{
"cells": [
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# [모듈 3.2] 전처리 스텝 개발 (SageMaker Model Building Pipeline 전처리 스텝)\n",
"\n",
"이 노트북은 \"모델 전처리\" 스텝을 정의하고, 모델 빌딩 파이프라인을 생성하여 실행하는 노트북 입니다.\n",
"아래의 목차와 같이 노트북 실행이 될 예정이고\n",
"전체를 모두 실행시에 완료 시간은 약 5분-10분 소요 됩니다.\n",
"\n",
"- 1. 전처리 개요 (SageMaker Processing 이용)\n",
"- 2. 기본 라이브러리 로딩\n",
"- 3. 원본 데이터 파일 확인 및 전처리 코드 로직 확인\n",
"- 4. 모델 빌딩 파이프라인 의 스텝(Step) 생성\n",
"- 5. 파리마터, 단계, 조건을 조합하여 최종 파이프라인 정의 및 실행\n",
"- 6. 세이지 메이커 스튜디오에서 확인하기\n",
"- 7. 전처리 파일 경로 추출\n",
"\n",
"---\n",
"## SageMaker 파이프라인 소개\n",
"\n",
"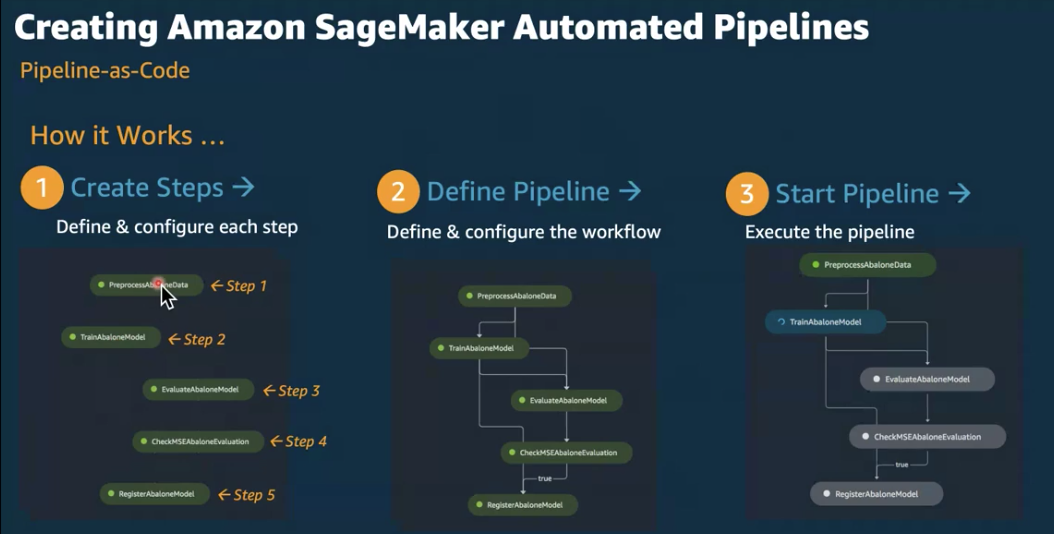\n",
"\n",
"\n",
"\n",
"SageMaker 파이프라인은 다음 기능을 지원하며 본 lab_03_pipelinie 에서 일부를 다루게 됩니다. \n",
"\n",
"* Processing job steps - 데이터처러 워크로드를 실행하기 위한 SageMaker의 관리형 기능. Feature engineering, 데이터 검증, 모델 평가, 모델 해석 등에 주로 사용됨 \n",
"* Training job steps - 학습작업. 모델에게 학습데이터셋을 이용하여 모델에게 예측을 하도록 학습시키는 작업 \n",
"* Conditional execution steps - 조건별 실행분기. 파이프라인을 분기시키는 역할.\n",
"* Register model steps - 학습이 완료된 모델패키지 리소스를 이후 배포를 위한 모델 레지스트리에 등록하기 \n",
"* Create model steps - 추론 엔드포인트 또는 배치 추론을 위한 모델의 생성 \n",
"* Transform job steps - 배치추론 작업. 배치작업을 이용하여 노이즈, bias의 제거 등 데이터셋을 전처리하고 대량데이터에 대해 추론을 실행하는 단계\n",
"* Pipelines - Workflow DAG. SageMaker 작업과 리소스 생성을 조율하는 단계와 조건을 가짐\n",
"* Parametrized Pipeline executions - 특정 파라미터에 따라 파이프라인 실행방식을 변화시키기 \n",
"\n",
"\n",
"- 상세한 개발자 가이드는 아래 참조 하세요.\n",
" - [세이지 메이커 모델 빌딩 파이프라인의 개발자 가이드](https://docs.aws.amazon.com/sagemaker/latest/dg/pipelines.html)\n",
"\n",
"---\n",
"### 노트북 커널\n",
"- 이 워크샵은 노트북 커널이 `conda_python3` 를 사용합니다. 다른 커널일 경우 변경 해주세요.\n",
"---\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# 1. 전처리 개요 (SageMaker Processing 이용)\n",
"\n",
"이 노트북은 세이지 메이커의 Processing Job을 통해서 데이터 전처리를 합니다.
\n",
"상세한 사항은 개발자 가이드를 참조 하세요. --> [SageMaker Processing](https://docs.aws.amazon.com/ko_kr/sagemaker/latest/dg/processing-job.html)\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"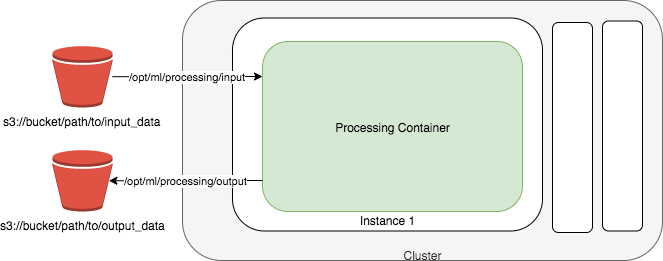\n",
"- 일반적으로 크게 아래 4가지의 스텝으로 진행이 됩니다.\n",
"\n",
" - (1) S3에 입력 파일 준비\n",
" - (2) 전처리를 수행하는 코드 준비\n",
" - (3) Projcessing Job을 생성시에 아래와 같은 항목을 제공합니다.\n",
" - Projcessing Job을 실행할 EC2(예: ml.m4.2xlarge) 기술\n",
" - EC2에서 로딩할 다커 이미지의 이름 기술\n",
" - S3 입력 파일 경로\n",
" - 전처리 코드 경로\n",
" - S3 출력 파일 경로\n",
" - (4) EC2에서 전치리 실행 하여 S3 출력 위치에 저장\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## 1.2 프로세싱 스텝 \n",
"- 프로세싱 단계의 개발자 가이드 \n",
" - [프로세싱 스텝](https://docs.aws.amazon.com/ko_kr/sagemaker/latest/dg/build-and-manage-steps.html#step-type-processing)\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# 2. 기본 라이브러리 로딩\n",
"\n",
"세이지 메이커 관련 라이브러리를 로딩 합니다."
]
},
{
"cell_type": "code",
"execution_count": 22,
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"import boto3\n",
"import sagemaker\n",
"import pandas as pd\n",
"from IPython.display import display as dp\n",
"\n",
"region = boto3.Session().region_name\n",
"sagemaker_session = sagemaker.session.Session()\n",
"role = sagemaker.get_execution_role()"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## 2.1 노트북 변수 로딩\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"저장된 변수를 확인 합니다."
]
},
{
"cell_type": "code",
"execution_count": 23,
"metadata": {
"tags": []
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Stored variables and their in-db values:\n",
"bucket -> 'sagemaker-us-east-1-585843180719'\n",
"claims_data_uri -> 's3://sagemaker-us-east-1-585843180719/sagemaker-w\n",
"customers_data_uri -> 's3://sagemaker-us-east-1-585843180719/sagemaker-w\n",
"input_data_uri -> 's3://sagemaker-us-east-1-585843180719/sagemaker-w\n",
"preprocessing_code -> 'src/preprocessing.py'\n",
"project_prefix -> 'sagemaker-webinar-pipeline-base'\n"
]
}
],
"source": [
"%store"
]
},
{
"cell_type": "code",
"execution_count": 24,
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"%store -r"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# 3. 원본 데이터 파일 확인 및 전처리 코드 로직 확인\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## 3.1. 전처리에서 사용할 원본 데이터를 확인\n",
"- 고객 데어터\n",
"- 보험 청구 데이터"
]
},
{
"cell_type": "code",
"execution_count": 25,
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"import os\n",
"\n",
"data_dir = '../data/raw'\n",
"local_claim_data_path = f\"{data_dir}/claims.csv\"\n",
"local_customers_data_path = f\"{data_dir}/customers.csv\"\n"
]
},
{
"cell_type": "code",
"execution_count": 26,
"metadata": {
"tags": []
},
"outputs": [
{
"data": {
"text/html": [
"\n",
"\n",
"
\n",
" \n",
" \n",
" | \n",
" policy_id | \n",
" customer_age | \n",
" months_as_customer | \n",
" num_claims_past_year | \n",
" num_insurers_past_5_years | \n",
" policy_state | \n",
" policy_deductable | \n",
" policy_annual_premium | \n",
" policy_liability | \n",
" customer_zip | \n",
" customer_gender | \n",
" customer_education | \n",
" auto_year | \n",
"
\n",
" \n",
" \n",
" \n",
" | 0 | \n",
" 1 | \n",
" 54 | \n",
" 94 | \n",
" 0 | \n",
" 1 | \n",
" WA | \n",
" 750 | \n",
" 3000 | \n",
" 25/50 | \n",
" 99207 | \n",
" Unkown | \n",
" Associate | \n",
" 2006 | \n",
"
\n",
" \n",
" | 1 | \n",
" 2 | \n",
" 41 | \n",
" 165 | \n",
" 0 | \n",
" 1 | \n",
" CA | \n",
" 750 | \n",
" 2950 | \n",
" 15/30 | \n",
" 95632 | \n",
" Male | \n",
" Bachelor | \n",
" 2012 | \n",
"
\n",
" \n",
" | 2 | \n",
" 3 | \n",
" 57 | \n",
" 155 | \n",
" 0 | \n",
" 1 | \n",
" CA | \n",
" 750 | \n",
" 3000 | \n",
" 15/30 | \n",
" 93203 | \n",
" Female | \n",
" Bachelor | \n",
" 2017 | \n",
"
\n",
" \n",
" | 3 | \n",
" 4 | \n",
" 39 | \n",
" 80 | \n",
" 0 | \n",
" 1 | \n",
" AZ | \n",
" 750 | \n",
" 3000 | \n",
" 30/60 | \n",
" 85208 | \n",
" Female | \n",
" Advanced Degree | \n",
" 2020 | \n",
"
\n",
" \n",
" | 4 | \n",
" 5 | \n",
" 39 | \n",
" 60 | \n",
" 0 | \n",
" 1 | \n",
" CA | \n",
" 750 | \n",
" 3000 | \n",
" 15/30 | \n",
" 91792 | \n",
" Female | \n",
" High School | \n",
" 2018 | \n",
"
\n",
" \n",
"
\n",
"
\n",
"\n",
"
\n",
" \n",
" \n",
" | \n",
" policy_id | \n",
" driver_relationship | \n",
" incident_type | \n",
" collision_type | \n",
" incident_severity | \n",
" authorities_contacted | \n",
" num_vehicles_involved | \n",
" num_injuries | \n",
" num_witnesses | \n",
" police_report_available | \n",
" injury_claim | \n",
" vehicle_claim | \n",
" total_claim_amount | \n",
" incident_month | \n",
" incident_day | \n",
" incident_dow | \n",
" incident_hour | \n",
" fraud | \n",
"
\n",
" \n",
" \n",
" \n",
" | 0 | \n",
" 1 | \n",
" Spouse | \n",
" Collision | \n",
" Front | \n",
" Minor | \n",
" None | \n",
" 2 | \n",
" 0 | \n",
" 0 | \n",
" No | \n",
" 71600 | \n",
" 8913.668763 | \n",
" 80513.668763 | \n",
" 3 | \n",
" 17 | \n",
" 6 | \n",
" 8 | \n",
" 0 | \n",
"
\n",
" \n",
" | 1 | \n",
" 2 | \n",
" Self | \n",
" Collision | \n",
" Rear | \n",
" Totaled | \n",
" Police | \n",
" 3 | \n",
" 4 | \n",
" 0 | \n",
" Yes | \n",
" 6400 | \n",
" 19746.724395 | \n",
" 26146.724395 | \n",
" 12 | \n",
" 11 | \n",
" 2 | \n",
" 11 | \n",
" 0 | \n",
"
\n",
" \n",
" | 2 | \n",
" 3 | \n",
" Self | \n",
" Collision | \n",
" Front | \n",
" Minor | \n",
" Police | \n",
" 2 | \n",
" 0 | \n",
" 1 | \n",
" Yes | \n",
" 10400 | \n",
" 11652.969918 | \n",
" 22052.969918 | \n",
" 12 | \n",
" 24 | \n",
" 1 | \n",
" 14 | \n",
" 0 | \n",
"
\n",
" \n",
" | 3 | \n",
" 4 | \n",
" Child | \n",
" Collision | \n",
" Side | \n",
" Minor | \n",
" None | \n",
" 2 | \n",
" 0 | \n",
" 0 | \n",
" No | \n",
" 104700 | \n",
" 11260.930936 | \n",
" 115960.930936 | \n",
" 12 | \n",
" 23 | \n",
" 0 | \n",
" 19 | \n",
" 0 | \n",
"
\n",
" \n",
" | 4 | \n",
" 5 | \n",
" Self | \n",
" Collision | \n",
" Side | \n",
" Major | \n",
" Police | \n",
" 2 | \n",
" 1 | \n",
" 0 | \n",
" No | \n",
" 3400 | \n",
" 27987.704652 | \n",
" 31387.704652 | \n",
" 5 | \n",
" 8 | \n",
" 2 | \n",
" 8 | \n",
" 0 | \n",
"
\n",
" \n",
"
\n",
"
\n",
"\n",
"
\n",
" \n",
" \n",
" | \n",
" fraud | \n",
" vehicle_claim | \n",
" total_claim_amount | \n",
" customer_age | \n",
" months_as_customer | \n",
" num_claims_past_year | \n",
" num_insurers_past_5_years | \n",
" policy_deductable | \n",
" policy_annual_premium | \n",
" customer_zip | \n",
" ... | \n",
" collision_type_missing | \n",
" incident_severity_Major | \n",
" incident_severity_Minor | \n",
" incident_severity_Totaled | \n",
" authorities_contacted_Ambulance | \n",
" authorities_contacted_Fire | \n",
" authorities_contacted_None | \n",
" authorities_contacted_Police | \n",
" police_report_available_No | \n",
" police_report_available_Yes | \n",
"
\n",
" \n",
" \n",
" \n",
" | 0 | \n",
" 0 | \n",
" 8913.668763 | \n",
" 80513.668763 | \n",
" 54 | \n",
" 94 | \n",
" 0 | \n",
" 1 | \n",
" 750 | \n",
" 3000 | \n",
" 99207 | \n",
" ... | \n",
" 0 | \n",
" 0 | \n",
" 1 | \n",
" 0 | \n",
" 0 | \n",
" 0 | \n",
" 1 | \n",
" 0 | \n",
" 1 | \n",
" 0 | \n",
"
\n",
" \n",
" | 1 | \n",
" 0 | \n",
" 19746.724395 | \n",
" 26146.724395 | \n",
" 41 | \n",
" 165 | \n",
" 0 | \n",
" 1 | \n",
" 750 | \n",
" 2950 | \n",
" 95632 | \n",
" ... | \n",
" 0 | \n",
" 0 | \n",
" 0 | \n",
" 1 | \n",
" 0 | \n",
" 0 | \n",
" 0 | \n",
" 1 | \n",
" 0 | \n",
" 1 | \n",
"
\n",
" \n",
" | 2 | \n",
" 0 | \n",
" 11652.969918 | \n",
" 22052.969918 | \n",
" 57 | \n",
" 155 | \n",
" 0 | \n",
" 1 | \n",
" 750 | \n",
" 3000 | \n",
" 93203 | \n",
" ... | \n",
" 0 | \n",
" 0 | \n",
" 1 | \n",
" 0 | \n",
" 0 | \n",
" 0 | \n",
" 0 | \n",
" 1 | \n",
" 0 | \n",
" 1 | \n",
"
\n",
" \n",
" | 3 | \n",
" 0 | \n",
" 11260.930936 | \n",
" 115960.930936 | \n",
" 39 | \n",
" 80 | \n",
" 0 | \n",
" 1 | \n",
" 750 | \n",
" 3000 | \n",
" 85208 | \n",
" ... | \n",
" 0 | \n",
" 0 | \n",
" 1 | \n",
" 0 | \n",
" 0 | \n",
" 0 | \n",
" 1 | \n",
" 0 | \n",
" 1 | \n",
" 0 | \n",
"
\n",
" \n",
" | 4 | \n",
" 0 | \n",
" 27987.704652 | \n",
" 31387.704652 | \n",
" 39 | \n",
" 60 | \n",
" 0 | \n",
" 1 | \n",
" 750 | \n",
" 3000 | \n",
" 91792 | \n",
" ... | \n",
" 0 | \n",
" 1 | \n",
" 0 | \n",
" 0 | \n",
" 0 | \n",
" 0 | \n",
" 0 | \n",
" 1 | \n",
" 1 | \n",
" 0 | \n",
"
\n",
" \n",
"
\n",
"
5 rows × 59 columns
\n",
"