{
"cells": [
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Explore Automated Deployment Artifacts \n",
"\n",
"This notebook explores an abbreviated Amazon Personalize learning experience where most of the Personalize resources have been pre-created for you. For example, the schemas and datasets have already been created and the machine learning models have already been trained. This allows you to get hands on experience with several Amazon Personalize concepts in a more brief and concise format.\n",
"\n",
"## How to Use the Notebook \n",
"\n",
"The notebook is broken up into a series of cells that can be either filled with documentation (like this one) or snippets of source code as you'll see below. Cells can be \"executed\" by clicking on the \"Run\" button in the toolbar at the top of this page. When a cell is executed, the notebook will move forward to the next cell. \n",
"\n",
"As a cell is executing you'll notice the square brackets in the left margin will display `*` while the cell is running and then will change to a number to indicate the last cell that completed executing after it has finished exectuting all the code within the cell.\n",
"\n",
"Simply follow the instructions below and read and execute the cells to get started.\n",
"\n",
"\n",
"## Introduction \n",
"[Back to top](#top)\n",
"\n",
"In Amazon Personalize, you start by creating a dataset group, which is a container for Amazon Personalize components. Your dataset group can be one of the following:\n",
"\n",
"A Domain dataset group, where you create preconfigured resources for different business domains and use cases, such as getting recommendations for similar videos (VIDEO_ON_DEMAND domain) or best selling items (ECOMMERCE domain). You choose your business domain, import your data, and create recommenders. You use recommenders in your application to get recommendations.\n",
"\n",
"Use a [Domain dataset group](https://docs.aws.amazon.com/personalize/latest/dg/domain-dataset-groups.html) if you have a video on demand or e-commerce application and want Amazon Personalize to find the best configurations for your use cases. If you start with a Domain dataset group, you can also add custom resources such as solutions with solution versions trained with recipes for custom use cases.\n",
"\n",
"A [Custom dataset group](https://docs.aws.amazon.com/personalize/latest/dg/custom-dataset-groups.html), where you create configurable resources for custom use cases and batch recommendation workflows. You choose a recipe, train a solution version (model), and deploy the solution version with a campaign. You use a campaign in your application to get recommendations.\n",
"\n",
"Use a Custom dataset group if you don't have a video on demand or e-commerce application or want to configure and manage only custom resources, or want to get recommendations in a batch workflow. If you start with a Custom dataset group, you can't associate it with a domain later. Instead, create a new Domain dataset group.\n",
"\n",
"You can create and manage Domain dataset groups and Custom dataset groups with the AWS console, the AWS Command Line Interface (AWS CLI), or programmatically with the AWS SDKs.\n",
"\n",
"\n",
"## Define your Use Case \n",
"[Back to top](#top)\n",
"\n",
"There are a few guidelines for scoping a problem suitable for Personalize. We recommend the values below as a starting point, although the [official limits](https://docs.aws.amazon.com/personalize/latest/dg/limits.html) lie a little lower.\n",
"\n",
"* Authenticated/known users\n",
"* At least 50 unique users\n",
"* At least 100 unique items\n",
"* At least 2 dozen interactions for each user \n",
"\n",
"Most of the time this is easily attainable, and if you are low in one category, you can often make up for it by having a larger number in another category.\n",
"\n",
"The user-item-iteraction data is key for getting started with the service. This means we need to look for use cases that generate that kind of data, a few common examples are:\n",
"\n",
"1. Video-on-demand applications\n",
"1. E-commerce platforms\n",
"1. Social media aggregators / platforms\n",
"\n",
"Generally speaking your data will not arrive in a perfect form for Personalize, and will take some modification to be structured correctly. This notebook looks to guide you through all of that. \n",
"\n",
"To begin with, we are going to use the latest MovieLens dataset, this dataset has over 25 million interactions and a rich collection of metadata for items, there is also a smaller version of this dataset, which can be used to shorten training times, while still incorporating the same capabilities as the full dataset. Set USE_FULL_MOVIELENS to True to use the full dataset.\n",
"\n",
"The cell below is the first code cell in this notebook. The run the code in the cell, select it and click the \"Run\" button in the toolbar at the top of the page."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"USE_FULL_MOVIELENS = False"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"First, you will download the dataset and unzip it in a new folder using the code below."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"data_dir = \"poc_data\"\n",
"!rm -rf $data_dir\n",
"!mkdir $data_dir\n",
"\n",
"if not USE_FULL_MOVIELENS:\n",
" !cd $data_dir && wget http://files.grouplens.org/datasets/movielens/ml-latest-small.zip\n",
" !cd $data_dir && unzip ml-latest-small.zip\n",
" dataset_dir = data_dir + \"/ml-latest-small/\"\n",
"else:\n",
" !cd $data_dir && wget http://files.grouplens.org/datasets/movielens/ml-25m.zip\n",
" !cd $data_dir && unzip ml-25m.zip\n",
" dataset_dir = data_dir + \"/ml-25m/\""
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Take a look at the data files you have downloaded."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"!ls $dataset_dir"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"At present not much is known except that we have a few CSVs and a readme. Next we will output the readme to learn more!"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Prepare your data \n",
"[Back to top](#top)\n",
"\n",
"The next thing to be done is to load the data and confirm the data is in a good state, then save it to a CSV where it is ready to be used with Amazon Personalize.\n",
"\n",
"To get started, import a collection of Python libraries commonly used in data science."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"import sys\n",
"import getopt\n",
"import logging\n",
"import botocore\n",
"import boto3\n",
"import time\n",
"from packaging import version\n",
"from time import sleep\n",
"from botocore.exceptions import ClientError\n",
"import json\n",
"from datetime import datetime\n",
"import pandas as pd\n",
"import uuid\n",
"import random"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Next,open the data file and take a look at the first several rows."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"original_data = pd.read_csv(dataset_dir + '/ratings.csv')\n",
"original_data.head(5)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"original_data.shape"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"original_data.describe()"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"This shows that we have a good range of values for `userId` and `movieId`. Next, it is always a good idea to confirm the data format."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"original_data.info()"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"original_data.isnull().any()"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"From this, you can see that there are a total of (25,000,095 for full 100836 for small) entries in the dataset, with 4 columns, and each cell stored as int64 format, with the exception of the rating whihch is a float64.\n",
"\n",
"The int64 format is clearly suitable for `userId` and `movieId`. However, we need to diver deeper to understand the timestamps in the data. To use Amazon Personalize, you need to save timestamps in [Unix Epoch](https://en.wikipedia.org/wiki/Unix_time) format.\n",
"\n",
"Currently, the timestamp values are not human-readable. So let's grab an arbitrary timestamp value and figure out how to interpret it."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Do a quick sanity check on the transformed dataset by picking an arbitrary timestamp and transforming it to a human-readable format."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"arb_time_stamp = original_data.iloc[50]['timestamp']\n",
"print(arb_time_stamp)\n",
"print(datetime.utcfromtimestamp(arb_time_stamp).strftime('%Y-%m-%d %H:%M:%S'))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"This date makes sense as a timestamp, so we can continue formatting the rest of the data. Remember, the data we need is user-item-interaction data, which is `userId`, `movieId`, and `timestamp` in this case. Our dataset has an additional column, `rating`, which can be dropped from the dataset after we have leveraged it to focus on positive interactions."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Since this is an explicit feedback movie rating dataset, it includes movies rated from 1 to 5, we want to include only moves that weree \"liked\" by the users, and simulate a implicit dataset that is more like what data would be gathered by a VOD platform. For that so we will filter out all interactions under 2 out of 5, and create an EVENT_Type of \"click\" and an EVENT_Type of \"watch\". We will then assign all movies rated 2 and above as \"click\" and movies above 4 and above as \"click\" and \"watch\".\n",
"\n",
"Note this is to correspond with the events we are modeling, for a real data set you would actually model based on implicit feedback like clicks, watches and/or explicit feedback like ratings, likes etc."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"watched_df = original_data.copy()\n",
"watched_df = watched_df[watched_df['rating'] > 3]\n",
"watched_df = watched_df[['userId', 'movieId', 'timestamp']]\n",
"watched_df['EVENT_TYPE']='watch'\n",
"watched_df.head()"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"clicked_df = original_data.copy()\n",
"clicked_df = clicked_df[clicked_df['rating'] > 1]\n",
"clicked_df = clicked_df[['userId', 'movieId', 'timestamp']]\n",
"clicked_df['EVENT_TYPE']='click'\n",
"clicked_df.head()"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"interactions_df = clicked_df.copy()\n",
"interactions_df = interactions_df.append(watched_df)\n",
"interactions_df.sort_values(\"timestamp\", axis = 0, ascending = True, \n",
" inplace = True, na_position ='last') "
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"interactions_df.info()"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"lets look at what the new dataset looks like "
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"interactions_df.describe()"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"After manipulating the data, always confirm if the data format has changed."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"interactions_df.dtypes"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
" Amazon Personalize has default column names for users, items, and timestamp. These default column names are `USER_ID`, `ITEM_ID`, AND `TIMESTAMP`. So the final modification to the dataset is to replace the existing column headers with the default headers."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"interactions_df.rename(columns = {'userId':'USER_ID', 'movieId':'ITEM_ID', \n",
" 'timestamp':'TIMESTAMP'}, inplace = True) "
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"That's it! At this point the data is ready to go, and we just need to save it as a CSV file."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"interactions_filename = \"interactions.csv\"\n",
"interactions_df.to_csv((data_dir+\"/\"+interactions_filename), index=False, float_format='%.0f')"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Retrieve your automated deployment variables\n",
"\n",
"As mentioned at the top of this notebook, a dataset group, schemas, datasets, solutions, and campaigns have already been created for you. You can open another browser tab/window to view these resources in the Personalize AWS Console. \n",
"\n",
"The code below will lookup the pre-created resources using the Personalize API."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Configure the SDK to Personalize:\n",
"personalize = boto3.client('personalize')\n",
"personalize_runtime = boto3.client('personalize-runtime')\n",
"personalize_events = boto3.client(service_name='personalize-events')\n",
"from script import get_dataset_group_info, filter_arns, dataset_arns, schema_arns, event_tracker_arns, campaign_arns, solution_arns\n",
"datasetGroupArn = get_dataset_group_info('AmazonPersonalizeImmersionDay')\n",
"for dataset in dataset_arns:\n",
" if dataset.find(\"INTERACTIONS\") != -1:\n",
" interactions_dataset_arn = dataset\n",
"for dataset in dataset_arns:\n",
" if dataset.find(\"ITEMS\") != -1:\n",
" items_dataset_arn = dataset\n",
"for dataset in dataset_arns:\n",
" if dataset.find(\"USERS\") != -1:\n",
" users_dataset_arn = dataset\n",
"for schema in schema_arns:\n",
" if schema.find(\"Interactions\") != -1:\n",
" interactions_schema_arn = schema\n",
"for schema in schema_arns:\n",
" if schema.find(\"User\") != -1:\n",
" users_schema_arn = schema \n",
"for schema in schema_arns:\n",
" if schema.find(\"Item\") != -1:\n",
" items_schema_arn = schema \n",
"for campaign in campaign_arns:\n",
" if campaign.find(\"Personalization\") != -1:\n",
" personalization_campaign_arn = campaign\n",
"for campaign in campaign_arns:\n",
" if campaign.find(\"sims\") != -1:\n",
" sims_campaign_arn = campaign\n",
"for campaign in campaign_arns:\n",
" if campaign.find(\"Ranking\") != -1:\n",
" ranking_campaign_arn = campaign\n",
"for solution in solution_arns:\n",
" if solution.find(\"Personalization\") != -1:\n",
" personalization_solution_arn = solution\n",
"for solution in solution_arns:\n",
" if solution.find(\"sims\") != -1:\n",
" sims_solution_arn = solution\n",
"for solution in solution_arns:\n",
" if solution.find(\"ranking\") != -1:\n",
" ranking_solution_arn = solution\n",
"\n",
"event_tracker_arn = event_tracker_arns[0]\n",
"with open('/opt/ml/metadata/resource-metadata.json') as notebook_info:\n",
" data = json.load(notebook_info)\n",
" resource_arn = data['ResourceArn']\n",
" region = resource_arn.split(':')[3]\n",
"print(region)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Dataset groups and the interactions dataset \n",
"[Back to top](#top)\n",
"\n",
"The highest level of isolation and abstraction with Amazon Personalize is a *dataset group*. Information stored within one of these dataset groups has no impact on any other dataset group or models created from one - they are completely isolated. This allows you to run many experiments and is part of how we keep your models private and fully trained only on your data. \n",
"\n",
"Before importing the data prepared earlier, there needs to be a dataset group and a dataset added to it that handles the interactions.\n",
"\n",
"Dataset groups can house the following types of information:\n",
"\n",
"* User-item-interactions\n",
"* Event streams (real-time interactions)\n",
"* User metadata\n",
"* Item metadata\n",
"\n",
"Before we create the dataset group and the dataset for our interaction data, let's validate that your environment can communicate successfully with Amazon Personalize."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Describe the dataset group\n",
"\n",
"The following cell will describe the dataset group with the name `AmazonPersonalizeImmersionDay`."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"print(datasetGroupArn)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"describe_dataset_group_response = personalize.describe_dataset_group(\n",
" datasetGroupArn = datasetGroupArn\n",
")\n",
"dataset_group_arn= datasetGroupArn\n",
"print(dataset_group_arn)\n",
"print(json.dumps(describe_dataset_group_response, indent=4, sort_keys=True, default=str))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Now that you have a dataset group, you can inspect the datasets."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Describe the Interactions dataset\n",
"\n",
"First, define a schema to tell Amazon Personalize what type of dataset you are uploading. There are several reserved and mandatory keywords required in the schema, based on the type of dataset. More detailed information can be found in the [documentation](https://docs.aws.amazon.com/personalize/latest/dg/how-it-works-dataset-schema.html).\n",
"\n",
"Here, you will retrieve the schema for interactions data, which needs the `USER_ID`, `ITEM_ID`, and `TIMESTAMP` fields. These must be defined in the same order in the schema as they appear in the dataset."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"describe_schema_response = personalize.describe_schema(\n",
" schemaArn=interactions_schema_arn\n",
")\n",
"\n",
"interaction_schema_arn = describe_schema_response['schema']['schemaArn']\n",
"print(json.dumps(describe_schema_response, indent=4, sort_keys=True, default=str))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Take note of the `schema` field within the `schema` dictionary. This string defines the schema layout for the dataset using the Avro format. \n",
"\n",
"Next we will describe the dataset itself to check its name, type, assigned schema, and status."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"dataset_type = \"INTERACTIONS\"\n",
"describe_dataset_response = personalize.describe_dataset(\n",
" datasetArn = interactions_dataset_arn,\n",
")\n",
"interactions_dataset_arn = describe_dataset_response['dataset']['datasetArn']\n",
"print(json.dumps(describe_dataset_response, indent=4, sort_keys=True, default=str))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Validating the Item Metadata \n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Prepare your Item metadata \n",
"[Back to top](#top)\n",
"\n",
"The next thing to be done is to load the data and confirm the data is in a good state, then save it to a CSV where it is ready to be used with Amazon Personalize."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"We'll open the data file and take a look at the first several rows."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"original_data = pd.read_csv(dataset_dir + '/movies.csv')\n",
"original_data.head(5)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"original_data.describe()"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"This does not really tell us much about the dataset, so we will explore a bit more for just raw info. We can see that genres are often grouped together, and that is fine for us as Personalize does support this structure."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"original_data.info()"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"From this, you can see that there are a total of (62,000+ for full 9742 for small) entries in the dataset, with 3 columns.\n",
"\n",
"This is a pretty minimal dataset of just the movieId, title and the list of genres that are applicable to each entry. However there is additional data available in the Movielens dataset. For instance the title includes the year of the movies release. Let's make that another column of metadata"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"original_data['year'] =original_data['title'].str.extract('.*\\((.*)\\).*',expand = False)\n",
"original_data.head(5)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"From an item metadata perspective, we only want to include information that is relevant to training a model and/or filtering resulte, so we will drop the title, retaining the genre information."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"itemmetadata_df = original_data.copy()\n",
"itemmetadata_df = itemmetadata_df[['movieId', 'genres', 'year']]\n",
"itemmetadata_df.head()"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"After manipulating the data, always confirm if the data format has changed."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"itemmetadata_df.dtypes"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Amazon Personalize has a default column for `ITEM_ID` that will map to our `movieId`, and now we can flesh out more information by specifying `GENRE` as well."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"itemmetadata_df.rename(columns = {'genres':'GENRE', 'movieId':'ITEM_ID', 'year':'YEAR'}, inplace = True) "
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"That's it! At this point the data is ready to go, and we just need to save it as a CSV file."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"itemmetadata_filename = \"item-meta.csv\"\n",
"itemmetadata_df.to_csv((data_dir+\"/\"+itemmetadata_filename), index=False, float_format='%.0f')"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Describe the Items dataset\n",
"\n",
"First, define a schema to tell Amazon Personalize what type of dataset you are uploading. There are several reserved and mandatory keywords required in the schema, based on the type of dataset. More detailed information can be found in the [documentation](https://docs.aws.amazon.com/personalize/latest/dg/how-it-works-dataset-schema.html).\n",
"\n",
"As with the interactions dataset, let's inspect the schema for item metadata data, which needs the `ITEM_ID` and `GENRE` fields. These must be defined in the same order in the schema as they appear in the dataset."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"describe_schema_response = personalize.describe_schema(\n",
" schemaArn=items_schema_arn\n",
")\n",
"\n",
"item_schema_arn = describe_schema_response['schema']['schemaArn']\n",
"print(json.dumps(describe_schema_response, indent=4, sort_keys=True, default=str))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Next let's inspect the items dataset itself."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"dataset_type = \"ITEMS\"\n",
"describe_dataset_response = personalize.describe_dataset(\n",
" datasetArn = items_dataset_arn,\n",
")\n",
"items_dataset_arn = describe_dataset_response['dataset']['datasetArn']\n",
"print(json.dumps(describe_dataset_response, indent=4, sort_keys=True, default=str))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Evaluating Solutions \n",
"\n",
"Multiple solutions have already been pre-created for you, specifically: \n",
"\n",
"1. User Personalization - what items are most relevant to a specific user.\n",
"1. Similar Items - given an item, what items are similar to it.\n",
"1. Personalized Ranking - given a user and a collection of items, in what order are they most releveant."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"In Amazon Personalize, a specific variation of an algorithm is called a recipe. Different recipes are suitable for different situations. A trained model is called a solution, and each solution can have many versions that relate to a given volume of data when the model was trained.\n",
"\n",
"To start, we will list all the recipes that are supported. This will allow you to select one and use that to build your model."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"personalize.list_recipes()"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"The output is just a JSON representation of all of the algorithms mentioned in the introduction.\n",
"\n",
"Next we will select specific recipes and build models with them.\n",
"\n",
"### User Personalization\n",
"The User-Personalization (aws-user-personalization) recipe is optimized for all USER_PERSONALIZATION recommendation scenarios. When recommending items, it uses automatic item exploration.\n",
"\n",
"With automatic exploration, Amazon Personalize automatically tests different item recommendations, learns from how users interact with these recommended items, and boosts recommendations for items that drive better engagement and conversion. This improves item discovery and engagement when you have a fast-changing catalog, or when new items, such as news articles or promotions, are more relevant to users when fresh.\n",
"\n",
"You can balance how much to explore (where items with less interactions data or relevance are recommended more frequently) against how much to exploit (where recommendations are based on what we know or relevance). Amazon Personalize automatically adjusts future recommendations based on implicit user feedback."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Describe the solution\n",
"\n",
"First you create a solution using the recipe. Our deployments are pre-trained so we will describe the solutions."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"user_personalization_describe_solution_response = personalize.describe_solution(\n",
" solutionArn = personalization_solution_arn\n",
")\n",
"\n",
"user_personalization_solution_arn = user_personalization_describe_solution_response['solution']['solutionArn']"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"print(json.dumps(user_personalization_describe_solution_response, indent=2, sort_keys=True, default=str))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Get the latest solution version\n",
"\n",
"Once you have a solution, you need to create a version in order to complete the model training. The training can take a while to complete, upwards of 25 minutes, and an average of 90 minutes for this recipe with our dataset. Normally, we would use a while loop to poll until the task is completed. However the task would block other cells from executing, and the goal here is to create many models and deploy them quickly. So we will set up the while loop for all of the solutions further down in the notebook. There, you will also find instructions for viewing the progress in the AWS console."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"userpersonalization_solution_version_arn = user_personalization_describe_solution_response['solution']['latestSolutionVersion']['solutionVersionArn']\n",
"print(json.dumps(user_personalization_describe_solution_response['solution']['latestSolutionVersion'], indent=2, default=str))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### SIMS\n",
"\n",
"SIMS is one of the oldest algorithms used within Amazon for recommendation systems. A core use case for it is when you have one item and you want to recommend items that have been interacted with in similar ways over your entire user base. This means the result is not personalized per user. Sometimes this leads to recommending mostly popular items, so there is a hyperparameter that can be tweaked which will reduce the popular items in your results. \n",
"\n",
"For our use case, using the Movielens data, let's assume we pick a particular movie. We can then use SIMS to recommend other movies based on the interaction behavior of the entire user base. The results are not personalized per user, but instead, differ depending on the movie we chose as our input."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Describe the solution\n",
"\n",
"As with User Personalization, start by describing the solution first. Although you provide the dataset ARN in this step, the model is not yet trained. See this as an identifier instead of a trained model."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"sims_describe_solution_response = personalize.describe_solution(\n",
" solutionArn = sims_solution_arn\n",
")\n",
"\n",
"sims_solution_arn = sims_describe_solution_response['solution']['solutionArn']\n",
"\n",
"print(json.dumps(sims_describe_solution_response, indent=2, default=str))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Describe the latest solution version\n",
"\n",
"Once you have a solution, you need to create a version in order to complete the model training. The training can take a while to complete, upwards of 25 minutes, and an average of 35 minutes for this recipe with our dataset. Normally, we would use a while loop to poll until the task is completed. However the task would block other cells from executing, and the goal here is to create many models and deploy them quickly. So we will set up the while loop for all of the solutions further down in the notebook. There, you will also find instructions for viewing the progress in the AWS console."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"sims_solution_version_arn = sims_describe_solution_response['solution']['latestSolutionVersion']['solutionVersionArn']\n",
"print(json.dumps(sims_describe_solution_response['solution']['latestSolutionVersion'], indent=2, default=str))\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Personalized Ranking\n",
"\n",
"Personalized Ranking is an interesting application of HRNN. Instead of just recommending what is most probable for the user in question, this algorithm takes in a user and a list of items as well. The items are then rendered back in the order of most probable relevance for the user. The use case here is for filtering on unique categories that you do not have item metadata to create a filter, or when you have a broad collection that you would like better ordered for a particular user.\n",
"\n",
"For our use case, using the MovieLens data, we could imagine that a VOD application may want to create a shelf of comic book movies, or movies by a specific director. We most likely have these lists based title metadata we have. We would use personalized ranking to re-order the list of movies for each user, based on their previous tagging history."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Describe the solution\n",
"\n",
"As with the previous solution, start by describing the solution first. Although you provide the dataset ARN in this step, the model is not yet trained. See this as an identifier instead of a trained model."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"rerank_describe_solution_response = personalize.describe_solution(\n",
" solutionArn = ranking_solution_arn\n",
")\n",
"\n",
"rerank_solution_arn = rerank_describe_solution_response['solution']['solutionArn']\n",
"\n",
"print(json.dumps(rerank_describe_solution_response, indent=2, default=str))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Describe the latest solution version\n",
"\n",
"Once you have a solution, you need to create a version in order to complete the model training. The training can take a while to complete, upwards of 25 minutes, and an average of 35 minutes for this recipe with our dataset. Normally, we would use a while loop to poll until the task is completed. However the task would block other cells from executing, and the goal here is to create many models and deploy them quickly. So we will set up the while loop for all of the solutions further down in the notebook. There, you will also find instructions for viewing the progress in the AWS console."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"\n",
"rerank_solution_version_arn = rerank_describe_solution_response['solution']['latestSolutionVersion']['solutionVersionArn']\n",
"print(json.dumps(rerank_describe_solution_response['solution']['latestSolutionVersion'], indent=2, default=str))\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Hyperparameter tuning\n",
"\n",
"Personalize offers the option of running hyperparameter tuning when creating a solution. Because of the additional computation required to perform hyperparameter tuning, this feature is turned off by default. Therefore, the solutions we created above, will simply use the default values of the hyperparameters for each recipe. For more information about hyperparameter tuning, see the [documentation](https://docs.aws.amazon.com/personalize/latest/dg/customizing-solution-config-hpo.html).\n",
"\n",
"If you have settled on the correct recipe to use, and are ready to run hyperparameter tuning, the following code shows how you would do so, using SIMS as an example.\n",
"\n",
"```python\n",
"sims_create_solution_response = personalize.create_solution(\n",
" name = \"personalize-poc-sims-hpo\",\n",
" datasetGroupArn = dataset_group_arn,\n",
" recipeArn = SIMS_recipe_arn,\n",
" performHPO=True\n",
")\n",
"\n",
"sims_solution_arn = sims_create_solution_response['solutionArn']\n",
"print(json.dumps(sims_create_solution_response, indent=2))\n",
"```\n",
"\n",
"If you already know the values you want to use for a specific hyperparameter, you can also set this value when you create the solution. The code below shows how you could set the value for the `popularity_discount_factor` for the SIMS recipe.\n",
"\n",
"```python\n",
"sims_create_solution_response = personalize.create_solution(\n",
" name = \"personalize-poc-sims-set-hp\",\n",
" datasetGroupArn = dataset_group_arn,\n",
" recipeArn = SIMS_recipe_arn,\n",
" solutionConfig = {\n",
" 'algorithmHyperParameters': {\n",
" 'popularity_discount_factor': '0.7'\n",
" }\n",
" }\n",
")\n",
"\n",
"sims_solution_arn = sims_create_solution_response['solutionArn']\n",
"print(json.dumps(sims_create_solution_response, indent=2))\n",
"```"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Evaluate solution versions \n",
"[Back to top](#top)\n",
"\n",
"It should 60-90 minutes to train all the solutions from this notebook. However, this has already completed for you. \n",
"\n",
"When the solution versions finish creating, the next step is to obtain the evaluation metrics. Personalize calculates these metrics based on a subset of the training data. The image below illustrates how Personalize splits the data. Given 10 users, with 10 interactions each (a circle represents an interaction), the interactions are ordered from oldest to newest based on the timestamp. Personalize uses all of the interaction data from 90% of the users (blue circles) to train the solution version, and the remaining 10% for evaluation. For each of the users in the remaining 10%, 90% of their interaction data (green circles) is used as input for the call to the trained model. The remaining 10% of their data (orange circle) is compared to the output produced by the model and used to calculate the evaluation metrics.\n",
"\n",
"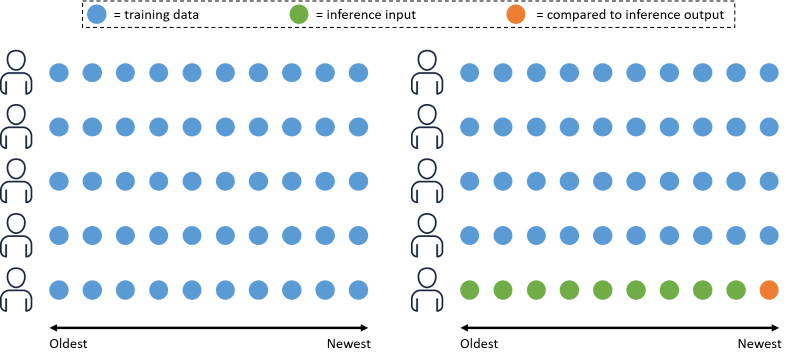\n",
"\n",
"We recommend reading [the documentation](https://docs.aws.amazon.com/personalize/latest/dg/working-with-training-metrics.html) to understand the metrics, but we have also copied parts of the documentation below for convenience.\n",
"\n",
"You need to understand the following terms regarding evaluation in Personalize:\n",
"\n",
"* *Relevant recommendation* refers to a recommendation that matches a value in the testing data for the particular user.\n",
"* *Rank* refers to the position of a recommended item in the list of recommendations. Position 1 (the top of the list) is presumed to be the most relevant to the user.\n",
"* *Query* refers to the internal equivalent of a GetRecommendations call.\n",
"\n",
"The metrics produced by Personalize are:\n",
"* **coverage**: The proportion of unique recommended items from all queries out of the total number of unique items in the training data (includes both the Items and Interactions datasets).\n",
"* **mean_reciprocal_rank_at_25**: The [mean of the reciprocal ranks](https://en.wikipedia.org/wiki/Mean_reciprocal_rank) of the first relevant recommendation out of the top 25 recommendations over all queries. This metric is appropriate if you're interested in the single highest ranked recommendation.\n",
"* **normalized_discounted_cumulative_gain_at_K**: Discounted gain assumes that recommendations lower on a list of recommendations are less relevant than higher recommendations. Therefore, each recommendation is discounted (given a lower weight) by a factor dependent on its position. To produce the [cumulative discounted gain](https://en.wikipedia.org/wiki/Discounted_cumulative_gain) (DCG) at K, each relevant discounted recommendation in the top K recommendations is summed together. The normalized discounted cumulative gain (NDCG) is the DCG divided by the ideal DCG such that NDCG is between 0 - 1. (The ideal DCG is where the top K recommendations are sorted by relevance.) Amazon Personalize uses a weighting factor of 1/log(1 + position), where the top of the list is position 1. This metric rewards relevant items that appear near the top of the list, because the top of a list usually draws more attention.\n",
"* **precision_at_K**: The number of relevant recommendations out of the top K recommendations divided by K. This metric rewards precise recommendation of the relevant items.\n",
"\n",
"Let's take a look at the evaluation metrics for each of the solutions produced in this notebook. *Please note, your results might differ from the results described in the text of this notebook, due to the quality of the Movielens dataset.* \n",
"\n",
"### User Personalization metrics\n",
"\n",
"First, retrieve the evaluation metrics for the User Personalization solution version."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"user_personalization_solution_metrics_response = personalize.get_solution_metrics(\n",
" solutionVersionArn = userpersonalization_solution_version_arn\n",
")\n",
"\n",
"print(json.dumps(user_personalization_solution_metrics_response, indent=2))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"The normalized discounted cumulative gain above tells us that at 5 items, we have less than a (38% for full 22% for small) chance in a recommendation being a part of a user's interaction history (in the hold out phase from training and validation). Around 13% of the recommended items are unique, and we have a precision of only (14% for full, 7.5% for small) in the top 5 recommended items. \n",
"\n",
"This is clearly not a great model, but keep in mind that we had to use rating data for our interactions because Movielens is an explicit dataset based on ratings. The Timestamps also were from the time that the movie was rated, not watched, so the order is not the same as the order a viewer would watch movies.\n",
"\n",
"### SIMS metrics\n",
"\n",
"Now, retrieve the evaluation metrics for the SIMS solution version."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"sims_solution_metrics_response = personalize.get_solution_metrics(\n",
" solutionVersionArn = sims_solution_version_arn\n",
")\n",
"\n",
"print(json.dumps(sims_solution_metrics_response, indent=2))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"In this example we are seeing a slightly elevated precision at 5 items, a little over (4.5% for full, 6.4% for small) this time. Effectively this is probably within the margin of error, but given that no effort was made to mask popularity, it may just be returning super popular results that a large volume of users have interacted with in some way. \n",
"\n",
"### Personalized ranking metrics\n",
"\n",
"Now, retrieve the evaluation metrics for the personalized ranking solution version."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"rerank_solution_metrics_response = personalize.get_solution_metrics(\n",
" solutionVersionArn = rerank_solution_version_arn\n",
")\n",
"\n",
"print(json.dumps(rerank_solution_metrics_response, indent=2))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Just a quick comment on this one, here we see again a precision of near (2.7% for full, 2.2% for small), as this is based on User Personalization, that is to be expected. However the sample items are not the same for validaiton, thus the low scoring.\n",
"\n",
"## Using evaluation metrics \n",
"[Back to top](#top)\n",
"\n",
"It is important to use evaluation metrics carefully. There are a number of factors to keep in mind.\n",
"\n",
"* If there is an existing recommendation system in place, this will have influenced the user's interaction history which you use to train your new solutions. This means the evaluation metrics are biased to favor the existing solution. If you work to push the evaluation metrics to match or exceed the existing solution, you may just be pushing the User Personalization to behave like the existing solution and might not end up with something better.\n",
"* The HRNN Coldstart recipe is difficult to evaluate using the metrics produced by Amazon Personalize. The aim of the recipe is to recommend items which are new to your business. Therefore, these items will not appear in the existing user transaction data which is used to compute the evaluation metrics. As a result, HRNN Coldstart will never appear to perform better than the other recipes, when compared on the evaluation metrics alone. Note: The User Personalization recipe also includes improved cold start functionality\n",
"\n",
"Keeping in mind these factors, the evaluation metrics produced by Personalize are generally useful for two cases:\n",
"1. Comparing the performance of solution versions trained on the same recipe, but with different values for the hyperparameters and features (impression data etc)\n",
"1. Comparing the performance of solution versions trained on different recipes (except HRNN Coldstart).\n",
"\n",
"Properly evaluating a recommendation system is always best done through A/B testing while measuring actual business outcomes. Since recommendations generated by a system usually influence the user behavior which it is based on, it is better to run small experiments and apply A/B testing for longer periods of time. Over time, the bias from the existing model will fade."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Describe campaigns \n",
"[Back to top](#top)\n",
"\n",
"A campaign is a hosted solution version; an endpoint which you can query for recommendations. Pricing is set by estimating throughput capacity (requests from users for personalization per second). When deploying a campaign, you set a minimum throughput per second (TPS) value. This service, like many within AWS, will automatically scale based on demand, but if latency is critical, you may want to provision ahead for larger demand. For this POC and demo, all minimum throughput thresholds are set to 1. For more information, see the [pricing page](https://aws.amazon.com/personalize/pricing/)."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### User Personalization\n",
"\n",
"Describe a campaign for your User Personalization solution version. It can take around 10 minutes to deploy a campaign, this is why this has been automated for you. Normally, we would use a while loop to poll until the task is completed. However the task would block other cells from executing, and the goal here is to create multiple campaigns. So we will set up the while loop for all of the campaigns further down in the notebook. There, you will also find instructions for viewing the progress in the AWS console."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"userpersonalization_describe_campaign_response = personalize.describe_campaign(\n",
" campaignArn = personalization_campaign_arn\n",
")\n",
"\n",
"userpersonalization_campaign_arn = userpersonalization_describe_campaign_response['campaign']['campaignArn']\n",
"print(json.dumps(userpersonalization_describe_campaign_response, indent=2, default=str))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### SIMS\n",
"\n",
"Describe a campaign for your SIMS solution version. It can take around 10 minutes to deploy a campaign. Normally, we would use a while loop to poll until the task is completed, this is why we automated this step. However the task would block other cells from executing, and the goal here is to create multiple campaigns. So we will set up the while loop for all of the campaigns further down in the notebook. There, you will also find instructions for viewing the progress in the AWS console."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"sims_describe_campaign_response = personalize.describe_campaign(\n",
" campaignArn = sims_campaign_arn\n",
")\n",
"\n",
"sims_campaign_arn = sims_describe_campaign_response['campaign']['campaignArn']\n",
"print(json.dumps(sims_describe_campaign_response, indent=2, default=str))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Personalized Ranking\n",
"\n",
"Describe a campaign for your personalized ranking solution version. It can take around 10 minutes to deploy a campaign, this is why we automated this step. Normally, we would use a while loop to poll until the task is completed. However the task would block other cells from executing, and the goal here is to create multiple campaigns. So we will set up the while loop for all of the campaigns further down in the notebook. There, you will also find instructions for viewing the progress in the AWS console."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"rerank_describe_campaign_response = personalize.describe_campaign(\n",
" campaignArn = ranking_campaign_arn\n",
")\n",
"\n",
"rerank_campaign_arn = rerank_describe_campaign_response['campaign']['campaignArn']\n",
"print(json.dumps(rerank_describe_campaign_response, indent=2, default=str))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Create Filters \n",
"[Back to top](#top)\n",
"\n",
"With active solution versions and campaigns, we can then create filters. Filters can be created for both Items and Events. A few common use cases for filters in Video On Demand are:\n",
"\n",
"Categorical filters based on Item Metadata - Often your item metadata will have information about thee title such as Genre, Keyword, Year, Decade etc. Filtering on these can provide recommendations within that data, such as action movies.\n",
"\n",
"Events - you may want to filter out certain events and provide results based on those events, such as moving a title from a \"suggestions to watch\" recommendation to a \"watch again\" recommendations.\n",
"\n",
"Lets look at the item metadata and user interactions, so we can get an idea what type of filters we can create."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Create a dataframe for the items by reading in the correct source CSV\n",
"items_df = pd.read_csv(data_dir + '/item-meta.csv', sep=',', index_col=0)\n",
"#interactions_df = pd.read_csv(data_dir + '/interactions.csv', sep=',', index_col=0)\n",
"\n",
"# Render some sample data\n",
"items_df.head(10)\n",
"#interactions_df.head(10)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Now what we want to do is determine the genres to filter on, for that we need a list of all genres. First we will get all the unique values of the column GENRE, then split strings on `|` if they exist, everyone will then get added to a long list which will be converted to a set for efficiency. That set will then be made into a list so that it can be iterated, and we can then use the create filter API."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"unique_genre_field_values = items_df['GENRE'].unique()\n",
"\n",
"genre_val_list = []\n",
"\n",
"def process_for_bar_char(val, val_list):\n",
" if '|' in val:\n",
" values = val.split('|')\n",
" for item in values:\n",
" val_list.append(item)\n",
" elif '(' in val:\n",
" pass\n",
" else:\n",
" val_list.append(val)\n",
" return val_list\n",
" \n",
"\n",
"for val in unique_genre_field_values:\n",
" genre_val_list = process_for_bar_char(val, genre_val_list)\n",
"\n",
"genres_to_filter = list(set(genre_val_list))"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"genres_to_filter"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"With this we now have all of the genres that exist in our dataset. A soft limit of Personalize at this time is 10 total filters, given we have a larger number of genres, we will select 7 at random to leave room for 2 interaction based filters later and an additional filter for year based recommendations"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"genres_to_filter = random.sample(genres_to_filter, 7)\n",
"genres_to_filter"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Now create a list for the metadata genre filters and then create the actual filters with the cells below. Note this will take a few minutes to complete."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Create a list for the filters:\n",
"meta_filter_arns = []"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Iterate through Genres\n",
"for genre in genres_to_filter:\n",
" # Start by creating a filter\n",
" try:\n",
" createfilter_response = personalize.create_filter(\n",
" name=genre,\n",
" datasetGroupArn=dataset_group_arn,\n",
" filterExpression='INCLUDE ItemID WHERE Items.GENRE IN (\"'+ genre +'\")'\n",
" )\n",
" # Add the ARN to the list\n",
" meta_filter_arns.append(createfilter_response['filterArn'])\n",
" print(\"Creating: \" + createfilter_response['filterArn'])\n",
" \n",
" # If this fails, wait a bit\n",
" except ClientError as error:\n",
" # Here we only care about raising if it isnt the throttling issue\n",
" if error.response['Error']['Code'] != 'LimitExceededException':\n",
" print(error)\n",
" else: \n",
" time.sleep(120)\n",
" createfilter_response = personalize.create_filter(\n",
" name=genre,\n",
" datasetGroupArn=dataset_group_arn,\n",
" filterExpression='INCLUDE ItemID WHERE Items.GENRE IN (\"'+ genre +'\")'\n",
" )\n",
" # Add the ARN to the list\n",
" meta_filter_arns.append(createfilter_response['filterArn'])\n",
" print(\"Creating: \" + createfilter_response['filterArn'])"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Lets also create 2 event filters for watched and unwatched content"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Create a dataframe for the interactions by reading in the correct source CSV\n",
"interactions_df = pd.read_csv(data_dir + '/interactions.csv', sep=',', index_col=0)\n",
"\n",
"# Render some sample data\n",
"interactions_df.head(10)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Lets also create 2 event filters for watched and unwatched content"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"createwatchedfilter_response = personalize.create_filter(name='watched',\n",
" datasetGroupArn=dataset_group_arn,\n",
" filterExpression='INCLUDE ItemID WHERE Interactions.event_type IN (\"watch\")'\n",
" )\n",
"\n",
"createunwatchedfilter_response = personalize.create_filter(name='unwatched',\n",
" datasetGroupArn=dataset_group_arn,\n",
" filterExpression='EXCLUDE ItemID WHERE Interactions.event_type IN (\"watch\")'\n",
" )\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Finally since we now have the year available in our item metadata, lets create a decade filter to recommend only moviees releaseed in a given decade, for this workshop we will choosee 1970s cinema. "
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"createdecadefilter_response = personalize.create_filter(name='1970s',\n",
" datasetGroupArn=dataset_group_arn,\n",
" filterExpression='INCLUDE ItemID WHERE Items.YEAR >= 1970 AND Items.YEAR < 1980'\n",
" )"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Before we are done we will want to add those filters to a list as well so they can be used later."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"interaction_filter_arns = [createwatchedfilter_response['filterArn'], createunwatchedfilter_response['filterArn']]"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"decade_filter_arns = [createdecadefilter_response['filterArn']]"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Wait for filters to become active\n",
"\n",
"Creating filters can take a couple minutes to complete. The following logic will wait until all filters have become active."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"%%time\n",
"\n",
"filter_arns = []\n",
"filter_arns += interaction_filter_arns\n",
"filter_arns += decade_filter_arns\n",
"filter_arns += meta_filter_arns\n",
"\n",
"max_time = time.time() + 60*60 # 1 hour\n",
"while time.time() < max_time:\n",
" for filter_arn in reversed(filter_arns):\n",
" response = personalize.describe_filter(\n",
" filterArn = filter_arn\n",
" )\n",
" status = response[\"filter\"][\"status\"]\n",
"\n",
" if status == \"ACTIVE\":\n",
" print(f'Filter {filter_arn} successfully created')\n",
" filter_arns.remove(filter_arn)\n",
" elif status == \"CREATE FAILED\":\n",
" print(f'Filter {filter_arn} failed')\n",
" if response['filter'].get('failureReason'):\n",
" print(' Reason: ' + response['filter']['failureReason'])\n",
" filter_arns.remove(filter_arn)\n",
"\n",
" if len(filter_arns) > 0:\n",
" print('At least one filter is still in progress')\n",
" time.sleep(15)\n",
" else:\n",
" print(\"All filters have completed\")\n",
" break"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Interact with campaigns \n",
"[Back to top](#top)\n",
"\n",
"Now that all campaigns are deployed and active, we can start to get recommendations via an API call. Each of the campaigns is based on a different recipe, which behave in slightly different ways because they serve different use cases. We will cover each campaign in a different order than used in previous notebooks, in order to deal with the possible complexities in ascending order (i.e. simplest first).\n",
"\n",
"First, let's create a supporting function to help make sense of the results returned by a Personalize campaign. Personalize returns only an `item_id`. This is great for keeping data compact, but it means you need to query a database or lookup table to get a human-readable result for the notebooks. We will create a helper function to return a human-readable result from the LastFM dataset.\n",
"\n",
"Start by loading in the dataset which we can use for our lookup table."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Create a dataframe for the items by reading in the correct source CSV\n",
"items_df = pd.read_csv(dataset_dir + '/movies.csv', sep=',', usecols=[0,1], encoding='latin-1', dtype={'movieId': \"object\", 'title': \"str\"},index_col=0)\n",
"\n",
"# Render some sample data\n",
"items_df.head(5)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"By defining the ID column as the index column it is trivial to return an artist by just querying the ID."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"movie_id_example = 589\n",
"title = items_df.loc[movie_id_example]['title']\n",
"print(title)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"That isn't terrible, but it would get messy to repeat this everywhere in our code, so the function below will clean that up."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"def get_movie_by_id(movie_id, movie_df=items_df):\n",
" \"\"\"\n",
" This takes in an artist_id from Personalize so it will be a string,\n",
" converts it to an int, and then does a lookup in a default or specified\n",
" dataframe.\n",
" \n",
" A really broad try/except clause was added in case anything goes wrong.\n",
" \n",
" Feel free to add more debugging or filtering here to improve results if\n",
" you hit an error.\n",
" \"\"\"\n",
" try:\n",
" return movie_df.loc[int(movie_id)]['title']\n",
" except:\n",
" return \"Error obtaining title\""
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Now let's test a few simple values to check our error catching."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# A known good id (The Princess Bride)\n",
"print(get_movie_by_id(movie_id=\"1197\"))\n",
"# A bad type of value\n",
"print(get_movie_by_id(movie_id=\"987.9393939\"))\n",
"# Really bad values\n",
"print(get_movie_by_id(movie_id=\"Steve\"))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Great! Now we have a way of rendering results. "
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### SIMS\n",
"\n",
"SIMS requires just an item as input, and it will return items which users interact with in similar ways to their interaction with the input item. In this particular case the item is a movie. "
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"The cells below will handle getting recommendations from SIMS and rendering the results. Let's see what the recommendations are for the first item we looked at earlier in this notebook (Terminator 2: Judgment Day)."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"get_recommendations_response = personalize_runtime.get_recommendations(\n",
" campaignArn = sims_campaign_arn,\n",
" itemId = str(589),\n",
")"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"item_list = get_recommendations_response['itemList']\n",
"for item in item_list:\n",
" print(get_movie_by_id(movie_id=item['itemId']))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Congrats, this is your first list of recommendations! This list is fine, but it would be better to see the recommendations for our sample collection of artists render in a nice dataframe. Again, let's create a helper function to achieve this."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Update DF rendering\n",
"pd.set_option('display.max_rows', 30)\n",
"\n",
"def get_new_recommendations_df(recommendations_df, movie_ID):\n",
" # Get the movie name\n",
" movie_name = get_movie_by_id(movie_ID)\n",
" # Get the recommendations\n",
" get_recommendations_response = personalize_runtime.get_recommendations(\n",
" campaignArn = sims_campaign_arn,\n",
" itemId = str(movie_ID),\n",
" )\n",
" # Build a new dataframe of recommendations\n",
" item_list = get_recommendations_response['itemList']\n",
" recommendation_list = []\n",
" for item in item_list:\n",
" movie = get_movie_by_id(item['itemId'])\n",
" recommendation_list.append(movie)\n",
" new_rec_DF = pd.DataFrame(recommendation_list, columns = [movie_name])\n",
" # Add this dataframe to the old one\n",
" recommendations_df = pd.concat([recommendations_df, new_rec_DF], axis=1)\n",
" return recommendations_df"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Now, let's test the helper function with several different movies. Let's sample some data from our dataset to test our SIMS campaign. Grab 5 random movies from our dataframe.\n",
"\n",
"Note: We are going to show similar titles, so you may want to re-run the sample until you recognize some of the movies listed"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"samples = items_df.sample(5)\n",
"samples"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"sims_recommendations_df = pd.DataFrame()\n",
"movies = samples.index.tolist()\n",
"\n",
"for movie in movies:\n",
" sims_recommendations_df = get_new_recommendations_df(sims_recommendations_df, movie)\n",
"\n",
"sims_recommendations_df"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"You may notice that a lot of the items look the same, hopefully not all of them do (this is more likely with a smaller # of interactions, which will be more common with the movielens small dataset). This shows that the evaluation metrics should not be the only thing you rely on when evaluating your solution version. So when this happens, what can you do to improve the results?\n",
"\n",
"This is a good time to think about the hyperparameters of the Personalize recipes. The SIMS recipe has a `popularity_discount_factor` hyperparameter (see [documentation](https://docs.aws.amazon.com/personalize/latest/dg/native-recipe-sims.html)). Leveraging this hyperparameter allows you to control the nuance you see in the results. This parameter and its behavior will be unique to every dataset you encounter, and depends on the goals of the business. You can iterate on the value of this hyperparameter until you are satisfied with the results, or you can start by leveraging Personalize's hyperparameter optimization (HPO) feature. For more information on hyperparameters and HPO tuning, see the [documentation](https://docs.aws.amazon.com/personalize/latest/dg/customizing-solution-config-hpo.html)."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### User Personalization\n",
"\n",
"HRNN is one of the more advanced algorithms provided by Amazon Personalize. It supports personalization of the items for a specific user based on their past behavior and can intake real time events in order to alter recommendations for a user without retraining. \n",
"\n",
"Since HRNN relies on having a sampling of users, let's load the data we need for that and select 3 random users. Since Movielens does not include user data, we will select 3 random numbers from the range of user id's in the dataset."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"if not USE_FULL_MOVIELENS:\n",
" users = random.sample(range(1, 600), 3)\n",
"else:\n",
" users = random.sample(range(1, 162000), 3)\n",
"users"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Now we render the recommendations for our 3 random users from above. After that, we will explore real-time interactions before moving on to Personalized Ranking.\n",
"\n",
"Again, we create a helper function to render the results in a nice dataframe.\n",
"\n",
"#### API call results"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Update DF rendering\n",
"pd.set_option('display.max_rows', 30)\n",
"\n",
"def get_new_recommendations_df_users(recommendations_df, user_id):\n",
" # Get the movie name\n",
" #movie_name = get_movie_by_id(artist_ID)\n",
" # Get the recommendations\n",
" get_recommendations_response = personalize_runtime.get_recommendations(\n",
" campaignArn = userpersonalization_campaign_arn,\n",
" userId = str(user_id),\n",
" )\n",
" # Build a new dataframe of recommendations\n",
" item_list = get_recommendations_response['itemList']\n",
" recommendation_list = []\n",
" for item in item_list:\n",
" movie = get_movie_by_id(item['itemId'])\n",
" recommendation_list.append(movie)\n",
" #print(recommendation_list)\n",
" new_rec_DF = pd.DataFrame(recommendation_list, columns = [user_id])\n",
" # Add this dataframe to the old one\n",
" recommendations_df = pd.concat([recommendations_df, new_rec_DF], axis=1)\n",
" return recommendations_df"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"recommendations_df_users = pd.DataFrame()\n",
"#users = users_df.sample(3).index.tolist()\n",
"\n",
"for user in users:\n",
" recommendations_df_users = get_new_recommendations_df_users(recommendations_df_users, user)\n",
"\n",
"recommendations_df_users"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Here we clearly see that the recommendations for each user are different. If you were to need a cache for these results, you could start by running the API calls through all your users and store the results, or you could use a batch export, which will be covered later in this notebook."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Now lets apply item filters to see recommendations for one of these users within a genre\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"def get_new_recommendations_df_by_filter(recommendations_df, user_id, filter_arn):\n",
" # Get the movie name\n",
" #movie_name = get_movie_by_id(artist_ID)\n",
" # Get the recommendations\n",
" get_recommendations_response = personalize_runtime.get_recommendations(\n",
" campaignArn = userpersonalization_campaign_arn,\n",
" userId = str(user_id),\n",
" filterArn = filter_arn\n",
" )\n",
" # Build a new dataframe of recommendations\n",
" item_list = get_recommendations_response['itemList']\n",
" recommendation_list = []\n",
" for item in item_list:\n",
" movie = get_movie_by_id(item['itemId'])\n",
" recommendation_list.append(movie)\n",
" #print(recommendation_list)\n",
" filter_name = filter_arn.split('/')[1]\n",
" new_rec_DF = pd.DataFrame(recommendation_list, columns = [filter_name])\n",
" # Add this dataframe to the old one\n",
" recommendations_df = pd.concat([recommendations_df, new_rec_DF], axis=1)\n",
" return recommendations_df"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"You can see the recommendations for movies within a given genre. Within a VOD application you could create Shelves (also known as rails or carosels) easily by using these filters. Depending on the information you have about your items, You could also filter on additional information such as keyword, year/decade etc."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"recommendations_df_shelves = pd.DataFrame()\n",
"for filter_arn in meta_filter_arns:\n",
" recommendations_df_shelves = get_new_recommendations_df_by_filter(recommendations_df_shelves, user, filter_arn)\n",
"for filter_arn in decade_filter_arns:\n",
" recommendations_df_shelves = get_new_recommendations_df_by_filter(recommendations_df_shelves, user, filter_arn)\n",
"\n",
"recommendations_df_shelves"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"The next topic is real-time events. Personalize has the ability to listen to events from your application in order to update the recommendations shown to the user. This is especially useful in media workloads, like video-on-demand, where a customer's intent may differ based on if they are watching with their children or on their own.\n",
"\n",
"Additionally the events that are recorded via this system are stored until a delete call from you is issued, and they are used as historical data alongside the other interaction data you provided when you train your next models.\n",
"\n",
"#### Real time events\n",
"\n",
"Start by describing the event tracker that is attached to the campaign. This step was also automated to save time"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"print(event_tracker_arn)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"response = personalize.describe_event_tracker(\n",
" eventTrackerArn = event_tracker_arn\n",
")\n",
"print(response['eventTracker']['eventTrackerArn'])\n",
"print(response['eventTracker']['trackingId'])\n",
"TRACKING_ID = response['eventTracker']['trackingId']\n",
"event_tracker_arn = response['eventTracker']['eventTrackerArn']"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"We will create some code that simulates a user interacting with a particular item. After running this code, you will get recommendations that differ from the results above.\n",
"\n",
"We start by creating some methods for the simulation of real time events."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"session_dict = {}\n",
"\n",
"def send_movie_click(USER_ID, ITEM_ID, EVENT_TYPE):\n",
" \"\"\"\n",
" Simulates a click as an envent\n",
" to send an event to Amazon Personalize's Event Tracker\n",
" \"\"\"\n",
" # Configure Session\n",
" try:\n",
" session_ID = session_dict[str(USER_ID)]\n",
" except:\n",
" session_dict[str(USER_ID)] = str(uuid.uuid1())\n",
" session_ID = session_dict[str(USER_ID)]\n",
" \n",
" # Configure Properties:\n",
" event = {\n",
" \"itemId\": str(ITEM_ID),\n",
" }\n",
" event_json = json.dumps(event)\n",
" \n",
" # Make Call\n",
" \n",
" personalize_events.put_events(\n",
" trackingId = TRACKING_ID,\n",
" userId= str(USER_ID),\n",
" sessionId = session_ID,\n",
" eventList = [{\n",
" 'sentAt': int(time.time()),\n",
" 'eventType': str(EVENT_TYPE),\n",
" 'properties': event_json\n",
" }]\n",
" )\n",
"\n",
"def get_new_recommendations_df_users_real_time(recommendations_df, user_id, item_id, event_type):\n",
" # Get the artist name (header of column)\n",
" movie_name = get_movie_by_id(item_id)\n",
" # Interact with different movies\n",
" print('sending event ' + event_type + ' for ' + get_movie_by_id(item_id))\n",
" send_movie_click(USER_ID=user_id, ITEM_ID=item_id, EVENT_TYPE=event_type)\n",
" # Get the recommendations (note you should have a base recommendation DF created before)\n",
" get_recommendations_response = personalize_runtime.get_recommendations(\n",
" campaignArn = userpersonalization_campaign_arn,\n",
" userId = str(user_id),\n",
" )\n",
" # Build a new dataframe of recommendations\n",
" item_list = get_recommendations_response['itemList']\n",
" recommendation_list = []\n",
" for item in item_list:\n",
" artist = get_movie_by_id(item['itemId'])\n",
" recommendation_list.append(artist)\n",
" new_rec_DF = pd.DataFrame(recommendation_list, columns = [movie_name])\n",
" # Add this dataframe to the old one\n",
" #recommendations_df = recommendations_df.join(new_rec_DF)\n",
" recommendations_df = pd.concat([recommendations_df, new_rec_DF], axis=1)\n",
" return recommendations_df"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"At this point, we haven't generated any real-time events yet; we have only set up the code. To compare the recommendations before and after the real-time events, let's pick one user and generate the original recommendations for them."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# First pick a user\n",
"user_id = user\n",
"\n",
"# Get recommendations for the user\n",
"get_recommendations_response = personalize_runtime.get_recommendations(\n",
" campaignArn = userpersonalization_campaign_arn,\n",
" userId = str(user_id),\n",
" )\n",
"\n",
"# Build a new dataframe for the recommendations\n",
"item_list = get_recommendations_response['itemList']\n",
"recommendation_list = []\n",
"for item in item_list:\n",
" artist = get_movie_by_id(item['itemId'])\n",
" recommendation_list.append(artist)\n",
"user_recommendations_df = pd.DataFrame(recommendation_list, columns = [user_id])\n",
"user_recommendations_df"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Ok, so now we have a list of recommendations for this user before we have applied any real-time events. Now let's pick 3 random artists which we will simulate our user interacting with, and then see how this changes the recommendations."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Next generate 3 random movies\n",
"movies = items_df.sample(3).index.tolist()"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"\n",
"# Note this will take about 15 seconds to complete due to the sleeps\n",
"for movie in movies:\n",
" user_recommendations_df = get_new_recommendations_df_users_real_time(user_recommendations_df, user_id, movie,'click')\n",
" time.sleep(5)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Now we can look at how the click events changed the recommendations."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"user_recommendations_df"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"In the cell above, the first column after the index is the user's default recommendations from User Personalization, and each column after that has a header of the artist that they interacted with via a real time event, and the recommendations after this event occurred. \n",
"\n",
"The behavior may not shift very much; this is due to the relatively limited nature of this dataset and effect of a few random clicks. If you wanted to better understand this, try simulating clicking more movies, and you should see a more pronounced impact."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Now lets look at the event filters, which allow you to filter items based on the interaction data. For this dataset, it could be click or watch based on the data we imported, but could be based on whatever interaction schema you design (click, rate, like, watch, purchase etc.) For VOD shelves you could move a title from \"Top picks for you\" to a \"Watch again\", the watch again recommendations will be based on the users current interactions, but only recommend titles that have already been watched.\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"recommendations_df_events = pd.DataFrame()\n",
"for filter_arn in interaction_filter_arns:\n",
" recommendations_df_events = get_new_recommendations_df_by_filter(recommendations_df_events, user, filter_arn)\n",
" \n",
"recommendations_df_events"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Now let's send a watch event in for 4 unwatched recommendations, which would simulate watching 4 movies. In a VOD application, you may choose to send in an event after they have watched a significant amount (over 75%) of a piece of content. Sending at 100% complete could miss people that stop short of the credits."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
" # Get the recommendations\n",
"top_unwatched_recommendations_response = personalize_runtime.get_recommendations(\n",
" campaignArn = userpersonalization_campaign_arn,\n",
" userId = str(user_id),\n",
" filterArn = filter_arn,\n",
" numResults=4)\n",
"item_list = top_unwatched_recommendations_response['itemList']\n",
"for item in item_list:\n",
" print('sending event watch for ' + get_movie_by_id(item['itemId']))\n",
" send_movie_click(USER_ID=user_id, ITEM_ID=item['itemId'], EVENT_TYPE='watch')\n",
" time.sleep(10)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Now we can look at the event filters to see the updated watched and unwatched recommendations "
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"recommendations_df_events = pd.DataFrame()\n",
"for filter_arn in interaction_filter_arns:\n",
" recommendations_df_events = get_new_recommendations_df_by_filter(recommendations_df_events, user, filter_arn)\n",
" \n",
"recommendations_df_events"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Personalized Ranking\n",
"\n",
"The core use case for personalized ranking is to take a collection of items and to render them in priority or probable order of interest for a user. For a VOD application you want dynamically render a personalized shelf/rail/carousel based on some information (director, location, superhero franchise, movie time period etc). This may not be information that you have in your metadata, so a item metadata filter will not work, howeverr you may have this information within you system to generate the item list. \n",
"\n",
"To demonstrate this, we will use the same user from before and a random collection of items."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"rerank_user = user\n",
"rerank_items = items_df.sample(25).index.tolist()"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Now build a nice dataframe that shows the input data."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"rerank_list = []\n",
"for item in rerank_items:\n",
" movie = get_movie_by_id(item)\n",
" rerank_list.append(movie)\n",
"rerank_df = pd.DataFrame(rerank_list, columns = ['Un-Ranked'])\n",
"rerank_df"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Then make the personalized ranking API call."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Convert user to string:\n",
"user_id = str(rerank_user)\n",
"rerank_item_list = []\n",
"for item in rerank_items:\n",
" rerank_item_list.append(str(item))\n",
" \n",
"# Get recommended reranking\n",
"get_recommendations_response_rerank = personalize_runtime.get_personalized_ranking(\n",
" campaignArn = rerank_campaign_arn,\n",
" userId = user_id,\n",
" inputList = rerank_item_list\n",
")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Now add the reranked items as a second column to the original dataframe, for a side-by-side comparison."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"ranked_list = []\n",
"item_list = get_recommendations_response_rerank['personalizedRanking']\n",
"for item in item_list:\n",
" movie = get_movie_by_id(item['itemId'])\n",
" ranked_list.append(movie)\n",
"ranked_df = pd.DataFrame(ranked_list, columns = ['Re-Ranked'])\n",
"rerank_df = pd.concat([rerank_df, ranked_df], axis=1)\n",
"rerank_df"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"You can see above how each entry was re-ordered based on the model's understanding of the user. This is a popular task when you have a collection of items to surface a user, a list of promotions for example."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Batch recommendations \n",
"[Back to top](#top)\n",
"\n",
"There are many cases where you may want to have a larger dataset of exported recommendations. Recently, Amazon Personalize launched batch recommendations as a way to export a collection of recommendations to S3. In this example, we will walk through how to do this for the HRNN solution. For more information about batch recommendations, please see the [documentation](https://docs.aws.amazon.com/personalize/latest/dg/getting-recommendations.html#recommendations-batch). This feature applies to all recipes, but the output format will vary.\n",
"\n",
"A simple implementation looks like this:\n",
"\n",
"```python\n",
"import boto3\n",
"\n",
"personalize_rec = boto3.client(service_name='personalize')\n",
"\n",
"personalize_rec.create_batch_inference_job (\n",
" solutionVersionArn = \"Solution version ARN\",\n",
" jobName = \"Batch job name\",\n",
" roleArn = \"IAM role ARN\",\n",
" jobInput = \n",
" {\"s3DataSource\": {\"path\": S3 input path}},\n",
" jobOutput = \n",
" {\"s3DataDestination\": {\"path\":S3 output path\"}}\n",
")\n",
"```\n",
"\n",
"The SDK import, the solution version arn, and role arns have all been determined. This just leaves an input, an output, and a job name to be defined.\n",
"\n",
"Starting with the input for HRNN, it looks like:\n",
"\n",
"\n",
"```JSON\n",
"{\"userId\": \"4638\"}\n",
"{\"userId\": \"663\"}\n",
"{\"userId\": \"3384\"}\n",
"```\n",
"\n",
"This should yield an output that looks like this:\n",
"\n",
"```JSON\n",
"{\"input\":{\"userId\":\"4638\"}, \"output\": {\"recommendedItems\": [\"296\", \"1\", \"260\", \"318\"]}}\n",
"{\"input\":{\"userId\":\"663\"}, \"output\": {\"recommendedItems\": [\"1393\", \"3793\", \"2701\", \"3826\"]}}\n",
"{\"input\":{\"userId\":\"3384\"}, \"output\": {\"recommendedItems\": [\"8368\", \"5989\", \"40815\", \"48780\"]}}\n",
"```\n",
"\n",
"The output is a JSON Lines file. It consists of individual JSON objects, one per line. So we will need to put in more work later to digest the results in this format."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Wrap up \n",
"[Back to top](#top)\n",
"\n",
"With that you now have a fully working collection of models to tackle various recommendation and personalization scenarios, as well as the skills to manipulate customer data to better integrate with the service, and a knowledge of how to do all this over APIs and by leveraging open source data science tools.\n",
"\n",
"Use these notebooks as a guide to getting started with your customers for POCs. As you find missing components, or discover new approaches, cut a pull request and provide any additional helpful components that may be missing from this collection.\n",
"\n",
"You'll want to make sure that you clean up all of the resources deployed during this POC, please run the script below"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Clean Up Resources\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"import sys\n",
"import getopt\n",
"import logging\n",
"import botocore\n",
"import boto3\n",
"import time\n",
"from packaging import version\n",
"from time import sleep\n",
"from botocore.exceptions import ClientError\n",
"\n",
"logger = logging.getLogger()\n",
"personalize = None\n",
"\n",
"def _get_dataset_group_arn(dataset_group_name):\n",
" dsg_arn = None\n",
"\n",
" paginator = personalize.get_paginator('list_dataset_groups')\n",
" for paginate_result in paginator.paginate():\n",
" for dataset_group in paginate_result[\"datasetGroups\"]:\n",
" if dataset_group['name'] == dataset_group_name:\n",
" dsg_arn = dataset_group['datasetGroupArn']\n",
" break\n",
"\n",
" if dsg_arn:\n",
" break\n",
"\n",
" if not dsg_arn:\n",
" raise NameError(f'Dataset Group \"{dataset_group_name}\" does not exist; verify region is correct')\n",
"\n",
" return dsg_arn\n",
"\n",
"def _get_solutions(dataset_group_arn):\n",
" solution_arns = []\n",
"\n",
" paginator = personalize.get_paginator('list_solutions')\n",
" for paginate_result in paginator.paginate(datasetGroupArn = dataset_group_arn):\n",
" for solution in paginate_result['solutions']:\n",
" solution_arns.append(solution['solutionArn'])\n",
"\n",
" return solution_arns\n",
"\n",
"def _delete_campaigns(solution_arns):\n",
" campaign_arns = []\n",
"\n",
" for solution_arn in solution_arns:\n",
" paginator = personalize.get_paginator('list_campaigns')\n",
" for paginate_result in paginator.paginate(solutionArn = solution_arn):\n",
" for campaign in paginate_result['campaigns']:\n",
" if campaign['status'] in ['ACTIVE', 'CREATE FAILED']:\n",
" logger.info('Deleting campaign: ' + campaign['campaignArn'])\n",
"\n",
" personalize.delete_campaign(campaignArn = campaign['campaignArn'])\n",
" elif campaign['status'].startswith('DELETE'):\n",
" logger.warning('Campaign {} is already being deleted so will wait for delete to complete'.format(campaign['campaignArn']))\n",
" else:\n",
" raise Exception('Campaign {} has a status of {} so cannot be deleted'.format(campaign['campaignArn'], campaign['status']))\n",
"\n",
" campaign_arns.append(campaign['campaignArn'])\n",
"\n",
" max_time = time.time() + 30*60 # 30 mins\n",
" while time.time() < max_time:\n",
" for campaign_arn in campaign_arns:\n",
" try:\n",
" describe_response = personalize.describe_campaign(campaignArn = campaign_arn)\n",
" logger.debug('Campaign {} status is {}'.format(campaign_arn, describe_response['campaign']['status']))\n",
" except ClientError as e:\n",
" error_code = e.response['Error']['Code']\n",
" if error_code == 'ResourceNotFoundException':\n",
" campaign_arns.remove(campaign_arn)\n",
"\n",
" if len(campaign_arns) == 0:\n",
" logger.info('All campaigns have been deleted or none exist for dataset group')\n",
" break\n",
" else:\n",
" logger.info('Waiting for {} campaign(s) to be deleted'.format(len(campaign_arns)))\n",
" time.sleep(20)\n",
"\n",
" if len(campaign_arns) > 0:\n",
" raise Exception('Timed out waiting for all campaigns to be deleted')\n",
"\n",
"def _delete_solutions(solution_arns):\n",
" for solution_arn in solution_arns:\n",
" try:\n",
" describe_response = personalize.describe_solution(solutionArn = solution_arn)\n",
" solution = describe_response['solution']\n",
" if solution['status'] in ['ACTIVE', 'CREATE FAILED']:\n",
" logger.info('Deleting solution: ' + solution_arn)\n",
"\n",
" personalize.delete_solution(solutionArn = solution_arn)\n",
" elif solution['status'].startswith('DELETE'):\n",
" logger.warning('Solution {} is already being deleted so will wait for delete to complete'.format(solution_arn))\n",
" else:\n",
" raise Exception('Solution {} has a status of {} so cannot be deleted'.format(solution_arn, solution['status']))\n",
" except ClientError as e:\n",
" error_code = e.response['Error']['Code']\n",
" if error_code != 'ResourceNotFoundException':\n",
" raise e\n",
"\n",
" max_time = time.time() + 30*60 # 30 mins\n",
" while time.time() < max_time:\n",
" for solution_arn in solution_arns:\n",
" try:\n",
" describe_response = personalize.describe_solution(solutionArn = solution_arn)\n",
" logger.debug('Solution {} status is {}'.format(solution_arn, describe_response['solution']['status']))\n",
" except ClientError as e:\n",
" error_code = e.response['Error']['Code']\n",
" if error_code == 'ResourceNotFoundException':\n",
" solution_arns.remove(solution_arn)\n",
"\n",
" if len(solution_arns) == 0:\n",
" logger.info('All solutions have been deleted or none exist for dataset group')\n",
" break\n",
" else:\n",
" logger.info('Waiting for {} solution(s) to be deleted'.format(len(solution_arns)))\n",
" time.sleep(20)\n",
"\n",
" if len(solution_arns) > 0:\n",
" raise Exception('Timed out waiting for all solutions to be deleted')\n",
"\n",
"def _delete_event_trackers(dataset_group_arn):\n",
" event_tracker_arns = []\n",
"\n",
" event_trackers_paginator = personalize.get_paginator('list_event_trackers')\n",
" for event_tracker_page in event_trackers_paginator.paginate(datasetGroupArn = dataset_group_arn):\n",
" for event_tracker in event_tracker_page['eventTrackers']:\n",
" if event_tracker['status'] in [ 'ACTIVE', 'CREATE FAILED' ]:\n",
" logger.info('Deleting event tracker {}'.format(event_tracker['eventTrackerArn']))\n",
" personalize.delete_event_tracker(eventTrackerArn = event_tracker['eventTrackerArn'])\n",
" elif event_tracker['status'].startswith('DELETE'):\n",
" logger.warning('Event tracker {} is already being deleted so will wait for delete to complete'.format(event_tracker['eventTrackerArn']))\n",
" else:\n",
" raise Exception('Solution {} has a status of {} so cannot be deleted'.format(event_tracker['eventTrackerArn'], event_tracker['status']))\n",
"\n",
" event_tracker_arns.append(event_tracker['eventTrackerArn'])\n",
"\n",
" max_time = time.time() + 30*60 # 30 mins\n",
" while time.time() < max_time:\n",
" for event_tracker_arn in event_tracker_arns:\n",
" try:\n",
" describe_response = personalize.describe_event_tracker(eventTrackerArn = event_tracker_arn)\n",
" logger.debug('Event tracker {} status is {}'.format(event_tracker_arn, describe_response['eventTracker']['status']))\n",
" except ClientError as e:\n",
" error_code = e.response['Error']['Code']\n",
" if error_code == 'ResourceNotFoundException':\n",
" event_tracker_arns.remove(event_tracker_arn)\n",
"\n",
" if len(event_tracker_arns) == 0:\n",
" logger.info('All event trackers have been deleted or none exist for dataset group')\n",
" break\n",
" else:\n",
" logger.info('Waiting for {} event tracker(s) to be deleted'.format(len(event_tracker_arns)))\n",
" time.sleep(20)\n",
"\n",
" if len(event_tracker_arns) > 0:\n",
" raise Exception('Timed out waiting for all event trackers to be deleted')\n",
"\n",
"def _delete_filters(dataset_group_arn):\n",
" filter_arns = []\n",
"\n",
" filters_response = personalize.list_filters(datasetGroupArn = dataset_group_arn, maxResults = 100)\n",
" for filter in filters_response['Filters']:\n",
" logger.info('Deleting filter ' + filter['filterArn'])\n",
" personalize.delete_filter(filterArn = filter['filterArn'])\n",
" filter_arns.append(filter['filterArn'])\n",
"\n",
" max_time = time.time() + 30*60 # 30 mins\n",
" while time.time() < max_time:\n",
" for filter_arn in filter_arns:\n",
" try:\n",
" describe_response = personalize.describe_filter(filterArn = filter_arn)\n",
" logger.debug('Filter {} status is {}'.format(filter_arn, describe_response['filter']['status']))\n",
" except ClientError as e:\n",
" error_code = e.response['Error']['Code']\n",
" if error_code == 'ResourceNotFoundException':\n",
" filter_arns.remove(filter_arn)\n",
"\n",
" if len(filter_arns) == 0:\n",
" logger.info('All filters have been deleted or none exist for dataset group')\n",
" break\n",
" else:\n",
" logger.info('Waiting for {} filter(s) to be deleted'.format(len(filter_arns)))\n",
" time.sleep(20)\n",
"\n",
" if len(filter_arns) > 0:\n",
" raise Exception('Timed out waiting for all filter to be deleted')\n",
"\n",
"def _delete_datasets_and_schemas(dataset_group_arn):\n",
" dataset_arns = []\n",
" schema_arns = []\n",
"\n",
" dataset_paginator = personalize.get_paginator('list_datasets')\n",
" for dataset_page in dataset_paginator.paginate(datasetGroupArn = dataset_group_arn):\n",
" for dataset in dataset_page['datasets']:\n",
" describe_response = personalize.describe_dataset(datasetArn = dataset['datasetArn'])\n",
" schema_arns.append(describe_response['dataset']['schemaArn'])\n",
"\n",
" if dataset['status'] in ['ACTIVE', 'CREATE FAILED']:\n",
" logger.info('Deleting dataset ' + dataset['datasetArn'])\n",
" personalize.delete_dataset(datasetArn = dataset['datasetArn'])\n",
" elif dataset['status'].startswith('DELETE'):\n",
" logger.warning('Dataset {} is already being deleted so will wait for delete to complete'.format(dataset['datasetArn']))\n",
" else:\n",
" raise Exception('Dataset {} has a status of {} so cannot be deleted'.format(dataset['datasetArn'], dataset['status']))\n",
"\n",
" dataset_arns.append(dataset['datasetArn'])\n",
"\n",
" max_time = time.time() + 30*60 # 30 mins\n",
" while time.time() < max_time:\n",
" for dataset_arn in dataset_arns:\n",
" try:\n",
" describe_response = personalize.describe_dataset(datasetArn = dataset_arn)\n",
" logger.debug('Dataset {} status is {}'.format(dataset_arn, describe_response['dataset']['status']))\n",
" except ClientError as e:\n",
" error_code = e.response['Error']['Code']\n",
" if error_code == 'ResourceNotFoundException':\n",
" dataset_arns.remove(dataset_arn)\n",
"\n",
" if len(dataset_arns) == 0:\n",
" logger.info('All datasets have been deleted or none exist for dataset group')\n",
" break\n",
" else:\n",
" logger.info('Waiting for {} dataset(s) to be deleted'.format(len(dataset_arns)))\n",
" time.sleep(20)\n",
"\n",
" if len(dataset_arns) > 0:\n",
" raise Exception('Timed out waiting for all datasets to be deleted')\n",
"\n",
" for schema_arn in schema_arns:\n",
" try:\n",
" logger.info('Deleting schema ' + schema_arn)\n",
" personalize.delete_schema(schemaArn = schema_arn)\n",
" except ClientError as e:\n",
" error_code = e.response['Error']['Code']\n",
" if error_code == 'ResourceInUseException':\n",
" logger.info('Schema {} is still in-use by another dataset (likely in another dataset group)'.format(schema_arn))\n",
" else:\n",
" raise e\n",
"\n",
" logger.info('All schemas used exclusively by datasets have been deleted or none exist for dataset group')\n",
"\n",
"def _delete_dataset_group(dataset_group_arn):\n",
" logger.info('Deleting dataset group ' + dataset_group_arn)\n",
" personalize.delete_dataset_group(datasetGroupArn = dataset_group_arn)\n",
"\n",
" max_time = time.time() + 30*60 # 30 mins\n",
" while time.time() < max_time:\n",
" try:\n",
" describe_response = personalize.describe_dataset_group(datasetGroupArn = dataset_group_arn)\n",
" logger.debug('Dataset group {} status is {}'.format(dataset_group_arn, describe_response['datasetGroup']['status']))\n",
" break\n",
" except ClientError as e:\n",
" error_code = e.response['Error']['Code']\n",
" if error_code == 'ResourceNotFoundException':\n",
" logger.info('Dataset group {} has been fully deleted'.format(dataset_group_arn))\n",
" else:\n",
" raise e\n",
"\n",
" logger.info('Waiting for dataset group to be deleted')\n",
" time.sleep(20)\n",
"\n",
"def delete_dataset_groups(dataset_group_names, region = None):\n",
" global personalize\n",
" personalize = boto3.client(service_name = 'personalize', region_name = region)\n",
"\n",
" for dataset_group_name in dataset_group_names:\n",
" dataset_group_arn = _get_dataset_group_arn(dataset_group_name)\n",
" logger.info('Dataset Group ARN: ' + dataset_group_arn)\n",
"\n",
" solution_arns = _get_solutions(dataset_group_arn)\n",
"\n",
" # 1. Delete campaigns\n",
" _delete_campaigns(solution_arns)\n",
"\n",
" # 2. Delete solutions\n",
" _delete_solutions(solution_arns)\n",
"\n",
" # 3. Delete event trackers\n",
" _delete_event_trackers(dataset_group_arn)\n",
"\n",
" # 4. Delete filters\n",
" _delete_filters(dataset_group_arn)\n",
"\n",
" # 5. Delete datasets and their schemas\n",
" _delete_datasets_and_schemas(dataset_group_arn)\n",
"\n",
" # 6. Delete dataset group\n",
" _delete_dataset_group(dataset_group_arn)\n",
"\n",
" logger.info(f'Dataset group {dataset_group_name} fully deleted')\n",
"\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"with open('/opt/ml/metadata/resource-metadata.json') as notebook_info:\n",
" data = json.load(notebook_info)\n",
" resource_arn = data['ResourceArn']\n",
" region = resource_arn.split(':')[3]\n",
"print(region)\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"delete_dataset_groups([dataset_group_arn], region)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Clean up the S3 bucket and IAM role\n",
"\n",
"Start by deleting the role, then empty the bucket, then delete the bucket."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"To delete an S3 bucket, it first needs to be empty. The easiest way to delete an S3 bucket, is just to navigate to S3 in the AWS console, delete the objects in the bucket, and then delete the S3 bucket itself.\n",
"\n",
"To clean up the IAM roles and this notebook please delete the Cloudformation template"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Deleting the Automation from the Initial CloudFormation deployment"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"stack_name = \"id-ml-ops\"\n",
"bucket= !aws cloudformation describe-stacks --stack-name $stack_name --query \"Stacks[0].Outputs[?OutputKey=='InputBucketName'].OutputValue\" --output text\n",
"bucket_name = bucket[0]\n",
"print(bucket_name)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"!aws s3 rb s3://$bucket_name --force"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"!aws cloudformation delete-stack --stack-name $stack_name\n",
"time.sleep(120)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"!aws cloudformation describe-stacks --stack-name $stack_name"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Deleting the bucket with the automation artifacts"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"stack_name = \"AmazonPersonalizeImmersionDay\"\n",
"bucket = !aws cloudformation describe-stack-resources --stack-name $stack_name --logical-resource-id SAMArtifactsBucket --query \"StackResources[0].PhysicalResourceId\" --output text\n",
"bucket_name = bucket[0]\n",
"print(bucket_name)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"!aws s3 rb s3://$bucket_name --force"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Now you can navigate to your [CloudFormation console](https://console.aws.amazon.com/cloudformation/) and delete the **AmazonPersonalizeImmersionDay** stack"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": []
}
],
"metadata": {
"kernelspec": {
"display_name": "conda_python3",
"language": "python",
"name": "conda_python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.6.13"
}
},
"nbformat": 4,
"nbformat_minor": 4
}