{
"cells": [
{
"cell_type": "markdown",
"metadata": {},
"source": [
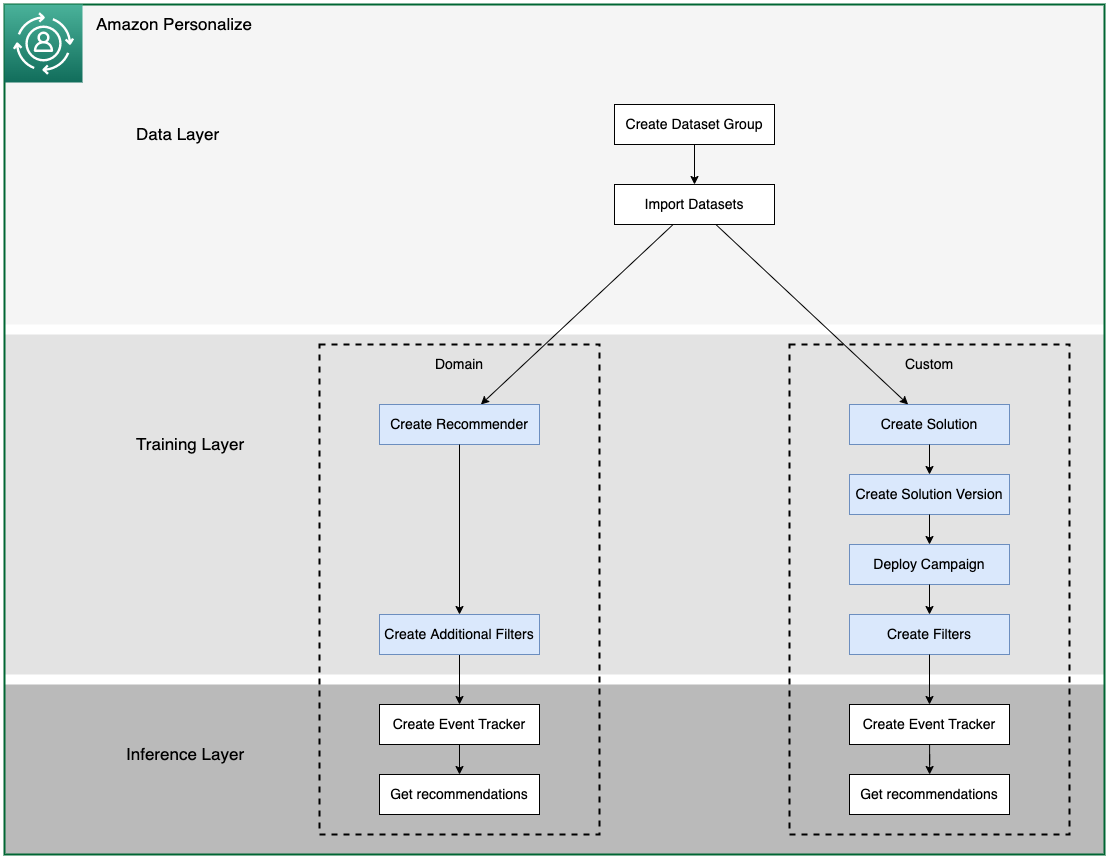
"# Creating Recommenders and Solutions \n",
"\n",
"## Outline\n",
"\n",
"1. [Introduction](#intro)\n",
"1. [Create Domain Recommenders](#recommenders)\n",
"1. [Create Solutions](#solutions)\n",
"1. [Evaluate Solutions](#eval)\n",
"1. [Using Evaluation Metrics](#use)\n",
"1. [Deploy a Campaign](#deploy)\n",
"1. [Create Filters](#interact)\n",
"1. [Storing useful variables](#wrapup)\n",
"\n",
"## Introduction \n",
"\n",
"To recap, we created a Domain dataset group, where you create preconfigured resources for different business domains and use cases, such as getting recommendations for similar videos (VIDEO_ON_DEMAND domain) or best selling items (ECOMMERCE domain). You choose your business domain, import your data, and create recommenders. You use recommenders in your application to get recommendations.\n",
"\n",
"Use a [Domain dataset group](https://docs.aws.amazon.com/personalize/latest/dg/domain-dataset-groups.html) if you have a video on demand or e-commerce application and want Amazon Personalize to find the best configurations for your use cases. If you start with a Domain dataset group, you can also add custom resources such as solutions with solution versions trained with recipes for custom use cases.\n",
"\n",
"A [Custom dataset group](https://docs.aws.amazon.com/personalize/latest/dg/custom-dataset-groups.html), where you create configurable resources for custom use cases and batch recommendation workflows. You choose a recipe, train a solution version (model), and deploy the solution version with a campaign. You use a campaign in your application to get recommendations.\n",
"\n",
"Use a Custom dataset group if you don't have a video on demand or e-commerce application or want to configure and manage only custom resources, or want to get recommendations in a batch workflow. If you start with a Custom dataset group, you can't associate it with a domain later. Instead, create a new Domain dataset group.\n",
"\n",
"Regardless of the use case, the algorithms all share a base of learning on user-item-interaction data which is defined by 3 core attributes:\n",
"\n",
"1. **UserID** - The user who interacted\n",
"1. **ItemID** - The item the user interacted with\n",
"1. **Timestamp** - The time at which the interaction occurred\n",
"\n",
"We also support optional event types and event values defined by:\n",
"\n",
"1. **Event Type** - Categorical label of an event (clicked, purchased, rated, listened, watched, etc).\n",
"1. **Event Value** - A numeric value corresponding to the event type that occurred. This value can be used to filter interactions that are included in model training by specifying a minimum threshold. For example, suppose you have an event type of `Rated` and the value is the user rating on a scale of 0 to 5. Since Personalize models on positive interactions, you can use an event value threshold of, say, 3 to only include interactions with an event type of `Rated` that have an event value of 3 or higher.\n",
"\n",
"The event type and event value fields are additional data which can be used to filter the data sent for training the personalization model. In this particular exercise we dol not have an event value and will not be filtering the training data, i.e. we will use all available data for training (More information on how to use the eventValue with eventValueThreshold for Custom Domains in the [documentation](https://docs.aws.amazon.com/personalize/latest/dg/recording-events.html)). \n",
"\n",
"### In this notebook we will accomplish the following:\n",
"\n",
"Create Video on Demand Domain Recommenders for the following use cases:\n",
"\n",
"1. [More like X](https://docs.aws.amazon.com/personalize/latest/dg/VIDEO_ON_DEMAND-use-cases.html#more-like-y-use-case): recommendations for movies that are similar to a movie that you specify. With this use case, Amazon Personalize automatically filters movies the user watched based on the userId that you specify and Watch events.\n",
"\n",
"1. [Top picks for you](https://docs.aws.amazon.com/personalize/latest/dg/VIDEO_ON_DEMAND-use-cases.html#top-picks-use-case): personalized content recommendations for a user that you specify. With this use case, Amazon Personalize automatically filters videos the user watched based on the userId that you specify and Watch events.\n",
"\n",
"Create a custom solution and solution versions for the following use case:\n",
"\n",
"3. [Personalized-Ranking](https://docs.aws.amazon.com/personalize/latest/dg/working-with-predefined-recipes.html): will be used to rerank a list of movies.\n",
"\n",
"\n",
"\n",
"To run this notebook, you need to have run the previous notebook, `01_Data_Layer.ipynb`, where you created a dataset and imported interaction, item, and user metadata data into Amazon Personalize. At the end of that notebook, you saved some of the variable values, which you now need to load into this notebook."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"%store -r"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Similar to the previous notebook, start by importing the relevant packages, and set up a connection to Amazon Personalize using the SDK."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"import time\n",
"from time import sleep\n",
"import json\n",
"from datetime import datetime\n",
"import uuid\n",
"import random\n",
"import boto3\n",
"import botocore\n",
"from botocore.exceptions import ClientError\n",
"import pandas as pd"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Configure the SDK to Personalize:\n",
"personalize = boto3.client('personalize')\n",
"personalize_runtime = boto3.client('personalize-runtime')"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Create Domain Recommenders \n",
"[Back to top](#top)\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"We'll start with pre-configured VIDEO_ON_DEMAND Recommenders that match some of our core use cases. Each domain has different use cases. When you create a recommender you create it for a specific use case, and each use case has different requirements for getting recommendations.\n",
"\n",
"Let us look at the Recommenders supported for this domain:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"available_recipes = personalize.list_recipes(domain='VIDEO_ON_DEMAND')\n",
"display_available_recipes = available_recipes ['recipes']\n",
"available_recipes = personalize.list_recipes(domain='VIDEO_ON_DEMAND',nextToken=available_recipes['nextToken'])#paging to get the rest of the recipes \n",
"display_available_recipes = display_available_recipes + available_recipes['recipes']\n",
"display(display_available_recipes)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"[More use cases per domain](https://docs.aws.amazon.com/personalize/latest/dg/domain-use-cases.html).\n",
"\n",
"### Create a \"More like X\" Recommender\n",
"\n",
"We are going to create a recommender of the type \"More like X\". This type of recommender offers recommendations for videos that are similar to a video a user watched. With this use case, Amazon Personalize automatically filters videos the user watched based on the userId specified in the `get_recommendations` call. "
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"create_recommender_response = personalize.create_recommender(\n",
" name = 'more-like-x',\n",
" recipeArn = 'arn:aws:personalize:::recipe/aws-vod-more-like-x',\n",
" datasetGroupArn = dataset_group_arn\n",
")\n",
"recommender_more_like_x_arn = create_recommender_response[\"recommenderArn\"]\n",
"print (json.dumps(create_recommender_response))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Create a \"Top picks for you\" Recommender\n",
"\n",
"We are going to create a second recommender of the type \"Top picks for you\". This type of recommender offers personalized streaming content recommendations for a user that you specify. With this use case, Amazon Personalize automatically filters videos the user watched based on the userId that you specify and Watch events."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"create_recommender_response = personalize.create_recommender(\n",
" name = 'top_picks_for_you',\n",
" recipeArn = 'arn:aws:personalize:::recipe/aws-vod-top-picks',\n",
" datasetGroupArn = dataset_group_arn\n",
")\n",
"recommender_top_picks_arn = create_recommender_response[\"recommenderArn\"]\n",
"print (json.dumps(create_recommender_response))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Create Solutions \n",
"[Back to top](#top)\n",
"\n",
"Some use cases require a custom implementation. \n",
"\n",
"In Amazon Personalize, a specific variation of an algorithm is called a recipe. Different recipes are suitable for different situations. A trained model is called a solution, and each solution can have many versions that relate to a given volume of data when the model was trained.\n",
"\n",
"Let's look at all available recipes that are not of a specific domain and can be used to create custom solutions. "
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"available_recipes = personalize.list_recipes()\n",
"display_available_recipes = available_recipes ['recipes']\n",
"available_recipes = personalize.list_recipes(nextToken=available_recipes['nextToken'])#paging to get the rest of the recipes \n",
"display_available_recipes = display_available_recipes + available_recipes['recipes']\n",
"\n",
"display ([recipe for recipe in display_available_recipes if 'domain' not in recipe])\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"We want to rank a list of items for a specific user. This is useful if you have a collection of ordered items, such as search results, promotions, or curated lists, and you want to provide a personalized re-ranking for each of your users. To implement this use case, we will create a custom solution using the recipe.\n",
"\n",
"The [Personalized-Ranking](https://docs.aws.amazon.com/personalize/latest/dg/working-with-predefined-recipes.html) recipe provides recommendations in ranked order based on predicted interest level. This recipe generates personalized rankings of items. A personalized ranking is a list of recommended items that are re-ranked for a specific user. This is useful if you have a collection of ordered items, such as search results, promotions, or curated lists, and you want to provide a personalized re-ranking for each of your users.\n",
"\n",
"These custom solution will use the same datasets that we already implemented so all we need to do is create a solution and solution version for this recipe."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Personalized Ranking\n",
"\n",
"Personalized Ranking is an interesting application of HRNN. Instead of just recommending what is most probable for the user in question, this algorithm takes in a list of items as well as a user. The items are then returned back in the order of most probable relevance for the user. The use case here is for filtering on unique categories that you do not have item metadata to create a filter, or when you have a broad collection that you would like better ordered for a particular user.\n",
"\n",
"For our use case, using the MovieLens data, we could imagine that a Video on Demand application may want to create a shelf of comic book movies, or movies by a specific director. We can generate these lists based on metadata we have. We would use personalized ranking to re-order the list of movies for each user. \n",
"\n",
"We start by selecting the recipe."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"rerank_recipe_arn = \"arn:aws:personalize:::recipe/aws-personalized-ranking\""
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Create the solution\n",
"\n",
"First you create a solution using the recipe. Although you provide the dataset ARN in this step, the model is not yet trained. See this as an identifier instead of a trained model."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"rerank_create_solution_response = personalize.create_solution(\n",
" name = \"personalize-poc-rerank\",\n",
" datasetGroupArn = dataset_group_arn,\n",
" recipeArn = rerank_recipe_arn\n",
")\n",
"\n",
"rerank_solution_arn = rerank_create_solution_response['solutionArn']\n",
"print(json.dumps(rerank_create_solution_response, indent=2))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Create the solution version\n",
"\n",
"Once you have a solution, you need to create a version in order to complete the model training. The training can take a while to complete, upwards of 25 minutes, and an average of 35 minutes for this recipe with our dataset. Normally, we would use a while loop to poll until the task is completed. "
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"rerank_create_solution_version_response = personalize.create_solution_version(\n",
" solutionArn = rerank_solution_arn\n",
")"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"rerank_solution_version_arn = rerank_create_solution_version_response['solutionVersionArn']\n",
"print(json.dumps(rerank_create_solution_version_response, indent=2))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### View solution and Recommender creation status\n",
"\n",
"To view the status updates in the console:\n",
"\n",
"* In another browser tab you should already have the AWS Console up from opening this notebook instance. \n",
"* Switch to that tab and search at the top for the service `Personalize`, then go to that service page. \n",
"* Click `Dataset groups`.\n",
"* Click the name of your dataset group, if you did not change it, it is \"personalize-poc-movielens\".\n",
"* Click `Recommenders`.\n",
"* You will see a list of the two recommenders you created above, including a column with the status of the recommender. Once it is `Active`, your recommender is ready.\n",
"* Click on `Custom Resources`. This oppens up the list of custom resources that youhave created.\n",
"* Click on `Solutions and Recipes` to see your re-ranking solutions. If you click on `personalize-poc-rerank` you can see the status of the solution versions. Once it is `Active`, your solution is ready to be reviewed. It is also capable of being deployed.\n",
"\n",
"Or simply run the cell below to keep track of the recommenders and solution version creation status."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"max_time = time.time() + 10*60*60 # 10 hours\n",
"while time.time() < max_time:\n",
"\n",
" # Recommender more_like_x\n",
" version_response = personalize.describe_recommender(\n",
" recommenderArn = recommender_more_like_x_arn\n",
" )\n",
" status_more_like_x = version_response[\"recommender\"][\"status\"]\n",
"\n",
" if status_more_like_x == \"ACTIVE\":\n",
" print(\"Build succeeded for {}\".format(recommender_more_like_x_arn))\n",
" \n",
" elif status_more_like_x == \"CREATE FAILED\":\n",
" print(\"Build failed for {}\".format(recommender_more_like_x_arn))\n",
" break\n",
"\n",
" if not status_more_like_x == \"ACTIVE\":\n",
" print(\"The recommender more_like_x build is still in progress\")\n",
" else:\n",
" print(\"The recommender more_like_x is ACTIVE\")\n",
"\n",
" # Recommender top_picks_for_you\n",
" version_response = personalize.describe_recommender(\n",
" recommenderArn = recommender_top_picks_arn\n",
" )\n",
" status_top_picks = version_response[\"recommender\"][\"status\"]\n",
"\n",
" if status_top_picks == \"ACTIVE\":\n",
" print(\"Build succeeded for {}\".format(recommender_top_picks_arn))\n",
" elif status_top_picks == \"CREATE FAILED\":\n",
" print(\"Build failed for {}\".format(recommender_top_picks_arn))\n",
" break\n",
"\n",
" if not status_top_picks == \"ACTIVE\":\n",
" print(\"The recommender top_picks build is still in progress\")\n",
" else:\n",
" print(\"The recommender top_picks is ACTIVE\")\n",
" \n",
" # Reranking Solution \n",
" version_response = personalize.describe_solution_version(\n",
" solutionVersionArn = rerank_solution_version_arn\n",
" )\n",
" status_rerank_solution = version_response[\"solutionVersion\"][\"status\"]\n",
"\n",
" if status_rerank_solution == \"ACTIVE\":\n",
" print(\"Build succeeded for {}\".format(rerank_solution_version_arn))\n",
" \n",
" elif status_rerank_solution == \"CREATE FAILED\":\n",
" print(\"Build failed for {}\".format(rerank_solution_version_arn))\n",
" break\n",
"\n",
" if not status_rerank_solution == \"ACTIVE\":\n",
" print(\"Rerank Solution Version build is still in progress\")\n",
" else:\n",
" print(\"The Rerank solution is ACTIVE\")\n",
" \n",
" if status_more_like_x == \"ACTIVE\" and status_top_picks == 'ACTIVE' and status_rerank_solution == \"ACTIVE\":\n",
" break\n",
"\n",
" print()\n",
" time.sleep(60)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Wait for Recommenders and Solution Versions to finish training\n",
"\n",
"It can take 40-60 minutes for all Recommenders and solution versions to be created. During this process a model is being trained and tested with the data contained within your datasets. The duration of training jobs can increase based on the size of the dataset, training parameters and a selected recipe. \n",
"\n",
"While you are waiting for this process to complete you can learn more about solutions in [the documentation](https://docs.aws.amazon.com/personalize/latest/dg/training-deploying-solutions.html)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Evaluate Solutions\n",
"[Back to top](#top)\n",
"\n",
"Custom Solutions and Solution Versions give you the freedom to fine tune parameters and evaluate them.\n",
"\n",
"### Hyperparameter tuning\n",
"\n",
"Personalize offers the option of running hyperparameter tuning when creating a solution. Because of the additional computation required to perform hyperparameter tuning, this feature is turned off by default. Therefore, the solution we created above, will simply use the default values of the hyperparameters for the recipe. For more information about hyperparameter tuning, see the [documentation](https://docs.aws.amazon.com/personalize/latest/dg/customizing-solution-config-hpo.html).\n",
"\n",
"If you have settled on the correct recipe to use, and are ready to run hyperparameter tuning, the following code shows how you would do so, using Personalized Ranking as an example.\n",
"\n",
"```python\n",
"rerank_create_solution_response = personalize.create_solution(\n",
" name = \"personalize-poc-rerank-hpo\",\n",
" datasetGroupArn = dataset_group_arn,\n",
" recipeArn = rerank_recipe_arn,\n",
" performHPO=True\n",
")\n",
"\n",
"rerank_solution_arn = rerank_create_solution_response['solutionArn']\n",
"print(json.dumps(rerank_create_solution_response, indent=2))\n",
"```\n",
"\n",
"If you already know the values you want to use for a specific hyperparameter, you can also set this value when you create the solution. The code below shows how you could set the value for the `recency_mask` for the Personalized Ranking recipe. More information on this hyperparameter in the [documentation](https://docs.aws.amazon.com/personalize/latest/dg/native-recipe-search.html).\n",
"\n",
"```python\n",
"rerank_create_solution_response = personalize.create_solution(\n",
" name = \"personalize-poc-rerank-set-hp\",\n",
" datasetGroupArn = dataset_group_arn,\n",
" recipeArn = rerank_recipe_arn,\n",
" solutionConfig = {\n",
" 'algorithmHyperParameters': {\n",
" 'recency_mask': False\n",
" }\n",
" }\n",
")\n",
"\n",
"rerank_solution_arn = rerank_create_solution_response['solutionArn']\n",
"print(json.dumps(rerank_create_solution_response, indent=2))\n",
"```"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Evaluate solution versions \n",
"\n",
"It should not take more than an hour to train all the recommenders and solutions from this notebook. While training is in progress, we recommend taking the time to read up on the various algorithms (recipes) and their behavior in detail. This is also a good time to consider alternatives to how the data was fed into the system and what kind of results you expect to see.\n",
"\n",
"When the solution finishes creating, the next step is to obtain the evaluation metrics. Personalize calculates these metrics based on a subset of the training data. The image below illustrates how Personalize splits the data. Given 10 users, with 10 interactions each (a circle represents an interaction), the interactions are ordered from oldest to newest based on the timestamp. Personalize uses all of the interaction data from 90% of the users (blue circles) to train the solution version, and the remaining 10% for evaluation. For each of the users in the remaining 10%, 90% of their interaction data (green circles) is used as input for the call to the trained model. The remaining 10% of their data (orange circle) is compared to the output produced by the model and used to calculate the evaluation metrics.\n",
"\n",
"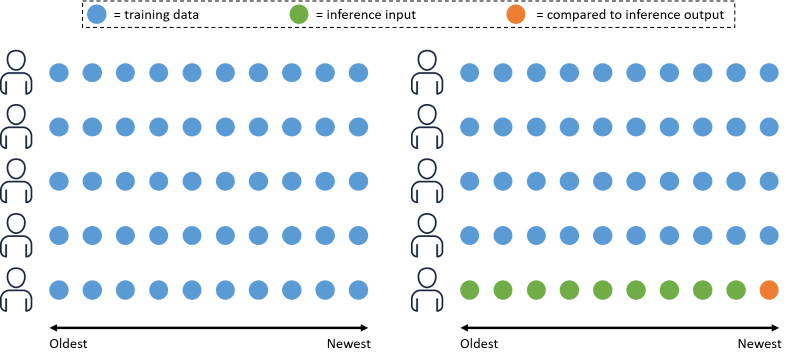\n",
"\n",
"We recommend reading [the documentation](https://docs.aws.amazon.com/personalize/latest/dg/working-with-training-metrics.html) to understand the metrics, but we have also copied parts of the documentation below for convenience.\n",
"\n",
"You need to understand the following terms regarding evaluation in Personalize:\n",
"\n",
"* *Relevant recommendation* refers to a recommendation that matches a value in the testing data for the particular user.\n",
"* *Rank* refers to the position of a recommended item in the list of recommendations. Position 1 (the top of the list) is presumed to be the most relevant to the user.\n",
"* *Query* refers to the internal equivalent of a GetRecommendations call.\n",
"\n",
"The metrics produced by Personalize are:\n",
"* **coverage**: The proportion of unique recommended items from all queries out of the total number of unique items in the training data (includes both the Items and Interactions datasets).\n",
"* **mean_reciprocal_rank_at_25**: The [mean of the reciprocal ranks](https://en.wikipedia.org/wiki/Mean_reciprocal_rank) of the first relevant recommendation out of the top 25 recommendations over all queries. This metric is appropriate if you're interested in the single highest ranked recommendation.\n",
"* **normalized_discounted_cumulative_gain_at_K**: Discounted gain assumes that recommendations lower on a list of recommendations are less relevant than higher recommendations. Therefore, each recommendation is discounted (given a lower weight) by a factor dependent on its position. To produce the [cumulative discounted gain](https://en.wikipedia.org/wiki/Discounted_cumulative_gain) (DCG) at K, each relevant discounted recommendation in the top K recommendations is summed together. The normalized discounted cumulative gain (NDCG) is the DCG divided by the ideal DCG such that NDCG is between 0 - 1. (The ideal DCG is where the top K recommendations are sorted by relevance.) Amazon Personalize uses a weighting factor of 1/log(1 + position), where the top of the list is position 1. This metric rewards relevant items that appear near the top of the list, because the top of a list usually draws more attention.\n",
"* **precision_at_K**: The number of relevant recommendations out of the top K recommendations divided by K. This metric rewards precise recommendation of the relevant items.\n",
"\n",
"Let's take a look at the evaluation metrics for each of the solutions produced in this notebook. Please note that your results might differ from the results described in the text of this notebook, due to the quality of the Movielens dataset. "
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Personalized ranking metrics\n",
"\n",
"Retrieve the evaluation metrics for the personalized ranking solution version."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"rerank_solution_metrics_response = personalize.get_solution_metrics(\n",
" solutionVersionArn = rerank_solution_version_arn\n",
")\n",
"\n",
"print(json.dumps(rerank_solution_metrics_response, indent=2))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Just a quick comment on this one, here we see again a precision of near (2.7% for full, 2.2% for small), as this is based on User Personalization, that is to be expected. However the sample items are not the same items used for validaiton, thus the low scoring.\n",
"\n",
"## Using Evaluation Metrics \n",
"[Back to top](#top)\n",
"\n",
"It is important to use evaluation metrics carefully. There are a number of factors to keep in mind.\n",
"\n",
"* If there is an existing recommendation system in place, this will have influenced the user's interaction history which you use to train your new solutions. This means the evaluation metrics are biased to favor the existing solution. If you work to push the evaluation metrics to match or exceed the existing solution, you may just be pushing the User Personalization to behave like the existing solution and might not end up with something better.\n",
"* The HRNN Coldstart recipe is difficult to evaluate using the metrics produced by Amazon Personalize. The aim of the recipe is to recommend items which are new to your business. Therefore, these items will not appear in the existing user transaction data which is used to compute the evaluation metrics. As a result, HRNN Coldstart will never appear to perform better than the other recipes, when compared on the evaluation metrics alone. Note: The User Personalization recipe also includes improved cold start functionality\n",
"\n",
"Keeping in mind these factors, the evaluation metrics produced by Personalize are generally useful for two cases:\n",
"1. Comparing the performance of solution versions trained on the same recipe, but with different values for the hyperparameters and features (impression data etc)\n",
"1. Comparing the performance of solution versions trained on different recipes (except HRNN Coldstart). Here also keep in mind that the recipes answer different use cases and comparing them to each other might not make sense in your solution.\n",
"\n",
"Properly evaluating a recommendation system is always best done through A/B testing while measuring actual business outcomes. Since recommendations generated by a system usually influence the user behavior which it is based on, it is better to run small experiments and apply A/B testing for longer periods of time. Over time, the bias from the existing model will fade."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Deploy a Campaign \n",
"[Back to top](#top)\n",
"\n",
"Once a solution version is created, it is possible to get recommendations from them, and to get a feel for their overall behavior.\n",
"\n",
"For real-time recommendations, after you prepare and import data and creating a solution, you are ready to deploy your solution version to generate recommendations. You deploy a solution version by creating an Amazon Personalize campaign. If you are getting batch recommendations, you don't need to create a campaign. For more information see [Getting batch recommendations and user segments](https://docs.aws.amazon.com/personalize/latest/dg/recommendations-batch.html).\n",
"\n",
"We will deploy a campaign for the solution version. "
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Create a campaign \n",
"\n",
"A campaign is a hosted solution version; an endpoint which you can query for recommendations. Pricing is set by estimating throughput capacity (requests from users for personalization per second). When deploying a campaign, you set a minimum throughput per second (TPS) value. This service, like many within AWS, will automatically scale based on demand, but if latency is critical, you may want to provision ahead for larger demand. For this POC and demo, all minimum throughput thresholds are set to 1. For more information, see the [pricing page](https://aws.amazon.com/personalize/pricing/).\n",
"\n",
"Once we're satisfied with our solution version, we need to create Campaigns for each solution version. When creating a campaign you specify the minimum transactions per second (`minProvisionedTPS`) that you expect to make against the service for this campaign. Personalize will automatically scale the inference endpoint up and down for the campaign to match demand but will never scale below `minProvisionedTPS`.\n",
"\n",
"Let's create a campaigns for our solution versions set at `minProvisionedTPS` of 1."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"rerank_create_campaign_response = personalize.create_campaign(\n",
" name = \"personalize-poc-rerank\",\n",
" solutionVersionArn = rerank_solution_version_arn,\n",
" minProvisionedTPS = 1\n",
")\n",
"\n",
"rerank_campaign_arn = rerank_create_campaign_response['campaignArn']\n",
"print(json.dumps(rerank_create_campaign_response, indent=2))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### View campaign creation status\n",
"\n",
"This is how you view the status updates in the console:\n",
"\n",
"* In another browser tab you should already have the AWS Console open from opening this notebook instance. \n",
"* Switch to that tab and search at the top for the service `Personalize`, then go to that service page. \n",
"* Click `Dataset groups`.\n",
"* Click the name of your dataset group.\n",
"* Click `Recommenders`\n",
"* Click `Custom Resources`\n",
"* Click `Campaigns`.\n",
"* You will now see a list of all of the campaigns you created above, including a column with the status of the campaign. Once it is `Active`, your campaign is ready to be queried.\n",
"\n",
"Or simply run the cell below to keep track of the campaign creation status of the campaign we created.\n",
"\n",
"While you are waiting for this to complete you can learn more about campaigns in [the documentation](https://docs.aws.amazon.com/personalize/latest/dg/campaigns.html)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"max_time = time.time() + 3*60*60 # 3 hours\n",
"while time.time() < max_time:\n",
"\n",
" version_response = personalize.describe_campaign(\n",
" campaignArn = rerank_campaign_arn\n",
" )\n",
" status = version_response['campaign']['status']\n",
"\n",
" if status == 'ACTIVE':\n",
" print('Build succeeded for {}'.format(rerank_campaign_arn))\n",
" elif status == \"CREATE FAILED\":\n",
" print('Build failed for {}'.format(rerank_campaign_arn))\n",
" in_progress_campaigns.remove(rerank_campaign_arn)\n",
" \n",
" if status == 'ACTIVE' or status == 'CREATE FAILED':\n",
" break\n",
" else:\n",
" print('The campaign build is still in progress')\n",
" \n",
" time.sleep(60)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Create Filters \n",
"[Back to top](#top)\n",
"\n",
"Amazon Personalize supports the ability to create [filters](https://docs.aws.amazon.com/personalize/latest/dg/filter.html) that can be used to exclude items from being recommended that meet a filter expression. \n",
"\n",
"Now that all campaigns are deployed and active amd the recommenders have been trained we can create filters. Filters can be created for fields of both Items and Events. Filters can also be created dynamically for `IN` and `=` operations. For range queries, you should use static filters. \n",
"Range queries use the following operations: `NOT IN`, `<`, `>`, `<=`, and `>=`.\n",
"\n",
"A few common use cases for static filters in Video On Demand are:\n",
"\n",
"Categorical filters based on Item Metadata (that are range based) - Often your item metadata will have information about the title such as year, user rating, available date. Filtering on these can provide recommendations within that data, such as movies that are available after a specific date, movies rated over 3 stars, movies from the 1990s etc.\n",
"\n",
"User Demographic ranges - you may want to recommend content to specific age demographics, for this you can create a filter that is specific to a age range like over 18, over 18 AND under 30, etc).\n",
"\n",
"Lets look at the item metadata and user interactions, so we can get an idea what type of filters we can create."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Create a dataframe for the items by reading in the correct source CSV\n",
"items_meta_df = pd.read_csv(data_dir + '/item-meta.csv', sep=',', index_col=0)\n",
"\n",
"# Render some sample data\n",
"items_meta_df.head(10)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Since there are a lot of genres to filter on, we will create a dynamic filter using the dynamic variable $GENRE, this will allow us to pass in the variable at runtime rather than create a static filter for each genre."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"create_genre_filter_response = personalize.create_filter(name='Genre',\n",
" datasetGroupArn = dataset_group_arn,\n",
" filterExpression = 'INCLUDE ItemID WHERE Items.GENRES IN ($GENRE)'\n",
" )"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"genre_filter_arn = create_genre_filter_response['filterArn']"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Since we have added the year to our item metadata, lets create a decade filter to recommend only movies released in a given decade. A soft limit of Personalize at this time is 10 total filters, so we will create 7 decade filters for this workshop, leaving room for additional static and dynamic filters."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Create a list for the metadata decade filters and then create the actual filters with the cells below. Note this will take a few minutes to complete."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"decades_to_filter = [1950,1960,1970,1980,1990,2000,2010]"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Create a list for the filters:\n",
"meta_filter_decade_arns = []"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Iterate through Genres\n",
"for decade in decades_to_filter:\n",
" # Start by creating a filter\n",
" current_decade = str(decade)\n",
" next_decade = str(decade + 10)\n",
" try:\n",
" createfilter_response = personalize.create_filter(\n",
" name = current_decade + \"s\",\n",
" datasetGroupArn = dataset_group_arn,\n",
" filterExpression = 'INCLUDE ItemID WHERE Items.YEAR >= '+ current_decade +' AND Items.YEAR < '+ next_decade +''\n",
" )\n",
" # Add the ARN to the list\n",
" meta_filter_decade_arns.append(createfilter_response['filterArn'])\n",
" print(\"Creating: \" + createfilter_response['filterArn'])\n",
" \n",
" # If this fails, wait a bit\n",
" except ClientError as error:\n",
" # Here we only care about raising if it isnt the throttling issue\n",
" if error.response['Error']['Code'] != 'LimitExceededException':\n",
" print(error)\n",
" else: \n",
" time.sleep(120)\n",
" createfilter_response = personalize.create_filter(\n",
" name = current_decade + \"s\",\n",
" datasetGroupArn = dataset_group_arn,\n",
" filterExpression = 'INCLUDE ItemID WHERE Items.YEAR >= '+ current_decade +' AND Items.YEAR < '+ next_decade +''\n",
" )\n",
" # Add the ARN to the list\n",
" meta_filter_decade_arns.append(createfilter_response['filterArn'])\n",
" print(\"Creating: \" + createfilter_response['filterArn'])"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Lets also create 2 event filters for watched and unwatched content. The [Top picks for you](https://docs.aws.amazon.com/personalize/latest/dg/VIDEO_ON_DEMAND-use-cases.html#top-picks-use-case) and [More like X](https://docs.aws.amazon.com/personalize/latest/dg/VIDEO_ON_DEMAND-use-cases.html#more-like-y-use-case) already have a filter on implemented to filter out watched events."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Create a dataframe for the interactions by reading in the correct source CSV\n",
"interactions_df = pd.read_csv(data_dir + '/interactions.csv', sep=',', index_col=0)\n",
"\n",
"# Render some sample data\n",
"interactions_df.head(10)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"createwatchedfilter_response = personalize.create_filter(name='watched',\n",
" datasetGroupArn = dataset_group_arn,\n",
" filterExpression = 'INCLUDE ItemID WHERE Interactions.event_type IN (\"Watch\")'\n",
" )\n",
"\n",
"createunwatchedfilter_response = personalize.create_filter(name='unwatched',\n",
" datasetGroupArn = dataset_group_arn,\n",
" filterExpression = 'EXCLUDE ItemID WHERE Interactions.event_type IN (\"Watch\")'\n",
" )"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Before we move on we want to add those filters to a list as well so they can be used later."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"interaction_filter_arns = [createwatchedfilter_response['filterArn'], createunwatchedfilter_response['filterArn']]"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Storing useful variables \n",
"[Back to top](#top)\n",
"\n",
"Before exiting this notebook, run the following cells to save the version ARNs for use in the next notebook."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"%store rerank_solution_version_arn\n",
"%store recommender_top_picks_arn\n",
"%store recommender_more_like_x_arn\n",
"%store rerank_solution_arn\n",
"%store rerank_campaign_arn\n",
"%store meta_filter_decade_arns\n",
"%store genre_filter_arn\n",
"%store interaction_filter_arns"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"You're all set to move on to the last exploratory notebook: `03_Inference_Layer.ipynb`. Open it from the browser and you can start interacting with the Recommenders and Campaign and getting recommendations!"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": []
}
],
"metadata": {
"kernelspec": {
"display_name": "conda_python3",
"language": "python",
"name": "conda_python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.6.13"
}
},
"nbformat": 4,
"nbformat_minor": 4
}