{
"cells": [
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Interacting with Recommenders and Campaigns \n",
"\n",
"In this notebook, you will deploy and interact with campaigns in Amazon Personalize.\n",
"\n",
"1. [Introduction](#intro)\n",
"1. [Interact with Recommenders](#interact-recommenders)\n",
"1. [Interact with Campaigns](#interact-campaigns)\n",
"1. [Using Static and Dynamic Filters](#filters)\n",
"1. [Real-time Events](#real-time)\n",
"1. [Batch Recommendations](#batch)\n",
"1. [Wrap Up](#wrapup)\n",
"\n",
"## Introduction \n",
"[Back to top](#top)\n",
"\n",
"At this point, you should have 2 Recommenders and one deployed campaign. Once they are active, there are resources for querying the recommendations, and helper functions to digest the output into something more human-readable. \n",
"\n",
"\n",
"In this Notebook we will interact with Recommenders and Campaigns and get recommendatiosn. We will interact with filters and send live data to Amazon Personalize to see the effect on recommendations.\n",
"\n",
"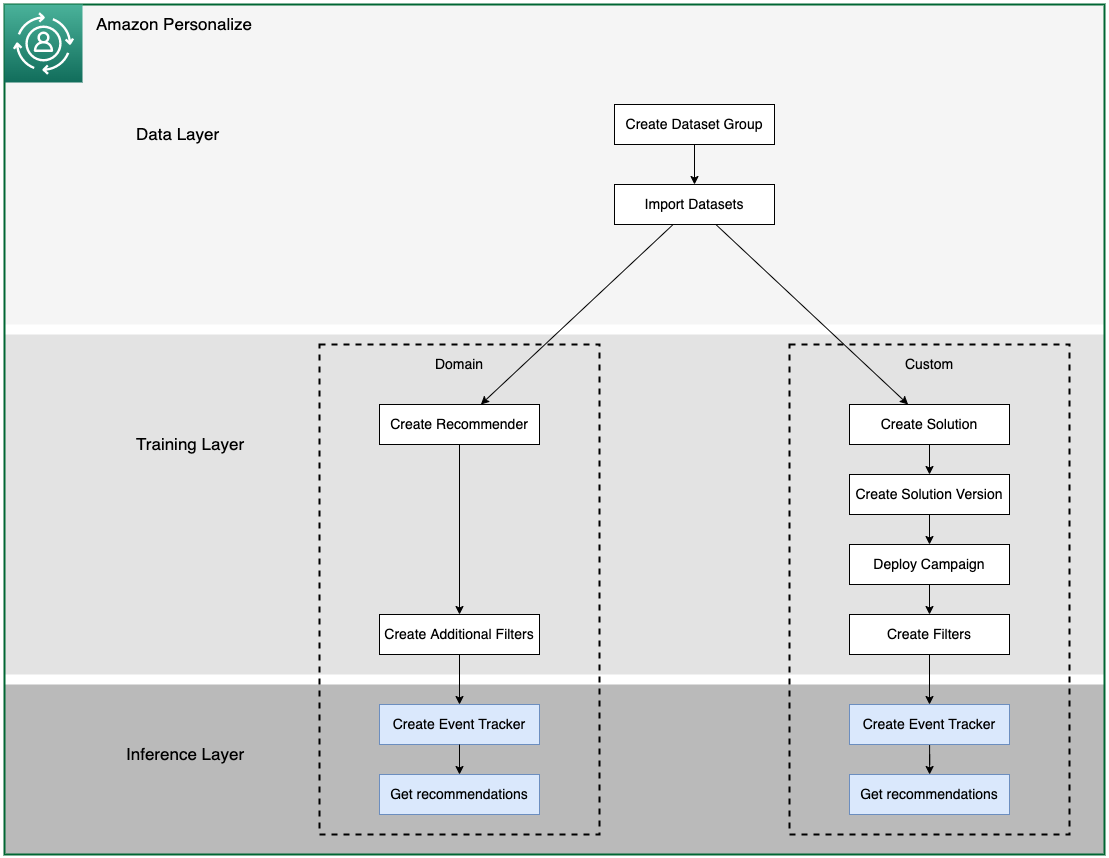\n",
"\n",
"To run this notebook, you need to have run the previous notebooks, `01_Data_Layer.ipynb`, and `02_Training_Layer.ipynb`, where you created a dataset and imported interaction, item, and user metadata data into Amazon Personalize, created recommenders, solutions and campaigns. At the end of that notebook, you saved some of the variable values, which you now need to load into this notebook.\n",
"\n",
"As you work with your customer on Amazon Personalize, you can modify the helper functions to fit the structure of their data input files to keep the additional rendering working.\n",
"\n",
"To get started, once again, we need to import libraries, load values from previous notebooks, and load the SDK."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"import time\n",
"from time import sleep\n",
"import json\n",
"from datetime import datetime\n",
"import uuid\n",
"import random\n",
"import boto3\n",
"import pandas as pd"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"%store -r"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"personalize = boto3.client('personalize')\n",
"personalize_runtime = boto3.client('personalize-runtime')\n",
"\n",
"# Establish a connection to Personalize's event streaming\n",
"personalize_events = boto3.client(service_name='personalize-events')"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"First, let's create a supporting function to help make sense of the results returned by a Personalize recommender or campaign. Personalize returns only an `item_id`. This is great for keeping data compact, but it means you need to query a database or lookup table to get a human-readable result for the notebooks. We will create a helper function to return a human-readable result from the Movielens dataset.\n",
"\n",
"Start by loading in the dataset which we can use for our lookup table."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Create a dataframe for the items by reading in the correct source CSV\n",
"items_df = pd.read_csv(dataset_dir + '/movies.csv', sep=',', usecols=[0,1], encoding='latin-1', dtype={'movieId': \"object\", 'title': \"str\"},index_col=0)\n",
"\n",
"# Render some sample data\n",
"items_df.head(5)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"By defining the ID column as the index column it is trivial to return a movie by just querying the ID. Movie #589 should be Terminator 2: Judgment Day."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"movieIdExample = 589\n",
"title = items_df.loc[movieIdExample]['title']\n",
"print(title)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"That isn't terrible, but it would get messy to repeat this everywhere in our code, so the function below will clean that up."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"def get_movie_by_id(movieId, movie_df=items_df):\n",
" \"\"\"\n",
" This takes in an artist_id from Personalize so it will be a string,\n",
" converts it to an int, and then does a lookup in a default or specified\n",
" dataframe.\n",
" \n",
" A really broad try/except clause was added in case anything goes wrong.\n",
" \n",
" Feel free to add more debugging or filtering here to improve results if\n",
" you hit an error.\n",
" \"\"\"\n",
" try:\n",
" return movie_df.loc[int(movieId)]['title']\n",
" except:\n",
" return \"Error obtaining title\""
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Now let's test a few simple values to check our error catching."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# A known good id (The Princess Bride)\n",
"print(get_movie_by_id(movieId=\"1197\"))\n",
"# A bad type of value\n",
"print(get_movie_by_id(movieId=\"987.9393939\"))\n",
"# Really bad values\n",
"print(get_movie_by_id(movieId=\"Steve\"))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Great! Now we have a way of rendering results. "
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Interact with recommenders \n",
"[Back to top](#top)\n",
"\n",
"Now that the recommenders have been trained, lets have a look at the recommendations we can get for our users!"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### \"More like X\" Recommender\n",
"\n",
"'More like X' requires an item and a user as input, and it will return items which users interact with in similar ways to their interaction with the input item. In this particular case the item is a movie. "
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"The cells below will handle getting recommendations from the \"More like X\" Recommender and rendering the results. Let's see what the recommendations are for the first item we looked at earlier in this notebook (Terminator 2: Judgment Day).\n",
"\n",
"We will be using the `recommenderArn`, the `itemId`, the `userId` as well as the number or results we want, `numResults`."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# First pick a user\n",
"testUserId = \"1\""
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"get_recommendations_response = personalize_runtime.get_recommendations(\n",
" recommenderArn = recommender_more_like_x_arn,\n",
" itemId = str(589),\n",
" userId = testUserId,\n",
" numResults = 20\n",
")"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"itemList = get_recommendations_response['itemList']\n",
"for item in itemList:\n",
" print(get_movie_by_id(movieId=item['itemId']))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Congrats, this is your first list of recommendations! This list is fine, but it would be better to see the recommendations for similar movies render in a nice dataframe. Again, let's create a helper function to achieve this."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Update DF rendering\n",
"pd.set_option('display.max_rows', 30)\n",
"\n",
"def get_new_recommendations_df(recommendations_df, movie_id, user_id):\n",
" # Get the movie name\n",
" movie_name = get_movie_by_id(movie_id)\n",
" # Get the recommendations\n",
" get_recommendations_response = personalize_runtime.get_recommendations(\n",
" recommenderArn = recommender_more_like_x_arn,\n",
" itemId = str(movie_id),\n",
" userId = user_id\n",
" )\n",
" # Build a new dataframe of recommendations\n",
" itemList = get_recommendations_response['itemList']\n",
" recommendationList = []\n",
" for item in itemList:\n",
" movie = get_movie_by_id(item['itemId'])\n",
" recommendation_list.append(movie)\n",
" new_rec_df = pd.DataFrame(recommendation_list, columns = [movie_name])\n",
" # Add this dataframe to the old one\n",
" recommendations_df = pd.concat([recommendations_df, new_rec_df], axis=1)\n",
" return recommendations_df"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Now, let's test the helper function with several different movies. Let's sample some data from our dataset to test our \"More like X\" Recommender. Grab 5 random movies from our dataframe.\n",
"\n",
"Note: We are going to show similar titles, so you may want to re-run the sample until you recognize some of the movies listed"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"samples = items_df.sample(5)\n",
"samples"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"more_like_x_recommendations_df = pd.DataFrame()\n",
"movies = samples.index.tolist()\n",
"\n",
"for movie in movies:\n",
" more_like_x_recommendations_df = get_new_recommendations_df(more_like_x_recommendations_df, movie, testUserId)\n",
"\n",
"more_like_x_recommendations_df"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"You may notice that some of the items look the same, hopefully not all of them do (this is more likely with a smaller # of interactions, which will be more common with the movielens small dataset). "
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### \"Top picks for you\" Recommender\n",
"\n",
"\"Top picks for you\" supports personalization of the items for a specific user based on their past behavior and can intake real time events in order to alter recommendations for a user without retraining. \n",
"\n",
"Since \"Top picks for you\" relies on having a sampling of users, let's load the data we need for that and select 3 random users. Since Movielens does not include user data, we will select 3 random numbers from the range of user id's in the dataset."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"if not USE_FULL_MOVIELENS:\n",
" users = random.sample(range(1, 600), 3)\n",
"else:\n",
" users = random.sample(range(1, 162000), 3)\n",
"users"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Now we render the recommendations for our 3 random users from above. After that, we will explore real-time interactions before moving on to Personalized Ranking.\n",
"\n",
"\"Top picks for you\" requires only a user as input, and it will return items that are relevant for that particular user. In this particular case the item is a movie.\n",
"\n",
"The cells below will handle getting recommendations from the \"Top picks for you\" Recommender and rendering the results. \n",
"\n",
"We will be using the `recommenderArn`, the `userId` as well as the number or results we want, `numResults`.\n",
"\n",
"Again, we create a helper function to render the results in a nice dataframe.\n",
"\n",
"#### API call results"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Update DF rendering\n",
"pd.set_option('display.max_rows', 30)\n",
"\n",
"def get_new_recommendations_df_users(recommendations_df, user_id):\n",
" # Get the movie name\n",
" #movie_name = get_movie_by_id(artist_ID)\n",
" # Get the recommendations\n",
" get_recommendations_response = personalize_runtime.get_recommendations(\n",
" recommenderArn = recommender_top_picks_arn,\n",
" userId = str(user_id),\n",
" numResults = 20\n",
" )\n",
" # Build a new dataframe of recommendations\n",
" itemList = get_recommendations_response['itemList']\n",
" recommendation_list = []\n",
" for item in itemList:\n",
" movie = get_movie_by_id(item['itemId'])\n",
" recommendation_list.append(movie)\n",
" new_rec_df = pd.DataFrame(recommendation_list, columns = [user_id])\n",
" # Add this dataframe to the old one\n",
" recommendations_df = pd.concat([recommendations_df, new_rec_df], axis=1)\n",
" return recommendations_df"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"recommendations_df_users = pd.DataFrame()\n",
"\n",
"for user in users:\n",
" recommendations_df_users = get_new_recommendations_df_users(recommendations_df_users, user)\n",
"\n",
"recommendations_df_users"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Here we clearly see that the recommendations for each user are different. If you were to need a cache for these results, you could start by running the API calls through all your users and store the results, or you could use a batch export, which will be covered later in this notebook."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Interact with Campaigns \n",
"[Back to top](#top)\n",
"\n",
"Now that the reranking campaign is deployed and active, we can start to get recommendations via an API call. "
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Personalized Ranking\n",
"\n",
"The core use case for personalized ranking is to take a collection of items and to render them in priority or probable order of interest for a user. For a VOD application you want dynamically render a personalized shelf/rail/carousel based on some information (director, location, superhero franchise, movie time period, etc...). This may not be information that you have in your metadata, so an item metadata filter will not work, however you may have this information within you system to generate the item list. \n",
"\n",
"To demonstrate this, we will use the same user from before and a random collection of items."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"rerank_user = user\n",
"rerank_items = items_df.sample(25).index.tolist()"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Now build a nice dataframe that shows the input data."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"rerank_list = []\n",
"for item in rerank_items:\n",
" movie = get_movie_by_id(item)\n",
" rerank_list.append(movie)\n",
"rerank_df = pd.DataFrame(rerank_list, columns = ['Un-Ranked'])\n",
"rerank_df"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Then make the personalized ranking API call."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"rerank_item_list = []\n",
"for item in rerank_items:\n",
" rerank_item_list.append(str(item))\n",
" \n",
"# Get recommended reranking\n",
"get_recommendations_response_rerank = personalize_runtime.get_personalized_ranking(\n",
" campaignArn = rerank_campaign_arn,\n",
" userId = str(rerank_user),\n",
" inputList = rerank_item_list\n",
")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Now add the reranked items as a second column to the original dataframe, for a side-by-side comparison."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"ranked_list = []\n",
"item_list = get_recommendations_response_rerank['personalizedRanking']\n",
"for item in item_list:\n",
" movie = get_movie_by_id(item['itemId'])\n",
" ranked_list.append(movie)\n",
"ranked_df = pd.DataFrame(ranked_list, columns = ['Re-Ranked'])\n",
"rerank_df = pd.concat([rerank_df, ranked_df], axis=1)\n",
"rerank_df"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"You can see above how each entry was re-ordered based on the model's understanding of the user. This is a popular task when you have a collection of items to surface a user, a list of promotions for example."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Using Static and Dynamic Filters \n",
"[Back to top](#top)\n",
"\n",
"Lets interact with the static filters we created in the previous notebook, and utilize dynamic filters in realtime.\n",
"\n",
"A few common use cases for dynamic filters in Video On Demand are:\n",
"\n",
"Categorical filters based on Item Metadata (that arent range based) - Often your item metadata will have information about the title such as Genre, Keyword, Year, Director, Actor etc. Filtering on these can provide recommendations within that data, such as action movies, Steven Spielberg movies, Movies from 1995 etc.\n",
"\n",
"Events - you may want to filter out certain events and provide results based on those events, such as moving a title from a \"suggestions to watch\" recommendation to a \"watch again\" recommendations."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Now lets apply item filters to see recommendations for one of these users within each decade of our static filters.\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"def get_new_recommendations_df_by_static_filter(recommendations_df, user_id, filter_arn):\n",
" # Get the recommendations\n",
" get_recommendations_response = personalize_runtime.get_recommendations(\n",
" recommenderArn = recommender_top_picks_arn,\n",
" userId = str(user_id),\n",
" filterArn = filter_arn\n",
" )\n",
" # Build a new dataframe of recommendations\n",
" item_list = get_recommendations_response['itemList']\n",
" recommendation_list = []\n",
" for item in item_list:\n",
" movie = get_movie_by_id(item['itemId'])\n",
" recommendation_list.append(movie)\n",
" #print(recommendation_list)\n",
" filter_name = filter_arn.split('/')[1]\n",
" new_rec_DF = pd.DataFrame(recommendation_list, columns = [filter_name])\n",
" # Add this dataframe to the old one\n",
" recommendations_df = pd.concat([recommendations_df, new_rec_DF], axis=1)\n",
" return recommendations_df"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"def get_new_recommendations_df_by_dynamic_filter(recommendations_df, user_id, genre_filter_arn, filter_values):\n",
" # Get the recommendations\n",
" get_recommendations_response = personalize_runtime.get_recommendations(\n",
" recommenderArn = recommender_top_picks_arn,\n",
" userId = str(user_id),\n",
" filterArn = genre_filter_arn,\n",
" filterValues = { \"GENRE\": \"\\\"\" + filter_values + \"\\\"\"}\n",
" )\n",
" # Build a new dataframe of recommendations\n",
" item_list = get_recommendations_response['itemList']\n",
" recommendation_list = []\n",
" for item in item_list:\n",
" movie = get_movie_by_id(item['itemId'])\n",
" recommendation_list.append(movie)\n",
" filter_name = genre_filter_arn.split('/')[1]\n",
" new_rec_DF = pd.DataFrame(recommendation_list, columns = [filter_values])\n",
" # Add this dataframe to the old one\n",
" recommendations_df = pd.concat([recommendations_df, new_rec_DF], axis=1)\n",
" return recommendations_df"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"You can see the recommendations for movies within a given decade. Within a VOD application you could create Shelves (also known as rails or carousels) easily by using these filters. Depending on the information you have about your items, You could also filter on additional information such as keyword, year/decade etc."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"recommendations_df_decade_shelves = pd.DataFrame()\n",
"for filter_arn in meta_filter_decade_arns:\n",
" recommendations_df_decade_shelves = get_new_recommendations_df_by_static_filter(recommendations_df_decade_shelves, user, filter_arn)\n",
"\n",
"recommendations_df_decade_shelves"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Create a dataframe for the items by reading in the correct source CSV\n",
"items_meta_df = pd.read_csv(data_dir + '/item-meta.csv', sep=',', index_col=0)\n",
"\n",
"# Render some sample data\n",
"items_meta_df.head(10)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Now what we want to do is determine the genres to filter on, for that we need a list of all genres. First we will get all the unique values of the column GENRE, then split strings on | if they exist, everyone will then get added to a long list which will be converted to a set for efficiency. That set will then be made into a list so that it can be iterated, and we can then use the get recommendatioins API."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"unique_genre_field_values = items_meta_df['GENRES'].unique()\n",
"\n",
"genre_val_list = []\n",
"\n",
"def process_for_bar_char(val, val_list):\n",
" if '|' in val:\n",
" values = val.split('|')\n",
" for item in values:\n",
" val_list.append(item)\n",
" elif '(' in val:\n",
" pass\n",
" else:\n",
" val_list.append(val)\n",
" return val_list\n",
" \n",
"\n",
"for val in unique_genre_field_values:\n",
" genre_val_list = process_for_bar_char(val, genre_val_list)\n",
"\n",
"genres_to_filter = list(set(genre_val_list))"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"genres_to_filter"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Iterate through Genres\n",
"recommendations_df_genre_shelves = pd.DataFrame()\n",
"for genre in genres_to_filter:\n",
" recommendations_df_genre_shelves = get_new_recommendations_df_by_dynamic_filter(recommendations_df_genre_shelves, user, genre_filter_arn , genre)\n",
" \n",
"recommendations_df_genre_shelves"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Real-time Events\n",
"[Back to top](#top)\n",
"\n",
"The next topic is real-time events. Personalize has the ability to listen to events from your application in order to update the recommendations shown to the user. This is especially useful in media workloads, like video-on-demand, where a customer's intent may differ based on if they are watching with their children or on their own.\n",
"\n",
"Additionally the events that are recorded via this system are stored until a delete call from you is issued, and they are used as historical data alongside the other interaction data you provided when you train your next models.\n",
"\n",
"Start by creating an event tracker that is attached to the dataset group. This event tracker will add information to the dataset and will influence the recommendations."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"response = personalize.create_event_tracker(\n",
" name='MovieTracker',\n",
" datasetGroupArn=dataset_group_arn\n",
")\n",
"print(response['eventTrackerArn'])\n",
"print(response['trackingId'])\n",
"trackingId = response['trackingId']\n",
"event_tracker_arn = response['eventTrackerArn']"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"We will create some code that simulates a user interacting with a particular item. After running this code, you will get recommendations that differ from the results above.\n",
"\n",
"We start by creating some methods for the simulation of real time events."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"sessionDict = {}\n",
"\n",
"def send_movie_click(userId, itemId, eventType):\n",
" \"\"\"\n",
" Simulates a click as an envent\n",
" to send an event to Amazon Personalize's Event Tracker\n",
" \"\"\"\n",
" # Configure Session\n",
" try:\n",
" sessionId = sessionDict[str(userId)]\n",
" except:\n",
" sessionDict[str(userId)] = str(uuid.uuid1())\n",
" sessionId = sessionDict[str(userId)]\n",
" \n",
" # Configure Properties:\n",
" event = {\n",
" \"itemId\": str(itemId),\n",
" }\n",
" event_json = json.dumps(event)\n",
" \n",
" # Make Call\n",
" \n",
" personalize_events.put_events(\n",
" trackingId = trackingId,\n",
" userId= str(userId),\n",
" sessionId = sessionId,\n",
" eventList = [{\n",
" 'sentAt': int(time.time()),\n",
" 'eventType': str(eventType),\n",
" 'properties': event_json\n",
" }]\n",
" )\n",
"\n",
"def get_new_recommendations_df_users_real_time(recommendations_df, userId, itemId, eventType):\n",
" # Get the artist name (header of column)\n",
" movieName = get_movie_by_id(itemId)\n",
" \n",
" # Interact with different movies\n",
" print('sending event ' + eventType + ' for ' + get_movie_by_id(itemId))\n",
" send_movie_click(userId=userId, itemId=itemId,eventType=eventType)\n",
" # Get the recommendations (note you should have a base recommendation DF created before)\n",
" get_recommendations_response = personalize_runtime.get_recommendations(\n",
" recommenderArn = recommender_top_picks_arn,\n",
" userId = str(userId),\n",
" )\n",
" # Build a new dataframe of recommendations\n",
" itemList = get_recommendations_response['itemList']\n",
" recommendation_list = []\n",
" for item in itemList:\n",
" artist = get_movie_by_id(item['itemId'])\n",
" recommendation_list.append(artist)\n",
" new_rec_df = pd.DataFrame(recommendation_list, columns = [movieName])\n",
" # Add this dataframe to the old one\n",
" #recommendations_df = recommendations_df.join(new_rec_DF)\n",
" recommendations_df = pd.concat([recommendations_df, new_rec_df], axis=1)\n",
" return recommendations_df"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"At this point, we haven't generated any real-time events yet; we have only set up the code. To compare the recommendations before and after the real-time events, let's pick one user and generate the original recommendations for them."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Get recommendations for the user\n",
"get_recommendations_response = personalize_runtime.get_recommendations(\n",
" recommenderArn = recommender_top_picks_arn,\n",
" userId = str(rerank_user),\n",
" )\n",
"\n",
"# Build a new dataframe for the recommendations\n",
"itemList = get_recommendations_response['itemList']\n",
"recommendationList = []\n",
"for item in item_list:\n",
" artist = get_movie_by_id(item['itemId'])\n",
" recommendationList.append(artist)\n",
"user_recommendations_df = pd.DataFrame(recommendationList, columns = [rerank_user])\n",
"user_recommendations_df"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Ok, so now we have a list of recommendations for this user before we have applied any real-time events. Now let's pick 3 random artists which we will simulate our user interacting with, and then see how this changes the recommendations."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Next generate 3 random movies\n",
"movies = items_df.sample(3).index.tolist()"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Note this will take about 15 seconds to complete due to the sleeps\n",
"for movie in movies:\n",
" user_recommendations_df = get_new_recommendations_df_users_real_time(user_recommendations_df, rerank_user, movie,'click')\n",
" time.sleep(5)\n",
" "
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Now we can look at how the click events changed the recommendations."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"user_recommendations_df"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"In the cell above, the first column after the index is the user's default recommendations from the \"Top pics for you\" recommender, and each column after that has as a header of the movie that they interacted with via a real time event, and the recommendations after this event occurred. \n",
"\n",
"The behavior may not shift very much or a lot; this is due to the relatively limited nature of this dataset and effect of a few random clicks. If you wanted to better understand this, try simulating clicking more movies to see the impact."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Now lets look at the event filters, which allow you to filter items based on the interaction data. For this dataset, it could be click or watch based on the data we imported, but could be based on whatever interaction schema you design (click, rate, like, watch, purchase etc.) \n",
"\n",
"We will create a new helper function to use the personalized ranking campaign, sice the Recommenders already filter out watched content."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"def get_new_ranked_recommendations_df_by_static_filter(recommendations_df, user_id, rerank_item_list, filter_arn):\n",
" \n",
" # Get the recommendations\n",
" get_recommendations_response = personalize_runtime.get_personalized_ranking(\n",
" campaignArn = rerank_campaign_arn,\n",
" userId = str(user_id),\n",
" inputList = rerank_item_list,\n",
" filterArn = filter_arn\n",
" )\n",
" # Build a new dataframe of recommendations\n",
" item_list = get_recommendations_response['personalizedRanking']\n",
" recommendation_list = []\n",
" for item in item_list:\n",
" movie = get_movie_by_id(item['itemId'])\n",
" recommendation_list.append(movie)\n",
"\n",
" filter_name = filter_arn.split('/')[1]\n",
" new_rec_df = pd.DataFrame(recommendation_list, columns = [filter_name])\n",
" # Add this dataframe to the old one\n",
" recommendations_df = pd.concat([recommendations_df, new_rec_df], axis=1)\n",
" return recommendations_df"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"recommendations_df_events = pd.DataFrame()\n",
"for filter_arn in interaction_filter_arns:\n",
" recommendations_df_events = get_new_ranked_recommendations_df_by_static_filter(recommendations_df_events, rerank_user, rerank_item_list, filter_arn)\n",
" \n",
"recommendations_df_events"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Now lets send a watch event in for the top 4 unwatched recommendations, which would simulate watching 4 movies. In a VOD application, you may choose to send in an event after they have watched a significant amount (over 75%) of a piece of content. Sending at 100% complete could miss people that stop short of the credits."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"ranked_unwatched_recommendations_response = personalize_runtime.get_personalized_ranking(\n",
" campaignArn = rerank_campaign_arn,\n",
" userId = str(rerank_user),\n",
" inputList = rerank_item_list,\n",
" filterArn = filter_arn)\n",
"\n",
"item_list = ranked_unwatched_recommendations_response['personalizedRanking'][:4]\n",
"\n",
"for item in item_list:\n",
" print('sending event watch for ' + get_movie_by_id(item['itemId']))\n",
" send_movie_click(userId=rerank_user, itemId=item['itemId'], eventType='Watch')\n",
" time.sleep(10)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Now we can look at the event filters to see the updated watched and unwatched recommendations "
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"recommendations_df_events = pd.DataFrame()\n",
"for filter_arn in interaction_filter_arns:\n",
" recommendations_df_events = get_new_ranked_recommendations_df_by_static_filter(recommendations_df_events, rerank_user, rerank_item_list, filter_arn)\n",
"recommendations_df_events"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Batch Recommendations \n",
"[Back to top](#top)\n",
"\n",
"There are many cases where you may want to have a larger dataset of exported recommendations. Amazon Personalize launched batch recommendations as a way to export a collection of recommendations to S3. In this example, we will walk through how to do this for the Personalized Ranking solution. For more information about batch recommendations, please see the [documentation](https://docs.aws.amazon.com/personalize/latest/dg/recommendations-batch.html). This feature applies to all recipes, but the output format will vary.\n",
"\n",
"A simple implementation looks like this:\n",
"\n",
"```python\n",
"import boto3\n",
"\n",
"personalize_rec = boto3.client(service_name='personalize')\n",
"\n",
"personalize_rec.create_batch_inference_job (\n",
" solutionVersionArn = \"Solution version ARN\",\n",
" jobName = \"Batch job name\",\n",
" roleArn = \"IAM role ARN\",\n",
" jobInput = \n",
" {\"s3DataSource\": {\"path\": }},\n",
" jobOutput = \n",
" {\"s3DataDestination\": {\"path\": }}\n",
")\n",
"```\n",
"\n",
"The SDK import, the solution version arn, and role arns have all been determined. This just leaves an input, an output, and a job name to be defined.\n",
"\n",
"Starting with the input for Personalized Ranking, it looks like:\n",
"\n",
"\n",
"```JSON\n",
"{\"userId\": \"891\", \"itemList\": [\"27\", \"886\", \"101\"]}\n",
"{\"userId\": \"445\", \"itemList\": [\"527\", \"55\", \"901\"]}\n",
"{\"userId\": \"71\", \"itemList\": [\"27\", \"351\", \"101\"]}\n",
"```\n",
"\n",
"This should yield an output that looks like this:\n",
"\n",
"```JSON\n",
"{\"input\":{\"userId\":\"891\",\"itemList\":[\"27\",\"886\",\"101\"]},\"output\":{\"recommendedItems\":[\"27\",\"101\",\"886\"],\"scores\":[0.48421,0.28133,0.23446]}}\n",
"{\"input\":{\"userId\":\"445\",\"itemList\":[\"527\",\"55\",\"901\"]},\"output\":{\"recommendedItems\":[\"901\",\"527\",\"55\"],\"scores\":[0.46972,0.31011,0.22017]}}\n",
"{\"input\":{\"userId\":\"71\",\"itemList\":[\"29\",\"351\",\"199\"]},\"output\":{\"recommendedItems\":[\"351\",\"29\",\"199\"],\"scores\":[0.68937,0.24829,0.06232]}}\n",
"\n",
"```\n",
"\n",
"The output is a JSON Lines file. It consists of individual JSON objects, one per line. So we will need to put in more work later to digest the results in this format."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Building the input file\n",
"\n",
"When you are using the batch feature, you specify the users that you'd like to receive recommendations for when the job has completed. The cell below will again select a few random users and will then build the file and save it to disk. From there, you will upload it to S3 to use in the API call later."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# We will use the same users from before\n",
"print (users)\n",
"# Write the file to disk\n",
"json_input_filename = \"json_input.json\"\n",
"with open(data_dir + \"/\" + json_input_filename, 'w') as json_input:\n",
" for user_id in users:\n",
" json_input.write('{\"userId\": \"' + str(user_id) + '\", \"itemList\":'+json.dumps(rerank_item_list)+'}\\n')"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Showcase the input file:\n",
"!cat $data_dir\"/\"$json_input_filename"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Upload the file to S3 and save the path as a variable for later."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Upload files to S3\n",
"boto3.Session().resource('s3').Bucket(bucket_name).Object(json_input_filename).upload_file(data_dir+\"/\"+json_input_filename)\n",
"s3_input_path = \"s3://\" + bucket_name + \"/\" + json_input_filename\n",
"print(s3_input_path)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Batch recommendations read the input from the file we've uploaded to S3. Similarly, batch recommendations will save the output to file in S3. So we define the output path where the results should be saved."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Define the output path\n",
"s3_output_path = \"s3://\" + bucket_name + \"/\"\n",
"print(s3_output_path)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Now just make the call to kick off the batch export process."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"batchInferenceJobArn = personalize.create_batch_inference_job (\n",
" solutionVersionArn = rerank_solution_version_arn,\n",
" jobName = \"VOD-POC-Batch-Inference-Job-PersonalizedRanking_\" + str(round(time.time()*1000)),\n",
" roleArn = role_arn,\n",
" jobInput = \n",
" {\"s3DataSource\": {\"path\": s3_input_path}},\n",
" jobOutput = \n",
" {\"s3DataDestination\":{\"path\": s3_output_path}}\n",
")\n",
"batchInferenceJobArn = batchInferenceJobArn['batchInferenceJobArn']"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Run the while loop below to track the status of the batch recommendation call. This can take around 30 minutes to complete, because Personalize needs to stand up the infrastructure to perform the task. We are testing the feature with a dataset of only 3 users, which is not an efficient use of this mechanism. Normally, you would only use this feature for bulk processing, in which case the efficiencies will become clear."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"current_time = datetime.now()\n",
"print(\"Import Started on: \", current_time.strftime(\"%I:%M:%S %p\"))\n",
"\n",
"max_time = time.time() + 6*60*60 # 6 hours\n",
"while time.time() < max_time:\n",
" describe_dataset_inference_job_response = personalize.describe_batch_inference_job(\n",
" batchInferenceJobArn = batchInferenceJobArn\n",
" )\n",
" status = describe_dataset_inference_job_response[\"batchInferenceJob\"]['status']\n",
" print(\"DatasetInferenceJob: {}\".format(status))\n",
" \n",
" if status == \"ACTIVE\" or status == \"CREATE FAILED\":\n",
" break\n",
" \n",
" time.sleep(60)\n",
" \n",
"current_time = datetime.now()\n",
"print(\"Import Completed on: \", current_time.strftime(\"%I:%M:%S %p\"))"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"s3 = boto3.client('s3')\n",
"export_name = json_input_filename + \".out\"\n",
"s3.download_file(bucket_name, export_name, data_dir+\"/\"+export_name)\n",
"\n",
"# Update DF rendering\n",
"pd.set_option('display.max_rows', 30)\n",
"with open(data_dir+\"/\"+export_name) as json_file:\n",
" # Get the first line and parse it\n",
" line = json.loads(json_file.readline())\n",
" # Do the same for the other lines\n",
" while line:\n",
" # extract the user ID \n",
" col_header = \"User: \" + line['input']['userId']\n",
" # Create a list for all the artists\n",
" recommendation_list = []\n",
" # Add all the entries\n",
" for item in line['output']['recommendedItems']:\n",
" movie = get_movie_by_id(item)\n",
" recommendation_list.append(movie)\n",
" if 'bulk_recommendations_df' in locals():\n",
" new_rec_DF = pd.DataFrame(recommendation_list, columns = [col_header])\n",
" bulk_recommendations_df = bulk_recommendations_df.join(new_rec_DF)\n",
" else:\n",
" bulk_recommendations_df = pd.DataFrame(recommendation_list, columns=[col_header])\n",
" try:\n",
" line = json.loads(json_file.readline())\n",
" except:\n",
" line = None\n",
"bulk_recommendations_df"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Wrap up \n",
"[Back to top](#top)\n",
"\n",
"With that you now have a fully working collection of models to tackle various recommendation and personalization scenarios, as well as the skills to manipulate customer data to better integrate with the service, and a knowledge of how to do all this over APIs and by leveraging open source data science tools.\n",
"\n",
"Use these notebooks as a guide to getting started with your customers for POCs. As you find missing components, or discover new approaches, make a pull request and provide any additional helpful components that may be missing from this collection.\n",
"\n",
"You can choose to head to `04_Operations_Layer.ipynb` to go deeper into ML Ops and what a production solution can look like with an automation pipeline.\n",
"\n",
"You'll want to make sure that you clean up all of the resources deployed during this POC. We have provided a separate notebook which shows you how to identify and delete the resources in `05_Clean_Up.ipynb`."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"%store event_tracker_arn\n",
"%store batchInferenceJobArn"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": []
}
],
"metadata": {
"kernelspec": {
"display_name": "conda_python3",
"language": "python",
"name": "conda_python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.6.13"
}
},
"nbformat": 4,
"nbformat_minor": 4
}