{
"cells": [
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Module 3. ê°œì¸í™” 추천 ëª¨ë¸ í•™ìŠµ ë° ìº íŽ˜ì¸ ìƒì„±\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Library Import \n",
"\n",
"파ì´ì¬ì—는 광범위한 ë¼ì´ë¸ŒëŸ¬ë¦¬ 모ìŒì´ í¬í•¨ë˜ì–´ 있으며, 본 LABì„ ìœ„í•´ì„œ 핵심 Data Scientistìš© Tool ì¸ boto3 (AWS SDK) ë° Pandas/Numpy와 ê°™ì€ ë¼ì´ë¸ŒëŸ¬ë¦¬ë¥¼ ê°€ì ¸ì™€ì•¼ 합니다. "
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Imports\n",
"#from codes import lambda_personalize\n",
"import boto3\n",
"import json\n",
"import numpy as np\n",
"import pandas as pd\n",
"import time\n",
"import jsonlines\n",
"import os\n",
"\n",
"\n",
"from datetime import datetime\n",
"import sagemaker\n",
"import time\n",
"import warnings\n",
"\n",
"import matplotlib.pyplot as plt\n",
"from matplotlib.dates import DateFormatter\n",
"import matplotlib.dates as mdate\n",
"from botocore.exceptions import ClientError"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"다ìŒìœ¼ë¡œ ì—¬ëŸ¬ë¶„ì˜ í™˜ê²½ì´ Amazon Personalize와 성공ì 으로 í†µì‹ í• ìˆ˜ 있는지 확ì¸í•´ì•¼ 합니다."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Configure the SDK to Personalize:\n",
"personalize = boto3.client('personalize')\n",
"personalize_runtime = boto3.client('personalize-runtime')\n",
"s3 = boto3.resource('s3')"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# 아래 코드 ì…€ì€ ì´ì „ notebookì—ì„œ ì €ìž¥í–ˆë˜ ë³€ìˆ˜ë“¤ì„ ë¶ˆëŸ¬ì˜µë‹ˆë‹¤.\n",
"%store -r"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"DATA_PREFIX = \"dataset\"\n",
"KEY_PREFIX = \"user-personalization\"\n",
"DATA_SET_GROUP_NAME= WORK_DATE+ \"-dataset-group\"\n",
"SCHEMA_NAME_INTERACTION= WORK_DATE+ \"-schema-interactions\"\n",
"DATASET_NAME_INTERACTION=\"dataset-interactions\"\n",
"DATASET_NAME_USERS=\"dataset-users\"\n",
"DATASET_NAME_ITEMS=\"dataset-items\"\n",
"\n",
"#ìƒì„±í• 오브ì íŠ¸ì˜ ëì— ìž„ì˜ì˜ 숫ìžë¥¼ 부여하기 위해 suffix ì •ì˜\n",
"suffix = str(np.random.uniform())[4:9]\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"%store suffix \n",
"%store DATA_PREFIX \n",
"%store KEY_PREFIX \n",
"%store DATA_SET_GROUP_NAME\n",
"%store SCHEMA_NAME_INTERACTION\n",
"%store DATASET_NAME_INTERACTION\n",
"%store DATASET_NAME_USERS\n",
"%store DATASET_NAME_ITEMS"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"inter_train=pd.read_csv(interaction_train_file)\n",
"user_train=pd.read_csv(user_train_file)\n",
"item_train=pd.read_csv(item_train_file)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"inter_train.head()"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"user_train.head()"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"item_train.head()"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## í¼ìŠ¤ë„ë¼ì´ì¦ˆ ì›Œí¬ í”Œë¡œìš°\n",
"\n",
"Personalize는 S3ì— ì—…ë¡œë“œ ëœ ë°ì´í„°ë¥¼ ê³ ê°ì´ ì •ì˜í•œ ìŠ¤í‚¤ë§ˆì— ë§žì¶° 학습 노드로 ìž„í¬íŠ¸ 하게 ë©ë‹ˆë‹¤. ë°ì´í„° ìž„í¬íŠ¸ 후ì—는 í¼ìŠ¤ë„ë¼ì´ì¦ˆì—ì„œ 추가ì ì¸ ë°ì´í„° ë¶„ì„ ë° EDA ìž‘ì—…ì„ í•œë’¤ í•™ìŠµì„ í•˜ê²Œ ë©ë‹ˆë‹¤. 학습 완료 후 모ë¸ì˜ ì„±ëŠ¥ì„ í™•ì¸í•´ ë³´ê³ ìº íŽ˜ì¸ ìƒì„±ì„ 통해 서비스를 위해 ë°°í¬í•˜ê²Œ ë©ë‹ˆë‹¤. ìƒì„¸í•œ ë‚´ìš©ì€ [여기](https://docs.aws.amazon.com/ko_kr/personalize/latest/dg/what-is-personalize.html) ë§í¬ë¥¼ 통해 확ì¸í•´ 봅니다.\n",
"\n",
"\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## S3ë¡œ ë°ì´í„° 업로드 하기\n",
"\n",
"ì •ì œëœ íŒŒì¼ì„ S3ì— ì—…ë¡œë“œí•©ë‹ˆë‹¤.\n",
"업로드ì—는 ëª‡ë¶„ì´ ê±¸ë¦´ 수 있습니다."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"target=KEY_PREFIX+\"/\"+DATA_PREFIX+\"/\"+interaction_train_file\n",
"boto3.Session().resource('s3').Bucket(BUCKET_NAME).Object(target).upload_file(interaction_train_file)\n",
"\n",
"target=KEY_PREFIX+\"/\"+DATA_PREFIX+\"/\"+user_train_file\n",
"boto3.Session().resource('s3').Bucket(BUCKET_NAME).Object(target).upload_file(user_train_file)\n",
"\n",
"\n",
"target=KEY_PREFIX+\"/\"+DATA_PREFIX+\"/\"+item_train_file\n",
"boto3.Session().resource('s3').Bucket(BUCKET_NAME).Object(target).upload_file(item_train_file)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## 스키마 ìƒì„±\n",
"\n",
"Personalizeê°€ ë°ì´í„°ë¥¼ ì´í•´í•˜ëŠ” ë°©ë²•ì˜ í•µì‹¬ 구성 요소는 아래 ì •ì˜ ëœ ìŠ¤í‚¤ë§ˆ(schema)ì—ì„œ 비롯ë©ë‹ˆë‹¤. ì´ ì„¤ì •ì€ CSV 파ì¼ì„ 통해 ì œê³µëœ ë°ì´í„°ë¥¼ 요약하는 ë°©ë²•ì„ Personalize ì„œë¹„ìŠ¤ì— ì•Œë ¤ì¤ë‹ˆë‹¤. ìŠ¤ì¹´ë§ˆì˜ ì´ë¦„(name)ê³¼ ìœ í˜•(type)ì€ ì´ì „ì— ìƒì„±í•œ 학습 파ì¼ì˜ ì»¬ëŸ¼ì˜ ìˆœì„œì™€ ìœ í˜•í•˜ê³ ì¼ì¹˜í•©ë‹ˆë‹¤."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Interaction 스키마 ìƒì„±"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"interaction_schema_name=\"Interaction-schema-\"+WORK_DATE+\"-\"+suffix"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"interaction_schema = {\n",
" \"type\": \"record\",\n",
" \"name\": \"Interactions\",\n",
" \"namespace\": \"com.amazonaws.personalize.schema\",\n",
" \"fields\": [\n",
" {\n",
" \"name\": \"USER_ID\",\n",
" \"type\": \"string\"\n",
" },\n",
" {\n",
" \"name\": \"ITEM_ID\",\n",
" \"type\": \"string\"\n",
" },\n",
" { \n",
" \"name\": \"EVENT_VALUE\",\n",
" \"type\": \"float\"\n",
" },\n",
" {\n",
" \"name\": \"TIMESTAMP\",\n",
" \"type\": \"long\"\n",
" },\n",
" {\n",
" \"name\": \"EVENT_TYPE\",\n",
" \"type\": \"string\"\n",
" }\n",
" ],\n",
" \"version\": \"1.0\"\n",
"}\n",
"\n",
"\n",
"create_schema_response = personalize.create_schema(\n",
" name = interaction_schema_name,\n",
" schema = json.dumps(interaction_schema)\n",
")\n",
"\n",
"interaction_schema_arn = create_schema_response['schemaArn']\n",
"print(json.dumps(create_schema_response, indent=2))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### User 스키마 ìƒì„±"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"user_schema_name=\"User-schema-\"+WORK_DATE+\"-\"+suffix"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"user_schema = {\n",
" \"type\": \"record\",\n",
" \"name\": \"Users\",\n",
" \"namespace\": \"com.amazonaws.personalize.schema\",\n",
" \"fields\": [\n",
" {\n",
" \"name\": \"USER_ID\",\n",
" \"type\": \"string\"\n",
" },\n",
" {\n",
" \"name\": \"GENDER\",\n",
" \"type\": [\"string\",\"null\"],\n",
" \"categorical\": True\n",
" },\n",
" {\n",
" \"name\": \"AGE\",\n",
" \"type\": [\"string\",\"null\"],\n",
" \"categorical\": True\n",
" },\n",
" {\n",
" \"name\": \"OCCUPATION\",\n",
" \"type\": [\"string\",\"null\"],\n",
" \"categorical\": True\n",
" }\n",
" \n",
" ],\n",
" \"version\": \"1.0\"\n",
"}\n",
"\n",
"\n",
"create_schema_response = personalize.create_schema(\n",
" name = user_schema_name,\n",
" schema = json.dumps(user_schema)\n",
")\n",
"\n",
"user_schema_arn = create_schema_response['schemaArn']\n",
"print(json.dumps(create_schema_response, indent=2))\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### ITEM 스키마 ìƒì„±"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"item_schema_name=\"Item-schema-\"+WORK_DATE+\"-\"+suffix"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"item_schema = {\n",
" \"type\": \"record\",\n",
" \"name\": \"Items\",\n",
" \"namespace\": \"com.amazonaws.personalize.schema\",\n",
" \"fields\": [\n",
" {\n",
" \"name\": \"ITEM_ID\",\n",
" \"type\": \"string\"\n",
" },\n",
" \n",
" \n",
" {\n",
" \"name\": \"GENRE\",\n",
" \"type\": [\"string\",\"null\"],\n",
" \"categorical\": True\n",
" }\n",
" \n",
" \n",
" ],\n",
" \"version\": \"1.0\"\n",
"}\n",
"\n",
"create_metadata_schema_response = personalize.create_schema(\n",
" name = item_schema_name,\n",
" schema = json.dumps(item_schema)\n",
")\n",
"\n",
"item_schema_arn = create_metadata_schema_response['schemaArn']\n",
"print(json.dumps(create_metadata_schema_response, indent=2))\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## ë°ì´í„° 세트 그룹 ìƒì„± ë° ëŒ€ê¸°\n",
"\n",
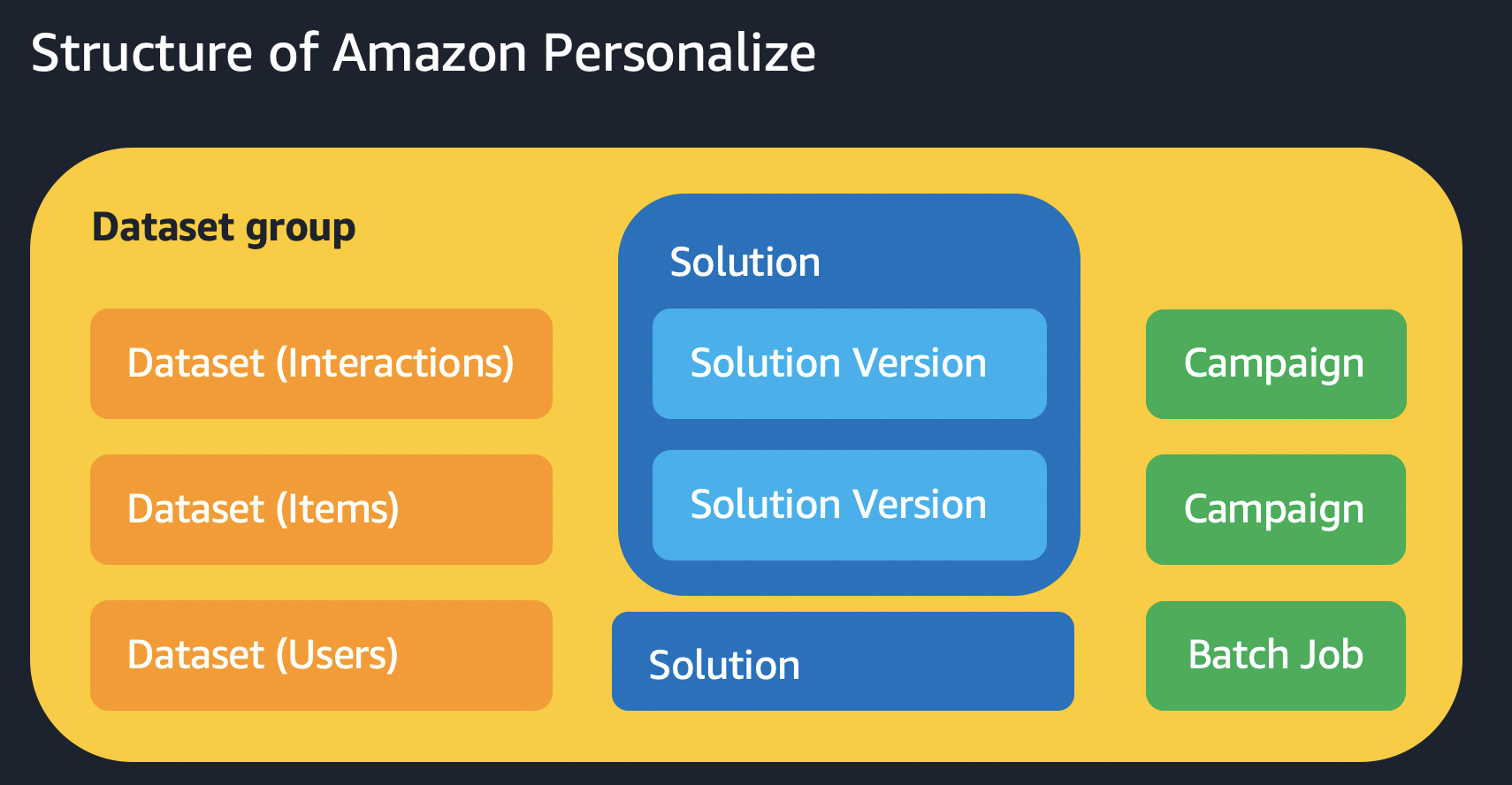
"Personalizeì—ì„œ 가장 í° ë‹¨ìœ„ëŠ” **ë°ì´í„° 세트 그룹(Dataset Group)** ì´ë©°, ì´ë ‡ê²Œ 하면 ë°ì´í„°, ì´ë²¤íŠ¸ 추ì 기(event tracker), 솔루션(solution) ë° ìº íŽ˜ì¸(campaign)ì´ ë¶„ë¦¬ë©ë‹ˆë‹¤. ê³µí†µì˜ ë°ì´í„° ìˆ˜ì§‘ì„ ê³µìœ í•˜ëŠ” ê²ƒë“¤ì„ ê·¸ë£¹í™”í•©ë‹ˆë‹¤. ì›í•˜ëŠ” 경우 아래 ê·¸ë£¹ëª…ì„ ìžìœ ë¡ê²Œ 변경해 주세요.\n",
"\n",
""
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### ë°ì´í„° 세트 그룹 ìƒì„±"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"create_dataset_group_response = personalize.create_dataset_group(\n",
" name = DATA_SET_GROUP_NAME\n",
")\n",
"\n",
"dataset_group_arn = create_dataset_group_response['datasetGroupArn']\n",
"print(json.dumps(create_dataset_group_response, indent=2))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### ë°ì´í„° 세트 ê·¸ë£¹ì´ í™œì„±í™” ìƒíƒœê°€ ë 때까지 대기\n",
"\n",
"ì•„ëž˜ì˜ ëª¨ë“ í•ëª©ì—ì„œ Dataset Groupì„ ì‚¬ìš©í•˜ë ¤ë©´ 활성화(active)ê°€ ë˜ì–´ì•¼ 합니다. 아래 ì…€ì„ ì‹¤í–‰í•˜ê³ DatasetGroup: ACTIVEë¡œ 변경ë 때까지 ê¸°ë‹¤ë ¤ 주세요."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"max_time = time.time() + 3*60*60 # 3 hours\n",
"while time.time() < max_time:\n",
" describe_dataset_group_response = personalize.describe_dataset_group(\n",
" datasetGroupArn = dataset_group_arn\n",
" )\n",
" status = describe_dataset_group_response[\"datasetGroup\"][\"status\"]\n",
" print(\"DatasetGroup: {}\".format(status))\n",
" \n",
" if status == \"ACTIVE\" or status == \"CREATE FAILED\":\n",
" break\n",
" \n",
" time.sleep(15)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### ë°ì´í„° 세트 ìƒì„±\n",
"\n",
"그룹 다ìŒìœ¼ë¡œ ìƒì„±í• ê²ƒì€ ì‹¤ì œ ë°ì´í„° 세트입니다. ì•„ëž˜ì˜ ì½”ë“œ ì…€ì„ ì‹¤í–‰í•˜ì—¬ ë°ì´í„° ì„¸íŠ¸ì„ ìƒì„±í•´ 주세요."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Interaction ë°ì´í„° 세트 ìƒì„±"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"dataset_type = \"INTERACTIONS\"\n",
"create_dataset_response = personalize.create_dataset(\n",
" name = DATASET_NAME_INTERACTION,\n",
" datasetType = dataset_type,\n",
" datasetGroupArn = dataset_group_arn,\n",
" schemaArn = interaction_schema_arn\n",
")\n",
"\n",
"interaction_dataset_arn = create_dataset_response['datasetArn']\n",
"print(json.dumps(create_dataset_response, indent=2))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### USER ë°ì´í„° 세트 ìƒì„± "
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"dataset_type = \"USERS\"\n",
"\n",
"create_dataset_response = personalize.create_dataset(\n",
" name = DATASET_NAME_USERS,\n",
" datasetType = dataset_type,\n",
" datasetGroupArn = dataset_group_arn,\n",
" schemaArn = user_schema_arn\n",
")\n",
"\n",
"user_dataset_arn = create_dataset_response['datasetArn']\n",
"print(json.dumps(create_dataset_response, indent=2))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### ITEM ë°ì´í„° 세트 ìƒì„±"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"dataset_type = \"ITEMS\"\n",
"\n",
"create_dataset_response = personalize.create_dataset(\n",
" name = DATASET_NAME_ITEMS,\n",
" datasetType = dataset_type,\n",
" datasetGroupArn = dataset_group_arn,\n",
" schemaArn = item_schema_arn\n",
")\n",
"\n",
"item_dataset_arn = create_dataset_response['datasetArn']\n",
"print(json.dumps(create_dataset_response, indent=2))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### S3 ë²„í‚·ì— ì •ì±… 부여\n",
"\n",
"Amazon Personalize는 ì•žì„œ ìƒì„±í•œ S3 ë²„í‚·ì˜ ë‚´ìš©ì„ ì½ì„ 수 있어야 합니다. 아래 코드 셀로 S3 버킷 ì ‘ê·¼ ì •ì±…(policy)ì„ ë¶€ì—¬í•©ë‹ˆë‹¤."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"s3 = boto3.client(\"s3\")\n",
"\n",
"policy = {\n",
" \"Version\": \"2012-10-17\",\n",
" \"Id\": \"PersonalizeS3BucketAccessPolicy\",\n",
" \"Statement\": [\n",
" {\n",
" \"Sid\": \"PersonalizeS3BucketAccessPolicy\",\n",
" \"Effect\": \"Allow\",\n",
" \"Principal\": {\n",
" \"Service\": \"personalize.amazonaws.com\"\n",
" },\n",
" \"Action\": [\n",
" \"s3:*Object\",\n",
" \"s3:ListBucket\",\n",
" ],\n",
" \"Resource\": [\n",
" \"arn:aws:s3:::{}\".format(BUCKET_NAME),\n",
" \"arn:aws:s3:::{}/*\".format(BUCKET_NAME)\n",
" ]\n",
" }\n",
" ]\n",
"}\n",
"\n",
"s3.put_bucket_policy(Bucket=BUCKET_NAME, Policy=json.dumps(policy))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Personalize IAM Role ìƒì„±\n",
"\n",
"ë˜í•œ, Amazon Personalize는 íŠ¹ì • ìž‘ì—…ë“¤ì„ ì‹¤í–‰í• ê¶Œí•œì„ ê°–ê¸° 위해, AWSì—ì„œ ì—í• ì„ ë§¡ì„ ìˆ˜ 있는 ê¸°ëŠ¥ì´ í•„ìš”í•©ë‹ˆë‹¤. "
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"\n",
"iam = boto3.client(\"iam\")\n",
"role_name = \"PersonalizeRoleDemo\" + suffix\n",
"assume_role_policy_document = {\n",
" \"Version\": \"2012-10-17\",\n",
" \"Statement\": [\n",
" {\n",
" \"Effect\": \"Allow\",\n",
" \"Principal\": {\n",
" \"Service\": \"personalize.amazonaws.com\"\n",
" },\n",
" \"Action\": \"sts:AssumeRole\"\n",
" }\n",
" ]\n",
"}\n",
"\n",
"\n",
"\n",
"\n",
"try:\n",
" create_role_response = iam.create_role(\n",
" RoleName = role_name,\n",
" AssumeRolePolicyDocument = json.dumps(assume_role_policy_document)\n",
" );\n",
"\n",
" iam.attach_role_policy(\n",
" RoleName = role_name,\n",
" PolicyArn = \"arn:aws:iam::aws:policy/AmazonS3ReadOnlyAccess\"\n",
" );\n",
"\n",
" role_arn = create_role_response[\"Role\"][\"Arn\"]\n",
"except ClientError as e:\n",
" if e.response['Error']['Code'] == 'EntityAlreadyExists':\n",
" role_arn = iam.get_role(RoleName=role_name)['Role']['Arn']\n",
" else:\n",
" raise\n",
" \n",
"\n",
"# AmazonPersonalizeFullAccess provides access to any S3 bucket with a name that includes \"personalize\" or \"Personalize\" \n",
"# if you would like to use a bucket with a different name, please consider creating and attaching a new policy\n",
"# that provides read access to your bucket or attaching the AmazonS3ReadOnlyAccess policy to the role\n",
"policy_arn = \"arn:aws:iam::aws:policy/service-role/AmazonPersonalizeFullAccess\"\n",
"iam.attach_role_policy(\n",
" RoleName = role_name,\n",
" PolicyArn = policy_arn\n",
")\n",
"\n",
"# Now add S3 support\n",
"iam.attach_role_policy(\n",
" RoleName=role_name, \n",
" PolicyArn='arn:aws:iam::aws:policy/AmazonS3FullAccess'\n",
")\n",
"time.sleep(60) # wait for a minute to allow IAM role policy attachment to propagate\n",
"\n",
"role_arn = create_role_response[\"Role\"][\"Arn\"]\n",
"print(role_arn)\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"%store role_arn"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### ë°ì´í„° 세트 Import\n",
"\n",
"ì´ì „ì—는 ì •ë³´ë¥¼ ì €ìž¥í•˜ê¸° 위해 ë°ì´í„° 세트 그룹 ë° ë°ì´í„° 세트를 ìƒì„±í–ˆìœ¼ë¯€ë¡œ, \n",
"ì´ì œëŠ” ëª¨ë¸ êµ¬ì¶•ì„ ìœ„í•´ S3ì—ì„œ Amazon Personalizeë¡œ ë°ì´í„°ë¥¼ 로드하는 import jobì„ ì‹¤í–‰í•©ë‹ˆë‹¤.\n",
"\n",
"#### Interaction ë°ì´í„° 세트 Import Job ìƒì„±"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"print(BUCKET_NAME, KEY_PREFIX+\"/\"+DATA_PREFIX+\"/\"+interaction_train_file)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"create_dataset_import_job_response = personalize.create_dataset_import_job(\n",
" jobName = \"interaction-dataset-import-\" + WORK_DATE,\n",
" datasetArn = interaction_dataset_arn,\n",
" dataSource = {\n",
" \"dataLocation\": \"s3://{}/{}\".format(BUCKET_NAME, KEY_PREFIX+\"/\"+DATA_PREFIX+\"/\"+interaction_train_file)\n",
" },\n",
" roleArn = role_arn\n",
")\n",
"\n",
"interation_dataset_import_job_arn = create_dataset_import_job_response['datasetImportJobArn']\n",
"print(json.dumps(create_dataset_import_job_response, indent=2))"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"print(BUCKET_NAME, KEY_PREFIX+\"/\"+DATA_PREFIX+\"/\"+user_train_file)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"create_dataset_import_job_response = personalize.create_dataset_import_job(\n",
" jobName = \"users-dataset-import-\" + WORK_DATE,\n",
" datasetArn = user_dataset_arn,\n",
" dataSource = {\n",
" \"dataLocation\": \"s3://{}/{}\".format(BUCKET_NAME, KEY_PREFIX+\"/\"+DATA_PREFIX+\"/\"+user_train_file)\n",
" },\n",
" roleArn = role_arn\n",
")\n",
"\n",
"user_dataset_import_job_arn = create_dataset_import_job_response['datasetImportJobArn']\n",
"print(json.dumps(create_dataset_import_job_response, indent=2))"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"print(BUCKET_NAME, KEY_PREFIX+\"/\"+DATA_PREFIX+\"/\"+user_train_file)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"create_dataset_import_job_response = personalize.create_dataset_import_job(\n",
" jobName = \"item-dataset-import-\" + WORK_DATE,\n",
" datasetArn = item_dataset_arn,\n",
" dataSource = {\n",
" \"dataLocation\": \"s3://{}/{}\".format(BUCKET_NAME, KEY_PREFIX+\"/\"+DATA_PREFIX+\"/\"+item_train_file)\n",
" },\n",
" roleArn = role_arn\n",
")\n",
"\n",
"item_dataset_import_job_arn = create_dataset_import_job_response['datasetImportJobArn']\n",
"print(json.dumps(create_dataset_import_job_response, indent=2))"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"%store dataset_group_arn\n",
"%store interaction_dataset_arn\n",
"%store user_dataset_arn\n",
"%store item_dataset_arn\n",
"%store interation_dataset_import_job_arn\n",
"%store user_dataset_import_job_arn\n",
"%store item_dataset_import_job_arn\n",
"%store role_arn\n",
"%store role_name"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### ì•„ì´í…œ ë°ì´í„° 세트 Import Job ìƒì„±"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### ë°ì´í„° 세트 Import jobì´ í™œì„±í™” ìƒíƒœê°€ ë 때까지 대기\n",
"\n",
"Import jobì´ ì™„ë£Œë˜ê¸°ê¹Œì§€ ì‹œê°„ì´ ê±¸ë¦½ë‹ˆë‹¤. 아래 코드 ì…€ì˜ ì¶œë ¥ 결과가 DatasetImportJob: ACTIVEê°€ ë 때까지 ê¸°ë‹¤ë ¤ 주세요."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"%%time\n",
"\n",
"status = None\n",
"max_time = time.time() + 3*60*60 # 3 hours\n",
"while time.time() < max_time:\n",
" describe_dataset_import_job_response = personalize.describe_dataset_import_job(\n",
" datasetImportJobArn = interation_dataset_import_job_arn\n",
" )\n",
" \n",
" dataset_import_job = describe_dataset_import_job_response[\"datasetImportJob\"]\n",
" if \"latestDatasetImportJobRun\" not in dataset_import_job:\n",
" status = dataset_import_job[\"status\"]\n",
" print(\"DatasetImportJob: {}\".format(status))\n",
" else:\n",
" status = dataset_import_job[\"latestDatasetImportJobRun\"][\"status\"]\n",
" print(\"LatestDatasetImportJobRun: {}\".format(status))\n",
" \n",
" if status == \"ACTIVE\" or status == \"CREATE FAILED\":\n",
" break\n",
" \n",
" time.sleep(60)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"status = None\n",
"max_time = time.time() + 3*60*60 # 3 hours\n",
"while time.time() < max_time:\n",
" describe_dataset_import_job_response = personalize.describe_dataset_import_job(\n",
" datasetImportJobArn = user_dataset_import_job_arn\n",
" )\n",
" \n",
" dataset_import_job = describe_dataset_import_job_response[\"datasetImportJob\"]\n",
" if \"latestDatasetImportJobRun\" not in dataset_import_job:\n",
" status = dataset_import_job[\"status\"]\n",
" print(\"DatasetImportJob: {}\".format(status))\n",
" else:\n",
" status = dataset_import_job[\"latestDatasetImportJobRun\"][\"status\"]\n",
" print(\"LatestDatasetImportJobRun: {}\".format(status))\n",
" \n",
" if status == \"ACTIVE\" or status == \"CREATE FAILED\":\n",
" break\n",
" \n",
" time.sleep(60)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"status = None\n",
"max_time = time.time() + 3*60*60 # 3 hours\n",
"while time.time() < max_time:\n",
" describe_dataset_import_job_response = personalize.describe_dataset_import_job(\n",
" datasetImportJobArn = item_dataset_import_job_arn\n",
" )\n",
" \n",
" dataset_import_job = describe_dataset_import_job_response[\"datasetImportJob\"]\n",
" if \"latestDatasetImportJobRun\" not in dataset_import_job:\n",
" status = dataset_import_job[\"status\"]\n",
" print(\"DatasetImportJob: {}\".format(status))\n",
" else:\n",
" status = dataset_import_job[\"latestDatasetImportJobRun\"][\"status\"]\n",
" print(\"LatestDatasetImportJobRun: {}\".format(status))\n",
" \n",
" if status == \"ACTIVE\" or status == \"CREATE FAILED\":\n",
" break\n",
" \n",
" time.sleep(60)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## 솔루션 ìƒì„± ë° ì†”ë£¨ì…˜ ë²„ì „ ìƒì„±\n",
"Amazon Personalizeì—ì„œ í›ˆë ¨ëœ ëª¨ë¸ì„ 솔루션ì´ë¼ê³ 하며, ê° ì†”ë£¨ì…˜ì—는 모ë¸ì´ í›ˆë ¨ë˜ì—ˆì„ ë•Œ 주어진 ë°ì´í„°ëŸ‰ê³¼ ê´€ë ¨ëœ ë§Žì€ íŠ¹ì • ë²„ì „ë“¤ì´ ìžˆì„ ìˆ˜ 있습니다.\n",
"\n",
"ìš°ì„ , Amazon Personalizeì—ì„œ 지ì›ë˜ëŠ” ëª¨ë“ ë ˆì‹œí”¼(ì•Œê³ ë¦¬ì¦˜)ì„ ë‚˜ì—´í•©ë‹ˆë‹¤. ë¦¬ìŠ¤íŠ¸ì—…ëœ ë ˆì‹œí”¼ë“¤ 중 User-personalize를 하나를 ì„ íƒí•˜ê³ ì´ë¥¼ 사용하여 모ë¸ì„ 빌드해 봅니다.\n",
"\n",
"\n",
"ì´ í”„ë¡œì„¸ìŠ¤ì˜ ì™„ë£ŒëŠ” ì‹¤ì œë¡œ 40분 ì´ìƒ 소요ë©ë‹ˆë‹¤. ìž‘ì—…ì´ ì™„ë£Œë 때까지(즉, 활성화 ìƒíƒœê°€ ë 때까지) while 루프를 수행하는 ë°©ë²•ë„ ìžˆì§€ë§Œ, ì´ë ‡ê²Œ 하면 다른 ì…€ì˜ ì‹¤í–‰ì„ ì°¨ë‹¨í•˜ê²Œ ë©ë‹ˆë‹¤. ë”°ë¼ì„œ, ë§Žì€ ëª¨ë¸ì„ 만들어 ì‹ ì†í•˜ê²Œ ë°°í¬í•˜ë ¤ë©´ while 루프를 사용하는 ëŒ€ì‹ , 필요한 솔루션 ë²„ì „ë“¤ì„ ìƒì„± 후, SageMaker ë° Cloudwatchì—ì„œ ì—…ë°ì´íŠ¸ë¥¼ 확ì¸í•˜ì„¸ìš”.\n",
"\n",
"### ë ˆì‹œí”¼ 리스트 확ì¸"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"recipe_list = personalize.list_recipes()\n",
"for recipe in recipe_list['recipes']:\n",
" print(recipe['recipeArn'])"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Recipe ì„ íƒ ë° ì†”ë£¨ì…˜ ìƒì„± \n",
"여기ì—서는 ì•Œê³ ë¦¬ì¦˜ ë° í•™ìŠµ 파ë¼ë¯¸í„° ì„ íƒì„ 하여 ëª¨ë¸ ìƒì„±ì„ í•´ 봅니다.\n",
"Personalize는 í›ˆë ¨ëœ ëª¨ë¸ì„ 최ì í™” 하기위한 하ì´í¼ 파ë¼ë¯¸í„° íŠœë‹ ìž‘ì—…ì„ ì§„í–‰í• ìˆ˜ 있습니다. ë ˆì‹œí”¼ì— ë”°ë¼ ì‚¬ìš© 가능한 하í¼íŒŒë¼ë¯¸í„°ëŠ” [여기](https://docs.aws.amazon.com/ko_kr/personalize/latest/dg/working-with-predefined-recipes.html)ì—ì„œ 확ì¸í•´ 봅니다. \n",
"아래는 하ì´í¼íŒŒë¼ë¯¸í„° 세팅 ì˜ˆì œìž…ë‹ˆë‹¤. 여기ì—서는 시간 ê´€ê³„ìƒ ë‹¤ë¥¸ 실험ì—ì„œ ì°¾ì€ ìµœì 화한 ê²°ê³¼ ê°’ì„ ì 용하ë„ë¡ í•©ë‹ˆë‹¤. \n",
"ë˜í•œ ì´ì „ 단계ì—ì„œ í™•ì¸ í–ˆë˜ëŒ€ë¡œ min/max_user_history_length_percentileì„ ì¡°ì •í•˜ì—¬ 봅니다.\n",
"\n",
"하ì´í¼ 파ë¼ë¯¸í„°ì— ê´€ë ¨í•˜ì—¬ ê°œë°œìž ê°€ì´ë“œ [하ì´í¼íŒŒë¼ë¯¸í„° ë° HPO단ì›](https://docs.aws.amazon.com/ko_kr/personalize/latest/dg/customizing-solution-config-hpo.html) ì°¸ê³ í•©ë‹ˆë‹¤.\n",
"\n",
"\n",
"```\n",
"{\n",
" \"performAutoML\": false,\n",
" \"recipeArn\": \"arn:aws:personalize:::recipe/aws-user-personalization\",\n",
" \"performHPO\": true,\n",
" \"solutionConfig\": {\n",
" \"algorithmHyperParameters\": {\n",
" \"hidden_dimension\": \"55\"\n",
" },\n",
" \"hpoConfig\": {\n",
" \"algorithmHyperParameterRanges\": {\n",
" \"categoricalHyperParameterRanges\": [\n",
" {\n",
" \"name\": \"recency_mask\",\n",
" \"values\": [ \"true\", \"false\" ]\n",
" }\n",
" ],\n",
" \"integerHyperParameterRanges\": [\n",
" {\n",
" \"name\": \"bptt\",\n",
" \"minValue\": 20,\n",
" \"maxValue\": 40\n",
" }\n",
" ]\n",
" },\n",
" \"hpoResourceConfig\": {\n",
" \"maxNumberOfTrainingJobs\": \"4\",\n",
" \"maxParallelTrainingJobs\": \"2\"\n",
" }\n",
" }\n",
" }\n",
"}\n",
"```\n",
"\n",
"},\n",
" ]"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"user_personalization_recipe_arn=\"arn:aws:personalize:::recipe/aws-user-personalization\""
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Solution ìƒì„± \n",
"create_solution_response = personalize.create_solution(\n",
" name = \"user-personalization-\" + WORK_DATE,\n",
" datasetGroupArn = dataset_group_arn,\n",
" recipeArn = user_personalization_recipe_arn,\n",
" performHPO=False,\n",
" solutionConfig={ \n",
" \"featureTransformationParameters\": {\n",
" \"max_user_history_length_percentile\": \"0.99\",\n",
" \"min_user_history_length_percentile\": \"0.05\"\n",
" },\n",
"\n",
" \"algorithmHyperParameters\": {\n",
" \"bptt\": \"31\",\n",
" \"hidden_dimension\": \"211\",\n",
" \"recency_mask\": \"true\"\n",
" },\n",
" }\n",
" \n",
" )\n",
"user_personalization_solution_arn = create_solution_response['solutionArn']\n",
"print(json.dumps(create_solution_response, indent=2))\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# 솔루션 ë²„ì „ ìƒì„±\n",
"create_solution_version_response = personalize.create_solution_version(\n",
" solutionArn = user_personalization_solution_arn \n",
")\n",
"\n",
"user_personalization_solution_version_arn = create_solution_version_response['solutionVersionArn']\n",
"print(json.dumps(create_solution_version_response, indent=2))"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"%store user_personalization_solution_version_arn\n",
"%store user_personalization_solution_arn"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"%%time\n",
"\n",
"max_time = time.time() + 8*60*60 # 8 hours\n",
"while time.time() < max_time:\n",
" \n",
" #hrnn status\n",
" describe_solution_version_response = personalize.describe_solution_version(\n",
" solutionVersionArn = user_personalization_solution_version_arn\n",
" ) \n",
" status= describe_solution_version_response[\"solutionVersion\"][\"status\"]\n",
" print(\"User-Personalization SolutionVersion: {}\".format(status))\n",
" \n",
" if (status== \"ACTIVE\" or status == \"CREATE FAILED\"):\n",
" break\n",
" \n",
" time.sleep(300)\n",
"\n",
"print(\"All solution creation completed\")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## 솔루션 í‰ê°€í•˜ê¸° \n",
"\n",
"\n",
"ì´ë²ˆ 파트ì—서는 Amazon Personalizeì—ì„œ 기본으로 ì œê³µí•˜ëŠ” ì†”ë£¨ì…˜ì— ëŒ€í•œ í‰ê°€ 지표를 확ì¸í•´ 봅니다. \n",
"Amazon Personalizeì—서는 í‰ê°€ 지표를 ìƒì„±í•˜ê¸° 위해 약 ëžœë¤ìœ¼ë¡œ 10% 사용ìžì˜ interaction data를 테스트 용으로 활용합니다. \n",
"\n",
"아래 ì´ë¯¸ì§€ëŠ” Amazon Personalizeê°€ ë°ì´í„°ë¥¼ 분리하는 ë°©ë²•ì„ ë³´ì—¬ì¤ë‹ˆë‹¤. 사용ìžê°€ 10 명ì´ê³ ê°ê° 10 ê°œì˜ ìƒí˜¸ ìž‘ìš©ì´ìžˆëŠ” 경우 (여기ì—ì„œ ì›ì€ Interaction data를 나타냄) 타임 스탬프를 기준으로 가장 ì˜¤ëž˜ëœ ê²ƒë¶€í„° ìµœì‹ ê²ƒê¹Œì§€ ë‚˜ì—´ëœ ê²ƒìž…ë‹ˆë‹¤. Amazon Personalize는 사용ìžì˜ 90 % (파란색 ì›)ì˜ ëª¨ë“ Interaction ë°ì´í„°ë¥¼ 사용하여 솔루션 ë²„ì „ì„ í›ˆë ¨ì‹œí‚¤ê³ ë‚˜ë¨¸ì§€ 10 %는 í‰ê°€ë¥¼ 위해 사용합니다. 나머지 10 %ì˜ ê° ì‚¬ìš©ìžì— 대해 Interaction data (녹색 ì›)ì˜ 90 %ê°€ í›ˆë ¨ ëœ ëª¨ë¸ì˜ ìž…ë ¥ê°’ìœ¼ë¡œ 사용ë©ë‹ˆë‹¤. ë°ì´í„°ì˜ 나머지 10 % (주황색 ì›)는 모ë¸ì—ì„œ ìƒì„± ëœ ì¶”ì²œ 결과물과 비êµë˜ê³ í‰ê°€ 지표를 계산하는 ë° ì‚¬ìš©ë©ë‹ˆë‹¤.\n",
"\n",
"\n",
"\n",
"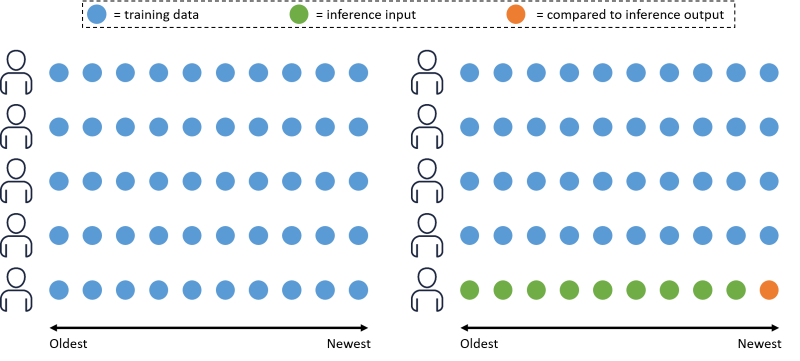\n",
"\n",
"[솔류션 í‰ê°€ 지표 ì •ì˜](https://docs.aws.amazon.com/personalize/latest/dg/working-with-training-metrics.html)\n",
"는 ê°œë°œìž ë¬¸ì„œì˜ ë§í¬ 참조 ë°”ëžë‹ˆë‹¤. ë˜í•œ ì´ ë§í¬ [솔류션 í‰ê°€ ì •ì˜ ì˜ˆì œ](http://francescopochetti.com/recommend-expedia-hotels-with-amazon-personalize-the-magic-of-hierarchical-rnns/) ì˜ íŽ˜ì´ì§€ 맨 아래 ìª½ì„ ë³´ì‹œë©´ 조금 ë” ì§ê´€ì ì¸ ê·¸ë¦¼ì„ ë³´ì‹¤ 수 있습니다.\n",
" <br>\n",
"ë˜í•œ reciprocal_rank_at_5, normalized_discounted_cumulative_gain_at_5,precision_at_5 ì˜ ì˜ˆì œëŠ” 아래와 같습니다. \n",
"* Exmaple\n",
" * 5 ê°œì˜ ì¶”ì²œë¦¬ìŠ¤íŠ¸ë¥¼ ì œê³µí–ˆê³ , ì´ ì¤‘ì— 2번째와 5번째가 ì‹¤ì œ ë°ì´íƒ€ì™€ ì¼ì¹˜ í–ˆë‹¤ê³ í•˜ë©´, 쉽게 ì´ë ‡ê²Œ [0,1,0,0,1] 표시 í• ìˆ˜ 있습니다.\n",
" * reciprocal_rank\n",
" * 1/2 (0.5) # 가장 ë¹ ë¥¸ ìˆœì„œì˜ í•˜ë‚˜ë§Œì„ ì„ íƒ í•©ë‹ˆë‹¤\n",
" * normalized_discounted_cumulative_gain_at_5\n",
" * (1/log(1+2) + 1/log(1+5)) / (1/log(1+1) + 1/log(1+2)) = 0.6241\n",
" * precision_at_5\n",
" * 2/5 (0.4)\n",
"\n",
"\n",
"\n",
"#### ì¡°ê¸ˆë” ìƒì„¸í•˜ê³ Custum í‰ê°€ 지표를 얻기 위해서 ì´ì „ì— ë¶„ë¦¬í•´ë‘” 테스트 ë°ì´í„°ë¥¼ ê°€ì§€ê³ ìº íŽ˜ì¸ ìƒì„± 후 ë³„ë„ í…ŒìŠ¤íŠ¸ë¥¼ 진행하ë„ë¡ í•©ë‹ˆë‹¤.\n",
"\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"get_solution_metrics_response = personalize.get_solution_metrics(\n",
" solutionVersionArn = user_personalization_solution_version_arn\n",
")\n",
"\n",
"print(json.dumps(get_solution_metrics_response, indent=2))\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## ìº íŽ˜ì¸ ìƒì„±í•˜ê¸° \n",
"\n",
"\n",
"\n",
"ìž‘ë™í•˜ëŠ” 솔루션 ë²„ì „ì„ ë³´ìœ í•˜ê³ ìžˆìœ¼ë¯€ë¡œ, ì´ì œ ì• í”Œë¦¬ì¼€ì´ì…˜ê³¼ 함께 ì‚¬ìš©í• ìº íŽ˜ì¸ì„ ìƒì„±í•©ë‹ˆë‹¤. ì¸í”„ë¼ê°€ í”„ë¡œë¹„ì €ë‹ë˜ê¸°ê¹Œì§€ì˜ ì‹œê°„ì´ ì†Œìš”ë©ë‹ˆë‹¤.\n",
"\n",
"\n",
"User-personalization ì†”ë£¨ì…˜ì€ ìº íŽ˜ì¸ì„ 만들 ë•Œ itemExplorationConfig를 ì„¤ì •í•˜ì—¬ 콜드 ì•„ì´í…œ íƒìƒ‰ 가중치와 íƒìƒ‰ ì—°ë ¹ ì œí•œì„ êµ¬ì„± í• ìˆ˜ 있습니다. ì§€ê¸ˆì€ ë” ë†’ì€ explorationWeight를 0ë¡œ ì„¤ì •í•˜ê³ ì½œë“œ ì•„ì´í…œì´ 추천 ë˜ì§€ ì•Šë„ë¡ ì„¸íŒ…í•©ë‹ˆë‹¤. explorationItemAgeCutOff를 7ë¡œ ì„¤ì •í•©ë‹ˆë‹¤.\n",
"ì´ê²½ìš° ìƒì„±í•œ 지 7 ì¼ ë¯¸ë§Œì˜ ëª¨ë“ í•ëª© ìƒì„± ì‹œê°„ì€ ì½œë“œ í•ëª©ìœ¼ë¡œ 간주ë©ë‹ˆë‹¤."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"\n",
"create_campaign_response = personalize.create_campaign(\n",
" name = \"user-personalization-campaign-\" + WORK_DATE,\n",
" solutionVersionArn = user_personalization_solution_version_arn,\n",
" campaignConfig = {\"itemExplorationConfig\": {\"explorationWeight\": \"0\", \"explorationItemAgeCutOff\": \"7\"}},\n",
" minProvisionedTPS = 1\n",
")\n",
"\n",
"user_personalization_campaign_arn = create_campaign_response['campaignArn']\n",
"print(json.dumps(create_campaign_response, indent=2))\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"%store user_personalization_campaign_arn "
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"\n",
"status = None\n",
"max_time = time.time() + 3*60*60 # 3 hours\n",
"while time.time() < max_time:\n",
" describe_campaign_response = personalize.describe_campaign(\n",
" campaignArn = user_personalization_campaign_arn\n",
" )\n",
" status = describe_campaign_response[\"campaign\"][\"status\"]\n",
" print(\"Campaign: {}\".format(status))\n",
" \n",
" if status == \"ACTIVE\" or status == \"CREATE FAILED\":\n",
" break\n",
" \n",
" time.sleep(60)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"describe_campaign_response = personalize.describe_campaign(campaignArn = user_personalization_campaign_arn)\n",
"campaign_summary = describe_campaign_response[\"campaign\"]\n",
"campaign_summary"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"items=pd.read_csv(item_file)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"def get_movie_title(movie_id):\n",
" \"\"\"\n",
" Takes in an ID, returns a title\n",
" \"\"\"\n",
" movie_id = int(movie_id)\n",
" movie_title=items[items['ITEM_ID']==movie_id]['TITLE']\n",
" return (movie_title.tolist())\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"user_id= 100\n",
"get_recommendations_response = personalize_runtime.get_recommendations(\n",
" campaignArn = user_personalization_campaign_arn,\n",
" userId = str(user_id),\n",
")\n",
"# Update DF rendering\n",
"pd.set_option('display.max_rows', 30)\n",
"\n",
"print(\"Recommendations for user: \", user_id)\n",
"\n",
"item_list = get_recommendations_response['itemList']\n",
"\n",
"recommendation_title_list = []\n",
"recommendation_id_list=[]\n",
"for item in item_list:\n",
" title = get_movie_title(item['itemId'])\n",
" score=item['score']\n",
" recommendation_title_list.append([title,score])\n",
" recommendation_id_list.append(item['itemId'])\n",
"recommendations_df = pd.DataFrame(recommendation_title_list ,columns = ['OriginalRecs','score'])\n",
"recommendations_df"
]
}
],
"metadata": {
"kernelspec": {
"display_name": "conda_python3",
"language": "python",
"name": "conda_python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.6.10"
}
},
"nbformat": 4,
"nbformat_minor": 4
}