{
"cells": [
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Train and Deploy GPT-J-6B model using Tensor Parallelism approach within SageMaker Model Parallel Library"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"In this notebook you will learn how to use the tensor parallelism feature provided by the [SageMaker Model Parallelism Library](https://docs.aws.amazon.com/sagemaker/latest/dg/model-parallel.html) to train the [EleutherAI's](https://www.eleuther.ai/) [GPT-J](https://arankomatsuzaki.wordpress.com/2021/06/04/gpt-j/) Model using the [GLUE/sst2 Dataset](https://huggingface.co/datasets/glue/viewer/sst2/train).\n",
"\n",
"EleutherAI released GPT-J 6B, an open-source alternative to [OpenAIs GPT-3](https://openai.com/blog/gpt-3-apps/). [GPT-J 6B](https://huggingface.co/EleutherAI/gpt-j-6B) is the 6 billion parameter successor to EleutherAIs GPT-NEO family, a family of transformer-based language models based on the GPT architecture for text generation.\n",
"\n",
"EleutherAI's primary goal is to train a model that is equivalent in size to GPT-3 and make it available to the public under an open license.\n",
"Over the last few months, GPT-J gained a lot of interest from Researchers, Data Scientists, and even Software Developers, but it remained very challenging to fine tune GPT-J.\n",
"\n",
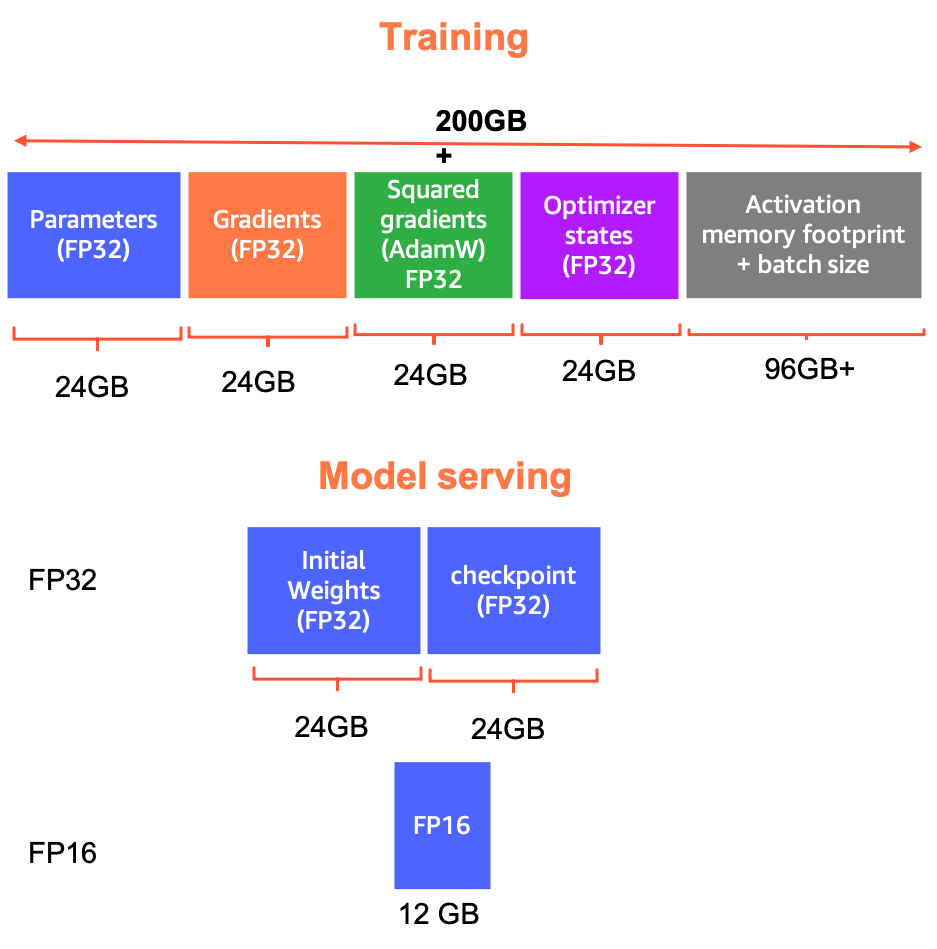
"The weights of the 6 billion parameter model represent a ~24GB memory footprint. To load it in float32, one would need at least 2x model size CPU RAM: 1x for initial weights and another 1x to load the checkpoint. Apart from the model parameters, there are the gradients, optimizer states, and activations taking memory, so the actual memory usage might be significantly higher than 48GB. Just as an example, with Adam optimizer and FP32 training, the use from parameters, gradients and optimizer states might be 96GB+, and activation memory footprint would be even more than this, so the total memory usage might be easily larger than 200 GB.\n",
"\n",
"\n",
"\n",
"We will walk you through how to easily run FP16 training and fine tune GPT-J using Amazon SageMaker and Hugging Face on NVIDIA GPU instances. The notebook demonstrates the use of Tensor Parallel approach of SageMaker Model Parallel library. \n",
"\n",
"This notebook depends on the following files and folders:\n",
"\n",
"1. `train_gptj_smp_tensor_parallel_script.py`: This is an entry-point script that is passed to the PyTorch estimator in the notebook instructions. This script is responsible for end to end training of the GPT-J model with SMP. The script has additional comments at places where the SMP API is used.\n",
"\n",
"3. `learning_rates.py`: This contains the functions for learning rate schedule.\n",
"4. `requirements.txt`: This will install the dependencies, like the right version of huggingface transformers.\n",
"5. `memory_tracker.py`: This contains a function to print the memory status.\n",
"\n",
"\n",
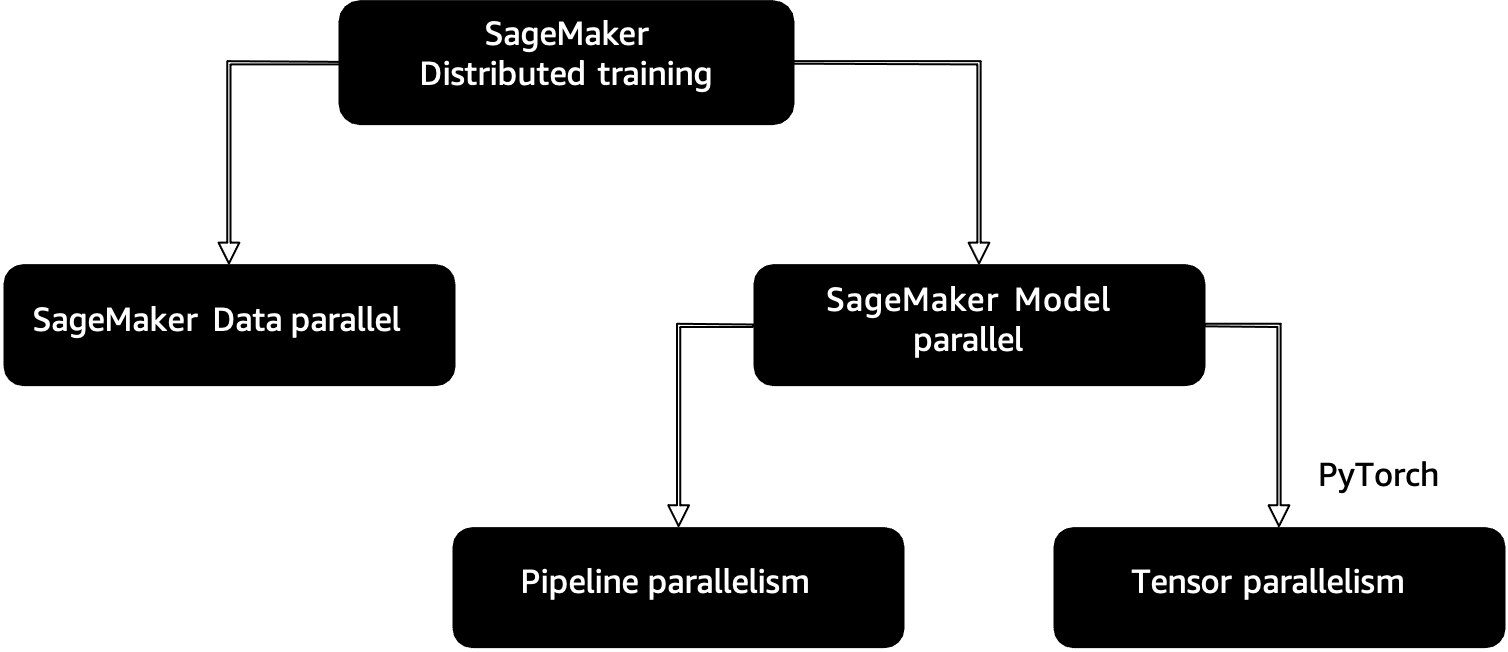
"## SageMaker Distributed Training \n",
"\n",
"SageMaker provides distributed training libraries for data parallelism and model parallelism. The libraries are optimized for the SageMaker training environment, help adapt your distributed training jobs to SageMaker, and improve training speed and throughput.\n",
"\n",
"### Approaches\n",
"\n",
"\n",
"\n",
"\n",
"### SageMaker Model Parallel\n",
"\n",
"Model parallelism is the process of splitting a model up between multiple devices or nodes (such as GPU-equipped instances) and creating an efficient pipeline to train the model across these devices to maximize GPU utilization.\n",
"\n",
"Increasing deep learning model size (layers and parameters) can result in better accuracy. However, there is a limit to the maximum model size you can fit in a single GPU. When training deep learning models, GPU memory limitations can be a bottleneck in the following ways:\n",
"\n",
"1. They can limit the size of the model you train. Given that larger models tend to achieve higher accuracy, this directly translates to trained model accuracy.\n",
"\n",
"2. They can limit the batch size you train with, leading to lower GPU utilization and slower training.\n",
"\n",
"To overcome the limitations associated with training a model on a single GPU, you can use model parallelism to distribute and train your model on multiple computing devices.\n",
"\n",
"### Core features of SageMaker Model Parallel \n",
"\n",
"1. [Automated Model Splitting](https://docs.aws.amazon.com/sagemaker/latest/dg/model-parallel-core-features.html): When you use SageMaker's model parallel library, you can take advantage of automated model splitting, also referred to as automated model partitioning. The library uses a partitioning algorithm that balances memory, minimizes communication between devices, and optimizes performance. You can configure the automated partitioning algorithm to optimize for speed or memory.\n",
"\n",
"2. [Pipeline Execution Schedule](https://docs.aws.amazon.com/sagemaker/latest/dg/model-parallel-core-features.html): A core feature of SageMaker's distributed model parallel library is pipelined execution, which determines the order in which computations are made and data is processed across devices during model training. Pipelining is a technique to achieve true parallelization in model parallelism, by having the GPUs compute simultaneously on different data samples, and to overcome the performance loss due to sequential computation.\n",
"\n",
"Pipelining is based on splitting a mini-batch into microbatches, which are fed into the training pipeline one-by-one and follow an execution schedule defined by the library runtime. A microbatch is a smaller subset of a given training mini-batch. The pipeline schedule determines which microbatch is executed by which device for every time slot.\n",
"\n",
"In addition to its [core features](https://docs.aws.amazon.com/sagemaker/latest/dg/model-parallel-core-features.html), the SageMaker distributed model parallel library offers [memory-saving features](https://docs.aws.amazon.com/sagemaker/latest/dg/model-parallel-extended-features-pytorch.html) for training deep learning models with PyTorch: [tensor parallelism](https://docs.aws.amazon.com/sagemaker/latest/dg/model-parallel-extended-features-pytorch-tensor-parallelism.html), [optimizer state sharding](https://docs.aws.amazon.com/sagemaker/latest/dg/model-parallel-extended-features-pytorch-optimizer-state-sharding.html), [activation checkpointing](https://docs.aws.amazon.com/sagemaker/latest/dg/model-parallel-extended-features-pytorch-activation-checkpointing.html), and [activation offloading](https://docs.aws.amazon.com/sagemaker/latest/dg/model-parallel-extended-features-pytorch-activation-offloading.html). "
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### SageMaker Model Parallel configuration\n",
"\n",
"Please refer to all the [configuration parameters](https://sagemaker.readthedocs.io/en/stable/api/training/smd_model_parallel_general.html) related to SageMaker Distributed Training.\n",
"\n",
"As we are going to use PyTorch and Hugging Face for training GPT-J, it is important to understand all the SageMaker Distributed configuration parameters specific to PyTorch [here](https://sagemaker.readthedocs.io/en/stable/api/training/smd_model_parallel_general.html#pytorch-specific-parameters).\n",
"\n",
"#### Important\n",
"\n",
"`process_per_host` must not be greater than the number of GPUs per instance and typically will be equal to the number of GPUs per instance.\n",
"\n",
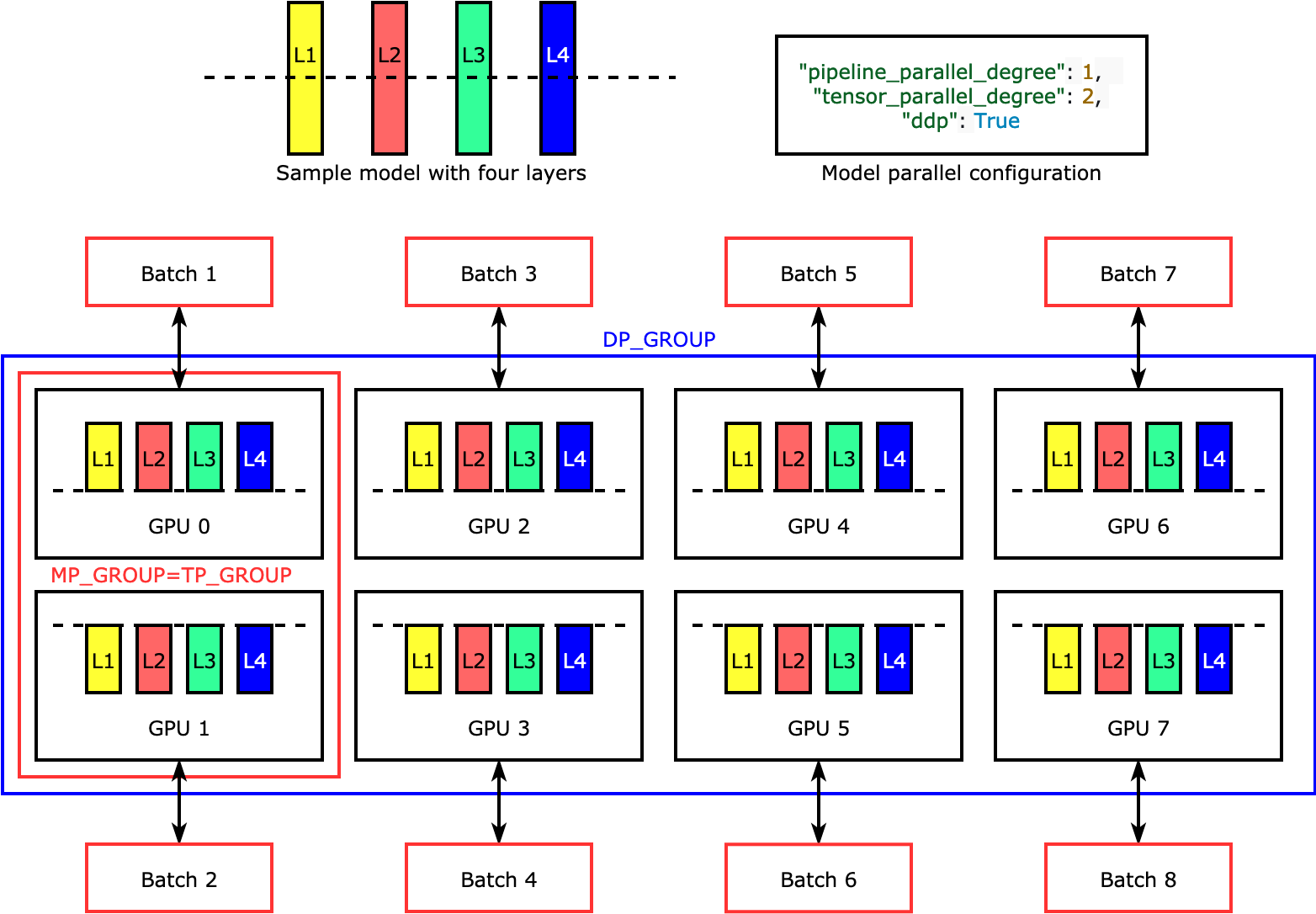
"#### SageMaker Tensor Parallel\n",
"\n",
"Tensor parallelism splits individual layers, or nn.Modules, across devices, to be run in parallel. The following figure shows the simplest example of how the library splits a model with four layers to achieve two-way tensor parallelism (\"tensor_parallel_degree\": 2). The layers of each model replica are bisected and distributed into two GPUs. In this example case, the model parallel configuration also includes \"pipeline_parallel_degree\": 1 and \"ddp\": True (uses PyTorch DistributedDataParallel package in the background), so the degree of data parallelism becomes eight. The library manages communication across the tensor-distributed model replicas.\n",
"\n",
"\n",
"\n",
"The usefulness of this feature is in the fact that you can select specific layers or a subset of layers to apply tensor parallelism. To dive deep into tensor parallelism and other memory-saving features for PyTorch, and to learn how to set a combination of pipeline and tensor parallelism, see Extended Features of the SageMaker Model Parallel Library for PyTorch.\n",
"\n",
"\n",
"\n",
"#### Additional Resources\n",
"If you are a new user of Amazon SageMaker, you may find the following helpful to learn more about SMP and using SageMaker with PyTorch.\n",
"\n",
"1. To learn more about the SageMaker model parallelism library, see [Model Parallel Distributed Training with SageMaker Distributed](https://docs.aws.amazon.com/sagemaker/latest/dg/model-parallel.html).\n",
"\n",
"2. To learn more about using the SageMaker Python SDK with PyTorch, see Using [PyTorch with the SageMaker Python SDK](https://sagemaker.readthedocs.io/en/stable/frameworks/pytorch/using_pytorch.html).\n",
"\n",
"3. To learn more about launching a training job in Amazon SageMaker with your own training image, see [Use Your Own Training Algorithms](https://docs.aws.amazon.com/sagemaker/latest/dg/your-algorithms-training-algo.html)."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
"Kernel Selection
\n",
"Please run this notebook using either the Data Science, Python 3 Kernel on SageMaker Studio Notebook or a conda_pytorch_p38 Kernel on SageMaker Notebook instances.\n",
"
"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Install and Upgrade Libraries\n",
"\n",
"The SageMaker model parallelism library's tensor parallelism feature requires the SageMaker Python SDK and the SageMaker Experiments library. Run the following cell to install or upgrade the libraries.\n",
"\n",
"\n",
"Kernel Restart: To finish applying the changes, you must restart the kernel.\n",
"
"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"scrolled": true,
"tags": []
},
"outputs": [],
"source": [
"# run once, restart kernel, then comment out this cell\n",
"%pip install -qU pip\n",
"%pip install -qU \"sagemaker>=2,<3\"\n",
"%pip install -qU sagemaker-experiments\n",
"%pip install -qU transformers datasets\n",
"\n",
"import IPython\n",
"\n",
"IPython.Application.instance().kernel.do_shutdown(True)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
">**Note:** After you run the above cell, comment it out for future runs."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Import and check if the SageMaker Python SDK version is successfully set to the latest version\n",
"\n",
"#### Check SageMaker Version"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"import sagemaker\n",
"\n",
"print(sagemaker.__version__)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Amazon SageMaker Initialization\n",
"\n",
"Throughout this example, you'll use a training script of GPT-J model and a small text dataset. "
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Run the following cell to import SageMaker modules and retrieve information of your current SageMaker work environment: your AWS account ID, the AWS Region you are using to run the notebook, and the ARN of your Amazon SageMaker execution role."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"%%time\n",
"import os\n",
"\n",
"from sagemaker import get_execution_role\n",
"from sagemaker.huggingface import HuggingFace\n",
"from smexperiments.experiment import Experiment\n",
"from smexperiments.trial import Trial\n",
"import boto3\n",
"\n",
"role = (\n",
" get_execution_role()\n",
") # provide a pre-existing role ARN as an alternative to creating a new role\n",
"print(f\"SageMaker Execution Role:{role}\")\n",
"\n",
"client = boto3.client(\"sts\")\n",
"account = client.get_caller_identity()[\"Account\"]\n",
"print(f\"AWS account:{account}\")\n",
"\n",
"session = boto3.session.Session()\n",
"region = session.region_name\n",
"print(f\"AWS region:{region}\")\n",
"\n",
"sm_boto_client = boto3.client(\"sagemaker\")\n",
"\n",
"sagemaker_session = sagemaker.session.Session(boto_session=session)\n",
"\n",
"\n",
"# get default bucket\n",
"default_bucket = sagemaker_session.default_bucket()\n",
"print()\n",
"print(\"Default bucket for this session: \", default_bucket)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"_This completes the SageMaker setup._"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Download and Prepare glue/sst2 Data\n",
"In this section you will download and prepare the glue/sst2 dataset, then copy the files to S3. This is done because the `train_gptj_smp_tensor_parallel_script.py` requires either S3 input or paths in an FSx file system of an already tokenized dataset. However, FSX for Lustre configuration is not a part of this notebook.\n",
"\n",
"The General Language Understanding Evaluation (GLUE) benchmark is a collection of resources for training, evaluating and analyzing Natural Language Understanding (NLU) systems. Additional information about [GLUE](https://gluebenchmark.com/) .\n",
"\n",
"The Standford Sentiment Analysis Treeback (glue/sst2) consists of sentences from movie reviews and human annotation of their sentiments. The task is to predict the sentiment of a given sentence. It uses the two-way (positive/negative) class split, with only sentence-level labels. Further information on [glue/sst2](https://nlp.stanford.edu/sentiment/index.html).\n",
"\n",
"We are now ready to begin training and tuning the GPT-J model."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### 0. Import Libraries and Specify Parameters"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Datasets is a library for easily accessing and sharing data for various applications including Natural Language Processing (NLP), Computer Vision and Audio."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"# Import the GLUE dataset\n",
"import datasets\n",
"from datasets import load_dataset, load_from_disk, load_metric"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Since the training script is written in Pytorch, you need to import the PyTorch estimator class."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"from sagemaker.pytorch import PyTorch\n",
"import transformers\n",
"import logging\n",
"\n",
"from transformers import (\n",
" AutoTokenizer,\n",
")\n",
"\n",
"from transformers.testing_utils import CaptureLogger"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"logger = logging.getLogger(__name__)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Next, you define the dataset configuration."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"data_config = {\n",
" \"dataset_name\": \"glue\",\n",
" \"dataset_config_name\": \"sst2\",\n",
" \"do_train\": True,\n",
" \"do_eval\": True,\n",
" \"cache_dir\": \"tmp\",\n",
"}"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### 1. Load data\n",
"This section loads the dataset and splits it to training and validation datasets."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"raw_datasets = load_dataset(\n",
" data_config[\"dataset_name\"],\n",
" data_config[\"dataset_config_name\"],\n",
")"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"# If the dataset is not split, then create 5% training split\n",
"if \"validation\" not in raw_datasets.keys():\n",
" raw_datasets[\"validation\"] = load_dataset(\n",
" data_config[\"dataset_name\"],\n",
" data_config[\"dataset_config_name\"],\n",
" split=\"train[:5%]\",\n",
" cache_dir=data_config[\"cache_dir\"],\n",
" )\n",
"\n",
" raw_datasets[\"train\"] = load_dataset(\n",
" data_config[\"dataset_name\"],\n",
" data_config[\"dataset_config_name\"],\n",
" split=\"train[5%:]\",\n",
" cache_dir=data_config[\"cache_dir\"],\n",
" )"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### 2. Load tokenizer\n",
"Nearly every NLP task requires a tokenization. A tokenizer converts your input into smaller units, usually words or subwords that can be easily ingested by a model. In many cases, the architecture you want to use can be guessed from the name or path of the pretrained model passed to the from_pretrained() method. AutoClasses are here to do this job for you so that you automatically retrieve the relevant model based on the name/path to the pretrained weights/config/vocabulary. You can learn more about HuggingFace [Auto Classes](https://huggingface.co/docs/transformers/model_doc/auto).\n",
"\n",
"The following cell loads a tokenizer with [AutoTokenizer.from_pretrained()](https://huggingface.co/docs/transformers/v4.19.4/en/autoclass_tutorial#autotokenizer)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"scrolled": true,
"tags": []
},
"outputs": [],
"source": [
"# Load a tokenizer using the AutoTokenizer Auto Class\n",
"tokenizer_kwargs = {\n",
" \"cache_dir\": data_config[\"cache_dir\"],\n",
"}\n",
"\n",
"tokenizer = AutoTokenizer.from_pretrained(\"EleutherAI/gpt-j-6B\", **tokenizer_kwargs)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### 3. Preprocess data"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"This section preprocesses the raw sst2 dataset in two steps. First, the dataset is tokenized, next the block-size is set and the tokenized dataset is concatenated into block-sized chunks.\n",
"\n",
"Define the `tokenize` and `concatenation` helper functions."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"# Tokenizer helper function\n",
"def tokenize_function(examples):\n",
" tok_logger = transformers.utils.logging.get_logger(\n",
" \"transformers.tokenization_utils_base\"\n",
" )\n",
"\n",
" with CaptureLogger(tok_logger) as cl:\n",
" output = tokenizer(examples[text_column_name])\n",
" # clm input could be much much longer than block_size\n",
" if \"Token indices sequence length is longer than the\" in cl.out:\n",
" tok_logger.warning(\n",
" \"^^^^^^^^^^^^^^^^ Please ignore the warning above - this long input will be chunked into smaller bits before being passed to the model.\"\n",
" )\n",
" return output\n",
"\n",
"\n",
"# Main data processing function that will concatenate all texts from our dataset and generate chunks of block_size.\n",
"def group_texts(examples):\n",
" # Concatenate all texts.\n",
" concatenated_examples = {k: sum(examples[k], []) for k in examples.keys()}\n",
" total_length = len(concatenated_examples[list(examples.keys())[0]])\n",
" # We drop the small remainder, we could add padding if the model supported it instead of this drop, you can\n",
" # customize this part to your needs.\n",
" if total_length >= block_size:\n",
" total_length = (total_length // block_size) * block_size\n",
" # Split by chunks of max_len.\n",
" result = {\n",
" k: [t[i : i + block_size] for i in range(0, total_length, block_size)]\n",
" for k, t in concatenated_examples.items()\n",
" }\n",
" result[\"labels\"] = result[\"input_ids\"].copy()\n",
" return result"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"The following code block tokenizes the raw dataset, sets the block-size to 1024 and concatenates the tokenized dataset."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"# Get the column names from the training raw dataset and set the movie review sentence column\n",
"column_names = raw_datasets[\"train\"].column_names\n",
"text_column_name = \"text\" if \"text\" in column_names else column_names[0]\n",
"\n",
"# since this will be pickled to avoid _LazyModule error in Hasher force logger loading before tokenize_function\n",
"tok_logger = transformers.utils.logging.get_logger(\n",
" \"transformers.tokenization_utils_base\"\n",
")\n",
"\n",
"tokenized_datasets = raw_datasets.map(\n",
" tokenize_function,\n",
" batched=True,\n",
" num_proc=1,\n",
" remove_columns=column_names,\n",
" desc=\"Running tokenizer on dataset\",\n",
")\n",
"\n",
"\n",
"block_size = tokenizer.model_max_length\n",
"if block_size > 1024:\n",
" logger.warning(\n",
" f\"The tokenizer picked seems to have a very large `model_max_length` ({tokenizer.model_max_length}). \"\n",
" \"Picking 1024 instead. You can change that default value by passing --block_size xxx.\"\n",
" )\n",
" block_size = 1024\n",
"else:\n",
" if args.block_size > tokenizer.model_max_length:\n",
" logger.warning(\n",
" f\"The block_size passed ({block_size}) is larger than the maximum length for the model\"\n",
" f\"({tokenizer.model_max_length}). Using block_size={tokenizer.model_max_length}.\"\n",
" )\n",
" block_size = min(block_size, tokenizer.model_max_length)\n",
"\n",
"lm_datasets = tokenized_datasets.map(\n",
" group_texts,\n",
" batched=True,\n",
" # num_proc=args.preprocessing_num_workers,\n",
" desc=f\"Grouping texts in chunks of {block_size}\",\n",
")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Next, check to see that training and validation data exist in the tokenized dataset."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"# check to see if train and validation is set in the config\n",
"if data_config[\"do_train\"]:\n",
" if \"train\" not in tokenized_datasets:\n",
" raise ValueError(\"--do_train requires a train dataset\")\n",
" train_dataset = lm_datasets[\"train\"]\n",
"\n",
"\n",
"if data_config[\"do_eval\"]:\n",
" if \"validation\" not in tokenized_datasets:\n",
" raise ValueError(\"--do_eval requires a validation dataset\")\n",
" eval_dataset = lm_datasets[\"validation\"]"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Convert a dataset object to json and set the s3 bucket locations for the training and validation tokenized datasets."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"training_dataset_location = None\n",
"validation_dataset_location = None\n",
"\n",
"\n",
"if data_config[\"do_train\"]:\n",
" train_dataset.to_json(\"./training.json\")\n",
" training_dataset_location = \"s3://{}/dataset/train/\".format(default_bucket)\n",
" object_name_training = \"dataset/train/training.json\"\n",
"\n",
"if data_config[\"do_eval\"]:\n",
" eval_dataset.to_json(\"./validation.json\")\n",
" validation_dataset_location = \"s3://{}/dataset/validation/\".format(default_bucket)\n",
" object_name_validation = \"dataset/validation/validation.json\""
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Upload training and validation tokenized datasets to the s3 bucket."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"# upload the training and validation data to s3\n",
"import boto3\n",
"\n",
"s3_client = boto3.client(\"s3\")\n",
"\n",
"if training_dataset_location is not None:\n",
" response = s3_client.upload_file(\n",
" \"./training.json\", default_bucket, object_name_training\n",
" )\n",
"\n",
"if validation_dataset_location is not None:\n",
" response = s3_client.upload_file(\n",
" \"./validation.json\", default_bucket, object_name_validation\n",
" )"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"# clean up local dir\n",
"if data_config[\"do_train\"]:\n",
" command = \"rm ./training.json\"\n",
" os.system(command)\n",
"\n",
"if data_config[\"do_eval\"]:\n",
" command = \"rm ./validation.json\"\n",
" os.system(command)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### 4. SageMaker Tensor Parallel Training\n",
"\n",
"In the cells above you downloaded, preprocessed and split the glue/sst2 dataset into training and validation datasets. And finally uploaded the json files to an s3 bucket in your AWS account.\n",
"\n",
"\n",
"AWS S3 Region
\n",
"The S3 bucket used to store your training and validation data must be in the same AWS region as you training jobs.\n",
"
\n",
"\n",
"You will use these files to train a GPT-J model using SageMaker Tensor Parallel training jobs.\n",
"\n",
"After you successfully run this example tensor parallel training job, you can modify the S3 bucket to where your own dataset is stored.\n",
"\n",
"Set the S3 bucket location for model training input and output."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"s3_train_bucket = training_dataset_location\n",
"s3_test_bucket = validation_dataset_location\n",
"s3_output_bucket = f\"s3://sagemaker-{region}-{account}/smp-tensorparallel-outputdir/\""
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Define Data Channels for SageMaker Training\n",
"\n",
"Set the SageMaker training data channels using the s3 locations for training and validation data."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"train = sagemaker.inputs.TrainingInput(\n",
" s3_train_bucket, distribution=\"FullyReplicated\", s3_data_type=\"S3Prefix\"\n",
")\n",
"test = sagemaker.inputs.TrainingInput(\n",
" s3_test_bucket, distribution=\"FullyReplicated\", s3_data_type=\"S3Prefix\"\n",
")\n",
"data_channels = {\"train\": train, \"test\": test}"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"s3_train_bucket"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Set Model Hyperparameters and Model Options\n",
"Define the model Hyperparameters, custom [Message Passing Interface(MPI)](https://docs.aws.amazon.com/sagemaker/latest/dg/data-parallel-config.html#data-parallel-config-mpi-custom) options, and any metrics definitions.\n",
"\n",
"The following model hyperparameters are particularly noteworthy:\n",
"\n",
"- \"fp16”: 1 - half precision enabled to save GPU memory,\n",
"- \"“save_final_full_model”: 1 - saving a full model from the last step, supported only if sharded data parallelism is disabled,\n",
"- “manual_partition”: 0 - disabled which means that library splits model automatically,\n",
"- “shard_optimizer_state”: 1 - optimizer state is sharded across data parallel group,\n",
"- “activation_checkpointing”: 1 - clearing activations of certain layers to reduce memory usage enabled."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"hyperparameters = {\n",
" \"max_steps\": 100,\n",
" \"seed\": 12345,\n",
" \"fp16\": 1,\n",
" \"lr\": 2.0e-4,\n",
" \"lr_decay_iters\": 125000,\n",
" \"min_lr\": 0.00001,\n",
" \"lr-decay-style\": \"linear\",\n",
" \"warmup\": 0.01,\n",
" \"num_kept_checkpoints\": 1,\n",
" \"checkpoint_freq\": 200,\n",
" \"validation_freq\": 1000,\n",
" \"logging_freq\": 10,\n",
" \"save_final_full_model\": 1,\n",
" \"manual_partition\": 0,\n",
" \"shard_optimizer_state\": 1,\n",
" \"activation_checkpointing\": 0,\n",
" \"activation_strategy\": \"each\",\n",
" \"optimize\": \"speed\",\n",
" # below flag loads model and optimizer state from checkpoint_s3_uri\n",
" # 'load_partial': 1,\n",
"}\n",
"\n",
"mpioptions = \"-x NCCL_DEBUG=WARN -x SMDEBUG_LOG_LEVEL=ERROR \"\n",
"mpioptions += \"-x SMP_DISABLE_D2D=1 -x SMP_D2D_GPU_BUFFER_SIZE_BYTES=1 -x SMP_NCCL_THROTTLE_LIMIT=1 \"\n",
"mpioptions += \"-x FI_EFA_USE_DEVICE_RDMA=1 -x FI_PROVIDER=efa -x RDMAV_FORK_SAFE=1\"\n",
"\n",
"metric_definitions = [\n",
" {\"Name\": \"base_metric\", \"Regex\": \"<><><><><><>\"}\n",
"] # Add your custom metric definitions"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Set the model configuration below.\n",
"\n",
"GPU Requirements
\n",
"GPT-J-6B requires at least one EC2 instance type of either g5.48xlarge, p3dn.24xlarge, p4d.24xlarge (or multiple smaller GPU instance types). You can use a single smaller GPU instance type with the GPT-J-XL 1.5B parameter model.\n",
"
"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"model_config = \"gpt-j-xl\"\n",
"\n",
"if model_config == \"gpt-j-6B\":\n",
" model_params = {\n",
" \"tensor_parallel_degree\": 8,\n",
" \"pipeline_parallel_degree\": 1,\n",
" # if sharded data par degree >1 -> tensor 1 pipeline 1 shard_optimizer_state to be set to False\n",
" \"sharded_data_parallel_degree\": 1,\n",
" \"train_batch_size\": 8,\n",
" \"val_batch_size\": 8,\n",
" \"prescaled_batch\": 1,\n",
" \"max_context_width\": 2048,\n",
" \"use_distributed_transformer\": 1,\n",
" \"finetune_6b\": 1,\n",
" }\n",
"elif model_config == \"gpt-j-xl\":\n",
" model_params = {\n",
" \"tensor_parallel_degree\": 8,\n",
" \"pipeline_parallel_degree\": 1,\n",
" \"sharded_data_parallel_degree\": 1,\n",
" \"train_batch_size\": 4,\n",
" \"val_batch_size\": 4,\n",
" \"prescaled_batch\": 1,\n",
" \"hidden_width\": 1600,\n",
" \"num_heads\": 25,\n",
" \"num_layers\": 48,\n",
" \"finetune_6b\": 0,\n",
" }\n",
"\n",
"for k, v in model_params.items():\n",
" hyperparameters[k] = v"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Set Up SageMaker Studio Experiment\n",
"Create a SageMaker Experiment for the training job.\n",
"\n",
"[SageMaker Experiments](https://docs.aws.amazon.com/sagemaker/latest/dg/experiments.html) allows you to automatically track input and output artifacts, (hyper-)parameters, metrics of your machine learning pipelines. You can efficiently manage your model development process by view, analyzing and comparing experimentation results."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"from time import gmtime, strftime\n",
"\n",
"# Specify your experiment name\n",
"experiment_name = \"smp-gptj-tensor-parallel\"\n",
"experiment_name = \"smp-gptj-sharded-data-parallel\"\n",
"# Specify your trial name\n",
"trial_name = f\"{experiment_name}-trial1\"\n",
"\n",
"all_experiment_names = [exp.experiment_name for exp in Experiment.list()]\n",
"# Load the experiment if it exists, otherwise create\n",
"if experiment_name not in all_experiment_names:\n",
" experiment = Experiment.create(\n",
" experiment_name=experiment_name, sagemaker_boto_client=sm_boto_client\n",
" )\n",
"else:\n",
" experiment = Experiment.load(\n",
" experiment_name=experiment_name, sagemaker_boto_client=sm_boto_client\n",
" )\n",
"\n",
"# Create the trial\n",
"trial = Trial.create(\n",
" trial_name=\"smp-{}-{}\".format(trial_name, strftime(\"%Y-%m-%d-%H-%M-%S\", gmtime())),\n",
" experiment_name=experiment.experiment_name,\n",
" sagemaker_boto_client=sm_boto_client,\n",
")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Specify Essential SageMaker Training Job Parameters\n",
"\n",
"Use the SageMaker [Estimator API](https://sagemaker.readthedocs.io/en/stable/api/training/estimators.html) to define a SageMaker Training Job. Pass the following parameters to this training job.\n",
"\n",
"* `instance_count`\n",
"* `instance_type`\n",
"* `volume_size`\n",
"* `base_job_name`\n",
"\n",
"> **Total GPUs**: The total number of GPU's available for training is determined by the `instance_type` and `instance_count`."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
" Training Instance Types
\n",
"\n",
" #### GPT-J-XL\n",
" * ml.g5.24xlarge\n",
" * ml.p3.16xlarge\n",
" * ml.p2.16xlarge\n",
" \n",
" #### GPT-J-6B\n",
" * ml.g5.48xlarge\n",
" * ml.p3dn.24xlarge\n",
" * ml.p4d.24xlarge\n",
"\n",
" "
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Set the instance type."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"instance_type = \"ml.p3.16xlarge\"\n",
"instance_count = 1"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
"Instance Specs
\n",
"Amazon SageMaker ml.p4d.24xlarge instances are powered by the latest Intel® Cascade Lake processors and eight NVIDIA A100 Tensor Core GPUs. They provide up to 100 Gbps networking throughput with 96 vCPUs, 8 NVIDIA A100 GPUs, 1.1 TB instance memory, 8 TB local NVMe-based SSD storage, and 19 Gbps EBS burst bandwidth.\n",
"
"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"# Set the processes per host equal to the number of GPUs on the EC2 instance\n",
"if instance_type in [\n",
" \"ml.p3.16xlarge\",\n",
" \"ml.p3dn.24xlarge\",\n",
" \"ml.g5.48xlarge\",\n",
" \"ml.p4d.24xlarge\",\n",
"]:\n",
" processes_per_host = 8\n",
"elif instance_type == \"ml.p2.16xlarge\":\n",
" processes_per_host = 16\n",
"else:\n",
" processes_per_host = 4\n",
"\n",
"print(\"processes_per_host is set to:\", processes_per_host)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Set the instance volume size to 500GB. The volume size must be larger than your input data size."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"volume_size = 500"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Specify a base job name to track a configuration."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"machine_str = instance_type.split(\".\")[1] + instance_type.split(\".\")[2][:3]\n",
"pp_degree = hyperparameters[\"pipeline_parallel_degree\"]\n",
"tp_degree = hyperparameters[\"tensor_parallel_degree\"]\n",
"base_job_name = f'smp-{model_config}-{machine_str}-tp{tp_degree}-pp{pp_degree}-sdp{hyperparameters[\"sharded_data_parallel_degree\"]}-bs{hyperparameters[\"train_batch_size\"]}'"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Set the S3 location for the model checkpoint"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"# If you want to resume training, set checkpoint_s3_uri to the same path as a previous job.\n",
"# Previous checkpoint to load must have same model config.\n",
"checkpoint_bucket = f\"s3://sagemaker-{region}-{account}/\"\n",
"checkpoint_s3_uri = f\"{checkpoint_bucket}/experiments/gptj_synthetic_simpletrainer_checkpoints/{base_job_name}/\""
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Create a SageMaker PyTorch Estimator\n",
"\n",
"Amazon SageMakers PyTorch estimator objects contain a [distribution](https://sagemaker.readthedocs.io/en/stable/api/training/smd_model_parallel_general.html) parameter which you can use to enable and specify parameters for SageMaker distributed training. The SageMaker model parallel library internally uses MPI. To use model parallelism, both `smdistributed` and `mpi` must be enabled through the distribution parameter."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"distribution = {\n",
" \"mpi\": {\n",
" \"enabled\": True,\n",
" \"processes_per_host\": processes_per_host,\n",
" \"custom_mpi_options\": mpioptions,\n",
" },\n",
" \"smdistributed\": {\n",
" \"modelparallel\": {\n",
" \"enabled\": True,\n",
" \"parameters\": {\n",
" \"ddp\": True,\n",
" \"tensor_parallel_degree\": hyperparameters[\"tensor_parallel_degree\"],\n",
" # partitions is a required param in the current SM SDK so it needs to be passed,\n",
" # these two map to the same config\n",
" \"partitions\": hyperparameters[\"pipeline_parallel_degree\"],\n",
" \"shard_optimizer_state\": hyperparameters[\"shard_optimizer_state\"] > 0,\n",
" \"prescaled_batch\": hyperparameters[\"prescaled_batch\"] > 0,\n",
" \"fp16\": hyperparameters[\"fp16\"] > 0,\n",
" \"optimize\": hyperparameters[\"optimize\"],\n",
" \"auto_partition\": False\n",
" if hyperparameters[\"manual_partition\"]\n",
" else True,\n",
" \"default_partition\": 0,\n",
" \"optimize\": hyperparameters[\"optimize\"],\n",
" },\n",
" }\n",
" },\n",
"}"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"The following cell constructs a PyTorch estimator using the parameters defined above. To see how the SageMaker tensor parallelism modules and functions are applied to the script, see the `train_gptj_smp_tensor_parallel_script.py` file."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"kwargs = {}\n",
"\n",
"smp_estimator = PyTorch(\n",
" entry_point=\"train_gptj_smp_tensor_parallel_script.py\",\n",
" source_dir=os.getcwd(),\n",
" role=role,\n",
" instance_type=instance_type,\n",
" volume_size=volume_size,\n",
" instance_count=instance_count,\n",
" sagemaker_session=sagemaker_session,\n",
" distribution=distribution,\n",
" framework_version=\"1.13\",\n",
" py_version=\"py39\",\n",
" output_path=s3_output_bucket,\n",
" checkpoint_s3_uri=checkpoint_s3_uri,\n",
" metric_definitions=metric_definitions,\n",
" hyperparameters=hyperparameters,\n",
" debugger_hook_config=False,\n",
" disable_profiler=True,\n",
" base_job_name=base_job_name,\n",
" **kwargs,\n",
")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Finally, run the estimator to launch the SageMaker training job of GPT-J model with tensor parallelism."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"scrolled": true,
"tags": []
},
"outputs": [],
"source": [
"smp_estimator.fit(\n",
" inputs=data_channels,\n",
" experiment_config={\n",
" \"ExperimentName\": experiment.experiment_name,\n",
" \"TrialName\": trial.trial_name,\n",
" \"TrialComponentDisplayName\": \"Training\",\n",
" },\n",
" logs=True,\n",
")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
"\n",
"
ResourceLimitExceeded Error \n",
"If you receive a
ResourceLimitExceeded error message when running the training job, you can request an increase on the default quota by contacting
AWS Support. For the quota Limit Type select SageMaker Training Jobs and the instance type.\n",
"
\n",
"Training Time
\n",
"The model training job takes approximately 30 minutes to complete.\n",
"
\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Accessing the Training Logs\n",
"\n",
"You can access the training logs from [Amazon CloudWatch](https://docs.aws.amazon.com/AmazonCloudWatch/latest/monitoring/WhatIsCloudWatch.html). Make sure to look at the logs of algo-1 as that is the master node whose output stream will have the training job logs.\n",
"\n",
"You can use CloudWatch to track SageMaker GPU and memory utilization during training and inference. To view the metrics and logs that SageMaker writes to CloudWatch, see *Processing Job, Training Job, Batch Transform Job, and Endpoint Instance Metrics* in [Monitor Amazon SageMaker with Amazon CloudWatch](https://docs.aws.amazon.com/sagemaker/latest/dg/monitoring-cloudwatch.html).\n",
"\n",
"If you are a new user of CloudWatch, see [Getting Started with Amazon CloudWatch](https://docs.aws.amazon.com/AmazonCloudWatch/latest/monitoring/GettingStarted.html). \n",
"\n",
"For additional information on monitoring and analyzing Amazon SageMaker training jobs, see [Monitor and Analyze Training Jobs Using Metrics](https://docs.aws.amazon.com/sagemaker/latest/dg/training-metrics.html).\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
"End of Lab3a
\n",
"Please return to workshop studio and continue to Lab3b - Inference"
]
}
],
"metadata": {
"availableInstances": [
{
"_defaultOrder": 0,
"_isFastLaunch": true,
"category": "General purpose",
"gpuNum": 0,
"hideHardwareSpecs": false,
"memoryGiB": 4,
"name": "ml.t3.medium",
"vcpuNum": 2
},
{
"_defaultOrder": 1,
"_isFastLaunch": false,
"category": "General purpose",
"gpuNum": 0,
"hideHardwareSpecs": false,
"memoryGiB": 8,
"name": "ml.t3.large",
"vcpuNum": 2
},
{
"_defaultOrder": 2,
"_isFastLaunch": false,
"category": "General purpose",
"gpuNum": 0,
"hideHardwareSpecs": false,
"memoryGiB": 16,
"name": "ml.t3.xlarge",
"vcpuNum": 4
},
{
"_defaultOrder": 3,
"_isFastLaunch": false,
"category": "General purpose",
"gpuNum": 0,
"hideHardwareSpecs": false,
"memoryGiB": 32,
"name": "ml.t3.2xlarge",
"vcpuNum": 8
},
{
"_defaultOrder": 4,
"_isFastLaunch": true,
"category": "General purpose",
"gpuNum": 0,
"hideHardwareSpecs": false,
"memoryGiB": 8,
"name": "ml.m5.large",
"vcpuNum": 2
},
{
"_defaultOrder": 5,
"_isFastLaunch": false,
"category": "General purpose",
"gpuNum": 0,
"hideHardwareSpecs": false,
"memoryGiB": 16,
"name": "ml.m5.xlarge",
"vcpuNum": 4
},
{
"_defaultOrder": 6,
"_isFastLaunch": false,
"category": "General purpose",
"gpuNum": 0,
"hideHardwareSpecs": false,
"memoryGiB": 32,
"name": "ml.m5.2xlarge",
"vcpuNum": 8
},
{
"_defaultOrder": 7,
"_isFastLaunch": false,
"category": "General purpose",
"gpuNum": 0,
"hideHardwareSpecs": false,
"memoryGiB": 64,
"name": "ml.m5.4xlarge",
"vcpuNum": 16
},
{
"_defaultOrder": 8,
"_isFastLaunch": false,
"category": "General purpose",
"gpuNum": 0,
"hideHardwareSpecs": false,
"memoryGiB": 128,
"name": "ml.m5.8xlarge",
"vcpuNum": 32
},
{
"_defaultOrder": 9,
"_isFastLaunch": false,
"category": "General purpose",
"gpuNum": 0,
"hideHardwareSpecs": false,
"memoryGiB": 192,
"name": "ml.m5.12xlarge",
"vcpuNum": 48
},
{
"_defaultOrder": 10,
"_isFastLaunch": false,
"category": "General purpose",
"gpuNum": 0,
"hideHardwareSpecs": false,
"memoryGiB": 256,
"name": "ml.m5.16xlarge",
"vcpuNum": 64
},
{
"_defaultOrder": 11,
"_isFastLaunch": false,
"category": "General purpose",
"gpuNum": 0,
"hideHardwareSpecs": false,
"memoryGiB": 384,
"name": "ml.m5.24xlarge",
"vcpuNum": 96
},
{
"_defaultOrder": 12,
"_isFastLaunch": false,
"category": "General purpose",
"gpuNum": 0,
"hideHardwareSpecs": false,
"memoryGiB": 8,
"name": "ml.m5d.large",
"vcpuNum": 2
},
{
"_defaultOrder": 13,
"_isFastLaunch": false,
"category": "General purpose",
"gpuNum": 0,
"hideHardwareSpecs": false,
"memoryGiB": 16,
"name": "ml.m5d.xlarge",
"vcpuNum": 4
},
{
"_defaultOrder": 14,
"_isFastLaunch": false,
"category": "General purpose",
"gpuNum": 0,
"hideHardwareSpecs": false,
"memoryGiB": 32,
"name": "ml.m5d.2xlarge",
"vcpuNum": 8
},
{
"_defaultOrder": 15,
"_isFastLaunch": false,
"category": "General purpose",
"gpuNum": 0,
"hideHardwareSpecs": false,
"memoryGiB": 64,
"name": "ml.m5d.4xlarge",
"vcpuNum": 16
},
{
"_defaultOrder": 16,
"_isFastLaunch": false,
"category": "General purpose",
"gpuNum": 0,
"hideHardwareSpecs": false,
"memoryGiB": 128,
"name": "ml.m5d.8xlarge",
"vcpuNum": 32
},
{
"_defaultOrder": 17,
"_isFastLaunch": false,
"category": "General purpose",
"gpuNum": 0,
"hideHardwareSpecs": false,
"memoryGiB": 192,
"name": "ml.m5d.12xlarge",
"vcpuNum": 48
},
{
"_defaultOrder": 18,
"_isFastLaunch": false,
"category": "General purpose",
"gpuNum": 0,
"hideHardwareSpecs": false,
"memoryGiB": 256,
"name": "ml.m5d.16xlarge",
"vcpuNum": 64
},
{
"_defaultOrder": 19,
"_isFastLaunch": false,
"category": "General purpose",
"gpuNum": 0,
"hideHardwareSpecs": false,
"memoryGiB": 384,
"name": "ml.m5d.24xlarge",
"vcpuNum": 96
},
{
"_defaultOrder": 20,
"_isFastLaunch": false,
"category": "General purpose",
"gpuNum": 0,
"hideHardwareSpecs": true,
"memoryGiB": 0,
"name": "ml.geospatial.interactive",
"supportedImageNames": [
"sagemaker-geospatial-v1-0"
],
"vcpuNum": 0
},
{
"_defaultOrder": 21,
"_isFastLaunch": true,
"category": "Compute optimized",
"gpuNum": 0,
"hideHardwareSpecs": false,
"memoryGiB": 4,
"name": "ml.c5.large",
"vcpuNum": 2
},
{
"_defaultOrder": 22,
"_isFastLaunch": false,
"category": "Compute optimized",
"gpuNum": 0,
"hideHardwareSpecs": false,
"memoryGiB": 8,
"name": "ml.c5.xlarge",
"vcpuNum": 4
},
{
"_defaultOrder": 23,
"_isFastLaunch": false,
"category": "Compute optimized",
"gpuNum": 0,
"hideHardwareSpecs": false,
"memoryGiB": 16,
"name": "ml.c5.2xlarge",
"vcpuNum": 8
},
{
"_defaultOrder": 24,
"_isFastLaunch": false,
"category": "Compute optimized",
"gpuNum": 0,
"hideHardwareSpecs": false,
"memoryGiB": 32,
"name": "ml.c5.4xlarge",
"vcpuNum": 16
},
{
"_defaultOrder": 25,
"_isFastLaunch": false,
"category": "Compute optimized",
"gpuNum": 0,
"hideHardwareSpecs": false,
"memoryGiB": 72,
"name": "ml.c5.9xlarge",
"vcpuNum": 36
},
{
"_defaultOrder": 26,
"_isFastLaunch": false,
"category": "Compute optimized",
"gpuNum": 0,
"hideHardwareSpecs": false,
"memoryGiB": 96,
"name": "ml.c5.12xlarge",
"vcpuNum": 48
},
{
"_defaultOrder": 27,
"_isFastLaunch": false,
"category": "Compute optimized",
"gpuNum": 0,
"hideHardwareSpecs": false,
"memoryGiB": 144,
"name": "ml.c5.18xlarge",
"vcpuNum": 72
},
{
"_defaultOrder": 28,
"_isFastLaunch": false,
"category": "Compute optimized",
"gpuNum": 0,
"hideHardwareSpecs": false,
"memoryGiB": 192,
"name": "ml.c5.24xlarge",
"vcpuNum": 96
},
{
"_defaultOrder": 29,
"_isFastLaunch": true,
"category": "Accelerated computing",
"gpuNum": 1,
"hideHardwareSpecs": false,
"memoryGiB": 16,
"name": "ml.g4dn.xlarge",
"vcpuNum": 4
},
{
"_defaultOrder": 30,
"_isFastLaunch": false,
"category": "Accelerated computing",
"gpuNum": 1,
"hideHardwareSpecs": false,
"memoryGiB": 32,
"name": "ml.g4dn.2xlarge",
"vcpuNum": 8
},
{
"_defaultOrder": 31,
"_isFastLaunch": false,
"category": "Accelerated computing",
"gpuNum": 1,
"hideHardwareSpecs": false,
"memoryGiB": 64,
"name": "ml.g4dn.4xlarge",
"vcpuNum": 16
},
{
"_defaultOrder": 32,
"_isFastLaunch": false,
"category": "Accelerated computing",
"gpuNum": 1,
"hideHardwareSpecs": false,
"memoryGiB": 128,
"name": "ml.g4dn.8xlarge",
"vcpuNum": 32
},
{
"_defaultOrder": 33,
"_isFastLaunch": false,
"category": "Accelerated computing",
"gpuNum": 4,
"hideHardwareSpecs": false,
"memoryGiB": 192,
"name": "ml.g4dn.12xlarge",
"vcpuNum": 48
},
{
"_defaultOrder": 34,
"_isFastLaunch": false,
"category": "Accelerated computing",
"gpuNum": 1,
"hideHardwareSpecs": false,
"memoryGiB": 256,
"name": "ml.g4dn.16xlarge",
"vcpuNum": 64
},
{
"_defaultOrder": 35,
"_isFastLaunch": false,
"category": "Accelerated computing",
"gpuNum": 1,
"hideHardwareSpecs": false,
"memoryGiB": 61,
"name": "ml.p3.2xlarge",
"vcpuNum": 8
},
{
"_defaultOrder": 36,
"_isFastLaunch": false,
"category": "Accelerated computing",
"gpuNum": 4,
"hideHardwareSpecs": false,
"memoryGiB": 244,
"name": "ml.p3.8xlarge",
"vcpuNum": 32
},
{
"_defaultOrder": 37,
"_isFastLaunch": false,
"category": "Accelerated computing",
"gpuNum": 8,
"hideHardwareSpecs": false,
"memoryGiB": 488,
"name": "ml.p3.16xlarge",
"vcpuNum": 64
},
{
"_defaultOrder": 38,
"_isFastLaunch": false,
"category": "Accelerated computing",
"gpuNum": 8,
"hideHardwareSpecs": false,
"memoryGiB": 768,
"name": "ml.p3dn.24xlarge",
"vcpuNum": 96
},
{
"_defaultOrder": 39,
"_isFastLaunch": false,
"category": "Memory Optimized",
"gpuNum": 0,
"hideHardwareSpecs": false,
"memoryGiB": 16,
"name": "ml.r5.large",
"vcpuNum": 2
},
{
"_defaultOrder": 40,
"_isFastLaunch": false,
"category": "Memory Optimized",
"gpuNum": 0,
"hideHardwareSpecs": false,
"memoryGiB": 32,
"name": "ml.r5.xlarge",
"vcpuNum": 4
},
{
"_defaultOrder": 41,
"_isFastLaunch": false,
"category": "Memory Optimized",
"gpuNum": 0,
"hideHardwareSpecs": false,
"memoryGiB": 64,
"name": "ml.r5.2xlarge",
"vcpuNum": 8
},
{
"_defaultOrder": 42,
"_isFastLaunch": false,
"category": "Memory Optimized",
"gpuNum": 0,
"hideHardwareSpecs": false,
"memoryGiB": 128,
"name": "ml.r5.4xlarge",
"vcpuNum": 16
},
{
"_defaultOrder": 43,
"_isFastLaunch": false,
"category": "Memory Optimized",
"gpuNum": 0,
"hideHardwareSpecs": false,
"memoryGiB": 256,
"name": "ml.r5.8xlarge",
"vcpuNum": 32
},
{
"_defaultOrder": 44,
"_isFastLaunch": false,
"category": "Memory Optimized",
"gpuNum": 0,
"hideHardwareSpecs": false,
"memoryGiB": 384,
"name": "ml.r5.12xlarge",
"vcpuNum": 48
},
{
"_defaultOrder": 45,
"_isFastLaunch": false,
"category": "Memory Optimized",
"gpuNum": 0,
"hideHardwareSpecs": false,
"memoryGiB": 512,
"name": "ml.r5.16xlarge",
"vcpuNum": 64
},
{
"_defaultOrder": 46,
"_isFastLaunch": false,
"category": "Memory Optimized",
"gpuNum": 0,
"hideHardwareSpecs": false,
"memoryGiB": 768,
"name": "ml.r5.24xlarge",
"vcpuNum": 96
},
{
"_defaultOrder": 47,
"_isFastLaunch": false,
"category": "Accelerated computing",
"gpuNum": 1,
"hideHardwareSpecs": false,
"memoryGiB": 16,
"name": "ml.g5.xlarge",
"vcpuNum": 4
},
{
"_defaultOrder": 48,
"_isFastLaunch": false,
"category": "Accelerated computing",
"gpuNum": 1,
"hideHardwareSpecs": false,
"memoryGiB": 32,
"name": "ml.g5.2xlarge",
"vcpuNum": 8
},
{
"_defaultOrder": 49,
"_isFastLaunch": false,
"category": "Accelerated computing",
"gpuNum": 1,
"hideHardwareSpecs": false,
"memoryGiB": 64,
"name": "ml.g5.4xlarge",
"vcpuNum": 16
},
{
"_defaultOrder": 50,
"_isFastLaunch": false,
"category": "Accelerated computing",
"gpuNum": 1,
"hideHardwareSpecs": false,
"memoryGiB": 128,
"name": "ml.g5.8xlarge",
"vcpuNum": 32
},
{
"_defaultOrder": 51,
"_isFastLaunch": false,
"category": "Accelerated computing",
"gpuNum": 1,
"hideHardwareSpecs": false,
"memoryGiB": 256,
"name": "ml.g5.16xlarge",
"vcpuNum": 64
},
{
"_defaultOrder": 52,
"_isFastLaunch": false,
"category": "Accelerated computing",
"gpuNum": 4,
"hideHardwareSpecs": false,
"memoryGiB": 192,
"name": "ml.g5.12xlarge",
"vcpuNum": 48
},
{
"_defaultOrder": 53,
"_isFastLaunch": false,
"category": "Accelerated computing",
"gpuNum": 4,
"hideHardwareSpecs": false,
"memoryGiB": 384,
"name": "ml.g5.24xlarge",
"vcpuNum": 96
},
{
"_defaultOrder": 54,
"_isFastLaunch": false,
"category": "Accelerated computing",
"gpuNum": 8,
"hideHardwareSpecs": false,
"memoryGiB": 768,
"name": "ml.g5.48xlarge",
"vcpuNum": 192
}
],
"hide_input": false,
"instance_type": "ml.m5.large",
"kernelspec": {
"display_name": "Python 3 (Data Science)",
"language": "python",
"name": "python3__SAGEMAKER_INTERNAL__arn:aws:sagemaker:us-west-2:236514542706:image/datascience-1.0"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.7.10"
},
"vscode": {
"interpreter": {
"hash": "31f2aee4e71d21fbe5cf8b01ff0e069b9275f58929596ceb00d14d90e3e16cd6"
}
}
},
"nbformat": 4,
"nbformat_minor": 4
}