{
"cells": [
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Text Moderation - Toxicity Classification\n",
"\n",
"The threat of abuse and harassment online means that many people stop expressing themselves and give up on seeking different opinions. Platforms struggle to effectively facilitate conversations, leading many communities to limit or completely shut down user comments. \n",
"\n",
"Toxicity classification allows customers from Gaming, Social Media, and many other industries automatically classify the user-generated text content and filter out the toxic ones to keep the online environment inclusive.\n",
"\n",
"In this Lab, we will use an AWS AI service - [Comprehend Custom Classfication](https://docs.aws.amazon.com/comprehend/latest/dg/how-document-classification.html) feature to train a custom model to classify toxicity text messages.\n",
"\n",
"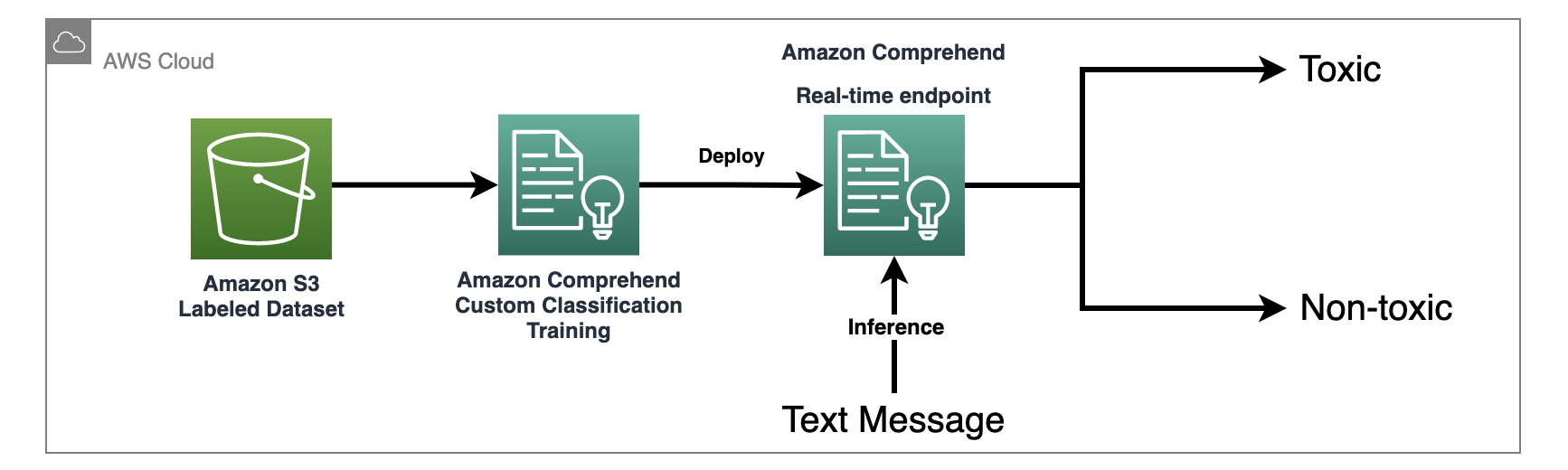"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Toxicity Classficiation\n",
"\n",
"- [Step 1: Setup notebook](#step1)\n",
"- [Step 2: Prepare custom classification training dataset](#step2)\n",
"- [Step 3: Create Amazon Comprehend Classification training job](#step3)\n",
"- [Step 4: Create Amazon Comprehend real time endpoint](#step4)\n",
"- [Step 5: Classify Documents using the real-time endpoint](#step5)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Step 1: Setup Notebook \n",
"Run the below cell to install/update Python dependencies if you run the lab using a local IDE. It is optional if you use a SageMaker Studio Juypter Notebook, which already includes the dependencies in the kernel. "
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# First, let's get the latest installations of our dependencies\n",
"%pip install -qU pip\n",
"%pip install boto3 -qU"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"You can skip the below cell if you are using SageMaker Studio Data Science kernel or they are already installed in your environment."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# install pandas if you are using a local IDE and they are not installed in your env\n",
"%pip install pandas"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"import boto3\n",
"import sagemaker as sm\n",
"import os\n",
"import io\n",
"import datetime\n",
"import pandas as pd\n",
"\n",
"# variables\n",
"data_bucket = sm.Session().default_bucket()\n",
"region = boto3.session.Session().region_name\n",
"\n",
"os.environ[\"BUCKET\"] = data_bucket\n",
"os.environ[\"REGION\"] = region\n",
"role = sm.get_execution_role()\n",
"\n",
"print(f\"SageMaker role is: {role}\\nDefault SageMaker Bucket: s3://{data_bucket}\")\n",
"\n",
"s3=boto3.client('s3')\n",
"comprehend=boto3.client('comprehend', region_name=region)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Step 2: Prepare custom classification training dataset \n",
"Unzip the sample data **toxicity.zip** and decompress files to a local folder"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"!unzip ../datasets/toxicity.zip -d toxicity_dataset"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"This CSV file contains 500 toxic and 500 non-toxic comments from a variety of popular social media platforms. Click on toxicity_en.csv to see a spreadsheet of 1000 English examples.\n",
"\n",
"Columns:\n",
"- text: the text of the comment\n",
"- is_toxic: whether or not the comment is toxic\n",
"\n",
"(The dataset contained in **../datasets/toxicity.zip** is an unaltered redistribution of [the toxicity dataset](https://github.com/surge-ai/toxicity) made available by Surge AI under MIT License.)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"df = pd.read_csv('./toxicity_dataset/toxicity_en.csv')\n",
"df"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### We will use this dataset to train a Comprehend Custom Classification model to classify toxic sentences.\n",
"Comprehend custom classification supports 2 modes: [multi-class](https://docs.aws.amazon.com/comprehend/latest/dg/prep-classifier-data-multi-class.html) or [multi-label](https://docs.aws.amazon.com/comprehend/latest/dg/prep-classifier-data-multi-label.html). Comprehend multi-class mode accepts training datasets in 2 formats: CSV or Augmented manifest file. In this lab, we will train a model in the multi-class mode with the training dataset in CSV format. \n",
"\n",
"For more information, refer to this [doc](https://docs.aws.amazon.com/comprehend/latest/dg/prep-classifier-data-multi-class.html) for more details about the multi-class data format."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Comprehend custom classifiers requires the CSV's first column to be the label and the second column to be the text. The CSV file doesn't require a header. The below code will create a CSV file in the expected format."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"df.to_csv('toxicity-custom-classification.csv', header=False, index=False, columns=['is_toxic','text'])"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Now, let's upload the training data to the S3 bucket, ready for Comprehend to access."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"s3_key = 'content-moderation-im/text-moderation/toxicity-custom-classification.csv'\n",
"s3.upload_file(f'toxicity-custom-classification.csv', data_bucket, s3_key)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Step 3: Create Amazon Comprehend Classification training job \n",
"Once we have a labeled dataset ready we are going to create and train a [Amazon Comprehend custom classification model](https://docs.aws.amazon.com/comprehend/latest/dg/how-document-classification.html) with the dataset.\n",
"\n",
"This job can take ~40 minutes to complete. Once the training job is completed move on to next step."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Create a Toxicity classifier\n",
"account_id = boto3.client('sts').get_caller_identity().get('Account')\n",
"id = str(datetime.datetime.now().strftime(\"%s\"))\n",
"\n",
"document_classifier_name = 'Sample-Toxicity-Classifier-Content-Moderation'\n",
"document_classifier_version = 'v1'\n",
"document_classifier_arn = ''\n",
"response = None\n",
"\n",
"try:\n",
" create_response = comprehend.create_document_classifier(\n",
" InputDataConfig={\n",
" 'DataFormat': 'COMPREHEND_CSV',\n",
" 'S3Uri': f's3://{data_bucket}/{s3_key}'\n",
" },\n",
" DataAccessRoleArn=role,\n",
" DocumentClassifierName=document_classifier_name,\n",
" VersionName=document_classifier_version,\n",
" LanguageCode='en',\n",
" Mode='MULTI_CLASS'\n",
" )\n",
" \n",
" document_classifier_arn = create_response['DocumentClassifierArn']\n",
" \n",
" print(f\"Comprehend Custom Classifier created with ARN: {document_classifier_arn}\")\n",
"except Exception as error:\n",
" if error.response['Error']['Code'] == 'ResourceInUseException':\n",
" print(f'A classifier with the name \"{document_classifier_name}\" already exists.')\n",
" document_classifier_arn = f'arn:aws:comprehend:{region}:{account_id}:document-classifier/{document_classifier_name}/version/{document_classifier_version}'\n",
" print(f'The classifier ARN is: \"{document_classifier_arn}\"')\n",
" else:\n",
" print(error)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Check status of the Comprehend Custom Classification Job"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"%%time\n",
"# Loop through and wait for the training to complete . Takes up to 10 mins \n",
"from IPython.display import clear_output\n",
"import time\n",
"from datetime import datetime\n",
"\n",
"jobArn = create_response['DocumentClassifierArn']\n",
"\n",
"max_time = time.time() + 3*60*60 # 3 hours\n",
"while time.time() < max_time:\n",
" now = datetime.now()\n",
" current_time = now.strftime(\"%H:%M:%S\")\n",
" describe_custom_classifier = comprehend.describe_document_classifier(\n",
" DocumentClassifierArn = jobArn\n",
" )\n",
" status = describe_custom_classifier[\"DocumentClassifierProperties\"][\"Status\"]\n",
" clear_output(wait=True)\n",
" print(f\"{current_time} : Custom document classifier: {status}\")\n",
" \n",
" if status == \"TRAINED\" or status == \"IN_ERROR\":\n",
" break\n",
" \n",
" time.sleep(60)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Alternatively, to create a Comprehend Custom Classifier Job manually using the console go to Amazon Comprehend Console\n",
"- On the left menu click \"Custom Classification\"\n",
"- In the \"Classifier models\" section, click on \"Create new model\"\n",
"- In Model Setting for Model name, enter a name \n",
"- In Data Specification; select \"Using Single-label\" mode and for Data format select CSV file\n",
"- For Training dataset browse to your data-bucket created above and select the file toxicity-custom-classification.csv\n",
"- For IAM role select \"Create an IAM role\" and specify a prefix (this will create a new IAM Role for Comprehend)\n",
"- Click create"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Step 4: Create Amazon Comprehend real time endpoint \n",
"Once our Comprehend custom classifier is fully trained (i.e. status = TRAINED). We can create a real-time endpoint. We will use this endpoint to classify text inputs in real time. The following code cells use the comprehend Boto3 client to create an endpoint, but you can also create one manually via the console. Instructions on how to do that can be found in the subsequent section."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"#create comprehend endpoint\n",
"model_arn = document_classifier_arn\n",
"ep_name = 'toxicity-endpoint'\n",
"\n",
"try:\n",
" endpoint_response = comprehend.create_endpoint(\n",
" EndpointName=ep_name,\n",
" ModelArn=model_arn,\n",
" DesiredInferenceUnits=1, \n",
" DataAccessRoleArn=role\n",
" )\n",
" ENDPOINT_ARN=endpoint_response['EndpointArn']\n",
" print(f'Endpoint created with ARN: {ENDPOINT_ARN}') \n",
"except Exception as error:\n",
" if error.response['Error']['Code'] == 'ResourceInUseException':\n",
" print(f'An endpoint with the name \"{ep_name}\" already exists.')\n",
" ENDPOINT_ARN = f'arn:aws:comprehend:{region}:{account_id}:document-classifier-endpoint/{ep_name}'\n",
" print(f'The classifier endpoint ARN is: \"{ENDPOINT_ARN}\"')\n",
" %store ENDPOINT_ARN\n",
" else:\n",
" print(error)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"display(endpoint_response)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Alternatively, use the steps below to create a Comprehend endpoint using the AWS console.\n",
"- Go to Comprehend on AWS Console and click on Endpoints in the left menu.\n",
"- Click on \"Create endpoint\"\n",
"- Give an Endpoint name; for Custom model type select Custom classification; for version select no version or the latest version of the model.\n",
"- For Classifier model select from the drop down menu\n",
"- For Inference Unit select 1\n",
"- Check \"Acknowledge\"\n",
"- Click \"Create endpoint\"\n",
"\n",
"[It may take ~10 minutes](https://console.aws.amazon.com/comprehend/v2/home?region=us-east-1#endpoints) for the endpoint to get created. The code cell below checks the creation status."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"%%time\n",
"# Loop through and wait for the training to complete . Takes up to 10 mins \n",
"from IPython.display import clear_output\n",
"import time\n",
"from datetime import datetime\n",
"\n",
"ep_arn = endpoint_response[\"EndpointArn\"]\n",
"\n",
"max_time = time.time() + 3*60*60 # 3 hours\n",
"while time.time() < max_time:\n",
" now = datetime.now()\n",
" current_time = now.strftime(\"%H:%M:%S\")\n",
" describe_endpoint_resp = comprehend.describe_endpoint(\n",
" EndpointArn=ep_arn\n",
" )\n",
" status = describe_endpoint_resp[\"EndpointProperties\"][\"Status\"]\n",
" clear_output(wait=True)\n",
" print(f\"{current_time} : Custom document classifier: {status}\")\n",
" \n",
" if status == \"IN_SERVICE\" or status == \"FAILED\":\n",
" break\n",
" \n",
" time.sleep(10)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Step 5: Classify message using the real-time endpoint \n",
"\n",
"Once the endpoint has been created, we will use some sample text messages to classify them into toxic or non-toxic categories."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"response = comprehend.classify_document(\n",
" Text= 'Why don''t you shoot him?! I hate you all!',\n",
" EndpointArn=ENDPOINT_ARN\n",
")\n",
"display(response)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"The inference result returned by Comprehend endpoint contains a \"Classes\" node, a list of labeled classes with a 'Score' representing the confidence score of the inference result.\n",
"\n",
"The above response shows that the text message \"Why don't you shoot him?! I hate you all!\" has a high confidence score (> 99%) for the \"Toxic\" category. You can try different inputs to test the Toxicity classification result."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Cleanup\n",
"Cleanup is optional if you want to execute subsequent notebooks. "
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Delete the Comprehend Endpoint\n",
"resp = comprehend.delete_endpoint(EndpointArn=ENDPOINT_ARN)\n",
"display(resp)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"You will need to wait a few minutes to run the below cell until the Comprehend endpoint is deleted successfully and the classifier is no longer in use."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Delete the Comprehend Custom Classifier \n",
"resp = comprehend.delete_document_classifier(DocumentClassifierArn=document_classifier_arn)\n",
"display(resp)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Conclusion\n",
"\n",
"In this lab, we have trained an Amazon Comprehend custom classifier using a sample toxicity dataset. And deploy the Custom Classifier to a Comprehend endpoint to serve real-time inference. "
]
}
],
"metadata": {
"instance_type": "ml.t3.large",
"kernelspec": {
"display_name": "Python 3 (Data Science)",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.7.10"
},
"vscode": {
"interpreter": {
"hash": "aee8b7b246df8f9039afb4144a1f6fd8d2ca17a180786b69acc140d282b71a49"
}
}
},
"nbformat": 4,
"nbformat_minor": 4
}