{
"cells": [
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Interacting with Recommenders and Campaigns \n",
"\n",
"In this notebook, you will deploy and interact with campaigns in Amazon Personalize.\n",
"\n",
"1. [Introduction](#intro)\n",
"1. [Interact with Recommenders](#interact-recommenders)\n",
"1. [Interact with Campaigns](#interact-campaigns)\n",
"1. [Event Tracking - Keeping up with Evolving User Intent](#event-tracking)\n",
"1. [Real-time Events](#real-time)\n",
"1. [Category Filter](#filter)\n",
"1. [Batch Recommendations](#batch)\n",
"1. [Wrap up](#wrapup)\n",
"\n",
"## Introduction \n",
"[Back to top](#top)\n",
"\n",
"At this point, you should have 2 Recommenders and one deployed campaign. Once they are active, there are resources for querying the recommendations, and helper functions to digest the output into something more human-readable. \n",
"\n",
"\n",
"In this Notebook we will interact with Recommenders and Campaigns and get recommendations. We will interact with filters and send live data to Amazon Personalize to see the effect on recommendations.\n",
"\n",
"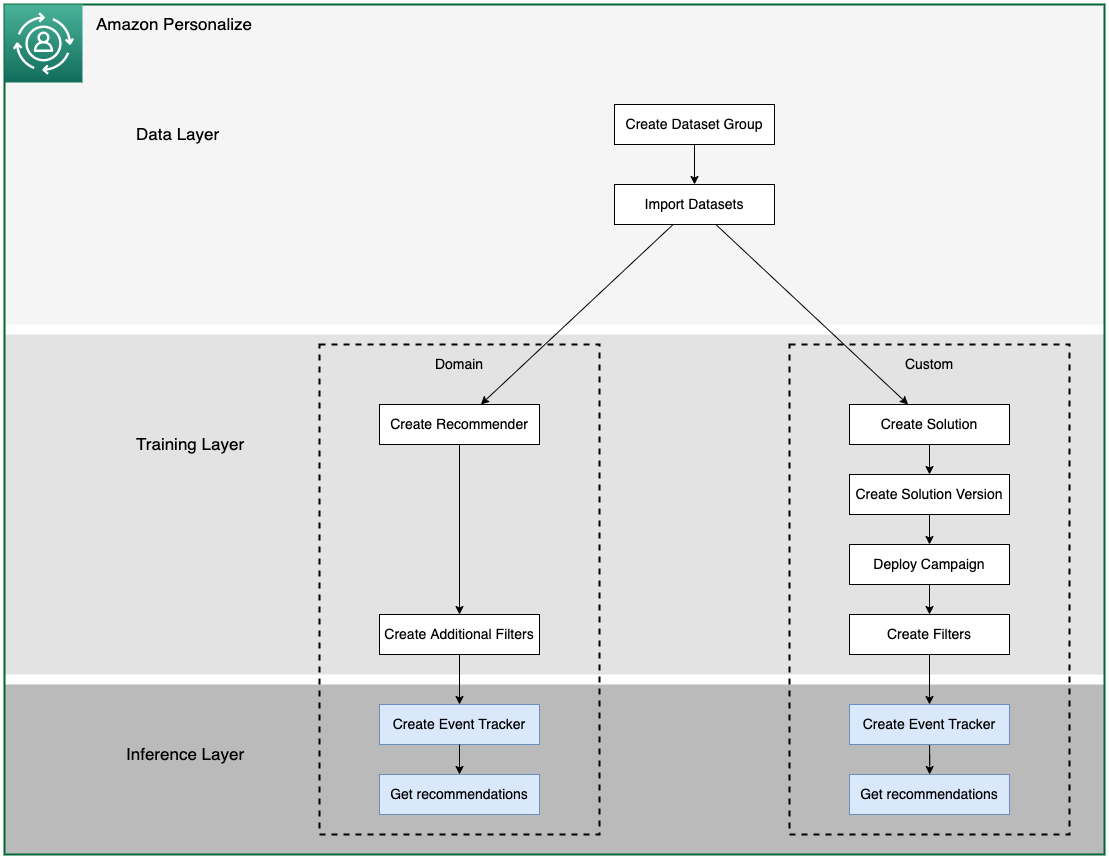\n",
"\n",
"To run this notebook, you need to have run the previous notebooks, `01_Data_Layer.ipynb`, and `02_Training_Layer.ipynb`, where you created a dataset and imported interaction, item, and user metadata data into Amazon Personalize, created recommenders, solutions and campaigns. At the end of that notebook, you saved some of the variable values, which you now need to load into this notebook.\n",
"\n",
"As you work with your customer on Amazon Personalize, you can modify the helper functions to fit the structure of their data input files to keep the additional rendering working.\n",
"\n",
"To get started, once again, we need to import libraries, load values from previous notebooks, and load the SDK."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"import time\n",
"from time import sleep\n",
"import json\n",
"from datetime import datetime\n",
"import uuid\n",
"import random\n",
"import boto3\n",
"import pandas as pd"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"#retrieves previously stored variables \n",
"%store -r "
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"personalize = boto3.client('personalize')\n",
"personalize_runtime = boto3.client('personalize-runtime')\n",
"\n",
"# Establish a connection to Personalize's event streaming\n",
"personalize_events = boto3.client(service_name='personalize-events')"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Adding some helper functions to make results more readable"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"def get_item_name_from_id ( item_id ):\n",
" item_name = item_metadata_df [item_metadata_df ['id'] == item_id]['name'].values[0]\n",
" return item_name"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"def get_item_category_from_id ( item_id ):\n",
" item_name = item_metadata_df [item_metadata_df ['id'] == item_id]['category'].values[0]\n",
" return item_name"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"def get_item_style_from_id ( item_id ):\n",
" item_name = item_metadata_df [item_metadata_df ['id'] == item_id]['style'].values[0]\n",
" return item_name"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Interact with Recommenders \n",
"[Back to top](#top)\n",
"\n",
"Now that the recommenders have been trained, lets have a look at the recommendations we can get for our users!"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### \"Customers who viewed X also viewed\" Recommender\n",
"\n",
"\"Customers who viewed X also viewed\" requires an item and a user as input, and it will return customers also viewed based on an item that you specify.\n",
"\n",
"The cells below will handle getting recommendations from the \"Customers who viewed X also viewed\" Recommender and rendering the results. Let's see what the recommendations are for an item.\n",
"\n",
"We will be using the `recommenderArn`, the `itemId`, the `userId`, as well as the number or results we want, `numResults`."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Select a User\n",
"\n",
"We'll just pick a random user for simplicity (there are about 6,000 users with user IDs assigned in sequential order). Feel free to change the `user_id` below and execute the following cells with a different user to get a sense for how the recommendations change."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"user_id = 555\n",
"user_metadata_df[user_metadata_df['id']==user_id]"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"We'll just pick a random product for simplicity. Feel free to change the `product_id` below and execute the following cells with a different product to get a sense for how the recommendations change."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"product_id = item_metadata_df.sample(1)[\"id\"].values[0]\n",
"\n",
"print ('productId: ', product_id)\n",
"\n",
"get_recommendations_response = personalize_runtime.get_recommendations(\n",
" recommenderArn = viewed_x_also_viewed_arn,\n",
" itemId = str(product_id),\n",
" userId = str(user_id),\n",
" numResults = 40\n",
")\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"item_list = get_recommendations_response['itemList']\n",
"\n",
"df = pd.DataFrame()\n",
"df['Item'] = [ itm['itemId'] for itm in item_list ]\n",
"df['Name'] = [ get_item_name_from_id ( itm['itemId']) for itm in item_list ]\n",
"df['Category'] = [ get_item_category_from_id ( itm['itemId']) for itm in item_list ]\n",
"df['Style'] = [ get_item_style_from_id ( itm['itemId']) for itm in item_list ]\n",
"display (df)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Congrats, this is your first list of recommendations! This list is fine, but it would be better to see the recommendations for similar movies render in a nice dataframe. Again, let's create a helper function to achieve this."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Update DF rendering\n",
"pd.set_option('display.max_rows', 30)\n",
"\n",
"def get_new_recommendations_df_viewed_x(recommendations_df, item_id, user_id):\n",
" # Get the item name\n",
" original_item_name = get_item_name_from_id(item_id)\n",
" # Get the recommendations\n",
" get_recommendations_response = personalize_runtime.get_recommendations(\n",
" recommenderArn = viewed_x_also_viewed_arn,\n",
" itemId = str(item_id),\n",
" userId = str(user_id),\n",
" )\n",
" # Build a new dataframe of recommendations\n",
" item_list = get_recommendations_response['itemList']\n",
" recommendation_list = []\n",
" for item in item_list:\n",
" item_name = get_item_name_from_id(item['itemId'])\n",
" recommendation_list.append(item_name)\n",
" new_rec_df = pd.DataFrame(recommendation_list, columns = [original_item_name])\n",
" # Add this dataframe to the old one\n",
" recommendations_df = pd.concat([recommendations_df, new_rec_df], axis=1)\n",
" return recommendations_df"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Now, let's test the helper function with several different items. Let's sample some data from our dataset to test our \"Customers who viewed X also viewed\" Recommender. Grab 5 random items from our dataframe."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"samples = item_metadata_df.sample(5)\n",
"samples"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"scrolled": true
},
"outputs": [],
"source": [
"viewed_x_also_viewed_recommendations_df = pd.DataFrame()\n",
"items = samples.id.tolist()\n",
"\n",
"for item in items:\n",
" viewed_x_also_viewed_recommendations_df = get_new_recommendations_df_viewed_x(viewed_x_also_viewed_recommendations_df, item, user_id)\n",
"\n",
"viewed_x_also_viewed_recommendations_df"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Based on the random product selected above, do the similar item recommendations from Personalize make sense? Keep in mind that the \"Customers who viewed X also viewed\" recommendations are based on the interactions we generated as input into the solution creation process above.\n",
"\n",
"You may notice that some of the items look the same, hopefully not all of them do (this is more likely with a smaller # of interactions, which will be more common with a small dataset)."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### \"Recommended for you\" Recommender\n",
"\n",
"\"Recommended for you\" supports personalization of the items for a specific user based on their past behavior and can intake real time events in order to alter recommendations for a user without retraining. \n",
"\n",
"With this use case, Amazon Personalize automatically filters items the user purchased based on the `userId` that you specify and \"Purchase\" events. For better performance, include \"Purchase\" events along with the required \"View\" events. "
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"get_recommendations_response = personalize_runtime.get_recommendations(\n",
" recommenderArn = recommended_for_you_arn,\n",
" userId = str(user_id),\n",
" numResults = 20\n",
")"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"item_list = get_recommendations_response['itemList']\n",
"\n",
"df = pd.DataFrame()\n",
"df['Item'] = [ itm['itemId'] for itm in item_list ]\n",
"df['Name'] = [ get_item_name_from_id ( itm['itemId']) for itm in item_list ]\n",
"df['Category'] = [ get_item_category_from_id ( itm['itemId']) for itm in item_list ]\n",
"df['Style'] = [ get_item_style_from_id ( itm['itemId']) for itm in item_list ]\n",
"display (df)\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Since \"Recommended for you\" relies on having a sampling of users, let's load the data we need for that and select 3 random users."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"samples = user_metadata_df.sample(3)\n",
"samples"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Now we render the recommendations for our 3 random users from above. After that, we will explore real-time interactions before moving on to Personalized Ranking.\n",
"\n",
"\"Recommended for you\" requires only a user as input, and it will return items that are relevant for that particular user. In this particular case the item is a product.\n",
"\n",
"The cells below will handle getting recommendations from the \"Recommended for you\" Recommender and rendering the results. \n",
"\n",
"We will be using the `recommenderArn`, the `userId` as well as the number or results we want, `numResults`.\n",
"\n",
"Again, we create a helper function to render the results in a nice dataframe.\n",
"\n",
"#### API call results"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Update DF rendering\n",
"pd.set_option('display.max_rows', 30)\n",
"\n",
"def get_new_recommendations_df_recommended_for_you(recommendations_df, user_id):\n",
" # Get the recommendations\n",
" get_recommendations_response = personalize_runtime.get_recommendations(\n",
" recommenderArn = recommended_for_you_arn,\n",
" userId = str(user_id),\n",
" )\n",
" # Build a new dataframe of recommendations\n",
" item_list = get_recommendations_response['itemList']\n",
" recommendation_list = []\n",
" for item in item_list:\n",
" item_name = get_item_name_from_id(item['itemId'])\n",
" recommendation_list.append(item_name)\n",
" new_rec_df = pd.DataFrame(recommendation_list, columns = [user_id])\n",
" # Add this dataframe to the old one\n",
" recommendations_df = pd.concat([recommendations_df, new_rec_df], axis=1)\n",
" return recommendations_df"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"recommendations_df_users = pd.DataFrame()\n",
"users = samples.id.tolist()\n",
"\n",
"for user in users:\n",
" recommendations_df_users = get_new_recommendations_df_recommended_for_you(recommendations_df_users, user)\n",
"\n",
"recommendations_df_users"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Applying the discount context\n",
"\n",
"We'll get the user recommendations when discount context is applied for comparison. This is a using the \"contextual metadata\" feature of Amazon Personalize. In this case our context is whether a discount was applied."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"get_recommendations_response = personalize_runtime.get_recommendations(\n",
" recommenderArn = recommended_for_you_arn,\n",
" userId = str(user_id),\n",
" numResults = 20,\n",
" context = {'DISCOUNT':'Yes'} # Here we provide the context for the recommendations\n",
")\n",
"\n",
"item_list_context = get_recommendations_response['itemList']\n",
"\n",
"df = pd.DataFrame()\n",
"df['Item'] = [ itm['itemId'] for itm in item_list_context ]\n",
"df['Name'] = [ get_item_name_from_id ( itm['itemId']) for itm in item_list_context ]\n",
"df['Category'] = [ get_item_category_from_id ( itm['itemId']) for itm in item_list_context ]\n",
"df['Style'] = [ get_item_style_from_id ( itm['itemId']) for itm in item_list_context ]\n",
"display (df)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Let us compare it to the previous set of recommendations without context."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"df = pd.DataFrame()\n",
"df['Item (No context)'] = [ itm['itemId'] for itm in item_list ]\n",
"df['Name (No context)'] = [ get_item_name_from_id ( itm['itemId']) for itm in item_list ]\n",
"\n",
"df['Item (Context)'] = [ itm['itemId'] for itm in item_list_context ]\n",
"df['Name (Context)'] = [ get_item_name_from_id ( itm['itemId']) for itm in item_list_context ]\n",
"display (df)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Interact with Campaigns \n",
"[Back to top](#top)\n",
"\n",
"Now that the reranking campaign is deployed and active, we can start to get recommendations via an API call. "
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Personalized Ranking\n",
"\n",
"The core use case for personalized ranking is to take a collection of items and to render them in priority or probable order of interest for a user. For an ECOMMERCE application you want dynamically render a personalized shelf/rail/carousel based on some information (category, style, season, etc...). This may not be information that you have in your metadata, so a item metadata filter will not work, however you may have this information within you system to generate the item list. You can use this campaign to rerank the products listed for each category and the featured products list as well as reranking catalog search results displayed in a search widget.\n",
"\n",
"To demonstrate this, we will use the same user from before and a random collection of items."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Get Featured Products List\n",
"\n",
"First let's get the list of featured products from the Products data."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"featured_products = item_metadata_df[item_metadata_df['featured']==True]"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### ReRank Featured Products\n",
"\n",
"Using the featured products list just retrieved, first we'll create a list of item IDs that we want to rerank for a specific user. This reranking will allow us to provide ranked products based on the user's behavior. These behaviors should be consistent the same persona that was mentioned above (since we're going to use the same `user_id`)."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"pycharm": {
"name": "#%%\n"
}
},
"outputs": [],
"source": [
"unranked_product_ids = list (featured_products['id'])\n",
"\n",
"df = pd.DataFrame()\n",
"df['Item'] = [ itm for itm in unranked_product_ids ]\n",
"df['Name'] = [ get_item_name_from_id ( itm) for itm in unranked_product_ids ]\n",
"df['Category'] = [ get_item_category_from_id ( itm) for itm in unranked_product_ids ]\n",
"df['Style'] = [ get_item_style_from_id ( itm) for itm in unranked_product_ids ]\n",
"display (df)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Now let's have Personalize rank the featured product IDs based on our random user."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"pycharm": {
"name": "#%%\n"
}
},
"outputs": [],
"source": [
"response = personalize_runtime.get_personalized_ranking(\n",
" campaignArn=rerank_campaign_arn,\n",
" inputList=unranked_product_ids,\n",
" userId=str(user_id)\n",
")\n",
"reranked = response['personalizedRanking']\n",
"print(json.dumps(response['personalizedRanking'], indent = 4))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Notice that in this response we have a score field returned with each itemId. For all recipes except SIMS and Popularity-Count, Personalize [calculates a score](https://docs.aws.amazon.com/personalize/latest/dg/getting-real-time-recommendations.html) for each recommended item. Score values are between 0.0 and 1.0. \n",
"\n",
"Let us compare it to the original list:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"df = pd.DataFrame()\n",
"df['Original List'] = [ itm for itm in unranked_product_ids]\n",
"df['Original List Name'] = [ get_item_name_from_id ( itm) for itm in unranked_product_ids ]\n",
"\n",
"df['Reranking'] = [ itm['itemId'] for itm in reranked]\n",
"df['Reranking Name'] = [ get_item_name_from_id ( itm['itemId']) for itm in reranked ]\n",
"\n",
"display (df)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Are the reranked results different than the original results from the Search service? Notice that we are also given a score for each item but this time the score values are larger. This is because scores for personalized-ranking results are calculated just across the items being reranked. Experiment with a different `user_id` in the cells above to see how the item ranking changes."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Event Tracking - Keeping up with Evolving User Intent\n",
"[Back to top](#top)\n",
"\n",
"Up to this point we have trained and deployed three Amazon Personalize campaigns based on historical data that we generated in this workshop. This allows us to make related product, user recommendations, and rerank product lists based on already observed behavior of our users. However, user intent often changes in real-time such that what products the user is interested in now may be different than what they were interested in a week ago, a day ago, or even a few minutes ago. Making recommendations that keep up with evolving user intent is one of the more difficult challenges with personalization. Fortunately, Amazon Personalize has a mechanism for this exact issue.\n",
"\n",
"Amazon Personalize supports the ability to send real-time user events (i.e. clickstream) data into the service.\n",
"Personalize uses this event data to improve recommendations. It will also save these events and automatically\n",
"include them when solutions for the same dataset group are re-created (i.e. model retraining).\n",
"\n",
"For our sample interactions dataset we have common e-commerce events such as 'View' (product), 'AddToCart', 'Purchase', and others. These can be streamed in real-time from client applications as they occur to a Personalize Event Tracker."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Create Personalize Event Tracker\n",
"\n",
"Let's start by creating an event tracker for our dataset group."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"event_tracker_response = personalize.create_event_tracker(\n",
" datasetGroupArn=dataset_group_arn,\n",
" name='amazon-personalize-immersionday-event-tracker'\n",
")\n",
"\n",
"event_tracker_arn = event_tracker_response['eventTrackerArn']\n",
"event_tracking_id = event_tracker_response['trackingId']\n",
"\n",
"print('Event Tracker ARN: ' + event_tracker_arn)\n",
"print('Event Tracking ID: ' + event_tracking_id)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Wait for Event Tracker Status to Become ACTIVE\n",
"\n",
"The event tracker should take a minute or so to become active."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"status = None\n",
"max_time = time.time() + 60*60 # 1 hours\n",
"while time.time() < max_time:\n",
" describe_event_tracker_response = personalize.describe_event_tracker(\n",
" eventTrackerArn = event_tracker_arn\n",
" )\n",
" status = describe_event_tracker_response[\"eventTracker\"][\"status\"]\n",
" print(\"EventTracker: {}\".format(status))\n",
" \n",
" if status == \"ACTIVE\" or status == \"CREATE FAILED\":\n",
" break\n",
" \n",
" time.sleep(15)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Cold User Recommendations\n",
"\n",
"One of the key features of Personalize is being able to cold start users. Cold users are typically those who are new to your site or application and cold starting a user is getting from no personalization to making personalized recommendations in real-time. \n",
"\n",
"Personalize accomplishes cold starting users via the Event Tracker. Since new users are typically anonymous for a period of time before they create an account or may choose to transact as a guest, personalization is a valuable tool to help convert those anonymous users to transacting users. \n",
"\n",
"The challenge here is that Personalize needs a `userId` for anonymous users before it can make personalized recommendations. This challenge can be solved by creating a provisional user ID the moment an anonymous user first hits the site. This provisional user ID is then used when streaming events to the Event Tracker and when retrieving recommendations from the Recommendations service. This allows applications to start serving personalized recommendations after the first couple events are streamed to Personalize. Before recommendations can be personalized, Personalize will provide recommendations for popular items as a fallback.\n",
"\n",
"There are some challenges with this approach, though. First is the question of what to do with the provisional user ID when the user creates an account. To maintain continuity of the user's interaction history, client applications can pass the provisional user ID to the user management system when creating a new user account. Another challenge is how to handle a user that anonymously browses the site using multiple devices such as on the mobile device and then on a desktop/laptop. In this case, separate provisional user IDs are generated for sessions on each device. However, once the user creates an account on one device and then signs in with that account on the other device, both devices will starting using the same user ID going forward. A side effect here is that the interaction history from one of the devices will be orphaned. This is an acceptable tradeoff given the benefit of cold starting users earlier and is functionally the same UX without this scheme. Additional logic could be added to merge the interaction history from both prior anonymous sessions when the user creates an account. Also, customer data platforms can be used to help manage this for you."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Test Purchased Products Filter\n",
"\n",
"To test our purchased products filter, we will request ranked recommendations for a random user. Then we will send a `Purchase` event for one of the recommended products to Personalize using the event tracker created above. Finally, we will request recommendations again for the same user but this time specify our filter. The purchased product would be excluded from the new recommendations."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Pick a user ID in the range of test users and fetch 5 recommendations.\n",
"user_id = 456\n",
"display(user_metadata_df[user_metadata_df['id']==user_id])"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"get_recommendations_response = personalize_runtime.get_personalized_ranking(\n",
" campaignArn=rerank_campaign_arn,\n",
" inputList=unranked_product_ids,\n",
" userId = str(user_id)\n",
")\n",
"\n",
"item_list = get_recommendations_response['personalizedRanking']\n",
"df = pd.DataFrame()\n",
"df['Item'] = [ itm['itemId'] for itm in item_list ]\n",
"df['Name'] = [ get_item_name_from_id ( itm['itemId']) for itm in item_list ]\n",
"df['Category'] = [ get_item_category_from_id ( itm['itemId']) for itm in item_list ]\n",
"df['Style'] = [ get_item_style_from_id ( itm['itemId']) for itm in item_list ]\n",
"display (df)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Next let's randomly select an item from the returned list of recommendations to be our product to purchase."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"product_id_to_purchase = random.choice(item_list)['itemId']\n",
"print(f'Product to simulate purchasing: {product_id_to_purchase}')\n",
"print(f'Product name: {get_item_name_from_id ( product_id_to_purchase)}')"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Next let's send a `Purchase` event to Personalize to simulate that the product was just purchased.\n",
"This will match the criteria for our filter.\n",
"In the Retail Demo Store web application, this event is sent for each product in the order after the order is completed."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"response = personalize_events.put_events(\n",
" trackingId = event_tracking_id,\n",
" userId = str(user_id),\n",
" sessionId = str(uuid.uuid4()),\n",
" eventList = [\n",
" {\n",
" 'eventId': str(uuid.uuid4()),\n",
" 'eventType': 'Purchase',\n",
" 'itemId': str(product_id_to_purchase),\n",
" 'sentAt': int(time.time()),\n",
" 'properties': '{\"discount\": \"No\"}'\n",
" }\n",
" ]\n",
")\n",
"\n",
"# Wait for Purchase event to become consistent.\n",
"time.sleep(10)\n",
"\n",
"print(json.dumps(response, indent=2))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Finally, let's retrieve recommendations for the user again but this time specifying the filter to exclude recently\n",
"purchased items. We do this by passing the filter's ARN via the `filterArn` parameter."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"get_recommendations_response = personalize_runtime.get_personalized_ranking(\n",
" campaignArn=rerank_campaign_arn,\n",
" inputList=unranked_product_ids,\n",
" userId = str(user_id),\n",
" filterArn = filter_purchase_arn\n",
")\n",
"\n",
"item_list = get_recommendations_response['personalizedRanking']\n",
"df = pd.DataFrame()\n",
"df['Item'] = [ itm['itemId'] for itm in item_list ]\n",
"df['Name'] = [ get_item_name_from_id ( itm['itemId']) for itm in item_list ]\n",
"df['Category'] = [ get_item_category_from_id ( itm['itemId']) for itm in item_list ]\n",
"df['Style'] = [ get_item_style_from_id ( itm['itemId']) for itm in item_list ]\n",
"display (df)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"The following code will raise an assertion error if the product we just purchased is still recommended."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"found_item = next((item for item in item_list if item['itemId'] == product_id_to_purchase), None)\n",
"if found_item:\n",
" assert found_item == False, 'Purchased item found unexpectedly in recommendations'\n",
"else:\n",
" print('Purchased item filtered from recommendations for user!')"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Category Filter\n",
"[Back to top](#top)\n",
"\n",
"To test our purchased products filter, we will request recommendations for a random user with a particular category."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"def get_new_recommendations_df_by_dynamic_filter(recommendations_df, user_id, category_filter_arn, filter_values):\n",
" # Get the recommendations\n",
" get_recommendations_response = personalize_runtime.get_recommendations(\n",
" recommenderArn = recommended_for_you_arn,\n",
" userId = str(user_id),\n",
" filterArn = filter_category_arn,\n",
" filterValues = { \"CATEGORY\": \"\\\"\" + filter_values + \"\\\"\"}\n",
" )\n",
" # Build a new dataframe of recommendations\n",
" item_list = get_recommendations_response['itemList']\n",
" recommendation_list = []\n",
" for item in item_list:\n",
" movie = get_item_name_from_id(item['itemId'])\n",
" recommendation_list.append(movie)\n",
" filter_name = filter_category_arn.split('/')[1]\n",
" new_rec_DF = pd.DataFrame(recommendation_list, columns = [filter_values])\n",
" # Add this dataframe to the old one\n",
" recommendations_df = pd.concat([recommendations_df, new_rec_DF], axis=1)\n",
" return recommendations_df"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"We will select the first 7 categories for this example."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"unique_category_field_values = list(item_metadata_df['category'].unique()[:7])\n",
"unique_category_field_values"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Iterate through Genres\n",
"recommendations_df_category = pd.DataFrame()\n",
"for category in unique_category_field_values:\n",
" recommendations_df_category = get_new_recommendations_df_by_dynamic_filter(recommendations_df_category, user_id, filter_category_arn , category)\n",
" \n",
"recommendations_df_category"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Batch recommendations \n",
"[Back to top](#top)\n",
"\n",
"There are many cases where you may want to have a larger dataset of exported recommendations. Amazon Personalize launched batch recommendations as a way to export a collection of recommendations to S3. In this example, we will walk through how to do this for the Personalized Ranking solution. For more information about batch recommendations, please see the [documentation](https://docs.aws.amazon.com/personalize/latest/dg/recommendations-batch.html). This feature applies to all recipes, but the output format will vary.\n",
"\n",
"A simple implementation looks like this:\n",
"\n",
"```python\n",
"import boto3\n",
"\n",
"personalize_rec = boto3.client(service_name='personalize')\n",
"\n",
"personalize_rec.create_batch_inference_job (\n",
" solutionVersionArn = \"Solution version ARN\",\n",
" jobName = \"Batch job name\",\n",
" roleArn = \"IAM role ARN\",\n",
" jobInput = \n",
" {\"s3DataSource\": {\"path\": }},\n",
" jobOutput = \n",
" {\"s3DataDestination\": {\"path\": }}\n",
")\n",
"```\n",
"\n",
"The SDK import, the solution version arn, and role arns have all been determined. This just leaves an input, an output, and a job name to be defined.\n",
"\n",
"Starting with the input for Personalized Ranking, it looks like:\n",
"\n",
"\n",
"```JSON\n",
"{\"userId\": \"891\", \"itemList\": [\"27\", \"886\", \"101\"]}\n",
"{\"userId\": \"445\", \"itemList\": [\"527\", \"55\", \"901\"]}\n",
"{\"userId\": \"71\", \"itemList\": [\"27\", \"351\", \"101\"]}\n",
"```\n",
"\n",
"This should yield an output that looks like this:\n",
"\n",
"```JSON\n",
"{\"input\":{\"userId\":\"891\",\"itemList\":[\"27\",\"886\",\"101\"]},\"output\":{\"recommendedItems\":[\"27\",\"101\",\"886\"],\"scores\":[0.48421,0.28133,0.23446]}}\n",
"{\"input\":{\"userId\":\"445\",\"itemList\":[\"527\",\"55\",\"901\"]},\"output\":{\"recommendedItems\":[\"901\",\"527\",\"55\"],\"scores\":[0.46972,0.31011,0.22017]}}\n",
"{\"input\":{\"userId\":\"71\",\"itemList\":[\"29\",\"351\",\"199\"]},\"output\":{\"recommendedItems\":[\"351\",\"29\",\"199\"],\"scores\":[0.68937,0.24829,0.06232]}}\n",
"\n",
"```\n",
"\n",
"The output is a JSON Lines file. It consists of individual JSON objects, one per line. So we will need to put in more work later to digest the results in this format."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Building the input file\n",
"\n",
"When you are using the batch feature, you specify the users that you'd like to receive recommendations for when the job has completed. The cell below will again select a few random users and will then build the file and save it to disk. From there, you will upload it to S3 to use in the API call later."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# We will use the same users from before\n",
"print (users)\n",
"# Write the file to disk\n",
"json_input_filename = \"json_input.json\"\n",
"with open(json_input_filename, 'w') as json_input:\n",
" for user_id in users:\n",
" json_input.write('{\"userId\": \"' + str(user_id) + '\", \"itemList\":'+json.dumps(unranked_product_ids)+'}\\n')"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Showcase the input file:\n",
"!cat $json_input_filename"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Upload the file to S3 and save the path as a variable for later."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Upload files to S3\n",
"boto3.Session().resource('s3').Bucket(bucket_name).Object(json_input_filename).upload_file(json_input_filename)\n",
"s3_input_path = \"s3://\" + bucket_name + \"/\" + json_input_filename\n",
"print(s3_input_path)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Batch recommendations read the input from the file we've uploaded to S3. Similarly, batch recommendations will save the output to file in S3. So we define the output path where the results should be saved."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Define the output path\n",
"s3_output_path = \"s3://\" + bucket_name + \"/\"\n",
"print(s3_output_path)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"batchInferenceJobArn = personalize.create_batch_inference_job (\n",
" solutionVersionArn = rerank_solution_version_arn,\n",
" jobName = \"POC-Batch-Inference-Job-PersonalizedRanking_\" + str(round(time.time()*1000)),\n",
" roleArn = role_arn,\n",
" jobInput = \n",
" {\"s3DataSource\": {\"path\": s3_input_path}},\n",
" jobOutput = \n",
" {\"s3DataDestination\":{\"path\": s3_output_path}}\n",
")\n",
"batchInferenceJobArn = batchInferenceJobArn['batchInferenceJobArn']"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Run the while loop below to track the status of the batch recommendation call. This can take around 30 minutes to complete, because Personalize needs to stand up the infrastructure to perform the task. We are testing the feature with a dataset of only 3 users, which is not an efficient use of this mechanism. Normally, you would only use this feature for bulk processing, in which case the efficiencies will become clear."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"%%time\n",
"\n",
"current_time = datetime.now()\n",
"print(\"Import Started on: \", current_time.strftime(\"%I:%M:%S %p\"))\n",
"\n",
"max_time = time.time() + 6*60*60 # 6 hours\n",
"while time.time() < max_time:\n",
" describe_dataset_inference_job_response = personalize.describe_batch_inference_job(\n",
" batchInferenceJobArn = batchInferenceJobArn\n",
" )\n",
" status = describe_dataset_inference_job_response[\"batchInferenceJob\"]['status']\n",
" print(\"DatasetInferenceJob: {}\".format(status))\n",
" \n",
" if status == \"ACTIVE\" or status == \"CREATE FAILED\":\n",
" break\n",
" \n",
" time.sleep(60)\n",
" \n",
"current_time = datetime.now()\n",
"print(\"Import Completed on: \", current_time.strftime(\"%I:%M:%S %p\"))"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"s3 = boto3.client('s3')\n",
"export_name = json_input_filename + \".out\"\n",
"s3.download_file(bucket_name, export_name, export_name)\n",
"\n",
"# Update DF rendering\n",
"pd.set_option('display.max_rows', 30)\n",
"with open(export_name) as json_file:\n",
" # Get the first line and parse it\n",
" line = json.loads(json_file.readline())\n",
" # Do the same for the other lines\n",
" while line:\n",
" # extract the user ID \n",
" col_header = \"User: \" + line['input']['userId']\n",
" # Create a list for all the artists\n",
" recommendation_list = []\n",
" # Add all the entries\n",
" for item in line['output']['recommendedItems']:\n",
" movie = get_item_name_from_id(item)\n",
" recommendation_list.append(movie)\n",
" if 'bulk_recommendations_df' in locals():\n",
" new_rec_DF = pd.DataFrame(recommendation_list, columns = [col_header])\n",
" bulk_recommendations_df = bulk_recommendations_df.join(new_rec_DF)\n",
" else:\n",
" bulk_recommendations_df = pd.DataFrame(recommendation_list, columns=[col_header])\n",
" try:\n",
" line = json.loads(json_file.readline())\n",
" except:\n",
" line = None\n",
"bulk_recommendations_df"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Wrap up \n",
"[Back to top](#top)\n",
"\n",
"With that you now have a fully working collection of models to tackle various recommendation and personalization scenarios, as well as the skills to manipulate customer data to better integrate with the service, and a knowledge of how to do all this over APIs and by leveraging open source data science tools.\n",
"\n",
"Use these notebooks as a guide to getting started with your customers for POCs. As you find missing components, or discover new approaches, cut a pull request and provide any additional helpful components that may be missing from this collection.\n",
"\n",
"You can choose to head to `04_Operations_Layer.ipynb` to go deeper into ML Ops and what a production solution can look like with an automation pipeline.\n",
"\n",
"You'll want to make sure that you clean up all of the resources deployed during this POC. We have provided a separate notebook which shows you how to identify and delete the resources in `05_Clean_Up_Resources.ipynb`."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"%store event_tracker_arn"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": []
}
],
"metadata": {
"kernelspec": {
"display_name": "conda_python3",
"language": "python",
"name": "conda_python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.6.13"
}
},
"nbformat": 4,
"nbformat_minor": 4
}