{
"cells": [
{
"cell_type": "markdown",
"id": "90dca00e-a649-4c27-9e96-18b5117c581a",
"metadata": {},
"source": [
"# Video Moderation - detecting inappropriate information in stored videos with image API"
]
},
{
"cell_type": "markdown",
"id": "5df63511-1bb0-44fb-9856-e9e16472318c",
"metadata": {},
"source": [
"Generally speaking, We recommend using the Amazon Rekonition video-based API [StartContentModeration](https://docs.aws.amazon.com/rekognition/latest/APIReference/API_StartContentModeration.html) for video content moderation, however, you can also choose to independently sample frames from videos and detect inappropriate content by sending the images to the Amazon Rekognition image-based API [DetectModerationLabels](https://docs.aws.amazon.com/rekognition/latest/APIReference/API_DetectModerationLabels.html). Image results are returned in real time with labels for inappropriate content or offensive content along with a confidence score. \n",
"\n",
"Depends on your requirements on accuracy, cost, performance, and architecture complexity, you can choose either of the approaches that best suited for your use case. Please refer to this blog for the detailed [comparison of the two content moderation approaches](https://aws.amazon.com/blogs/machine-learning/how-to-decide-between-amazon-rekognition-image-and-video-api-for-video-moderation/).\n",
"\n",
"This lab will show you how to use [ffmpeg](https://ffmpeg.org/) to sample frames from video and store them as images, then send those images for content moderation using image moderation API and show moderation results in json format"
]
},
{
"cell_type": "markdown",
"id": "eda488a4-1160-436e-838c-dfdfba59a197",
"metadata": {},
"source": [
"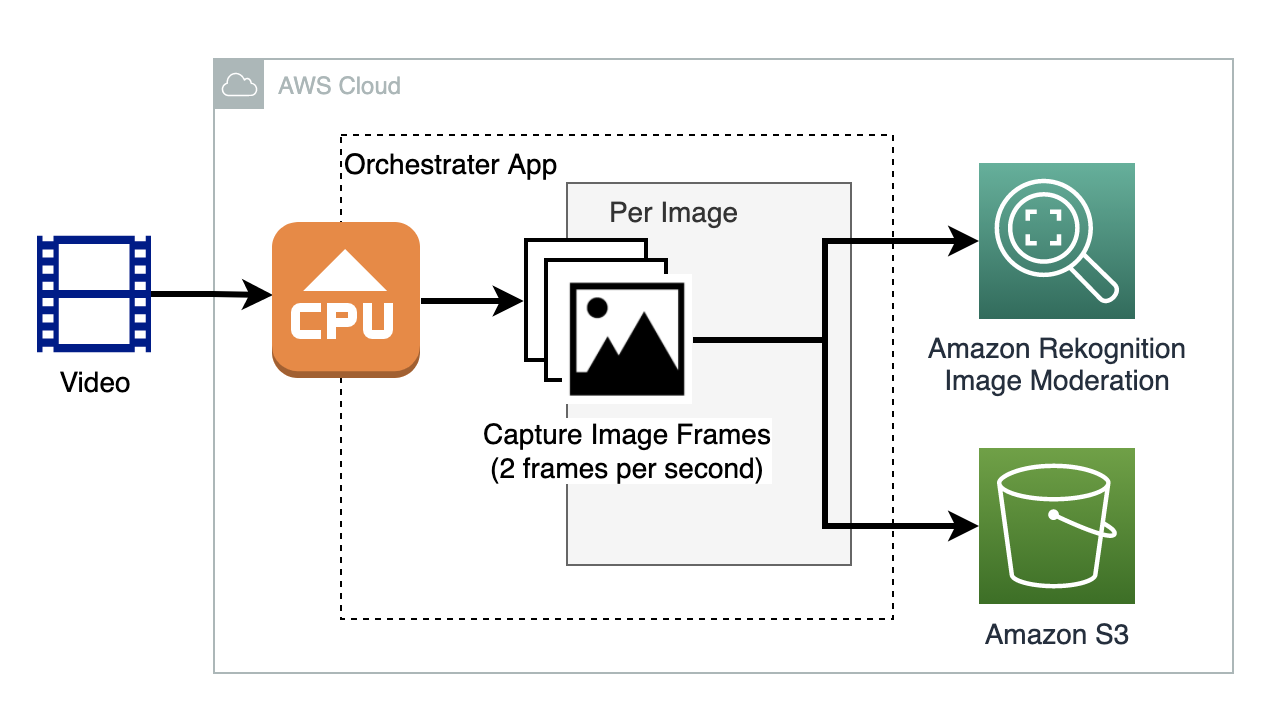\n",
"\n",
"- [Step 1: Setup Notebook](#step1)\n",
"- [Step 2: Sample image frames](#step2)\n",
"- [Step 3: Moderate sample image frames](#step3)\n",
"- [Step 4: Clean up](#step4)"
]
},
{
"cell_type": "markdown",
"id": "7a3b1293-3741-4db2-a68e-abdf21d8945a",
"metadata": {},
"source": [
"# Step 1: Setup Notebook \n",
"Run the below cell to install/update Python dependencies if you run the lab using a local IDE. It is optional if you use a SageMaker Studio Juypter Notebook, which already includes the dependencies in the kernel. "
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "61c07f68-4008-478c-bc6c-2b5d31d9a05e",
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"# First, let's get the latest installations of our dependencies\n",
"%pip install pip -qU \n",
"%pip install boto3 -qU\n",
"%pip install IPython -qU"
]
},
{
"cell_type": "markdown",
"id": "37ed0e64-0588-4453-8bf0-a184382338c9",
"metadata": {},
"source": [
"Run the below cell to install [ffmpeg](https://ffmpeg.org/) which will be used to decode the video file and sample image frames"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "103399ca-0e43-4199-aefa-c4b291f02d55",
"metadata": {},
"outputs": [],
"source": [
"# Install ffmpeg\n",
"!conda install ffmpeg -y\n",
"!which ffmpeg"
]
},
{
"cell_type": "markdown",
"id": "066ac8c6-6441-4e81-a8cd-f83b99054cd1",
"metadata": {},
"source": [
"Import needed Python libraries and set up environment variables"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "8c7a7164-4d90-44fc-a545-d45f55b82b54",
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"import boto3\n",
"import sagemaker as sm\n",
"import os\n",
"import io\n",
"from datetime import datetime\n",
"from IPython.display import HTML, display\n",
"import uuid\n",
"import json\n",
"import time\n",
"import subprocess\n",
"\n",
"# Constants\n",
"IMAGE_NAME_EXTENSION = '.png'\n",
"LOCAL_DIR = '/tmp'\n",
"SAMPLE_FREQUENCY = 2 # 2 image every 1 seconds\n",
"API_NAME = 'cm_video_moderation_image_sampling'\n",
"HOME_DIR=os.getcwd()\n",
"VIDEO_LOCATION = HOME_DIR + \"/../datasets/moderation-video.mp4\"\n",
"MIN_CONFIDENCE = 50 \n",
"\n",
"# Initializing environment variables\n",
"bucket_name = sm.Session().default_bucket()\n",
"region = boto3.session.Session().region_name\n",
"\n",
"role = sm.get_execution_role()\n",
"list_temp_s3_prefix = []\n",
"\n",
"print(f\"SageMaker role is: {role}\\nDefault SageMaker Bucket: s3://{bucket_name}\")\n",
"\n",
"s3=boto3.client('s3', region_name=region)\n",
"data_bucket = boto3.resource('s3').Bucket(bucket_name)\n",
"rekognition=boto3.client('rekognition', region_name=region)"
]
},
{
"cell_type": "markdown",
"id": "65244f8e-a860-47ac-b3d7-bd10eb22ee40",
"metadata": {},
"source": [
"# Step 2: Sample image frames \n",
"Use ffmpeg to sample image frames from the stored video file"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "77a05ce6-217c-4585-9ce2-18fc909f5a97",
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"ffmpeg_cmd = f\"ffmpeg -i {VIDEO_LOCATION} -r {SAMPLE_FREQUENCY} {LOCAL_DIR}/%07d{IMAGE_NAME_EXTENSION}\"\n",
"cmd = ffmpeg_cmd.split(' ')\n",
"p1 = subprocess.run(cmd, stdout=subprocess.PIPE, stderr=subprocess.PIPE)"
]
},
{
"cell_type": "markdown",
"id": "dc21b985-0de1-4340-8400-fd8c8616d482",
"metadata": {},
"source": [
"# Step 3: Moderate sampled image frames \n",
"Upload sampled images to s3 bucket for moderation"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "5ab856c5-d5c7-4aa0-8ea7-a7a9174a6518",
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"# Parse the video filename and generate S3 prefix for sampled image frames\n",
"file_name=VIDEO_LOCATION.split('/')[-1].replace('.','-')\n",
"print(\"Video file name is: \" + file_name)\n",
"folder_suffix = datetime.now().strftime('%Y%m%d-%H-%M')\n",
"# Target folder: using the video file name as a sub folder\n",
"s3_target_folder = file_name.lower() + \"-\" + folder_suffix\n",
"print(\"S3 prefix is: \" + s3_target_folder)"
]
},
{
"cell_type": "markdown",
"id": "9f489639-bf0d-4e07-97bc-ce545babba3c",
"metadata": {},
"source": [
"Upload sampled image frames to S3 and call image-based API [DetectModerationLabels](https://docs.aws.amazon.com/rekognition/latest/APIReference/API_DetectModerationLabels.html) to moderate them."
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "68289d25-a937-4ef1-a220-39b0a5b16124",
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"# Define the function to moderate image samples using image moderation API\n",
"def moderate_image(s3_bucket, s3_key):\n",
" ts = s3_key.split('/')[-1].replace(IMAGE_NAME_EXTENSION,'')\n",
" detectModerationLabelsResponse = rekognition.detect_moderation_labels(\n",
" Image={\n",
" 'S3Object': {\n",
" 'Bucket': s3_bucket,\n",
" 'Name': s3_key,\n",
" }\n",
" },\n",
" MinConfidence=MIN_CONFIDENCE,\n",
" \n",
" )\n",
" result = {\"Timestamp\": float(ts), \"ModerationLabel\": []}\n",
" for l in detectModerationLabelsResponse[\"ModerationLabels\"]:\n",
" result[\"ModerationLabel\"].append(\n",
" {\n",
" \"Confidence\": l[\"Confidence\"],\n",
" \"Name\": l[\"Name\"],\n",
" \"ParentName\": l[\"ParentName\"]\n",
" }\n",
" )\n",
" return result\n",
"\n",
"# Upload images to s3 and perform moderation, and cleanup temp files on local disk\n",
"labels = []\n",
"for file in os.listdir(LOCAL_DIR):\n",
" if file.endswith(IMAGE_NAME_EXTENSION):\n",
" # convert file name from sequence to time position\n",
" seq = float(file.replace(IMAGE_NAME_EXTENSION,''))\n",
" ms_pos = 1/SAMPLE_FREQUENCY * (seq-1) * 1000\n",
" s3.upload_file(f'{LOCAL_DIR}/{file}', bucket_name, f'{s3_target_folder}/{ms_pos}.png')\n",
" \n",
" # moderate image\n",
" mr = moderate_image(bucket_name, f'{s3_target_folder}/{ms_pos}.png')\n",
" if mr is not None and len(mr[\"ModerationLabel\"]) > 0:\n",
" labels.append(mr)\n",
" \n",
" # Delete local file: image or video\n",
" os.remove(f'{LOCAL_DIR}/{file}')\n",
"\n",
"list_temp_s3_prefix.append(s3_target_folder)"
]
},
{
"cell_type": "markdown",
"id": "90614d30-c343-4339-b18c-32fdfaf24300",
"metadata": {},
"source": [
"Display the moderation results"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "5c428baf-6c71-4eb6-8533-d95bf8a19009",
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"# sort labels\n",
"labels.sort(key=lambda x: x[\"Timestamp\"], reverse=False)\n",
" \n",
"result = {\n",
" \"API\": API_NAME,\n",
" \"Video\": {\n",
" \"S3Bucket\": bucket_name,\n",
" \"S3ObjectName\": file_name\n",
" },\n",
" \"ModerationLabels\": labels\n",
" }\n",
"\n",
"# Display results\n",
"print(result)\n",
" "
]
},
{
"cell_type": "markdown",
"id": "ae7798f5-d372-4f6c-925a-b905e18bb443",
"metadata": {},
"source": [
"# Step 4: Clean up \n",
"Clean up sampled images in S3 bucket"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "81c278bd-e099-4fd5-9ddc-4ac5d9b5ab70",
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"prefix_to_be_deleted = set(list_temp_s3_prefix)\n",
"for pf in prefix_to_be_deleted:\n",
" for obj in data_bucket.objects.filter(Prefix=pf):\n",
" s3.delete_object(Bucket=bucket_name, Key=obj.key)"
]
}
],
"metadata": {
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.7.10"
}
},
"nbformat": 4,
"nbformat_minor": 5
}