# End to end Machine Learning with Amazon SageMaker
## Introduction
The Machine Learning process is an iterative process that consists of several steps:
- Identifying a business problem and the related Machine Learning problem
- Data ingestion, integration and preparation
- Data visualization and analysis, feature engineering, model training and model evaluation
- Model deployment, model monitoring and debugging
The previous steps are generally repeated multiple times to better meet business goals after the source data changes or performance of the model drops, for example.
The process can be represented with the following diagram:
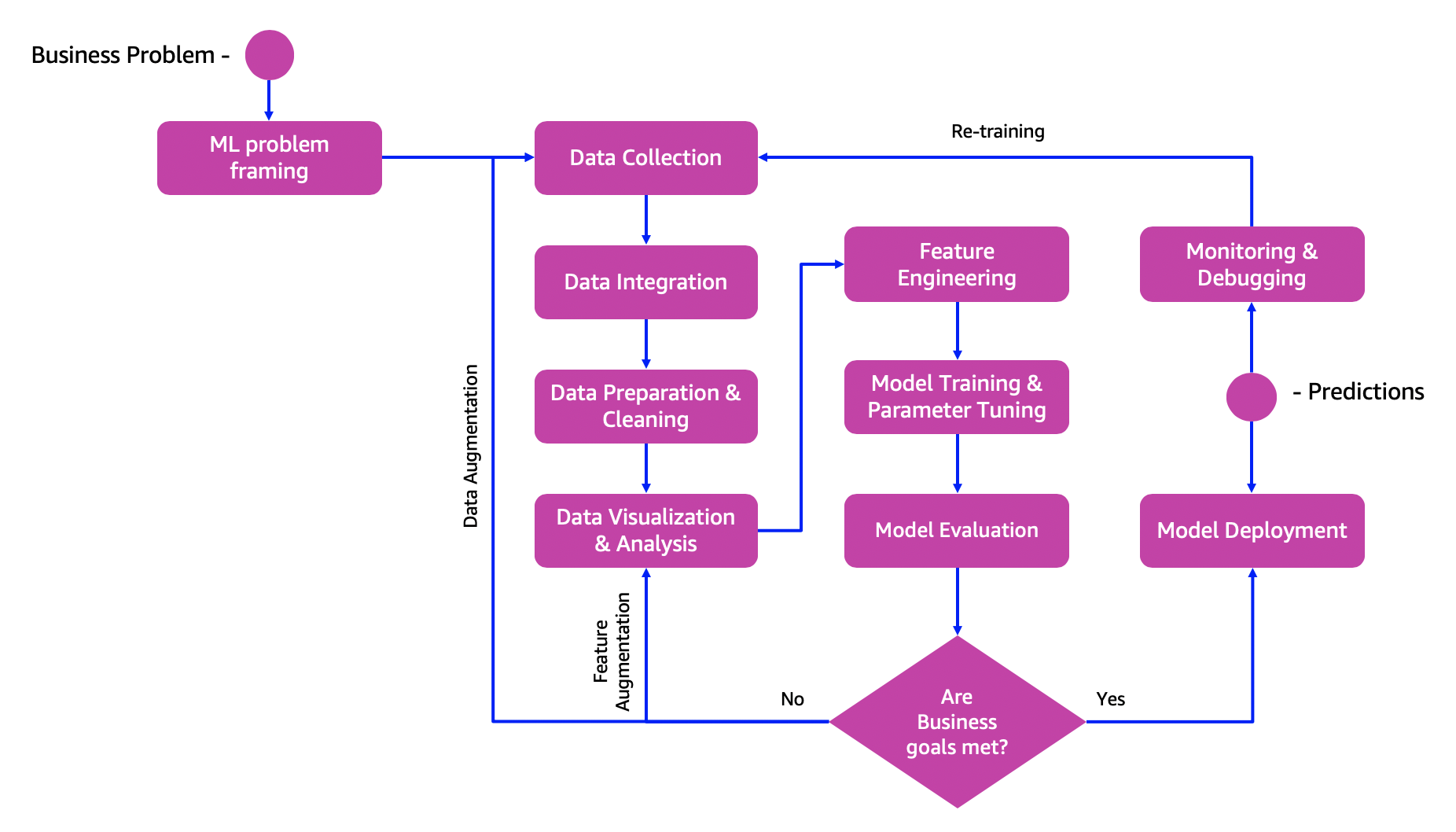 After you deploy a model, you can integrate it with your own application to provide insights to end users.
In this workshop, you will go through the steps required to build a machine learning application on AWS. You will perform an iteration of the Machine Learning process to build, train and deploy a model using Amazon SageMaker. You will then deploy a HTTP API using Amazon API Gateway to perform inferences from a web client. In the last module, you will automate the ML workflow using Amazon SageMaker Pipelines..
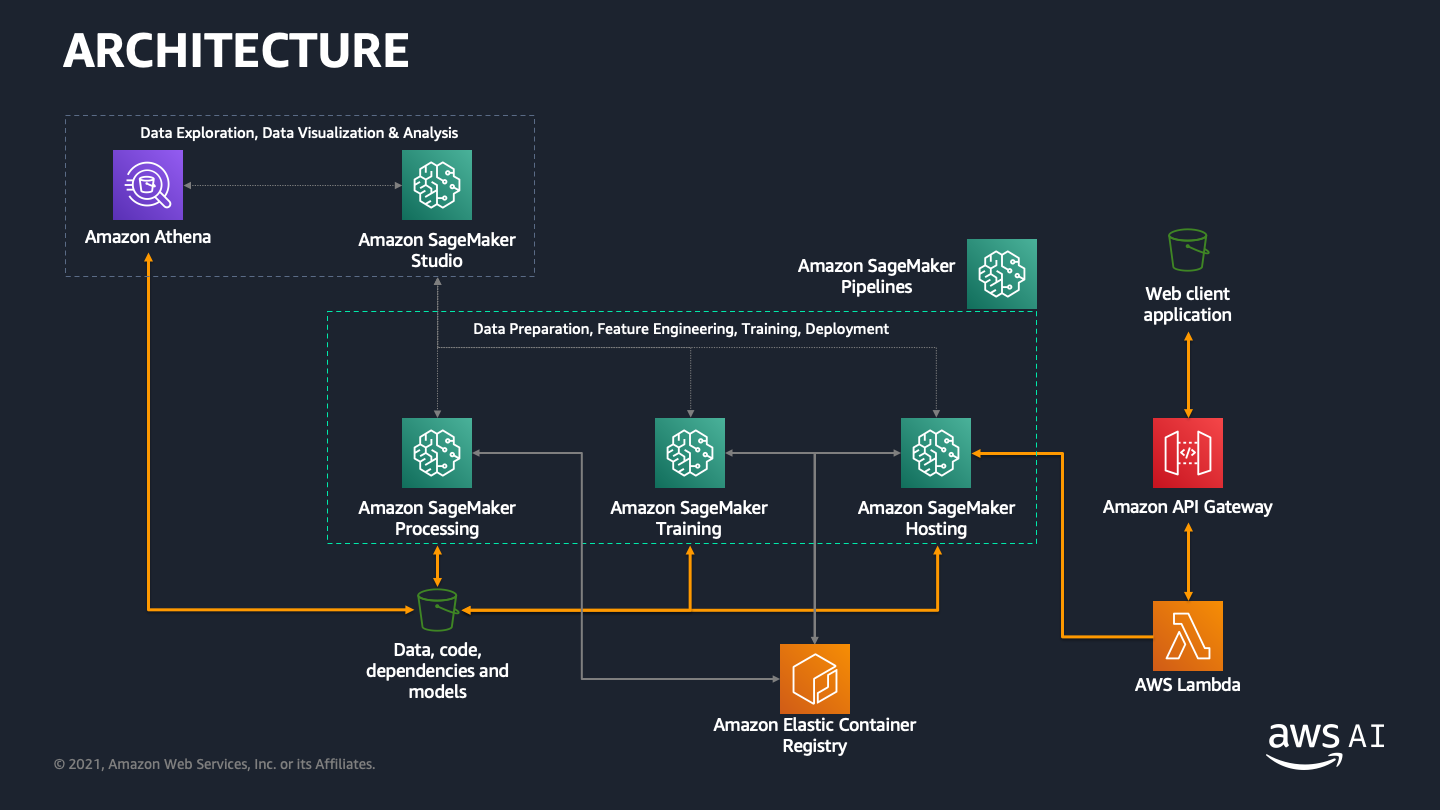
The final architecture is shown below:
After you deploy a model, you can integrate it with your own application to provide insights to end users.
In this workshop, you will go through the steps required to build a machine learning application on AWS. You will perform an iteration of the Machine Learning process to build, train and deploy a model using Amazon SageMaker. You will then deploy a HTTP API using Amazon API Gateway to perform inferences from a web client. In the last module, you will automate the ML workflow using Amazon SageMaker Pipelines..
The final architecture is shown below:
 ## The Machine Learning task
You will use the AI4I 2020 Predictive Maintenance Dataset from the UCI Machine Learning Repository. This synthetic dataset reflects real predictive maintenance data encountered in industry.
The dataset consists of 10000 records and 14 features, representing some measurements that have been collected on the machinery, plus the indication of failure, if any.
> ⚠️ **Note**: This is a basic dataset that oversimplifies the Predictive Maintenance task. However, it keeps this workshop easy to follow while while being a good representative of the various steps of the ML workflow.
Your goal is to build a simple machine learning model that predicts whether a piece of machinery is going to fail (Predictive Maintenance).
Following is an excerpt from the dataset:
|UDI|Product ID|Type|Air temperature [K]|Process temperature [K]|...|Machine failure|
|-------|-------|-------|-------|-------|-------|-------|
|1|M14860|M|298.1|308.6|...|0|
|2|L47181|L|298.2|308.7|...|0|
|3|L47182|L|298.1|308.5|...|0|
|51|L47230|L|298.9|309.1|...|1|
The target variable, **Machine failure**, is a binary attributes, so it suggests the problem is a binary classification problem.
## Modules
This workshops consists of eight modules:
- **Module 01**: Prepare Amazon SageMaker Studio and clone the GitHub repository.
- **Module 02**: Use Amazon SageMaker Studio Notebooks and standard Python libraries to perform fast experimentation.
- **Module 03**: Perform data preprocessing and feature engineering using Amazon SageMaker Processing and SKLearn.
- **Module 04**: Train a binary classification model with the Amazon SageMaker open-source XGBoost container; the model will predict whether the machinery is going to fail. [Optional] Use Sagemaker Debugger to monitor training progress with rules and visualize training metrics like accuracy and feature importance.
- **Module 05**: Deploy the feature engineering and ML models as a pipeline using Amazon SageMaker hosting (inference pipelines). [Optional] Use Sagemaker Model Monitor to track data drift violations against the training data baseline.
- **Module 06**: Build a HTTP API using Amazon API Gateway and create an AWS Lambda function that invokes the Amazon SageMaker endpoint for inference.
- **Module 07**: Use a web client to invoke the HTTP API and get inferences.
- **Module 08**: Use Amazon SageMaker Pipelines to orchestrate the model build workflow and store models in model registry.
Please follow the order of modules because some of the modules depend on the outputs from the previous modules.
## Getting started
We have designed this workshop assuming that each participant is using an AWS account provided and pre-configured by the workshop instructor(s). However, you can also choose to use your own AWS account, but you'll have to execute some preliminary configuration steps as described in the setup directory. If you are using your own AWS account, note that running this workshop will incur costs. You will need to delete the resources you create to avoid incurring further costs after you have completed running the workshop.
Once you are ready to go, please start with **Module 01**.
## License
The contents of this workshop are licensed under the [Apache 2.0 License](./LICENSE).
## Acknowledgements
Dua, D. and Graff, C. (2019). UCI Machine Learning Repository [http://archive.ics.uci.edu/ml]. Irvine, CA: University of California, School of Information and Computer Science.
## Authors
[Giuseppe A. Porcelli](https://it.linkedin.com/in/giuporcelli) - Principal ML Specialist Solutions Architect - Amazon Web Services EMEA
## The Machine Learning task
You will use the AI4I 2020 Predictive Maintenance Dataset from the UCI Machine Learning Repository. This synthetic dataset reflects real predictive maintenance data encountered in industry.
The dataset consists of 10000 records and 14 features, representing some measurements that have been collected on the machinery, plus the indication of failure, if any.
> ⚠️ **Note**: This is a basic dataset that oversimplifies the Predictive Maintenance task. However, it keeps this workshop easy to follow while while being a good representative of the various steps of the ML workflow.
Your goal is to build a simple machine learning model that predicts whether a piece of machinery is going to fail (Predictive Maintenance).
Following is an excerpt from the dataset:
|UDI|Product ID|Type|Air temperature [K]|Process temperature [K]|...|Machine failure|
|-------|-------|-------|-------|-------|-------|-------|
|1|M14860|M|298.1|308.6|...|0|
|2|L47181|L|298.2|308.7|...|0|
|3|L47182|L|298.1|308.5|...|0|
|51|L47230|L|298.9|309.1|...|1|
The target variable, **Machine failure**, is a binary attributes, so it suggests the problem is a binary classification problem.
## Modules
This workshops consists of eight modules:
- **Module 01**: Prepare Amazon SageMaker Studio and clone the GitHub repository.
- **Module 02**: Use Amazon SageMaker Studio Notebooks and standard Python libraries to perform fast experimentation.
- **Module 03**: Perform data preprocessing and feature engineering using Amazon SageMaker Processing and SKLearn.
- **Module 04**: Train a binary classification model with the Amazon SageMaker open-source XGBoost container; the model will predict whether the machinery is going to fail. [Optional] Use Sagemaker Debugger to monitor training progress with rules and visualize training metrics like accuracy and feature importance.
- **Module 05**: Deploy the feature engineering and ML models as a pipeline using Amazon SageMaker hosting (inference pipelines). [Optional] Use Sagemaker Model Monitor to track data drift violations against the training data baseline.
- **Module 06**: Build a HTTP API using Amazon API Gateway and create an AWS Lambda function that invokes the Amazon SageMaker endpoint for inference.
- **Module 07**: Use a web client to invoke the HTTP API and get inferences.
- **Module 08**: Use Amazon SageMaker Pipelines to orchestrate the model build workflow and store models in model registry.
Please follow the order of modules because some of the modules depend on the outputs from the previous modules.
## Getting started
We have designed this workshop assuming that each participant is using an AWS account provided and pre-configured by the workshop instructor(s). However, you can also choose to use your own AWS account, but you'll have to execute some preliminary configuration steps as described in the setup directory. If you are using your own AWS account, note that running this workshop will incur costs. You will need to delete the resources you create to avoid incurring further costs after you have completed running the workshop.
Once you are ready to go, please start with **Module 01**.
## License
The contents of this workshop are licensed under the [Apache 2.0 License](./LICENSE).
## Acknowledgements
Dua, D. and Graff, C. (2019). UCI Machine Learning Repository [http://archive.ics.uci.edu/ml]. Irvine, CA: University of California, School of Information and Computer Science.
## Authors
[Giuseppe A. Porcelli](https://it.linkedin.com/in/giuporcelli) - Principal ML Specialist Solutions Architect - Amazon Web Services EMEA
[Antonio Duma](https://it.linkedin.com/in/antoniod82) - Senior Startup Solutions Architect - Amazon Web Services EMEA
[Hasan Poonawala](https://www.linkedin.com/in/hasanp) - Senior ML Specialist Solutions Architect - Amazon Web Services EMEA
[Mehran Nikoo](https://www.linkedin.com/in/mnikoo/) - Senior Digital Native Business Solutions Architect - Amazon Web Services EMEA
[Bruno Pistone](https://www.linkedin.com/in/bpistone) - AI/ML Specialist Solutions Architect - Amazon Web Services WW
[Durga Sury](https://www.linkedin.com/in/durgasury) - ML Solution Architect - Amazon Web Services