{
"cells": [
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Validating and Importing User-Item-Interaction Data \n",
"\n",
"In this notebook, you will choose a dataset and prepare it for use with Amazon Personalize.\n",
"\n",
"1. [How to Use the Notebook](#usenotebook)\n",
"1. [Introduction](#intro)\n",
"1. [Define your Use Case](#usecase)\n",
"1. [Choose a Dataset or Data Source](#source)\n",
"1. [Prepare the Interactions Data](#prepare_interactions)\n",
"1. [Prepare the Item Metadata](#prepare_items)\n",
"1. [Prepare the User Metadata](#prepare_users)\n",
"1. [Configure an S3 bucket and an IAM role](#bucket_role)\n",
"1. [Create Dataset Group](#group_dataset)\n",
"1. [Create the Interactions Schema](#interact_schema)\n",
"1. [Create the Items (Movies) Schema](#items_schema)\n",
"1. [Create the Users Schema](#users_schema)\n",
"1. [Import the Interactions Data](#import_interactions)\n",
"1. [Import the Item Metadata](#import_items)\n",
"1. [Import the User Metadata](#import_users)\n",
"\n",
"## How to Use the Notebook \n",
"\n",
"The code is broken up into cells like the one below. There's a triangular Run button at the top of this page that you can click to execute each cell and move onto the next, or you can press `Shift` + `Enter` while in the cell to execute it and move onto the next one.\n",
"\n",
"As a cell is executing you'll notice a line to the side showcase an `*` while the cell is running or it will update to a number to indicate the last cell that completed executing after it has finished exectuting all the code within a cell.\n",
"\n",
"Simply follow the instructions below and execute the cells to get started with Amazon Personalize using case optimized recommenders.\n",
"\n",
"\n",
"## Introduction \n",
"[Back to top](#top)\n",
"\n",
"In Amazon Personalize, you start by creating a dataset group, which is a container for Amazon Personalize components. Your dataset group can be one of the following:\n",
"\n",
"A Domain dataset group, where you create preconfigured resources for different business domains and use cases, such as getting recommendations for similar videos (VIDEO_ON_DEMAND domain) or best selling items (ECOMMERCE domain). You choose your business domain, import your data, and create recommenders. You use recommenders in your application to get recommendations.\n",
"\n",
"Use a [Domain dataset group](https://docs.aws.amazon.com/personalize/latest/dg/domain-dataset-groups.html) if you have a video on demand or e-commerce application and want Amazon Personalize to find the best configurations for your use cases. If you start with a Domain dataset group, you can also add custom resources such as solutions with solution versions trained with recipes for custom use cases.\n",
"\n",
"A [Custom dataset group](https://docs.aws.amazon.com/personalize/latest/dg/custom-dataset-groups.html), where you create configurable resources for custom use cases and batch recommendation workflows. You choose a recipe, train a solution version (model), and deploy the solution version with a campaign. You use a campaign in your application to get recommendations.\n",
"\n",
"Use a Custom dataset group if you don't have a video on demand or e-commerce application or want to configure and manage only custom resources, or want to get recommendations in a batch workflow. If you start with a Custom dataset group, you can't associate it with a domain later. Instead, create a new Domain dataset group.\n",
"\n",
"You can create and manage Domain dataset groups and Custom dataset groups with the AWS console, the AWS Command Line Interface (AWS CLI), or programmatically with the AWS SDKs.\n",
"\n",
"\n",
"## Define your Use Case \n",
"[Back to top](#top)\n",
"\n",
"There are a few guidelines for scoping a problem suitable for Personalize. We recommend the values below as a starting point, although the [official limits](https://docs.aws.amazon.com/personalize/latest/dg/limits.html) lie a little lower.\n",
"\n",
"* Authenticated users\n",
"* At least 50 unique users\n",
"* At least 100 unique items\n",
"* At least 2 dozen interactions for each user \n",
"\n",
"Most of the time this is easily attainable, and if you are low in one category, you can often make up for it by having a larger number in another category.\n",
"\n",
"The user-item-iteraction data is key for getting started with the service. This means we need to look for use cases that generate that kind of data, a few common examples are:\n",
"\n",
"1. Video-on-demand applications\n",
"1. E-commerce platforms\n",
"\n",
"Defining your use-case will inform what data and what type of data you need.\n",
"\n",
"In this example we are going to be creating:\n",
"\n",
"1. Amazon Personalize VIDEO_ON_DEMAND Domain recommender for the [\"More Like X\"](https://docs.aws.amazon.com/personalize/latest/dg/VIDEO_ON_DEMAND-use-cases.html#more-like-y-use-case) use case.\n",
"1. Amazon Personalize VIDEO_ON_DEMAND Domain recommender for the [\"Top pics for you\"](https://docs.aws.amazon.com/personalize/latest/dg/VIDEO_ON_DEMAND-use-cases.html#top-picks-use-case) use case.\n",
"1. Amazon Personalize Custom Campaign for a personalized ranked list of movies, for instance shelf/rail/carousel based on some information (director, location, superhero franchise, etc...) \n",
"\n",
"All of these will be created within the same dataset group and with the same input data.\n",
"\n",
"The diagram bellow shows an overview of what we will be building in this wokshop.\n",
"\n",
"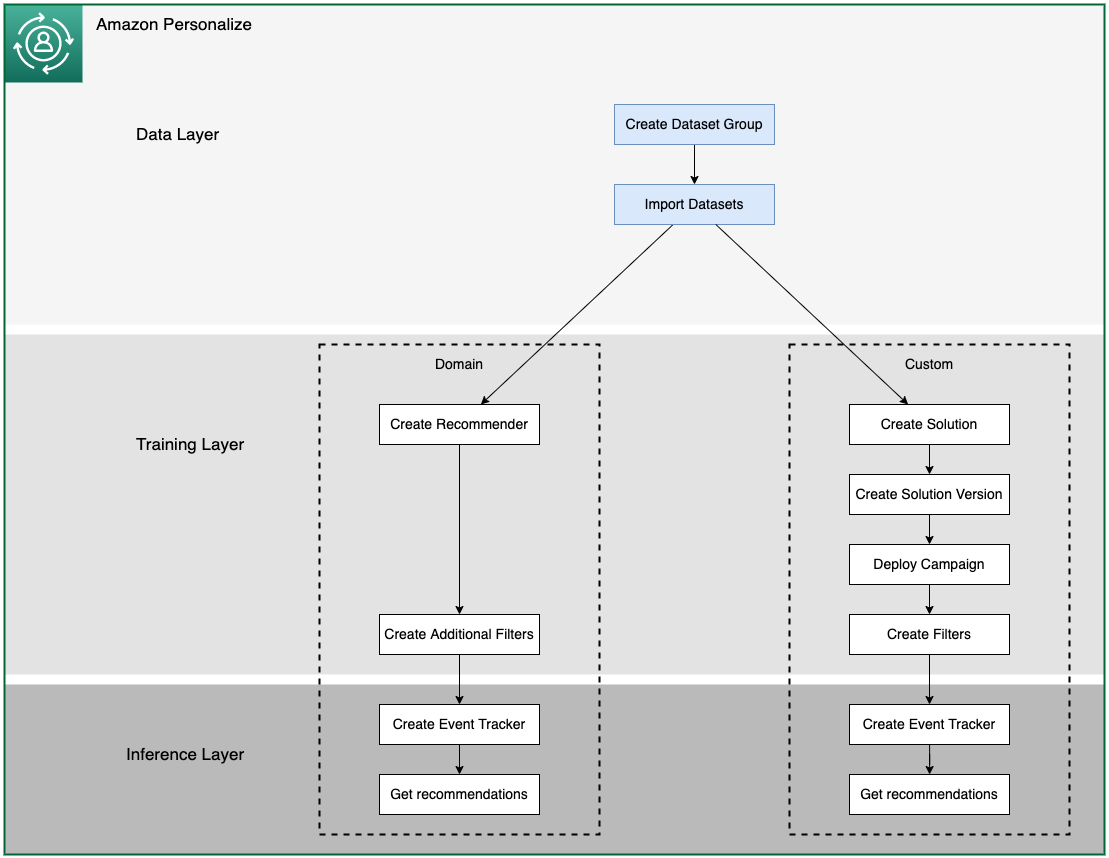\n",
"\n",
"In this notebook we will be working on the Data Layer, Creatig a Dataset Group and importing the Datasets. \n",
"\n",
"\n",
"## Choose a Dataset or Data Source \n",
"[Back to top](#top)\n",
"\n",
"Regardless of the use case, the algorithms all share a base of learning on user-item-interaction data which is defined by 3 core attributes:\n",
"\n",
"1. **UserID** - The user who interacted\n",
"1. **ItemID** - The item the user interacted with\n",
"1. **Timestamp** - The time at which the interaction occurred\n",
"\n",
"To begin, we are going to use the latest MovieLens dataset, this dataset has over 25 million interactions and a rich collection of metadata for items. There is also a smaller version of this dataset, which can be used to shorten training times, while still incorporating the same capabilities as the full dataset.\n",
"\n",
"Generally speaking your data will not arrive in a perfect form for Personalize, and will take some modification to be structured correctly. This notebook guides you through all of that. \n",
"\n",
"Set USE_FULL_MOVIELENS to True to use the full dataset."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"USE_FULL_MOVIELENS = False"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"First, you will download the dataset from the Movielens website and unzip it in a new folder using the code below."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"data_dir = \"poc_data\"\n",
"!mkdir $data_dir\n",
"\n",
"if not USE_FULL_MOVIELENS:\n",
" !cd $data_dir && wget http://files.grouplens.org/datasets/movielens/ml-latest-small.zip\n",
" !cd $data_dir && unzip ml-latest-small.zip\n",
" dataset_dir = data_dir + \"/ml-latest-small/\"\n",
"else:\n",
" !cd $data_dir && wget http://files.grouplens.org/datasets/movielens/ml-25m.zip\n",
" !cd $data_dir && unzip ml-25m.zip\n",
" dataset_dir = data_dir + \"/ml-25m/\""
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Take a look at the data files you have downloaded."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"!ls $dataset_dir"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"At present not much is known except that we have a few CSVs and a readme. Next we will output the readme to learn more!"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"!pygmentize $dataset_dir/README.txt"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"From the README, we see there is a file `ratings.csv` that should work as a proxy for our interactions data, after all rating a film definitely is a form of interacting with it. The dataset also has some genre information as some movie genome data. In this POC we will focus on the interactions and the genre data.\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Prepare the Interactions data \n",
"[Back to top](#top)\n",
"\n",
"The next thing to be done is to load the data and confirm the data is in a good state.\n",
"\n",
"Python ships with a broad collection of libraries and we need to import those as well as the ones installed to help us like [boto3](https://aws.amazon.com/sdk-for-python/) (AWS SDK for python) and [Pandas](https://pandas.pydata.org/)/[Numpy](https://numpy.org/) which are core data science tools."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"import time\n",
"from time import sleep\n",
"import json\n",
"from datetime import datetime\n",
"import boto3\n",
"import pandas as pd\n",
"import numpy as np"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Next, open the `ratings.csv` file and take a look at the first rows."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"original_data = pd.read_csv(dataset_dir + '/ratings.csv')\n",
"original_data.head(5)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"original_data.shape"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"original_data.describe()"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"This shows that we have a good range of values for `userId` and `movieId`. Next, it is always a good idea to confirm the data format."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"original_data.info()"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"original_data.isnull().any()"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"arb_time_stamp = original_data.iloc[50]['timestamp']\n",
"print(arb_time_stamp)\n",
"print(datetime.utcfromtimestamp(arb_time_stamp).strftime('%Y-%m-%d %H:%M:%S'))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"From this, you can see that there are a total of (25,000,095 for full 100836 for small) entries in the dataset, with 4 columns, and each cell stored as int64 format, with the exception of the rating whihch is a float64.\n",
"\n",
"The int64 format is clearly suitable for `userId` and `movieId`. However, we need to dive deeper to understand the timestamps in the data. To use Amazon Personalize, you need to save timestamps in [Unix Epoch](https://en.wikipedia.org/wiki/Unix_time) format.\n",
"\n",
"Currently, the timestamp values are not human-readable. So let's grab an arbitrary timestamp value and figure out how to interpret it."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Do a quick sanity check on the transformed dataset by picking an arbitrary timestamp and transforming it to a human-readable format."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"This date makes sense as a timestamp, so we can continue formatting the rest of the data. Remember, the data we need is user-item-interaction data, which is `userId`, `movieId`, and `timestamp` in this case. Our dataset has an additional column, `rating`, which can be dropped from the dataset after we have leveraged it to focus on positive interactions."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Convert the Interactions Data\n",
"\n",
"Since this is a dataset of an explicit feedback movie ratings, it includes movies rated from 1 to 5. We want to include only moves that were \"liked\" by the users, and simulate a dataset of data that would be gathered by a VOD platform. In order to do that, we will filter out all interactions under 2 out of 5, and create two event types: \"Click\" and and \"Watch\". We will then assign all movies rated 2 and above as \"Click\" and movies rated 4 and above as both \"Click\" and \"Watch\". \n",
"\n",
"Note that for a real data set you would actually model based on implicit feedback such as clicks, watches and/or explicit feedback such as ratings, likes etc."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"watched_df = original_data.copy()\n",
"watched_df = watched_df[watched_df['rating'] > 3]\n",
"watched_df = watched_df[['userId', 'movieId', 'timestamp']]\n",
"watched_df['EVENT_TYPE']='Watch'\n",
"watched_df.head()"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"clicked_df = original_data.copy()\n",
"clicked_df = clicked_df[clicked_df['rating'] > 1]\n",
"clicked_df = clicked_df[['userId', 'movieId', 'timestamp']]\n",
"clicked_df['EVENT_TYPE']='Click'\n",
"clicked_df.head()"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"interactions_df = clicked_df.copy()\n",
"interactions_df = interactions_df.append(watched_df)\n",
"interactions_df.sort_values(\"timestamp\", axis = 0, ascending = True, \n",
" inplace = True, na_position ='last') "
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"interactions_df.info()"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Lets look at what the new dataset looks like."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"interactions_df.describe()"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"After manipulating the data, always confirm the data format has not changed."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"interactions_df.dtypes"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
" Amazon Personalize has default column names for users, items, and timestamp. These default column names are `USER_ID`, `ITEM_ID`, `TIMESTAMP` and `EVENT_VALUE` for the [VIDEO_ON_DEMAND domain dataset](https://docs.aws.amazon.com/personalize/latest/dg/VIDEO-ON-DEMAND-datasets-and-schemas.html). The final modification to the dataset is to replace the existing column headers with the default headers."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"interactions_df.rename(columns = {'userId':'USER_ID', 'movieId':'ITEM_ID', \n",
" 'timestamp':'TIMESTAMP'}, inplace = True) "
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"That's it! At this point the data is ready to go, and we just need to save it as a CSV file."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"interactions_filename = \"interactions.csv\"\n",
"interactions_df.to_csv((data_dir+\"/\"+interactions_filename), index=False, float_format='%.0f')"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Prepare the Item Metadata \n",
"[Back to top](#top)\n",
"\n",
"This will allow you to work with filters as well as supporting the [Top Pics for you Domain Recommender](https://docs.aws.amazon.com/personalize/latest/dg/VIDEO_ON_DEMAND-use-cases.html#top-picks-use-case), and complying with the [VIDEO_ON_DEMAND domain dataset and schema requirements](https://docs.aws.amazon.com/personalize/latest/dg/VIDEO-ON-DEMAND-datasets-and-schemas.html#VIDEO-ON-DEMAND-dataset-requirements)..\n",
"\n",
"Next we load the data and confirm the data is in a good state.\n",
"\n",
"Next, open the `movies.csv` file and take a look at the first rows. This file has information about the movie."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"original_data = pd.read_csv(dataset_dir + '/movies.csv')\n",
"original_data.head(5)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"original_data.describe()"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"This does not really tell us much about the dataset, so we will explore a bit more and look at the raw information. We can see that genres often appear in groups. That is fine for us as Personalize supports this structure."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"original_data.info()"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"From this, you can see that there are a total of (62,000+ for full 9742 for small) entries in the dataset, with 3 columns.\n",
"\n",
"Lets look for potential data issues. First we will check for null values."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"original_data.isnull().sum()"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Looks good, we currently have no null values."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"This is a pretty small dataset of just the movieId, title and the list of genres that are applicable to each entry. However there is additional data available in the Movielens dataset. For instance the title includes the year of the movies release. Let's make that another column of metadata."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"original_data['year'] = original_data['title'].str.extract('.*\\((.*)\\).*',expand = False)\n",
"original_data.head(5)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Lets check again for null values, now that we have added a new field."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"original_data.isnull().sum()"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"It looks like we have introduced some null values, this is likely due to something in the orginal data. If we had time, we could investigate the titles that resulted in the null values. However, for this workshop we will drop the null value titles."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"original_data = original_data.dropna(axis=0)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Lets validate that we resololved the data issue"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"original_data.isnull().sum()"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"From an item metadata perspective, we only want to include information that is relevant to training a model and/or filtering results, so we will drop the title column, and keep the genre information."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"itemmetadata_df = original_data.copy()\n",
"itemmetadata_df = itemmetadata_df[['movieId', 'genres', 'year']]\n",
"itemmetadata_df.head()"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"We will add a new dataframe to help us generate a creation timestamp. If you don’t provide the CREATION_TIMESTAMP for an item, the model infers this information from the interaction dataset and uses the timestamp of the item’s earliest interaction as its corresponding release date. If an item doesn’t have an interaction, its release date is set as the timestamp of the latest interaction in the training set and it is considered a new item. \n",
"\n",
"For the current example we are selecting a today's date as the creation timestamp because the actual creation timestamp is unknown. In your use-case, please provide the appropriate creation timestamp for the item. This can be when the item was added to your platform."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"ts = datetime(2022, 1, 1, 0, 0).strftime('%s')\n",
"print(ts)\n",
"\n",
"itemmetadata_df['CREATION_TIMESTAMP'] = ts"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"After manipulating the data, always confirm that the data format has not changed."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"itemmetadata_df.dtypes"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Amazon Personalize has a default column for `ITEM_ID` that will map to our `movieId`. We will flesh out more information by specifying `GENRE` as well."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"itemmetadata_df.rename(columns = {'genres':'GENRES', 'movieId':'ITEM_ID', 'year':'YEAR'}, inplace = True) "
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"itemmetadata_df"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"That's it! At this point the item data is ready to go, and we just need to save it as a CSV file."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"items_filename = \"item-meta.csv\"\n",
"itemmetadata_df.to_csv((data_dir+\"/\"+items_filename), index=False, float_format='%.0f')"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Prepare the User Metadata \n",
"[Back to top](#top)\n",
"\n",
"This will supporting the [Top Pics for you Domain Recommender](https://docs.aws.amazon.com/personalize/latest/dg/VIDEO_ON_DEMAND-use-cases.html#top-picks-use-case), and complying with the [VIDEO_ON_DEMAND domain dataset and schema requirements](https://docs.aws.amazon.com/personalize/latest/dg/VIDEO-ON-DEMAND-datasets-and-schemas.html#VIDEO-ON-DEMAND-dataset-requirements).\n",
"\n",
"The dataset does not have any user metadata so we will create a fake metadata field."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# get all unique user ids from the interaction dataset\n",
"\n",
"user_ids = interactions_df['USER_ID'].unique()\n",
"user_data = pd.DataFrame()\n",
"user_data[\"USER_ID\"]= user_ids\n",
"user_data"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Adding Metadata\n",
"The current dataset does not contain additiona user information. For this example, we'll randomly assign a gender to the users with equal probablity of male and female."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"possible_genders = ['female', 'male']\n",
"random = np.random.choice(possible_genders, len(user_data.index), p=[0.5, 0.5])\n",
"user_data[\"GENDER\"] = random\n",
"user_data"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Saving the data as a CSV file\n",
"users_filename = \"users.csv\"\n",
"user_data.to_csv((data_dir+\"/\"+users_filename), index=False, float_format='%.0f')\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Configure an S3 bucket and an IAM role \n",
"[Back to top](#top)\n",
"\n",
"So far, we have downloaded, manipulated, and saved the data onto the Amazon EBS instance attached to instance running this Jupyter notebook. \n",
"\n",
"By default, the Personalize service does not have permission to acccess the data we uploaded into the S3 bucket in our account. In order to grant access to the Personalize service to read our CSVs, we need to set a Bucket Policy and create an IAM role that the Amazon Personalize service will assume. Let's set all of that up.\n",
"\n",
"Use the metadata stored on the instance underlying this Amazon SageMaker notebook, to determine the region it is operating in. If you are using a Jupyter notebook outside of Amazon SageMaker, simply define the region as a string below. The Amazon S3 bucket needs to be in the same region as the Amazon Personalize resources we have been creating so far."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"with open('/opt/ml/metadata/resource-metadata.json') as notebook_info:\n",
" data = json.load(notebook_info)\n",
" resource_arn = data['ResourceArn']\n",
" region = resource_arn.split(':')[3]\n",
"print('region:', region)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Amazon S3 bucket names are globally unique. To create a unique bucket name, the code below will append the string `personalizepocvod` to your AWS account number. Then it creates a bucket with this name in the region discovered in the previous cell."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"s3 = boto3.client('s3')\n",
"account_id = boto3.client('sts').get_caller_identity().get('Account')\n",
"bucket_name = account_id + \"-\" + region + \"-\" + \"personalizepocvod\"\n",
"print('bucket_name:', bucket_name)\n",
"try: \n",
" if region == \"us-east-1\":\n",
" s3.create_bucket(Bucket=bucket_name)\n",
" else:\n",
" s3.create_bucket(\n",
" Bucket=bucket_name,\n",
" CreateBucketConfiguration={'LocationConstraint': region}\n",
" )\n",
"except s3.exceptions.BucketAlreadyOwnedByYou:\n",
" print(\"Bucket already exists. Using bucket\", bucket_name)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Set the S3 bucket policy\n",
"Amazon Personalize needs to be able to read the contents of your S3 bucket. So add a bucket policy which allows that."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"policy = {\n",
" \"Version\": \"2012-10-17\",\n",
" \"Id\": \"PersonalizeS3BucketAccessPolicy\",\n",
" \"Statement\": [\n",
" {\n",
" \"Sid\": \"PersonalizeS3BucketAccessPolicy\",\n",
" \"Effect\": \"Allow\",\n",
" \"Principal\": {\n",
" \"Service\": \"personalize.amazonaws.com\"\n",
" },\n",
" \"Action\": [\n",
" \"s3:*Object\",\n",
" \"s3:ListBucket\"\n",
" ],\n",
" \"Resource\": [\n",
" \"arn:aws:s3:::{}\".format(bucket_name),\n",
" \"arn:aws:s3:::{}/*\".format(bucket_name)\n",
" ]\n",
" }\n",
" ]\n",
"}\n",
"\n",
"s3.put_bucket_policy(Bucket=bucket_name, Policy=json.dumps(policy))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Create an IAM role\n",
"\n",
"Amazon Personalize needs the ability to assume roles in AWS in order to have the permissions to execute certain tasks. Let's create an IAM role and attach the required policies to it. The code below attaches very permissive policies; please use more restrictive policies for any production application."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"iam = boto3.client(\"iam\")\n",
"\n",
"role_name = account_id+\"-PersonalizeS3-Immersion-Day\"\n",
"assume_role_policy_document = {\n",
" \"Version\": \"2012-10-17\",\n",
" \"Statement\": [\n",
" {\n",
" \"Effect\": \"Allow\",\n",
" \"Principal\": {\n",
" \"Service\": \"personalize.amazonaws.com\"\n",
" },\n",
" \"Action\": \"sts:AssumeRole\"\n",
" }\n",
" ]\n",
"}\n",
"\n",
"try:\n",
" create_role_response = iam.create_role(\n",
" RoleName = role_name,\n",
" AssumeRolePolicyDocument = json.dumps(assume_role_policy_document)\n",
" );\n",
" \n",
"except iam.exceptions.EntityAlreadyExistsException as e:\n",
" print('Warning: role already exists:', e)\n",
" create_role_response = iam.get_role(\n",
" RoleName = role_name\n",
" );\n",
"\n",
"role_arn = create_role_response[\"Role\"][\"Arn\"]\n",
" \n",
"print('IAM Role: {}'.format(role_arn))\n",
" \n",
"attach_response = iam.attach_role_policy(\n",
" RoleName = role_name,\n",
" PolicyArn = \"arn:aws:iam::aws:policy/AmazonS3FullAccess\"\n",
");\n",
"\n",
"role_arn = create_role_response[\"Role\"][\"Arn\"]\n",
"\n",
"# Pause to allow role to be fully consistent\n",
"time.sleep(30)\n",
"print('Done.')"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Upload data to S3\n",
"\n",
"Now that your Amazon S3 bucket has been created, upload the CSV file of our user-item-interaction data. "
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"interactions_file_path = data_dir + \"/\" + interactions_filename\n",
"boto3.Session().resource('s3').Bucket(bucket_name).Object(interactions_filename).upload_file(interactions_file_path)\n",
"\n",
"items_file_path = data_dir + \"/\" + items_filename\n",
"boto3.Session().resource('s3').Bucket(bucket_name).Object(items_filename).upload_file(items_file_path)\n",
"\n",
"users_file_path = data_dir + \"/\" + users_filename\n",
"boto3.Session().resource('s3').Bucket(bucket_name).Object(users_filename).upload_file(users_file_path)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Create the Dataset Group \n",
"[Back to top](#top)\n",
"\n",
"The highest level of isolation and abstraction with Amazon Personalize is a *dataset group*. Information stored within one of these dataset groups has no impact on any other dataset group or models created from one - they are completely isolated. This allows you to run many experiments and is part of how we keep your models private and fully trained only on your data. \n",
"\n",
"Before importing the data prepared earlier, there needs to be a dataset group and a dataset added to it that handles the interactions.\n",
"\n",
"Dataset groups can house the following types of information:\n",
"\n",
"* User-item-interactions\n",
"* Event streams (real-time interactions)\n",
"* User metadata\n",
"* Item metadata\n",
"\n",
"We need to create the dataset group that will contain our three datasets."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Create the Dataset Group\n",
"\n",
"The following cell will create a new dataset group with the name `personalize-poc-movielens`."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Configure the SDK to Personalize:\n",
"personalize = boto3.client('personalize')\n",
"personalize_runtime = boto3.client('personalize-runtime')\n",
"print(\"We can communicate with Personalize!\")"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"create_dataset_group_response = personalize.create_dataset_group(\n",
" name = \"personalize-poc-movielens\",\n",
" domain='VIDEO_ON_DEMAND'\n",
")\n",
"\n",
"dataset_group_arn = create_dataset_group_response['datasetGroupArn']\n",
"print(json.dumps(create_dataset_group_response, indent=2))\n",
"\n",
"print(f'DatasetGroupArn = {dataset_group_arn}')"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Wait for Dataset Group to Have ACTIVE Status \n",
"\n",
"Before we can use the Dataset Group in any items below it must be active. This can take a minute or two. Execute the cell below and wait for it to show the ACTIVE status. It checks the status of the dataset group every 60 seconds, up to a maximum of 3 hours."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"max_time = time.time() + 3*60*60 # 3 hours\n",
"while time.time() < max_time:\n",
" describe_dataset_group_response = personalize.describe_dataset_group(\n",
" datasetGroupArn = dataset_group_arn\n",
" )\n",
" status = describe_dataset_group_response[\"datasetGroup\"][\"status\"]\n",
" print(\"DatasetGroup: {}\".format(status))\n",
" \n",
" if status == \"ACTIVE\" or status == \"CREATE FAILED\":\n",
" break\n",
" \n",
" time.sleep(60)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Now that you have a dataset group, you can create a dataset for the interaction data."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Create the Interactions Schema \n",
"[Back to top](#top)\n",
"\n",
"Now that we've loaded and prepared our three datasets we'll need to configure the Amazon Personalize service to understand our data so that it can be used to train models for generating recommendations.Amazon Personalize requires a schema for each dataset so it can map the columns in our CSVs to fields for model training. Each schema is declared in JSON using the [Apache Avro](https://avro.apache.org/) format. \n",
"\n",
"First, define a schema to tell Amazon Personalize what type of dataset you are uploading. There are several reserved and mandatory keywords required in the schema, based on the type of dataset. More detailed information can be found in the [documentation](https://docs.aws.amazon.com/personalize/latest/dg/how-it-works-dataset-schema.html).\n",
"\n",
"Here, you will create a schema for interactions data, which requires the `USER_ID`, `ITEM_ID`, and `TIMESTAMP` fields. These must be defined in the same order in the schema as they appear in the dataset."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"The interactions dataset has three required columns: `ITEM_ID`, `USER_ID`, and `TIMESTAMP`. The `TIMESTAMP` represents when the user interated with an item and must be expressed in Unix timestamp format (seconds). For this dataset we also have an `EVENT_TYPE` column."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"interactions_schema = {\n",
" \"type\": \"record\",\n",
" \"name\": \"Interactions\",\n",
" \"namespace\": \"com.amazonaws.personalize.schema\",\n",
" \"fields\": [\n",
" {\n",
" \"name\": \"USER_ID\",\n",
" \"type\": \"string\"\n",
" },\n",
" {\n",
" \"name\": \"ITEM_ID\",\n",
" \"type\": \"string\"\n",
" },\n",
" {\n",
" \"name\": \"EVENT_TYPE\", # \"Watch\", \"Click\", etc.\n",
" \"type\": \"string\"\n",
" },\n",
" {\n",
" \"name\": \"TIMESTAMP\",\n",
" \"type\": \"long\"\n",
" }\n",
" ],\n",
" \"version\": \"1.0\"\n",
"}\n",
"\n",
"try:\n",
" create_schema_response = personalize.create_schema(\n",
" name = \"personalize-poc-movielens-interactions-schema\",\n",
" schema = json.dumps(interactions_schema),\n",
" domain='VIDEO_ON_DEMAND'\n",
" )\n",
" print(json.dumps(create_schema_response, indent=2))\n",
" interactions_schema_arn = create_schema_response['schemaArn']\n",
"except personalize.exceptions.ResourceAlreadyExistsException:\n",
" print('You aready created this schema.')\n",
" schemas = personalize.list_schemas(maxResults=100)['schemas']\n",
" for schema_response in schemas:\n",
" if schema_response['name'] == \"personalize-poc-movielens-interactions-schema\":\n",
" interactions_schema_arn = schema_response['schemaArn']\n",
" print(f\"Using existing schema: {interactions_schema_arn}\")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Create the Interactions Dataset\n",
"\n",
"With a schema created, you can create a dataset within the dataset group. Note that this does not load the data yet, but creates a schema of what the data looks like. "
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"dataset_type = \"INTERACTIONS\"\n",
"create_dataset_response = personalize.create_dataset(\n",
" name = \"personalize-poc-movielens-interactions\",\n",
" datasetType = dataset_type,\n",
" datasetGroupArn = dataset_group_arn,\n",
" schemaArn = interactions_schema_arn\n",
")\n",
"\n",
"interactions_dataset_arn = create_dataset_response['datasetArn']\n",
"print(json.dumps(create_dataset_response, indent=2))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Create the Items (Movies) Schema\n",
"[Back to top](#top)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"First, define a schema to tell Amazon Personalize what type of dataset you are uploading. There are several reserved and mandatory keywords required in the schema, based on the type of dataset. More detailed information can be found in the [documentation](https://docs.aws.amazon.com/personalize/latest/dg/how-it-works-dataset-schema.html).\n",
"\n",
"Here, you will create a schema for item metadata data, and we define the `ITEM_ID`, `GENRES`, `YEAR`, and `CREATION_TIMESTAMP` fields. These must be defined in the same order in the schema as they appear in the dataset."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"items_schema = {\n",
" \"type\": \"record\",\n",
" \"name\": \"Items\",\n",
" \"namespace\": \"com.amazonaws.personalize.schema\",\n",
" \"fields\": [\n",
" {\n",
" \"name\": \"ITEM_ID\",\n",
" \"type\": \"string\"\n",
" },\n",
" {\n",
" \"name\": \"GENRES\",\n",
" \"type\": \"string\",\n",
" \"categorical\": True\n",
" },{\n",
" \"name\": \"YEAR\",\n",
" \"type\": \"int\",\n",
" },\n",
" {\n",
" \"name\": \"CREATION_TIMESTAMP\",\n",
" \"type\": \"long\",\n",
" }\n",
" ],\n",
" \"version\": \"1.0\"\n",
"}\n",
" \n",
"try:\n",
" create_schema_response = personalize.create_schema(\n",
" name = \"personalize-poc-movielens-items-schema\",\n",
" schema = json.dumps(items_schema),\n",
" domain='VIDEO_ON_DEMAND'\n",
" )\n",
" items_schema_arn = create_schema_response['schemaArn']\n",
" print(json.dumps(create_schema_response, indent=2))\n",
"except personalize.exceptions.ResourceAlreadyExistsException:\n",
" print('You aready created this schema.')\n",
" schemas = personalize.list_schemas(maxResults=100)['schemas']\n",
" for schema_response in schemas:\n",
" if schema_response['name'] == \"personalize-poc-movielens-items-schema\":\n",
" items_schema_arn = schema_response['schemaArn']\n",
" print(f\"Using existing schema: {items_schema_arn}\")\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Create the Items Dataset\n",
"\n",
"With a schema created, you can create a dataset within the dataset group. Note that this does not load the data yet, but creates a schema of what the data looks like. "
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"dataset_type = \"ITEMS\"\n",
"create_dataset_response = personalize.create_dataset(\n",
" name = \"personalize-poc-movielens-items\",\n",
" datasetType = dataset_type,\n",
" datasetGroupArn = dataset_group_arn,\n",
" schemaArn = items_schema_arn\n",
")\n",
"\n",
"items_dataset_arn = create_dataset_response['datasetArn']\n",
"print(json.dumps(create_dataset_response, indent=2))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Create the Users Schema\n",
"[Back to top](#top)\n",
"\n",
"First, define a schema to tell Amazon Personalize what type of dataset you are uploading. There are several reserved and mandatory keywords required in the schema, based on the type of dataset. More detailed information can be found in the [documentation](https://docs.aws.amazon.com/personalize/latest/dg/how-it-works-dataset-schema.html).\n",
"\n",
"Here, you will create a schema for user data, which requires the `USER_ID`, and an additonal metadata field, in this case `GENDER`. These must be defined in the same order in the schema as they appear in the dataset."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"users_schema = {\n",
" \"type\": \"record\",\n",
" \"name\": \"Users\",\n",
" \"namespace\": \"com.amazonaws.personalize.schema\",\n",
" \"fields\": [\n",
" {\n",
" \"name\": \"USER_ID\",\n",
" \"type\": \"string\"\n",
" },\n",
" {\n",
" \"name\": \"GENDER\",\n",
" \"type\": \"string\",\n",
" \"categorical\": True\n",
" }\n",
" ],\n",
" \"version\": \"1.0\"\n",
"}\n",
" \n",
"try:\n",
" create_schema_response = personalize.create_schema(\n",
" name = \"personalize-poc-movielens-users-schema\",\n",
" schema = json.dumps(users_schema),\n",
" domain='VIDEO_ON_DEMAND'\n",
" )\n",
" print(json.dumps(create_schema_response, indent=2))\n",
" users_schema_arn = create_schema_response['schemaArn']\n",
"except personalize.exceptions.ResourceAlreadyExistsException:\n",
" print('You aready created this schema.')\n",
" schemas = personalize.list_schemas(maxResults=100)['schemas']\n",
" for schema_response in schemas:\n",
" if schema_response['name'] == \"personalize-poc-movielens-users-schema\":\n",
" users_schema_arn = schema_response['schemaArn']\n",
" print(f\"Using existing schema: {users_schema_arn}\")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Create the Users dataset\n",
"\n",
"With a schema created, you can create a dataset within the dataset group. Note that this does not load the data yet, but creates a schema of what the data looks like. "
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"dataset_type = \"USERS\"\n",
"create_dataset_response = personalize.create_dataset(\n",
" name = \"personalize-poc-movielens-users\",\n",
" datasetType = dataset_type,\n",
" datasetGroupArn = dataset_group_arn,\n",
" schemaArn = users_schema_arn\n",
")\n",
"\n",
"users_dataset_arn = create_dataset_response['datasetArn']\n",
"print(json.dumps(create_dataset_response, indent=2))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Let's wait untill all the datasets have been created."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"%%time\n",
"\n",
"max_time = time.time() + 6*60*60 # 6 hours\n",
"while time.time() < max_time:\n",
" describe_dataset_response = personalize.describe_dataset(\n",
" datasetArn = interactions_dataset_arn\n",
" )\n",
" status = describe_dataset_response[\"dataset\"]['status']\n",
" print(\"Interactions Dataset: {}\".format(status))\n",
" \n",
" if status == \"ACTIVE\" or status == \"CREATE FAILED\":\n",
" break\n",
" \n",
" time.sleep(60)\n",
" \n",
"while time.time() < max_time:\n",
" describe_dataset_response = personalize.describe_dataset(\n",
" datasetArn = items_dataset_arn\n",
" )\n",
" status = describe_dataset_response[\"dataset\"]['status']\n",
" print(\"Items Dataset: {}\".format(status))\n",
" \n",
" if status == \"ACTIVE\" or status == \"CREATE FAILED\":\n",
" break\n",
" \n",
" time.sleep(60)\n",
" \n",
"while time.time() < max_time:\n",
" describe_dataset_response = personalize.describe_dataset(\n",
" datasetArn = users_dataset_arn\n",
" )\n",
" status = describe_dataset_response[\"dataset\"]['status']\n",
" print(\"Users Dataset: {}\".format(status))\n",
" \n",
" if status == \"ACTIVE\" or status == \"CREATE FAILED\":\n",
" break\n",
" \n",
" time.sleep(60)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Import the interactions data \n",
"[Back to top](#top)\n",
"\n",
"Earlier you created the dataset group and dataset to house your information, so now you will execute an import job that will load the interactions data from the S3 bucket into the Amazon Personalize dataset. "
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"create_dataset_import_job_response = personalize.create_dataset_import_job(\n",
" jobName = \"personalize-poc-interactions-import\",\n",
" datasetArn = interactions_dataset_arn,\n",
" dataSource = {\n",
" \"dataLocation\": \"s3://{}/{}\".format(bucket_name, interactions_filename)\n",
" },\n",
" roleArn = role_arn\n",
")\n",
"\n",
"interactions_dataset_import_job_arn = create_dataset_import_job_response['datasetImportJobArn']\n",
"print(json.dumps(create_dataset_import_job_response, indent=2))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Import the Item Metadata \n",
"[Back to top](#top)\n",
"\n",
"Earlier you created the dataset group and dataset to house your information, now you will execute an import job that will load the item data from the S3 bucket into the Amazon Personalize dataset. "
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"create_dataset_import_job_response = personalize.create_dataset_import_job(\n",
" jobName = \"personalize-poc-items-import\",\n",
" datasetArn = items_dataset_arn,\n",
" dataSource = {\n",
" \"dataLocation\": \"s3://{}/{}\".format(bucket_name, items_filename)\n",
" },\n",
" roleArn = role_arn\n",
")\n",
"\n",
"items_dataset_import_job_arn = create_dataset_import_job_response['datasetImportJobArn']\n",
"print(json.dumps(create_dataset_import_job_response, indent=2))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Import the User Metadata \n",
"[Back to top](#top)\n",
"\n",
"Earlier you created the dataset group and dataset to house your information, now you will execute an import job that will load the user data from the S3 bucket into the Amazon Personalize dataset. "
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"create_dataset_import_job_response = personalize.create_dataset_import_job(\n",
" jobName = \"personalize-poc-users-import\",\n",
" datasetArn = users_dataset_arn,\n",
" dataSource = {\n",
" \"dataLocation\": \"s3://{}/{}\".format(bucket_name, users_filename)\n",
" },\n",
" roleArn = role_arn\n",
")\n",
"\n",
"users_dataset_import_job_arn = create_dataset_import_job_response['datasetImportJobArn']\n",
"print(json.dumps(create_dataset_import_job_response, indent=2))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Before we can use the dataset, the import job must be active. Execute the cell below and wait for it to show the ACTIVE status. It checks the status of the import job every minute, up to a maximum of 6 hours.\n",
"\n",
"Importing the data can take some time, depending on the size of the dataset. In this workshop, the data import job should take around 15 minutes. While you're waiting you can learn more about Datasets and Schemas in [the documentation](https://docs.aws.amazon.com/personalize/latest/dg/how-it-works-dataset-schema.html). We need to wait for the data imports to complete."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"%%time\n",
"\n",
"max_time = time.time() + 6*60*60 # 6 hours\n",
"while time.time() < max_time:\n",
" describe_dataset_import_job_response = personalize.describe_dataset_import_job(\n",
" datasetImportJobArn = interactions_dataset_import_job_arn\n",
" )\n",
" status = describe_dataset_import_job_response[\"datasetImportJob\"]['status']\n",
" print(\"Interactions DatasetImportJob: {}\".format(status))\n",
" \n",
" if status == \"ACTIVE\" or status == \"CREATE FAILED\":\n",
" break\n",
" \n",
" time.sleep(60)\n",
" \n",
"while time.time() < max_time:\n",
" describe_dataset_import_job_response = personalize.describe_dataset_import_job(\n",
" datasetImportJobArn = items_dataset_import_job_arn\n",
" )\n",
" status = describe_dataset_import_job_response[\"datasetImportJob\"]['status']\n",
" print(\"Items DatasetImportJob: {}\".format(status))\n",
" \n",
" if status == \"ACTIVE\" or status == \"CREATE FAILED\":\n",
" break\n",
" \n",
" time.sleep(60)\n",
" \n",
"while time.time() < max_time:\n",
" describe_dataset_import_job_response = personalize.describe_dataset_import_job(\n",
" datasetImportJobArn = users_dataset_import_job_arn\n",
" )\n",
" status = describe_dataset_import_job_response[\"datasetImportJob\"]['status']\n",
" print(\"Users DatasetImportJob: {}\".format(status))\n",
" \n",
" if status == \"ACTIVE\" or status == \"CREATE FAILED\":\n",
" break\n",
" \n",
" time.sleep(60)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"With all imports now complete you can start training recommenders and solutions. Run the cell below before moving on to store a few values for usage in the next notebooks. After completing that cell open notebook `02_Training_Layer.ipynb` to continue."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"%store USE_FULL_MOVIELENS\n",
"%store dataset_dir\n",
"%store dataset_group_arn\n",
"%store bucket_name\n",
"%store role_arn\n",
"%store role_name\n",
"%store data_dir\n",
"%store region\n",
"%store interactions_dataset_arn\n",
"%store items_dataset_arn\n",
"%store users_dataset_arn\n",
"%store interactions_schema_arn\n",
"%store items_schema_arn\n",
"%store users_schema_arn"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": []
}
],
"metadata": {
"kernelspec": {
"display_name": "conda_python3",
"language": "python",
"name": "conda_python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.8.12"
}
},
"nbformat": 4,
"nbformat_minor": 4
}