{
"cells": [
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Image Moderation\n",
"\n",
"In this tutorial, we will show how you can use Amazon Rekognition and Amazon Comprehend to quickly identify unsafe/inappropriate content in your image libraries.\n",
"\n",
"Below is the list of AWS services that we're going to use in this notebook. \n",
"- [Amazon Rekognition](https://aws.amazon.com/rekognition/) makes it easy to add image and video analysis to your applications.\n",
"- [Amazon Comprehend](https://aws.amazon.com/comprehend/) uses natural language processing (NLP) to extract insights about the content of documents.\n",
"- [Amazon Simple Storage Service (Amazon S3)](https://aws.amazon.com/s3/) is an object storage service that offers industry-leading scalability, data availability, security, and performance.\n",
"- [Amazon SageMaker](https://aws.amazon.com/sagemaker/) allows you to build, train, and deploy machine learning (ML) models for any use case with fully managed infrastructure, tools, and workflows.\n",
"\n",
"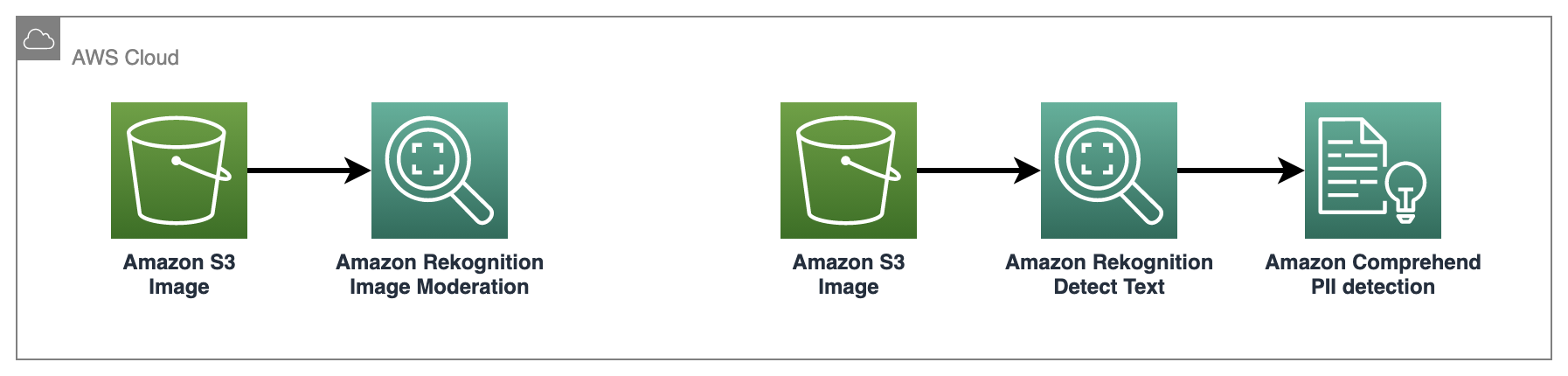\n",
"\n",
"Follow the steps in this notebook to understand how you can identify inappropriate content and PII information in an image. For more in depth instructions, Please visit [this link](https://docs.aws.amazon.com/rekognition/latest/dg/procedure-moderate-images.html)\n",
"\n",
"- [Step 1: Setup Notebook](#step1)\n",
"- [Step 2: Moderate image using Rekognition image moderation API](#step2)\n",
"- [Step 3: Moderate text in image using Comprehend PII detection API](#step3)\n",
"- [Step 4: Clean up](#step4)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Step 1: Setup Notebook \n",
"Run the below cell to install/update Python dependencies if you run the lab using a local IDE. It is optional if you use a SageMaker Studio Juypter Notebook, which already includes the dependencies in the kernel. "
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"%pip install -qU pip\n",
"%pip install boto3 -qU"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"import boto3\n",
"import sagemaker\n",
"\n",
"# variables\n",
"data_bucket = sagemaker.Session().default_bucket()\n",
"role = sagemaker.get_execution_role()\n",
"region = boto3.session.Session().region_name\n",
"\n",
"s3 = boto3.client('s3', region_name=region)\n",
"rekognition = boto3.client('rekognition', region_name=region)\n",
"comprehend = boto3.client('comprehend', region_name=region)\n",
"\n",
"\n",
"print(f\"SageMaker role is: {role}\\nDefault SageMaker Bucket: s3://{data_bucket}\")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"For this lab, we will use a sample image stored in this repo: ../datasets/yoga_swimwear_lighttext.jpg.\n",
"\n",
"The image contains a lady in a bikini and Rekognition Image Moderation will label it as \"Suggestive\". Also as the image contains phone number, we can use the combination of Amazon Rekognition and Amazon Comprehend together to detect and label the phone number as PII (Personal Identification Information)."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
""
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Now, let's upload the image to the default S3 bucket for Rekognition to access."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"s3_key = 'content-moderation-im/image-moderation/yoga_swimwear_lighttext.jpg'\n",
"s3.upload_file('../datasets/yoga_swimwear_lighttext.jpg', data_bucket, s3_key)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Step 2: Moderate image \n",
"In this step, we will call Amazon Rekognition [Content Moderation API](https://docs.aws.amazon.com/rekognition/latest/dg/procedure-moderate-images.html) to detect inappropriate content in the image. "
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"scrolled": true
},
"outputs": [],
"source": [
"detectModerationLabelsResponse = rekognition.detect_moderation_labels(\n",
" Image={\n",
" 'S3Object': {\n",
" 'Bucket': data_bucket,\n",
" 'Name': s3_key,\n",
" }\n",
" }\n",
")\n",
"detectModerationLabelsResponse"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Note the response from a call to DetectModerationLabels:\n",
"\n",
"- ModerationLabels – The example shows a list of labels for inappropriate or offensive content found in the image. The list includes the top-level label and each second-level label that are detected in the image. Please see [Amazon Rekognition doucmentation](https://docs.aws.amazon.com/rekognition/latest/dg/moderation.html) for the complete list of supported top/second level labels.\n",
"\n",
"- Name/ParentName – Each label has a name, an estimation of the confidence that Amazon Rekognition has that the label is accurate, and the name of its parent label. The parent name for a top-level label is \"\".\n",
"\n",
"- Confidence – Each label has a confidence value between 0 and 100 that indicates the percentage confidence that Amazon Rekognition has that the label is correct. You specify the [minimal confidence level](https://docs.aws.amazon.com/rekognition/latest/APIReference/API_DetectModerationLabels.html#rekognition-DetectModerationLabels-request-MinConfidence) for a label to be returned in the response in the API operation request."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"for label in detectModerationLabelsResponse[\"ModerationLabels\"]:\n",
" print(\"- {} (Confidence: {})\".format(label[\"Name\"], label[\"Confidence\"]))\n",
" print(\" - Parent: {}\".format(label[\"ParentName\"]))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"As we can see in the Rekognition response, the Image Moderation API labeled the image in 3 categories with confidence scores:\n",
"- Top level category: **Suggestive** with a confidence score > 98%\n",
"- Second level category: **Female Swimwear Or Underwear** with a confidence score > 98%\n",
"- Second level category: **Revealing Clothes** with a confidence score ~ 68% "
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Step 3: Moderate text in image \n",
"Now, let's see how to extract text in an image and detect if it contains sensitive information. In this step. we are going to use Rekognition API to [detect text in image](https://docs.aws.amazon.com/rekognition/latest/APIReference/API_DetectText.html) and pass it on to Amazon Comprehend API to [detect PII](https://docs.aws.amazon.com/comprehend/latest/APIReference/API_DetectPiiEntities.html)."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"detectTextResponse = rekognition.detect_text(\n",
" Image={\n",
" 'S3Object': {\n",
" 'Bucket': data_bucket,\n",
" 'Name': s3_key,\n",
" }\n",
" }\n",
")\n",
"\n",
"detected_text_list=[]\n",
"textDetections=detectTextResponse['TextDetections']\n",
"for text in textDetections:\n",
" if text['Type'] == 'LINE':\n",
" print ('Detected text: ' + text['DetectedText'])\n",
" detected_text_list.append(text['DetectedText'])\n",
" \n",
" \n",
"for text in detected_text_list:\n",
" response=comprehend.detect_pii_entities(Text=text, LanguageCode='en')\n",
" if len(response['Entities']) > 0: \n",
" print(\"Detected PII entity is: \" + text[response['Entities'][0]['BeginOffset']:response['Entities'][0]['EndOffset']])\n",
" print(\"PII type is: \" + response['Entities'][0]['Type'])\n",
" print(\"Confidence score is: \" + str(response['Entities'][0]['Score']))\n",
" print()"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Step 4: Clean up \n",
"\n",
"Remove the resources that may incur the cost"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# remove the image from s3 bucket\n",
"response = s3.delete_object(Bucket=data_bucket, Key=s3_key)\n",
"print(response)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Conclusion\n",
"In this lab, we moderated an image (containing text) using Amazon Rekognition and Amazon Comprehend."
]
}
],
"metadata": {
"instance_type": "ml.t3.medium",
"kernelspec": {
"display_name": "Python 3 (Data Science)",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.7.10"
},
"vscode": {
"interpreter": {
"hash": "aee8b7b246df8f9039afb4144a1f6fd8d2ca17a180786b69acc140d282b71a49"
}
}
},
"nbformat": 4,
"nbformat_minor": 4
}