\n",
" \"S3Config\" : {\n",
" \"Path\": ts_s3_path,\n",
" \"RoleArn\": role_arn\n",
" } \n",
" },\n",
" TimestampFormat=TIMESTAMP_FORMAT,\n",
" TimeZone = TIMEZONE)\n",
"\n",
"ts_dataset_import_job_arn = ts_dataset_import_job_response['DatasetImportJobArn']\n",
"\n",
"print(f\"Waiting for Dataset Import Job with ARN {mask_arn(ts_dataset_import_job_arn)} to become ACTIVE.\\n\\nCurrent Status:\\n\")\n",
"\n",
"status = util.wait(lambda: forecast.describe_dataset_import_job(DatasetImportJobArn=ts_dataset_import_job_arn), sleep_duration)\n",
" "
]
},
{
"cell_type": "markdown",
"id": "7a35a3c2",
"metadata": {},
"source": [
"### Create a dataset group"
]
},
{
"cell_type": "code",
"execution_count": 11,
"id": "1b72499f",
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"The DatasetGroup with ARN arn:aws:forecast:us-west-2XXXXXXXXXXXXdataset-group/TAXI_PREDICTOR_MONITOR_DEMO is now ACTIVE.\n"
]
}
],
"source": [
"DATASET_GROUP_NAME = \"TAXI_PREDICTOR_MONITOR_DEMO\"\n",
"DATASET_ARNS = [ts_dataset_arn]\n",
"\n",
"create_dataset_group_response = \\\n",
" forecast.create_dataset_group(Domain=\"CUSTOM\",\n",
" DatasetGroupName=DATASET_GROUP_NAME,\n",
" DatasetArns=DATASET_ARNS)\n",
"\n",
"dataset_group_arn = create_dataset_group_response['DatasetGroupArn']\n",
"describe_dataset_group_response = forecast.describe_dataset_group(DatasetGroupArn=dataset_group_arn)\n",
"\n",
"print(f\"The DatasetGroup with ARN {mask_arn(dataset_group_arn)} is now {describe_dataset_group_response['Status']}.\")"
]
},
{
"cell_type": "markdown",
"id": "5b8720a3",
"metadata": {},
"source": [
"### Create a new auto predictor with MonitorConfig defined\n",
"\n",
"Observe the new paramter in the create_auto_predictor() function MonitorConfig."
]
},
{
"cell_type": "code",
"execution_count": 16,
"id": "f6dec49e",
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Waiting for Predictor with ARN arn:aws:forecast:us-west-2XXXXXXXXXXXXpredictor/TAXI_PREDICTOR_MONITOR_DEMO_01G3RQ4MCPS4YD26G4YB5FNYRR to become ACTIVE. Depending on data size and predictor setting,it can take several hours to be ACTIVE.\n",
"\n",
"Current Status:\n",
"\n",
"CREATE_PENDING \n",
"CREATE_IN_PROGRESS ..........\n",
"ACTIVE \n",
"Predictor with ARN arn:aws:forecast:us-west-2XXXXXXXXXXXXpredictor/TAXI_PREDICTOR_MONITOR_DEMO_01G3RQ4MCPS4YD26G4YB5FNYRR is ACTIVE.\n"
]
}
],
"source": [
"PREDICTOR_NAME = \"TAXI_PREDICTOR_MONITOR_DEMO\"\n",
"FORECAST_HORIZON = 4\n",
"FORECAST_FREQUENCY = \"D\"\n",
"\n",
"create_auto_predictor_response = \\\n",
" forecast.create_auto_predictor(PredictorName = PREDICTOR_NAME,\n",
" ForecastHorizon = FORECAST_HORIZON,\n",
" ForecastFrequency = FORECAST_FREQUENCY,\n",
" DataConfig = {\n",
" 'DatasetGroupArn': dataset_group_arn\n",
" },\n",
" MonitorConfig={\"MonitorName\": \"TAXI_PREDICTOR_MONITOR_DEMO\"},\n",
" ForecastTypes=[\"0.5\"],\n",
" OptimizationMetric=\"MAPE\"\n",
" )\n",
"\n",
"predictor_arn = create_auto_predictor_response['PredictorArn']\n",
"print(f\"Waiting for Predictor with ARN {mask_arn(predictor_arn)} to become ACTIVE. Depending on data size and predictor setting,it can take several hours to be ACTIVE.\\n\\nCurrent Status:\\n\")\n",
"\n",
"status = util.wait(lambda: forecast.describe_auto_predictor(PredictorArn=predictor_arn), sleep_duration)\n",
"\n",
"print(f\"Predictor with ARN {mask_arn(predictor_arn)} is ACTIVE.\")\n",
"\n",
"# retrieve the monitor ARN for future inspection as monitor_arn variable\n",
"response = forecast.list_monitors()\n",
"for i in response['Monitors']:\n",
" if i['ResourceArn']==predictor_arn:\n",
" monitor_arn = i['MonitorArn']"
]
},
{
"cell_type": "markdown",
"id": "cb24bb7f",
"metadata": {},
"source": [
"### Create a new forecast based on the newly created predictor\n",
"\n",
"This predictor and forecast is based on the initial seed dataset only, the first 100k rows."
]
},
{
"cell_type": "code",
"execution_count": 17,
"id": "6c864c96",
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Waiting for Forecast with ARN arn:aws:forecast:us-west-2XXXXXXXXXXXXforecast/TAXI_FORECAST_seed to become ACTIVE. Depending on data size and predictor settings,it can take several hours to be ACTIVE.\n",
"\n",
"Current Status:\n",
"\n",
"CREATE_PENDING \n",
"CREATE_IN_PROGRESS .\n",
"ACTIVE \n"
]
}
],
"source": [
"FORECAST_NAME = \"TAXI_FORECAST_seed\"\n",
" \n",
"create_forecast_response = \\\n",
" forecast.create_forecast(ForecastName=FORECAST_NAME,\n",
" PredictorArn=predictor_arn)\n",
"\n",
"forecast_arn = create_forecast_response['ForecastArn']\n",
"\n",
"print(f\"Waiting for Forecast with ARN {mask_arn(forecast_arn)} to become ACTIVE. Depending on data size and predictor settings,it can take several hours to be ACTIVE.\\n\\nCurrent Status:\\n\")\n",
"\n",
"status = util.wait(lambda: forecast.describe_forecast(ForecastArn=forecast_arn), sleep_duration)\n"
]
},
{
"cell_type": "markdown",
"id": "9f44f041",
"metadata": {},
"source": [
"# Step 3: Demonstrate the Predictor Monitoring Lifecycle\n",
"\n",
"In Step 3, we will import the four additional data files created from Step 1. Each data file successively adds an additional 25k rows of new ground truth target time series data.\n",
"\n",
"It is not expected you have to run this workflow, you may elect to read the output results. The workflow is as follows.\n",
"\n",
"1. import t1 csv file\n",
"2. produce a new forecast which is based on t1 imported TTS state\n",
"3. import t2 csv file\n",
"4. produce a new forecast which is based on t2 imported TTS state\n",
"5. import t3 csv file\n",
"6. retrain the original auto-predictor based on the t3 imported TTS state\n",
"7. produce a new forecast which is based on t3 imported TTS state\n",
"8. import t4 csv file\n",
"9. produce a new forecast which is based on t4 imported TTS state\n",
"10. finally, review the monitor performance results in this notebook.\n",
"\n",
"If you elect to run this in your account, you may see the graphic in the console also."
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "b92d7644",
"metadata": {
"scrolled": false
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"\n",
"\n",
"Processing incremental TTS dataset file 1\n",
"\n",
"Waiting for Dataset Import Job with ARN arn:aws:forecast:us-west-2XXXXXXXXXXXXdataset-import-job/TAXI_PREDICTOR_MONITOR_DEMO/TAXI_TTS_t1 to become ACTIVE.\n",
"\n",
"CREATE_PENDING \n",
"ACTIVE \n",
"Waiting for Dataset ARN arn:aws:forecast:us-west-2XXXXXXXXXXXXdataset/TAXI_PREDICTOR_MONITOR_DEMO to become ACTIVE.\n",
"\n",
"ACTIVE \n",
"Waiting for Forecast with ARN arn:aws:forecast:us-west-2XXXXXXXXXXXXforecast/TAXI_FORECAST_1 to become ACTIVE.\n",
"\n",
"CREATE_PENDING \n",
"CREATE_IN_PROGRESS ...\n",
"ACTIVE \n",
"\n",
"\n",
"Processing incremental TTS dataset file 2\n",
"\n",
"Waiting for Dataset Import Job with ARN arn:aws:forecast:us-west-2XXXXXXXXXXXXdataset-import-job/TAXI_PREDICTOR_MONITOR_DEMO/TAXI_TTS_t2 to become ACTIVE.\n",
"\n",
"CREATE_PENDING \n",
"ACTIVE \n",
"Waiting for Dataset ARN arn:aws:forecast:us-west-2XXXXXXXXXXXXdataset/TAXI_PREDICTOR_MONITOR_DEMO to become ACTIVE.\n",
"\n",
"ACTIVE \n",
"Waiting for Forecast with ARN arn:aws:forecast:us-west-2XXXXXXXXXXXXforecast/TAXI_FORECAST_2 to become ACTIVE.\n",
"\n",
"CREATE_PENDING \n",
"CREATE_IN_PROGRESS ...\n",
"ACTIVE \n",
"\n",
"\n",
"Processing incremental TTS dataset file 3\n",
"\n",
"Waiting for Dataset Import Job with ARN arn:aws:forecast:us-west-2XXXXXXXXXXXXdataset-import-job/TAXI_PREDICTOR_MONITOR_DEMO/TAXI_TTS_t3 to become ACTIVE.\n",
"\n",
"CREATE_PENDING \n",
"ACTIVE \n",
"Waiting for Dataset ARN arn:aws:forecast:us-west-2XXXXXXXXXXXXdataset/TAXI_PREDICTOR_MONITOR_DEMO to become ACTIVE.\n",
"\n",
"ACTIVE \n",
"Waiting for Predictor with ARN arn:aws:forecast:us-west-2XXXXXXXXXXXXpredictor/TAXI_PREDICTOR_MONITOR_DEMO_RETRAIN1_01G3RZNZRZXBQP0EF81NC4CETK to become ACTIVE.\n",
"\n",
"CREATE_PENDING \n",
"CREATE_IN_PROGRESS .....\n",
"ACTIVE \n",
"Waiting for Forecast with ARN arn:aws:forecast:us-west-2XXXXXXXXXXXXforecast/TAXI_FORECAST_3 to become ACTIVE.\n",
"\n",
"CREATE_PENDING \n",
"CREATE_IN_PROGRESS .\n",
"ACTIVE \n",
"\n",
"\n",
"Processing incremental TTS dataset file 4\n",
"\n",
"Waiting for Dataset Import Job with ARN arn:aws:forecast:us-west-2XXXXXXXXXXXXdataset-import-job/TAXI_PREDICTOR_MONITOR_DEMO/TAXI_TTS_t4 to become ACTIVE.\n",
"\n",
"CREATE_PENDING \n",
"ACTIVE \n",
"Waiting for Dataset ARN arn:aws:forecast:us-west-2XXXXXXXXXXXXdataset/TAXI_PREDICTOR_MONITOR_DEMO to become ACTIVE.\n",
"\n",
"ACTIVE \n",
"Waiting for Forecast with ARN arn:aws:forecast:us-west-2XXXXXXXXXXXXforecast/TAXI_FORECAST_4 to become ACTIVE.\n",
"\n",
"CREATE_PENDING \n",
"CREATE_IN_PROGRESS ....\n",
"ACTIVE \n"
]
}
],
"source": [
"TIMESTAMP_FORMAT = \"yyyy-MM-dd hh:mm:ss\"\n",
"TIMEZONE = \"EST\"\n",
"\n",
"for i in range(1,5):\n",
"\n",
" TS_IMPORT_JOB_NAME = 'TAXI_TTS_t'+str(i)\n",
" ts_s3_path = f\"s3://{bucket_name}/{TS_IMPORT_JOB_NAME}.csv\"\n",
"\n",
" print('\\n\\nProcessing incremental TTS dataset file '+str(i)+'\\n')\n",
" \n",
" # Invoke import job of file i\n",
" ts_dataset_import_job_response = \\\n",
" forecast.create_dataset_import_job(DatasetImportJobName=TS_IMPORT_JOB_NAME,\n",
" DatasetArn=ts_dataset_arn,\n",
" DataSource= {\n",
" \"S3Config\" : {\n",
" \"Path\": ts_s3_path,\n",
" \"RoleArn\": role_arn\n",
" } \n",
" },\n",
" TimestampFormat=TIMESTAMP_FORMAT,\n",
" TimeZone = TIMEZONE)\n",
"\n",
" ts_dataset_import_job_arn = ts_dataset_import_job_response['DatasetImportJobArn']\n",
"\n",
" # Wait on import to complete\n",
" print(f\"Waiting for Dataset Import Job with ARN {mask_arn(ts_dataset_import_job_arn)} to become ACTIVE.\\n\")\n",
" status = util.wait(lambda: forecast.describe_dataset_import_job(DatasetImportJobArn=ts_dataset_import_job_arn), sleep_duration)\n",
"\n",
" # Wait on dataset to become active\n",
" print(f\"Waiting for Dataset ARN {mask_arn(ts_dataset_arn)} to become ACTIVE.\\n\")\n",
" status = util.wait(lambda: forecast.describe_dataset(DatasetArn=ts_dataset_arn), sleep_duration)\n",
" \n",
" # only after importing third of four new datasets, retrain original predictor\n",
" \n",
" if i==3:\n",
" \n",
" PREDICTOR_NAME = \"TAXI_PREDICTOR_MONITOR_DEMO_RETRAIN1\"\n",
"\n",
" create_auto_predictor_response = \\\n",
" forecast.create_auto_predictor(PredictorName = PREDICTOR_NAME,\n",
" ReferencePredictorArn=predictor_arn\n",
" )\n",
" \n",
" predictor_arn = create_auto_predictor_response['PredictorArn']\n",
"\n",
" # wait on retrained predictor to become active\n",
" print(f\"Waiting for Predictor with ARN {mask_arn(predictor_arn)} to become ACTIVE.\\n\")\n",
" status = util.wait(lambda: forecast.describe_auto_predictor(PredictorArn=predictor_arn), sleep_duration)\n",
"\n",
" \n",
" # Generate a new forecast based on latest file import\n",
" \n",
" FORECAST_NAME = \"TAXI_FORECAST_\" + str(i)\n",
" \n",
" create_forecast_response = \\\n",
" forecast.create_forecast(ForecastName=FORECAST_NAME,\n",
" PredictorArn=predictor_arn)\n",
"\n",
" forecast_arn = create_forecast_response['ForecastArn']\n",
"\n",
" # Wait on forecast to complete\n",
" print(f\"Waiting for Forecast with ARN {mask_arn(forecast_arn)} to become ACTIVE.\\n\")\n",
" status = util.wait(lambda: forecast.describe_forecast(ForecastArn=forecast_arn), sleep_duration)"
]
},
{
"cell_type": "markdown",
"id": "27438c6d",
"metadata": {},
"source": [
"# Step 4: View the Predictor Monitor Evaluation\n",
"\n",
"This overall step shows the performance of the monitor over time after cumulative files t1, t2, t3, t4 were imported. While this example shows how to look at the data from the JSON response produced by list_monitor_evaluations(), you might consider using the built-in visualization available inside the AWS Console.\n",
"\n",
"Please review the output below. The model metrics decrease slightly after input files t1 and t2 are imported. After t2, a new predictor is trained, leading to better loss metrics in t3 and t4. The main goal is to use the monitor to know when metrics have degraded beyond your required threshold. At that time, you can create and install a new predictor as the basis for generating forecasts.\n"
]
},
{
"cell_type": "code",
"execution_count": 19,
"id": "7b24f5c8",
"metadata": {
"scrolled": false
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"PredictorARN:\n",
" arn:aws:forecast:us-west-2XXXXXXXXXXXXpredictor/TAXI_PREDICTOR_MONITOR_DEMO_RETRAIN1_01G3RZNZRZXBQP0EF81NC4CETK\n",
"MonitorARN:\n",
" arn:aws:forecast:us-west-2XXXXXXXXXXXXmonitor/TAXI_PREDICTOR_MONITOR_DEMO_RETRAIN1_01G3S1G876GRBAV467GCM9H53Q \n",
"\n",
"\n",
"Dataset ARN:\n",
" arn:aws:forecast:us-west-2XXXXXXXXXXXXdataset-import-job/TAXI_PREDICTOR_MONITOR_DEMO/TAXI_TTS_t4\n",
"Evaluation State: SUCCESS\n",
"Evaluation EvaluationTime: 2022-05-23 18:26:37.953000+00:00\n",
"Evaluation Window: 2018-02-01 00:00:00+00:00 2018-02-04 00:00:00+00:00\n",
"AverageWeightedQuantileLoss : 0.3553749003728468\n",
"MAPE : 0.34043327644304344\n",
"MASE : 1.38765530970562\n",
"RMSE : 1120.6850296685875\n",
"WAPE : 0.36202280281927385\n",
"\n",
"\n",
"\n",
"Dataset ARN:\n",
" arn:aws:forecast:us-west-2XXXXXXXXXXXXdataset-import-job/TAXI_PREDICTOR_MONITOR_DEMO/TAXI_TTS_t3\n",
"Evaluation State: SUCCESS\n",
"Evaluation EvaluationTime: 2022-05-23 17:31:12.771000+00:00\n",
"Evaluation Window: 2018-01-23 00:00:00+00:00 2018-01-26 00:00:00+00:00\n",
"AverageWeightedQuantileLoss : 0.3991355863665969\n",
"MAPE : 0.3479828773653574\n",
"MASE : 2.117661988914599\n",
"RMSE : 1300.8822299266126\n",
"WAPE : 0.40440517358383227\n",
"\n",
"\n",
"\n",
"Dataset ARN:\n",
" arn:aws:forecast:us-west-2XXXXXXXXXXXXdataset-import-job/TAXI_PREDICTOR_MONITOR_DEMO/TAXI_TTS_t2\n",
"Evaluation State: SUCCESS\n",
"Evaluation EvaluationTime: 2022-05-23 17:01:30.794000+00:00\n",
"Evaluation Window: 2018-01-14 00:00:00+00:00 2018-01-17 00:00:00+00:00\n",
"AverageWeightedQuantileLoss : 0.34650592141115494\n",
"MAPE : 0.3941621451322716\n",
"MASE : 1.215797920572568\n",
"RMSE : 1088.2858784224168\n",
"WAPE : 0.3545567487712633\n",
"\n",
"\n",
"\n",
"Dataset ARN:\n",
" arn:aws:forecast:us-west-2XXXXXXXXXXXXdataset-import-job/TAXI_PREDICTOR_MONITOR_DEMO/TAXI_TTS_t1\n",
"Evaluation State: SUCCESS\n",
"Evaluation EvaluationTime: 2022-05-23 16:31:25.517000+00:00\n",
"Evaluation Window: 2018-01-05 00:00:00+00:00 2018-01-08 00:00:00+00:00\n",
"AverageWeightedQuantileLoss : 0.34519002283184813\n",
"MAPE : 0.3926562708496404\n",
"MASE : 1.3463904011138421\n",
"RMSE : 969.3938966956972\n",
"WAPE : 0.3575639169813357\n",
"\n",
"\n",
"\n"
]
}
],
"source": [
"list_monitor_response = forecast.list_monitors()\n",
"\n",
"for i in list_monitor_response['Monitors']:\n",
" if i['ResourceArn'] == predictor_arn:\n",
" monitor_arn = i['MonitorArn']\n",
"\n",
"#for display purposes\n",
"monitor_evaluations = forecast.list_monitor_evaluations(\n",
" MonitorArn=monitor_arn,\n",
" MaxResults=10\n",
")\n",
"\n",
"print('PredictorARN:\\n',mask_arn(predictor_arn))\n",
"print('MonitorARN:\\n',mask_arn(monitor_arn),'\\n\\n')\n",
"\n",
"for i in monitor_evaluations['PredictorMonitorEvaluations']:\n",
"\n",
" print ('Dataset ARN:\\n',mask_arn(i['MonitorDataSource']['DatasetImportJobArn']))\n",
" print ('Evaluation State: ',i['EvaluationState'])\n",
" print ('Evaluation EvaluationTime: ',i['EvaluationTime'])\n",
" print ('Evaluation Window: ',i['WindowStartDatetime'],i['WindowEndDatetime'])\n",
" \n",
" if i['EvaluationState'] !='FAILURE':\n",
" \n",
" for m in i['MetricResults']:\n",
" print (m['MetricName'],': ',m['MetricValue'])\n",
" \n",
" print ('\\n\\n')"
]
},
{
"cell_type": "markdown",
"id": "b0bcb59e",
"metadata": {},
"source": [
"Below is an example of a chart that helps conceptualize a model's performance over time, available inside the AWS Console.\n",
"\n",
"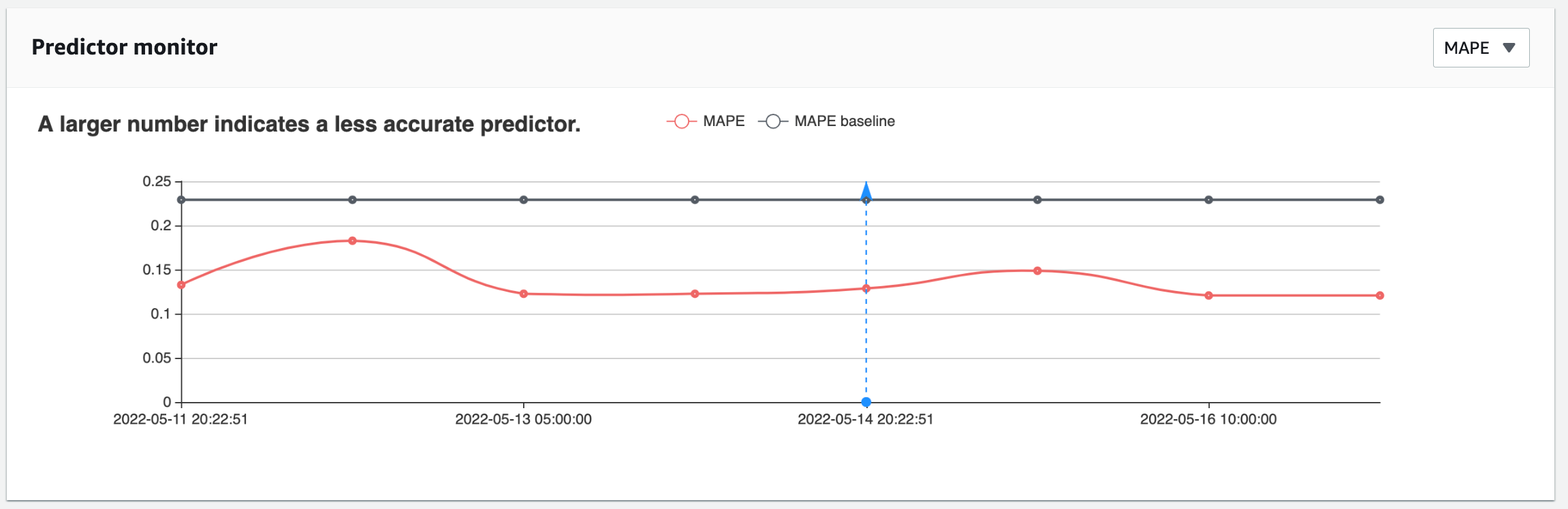"
]
},
{
"cell_type": "markdown",
"id": "e1eb1c22",
"metadata": {},
"source": [
"# Step 5: Cleanup\n",
"\n",
"You will need to allow a few minutes for each of these steps to complete.\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "d9413778",
"metadata": {},
"outputs": [],
"source": [
"forecast.delete_resource_tree(ResourceArn=dataset_group_arn)"
]
},
{
"cell_type": "markdown",
"id": "47afb63e",
"metadata": {},
"source": [
"Once the dataset group has been deleted (allow a few minutes), you may proceed. The following code will allow you to test and determine when the dataset group has been deleted. When you run this next cell, you may see your dataset group. Allow a couple minutes, and try again. Once your dataset is deleted, you may proceed to next step."
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "38792508",
"metadata": {},
"outputs": [],
"source": [
"forecast.list_dataset_groups()"
]
},
{
"cell_type": "markdown",
"id": "99effe01",
"metadata": {},
"source": [
"Delete dataset import jobs with TAXI_PREDICTOR_MONITOR_DEMO in the job name."
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "7ec3762f",
"metadata": {},
"outputs": [],
"source": [
"response = forecast.list_dataset_import_jobs()\n",
"\n",
"for i in response['DatasetImportJobs']:\n",
"\n",
" try:\n",
" if i['DatasetImportJobArn'].index('TAXI_PREDICTOR_MONITOR_DEMO'):\n",
" print('Deleting',i['DatasetImportJobName'])\n",
" forecast.delete_dataset_import_job(DatasetImportJobArn=i['DatasetImportJobArn'])\n",
" except:\n",
" pass"
]
},
{
"cell_type": "markdown",
"id": "b1087d64",
"metadata": {},
"source": [
"It will take a few minutes to delete the dataset import jobs. Once that is complete, the dataset can be deleted as follows in the next cell."
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "8e85dbec",
"metadata": {},
"outputs": [],
"source": [
"forecast.delete_dataset(DatasetArn=ts_dataset_arn)"
]
}
],
"metadata": {
"kernelspec": {
"display_name": "conda_pytorch_p36",
"language": "python",
"name": "conda_pytorch_p36"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.6.13"
}
},
"nbformat": 4,
"nbformat_minor": 5
}