# SageMaker Pipeline Project 를 위한 사용자 정의 프로젝트 템플릿 생성 및 배포
원제목: SageMaker 프로젝트와 함께 Amazon SageMaker 재사용 가능한 구성 요소
## [역자 알림]
- 원문 코드 리파지토리 [Amazon SageMaker reusable components with SageMaker Projects](https://github.com/aws-samples/amazon-sagemaker-reusable-components) 의 컨텐츠를 재사용하였으며, 실습의 편리함을 위해 재구성을 하였고, 원문의 에러를 수정한 버젼 입니다.
- 바로 실습을 가실 분은 아래를 클릭 하세요.
- [README-Action](README-Action.md)
# 1. 전체 개요
이 솔루션은 [AWS Service Catalog](https://aws.amazon.com/servicecatalog/), [AWS CloudFormation](https://aws.amazon.com/cloudformation/), [SageMaker Projects](https://docs.aws.amazon.com/sagemaker/latest/dg/sagemaker-projects-whatis.html) 및 [SageMaker Pipelines](https://aws.amazon.com/sagemaker/pipelines/) 을 사용하여
세이지 메이커 환경에 재사용 가능하고 독립적인 ML 구성 요소를 제공하는 방법을 보여줍니다.
상세한 사항은 여기 블로그를 [Enhance your machine learning development by using a modular architecture with Amazon SageMaker projects](https://aws.amazon.com/blogs/machine-learning/enhance-your-machine-learning-development-by-using-a-modular-architecture-with-amazon-sagemaker-projects/) 참조 하세요.
# 2. 솔루션 개요
여러 개발 도메인에 걸쳐 있는 ML 워크플로의 예로 제안된 솔루션은 [Amazon SageMaker Feature Store](https://aws.amazon.com//sagemaker/feature-store/)로 데이터 변환, 기능 추출 및 수집을 위한 자동화된 파이프라인의 사용 사례를 구현합니다.
높은 수준에서 워크플로는 다음 단계로 구성됩니다.
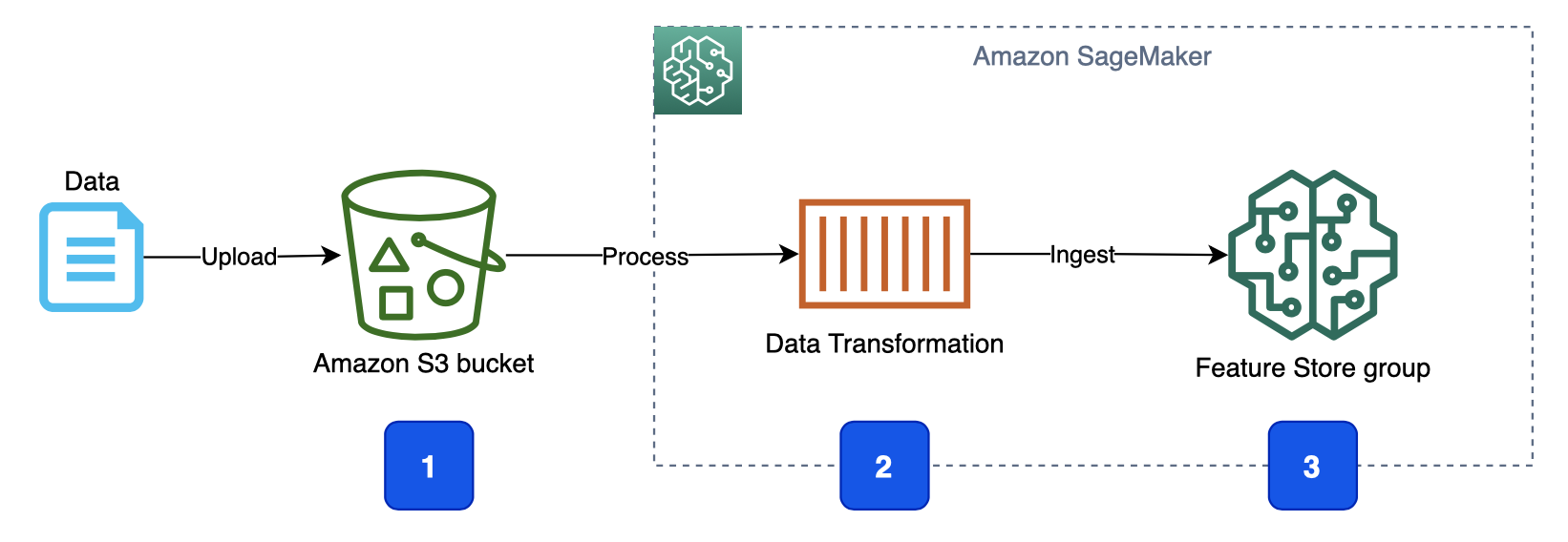 1. 업스트림 데이터 수집 구성 요소는 데이터 파일을 [Amazon Simple Storage Service(Amazon S3)](https://docs.aws.amazon.com/sagemaker/latest/dg/feature-store-getting-started.html) 버킷에 업로드합니다.
2. 데이터 업로드 이벤트는 데이터 처리 및 변환 프로세스를 시작합니다.
3. 데이터 변환 프로세스는 기능을 추출, 처리 및 변환하고 이를 기능 저장소의 지정된 [피쳐 그룹] 으로 수집합니다.
# 3. 솔루션 아키텍처
솔루션의 자세한 구성 요소 아키텍처는 다음 다이어그램에 나와 있습니다.
1. 업스트림 데이터 수집 구성 요소는 데이터 파일을 [Amazon Simple Storage Service(Amazon S3)](https://docs.aws.amazon.com/sagemaker/latest/dg/feature-store-getting-started.html) 버킷에 업로드합니다.
2. 데이터 업로드 이벤트는 데이터 처리 및 변환 프로세스를 시작합니다.
3. 데이터 변환 프로세스는 기능을 추출, 처리 및 변환하고 이를 기능 저장소의 지정된 [피쳐 그룹] 으로 수집합니다.
# 3. 솔루션 아키텍처
솔루션의 자세한 구성 요소 아키텍처는 다음 다이어그램에 나와 있습니다.
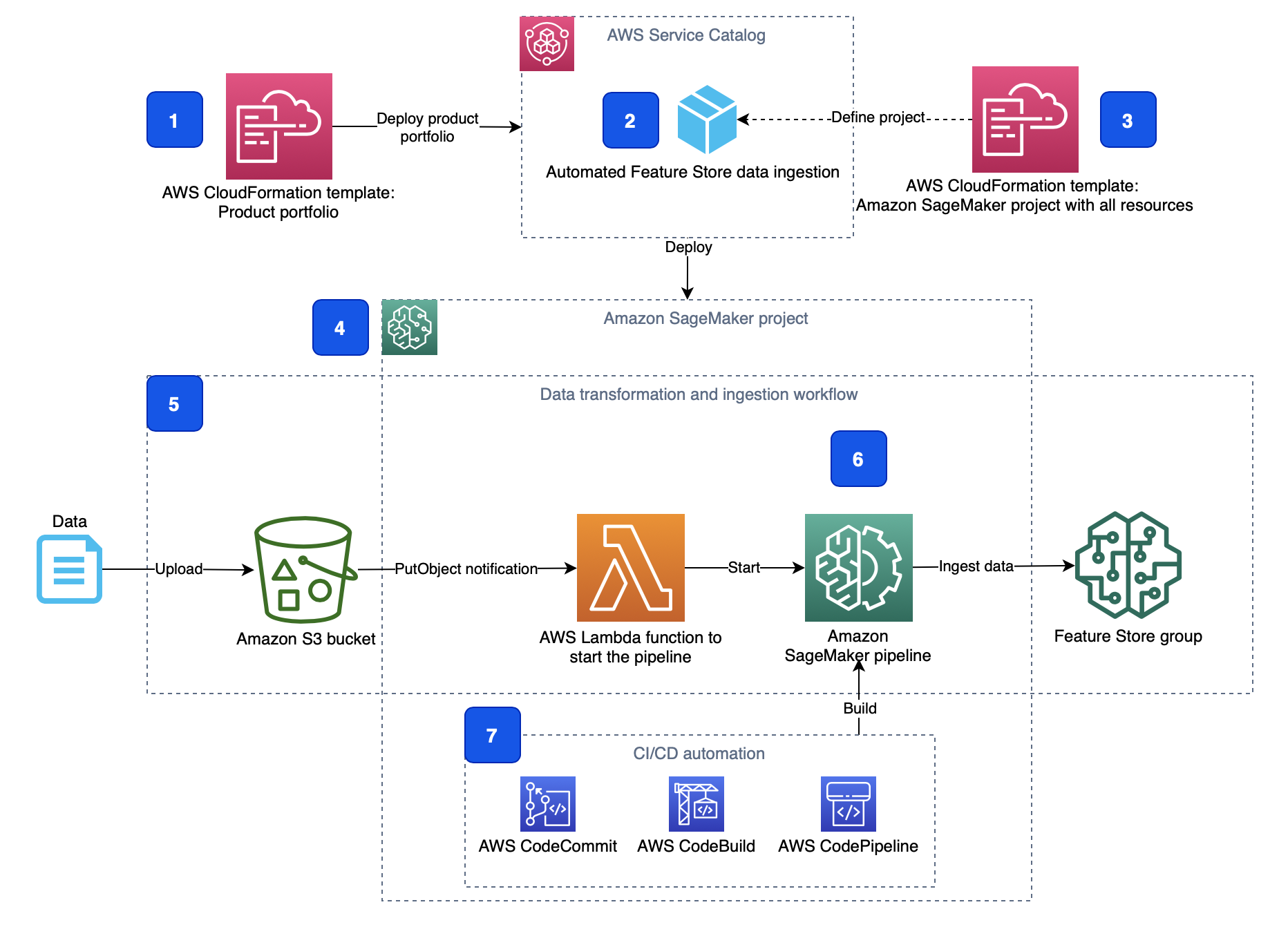 - 제품 포트폴리오 **(1)**는 포트폴리오 및 포함 제품을 사용할 수 있는 관련 사용자 역할과 함께 자동화된 기능 저장소 데이터 수집 제품 **(2)**을 정의합니다.
- CloudFormation 템플릿은 제품 포트폴리오(1)와 제품(2)을 모두 정의합니다.
- CloudFormation 템플릿 **(3)**에는 SageMaker 환경에서 제품을 프로비저닝하는 데 필요한 모든 리소스, 소스 코드, 구성 및 권한이 포함되어 있습니다.
- AWS CloudFormation은 제품을 배포할 때 새 SageMaker 프로젝트 **(4)**를 생성합니다.
- SageMaker 프로젝트는 기능 수집 워크플로 **(5)**를 구현합니다. 워크플로에는 매번 [Amazon EventBridge](https://aws.amazon.com/eventbridge/) 규칙에 의해 시작되는 [AWS Lambda](https://aws.amazon.com/lambda/) 함수가 포함되어 있습니다. 새 객체가 모니터링되는 S3 버킷에 업로드됩니다. Lambda 함수는 SageMaker 프로젝트의 일부로 정의 및 프로비저닝되는 [Amazon SageMaker Pipeline](https://aws.amazon.com/sagemaker/pipelines/) **(6)**을 시작합니다. 파이프라인은 기능 저장소에서 데이터 변환 및 수집을 구현합니다.
- SageMaker 파이프라인의 빌드 및 배포를 오케스트레이션 [AWS CodePipeline](https://aws.amazon.com/codepipeline/) 하기 위해서 파이프라인 빌드 스크립트와 함꼐 프로젝트는 또한 [AWS CodeBuild](https://aws.amazon.com/codebuild/) 소스 코드가 있는 [AWS CodeCommit](https://aws.amazon.com/codecommit/) 리포지토리로 CI/CD 자동화 **(7)**를 프로비저닝합니다.
# 4. ML 파이프라인
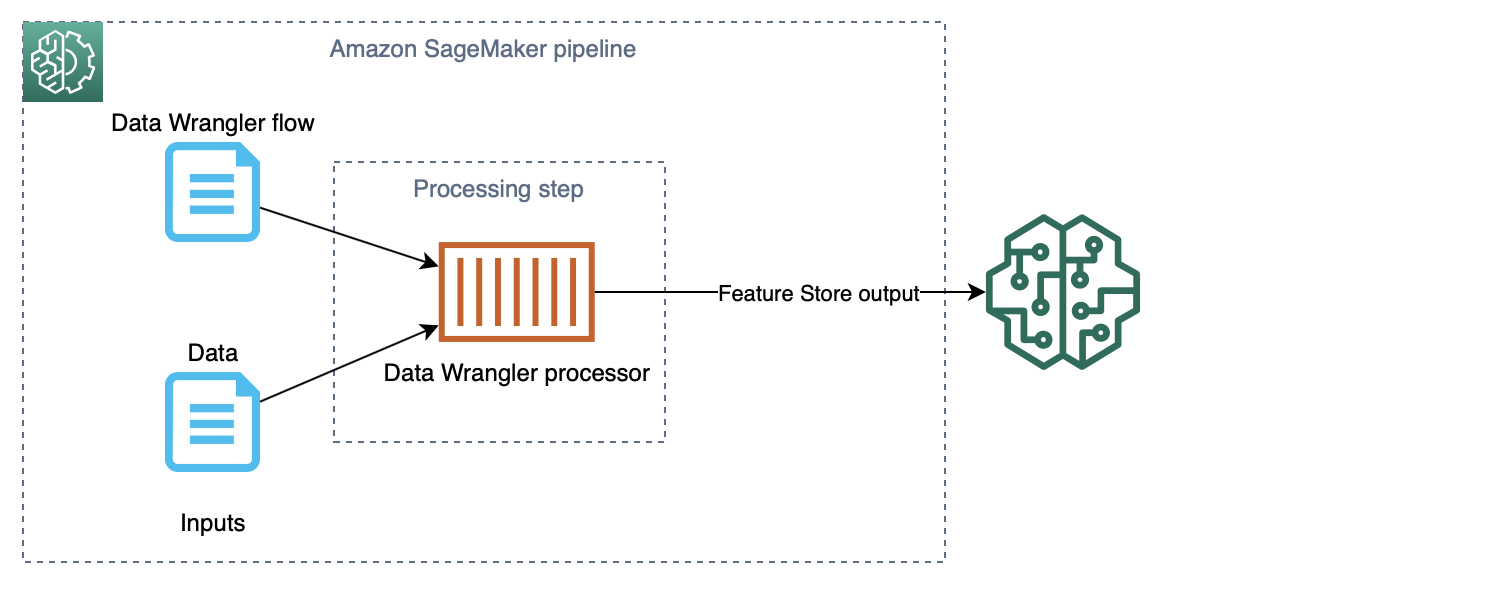
- 이 솔루션은 ML 워크플로 생성 및 조정 프레임워크인 Amazon SageMaker Pipelines를 사용하여 ML 파이프라인을 구현합니다.
- 파이프라인에는 피쳐 저장소의 피쳐 그룹으로 데이터 변환 및 수집을 위한 [Amazon SageMaker Data Wrangler](https://aws.amazon.com/sagemaker/data-wrangler/) 프로세서가 포함된 단일 단계가 포함되어 있습니다.
- 다음 다이어그램은 이 솔루션으로 구현된 데이터 처리 파이프라인을 보여줍니다.
- 제품 포트폴리오 **(1)**는 포트폴리오 및 포함 제품을 사용할 수 있는 관련 사용자 역할과 함께 자동화된 기능 저장소 데이터 수집 제품 **(2)**을 정의합니다.
- CloudFormation 템플릿은 제품 포트폴리오(1)와 제품(2)을 모두 정의합니다.
- CloudFormation 템플릿 **(3)**에는 SageMaker 환경에서 제품을 프로비저닝하는 데 필요한 모든 리소스, 소스 코드, 구성 및 권한이 포함되어 있습니다.
- AWS CloudFormation은 제품을 배포할 때 새 SageMaker 프로젝트 **(4)**를 생성합니다.
- SageMaker 프로젝트는 기능 수집 워크플로 **(5)**를 구현합니다. 워크플로에는 매번 [Amazon EventBridge](https://aws.amazon.com/eventbridge/) 규칙에 의해 시작되는 [AWS Lambda](https://aws.amazon.com/lambda/) 함수가 포함되어 있습니다. 새 객체가 모니터링되는 S3 버킷에 업로드됩니다. Lambda 함수는 SageMaker 프로젝트의 일부로 정의 및 프로비저닝되는 [Amazon SageMaker Pipeline](https://aws.amazon.com/sagemaker/pipelines/) **(6)**을 시작합니다. 파이프라인은 기능 저장소에서 데이터 변환 및 수집을 구현합니다.
- SageMaker 파이프라인의 빌드 및 배포를 오케스트레이션 [AWS CodePipeline](https://aws.amazon.com/codepipeline/) 하기 위해서 파이프라인 빌드 스크립트와 함꼐 프로젝트는 또한 [AWS CodeBuild](https://aws.amazon.com/codebuild/) 소스 코드가 있는 [AWS CodeCommit](https://aws.amazon.com/codecommit/) 리포지토리로 CI/CD 자동화 **(7)**를 프로비저닝합니다.
# 4. ML 파이프라인
- 이 솔루션은 ML 워크플로 생성 및 조정 프레임워크인 Amazon SageMaker Pipelines를 사용하여 ML 파이프라인을 구현합니다.
- 파이프라인에는 피쳐 저장소의 피쳐 그룹으로 데이터 변환 및 수집을 위한 [Amazon SageMaker Data Wrangler](https://aws.amazon.com/sagemaker/data-wrangler/) 프로세서가 포함된 단일 단계가 포함되어 있습니다.
- 다음 다이어그램은 이 솔루션으로 구현된 데이터 처리 파이프라인을 보여줍니다.
 # 5. IAM 역할 및 권한
다음 다이어그램은 관련된 모든 IAM 역할과 어떤 서비스 또는 리소스가 어떤 역할을 맡는지 보여줍니다.
# 5. IAM 역할 및 권한
다음 다이어그램은 관련된 모든 IAM 역할과 어떤 서비스 또는 리소스가 어떤 역할을 맡는지 보여줍니다.
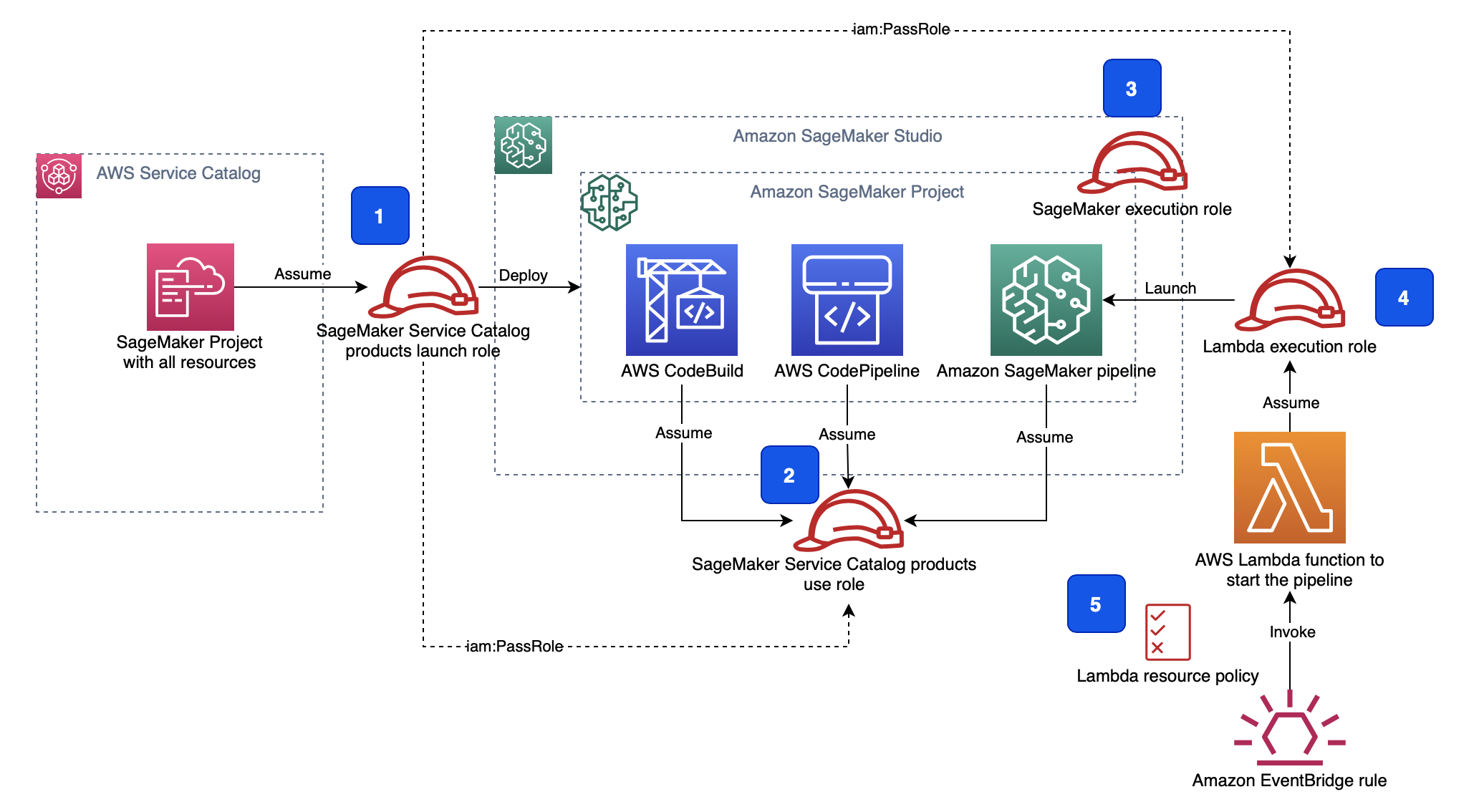 IAM 설정에는 다음 역할이 포함됩니다.
1. SageMaker 서비스 카탈로그 제품 시작 역할. 이 역할은 SageMaker 서비스 카탈로그 제품 사용 역할(2) 및 Lambda 실행 역할(4)에 대한 'iam:PassRole' API를 호출합니다.
2. SageMaker 서비스 카탈로그 제품은 역할을 사용합니다. 프로젝트 자원은 작업을 수행하기 위해 이 역할을 맡습니다 (Assume).
3. SageMaker 실행 역할. Studio 노트북은 이 역할을 사용하여 S3 버킷을 포함한 모든 리소스에 액세스합니다.
4. Lambda 실행 역할. Lambda 함수는 이 역할을 맡습니다 (Assume).
5. Lambda 함수 [리소스 정책](https://docs.aws.amazon.com/lambda/latest/dg/access-control-resource-based.html)은 EventBridge가 함수를 호출하도록 허용합니다.
프로젝트에 대한 Studio 권한 설정에 대한 자세한 내용은 [SageMaker Studio 프로젝트 사용에 필요한 권한](https://docs.aws.amazon.com/sagemaker/latest/dg/sagemaker-projects-studio-updates.html)을 참조하십시오.
# 6. 액션: 실습하기
다음의 설명서로 이동 합니다.
- [README-Action](README-Action.md)
# 7. 데이터 세트
이 솔루션에서는 잘 알려진 [Abalone dataset](https://www.csie.ntu.edu.tw/~cjlin/libsvmtools/datasets/regression.html#abalone)을 사용합니다. 데이터 세트에는 4177개의 데이터 행과 8개의 기능이 있습니다.
Dua, D. 및 Graff, C. (2019). UCI 기계 학습 저장소. 캘리포니아 어바인: 캘리포니아 대학교 정보 및 컴퓨터 과학 학교.
다음에서 데이터세트를 다운로드할 수 있습니다. [UCI website](http://archive.ics.uci.edu/ml/datasets/Abalone):
```
wget -t inf http://archive.ics.uci.edu/ml/machine-learning-databases/abalone/abalone.data
wget -t inf http://archive.ics.uci.edu/ml/machine-learning-databases/abalone/abalone.names
```
데이터 세트를 다운로드하고 사용하는 방법에 대한 지침은 여기서 확인 하세요. [`00-setup` notebook](notebooks/00-setup.ipynb)
# 8. Resources
- [Automate a centralized deployment of Amazon SageMaker Studio with AWS Service Catalog](https://aws.amazon.com/blogs/machine-learning/automate-a-centralized-deployment-of-amazon-sagemaker-studio-with-aws-service-catalog/)
- [Create Amazon SageMaker projects with image building CI/CD pipelines](https://aws.amazon.com/blogs/machine-learning/create-amazon-sagemaker-projects-with-image-building-ci-cd-pipelines/)
- [Create Amazon SageMaker projects using third-party source control and Jenkins
](https://aws.amazon.com/blogs/machine-learning/create-amazon-sagemaker-projects-using-third-party-source-control-and-jenkins/)
- [GitHub public repository for Feature Store workshop](https://github.com/aws-samples/amazon-sagemaker-feature-store-end-to-end-workshop)
- [GitHub public repository for Amazon SageMaker Drift Detection](https://github.com/aws-samples/amazon-sagemaker-drift-detection)
- [Schedule an Amazon SageMaker Data Wrangler flow to process new data periodically using AWS Lambda functions](https://aws.amazon.com/blogs/machine-learning/schedule-an-amazon-sagemaker-data-wrangler-flow-to-process-new-data-periodically-using-aws-lambda-functions/)
- [Build, tune, and deploy an end-to-end churn prediction model using Amazon SageMaker Pipelines](https://aws.amazon.com/blogs/machine-learning/build-tune-and-deploy-an-end-to-end-churn-prediction-model-using-amazon-sagemaker-pipelines/)
- [Build Custom SageMaker Project Templates – Best Practices](https://aws.amazon.com/blogs/machine-learning/build-custom-sagemaker-project-templates-best-practices/)
# 9. 라이센스
이 라이브러리는 MIT-0 라이선스에 따라 사용이 허가되었습니다. [LICENSE](LICENSE) 파일을 참조하십시오.
Copyright Amazon.com, Inc. or its affiliates. All Rights Reserved.
SPDX-License-Identifier: MIT-0
IAM 설정에는 다음 역할이 포함됩니다.
1. SageMaker 서비스 카탈로그 제품 시작 역할. 이 역할은 SageMaker 서비스 카탈로그 제품 사용 역할(2) 및 Lambda 실행 역할(4)에 대한 'iam:PassRole' API를 호출합니다.
2. SageMaker 서비스 카탈로그 제품은 역할을 사용합니다. 프로젝트 자원은 작업을 수행하기 위해 이 역할을 맡습니다 (Assume).
3. SageMaker 실행 역할. Studio 노트북은 이 역할을 사용하여 S3 버킷을 포함한 모든 리소스에 액세스합니다.
4. Lambda 실행 역할. Lambda 함수는 이 역할을 맡습니다 (Assume).
5. Lambda 함수 [리소스 정책](https://docs.aws.amazon.com/lambda/latest/dg/access-control-resource-based.html)은 EventBridge가 함수를 호출하도록 허용합니다.
프로젝트에 대한 Studio 권한 설정에 대한 자세한 내용은 [SageMaker Studio 프로젝트 사용에 필요한 권한](https://docs.aws.amazon.com/sagemaker/latest/dg/sagemaker-projects-studio-updates.html)을 참조하십시오.
# 6. 액션: 실습하기
다음의 설명서로 이동 합니다.
- [README-Action](README-Action.md)
# 7. 데이터 세트
이 솔루션에서는 잘 알려진 [Abalone dataset](https://www.csie.ntu.edu.tw/~cjlin/libsvmtools/datasets/regression.html#abalone)을 사용합니다. 데이터 세트에는 4177개의 데이터 행과 8개의 기능이 있습니다.
Dua, D. 및 Graff, C. (2019). UCI 기계 학습 저장소. 캘리포니아 어바인: 캘리포니아 대학교 정보 및 컴퓨터 과학 학교.
다음에서 데이터세트를 다운로드할 수 있습니다. [UCI website](http://archive.ics.uci.edu/ml/datasets/Abalone):
```
wget -t inf http://archive.ics.uci.edu/ml/machine-learning-databases/abalone/abalone.data
wget -t inf http://archive.ics.uci.edu/ml/machine-learning-databases/abalone/abalone.names
```
데이터 세트를 다운로드하고 사용하는 방법에 대한 지침은 여기서 확인 하세요. [`00-setup` notebook](notebooks/00-setup.ipynb)
# 8. Resources
- [Automate a centralized deployment of Amazon SageMaker Studio with AWS Service Catalog](https://aws.amazon.com/blogs/machine-learning/automate-a-centralized-deployment-of-amazon-sagemaker-studio-with-aws-service-catalog/)
- [Create Amazon SageMaker projects with image building CI/CD pipelines](https://aws.amazon.com/blogs/machine-learning/create-amazon-sagemaker-projects-with-image-building-ci-cd-pipelines/)
- [Create Amazon SageMaker projects using third-party source control and Jenkins
](https://aws.amazon.com/blogs/machine-learning/create-amazon-sagemaker-projects-using-third-party-source-control-and-jenkins/)
- [GitHub public repository for Feature Store workshop](https://github.com/aws-samples/amazon-sagemaker-feature-store-end-to-end-workshop)
- [GitHub public repository for Amazon SageMaker Drift Detection](https://github.com/aws-samples/amazon-sagemaker-drift-detection)
- [Schedule an Amazon SageMaker Data Wrangler flow to process new data periodically using AWS Lambda functions](https://aws.amazon.com/blogs/machine-learning/schedule-an-amazon-sagemaker-data-wrangler-flow-to-process-new-data-periodically-using-aws-lambda-functions/)
- [Build, tune, and deploy an end-to-end churn prediction model using Amazon SageMaker Pipelines](https://aws.amazon.com/blogs/machine-learning/build-tune-and-deploy-an-end-to-end-churn-prediction-model-using-amazon-sagemaker-pipelines/)
- [Build Custom SageMaker Project Templates – Best Practices](https://aws.amazon.com/blogs/machine-learning/build-custom-sagemaker-project-templates-best-practices/)
# 9. 라이센스
이 라이브러리는 MIT-0 라이선스에 따라 사용이 허가되었습니다. [LICENSE](LICENSE) 파일을 참조하십시오.
Copyright Amazon.com, Inc. or its affiliates. All Rights Reserved.
SPDX-License-Identifier: MIT-0