{
"cells": [
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Audio Transcribe With Custom Library for Content Moderation\n",
"\n",
"Audio and video files can have profanity as part of their content. When transcribing the files for closed captions etc. there is a need to mask or remove words which are considered profane, and not suitable for the audience. Amazon Transcribe with custom vocabulary provides the ability to filter out unsuitable words. \n",
"Learn more about Amazon transcribe [here](https://aws.amazon.com/transcribe/).\n",
"\n",
"In this tutorial we will learn how to create and use a custom vocabulary to mask out unsuitable words from a transcription.\n",
"You can learn more [here](https://docs.aws.amazon.com/transcribe/latest/dg/vocabulary-filtering.html).\n",
"\n",
"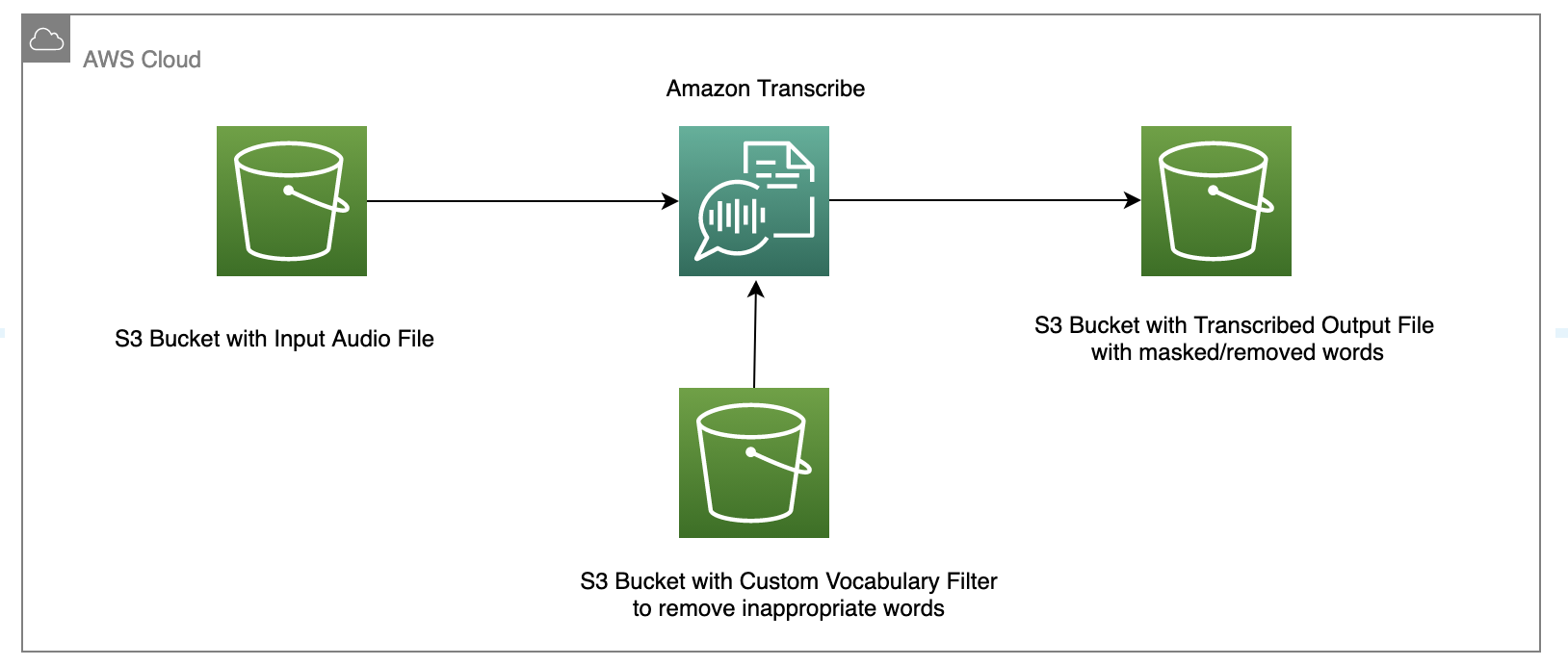\n",
"\n",
"- [Step 1: Setup Notebook](#step1)\n",
"- [Step 2: Setup Variables and import packages](#step2)\n",
"- [Step 3: Setup input audio file & Run Transcribe without moderation ](#step3)\n",
"- [Step 4: Create a custom vocabulary file](#step4)\n",
"- [Step 5: Run transcribe Job with Custom Vocabulary Filter](#step5)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Step 1: Setup Notebook \n",
"Run the below cell to install/update Python dependencies if you run the lab using a local IDE. It is optional if you use a SageMaker Studio Juypter Notebook, which already includes the dependencies in the kernel. "
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# install the below packages if you are using a local IDE and they are not installed in your env\n",
"%pip install -qU pip\n",
"%pip install boto3 -qU"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Step 2: Setup Variables and import packages "
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"import boto3\n",
"import sagemaker as sm\n",
"import os\n",
"import datetime\n",
"import time\n",
"import json\n",
"\n",
"# variables\n",
"data_bucket = sm.Session().default_bucket()\n",
"region = boto3.session.Session().region_name\n",
"\n",
"os.environ[\"BUCKET\"] = data_bucket\n",
"os.environ[\"REGION\"] = region\n",
"role = sm.get_execution_role()\n",
"#The role should have SagemakerFullAccess and TranscribeFullAccess\n",
"print(f\"SageMaker role is: {role}\\nDefault SageMaker Bucket: s3://{data_bucket}\")\n",
"\n",
"s3=boto3.client('s3')\n",
"transcribe_client=boto3.client('transcribe', region_name=region)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Step 3: Setup input audio file and run Transcribe without moderation \n",
"Run the below cell to upload a sample audio file (mp3) to the default S3 bucket for Transcribe to access."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"#Here we use a file from the datasets directory and upload it to S3. You can modify the name/path for s3_key, location of audio file to upload. \n",
"#Also change the name of job_name if you are rerunning the job.\n",
"s3_key = 'content-moderation-im/audio-moderation/moderation-audio-speech.mp3'\n",
"s3.upload_file('../datasets/moderation-audio-speech.mp3', data_bucket, s3_key)\n",
"file_uri = 's3://'+data_bucket+'/'+s3_key\n",
"print(file_uri)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Call Transcribe **StartTranscriptionJob** API to transcribe the audio to text. Amazon Transcribe StartTranscriptionJob is an asynchronous API that will start a job managed by Transcribe. We will then call the **GetTranscriptionJob** API to check the job status until the job completes."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"import uuid\n",
"job_name = f'audio_moderation_{str(uuid.uuid1())[0:4]}'\n",
"\n",
"transcribe_client.start_transcription_job(\n",
" TranscriptionJobName = job_name,\n",
" Media = {\n",
" 'MediaFileUri': file_uri\n",
" },\n",
" OutputBucketName = data_bucket,\n",
" OutputKey = 'content-moderation-im/audio-moderation/my-output-files/',\n",
" MediaFormat = 'mp3',\n",
" LanguageCode = 'en-US'\n",
" )\n",
"max_tries = 60\n",
"while max_tries > 0:\n",
" max_tries -= 1\n",
" job = transcribe_client.get_transcription_job(TranscriptionJobName = job_name)\n",
" job_status = job['TranscriptionJob']['TranscriptionJobStatus']\n",
" if job_status in ['COMPLETED', 'FAILED']:\n",
" print(f\"Job {job_name} is {job_status}.\")\n",
" if job_status == 'COMPLETED':\n",
" print(\n",
" f\"Download the transcript from\\n\"\n",
" f\"\\t{job['TranscriptionJob']['Transcript']['TranscriptFileUri']}.\")\n",
" break\n",
" else:\n",
" print(f\"Waiting for {job_name}. Current status is {job_status}.\")\n",
" time.sleep(10)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"The job is completed. Transcribe stored the output data to a JSON file in the S3 path specified in the `OutputKey` parameter. We now open the transcribed output JSON file from S3 and check the transcription accuracy. Notice that some of the words may be inappropriate. Identify those words and make a list. "
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"filename = 'content-moderation-im/audio-moderation/my-output-files/'+job_name+'.json'\n",
"s3_clientobj = s3.get_object(Bucket=data_bucket, Key=filename)\n",
"s3_clientdata = s3_clientobj[\"Body\"].read().decode(\"utf-8\")\n",
"original = json.loads(s3_clientdata)\n",
"output_transcript = original[\"results\"][\"transcripts\"]\n",
"print(output_transcript)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Step 4: Create a custom vocabulary file \n",
"Amazon Transcribe allows you to create [Custom Vocabulary Filters](https://docs.aws.amazon.com/transcribe/latest/dg/vocabulary-filtering.html) to delete, mask, or flag words. This section will customize a profanity filter to redact offensive terms while transcribing the audio.\n",
"\n",
"Open the \"my-vocabulary-filter.txt\" file in the datasets directory and see the list of words entered there. If you wish to add additional terms, please do so and save the file. Execute this cell afterwords. We then will upload it to the default S3 bucket for Transcribe to access."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Upload the text file with profane terms to the default S3 bucket\n",
"s3_vocabfile_key = 'content-moderation-im/audio-moderation/my-vocabulary-filters/my-vocabulary-filter.txt'\n",
"s3.upload_file('../datasets/my-vocabulary-filter.txt', data_bucket, s3_vocabfile_key)\n",
"vocab_file_uri = 's3://'+data_bucket+'/'+s3_vocabfile_key\n",
"print(vocab_file_uri)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Now, let's call Transcribe **CreateVocabularyFilter** API to create a new vocabulary filter."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Change the name for vocab_name if you have created a custom vocabulary already\n",
"vocab_name = \"audio-moderation-filter\"\n",
"response = transcribe_client.create_vocabulary_filter(\n",
" LanguageCode = 'en-US',\n",
" VocabularyFilterName = vocab_name,\n",
" VocabularyFilterFileUri = vocab_file_uri\n",
")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Step 5: Run transcribe Job with Custom Vocabulary Filter \n",
"In this step, we will call the same Transcribe `StartTranscriptionJob` API but pass the Vocabulary Filter created in the previous step as an additional parameter under `Settings`. So Transcribe will transcribe the audio to text and apply the profane filter and masking based on the setting."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"#In this case we are running the transcribe job with option to \"mask\" the words. You can also run the job with \"remove\" or \"tag\". \n",
"#In each case, give a new job_name and change the VocabularyFilterMethod to the desired option\n",
"\n",
"job_name = f'transcription_with_audio_moderation_mask_{str(uuid.uuid1())[0:4]}'\n",
"\n",
"transcribe_client.start_transcription_job(\n",
" TranscriptionJobName = job_name,\n",
" Media = {\n",
" 'MediaFileUri': file_uri\n",
" },\n",
" OutputBucketName = data_bucket,\n",
" OutputKey = 'content-moderation-im/audio-moderation/my-output-files/', \n",
" LanguageCode = 'en-US', \n",
" Settings = {\n",
" 'VocabularyFilterName': vocab_name,\n",
" 'VocabularyFilterMethod': 'mask' \n",
" }\n",
")\n",
"\n",
"while True:\n",
" status = transcribe_client.get_transcription_job(TranscriptionJobName = job_name)\n",
" if status['TranscriptionJob']['TranscriptionJobStatus'] in ['COMPLETED', 'FAILED']:\n",
" break\n",
" print(\"Not ready yet...\")\n",
" time.sleep(5)\n",
"print(status)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"The Transcribe job is completed. Now, let's download & open the JSON file from the output directory in S3 and check if the words from the custom vocabulary list have been masked/removed as per the selected option. "
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"filename = 'content-moderation-im/audio-moderation/my-output-files/'+job_name+'.json'\n",
"s3_clientobj = s3.get_object(Bucket=data_bucket, Key=filename)\n",
"s3_clientdata = s3_clientobj[\"Body\"].read().decode(\"utf-8\")\n",
"original = json.loads(s3_clientdata)\n",
"output_transcript = original[\"results\"][\"transcripts\"]\n",
"print(output_transcript)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"As you can see in the above text, Transcribe masked the profane words based on the vocabulary filter we uploaded earlier."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Cleanup : \n",
"We will delete the audio file in the S3 bucket and the Audio Filter in Transcribe to clean up resources and prevent unnecessary costs."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"transcribe_client.delete_vocabulary_filter(VocabularyFilterName=vocab_name)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"s3.delete_object(Bucket=data_bucket, Key=s3_key)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Conclusion : \n",
"In this lab, we learned how to use the custom vocabulary with Amazon transcribe to filter out offensive and profane words."
]
}
],
"metadata": {
"instance_type": "ml.t3.medium",
"kernelspec": {
"display_name": "Python 3 (Data Science)",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.7.10"
},
"vscode": {
"interpreter": {
"hash": "aee8b7b246df8f9039afb4144a1f6fd8d2ca17a180786b69acc140d282b71a49"
}
}
},
"nbformat": 4,
"nbformat_minor": 5
}