{
"cells": [
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Video Moderation - detecting inappropriate information in stored videos"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"You can use Amazon Rekognition to detect content that is inappropriate, unwanted, or offensive. You can use Rekognition moderation APIs in social media, broadcast media, advertising, and e-commerce situations to create a safer user experience, provide brand safety assurances to advertisers, and comply with local and global regulations.\n",
"\n",
"Amazon Rekognition Video inappropriate or offensive content detection in stored videos is an asynchronous operation. To start detecting inappropriate or offensive content, call [StartContentModeration](https://docs.aws.amazon.com/rekognition/latest/APIReference/API_StartContentModeration.html). Amazon Rekognition Video publishes the completion status of the video analysis to an Amazon Simple Notification Service topic. If the video analysis is successful, call [GetContentModeration](https://docs.aws.amazon.com/rekognition/latest/APIReference/API_GetContentModeration.html) to get the analysis results. For more information about starting video analysis and getting the results, see [Calling Amazon Rekognition Video operations](https://docs.aws.amazon.com/rekognition/latest/dg/api-video.html). \n",
"\n",
"This tutorial will show you how to use Amazon Rekognition Moderation API to moderate stored videos, how to extract text from a video using Amazon Rekognition for Text Moderation, and how to transcribe the audio of the video into text for Text Moderation. This lab will not cover the text moderation logic. You can refer to labs in the **04-text-moderation** module for more examples."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"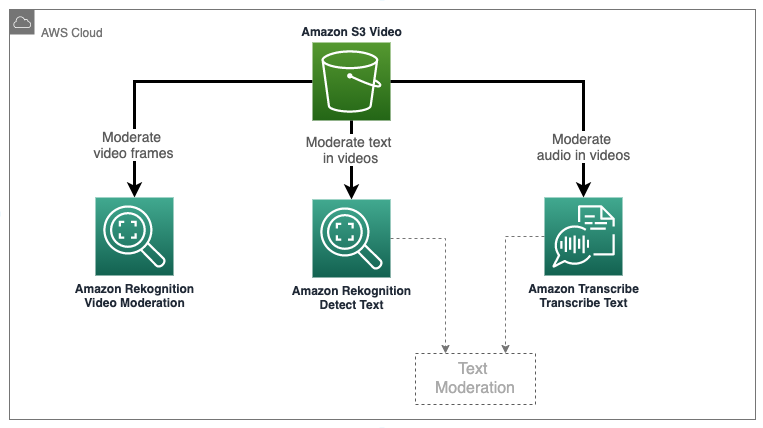\n",
"\n",
"- [Step 1: Setup Notebook](#step1)\n",
"- [Step 2: Moderate video using Rekognition video moderation API](#step2)\n",
"- [Step 3: Detect text in video](#step3)\n",
"- [Step 4: Transcribe audio in video](#step4)\n",
"- [Step 5: Clean up](#step5)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Step 1: Setup Notebook \n",
"Run the below cell to install/update Python dependencies if you run the lab using a local IDE. It is optional if you use a SageMaker Studio Juypter Notebook, which already includes the dependencies in the kernel. "
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# First, let's get the latest installations of our dependencies\n",
"%pip install -qU pip\n",
"%pip install boto3 -qU\n",
"%pip install IPython -qU"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"import boto3\n",
"import sagemaker as sm\n",
"import os\n",
"import io\n",
"import datetime\n",
"from IPython.display import HTML, display\n",
"import uuid\n",
"import json\n",
"import time\n",
"\n",
"# variables\n",
"data_bucket = sm.Session().default_bucket()\n",
"region = boto3.session.Session().region_name\n",
"\n",
"os.environ[\"BUCKET\"] = data_bucket\n",
"os.environ[\"REGION\"] = region\n",
"role = sm.get_execution_role()\n",
"\n",
"print(f\"SageMaker role is: {role}\\nDefault SageMaker Bucket: s3://{data_bucket}\")\n",
"\n",
"s3=boto3.client('s3', region_name=region)\n",
"rekognition=boto3.client('rekognition', region_name=region)\n",
"comprehend = boto3.client('comprehend', region_name=region)\n",
"transcribe=boto3.client('transcribe', region_name=region)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"For this lab, we will moderate a demo video containing typical inappropriate scenes, such as alcohol, tobacco, and suggestive. The video also has text and audio containing inappropriate information, such as profanity. You can find the video at `datasets/moderation-video.mp4`.\n",
"\n",
""
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Now, let's upload the video to the default S3 bucket for Rekognition to access."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"s3_key = 'content-moderation-im/video-moderation/moderation-video.mp4'\n",
"s3.upload_file('../datasets/moderation-video.mp4', data_bucket, s3_key)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Step 2: Moderate video using Rekognition moderation API \n",
"Call Rekognition **StartContentModeration** API to detect inappropriate information in the video. Rekognition Video moderation API is an asynchronize API that will start a job managed by Rekognition. We will receive a job_id back when we start the job. Then use iteration logic to heart-beat the **GetContentModeration** API to check job status until the job completes.\n",
"The below process should take ~1 minute to complete.\n",
"\n",
"However, it is highly recommended to check out the Notification Channel feature which allows you to receive a SNS notification when the detection job is completed instead of periodically polling the status of the detection. Check [boto3 document](https://docs.aws.amazon.com/cli/latest/reference/rekognition/start-content-moderation.html) for details."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"startModerationLabelDetection = rekognition.start_content_moderation(\n",
" Video={\n",
" 'S3Object': {\n",
" 'Bucket': data_bucket,\n",
" 'Name': s3_key,\n",
" }\n",
" },\n",
" #MinConfidence=50\n",
")\n",
"\n",
"moderationJobId = startModerationLabelDetection['JobId']\n",
"display(\"Job Id: {0}\".format(moderationJobId))\n",
"\n",
"getContentModeration = rekognition.get_content_moderation(\n",
" JobId=moderationJobId,\n",
" SortBy='TIMESTAMP'\n",
")\n",
"\n",
"while(getContentModeration['JobStatus'] == 'IN_PROGRESS'):\n",
" time.sleep(5)\n",
" print('.', end='')\n",
"\n",
" getContentModeration = rekognition.get_content_moderation(\n",
" JobId=moderationJobId,\n",
" SortBy='TIMESTAMP')\n",
"\n",
"display(getContentModeration['JobStatus'])"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"The below cell will display the video in the browser with a list of hyperlinks. Click on the links to navigate the video to the specific timestamp."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"s3_video_url = s3.generate_presigned_url('get_object', Params={'Bucket': data_bucket, 'Key': s3_key})\n",
"video_tag = f\"\"\n",
"\n",
"label_html = ''''''\n",
"for label in getContentModeration[\"ModerationLabels\"]:\n",
" if len(label[\"ModerationLabel\"][\"ParentName\"]) > 0:\n",
" label_html += f'''[{label['Timestamp']} ms]: \n",
" {label['ModerationLabel']['Name']}, confidence: {round(label['ModerationLabel']['Confidence'],2)}%
\n",
" '''\n",
"display(HTML(video_tag))\n",
"display(HTML(label_html))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Step 3: Extract text in video "
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Similarly to the Video moderation API, text detection with Amazon Rekognition Video is also an asynchronous operation. You start text detection by calling StartTextDetection, which returns a job identifier (JobId). Then we will periodically poll the job status by calling GetTextDetection API. Until the job status becomes SUCCEED.\n",
"\n",
"The below process should take ~1 minute to complete."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"getTextDetection = rekognition.start_text_detection(\n",
" Video={\n",
" 'S3Object': {\n",
" 'Bucket': data_bucket,\n",
" 'Name': s3_key,\n",
" }\n",
" }\n",
")\n",
"\n",
"textJobId = getTextDetection['JobId']\n",
"display(\"Job Id: {0}\".format(moderationJobId))\n",
"\n",
"getTextDetection = rekognition.get_text_detection(JobId=textJobId)\n",
"\n",
"while(getTextDetection['JobStatus'] == 'IN_PROGRESS'):\n",
" time.sleep(5)\n",
" print('.', end='')\n",
"\n",
" getTextDetection = rekognition.get_text_detection(JobId=textJobId)\n",
"\n",
"display(getTextDetection['JobStatus'])"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Now, let's display the video and use the hyperlinks to navigate the timestamps where text was detected."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"s3_video_url = s3.generate_presigned_url('get_object', Params={'Bucket': data_bucket, 'Key': s3_key})\n",
"video_tag = f\"\"\n",
"\n",
"text_html = ''''''\n",
"for txt in getTextDetection[\"TextDetections\"]:\n",
" if txt[\"TextDetection\"][\"Type\"] == 'LINE':\n",
" text_html += f'''[{txt['Timestamp']} ms]: \n",
" {txt[\"TextDetection\"][\"DetectedText\"]}, confidence: {round(txt[\"TextDetection\"][\"Confidence\"],2)}%
\n",
" '''\n",
"display(HTML(video_tag))\n",
"display(HTML(text_html))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"After extracting text from the video, we can then moderate it using Amazon Comprehend. This lab will not cover the text moderation logic. You can refer to the 04-text-moderation module for more examples."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Step 4: Transcribe audio in video \n",
"\n",
"We have moderated the video and extracted text from the video using Rekognition. Now, we will transcribe the audio to text using Amazon Transcribe.\n",
"\n",
"Call Transcribe **StartTranscriptionJob** API to transcribe the audio to text. Amazon Transcribe StartTranscriptionJob is an asynchronous API that will start a job managed by Transcribe. We will then call the **GetTranscriptionJob** API to check job status until the job completes."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"import uuid\n",
"job_name = f'video_moderation_{str(uuid.uuid1())[0:4]}'\n",
"\n",
"transcribe.start_transcription_job(\n",
" TranscriptionJobName = job_name,\n",
" Media = {\n",
" 'MediaFileUri': f's3://{data_bucket}/{s3_key}'\n",
" },\n",
" OutputBucketName = data_bucket,\n",
" OutputKey = 'content-moderation-im/video-moderation/audio_output/',\n",
" MediaFormat = 'mp4',\n",
" LanguageCode = 'en-US'\n",
" )\n",
"\n",
"getTranscription = transcribe.get_transcription_job(TranscriptionJobName = job_name)\n",
"\n",
"while(getTranscription['TranscriptionJob']['TranscriptionJobStatus'] == 'IN_PROGRESS'):\n",
" time.sleep(5)\n",
" print('.', end='')\n",
"\n",
" getTranscription = transcribe.get_transcription_job(TranscriptionJobName = job_name)\n",
"\n",
"display(getTranscription['TranscriptionJob']['TranscriptionJobStatus'])"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"The job is completed. Transcribe stored the output data to a JSON file in the S3 path specified in the `OutputKey` parameter. We now open the transcribed output JSON file from S3 and check the transcription accuracy. Notice that some of the words may be inappropriate. "
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"filename = 'content-moderation-im/video-moderation/audio_output/'+job_name+'.json'\n",
"s3_clientobj = s3.get_object(Bucket=data_bucket, Key=filename)\n",
"s3_clientdata = s3_clientobj[\"Body\"].read().decode(\"utf-8\")\n",
"original = json.loads(s3_clientdata)\n",
"output_transcript = original[\"results\"][\"transcripts\"]\n",
"print(output_transcript)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"After transcribing text from the audio of the video, we can then moderate it using Amazon Comprehend. This lab will not cover the text moderation logic. You can refer to labs in the 04-text-moderation module for more examples."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Step 5: Clean up \n",
"\n",
"Remove the resources that may incur the cost"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# remove the image from s3 bucket\n",
"response = s3.delete_object(Bucket=data_bucket, Key=s3_key)\n",
"print(response)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Conclusion\n",
"In this lab, we moderated a video (containing text) using Amazon Rekognition and Amazon Comprehend."
]
}
],
"metadata": {
"instance_type": "ml.t3.medium",
"kernelspec": {
"display_name": "Python 3 (Data Science)",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.7.10"
},
"vscode": {
"interpreter": {
"hash": "aee8b7b246df8f9039afb4144a1f6fd8d2ca17a180786b69acc140d282b71a49"
}
}
},
"nbformat": 4,
"nbformat_minor": 4
}