 \n",
"\n",
"2. There are several ways to convert MIDI files into a sequence of tokens. MIDI carries event messages, data that specify the instructions for music including a note's notation, pitch, velocity (which is heard typically as loudness or softness of volume). The tokens will accordingly represent these events found in the music/MIDI file such as the onset of notes, the duration or offset of notes, and the passage of time. [Music Transformer](https://arxiv.org/abs/1809.04281) and [Musenet](https://openai.com/blog/musenet/) are examples of models that treat music as a sequence. You can examine a specific sequential format, called the note sequence, later on in this notebook.\n",
"\n",
"In this notebook, music generation is treated as a sequence generation problem. You will train a strong sequential model - the Transformer-XL - to learn the distribution of these sequences."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## An introduction to Transformers and the Transformer-XL\n",
"\n",
"In this section, you can examine the structure of the Transformer architecture, and see how the Transformer-XL improves on the original design.\n",
"\n",
"### The original Transformer\n",
"Briefly, here are the advantages and disadvantages of using either CNNs or RNNs to solve sequence generation based problems.\n",
"- CNNs are easy to parallelize, but can only capture fixed length sequential dependencies.\n",
"- RNNs can learn long-range, variable length sequential dependencies but cannot be parallelized within a sequence.\n",
"\n",
"To combine the advantages of CNNs and RNNs, a novel architecture was proposed in the paper [Attention is all you need](https://arxiv.org/abs/1706.03762), which solely uses the [attention mechanism](https://d2l.ai/chapter_attention-mechanisms/attention.html) and therefore helps the model focus on relevant parts of the input or output sentence. This architecture, called the Transformer, first encodes each word's position in the input sequence and then acts on it with the attention mechanism. The attention mechanism enables the Transformer to be trained in parallel, achieving significantly shorter training time (often by a factor of 10 or more) when compared to an RNN.\n",
"\n",
"
\n",
"\n",
"2. There are several ways to convert MIDI files into a sequence of tokens. MIDI carries event messages, data that specify the instructions for music including a note's notation, pitch, velocity (which is heard typically as loudness or softness of volume). The tokens will accordingly represent these events found in the music/MIDI file such as the onset of notes, the duration or offset of notes, and the passage of time. [Music Transformer](https://arxiv.org/abs/1809.04281) and [Musenet](https://openai.com/blog/musenet/) are examples of models that treat music as a sequence. You can examine a specific sequential format, called the note sequence, later on in this notebook.\n",
"\n",
"In this notebook, music generation is treated as a sequence generation problem. You will train a strong sequential model - the Transformer-XL - to learn the distribution of these sequences."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## An introduction to Transformers and the Transformer-XL\n",
"\n",
"In this section, you can examine the structure of the Transformer architecture, and see how the Transformer-XL improves on the original design.\n",
"\n",
"### The original Transformer\n",
"Briefly, here are the advantages and disadvantages of using either CNNs or RNNs to solve sequence generation based problems.\n",
"- CNNs are easy to parallelize, but can only capture fixed length sequential dependencies.\n",
"- RNNs can learn long-range, variable length sequential dependencies but cannot be parallelized within a sequence.\n",
"\n",
"To combine the advantages of CNNs and RNNs, a novel architecture was proposed in the paper [Attention is all you need](https://arxiv.org/abs/1706.03762), which solely uses the [attention mechanism](https://d2l.ai/chapter_attention-mechanisms/attention.html) and therefore helps the model focus on relevant parts of the input or output sentence. This architecture, called the Transformer, first encodes each word's position in the input sequence and then acts on it with the attention mechanism. The attention mechanism enables the Transformer to be trained in parallel, achieving significantly shorter training time (often by a factor of 10 or more) when compared to an RNN.\n",
"\n",
" \n",
"Using a fixed-length context introduces two __critical limitations__: \n",
"\n",
"1. The Transformer is not able to model dependencies that are longer than a fixed length. \n",
"2. In music generation, a single musical note is frequently composed of multiple tokens. Fixed-length segments often do not respect musical note boundaries, resulting in context fragmentation which in turn causes inefficient optimization. This is problematic even for short sequences, where long range dependency isn't an issue.\n",
"\n",
"### The Transformer-XL \n",
"\n",
"The [Transformer-XL](https://arxiv.org/abs/1901.02860) is a novel architecture based on the Transformer decoder. It improves on the original Transformer decoder and enables language modeling beyond a fixed-length context. It accomplishes this with two techniques: a segment-level recurrence mechanism and a relative positional encoding scheme.\n",
"\n",
"*__Segment-level Recurrence__* During Transformer-XL training, the representations computed for the previous segment are fixed and cached to be reused as an extended context when the model processes the next new segment. This additional connection increases the largest possible dependency length by N times, where N is the depth of the network, because contextual information is now able to flow across segment boundaries. This recurrence mechanism also resolves the context fragmentation issue, providing necessary context for tokens in the front of a new segment.\n",
" \n",
"
\n",
"Using a fixed-length context introduces two __critical limitations__: \n",
"\n",
"1. The Transformer is not able to model dependencies that are longer than a fixed length. \n",
"2. In music generation, a single musical note is frequently composed of multiple tokens. Fixed-length segments often do not respect musical note boundaries, resulting in context fragmentation which in turn causes inefficient optimization. This is problematic even for short sequences, where long range dependency isn't an issue.\n",
"\n",
"### The Transformer-XL \n",
"\n",
"The [Transformer-XL](https://arxiv.org/abs/1901.02860) is a novel architecture based on the Transformer decoder. It improves on the original Transformer decoder and enables language modeling beyond a fixed-length context. It accomplishes this with two techniques: a segment-level recurrence mechanism and a relative positional encoding scheme.\n",
"\n",
"*__Segment-level Recurrence__* During Transformer-XL training, the representations computed for the previous segment are fixed and cached to be reused as an extended context when the model processes the next new segment. This additional connection increases the largest possible dependency length by N times, where N is the depth of the network, because contextual information is now able to flow across segment boundaries. This recurrence mechanism also resolves the context fragmentation issue, providing necessary context for tokens in the front of a new segment.\n",
" \n",
"  \n",
" \n",
"*__Relative Positional Encodings__* Since the Transformer-XL caches representations between segments, a new way to represent the contexual positions of representations from different segments is needed. For example, if an old segment uses contextual positions [0, 1, 2, 3], then when a new segment is processed,the positions are [0, 1, 2, 3, 0, 1, 2, 3] for the two segments combined. The semantics of each position id is incoherent throughout the sequence and the Transformer-XL therefore proposes a novel relative positional encoding scheme to make the recurrence mechanism possible. \n",
" \n",
"When both of these approaches are combined, Transformer-XL has a much longer effective context than the original Transformer model at evaluation time."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Installing dependencies\n",
"First, let's install and import all of the Python packages that you will use in this tutorial."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"pycharm": {
"is_executing": false
}
},
"outputs": [],
"source": [
"# Copyright Amazon.com, Inc. or its affiliates. All Rights Reserved.\n",
"# SPDX-License-Identifier: Apache-2.0\n",
"\n",
"# Create the environment and install required packages\n",
"!pip install -r requirements.txt"
]
},
{
"cell_type": "code",
"execution_count": 3,
"metadata": {
"pycharm": {
"is_executing": false,
"name": "#%%\n"
}
},
"outputs": [
{
"name": "stderr",
"output_type": "stream",
"text": [
"/home/ubuntu/anaconda3/envs/tensorflow_p36/lib/python3.6/site-packages/pydub/utils.py:170: RuntimeWarning: Couldn't find ffmpeg or avconv - defaulting to ffmpeg, but may not work\n",
" warn(\"Couldn't find ffmpeg or avconv - defaulting to ffmpeg, but may not work\", RuntimeWarning)\n"
]
}
],
"source": [
"# Imports\n",
"import glob\n",
"import json\n",
"import math\n",
"import multiprocessing\n",
"import os\n",
"import pickle\n",
"import random\n",
"import time\n",
"from pprint import pprint\n",
"from typing import *\n",
"\n",
"import matplotlib.pyplot as plt\n",
"import numpy as np\n",
"import torch\n",
"import torch.nn as nn\n",
"import torch.nn.functional as F\n",
"import torch.optim as optim\n",
"from IPython import display\n",
"from autocfg import dataclass, field\n",
"from utils.performance_event_repo import BaseVocab\n",
"from utils.midi_utils import play_midi, print_sample_array\n",
"from utils.music_encoder import MusicEncoder\n",
"from utils.utils import plot_losses, save_checkpoint\n",
"\n",
"%matplotlib inline"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Importing the data \n",
"\n",
"The input dataset is in the [MIDI](https://en.wikipedia.org/wiki/MIDI) format. In this tutorial, you will use the [`JSB-Chorales-dataset`](http://www-etud.iro.umontreal.ca/~boulanni/icml2012). The link contains pickled files that you will convert to MIDI in the cells below. \n",
"\n",
"A chorale is a type of musical structure or form. Chorales usually consist of one voice singing a simple melody and three lower voices providing harmony. In this dataset, the voices are represented by four individual piano tracks.\n",
"\n",
"You will now download and use this dataset locally.\n",
"\n",
"### Downloading the `JSB-Chorales-dataset`\n"
]
},
{
"cell_type": "code",
"execution_count": 5,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"--2021-01-21 17:50:43-- http://www-etud.iro.umontreal.ca/~boulanni/JSB%20Chorales.zip\n",
"Resolving www-etud.iro.umontreal.ca (www-etud.iro.umontreal.ca)... 132.204.26.158\n",
"Connecting to www-etud.iro.umontreal.ca (www-etud.iro.umontreal.ca)|132.204.26.158|:80... connected.\n",
"HTTP request sent, awaiting response... 200 OK\n",
"Length: 215242 (210K) [application/zip]\n",
"Saving to: ‘data/JSB Chorales.zip.1’\n",
"\n",
"JSB Chorales.zip.1 100%[===================>] 210.20K --.-KB/s in 0.09s \n",
"\n",
"2021-01-21 17:50:44 (2.31 MB/s) - ‘data/JSB Chorales.zip.1’ saved [215242/215242]\n",
"\n"
]
}
],
"source": [
"# Download a .zip file containing the .mid files from the dataset.\n",
"!wget http://www-etud.iro.umontreal.ca/~boulanni/JSB%20Chorales.zip -P data/\n",
"\n",
"# Unzip the contents of that directory\n",
"!unzip -q \"data/JSB Chorales.zip\" -d data/\n",
"\n",
"# Rename downloaded file\n",
"!mv \"data/JSB Chorales\" data/jsb_chorales/\n",
"\n",
"# Change the string in the the `data_dir` variable to the correct file path\n",
"data_dir = \"data/jsb_chorales/**/*.mid\"\n",
"\n",
"# Load midi files\n",
"midi_files = glob.glob(data_dir)"
]
},
{
"cell_type": "code",
"execution_count": 6,
"metadata": {},
"outputs": [
{
"data": {
"text/html": [
"\n",
" \n",
" \n",
" "
],
"text/plain": [
"
\n",
" \n",
"*__Relative Positional Encodings__* Since the Transformer-XL caches representations between segments, a new way to represent the contexual positions of representations from different segments is needed. For example, if an old segment uses contextual positions [0, 1, 2, 3], then when a new segment is processed,the positions are [0, 1, 2, 3, 0, 1, 2, 3] for the two segments combined. The semantics of each position id is incoherent throughout the sequence and the Transformer-XL therefore proposes a novel relative positional encoding scheme to make the recurrence mechanism possible. \n",
" \n",
"When both of these approaches are combined, Transformer-XL has a much longer effective context than the original Transformer model at evaluation time."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Installing dependencies\n",
"First, let's install and import all of the Python packages that you will use in this tutorial."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"pycharm": {
"is_executing": false
}
},
"outputs": [],
"source": [
"# Copyright Amazon.com, Inc. or its affiliates. All Rights Reserved.\n",
"# SPDX-License-Identifier: Apache-2.0\n",
"\n",
"# Create the environment and install required packages\n",
"!pip install -r requirements.txt"
]
},
{
"cell_type": "code",
"execution_count": 3,
"metadata": {
"pycharm": {
"is_executing": false,
"name": "#%%\n"
}
},
"outputs": [
{
"name": "stderr",
"output_type": "stream",
"text": [
"/home/ubuntu/anaconda3/envs/tensorflow_p36/lib/python3.6/site-packages/pydub/utils.py:170: RuntimeWarning: Couldn't find ffmpeg or avconv - defaulting to ffmpeg, but may not work\n",
" warn(\"Couldn't find ffmpeg or avconv - defaulting to ffmpeg, but may not work\", RuntimeWarning)\n"
]
}
],
"source": [
"# Imports\n",
"import glob\n",
"import json\n",
"import math\n",
"import multiprocessing\n",
"import os\n",
"import pickle\n",
"import random\n",
"import time\n",
"from pprint import pprint\n",
"from typing import *\n",
"\n",
"import matplotlib.pyplot as plt\n",
"import numpy as np\n",
"import torch\n",
"import torch.nn as nn\n",
"import torch.nn.functional as F\n",
"import torch.optim as optim\n",
"from IPython import display\n",
"from autocfg import dataclass, field\n",
"from utils.performance_event_repo import BaseVocab\n",
"from utils.midi_utils import play_midi, print_sample_array\n",
"from utils.music_encoder import MusicEncoder\n",
"from utils.utils import plot_losses, save_checkpoint\n",
"\n",
"%matplotlib inline"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Importing the data \n",
"\n",
"The input dataset is in the [MIDI](https://en.wikipedia.org/wiki/MIDI) format. In this tutorial, you will use the [`JSB-Chorales-dataset`](http://www-etud.iro.umontreal.ca/~boulanni/icml2012). The link contains pickled files that you will convert to MIDI in the cells below. \n",
"\n",
"A chorale is a type of musical structure or form. Chorales usually consist of one voice singing a simple melody and three lower voices providing harmony. In this dataset, the voices are represented by four individual piano tracks.\n",
"\n",
"You will now download and use this dataset locally.\n",
"\n",
"### Downloading the `JSB-Chorales-dataset`\n"
]
},
{
"cell_type": "code",
"execution_count": 5,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"--2021-01-21 17:50:43-- http://www-etud.iro.umontreal.ca/~boulanni/JSB%20Chorales.zip\n",
"Resolving www-etud.iro.umontreal.ca (www-etud.iro.umontreal.ca)... 132.204.26.158\n",
"Connecting to www-etud.iro.umontreal.ca (www-etud.iro.umontreal.ca)|132.204.26.158|:80... connected.\n",
"HTTP request sent, awaiting response... 200 OK\n",
"Length: 215242 (210K) [application/zip]\n",
"Saving to: ‘data/JSB Chorales.zip.1’\n",
"\n",
"JSB Chorales.zip.1 100%[===================>] 210.20K --.-KB/s in 0.09s \n",
"\n",
"2021-01-21 17:50:44 (2.31 MB/s) - ‘data/JSB Chorales.zip.1’ saved [215242/215242]\n",
"\n"
]
}
],
"source": [
"# Download a .zip file containing the .mid files from the dataset.\n",
"!wget http://www-etud.iro.umontreal.ca/~boulanni/JSB%20Chorales.zip -P data/\n",
"\n",
"# Unzip the contents of that directory\n",
"!unzip -q \"data/JSB Chorales.zip\" -d data/\n",
"\n",
"# Rename downloaded file\n",
"!mv \"data/JSB Chorales\" data/jsb_chorales/\n",
"\n",
"# Change the string in the the `data_dir` variable to the correct file path\n",
"data_dir = \"data/jsb_chorales/**/*.mid\"\n",
"\n",
"# Load midi files\n",
"midi_files = glob.glob(data_dir)"
]
},
{
"cell_type": "code",
"execution_count": 6,
"metadata": {},
"outputs": [
{
"data": {
"text/html": [
"\n",
" \n",
" \n",
" "
],
"text/plain": [
" \n",
"\n",
"### Data augmentation\n",
"[Data augmentation](https://d2l.ai/chapter_computer-vision/image-augmentation.html) provides a simple way of encoding domain specific prior knowledge in any machine learning algorithm. You will augment the dataset as originally suggested in the paper, [Music Transformer](https://arxiv.org/abs/1809.04281). Two kinds of data augmentation are applied to every note to reflect how music can retain a melody when either the pitch is transposed (moving up or down an octave) or the tempo is changed. Below are the two variables used to accomplish this: \n",
"- Pitch transpositions are controlled using integers `pitch_transpose_lower` and `pitch_transpose_upper`. The transpositions applied to a note are sampled uniformly from the integer set of half-steps {pitch_transpose_lower,...,pitch_transpose_upper}. We use `pitch_transpose_lower`=-3 and `pitch_transpose_upper`=3.\n",
"- Time stretch factors are uniformly sampled from the set {0.95,0.975,1.0,1.025,1.05} that we denote using the variable `stretch_factors`. The duration of a note is multiplied with this sampled stretch factor."
]
},
{
"cell_type": "code",
"execution_count": 7,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Converting midi files from data/jsb_chorales to npy...\n",
"Loaded dataset from data/jsb_chorales. Train/Val/Test=229/76/77\n",
"Split train converted! Spent 12.860990047454834s to convert 229 samples.\n",
"Split valid converted! Spent 0.4431154727935791s to convert 76 samples.\n",
"Split test converted! Spent 0.42433857917785645s to convert 77 samples.\n"
]
}
],
"source": [
"# Creates a class that will be used to transform the dataset from \n",
"# MIDI to a numpy array based on the Performance vocabulary\n",
"music_encoder = MusicEncoder()\n",
" \n",
"# Specify event representation algorithm ('performance') and dataset augmentation parameters\n",
"pitch_transpose_lower, pitch_transpose_upper = -3, 3\n",
"music_encoder.build_encoder(algorithm='performance', stretch_factors=[0.95,0.975,1.0,1.025,1.05],\n",
" pitch_transpose = (pitch_transpose_lower, pitch_transpose_upper))\n",
"\n",
"# Convert midi dataset to numpy array\n",
"music_encoder.convert(input_folder= 'data/jsb_chorales', \n",
" output_folder='data/jsb_chorales_numpy',\n",
" mode='midi_to_npy')\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"You will print a sample MIDI file from the training set. This is now a numpy array of indices for each event type."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Prints a randomly sampled numpy array from the parent_dir\n",
"print_sample_array(split=\"train\", parent_dir=\"data/jsb_chorales_numpy\")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Model architecture\n",
"\n",
"In the sections below, you can see how the Transformer-XL decoder is implemented one piece at a time. You will begin by looking at the attention matrix and the terms within. You will then implement the Transformer-XL decoder using a sequence of multi-head attention layers along with feed forward layers, residual connections and `LayerNorm` layers.\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Self attention\n",
"\n",
"The attention layer is the fundamental part of the Transformer-XL model architecture. In this section you can see how the attention score matrix for a single head is computed. Later on you will see how the multi-head attention layer is composed of several attention heads.\n",
"\n",
"Say you have a music sequence of length (`tgt_len`) of 10 events with a batch size (`batch_size`) of 8 that you want to use self-attention on. `tgt_len` and `batch_size` are examples of hyperparameters that are tuned while training the Transformer-XL. "
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"tgt_len = 10 # Length of input music sequence\n",
"batch_size = 8 # Batch size\n",
"vocab_size = 310 # Effective Vocabulary size for the Performance event representation\n",
" \n",
"sequence = torch.randint(vocab_size, (tgt_len, batch_size))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"You first transform the sequence indices into word embeddings of dimension 32 which is another hyperparameter."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"dim_embed = 32 # Embedding dimension\n",
"\n",
"word_emb_layer = nn.Embedding(vocab_size, dim_embed)\n",
"word_emb = word_emb_layer(sequence)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"word_emb.shape # tgt_len x batch_size x dim_embed"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"The Transformer-XL introduces a segment level recurrence mechanism, where cached states for the previous segment (sequence) are also provided as additional input to the model.\n",
"The cached states are referred to as the memory. \n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"mem_len = 10 # Previous sequence len (same as input sequence length here)\n",
"\n",
"mems = torch.rand(mem_len, batch_size, dim_embed) # memory of cached states"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"While the memory length or number of cached states stored is the same as the sequence length (equal to 10) in this example, this need not be the case.\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"As in the original Transformer, the attention layer operates on keys, queries and values. The keys and values are comprised of both memory and current sequence while the queries are the current sequence alone.\n",
"\n",
"You first linearly project the queries, keys and values to a dimension `dim_head` for efficient computation of attention."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"dim_head = 5 # Inner dimension of attention head\n",
"\n",
"# Define linear projection layers\n",
"q_net = nn.Linear(dim_embed, dim_head)\n",
"k_net = nn.Linear(dim_embed, dim_head)\n",
"v_net = nn.Linear(dim_embed, dim_head)\n",
"\n",
"# Keys and values are comprised of memory and current sequence\n",
"word_emb_concat = torch.cat([mems, word_emb], dim=0) # Concatenated along seq dim\n",
"K = k_net(word_emb_concat)\n",
"V = v_net(word_emb_concat)\n",
"\n",
"# Queries are comprised of current sequence\n",
"Q = q_net(word_emb)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
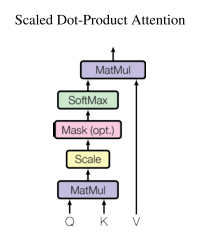
"You now compute the scaled dot product attention between the query __Q__, key __K__ and value __V__ matrices. As in the original paper, you divide the attention score matrix with the square root of the embedding dimension. For large values of embedding dimension the dot products grow large in magnitude, pushing the softmax function into regions where it has\n",
"extremely small gradients. Scaling the dot products by $\\sqrt{1/d_k}$ helps address this."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"$$ \\textrm{Attention}(Q, K, V) = \\textrm{softmax}(\\frac{QK^T}{\\sqrt{d_k}})V $$"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
""
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"To compute the dot product $QK^T$ in Pytorch you will use [einsum](https://pytorch.org/docs/stable/generated/torch.einsum.html) and then scale the result. This term is called `attn_a` and you shall soon understand why.\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"attn_a = torch.einsum(\"ibd,jbd->bij\", Q, K) / (dim_embed ** 0.5)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"The Transformer-XL attention matrix introduces additional components from relative positional embeddings as you will see next. Once you compute these additional components you add them to obtain the net attention score matrix before applying the softmax activation."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Relative Positional Encoding\n",
"\n",
"Observe that unlike the original Transformer, you did not add positional embeddings to `word_emb` before you computed the attention score. \n",
"\n",
"Music has multiple dimensions along which relative differences arguably matter more than their absolute values; the two most prominent are timing and pitch. To model such pairwise relations between representations, the paper, [Self-Attention with Relative Position Representations](https://arxiv.org/abs/1803.02155) introduced a relation-aware version of self-attention.\n",
"\n",
"The Transformer-XL uses an efficient implementation of this idea in the form of relative positional embeddings. Unlike the Transformer that uses absolute positional embeddings that are added to every token embedding, the Transformer-XL uses an embedding that represents the relative distance i-j between query $q_i$ and key $k_j$. \n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Recap by taking a look at the $ij^{th}$ entry in the attention matrix of the original Transformer. The original Transformer uses absolute positional embeddings denoted by $U$"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\\begin{align}\n",
"A^{abs}_{i,j} = \n",
" \\underbrace{E_{x_i}^T W_q^T W_{k} E_{x_j}}_{(a)}\n",
" + \\underbrace{E_{x_i}^T W_q^T W_{k} U_{j}}_{(b)}\n",
" \\\\ \n",
" + \\underbrace{ U_{i}^T W_{q}^T W_{k} E_{x_j}}_{(c)} \n",
" + \\underbrace{ U_{i}^T W_{q}^T W_{k} U_{j}}_{(d)}\n",
"\\end{align}"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Now look at the $ij^{th}$ entry in the relative attention matrix of a the Transformer-XL."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\\begin{align}\n",
"A^{rel}_{i,j} = \n",
" \\underbrace{E_{x_i}^TW_q^TW_{k,E}E_{x_j}}_{(a)}\n",
" + \\underbrace{E_{x_i}^TW_q^TW_{k,R} \\color{blue}R_\\color{blue}{i-j} }_{(b)}\n",
" \\\\ \n",
" + \\underbrace{ \\color{red}u^\\color{red}T W_{k,E}E_{x_j}}_{(c)} \n",
" + \\underbrace{ \\color{red}v^\\color{red}T W_{k,R} \\color{blue}R_\\color{blue}{i-j}}_{(d)}\n",
"\\end{align}"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"$E_x$ is the sequence embedding representing content
\n",
"\n",
"### Data augmentation\n",
"[Data augmentation](https://d2l.ai/chapter_computer-vision/image-augmentation.html) provides a simple way of encoding domain specific prior knowledge in any machine learning algorithm. You will augment the dataset as originally suggested in the paper, [Music Transformer](https://arxiv.org/abs/1809.04281). Two kinds of data augmentation are applied to every note to reflect how music can retain a melody when either the pitch is transposed (moving up or down an octave) or the tempo is changed. Below are the two variables used to accomplish this: \n",
"- Pitch transpositions are controlled using integers `pitch_transpose_lower` and `pitch_transpose_upper`. The transpositions applied to a note are sampled uniformly from the integer set of half-steps {pitch_transpose_lower,...,pitch_transpose_upper}. We use `pitch_transpose_lower`=-3 and `pitch_transpose_upper`=3.\n",
"- Time stretch factors are uniformly sampled from the set {0.95,0.975,1.0,1.025,1.05} that we denote using the variable `stretch_factors`. The duration of a note is multiplied with this sampled stretch factor."
]
},
{
"cell_type": "code",
"execution_count": 7,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Converting midi files from data/jsb_chorales to npy...\n",
"Loaded dataset from data/jsb_chorales. Train/Val/Test=229/76/77\n",
"Split train converted! Spent 12.860990047454834s to convert 229 samples.\n",
"Split valid converted! Spent 0.4431154727935791s to convert 76 samples.\n",
"Split test converted! Spent 0.42433857917785645s to convert 77 samples.\n"
]
}
],
"source": [
"# Creates a class that will be used to transform the dataset from \n",
"# MIDI to a numpy array based on the Performance vocabulary\n",
"music_encoder = MusicEncoder()\n",
" \n",
"# Specify event representation algorithm ('performance') and dataset augmentation parameters\n",
"pitch_transpose_lower, pitch_transpose_upper = -3, 3\n",
"music_encoder.build_encoder(algorithm='performance', stretch_factors=[0.95,0.975,1.0,1.025,1.05],\n",
" pitch_transpose = (pitch_transpose_lower, pitch_transpose_upper))\n",
"\n",
"# Convert midi dataset to numpy array\n",
"music_encoder.convert(input_folder= 'data/jsb_chorales', \n",
" output_folder='data/jsb_chorales_numpy',\n",
" mode='midi_to_npy')\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"You will print a sample MIDI file from the training set. This is now a numpy array of indices for each event type."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Prints a randomly sampled numpy array from the parent_dir\n",
"print_sample_array(split=\"train\", parent_dir=\"data/jsb_chorales_numpy\")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Model architecture\n",
"\n",
"In the sections below, you can see how the Transformer-XL decoder is implemented one piece at a time. You will begin by looking at the attention matrix and the terms within. You will then implement the Transformer-XL decoder using a sequence of multi-head attention layers along with feed forward layers, residual connections and `LayerNorm` layers.\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Self attention\n",
"\n",
"The attention layer is the fundamental part of the Transformer-XL model architecture. In this section you can see how the attention score matrix for a single head is computed. Later on you will see how the multi-head attention layer is composed of several attention heads.\n",
"\n",
"Say you have a music sequence of length (`tgt_len`) of 10 events with a batch size (`batch_size`) of 8 that you want to use self-attention on. `tgt_len` and `batch_size` are examples of hyperparameters that are tuned while training the Transformer-XL. "
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"tgt_len = 10 # Length of input music sequence\n",
"batch_size = 8 # Batch size\n",
"vocab_size = 310 # Effective Vocabulary size for the Performance event representation\n",
" \n",
"sequence = torch.randint(vocab_size, (tgt_len, batch_size))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"You first transform the sequence indices into word embeddings of dimension 32 which is another hyperparameter."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"dim_embed = 32 # Embedding dimension\n",
"\n",
"word_emb_layer = nn.Embedding(vocab_size, dim_embed)\n",
"word_emb = word_emb_layer(sequence)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"word_emb.shape # tgt_len x batch_size x dim_embed"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"The Transformer-XL introduces a segment level recurrence mechanism, where cached states for the previous segment (sequence) are also provided as additional input to the model.\n",
"The cached states are referred to as the memory. \n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"mem_len = 10 # Previous sequence len (same as input sequence length here)\n",
"\n",
"mems = torch.rand(mem_len, batch_size, dim_embed) # memory of cached states"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"While the memory length or number of cached states stored is the same as the sequence length (equal to 10) in this example, this need not be the case.\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"As in the original Transformer, the attention layer operates on keys, queries and values. The keys and values are comprised of both memory and current sequence while the queries are the current sequence alone.\n",
"\n",
"You first linearly project the queries, keys and values to a dimension `dim_head` for efficient computation of attention."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"dim_head = 5 # Inner dimension of attention head\n",
"\n",
"# Define linear projection layers\n",
"q_net = nn.Linear(dim_embed, dim_head)\n",
"k_net = nn.Linear(dim_embed, dim_head)\n",
"v_net = nn.Linear(dim_embed, dim_head)\n",
"\n",
"# Keys and values are comprised of memory and current sequence\n",
"word_emb_concat = torch.cat([mems, word_emb], dim=0) # Concatenated along seq dim\n",
"K = k_net(word_emb_concat)\n",
"V = v_net(word_emb_concat)\n",
"\n",
"# Queries are comprised of current sequence\n",
"Q = q_net(word_emb)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"You now compute the scaled dot product attention between the query __Q__, key __K__ and value __V__ matrices. As in the original paper, you divide the attention score matrix with the square root of the embedding dimension. For large values of embedding dimension the dot products grow large in magnitude, pushing the softmax function into regions where it has\n",
"extremely small gradients. Scaling the dot products by $\\sqrt{1/d_k}$ helps address this."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"$$ \\textrm{Attention}(Q, K, V) = \\textrm{softmax}(\\frac{QK^T}{\\sqrt{d_k}})V $$"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
""
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"To compute the dot product $QK^T$ in Pytorch you will use [einsum](https://pytorch.org/docs/stable/generated/torch.einsum.html) and then scale the result. This term is called `attn_a` and you shall soon understand why.\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"attn_a = torch.einsum(\"ibd,jbd->bij\", Q, K) / (dim_embed ** 0.5)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"The Transformer-XL attention matrix introduces additional components from relative positional embeddings as you will see next. Once you compute these additional components you add them to obtain the net attention score matrix before applying the softmax activation."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Relative Positional Encoding\n",
"\n",
"Observe that unlike the original Transformer, you did not add positional embeddings to `word_emb` before you computed the attention score. \n",
"\n",
"Music has multiple dimensions along which relative differences arguably matter more than their absolute values; the two most prominent are timing and pitch. To model such pairwise relations between representations, the paper, [Self-Attention with Relative Position Representations](https://arxiv.org/abs/1803.02155) introduced a relation-aware version of self-attention.\n",
"\n",
"The Transformer-XL uses an efficient implementation of this idea in the form of relative positional embeddings. Unlike the Transformer that uses absolute positional embeddings that are added to every token embedding, the Transformer-XL uses an embedding that represents the relative distance i-j between query $q_i$ and key $k_j$. \n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Recap by taking a look at the $ij^{th}$ entry in the attention matrix of the original Transformer. The original Transformer uses absolute positional embeddings denoted by $U$"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\\begin{align}\n",
"A^{abs}_{i,j} = \n",
" \\underbrace{E_{x_i}^T W_q^T W_{k} E_{x_j}}_{(a)}\n",
" + \\underbrace{E_{x_i}^T W_q^T W_{k} U_{j}}_{(b)}\n",
" \\\\ \n",
" + \\underbrace{ U_{i}^T W_{q}^T W_{k} E_{x_j}}_{(c)} \n",
" + \\underbrace{ U_{i}^T W_{q}^T W_{k} U_{j}}_{(d)}\n",
"\\end{align}"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Now look at the $ij^{th}$ entry in the relative attention matrix of a the Transformer-XL."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\\begin{align}\n",
"A^{rel}_{i,j} = \n",
" \\underbrace{E_{x_i}^TW_q^TW_{k,E}E_{x_j}}_{(a)}\n",
" + \\underbrace{E_{x_i}^TW_q^TW_{k,R} \\color{blue}R_\\color{blue}{i-j} }_{(b)}\n",
" \\\\ \n",
" + \\underbrace{ \\color{red}u^\\color{red}T W_{k,E}E_{x_j}}_{(c)} \n",
" + \\underbrace{ \\color{red}v^\\color{red}T W_{k,R} \\color{blue}R_\\color{blue}{i-j}}_{(d)}\n",
"\\end{align}"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"$E_x$ is the sequence embedding representing content\n", "$W_q$,$W_{k,E}$ and $W_{k,R}$ are the linear transformation matrices
\n", "$u$ and $v$ are learnable bias terms that represent content bias and position bias respectively
\n", "T denotes matrix transpose" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "What are the differences?\n", "\n", "- The first change is to replace all appearances of the absolute positional embedding $U_j$ for computing key vectors in term (b) and (d) with its relative counterpart $R_{i−j}$. This essentially reflects the prior belief that only the relative distance matters for where to attend. R is a [sinusoid encoding matrix](https://kazemnejad.com/blog/transformer_architecture_positional_encoding/) without learnable parameters that you shall soon visualize in the cells below.\n", "\n", "- Second, a trainable parameter $u \\in \\mathbb{R}^d$ is introduced to replace the content query $U_{i}^T W_{q}^T$ in term (c). In this case, since the query vector is the same for all query positions, it suggests that the attentive bias towards different words should remain the same regardless of the query position. With a similar reasoning, a trainable parameter $v \\in \\mathbb{R}^d$ is added to substitute $U_{i}^T W_{q}^T$ in term (d).\n", "\n", "- Finally, the two weight matrices $W_{k,E}$ and $W_{k,R}$ are deliberately separated for producing the content-based key vectors and location-based key vectors respectively.\n" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "Above you saw the code to compute the content based attention term (a), denoted by `attn_a`. You can see below how remaining terms (b),(c) and (d) are computed. (b) and (d) involve the relative positional embeddings. \n", "\n", "Term (c) is computed first. " ] }, { "cell_type": "code", "execution_count": null, "metadata": {}, "outputs": [], "source": [ "u = torch.rand(5).expand_as(Q) # Learnable bias\n", "\n", "attn_c = torch.einsum(\"ibd,jbd->bij\", u, K) / (dim_embed ** 0.5)" ] }, { "cell_type": "code", "execution_count": null, "metadata": {}, "outputs": [], "source": [ "attn_content = attn_a + attn_c # Content attention is composed of terms (a) and (c)" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "You will now understand the relative positional embeddings terms (b) and (d). The Transformer-XL uses [sinusoidal embeddings](https://console.aws.amazon.com/deepcomposer/home?region=us-east-1#learningCapsules/transformerTechnique) like the original Transformer." ] }, { "cell_type": "code", "execution_count": null, "metadata": {}, "outputs": [], "source": [ "# Define positional indices\n", "pos_seq = torch.arange(tgt_len + mem_len - 1, -1, -1, dtype=torch.float)\n", "pos_seq" ] }, { "cell_type": "code", "execution_count": null, "metadata": {}, "outputs": [], "source": [ "# Compute sinusoidal positional embeddings\n", "inv_freq = 1 / (10000 ** (torch.arange(0.0, dim_embed, 2.0) / dim_embed))\n", "sinusoid_inp = torch.ger(pos_seq, inv_freq) # Outer product of vectors\n", "pos_emb = torch.cat([sinusoid_inp.sin(), sinusoid_inp.cos()], dim=-1)[:, None, :]" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "Let us visualize a few dimensions in the positional embeddings matrix for better understanding. The sines and cosines act as basis functions to [represent the position](https://kazemnejad.com/blog/transformer_architecture_positional_encoding/)." ] }, { "cell_type": "code", "execution_count": null, "metadata": {}, "outputs": [], "source": [ "# Visualize a few sinusoidal embeddings in pos_emb\n", "plt.plot(pos_seq, pos_emb[:, 0, 0:4])\n", "plt.legend([\"dim %d\" % p for p in [0, 1, 2, 3]])" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "You will now define all the core components of the Transformer-XL in a class. The relative positional embeddings are defined inside a class `PositionalEmbedding`." ] }, { "cell_type": "code", "execution_count": null, "metadata": {}, "outputs": [], "source": [ "class PositionalEmbedding(nn.Module):\n", " \"\"\" \n", " Transformer-XL positional embedding definition \n", " \"\"\"\n", "\n", " def __init__(self, dim_embed):\n", " super(PositionalEmbedding, self).__init__()\n", "\n", " self.dim_embed = dim_embed\n", "\n", " inv_freq = 1 / (10000 ** (torch.arange(0.0, dim_embed, 2.0) / dim_embed))\n", " self.register_buffer(\"inv_freq\", inv_freq)\n", "\n", " def forward(self, pos_seq, batch_size=None):\n", "\n", " sinusoid_inp = torch.ger(pos_seq, self.inv_freq) # Outer product\n", "\n", " # Define relative positional embeddings\n", " pos_emb = torch.cat([sinusoid_inp.sin(), sinusoid_inp.cos()], dim=-1)\n", "\n", " if batch_size is not None:\n", " return pos_emb[:, None, :].expand(-1, batch_size, -1)\n", " else:\n", " return pos_emb[:, None, :]" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "As seen earlier for the queries, keys and values, you need to apply linear transformations ($W_{k,R}$) to the positional embeddings as well for efficiency when computing across several heads." ] }, { "cell_type": "code", "execution_count": null, "metadata": {}, "outputs": [], "source": [ "# Define linear transformation layer that acts on positional embeddings\n", "r_net = nn.Linear(dim_embed, dim_head)\n", "\n", "# Project positional embeddings\n", "R = r_net(pos_emb) " ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "You will now compute terms (b) and (d) together" ] }, { "cell_type": "code", "execution_count": null, "metadata": {}, "outputs": [], "source": [ "v = torch.rand(5) # Learnable bias\n", "\n", "attn_bd = torch.einsum(\"ibd,jd->bij\", Q + v, R[:, 0, :]) / (dim_embed ** 0.5)" ] }, { "cell_type": "code", "execution_count": null, "metadata": {}, "outputs": [], "source": [ "attn_bd.shape" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "Observe that `R` currently scales linearly with sequence length (say n) since `pos_seq` scales linearly with n. The terms (b) and (d) however depend on both i and j. Naively computing `R` and its linear projection would involve computing and storing vectors that are proportional to $O(n^2)$. The authors proposed a trick (padding+shifting) to reduce this to $O(n)$ time and memory instead by computing the attention for one query then shifting the embeddings for different query positions. This trick makes the original [Relative Attention](https://arxiv.org/abs/1803.02155) idea feasible for modeling long sequences." ] }, { "cell_type": "code", "execution_count": null, "metadata": {}, "outputs": [], "source": [ "padding = torch.zeros((batch_size, tgt_len, 1), dtype=torch.float)\n", "\n", "# padding + shifting is the trick for efficiently computing pos_attn\n", "attn_pos = (\n", " torch.cat([padding, attn_bd], dim=-1)\n", " .view(batch_size, tgt_len + mem_len + 1, tgt_len)[:, 1:]\n", " .view_as(attn_bd)\n", ")" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "The net attention matrix is the sum of terms (a),(b),(c) and (d)" ] }, { "cell_type": "code", "execution_count": null, "metadata": {}, "outputs": [], "source": [ "attn = attn_content + attn_pos" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "Since you are interested in music generation (formulated as language modeling), you need to use a causal mask to prevent the model from looking into the future as its predicting." ] }, { "cell_type": "code", "execution_count": null, "metadata": {}, "outputs": [], "source": [ "mask = torch.triu(\n", " torch.ones((tgt_len, tgt_len + mem_len)),\n", " diagonal=1 + mem_len,\n", ").bool()[None, ...]\n", "\n", "attn = attn.masked_fill(mask, -float(\"inf\"))" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "You now compute the outputs of the attention layer by taking a weighted sum of the value vectors using the attention probabilities" ] }, { "cell_type": "code", "execution_count": null, "metadata": {}, "outputs": [], "source": [ "attn_probs = torch.softmax(attn, dim=2)\n", "attn_vec = torch.einsum(\"bij,jbd->ibd\", attn_probs, V)\n" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "Finally you transform `attn_vec` using a linear layer to bring it back to its original dimension. You also apply the residual connection and layer normalization as in the original Transformer." ] }, { "cell_type": "code", "execution_count": null, "metadata": {}, "outputs": [], "source": [ "o_net = nn.Linear(dim_head, dim_embed)\n", "layer_norm = nn.LayerNorm(dim_embed)\n", "outputs = layer_norm(word_emb + o_net(attn_vec))" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "### Multi-head attention\n", "\n", "You now define the Transformer-XL `MultiHeadAttn` module by applying self attention across several heads. " ] }, { "cell_type": "code", "execution_count": null, "metadata": {}, "outputs": [], "source": [ "class MultiHeadAttn(nn.Module):\n", " \"\"\" \n", " Defines the Multihead Attention module in the Transformer-XL \n", " \"\"\"\n", " \n", " def __init__(\n", " self,\n", " n_head,\n", " dim_model,\n", " dim_head,\n", " dropout,\n", " dropatt=0,\n", " ):\n", " super(MultiHeadAttn, self).__init__()\n", "\n", " # number of heads\n", " self.n_head = n_head\n", " \n", " # input dimension\n", " self.dim_model = dim_model\n", " \n", " # inner dimension\n", " self.dim_head = dim_head\n", " \n", " self.dropout = dropout\n", " \n", " # you apply the linear transformation to queries, keys and values \n", " # at once for efficiency\n", " self.qkv_net = nn.Linear(dim_model, 3 * n_head * dim_head, bias=False)\n", " \n", " # linear transformation for output and position embeddings\n", " self.o_net = nn.Linear(n_head * dim_head, dim_model, bias=False)\n", " self.r_net = nn.Linear(self.dim_model, self.n_head * self.dim_head, bias=False)\n", " \n", " # Parameters controlling dropout or drop attention\n", " self.drop = nn.Dropout(dropout)\n", " self.dropatt = nn.Dropout(dropatt)\n", " \n", " self.layer_norm = nn.LayerNorm(dim_model)\n", " \n", " # Dot product attention scaling factor \n", " self.scale = 1 / (dim_head ** 0.5)\n", " \n", " def rel_shift(self, x):\n", " \"\"\" \n", " Function to help compute positional attention component efficiently \n", " \"\"\"\n", " \n", " padding = torch.zeros(\n", " (x.size(0), x.size(1), x.size(2), 1), device=x.device, dtype=x.dtype\n", " )\n", " x_padded = torch.cat([padding, x], dim=3)\n", "\n", " x_padded = x_padded.view(x.size(0), x.size(1), x.size(3) + 1, x.size(2))\n", "\n", " x = x_padded[:, :, 1:].view_as(x)\n", "\n", " return x\n", "\n", " def forward(self, w: torch.FloatTensor, # (q_len, batch_size, dim_model)\n", " r: torch.FloatTensor, # (k_len, dim_model)\n", " u: torch.FloatTensor, # (batch_size, dim_model)\n", " v: torch.FloatTensor, # (batch_size, dim_model)\n", " attn_mask: Optional[torch.FloatTensor]=None, \n", " mems: Optional[torch.FloatTensor]=None): #(prev_seq_len, batch_size, dim_model)\n", " \n", " # qlen is length of current segment\n", " # rlen is length of current segment + length of previous segment\n", " qlen, rlen, batch_size = w.size(0), r.size(0), w.size(1)\n", "\n", " if mems is not None:\n", " # concatenate memory across sequence dimension\n", " cat = torch.cat([mems, w], 0)\n", " \n", " w_heads = self.qkv_net(cat)\n", " r_head_k = self.r_net(r)\n", "\n", " w_head_q, w_head_k, w_head_v = torch.chunk(w_heads, 3, dim=-1)\n", " w_head_q = w_head_q[-qlen:]\n", " else:\n", " w_heads = self.qkv_net(w)\n", " r_head_k = self.r_net(r)\n", "\n", " w_head_q, w_head_k, w_head_v = torch.chunk(w_heads, 3, dim=-1)\n", "\n", " klen = w_head_k.size(0)\n", "\n", " w_head_q = w_head_q.view(\n", " qlen, batch_size, self.n_head, self.dim_head\n", " ) # [qlen x batch_size x n_head x dim_head]\n", " w_head_k = w_head_k.view(\n", " klen, batch_size, self.n_head, self.dim_head\n", " ) # [klen x batch_size x n_head x dim_head]\n", " w_head_v = w_head_v.view(\n", " klen, batch_size, self.n_head, self.dim_head\n", " ) # [klen x batch_size x n_head x dim_head]\n", "\n", " r_head_k = r_head_k.view(\n", " rlen, self.n_head, self.dim_head\n", " ) # [klen x n_head x dim_head]\n", "\n", " # Compute attention score\n", " \n", " # Terms (a) and (c)\n", " uw_head_q = w_head_q + u # qlen x batch_size x n_head x dim_head\n", " \n", " AC = torch.einsum(\n", " \"ibnd,jbnd->bnij\", (uw_head_q, w_head_k)\n", " ) # [batch_size x n_head x qlen x klen]\n", "\n", " # Terms (b) and (d)\n", " vw_head_q = w_head_q + v\n", " BD = torch.einsum(\n", " \"ibnd,jnd->bnij\", (vw_head_q, r_head_k)\n", " ) # [batch_size x n_head x qlen x klen]\n", " \n", " # Compute positional attention component efficiently\n", " BD = self.rel_shift(BD) # [batch_size x n_head x qlen x klen]\n", " \n", " attn_score = AC + BD\n", " attn_score.mul_(self.scale)\n", "\n", " # Compute attention probability\n", " \n", " # Use a causal mask if provided\n", " if attn_mask is not None:\n", " attn_score.masked_fill_(attn_mask[None, None, :, :], -float(\"inf\"))\n", "\n", " \n", " attn_prob = F.softmax(attn_score, dim=3) # [batch_size x n_head x qlen x klen]\n", " attn_prob = self.dropatt(attn_prob) # [batch_size x n_head x qlen x klen]\n", "\n", " attn_vec = torch.einsum(\"bnij,jbnd->ibnd\", (attn_prob, w_head_v))\n", " # [qlen x batch_size x n_head x dim_head]\n", " \n", " attn_vec = attn_vec.contiguous().view(\n", " attn_vec.size(0), attn_vec.size(1), self.n_head * self.dim_head\n", " )\n", "\n", " # linear projection\n", " attn_out = self.o_net(attn_vec)\n", " attn_out = self.drop(attn_out)\n", "\n", " # residual connection + layer normalization\n", " output = self.layer_norm(w + attn_out)\n", "\n", " return output\n" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "To test if this layer works as expected, we expect the input and output shapes to be identical." ] }, { "cell_type": "code", "execution_count": null, "metadata": {}, "outputs": [], "source": [ "mha_layer = MultiHeadAttn(n_head=2, dim_model=16, dim_head=5, dropout=0.1, dropatt=0)\n", "\n", "seq = torch.rand(10, 8, 16) # [q_len x batch_size x dim_model]\n", "pos_emb = torch.rand(16, 16) # [k_len x dim_model]\n", "mems = torch.rand(6, 8, 16) # [mem_len x batch_size x dim_model]\n", "u, v = torch.rand(2, 5), torch.rand(2, 5) # [batch_size, dim_head]\n", "\n", "outputs = mha_layer(w=seq, r=pos_emb, u=u, v=v, attn_mask=None, mems=mems)" ] }, { "cell_type": "code", "execution_count": null, "metadata": {}, "outputs": [], "source": [ "print(\"Input sequence shape = \", seq.shape)\n", "print(\"Output sequence shape = \", outputs.shape)\n", "\n", "assert seq.shape == outputs.shape" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "### The decoder layer\n", "\n", "You will build the decoder block by using MultiHeadAttn along with a Positionwise Feed Forward layer identical to the original Transformer.\n", "" ] }, { "cell_type": "code", "execution_count": null, "metadata": {}, "outputs": [], "source": [ "class PositionwiseFF(nn.Module):\n", " \"\"\" \n", " Defines the Position wise FeedForward layer in the Transformer-XL \n", " \"\"\"\n", " \n", " def __init__(self, dim_model, dim_inner, dropout):\n", " super(PositionwiseFF, self).__init__()\n", "\n", " # Input dimension\n", " self.dim_model = dim_model\n", "\n", " # Inner dimension within Positionwise FF\n", " self.dim_inner = dim_inner\n", " \n", " self.dropout = dropout\n", "\n", " self.CoreNet = nn.Sequential(\n", " nn.Linear(dim_model, dim_inner),\n", " nn.ReLU(inplace=True),\n", " nn.Dropout(dropout),\n", " nn.Linear(dim_inner, dim_model),\n", " nn.Dropout(dropout),\n", " )\n", "\n", " self.layer_norm = nn.LayerNorm(dim_model)\n", "\n", " def forward(\n", " self, inp: torch.FloatTensor # (q_len, batch_size, dim_model)\n", " ) -> torch.FloatTensor: # (q_len, batch_size, dim_model)\n", "\n", " # positionwise feed-forward\n", " core_out = self.CoreNet(inp)\n", "\n", " # residual connection + layer normalization\n", " output = self.layer_norm(inp + core_out)\n", "\n", " return output" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "You will use this `PositionwiseFF` layer in the `DecoderLayer`" ] }, { "cell_type": "code", "execution_count": null, "metadata": {}, "outputs": [], "source": [ "class DecoderLayer(nn.Module):\n", " \"\"\" \n", " Transformer-XL decoder layer comprised of the Multihead attention \n", " and Positionwise Feed Forward layers \n", " \"\"\"\n", " \n", " def __init__(self, n_head, dim_model, dim_head, dim_inner, dropout, dropatt=0):\n", "\n", " super(DecoderLayer, self).__init__()\n", "\n", " self.dec_attn = MultiHeadAttn(n_head, dim_model, dim_head, dropout, dropatt)\n", "\n", " self.pos_ff = PositionwiseFF(dim_model, dim_inner, dropout)\n", "\n", " def forward(self, dec_inp, r, u, v, dec_attn_mask=None, mems=None):\n", "\n", " output = self.dec_attn(\n", " dec_inp, r, u, v, attn_mask=dec_attn_mask, mems=mems\n", " )\n", "\n", " output = self.pos_ff(output)\n", "\n", " return output" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "### The Transformer-XL decoder\n", "\n", "Using the `DecoderLayer` defined above you can now build the Transformer-XL.\n", "\n", "You will also need to define the input `Embedding` layer that maps from input indices to a sequence of dimension `dim_model` and the Output layer that maps from `dim_model` to the length of vocabulary.\n", "\n", "The Transformer-XL ties the weights in the Embedding Layer and Output layer so that the total parameter count is reduced. " ] }, { "cell_type": "code", "execution_count": null, "metadata": {}, "outputs": [], "source": [ "class Embedding(nn.Module):\n", " \"\"\"\n", " Embedding layer in the Transformer-XL\n", " \"\"\"\n", " def __init__(self, n_token, dim_embed):\n", " \"\"\"\n", " Args:\n", " n_token: number of tokens in vocab\n", " dim_embed: dimension of embedding\n", " \"\"\"\n", "\n", " super(Embedding, self).__init__()\n", "\n", " self.n_token = n_token\n", " self.dim_embed = dim_embed\n", "\n", " self.emb_scale = dim_embed ** 0.5\n", "\n", " self.emb_layers = nn.ModuleList()\n", "\n", " self.emb_layers.append(nn.Embedding(n_token, dim_embed, sparse=False))\n", "\n", " def forward(\n", " self,\n", " inp: torch.LongTensor, # (qlen, batch_size)\n", " ) -> torch.FloatTensor: # (qlen, batch_size, dim_embed)\n", " embed = self.emb_layers[0](inp)\n", "\n", " # Embeddings are scaled while the Output Layer of Transformer-XL is not\n", " embed.mul_(self.emb_scale)\n", "\n", " return embed" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "You will now define the Transformer-XL module using everything you have learnt so far." ] }, { "cell_type": "code", "execution_count": null, "metadata": {}, "outputs": [], "source": [ "class TransformerXL(nn.Module):\n", " \"\"\" \n", " The Transformer-XL module comprised of the Embedding layer,\n", " multiple Decoder layers and the output layer\n", " \"\"\"\n", " def __init__(\n", " self,\n", " n_layer,\n", " n_head,\n", " dim_model,\n", " dim_inner,\n", " dropout,\n", " dropatt,\n", " tie_weight,\n", " tgt_len,\n", " mem_len,\n", " n_token,\n", " ):\n", "\n", " super(TransformerXL, self).__init__()\n", "\n", " # Embedding layer\n", " self.word_emb = Embedding(\n", " n_token,\n", " dim_model,\n", " )\n", "\n", " dim_head = dim_model // n_head # Dimensionality of the model’s heads\n", "\n", " # Positional embedding\n", " self.pos_emb = PositionalEmbedding(dim_model)\n", " self.u = nn.Parameter(torch.Tensor(n_head, dim_head))\n", " self.v = nn.Parameter(torch.Tensor(n_head, dim_head))\n", "\n", " self.drop = nn.Dropout(dropout)\n", "\n", " self.n_layer = n_layer\n", "\n", " self.tgt_len = tgt_len\n", " self.mem_len = mem_len\n", "\n", " # Define the decoder layers that comprise the Transformer-XL\n", " self.layers = nn.ModuleList()\n", "\n", " for i in range(n_layer):\n", " self.layers.append(\n", " DecoderLayer(\n", " n_head,\n", " dim_model,\n", " dim_head,\n", " dim_inner,\n", " dropout,\n", " dropatt=dropatt,\n", " )\n", " )\n", "\n", " # Define output layer\n", " self.out_layers = nn.ModuleList()\n", " self.out_layers.append(nn.Linear(dim_model, n_token))\n", "\n", " # Tie weights of output layer with embedding layer\n", " if tie_weight:\n", " for i in range(len(self.out_layers)):\n", " self.out_layers[i].weight = self.word_emb.emb_layers[i].weight\n", "\n", " def reset_length(self, tgt_len, mem_len):\n", " \"\"\"\n", " Resets tgt_len and mem_len to specified values\n", " \n", " Used when tgt_len and mem_len may be different between training,\n", " evaluation and generation\n", " \"\"\"\n", " self.tgt_len = tgt_len\n", " self.mem_len = mem_len\n", "\n", " def init_mems(self, n_layers):\n", " \"\"\"\n", " Initialize mems tensor if mems is None\n", " \"\"\"\n", " param = next(self.parameters())\n", " mems = torch.empty(n_layers + 1, 0, dtype=param.dtype, device=param.device)\n", " return mems\n", "\n", " def update_mems(self, hids, mems, qlen, mlen):\n", " \"\"\"\n", " This function is called at the end of a forward.\n", " Updates mems with hidden states of current segment\n", " \"\"\"\n", " \n", " if mems is None:\n", " return None\n", "\n", " with torch.no_grad():\n", "\n", " # Update mems with the most recent `self.mem_len`\n", " # states that includes the previous memory\n", "\n", " stacked = torch.stack(hids)\n", " end_idx = mlen + max(0, qlen)\n", " start_idx = max(0, end_idx - self.mem_len)\n", " \n", " # Dimension of cat is (num_layers, self.mem_len+qlen, batch_size, dim_model)\n", " cat = torch.cat([mems, stacked], dim=1) if mems.numel() else stacked\n", " \n", " # Dimension of new_mems is (num_layers, self.mem_len, batch_size, dim_model)\n", " new_mems = cat[:, start_idx:end_idx].detach()\n", " \n", " return new_mems\n", "\n", " def _forward(self, dec_inp, mems=None):\n", " \"\"\"\n", " Helper function used by forward()\n", "\n", " \"\"\"\n", " qlen, batch_size = dec_inp.size()[0], dec_inp.size()[1]\n", " word_emb = self.word_emb(dec_inp)\n", "\n", " mlen = mems[0].size(0) if mems is not None else 0\n", " klen = mlen + qlen\n", "\n", " # Construct attention mask\n", " dec_attn_mask = torch.triu(\n", " word_emb.new_ones(qlen, klen), diagonal=1 + mlen\n", " ).bool()[:, :]\n", "\n", " # Construct positional embeddings\n", " pos_seq = torch.arange(\n", " klen - 1, -1, -1.0, device=word_emb.device, dtype=word_emb.dtype\n", " )\n", "\n", " pos_emb = self.pos_emb(pos_seq)\n", " pos_emb = self.drop(pos_emb)\n", "\n", " # Successively run through Decoder Layers\n", " hids = []\n", " core_out = self.drop(word_emb)\n", " hids.append(core_out)\n", "\n", " for i, layer in enumerate(self.layers):\n", " mems_i = None if mems is None else mems[i]\n", " core_out = layer(\n", " core_out,\n", " pos_emb,\n", " self.u,\n", " self.v,\n", " dec_attn_mask=dec_attn_mask,\n", " mems=mems_i,\n", " )\n", " hids.append(core_out)\n", " core_out = self.drop(core_out)\n", "\n", " # Update memory\n", " new_mems = self.update_mems(hids, mems, mlen, qlen)\n", "\n", " return core_out, new_mems\n", "\n", " def forward(self, data, target, mems=None):\n", "\n", " if mems is None and self.mem_len > 0:\n", " mems = self.init_mems(self.n_layer)\n", "\n", " tgt_len = target.size(0)\n", " hidden, new_mems = self._forward(data, mems=mems)\n", "\n", " pred_hid = hidden[-tgt_len:]\n", "\n", " logit = self.out_layers[0](pred_hid.view(-1, pred_hid.size(-1)))\n", "\n", " loss = (\n", " -F.log_softmax(logit, dim=-1)\n", " .gather(1, target.view(-1).unsqueeze(1))\n", " .squeeze(1)\n", " )\n", "\n", " loss = loss.view(tgt_len, -1)\n", "\n", " return (loss, new_mems)\n", "\n", " def forward_generate(self, data, mems):\n", " \"\"\"\n", " This function is called during inference (decoding)\n", " when one generates tokens incrementally.\n", " It is identical to forward() but does not compute the loss\n", " and returns the logits instead\n", "\n", " \"\"\"\n", " if mems is None and self.mem_len > 0:\n", " mems = self.init_mems(self.n_layer)\n", "\n", " tgt_len = data.size(0)\n", " batch_size = data.size(1)\n", "\n", " hidden, new_mems = self._forward(data, mems=mems)\n", "\n", " pred_hid = hidden[-tgt_len:]\n", "\n", " logits = self.out_layers[0](pred_hid.view(-1, pred_hid.size(-1)))\n", " logits = logits.view(tgt_len, batch_size, -1)\n", "\n", " return (logits, new_mems)" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "You will test if the model is working with some dummy inputs" ] }, { "cell_type": "code", "execution_count": null, "metadata": {}, "outputs": [], "source": [ "transformerxl = TransformerXL(\n", " n_layer=5,\n", " n_head=4,\n", " dim_model=10,\n", " dim_inner=5,\n", " dropout=0.1,\n", " dropatt=0,\n", " tie_weight=True,\n", " tgt_len=20,\n", " mem_len=5,\n", " n_token=310,\n", ")" ] }, { "cell_type": "code", "execution_count": null, "metadata": {}, "outputs": [], "source": [ "inputs = torch.randint(310, (20, 2)) # input indices of shape (tgt_len, batch_size)\n", "tgts = torch.randint(310, (20, 2)) # target indices of shape (tgt_len, batch_size)\n", "outputs = transformerxl(inputs, tgts)\n", "\n", "print(\"Output is a tuple of shape \", len(outputs))\n", "assert len(outputs)==2\n", "\n", "print(\"Loss is a tensor of shape \", outputs[0].shape) # (tgt_len, batch_size)\n", "assert outputs[0].shape == tgts.shape\n", "\n", "print(\"Memory is a tensor of shape \", outputs[1].shape) # (n_layer+1, mem_len, batch_size, dim_model)\n", "assert outputs[1].shape == torch.Size([5+1, 5, tgts.shape[1], 10])" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "## Training the model\n", "\n", "In the following sections, you can see how to train the Transformers-XL model.\n", "\n", "You will first define the hyperparameters that you will use in the data loader, training, and evaluation loops." ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "### Training hyperparameters\n", "\n", "Hyperparameters are broadly categorized into those that control training and evaluation, and those that define the model architecture." ] }, { "cell_type": "code", "execution_count": null, "metadata": {}, "outputs": [], "source": [ "@dataclass\n", "class TrainConfig:\n", " \"\"\"\n", " Defines configuration parameters used during model training\n", " \"\"\"\n", " \n", " # Dataset\n", " data_dir = \"data/jsb_chorales_numpy\"\n", "\n", " # Checkpoint save path\n", " save_path = \"checkpoints/\"\n", "\n", " # Training and evaluation hyperparameters\n", " batch_size = 64 # Training batch size\n", " seed = 101 # Seed to reproduce losses\n", " tgt_len = 128 # Target length or bptt (use as large as fits in GPU memory)\n", " mem_len = 512 # Memory length (use as large as fits in GPU memory)\n", " clip = 1.0 # Grad norm clip constant\n", " scheduler = \"inv_sqrt\" # Learning rate scheduler\n", " warmup_step = 4000 # Learning rate warmup\n", " lr = 0.004 / 8 # Learning rate\n", " lr_min = 0.0001 / 4 # Min learning rate\n", " optim = \"adam\" # Optimizer\n", " weight_decay = 0.0 # Weight decay for adam\n", " max_step = 20000 # Max steps\n", " \n", " eval_batch_size = 2 # Evaluation batch size\n", " eval_tgt_len = 128 # Evaluation target length\n", " eval_mem_len = 512 # Evaluation memory length\n", "\n", " log_interval = 100 # Print logs every log_interval training iterations\n", " eval_interval = 500 # Evaluate after eval_interval training iterations\n", "\n", " # Plotting and saving params\n", " save_all_test_losses = True \n", " plot_losses_while_training = True\n", " plot_interval = 100 # Plot losses every plot_interval training iterations\n", "\n", " # Weight initialization\n", " base_init = [\"normal\", 0.01] # Initialization parameters for weights\n", " embed_init = [\"normal\", 0.01] # Intialization parameters for embeddings\n", "\n", " # Model hyperparameters\n", " dropout = 0.1 # The dropout probability for all fully connected layers in the embeddings, encoder, and pooler\n", " dropatt = 0.1 # The dropout ratio for the attention probabilities\n", " dim_inner = 1000 # Inner dimension within Positionwise FF \n", " num_heads = 10 # Number of heads in Multihead attention\n", " num_layers = 4 # Number of layers in Transformer-XL\n", " tie_embedding = True # Share weights between input embedding and output layer\n", " dim_model = 500 # Dimensionality of the model’s hidden states" ] }, { "cell_type": "code", "execution_count": null, "metadata": {}, "outputs": [], "source": [ "train_cfg = TrainConfig()" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "### Building the data loader\n", "\n", "While the Transformer-XL data loader resembles the standard data loading pipeline in language models like the RNN, it is different in that the Transformer-XL memory persists across batches.\n", "\n", "You need to ensure that batch elements across batches in the Transformer-XL correspond to the same MIDI file. This ensures that the Transformer-XL memory contains the cached segments preceding the current segment when you train using minibatches.\n", "\n", "\n", "\n", "In the figure above, we depict two successive batches (each with 2 elements) that the model is trained on. Each batch element is a sequence of length `tgt_len`. The batches are constructed so that each batch element (Element 1 in Batch 1 and Element 1 in Batch 2) uses segments from the same MIDI file. This ensures that the Transformer-XL memory for a batch element caches segments from same MIDI file that the current segment is from. \n", "\n", "You will also use a `BaseVocab` class that will help you work with the Magenta vocabulary. This class abstracts several functions that map from token names (NOTE_ON_70 etc.) to indices." ] }, { "cell_type": "code", "execution_count": null, "metadata": {}, "outputs": [], "source": [ "class MusicDataset:\n", " def __init__(self, data_dir):\n", " \"\"\"Load the music corpus\n", " Args:\n", " data_dir: The base folder of the preprocessed music dataset\n", " \"\"\"\n", " self.vocab_path = os.path.join(data_dir, \"vocab.txt\")\n", " self.train_folder = os.path.join(data_dir, \"train\")\n", " self.valid_folder = os.path.join(data_dir, \"valid\")\n", " self.test_folder = os.path.join(data_dir, \"test\")\n", " all_tokens = []\n", " with open(self.vocab_path, \"r\") as f:\n", " all_tokens = [token.strip() for token in f]\n", " \n", " # BaseVocab class that provides useful functions to interact with vocabulary\n", " self.vocab = BaseVocab(all_tokens)\n", "\n", " self.train_data = self.load_cache_data(self.train_folder)\n", " self.valid_data = self.load_cache_data(self.valid_folder)\n", " self.test_data = self.load_cache_data(self.test_folder)\n", "\n", " # Insert start tokens\n", " \n", " self.train_data = [\n", " torch.from_numpy(np.insert(arr, 0, self.vocab.bos_id))\n", " for arr in self.train_data\n", " ]\n", " self.valid_data = [\n", " torch.from_numpy(np.insert(arr, 0, self.vocab.bos_id))\n", " for arr in self.valid_data\n", " ]\n", " self.test_data = [\n", " torch.from_numpy(np.insert(arr, 0, self.vocab.bos_id))\n", " for arr in self.test_data\n", " ]\n", "\n", " # Extract sequence lengths for the different splits\n", " self.train_seq_length = np.array(\n", " [ele.shape[0] for ele in self.train_data], dtype=np.int32\n", " )\n", " self.valid_seq_length = np.array(\n", " [ele.shape[0] for ele in self.valid_data], dtype=np.int32\n", " )\n", " self.test_seq_length = np.array(\n", " [ele.shape[0] for ele in self.test_data], dtype=np.int32\n", " )\n", " print(\n", " \"Loaded Data, #Samples Train/Val/Test:{}/{}/{}\".format(\n", " len(self.train_data), len(self.valid_data), len(self.test_data)\n", " )\n", " )\n", " print(\n", " \"#Avg Length:{}/{}/{}\".format(\n", " np.mean([len(ele) for ele in self.train_data]),\n", " np.mean([len(ele) for ele in self.valid_data]),\n", " np.mean([len(ele) for ele in self.test_data]),\n", " )\n", " )\n", " print(\n", " \"#Total Number of Valid/Test Tokens: {}/{}\".format(\n", " (self.valid_seq_length - 1).sum(), (self.test_seq_length - 1).sum()\n", " )\n", " )\n", "\n", " def load_cache_data(self, dir_name):\n", " \"\"\"\n", " Returns the loaded numpy dataset from dir_name\n", " \"\"\"\n", " all_fnames = sorted(glob.glob(os.path.join(dir_name, \"*.npy\")))\n", " print(\"Loading #{} files from {}\".format(len(all_fnames), dir_name))\n", " # Create a large array\n", " with multiprocessing.Pool(8) as pool:\n", " dat = pool.map(np.load, all_fnames)\n", " return np.array(dat)\n", "\n", " def get_iterator(\n", " self, batch_size, bptt, device, split=\"train\", do_shuffle=True, seed=None\n", " ):\n", " \"\"\"\n", " Function that returns an iterator over the dataset specified by \n", " batch_size, bptt, device and split\n", " \"\"\"\n", " if split == \"train\":\n", " split_data = self.train_data\n", " split_seq_lengths = self.train_seq_length\n", " elif split == \"valid\":\n", " split_data = self.valid_data\n", " split_seq_lengths = self.valid_seq_length\n", " elif split == \"test\":\n", " split_data = self.test_data\n", " split_seq_lengths = self.test_seq_length\n", " else:\n", " raise NotImplementedError\n", " total_sample_num = len(split_data)\n", "\n", " def iterator():\n", " perm = np.arange(total_sample_num)\n", " if do_shuffle:\n", " rng = np.random.RandomState(seed)\n", " rng.shuffle(perm)\n", " assert batch_size < total_sample_num\n", " tracker_list = [(i, 0) for i in range(batch_size)]\n", " next_idx = batch_size\n", " data = torch.LongTensor(bptt, batch_size)\n", " target = torch.LongTensor(bptt, batch_size)\n", "\n", " while True:\n", "\n", " # Fill with pad_id\n", " data[:] = self.vocab.pad_id\n", " target[:] = self.vocab.pad_id\n", "\n", " batch_token_num = 0\n", " for i in range(batch_size):\n", " idx, pos = tracker_list[i]\n", " while idx < total_sample_num:\n", " seq_id = perm[idx]\n", " seq_length = split_seq_lengths[seq_id]\n", " if pos + 1 >= seq_length:\n", " idx, pos = next_idx, 0\n", " tracker_list[i] = (idx, pos)\n", " next_idx += 1\n", " continue\n", " else:\n", " n_new = min(seq_length - 1 - pos, bptt)\n", " data[:n_new, i] = split_data[seq_id][pos: pos + n_new]\n", " target[:n_new, i] = split_data[seq_id][\n", " (pos + 1): (pos + 1 + n_new)]\n", " batch_token_num += n_new\n", " tracker_list[i] = (idx, pos + n_new)\n", "\n", " break\n", " \n", " if batch_token_num == 0:\n", " # Haven't found anything to fill. This indicates we have reached the end\n", " if do_shuffle:\n", " rng.shuffle(perm)\n", " else:\n", " return # One pass dataloader when do_shuffle is False\n", " tracker_list = [(i, 0) for i in range(batch_size)]\n", " next_idx = batch_size\n", " continue\n", "\n", " yield data.to(device), target.to(device), batch_token_num\n", "\n", " return iterator\n" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "### Loading data\n", "\n", "You will use the Dataloader you just defined to load the dataset.\n" ] }, { "cell_type": "code", "execution_count": null, "metadata": {}, "outputs": [], "source": [ "dataset = MusicDataset(train_cfg.data_dir) # Dataset path\n", "vocab = dataset.vocab # Vocabulary class\n", "seed = train_cfg.seed # seed to ensure constant behavior across runs\n", "device = (\n", " torch.device(\"cpu\") if not torch.cuda.is_available() else torch.device(\"cuda:0\")\n", ")\n", "\n", "batch_size = train_cfg.batch_size\n", "\n", "# Train split iterator\n", "train_iter = dataset.get_iterator(\n", " batch_size, train_cfg.tgt_len, device, \"train\", do_shuffle=True, seed=seed\n", ")\n", "\n", "# Validation split iterator\n", "val_iter = dataset.get_iterator(\n", " train_cfg.eval_batch_size,\n", " train_cfg.eval_tgt_len,\n", " device,\n", " \"valid\",\n", " do_shuffle=False,\n", " seed=seed,\n", ")\n", "\n", "# Test split iterator\n", "test_iter = dataset.get_iterator(\n", " train_cfg.eval_batch_size,\n", " train_cfg.eval_tgt_len,\n", " device,\n", " \"test\",\n", " do_shuffle=False,\n", " seed=seed,\n", ")" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "### Evaluation loop\n", "\n", "You will now define the evaluation loop used while training the model." ] }, { "cell_type": "code", "execution_count": null, "metadata": {}, "outputs": [], "source": [ "def evaluate(model, eval_iter):\n", " \"\"\"\n", " Function to compute validation negative log-likelihood (nll) of a model\n", " on a dataset specified with the eval_iter iterator\n", " \"\"\"\n", " \n", " # Turn on evaluation mode def disables dropout.\n", " model.eval()\n", "\n", " model.reset_length(tgt_len=train_cfg.eval_tgt_len, \n", " mem_len=train_cfg.eval_mem_len)\n", " \n", " # Evaluation\n", " total_token_num = 0\n", " total_nll = 0.0\n", "\n", " with torch.no_grad():\n", " mems = None\n", "\n", " for i, (data, target, batch_token_num) in enumerate(eval_iter()):\n", "\n", " loss, mems = model(data, target, mems)\n", " loss = loss[target != dataset.vocab.pad_id]\n", " loss = loss.mean()\n", " total_nll += batch_token_num * loss.float().item()\n", " total_token_num += batch_token_num\n", " \n", " model.reset_length(train_cfg.tgt_len, train_cfg.mem_len)\n", " model.train()\n", " \n", " return total_token_num, total_nll\n" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "### Training loop\n", "\n", "You will now write the training loop. First a few helper functions that help with training." ] }, { "cell_type": "code", "execution_count": null, "metadata": {}, "outputs": [], "source": [ "# Dictionaries to record train, val and test losses\n", "train_losses = dict()\n", "val_losses = dict()\n", "test_losses = dict()" ] }, { "cell_type": "code", "execution_count": null, "metadata": {}, "outputs": [], "source": [ "def plot_losses_while_training():\n", " \"\"\"\n", " Helper function to plot losses while training\n", " \"\"\"\n", " display.clear_output(wait=True)\n", " fig = plt.figure(figsize=(15, 5))\n", "\n", " def plot_lines(loss_dic, color):\n", " iters = list(loss_dic.keys())\n", " vals = [loss_dic[i] for i in iters]\n", " return plt.plot(iters, vals, color)\n", "\n", " (line1,) = plot_lines(train_losses, \"r\")\n", " (line2,) = plot_lines(val_losses, \"k\")\n", " (line3,) = plot_lines(test_losses, \"b\")\n", "\n", " plt.xlabel(\"Iterations\")\n", " plt.ylabel(\"Losses\")\n", " plt.legend((line1, line2, line3), (\"train-loss\", \"val-loss\", \"test-loss\"))\n", " display.display(fig)\n", " plt.close()" ] }, { "cell_type": "code", "execution_count": null, "metadata": {}, "outputs": [], "source": [ "def evaluate_and_log(model, train_step, mode=\"eval\"):\n", " \"\"\"\n", " Helper function to evaluate model in \"eval\" or \"test\" mode and log losses\n", " \"\"\"\n", " start_time = time.time()\n", " \n", " eval_iter = val_iter if mode==\"eval\" else test_iter\n", " token_num, total_nll = evaluate(model=model, eval_iter=eval_iter)\n", "\n", " nll = total_nll / token_num\n", "\n", " pprint(\n", " f\"{mode} step {train_step}, time={(time.time() - start_time)}s, {mode} nll={nll},\" \n", " f\"{mode} ppl={math.exp(nll)}, #evaluated tokens={token_num}\"\n", " )\n", " \n", " return nll" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "You are now ready to write the entire training loop. We minimize the [negative log-likelihood (NLL)](https://d2l.ai/chapter_appendix-mathematics-for-deep-learning/maximum-likelihood.html) loss that is standard practice in language modeling." ] }, { "cell_type": "code", "execution_count": null, "metadata": {}, "outputs": [], "source": [ "def train(model):\n", " \"\"\"\n", " Main training function that iterates over epochs, computes the loss,\n", " computes gradients via the backward pass and updates weights using \n", " the optimizer.\n", " \n", " Also includes functionality for plotting losses realtime and saving the\n", " best model checkpoint\n", " \n", " \"\"\"\n", " train_step = 0\n", " best_val_nll = np.inf\n", "\n", " log_train_loss = torch.tensor(0.0).float().to(device)\n", " log_grad_norm = torch.tensor(0.0).float().to(device)\n", " log_token_num = torch.tensor(0).to(device)\n", "\n", " log_start_time = time.time()\n", "\n", " mems = None\n", "\n", " # Define optimizer\n", " if train_cfg.optim.lower() == \"adam\":\n", " optimizer = optim.Adam(\n", " model.parameters(), lr=train_cfg.lr, weight_decay=train_cfg.weight_decay\n", " )\n", " else:\n", " raise NotImplementedError\n", "\n", " # Define scheduler\n", " if train_cfg.scheduler == \"inv_sqrt\":\n", " # originally used for Transformer (in Attention is all you need)\n", " def lr_lambda(step):\n", " # return a multiplier instead of a learning rate\n", " if step == 0 and train_cfg.warmup_step == 0:\n", " return 1.0\n", " else:\n", " return (\n", " max(\n", " (train_cfg.warmup_step ** 0.5) / (step ** 0.5),\n", " train_cfg.lr_min / train_cfg.lr,\n", " )\n", " if step > train_cfg.warmup_step\n", " else step / train_cfg.warmup_step\n", " )\n", "\n", " scheduler = optim.lr_scheduler.LambdaLR(optimizer, lr_lambda=lr_lambda)\n", " else:\n", " raise NotImplementedError\n", "\n", " train_real_iter = train_iter()\n", "\n", " # Iterate over epochs\n", " for batch, (data, target, batch_token_num) in enumerate(train_real_iter):\n", "\n", " model.zero_grad()\n", "\n", " loss, mems = model(data, target, mems)\n", "\n", " loss = loss[target != dataset.vocab.pad_id]\n", " loss = loss.float().mean()\n", "\n", " # Record total loss over all non pad tokens\n", " log_train_loss += loss.item() * (target != dataset.vocab.pad_id).sum()\n", "\n", " loss.backward()\n", "\n", " log_token_num += int(batch_token_num)\n", "\n", " grad_norm = torch.nn.utils.clip_grad_norm_(model.parameters(), train_cfg.clip)\n", "\n", " log_grad_norm += grad_norm\n", " optimizer.step()\n", " optimizer.zero_grad()\n", "\n", " # step-wise learning rate annealing\n", " train_step += 1\n", " scheduler.step()\n", "\n", " # Log losses\n", " if train_step % train_cfg.log_interval == 0:\n", " \n", " log_train_loss /= log_token_num\n", " log_grad_norm /= train_cfg.log_interval\n", "\n", " elapsed = time.time() - log_start_time\n", " pprint(\n", " \"train Step {}/{}, lr={:f}, tokens/s={:.1f},\"\n", " \" train nll={:.4f}, train ppl={:.2f}, grad norm={}\".format(\n", " train_step,\n", " train_cfg.max_step,\n", " optimizer.param_groups[0][\"lr\"],\n", " log_token_num.item() / elapsed,\n", " log_train_loss.item(),\n", " math.exp(log_train_loss.item()),\n", " log_grad_norm.item(),\n", " )\n", " )\n", "\n", " # Save train loss\n", " train_losses[train_step] = log_train_loss.item()\n", "\n", " log_train_loss[()] = 0\n", " log_grad_norm[()] = 0\n", " log_token_num[()] = 0\n", "\n", " log_start_time = time.time()\n", " \n", " # Evaluate\n", " if train_step % train_cfg.eval_interval == 0:\n", " val_nll = evaluate_and_log(model, train_step, mode=\"val\")\n", " \n", " # Save val loss\n", " val_losses[train_step] = val_nll.item()\n", "\n", " # Save best model\n", " if val_nll < best_val_nll or train_cfg.save_all_test_losses:\n", " \n", " if val_nll < best_val_nll:\n", " best_val_nll = val_nll\n", "\n", " save_checkpoint(\n", " model,\n", " train_step,\n", " best_val_nll,\n", " train_cfg.save_path,\n", " \"checkpoint_best.pt\",\n", " )\n", "\n", " # Get test nll\n", " test_nll = evaluate_and_log(model, train_step, mode=\"test\")\n", " \n", " # Save test loss\n", " test_losses[train_step] = test_nll.item()\n", " \n", " # Plot losses while training\n", " if train_cfg.plot_losses_while_training and train_step % train_cfg.plot_interval == 0:\n", " plot_losses_while_training()\n", "\n", " if train_step == train_cfg.max_step:\n", " pprint(\"-\" * 100)\n", " pprint(\"Max steps reached. End of training\")\n", " break" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "### Weight initialization\n", "\n", "Before you begin training, you will define functions to initialize the weights in the model. \n" ] }, { "cell_type": "code", "execution_count": null, "metadata": {}, "outputs": [], "source": [ "def init_weight(weight):\n", " \"\"\"\n", " Function to help initialize all layer weights\n", " \"\"\"\n", " if train_cfg.base_init[0] == \"normal\":\n", " init_std = train_cfg.base_init[1]\n", " nn.init.normal_(weight, 0.0, init_std)\n", " else:\n", " raise NotImplementedError\n", " \n", "def init_embed(weight):\n", " \"\"\"\n", " Function to help initialize embedding weights\n", " \"\"\"\n", " if train_cfg.embed_init[0] == \"normal\":\n", " init_std = train_cfg.embed_init[1]\n", " nn.init.normal_(weight, 0.0, init_std)\n", " else:\n", " raise NotImplementedError\n", "\n", "def init_bias(bias):\n", " \"\"\"\n", " Function to help initialize layer bias\n", " \"\"\"\n", " nn.init.constant_(bias, 0.0)\n", "\n", "def weights_init(m):\n", " \"\"\"\n", " Function that initializes layer weights and biases in the Transformer-XL\n", " based on name \n", " \"\"\"\n", " classname = m.__class__.__name__\n", " if classname.find(\"Linear\") != -1:\n", " if hasattr(m, \"weight\") and m.weight is not None:\n", " init_weight(m.weight)\n", " if hasattr(m, \"bias\") and m.bias is not None:\n", " init_bias(m.bias)\n", " elif classname.find(\"Embedding\") != -1:\n", " if hasattr(m, \"weight\"):\n", " init_weight(m.weight)\n", " elif classname.find(\"LayerNorm\") != -1:\n", " if hasattr(m, \"weight\"):\n", " nn.init.normal_(m.weight, 1.0, train_cfg.base_init[1])\n", " if hasattr(m, \"bias\") and m.bias is not None:\n", " init_bias(m.bias)\n", " elif classname.find(\"TransformerXL\") != -1:\n", " if hasattr(m, \"u\"):\n", " init_weight(m.u)\n", " if hasattr(m, \"v\"):\n", " init_weight(m.v)\n" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "\n", "### Let's train the model\n", "You shall now proceed to define the model, initialize weights and then begin training.\n" ] }, { "cell_type": "code", "execution_count": null, "metadata": {}, "outputs": [], "source": [ "# Let us save our config file along with the saved checkpoints\n", "train_cfg.save(os.path.join(train_cfg.save_path, \"exp.yaml\"))" ] }, { "cell_type": "code", "execution_count": null, "metadata": {}, "outputs": [], "source": [ "# Create the model\n", "transformerxl = TransformerXL(n_layer=train_cfg.num_layers, n_head=train_cfg.num_heads,\n", " dim_model=train_cfg.dim_model, dim_inner=train_cfg.dim_inner, \n", " dropout=train_cfg.dropout, dropatt=train_cfg.dropatt,\n", " tie_weight=train_cfg.tie_embedding, tgt_len=train_cfg.tgt_len,\n", " mem_len=train_cfg.mem_len, n_token=len(vocab),)\n", "\n", "# Apply weight initialization to model\n", "transformerxl.apply(weights_init)\n", "transformerxl.word_emb.apply(weights_init) # ensure embedding init is not overridden by out_layer in case of weight sharing\n", "\n", "# Send model to device\n", "transformerxl = transformerxl.to(device)\n" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "You will now call `train` that also plots the train and validation losses while training. With the default parameters training for 5000 iterations is sufficient." ] }, { "cell_type": "code", "execution_count": null, "metadata": {}, "outputs": [], "source": [ "train(transformerxl)" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "### Load a pretrained checkpoint (Optional)" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "If your model did not finish training, uncomment the cell below so that you can load a pretrained checkpoint." ] }, { "cell_type": "code", "execution_count": null, "metadata": {}, "outputs": [], "source": [ "# pretrained_path = 'pretrained_checkpoints'\n", "\n", "# # Load pretrained config file\n", "# train_cfg = TrainConfig.load(os.path.join(pretrained_path,'exp.yaml'))\n", "\n", "# # Create the model\n", "# transformerxl = TransformerXL(n_layer=train_cfg.num_layers, n_head=train_cfg.num_heads,\n", "# dim_model=train_cfg.dim_model, dim_inner=train_cfg.dim_inner, \n", "# dropout=train_cfg.dropout, dropatt=train_cfg.dropatt,\n", "# tie_weight=train_cfg.tie_embedding, tgt_len=train_cfg.tgt_len,\n", "# mem_len=train_cfg.mem_len, n_token=len(vocab),)\n", "\n", "# # Load pretrained checkpoint\n", "# model_fp = os.path.join(pretrained_path,'checkpoint_best.pt')\n", "# checkpoint = torch.load(model_fp)\n", "# transformerxl.load_state_dict(checkpoint[\"model\"])\n", "\n", "# # Send model to device\n", "# transformerxl = transformerxl.to(device)\n", "\n", "# # Load saved losses\n", "# with open(os.path.join(pretrained_path,'losses.pickle'),'rb') as handle:\n", "# losses = pickle.load(handle)\n", "# train_losses = losses['train_losses']\n", "# val_losses = losses['val_losses']\n", "# test_losses = losses['test_losses']" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "### Plot losses\n", "\n", "Below, the training, validation and test losses are plotted after training is completed. The training loss is non-increasing while the validation and test losses increase after a certain number of iterations due to overfitting. Our best checkpoint corresponds to the model with lowest validation loss.\n" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "scrolled": true }, "outputs": [], "source": [ "# Plot train, validation and test losses\n", "plot_losses(train_losses, val_losses, test_losses)" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "## Generating samples \n" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "Congratulations! You have now trained your very own Transformer-XL model, and you can now use this trained model to extend an input melody file.\n", "\n", "The model generates a melody by sampling a sequence from the model's distribution.\n", "\n", "Sampling in an autoregressive model like the Transformer is an iterative process. To sample a sequence from the model sample the next token from the model's output probabability distribution given the history of tokens. \n", "\n", "You will look at two different sampling techniques in this notebook: TopK and Nucleus. A `threshold` value called the sampling threshold is associated with each. \n", "\n", "__TopK sampling__\n", "\n", " \n", "\n", "In TopK sampling, the model samples from the K-tokens that have the highest probability of occurring. Here k is set using the `threshold` parameter.\n", "\n", "If your sampling threshold is set high, then the number of available tokens (K) is large. This means the model can choose from a wider variety of musical tokens. In your extended melody, this means the generated notes are likely to be more diverse, but it comes at the cost of potentially creating less coherent music.\n", "\n", "On the other hand, if you choose a threshold value that is too low, the model is limited to choosing from a smaller set of tokens which the model believes has a higher probability of being correct. In your extended melody, you might notice less musical diversity and more repetitive results. \n", "\n", "__Nucleus sampling__\n", "\n", " \n", "\n", "Instead of sampling only from the most likely K tokens, nucleus sampling chooses from the smallest possible set of tokens whose cumulative probability exceeds the probability p. p is set using the `threshold` parameter. The probability mass is then redistributed among this set of tokens. This way, the size of the set of tokens can dynamically increase and decrease according to the next word's probability distribution.\n", "\n", "At a high level, Nucleus sampling is very similar to TopK. Setting a higher sampling threshold allows for more diversity at the cost of coherence or consistency. \n", "\n", "__Other inference parameters__\n", "\n", "- Number of Conditional Tokens: This parameter tells the model what portion of the input melody to condition on during inference. \n", "\n", "- Temperature: To create the output probability distribution, the final layer uses a softmax activation. You can [change the temperature](https://console.aws.amazon.com/deepcomposer/home?region=us-east-1#musicStudio) for the softmax to produce different levels of creativity in the outputs generated by the model.\n", "\n", "- Generation length: The number of tokens to generate using the Transformer-XL. \n", "\n", "You can change the inference parameters in `InferenceConfig` class to observe differences in the quality of the music generated." ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "### Inference hyperparameters" ] }, { "cell_type": "code", "execution_count": null, "metadata": {}, "outputs": [], "source": [ "@dataclass\n", "class InferenceConfig:\n", " \"\"\"\n", " Defines configuration parameters used during inference (melody extension)\n", " \"\"\"\n", " \n", " # Model parameters\n", " memory_length = 4096\n", "\n", " # Sampling parameters\n", " technique = 'nucleus' # topk or nucleus\n", " threshold = 0.95 # theshold acts as both k [0-309] for topk sampling or p [0-1] for nucleus sampling\n", " temperature = 0.95\n", "\n", " # Input parameters \n", " num_conditional_tokens = 100 # Number of tokens [>= 1] from the input melody that is used\n", " \n", " # Generation parameters\n", " generation_length = 1500 # Number of tokens to extend the melody\n" ] }, { "cell_type": "code", "execution_count": null, "metadata": { "scrolled": false }, "outputs": [], "source": [ "inference_cfg = InferenceConfig()" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "### Input midi file to extend\n" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "Below, you can update the code cell to select an input MIDI melody to extend.\n", "\n", "The default provided is a MIDI from the test set." ] }, { "cell_type": "code", "execution_count": null, "metadata": {}, "outputs": [], "source": [ "input_melody_path = 'data/jsb_chorales_numpy/test/9.npy'" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "#### To choose a custom input melody (Optional)\n", "\n", "1. Open the `sample_inputs` directory\n", "2. Upload the file that you want to use into this folder. For example, `new_world.midi`\n", "3. Uncomment and run the following cell replacing midi_file with the custom file path" ] }, { "cell_type": "code", "execution_count": null, "metadata": {}, "outputs": [], "source": [ "# # Input melody name\n", "# midi_file = \"sample_inputs/new_world.midi\"\n", "\n", "# # Convert midi to numpy \n", "# out_dir = 'sample_inputs'\n", "# music_encoder.run_to_npy(midi_file, out_dir)\n", "\n", "# filename = os.path.splitext(os.path.basename(midi_file))[0]\n", "# input_melody_path = os.path.join(out_dir, filename + '.npy')" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "### Let's run inference!" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "You will first define a few helper functions for top-k and nucleus sampling." ] }, { "cell_type": "code", "execution_count": null, "metadata": {}, "outputs": [], "source": [ "def get_topk(probs):\n", " \"\"\"\n", " Apply Top-k sampling mask to probabilities vector probs\n", " \"\"\"\n", " # Apply topk mask\n", " topk = int(inference_cfg.threshold)\n", " _, top_idx = torch.topk(probs, topk)\n", " mask = torch.zeros_like(probs)\n", " mask[top_idx] = 1.0\n", " probs *= mask\n", " probs /= probs.sum()\n", " \n", "def get_topp(probs): \n", " \"\"\"\n", " Apply nucleus sampling mask to probabilities vector probs\n", " \"\"\"\n", " p = inference_cfg.threshold\n", " sorted_probs, sorted_indices = torch.sort(probs, descending=True)\n", "\n", " cumulative_probs = torch.cumsum(sorted_probs, dim=0)\n", "\n", " # Remove tokens with cumulative probability above the threshold\n", " sorted_indices_to_remove = cumulative_probs >= p\n", "\n", " # Shift the indices to the right to keep also the first token above the threshold\n", " sorted_indices_to_remove[1:] = sorted_indices_to_remove[:-1].clone()\n", " sorted_indices_to_remove[0] = 0\n", "\n", " # scatter sorted tensors to original indexing\n", " indices_to_remove = sorted_indices_to_remove.scatter(\n", " dim=0, index=sorted_indices, src=sorted_indices_to_remove\n", " )\n", " probs[indices_to_remove] = 0\n", " probs /= probs.sum()" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "#### Prepare model for inference" ] }, { "cell_type": "code", "execution_count": null, "metadata": {}, "outputs": [], "source": [ "transformerxl.eval()\n", "\n", "# Reset tgt_length to 1, so that 1 token is generated incrementally\n", "transformerxl.reset_length(1, inference_cfg.memory_length)" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "#### Define function to generate tokens incrementally" ] }, { "cell_type": "code", "execution_count": null, "metadata": {}, "outputs": [], "source": [ "def extend_melody():\n", " \"\"\"\n", " Loads the input melody specified by input_melody_path and returns\n", " the extended melody based on parameters specified in inference_cfg\n", " \n", " \"\"\"\n", " # Load input melody\n", " \n", " conditional_data = np.load(input_melody_path).tolist()\n", " print('Loaded conditional file {}'.format(input_melody_path))\n", " \n", " num_conditional_tokens = inference_cfg.num_conditional_tokens\n", "\n", " seq = [0]\n", " mems = None\n", " \n", " with torch.no_grad(): \n", " \n", " # Pass prefix through Transformer-XL\n", " context = np.array(seq + conditional_data[:num_conditional_tokens-1], dtype=np.int32)[:, np.newaxis]\n", " context = torch.from_numpy(context).to(device).type(torch.long)\n", " ret = transformerxl.forward_generate(context, mems)\n", " _, mems = ret\n", " seq = seq + conditional_data[:num_conditional_tokens]\n", "\n", " # Load generation length\n", " generation_length = inference_cfg.generation_length\n", " \n", " for _ in range(generation_length):\n", " \n", " # Create input array from last token\n", " inp = np.array([seq[-1]], dtype=np.int32)[:, np.newaxis]\n", " inp = torch.from_numpy(inp).to(device).type(torch.long)\n", " \n", " # Generate next token incrementally\n", " ret = transformerxl.forward_generate(inp, mems)\n", " all_logits, mems = ret\n", "\n", " # Select last tinmestep from the single batch item\n", " logits = all_logits[-1, 0]\n", "\n", " # Do not predict start token\n", " logits = logits[1:]\n", "\n", " # Handle temp 0 (argmax) case\n", " if inference_cfg.temperature == 0:\n", " probs = torch.zeros_like(logits)\n", " probs[logits.argmax()] = 1.0\n", " else:\n", " # Apply temperature normalization\n", " logits /= inference_cfg.temperature\n", "\n", " # Compute softmax\n", " probs = F.softmax(logits, dim=-1)\n", "\n", " probs = F.pad(probs, [1, 0])\n", "\n", " # Apply sampling masks\n", " if inference_cfg.technique == \"topk\":\n", " get_topk(probs)\n", " elif inference_cfg.technique == \"nucleus\":\n", " get_topp(probs)\n", " \n", " # Sample from probabilities\n", " token = torch.multinomial(probs, 1)\n", " token = int(token.item())\n", " \n", " # Add to output list\n", " seq.append(token)\n", "\n", " # Convert output list to numpy, ignore start token and return\n", " return np.asarray(seq[1:])" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "#### Run inference and save outputs" ] }, { "cell_type": "code", "execution_count": null, "metadata": {}, "outputs": [], "source": [ "# Run inference\n", "outputs = extend_melody()\n", "\n", "# Save numpy outputs\n", "output_dir = \"sample_outputs\"\n", "output_path = os.path.join(output_dir, \"sample_melody.npy\")\n", "np.save(output_path, outputs)" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "### Listen to your output\n", "\n", " You can listen to the extended melody.\n" ] }, { "cell_type": "code", "execution_count": null, "metadata": {}, "outputs": [], "source": [ "# Convert numpy to midi\n", "music_encoder.run_npy_to_midi(output_path, output_dir)" ] }, { "cell_type": "code", "execution_count": null, "metadata": {}, "outputs": [], "source": [ "# Play midi\n", "filename, _ = os.path.splitext(os.path.basename(output_path))\n", "midi_name = os.path.join(output_dir, filename + \".mid\")\n", "play_midi(midi_name)" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "## Cleaning up \n", "\n", "After completing this notebook, make sure that you stop your Amazon SageMaker notebook instance so that you don't incur unexpected costs. \n", "\n", "#### To stop an Amazon SageMaker notebook instance \n", "\n", "1. Open the [Amazon SageMaker console](https://console.aws.amazon.com/sagemaker/home?region=us-east-1#/dashboard).\n", "\n", "2. In the navigation pane, choose **Notebook instances**.\n", "\n", "3. Choose the notebook instance that you want to stop. \n", "\n", "4. From the **Actions** menu, choose **Stop**.\n", "\n", ">**NOTE**: When your notebook instance stops, its status changes from **In service** to **Stopped**. " ] }, { "cell_type": "markdown", "metadata": {}, "source": [ "# More info\n", "\n", "For more open-source implementations of generative models for music, see the following:\n", "\n", "- [Transformer-GAN](https://www.amazon.science/publications/symbolic-music-generation-with-transformer-gans): Trains the Transformer-XL in a GAN framework to generate music\n", "\n", "- [LakhNES](https://arxiv.org/abs/1907.04868): Transformer-XL to generate multi-instrumental scores from the NES-MDB dataset\n", "\n", "- [Pop music transformer](https://arxiv.org/abs/2002.00212): Transformer-XL to generate pop music by imposing a metrical structure\n", "\n", "- [Jukebox](https://openai.com/blog/jukebox/): Uses various neural nets to generate music, including rudimentary singing, as raw audio in a variety of genres and artist styles\n", "- [Music Transformer](https://github.com/tensorflow/magenta/tree/master/magenta/models/score2perf): Uses transformers to generate music\n", "- [MuseNet](https://openai.com/blog/musenet/): Uses GPT2, a large-scale Transformer model, to generate multi instrumental music\n", "\n" ] }, { "cell_type": "code", "execution_count": null, "metadata": {}, "outputs": [], "source": [] } ], "metadata": { "kernelspec": { "display_name": "Environment (conda_tensorflow_p36)", "language": "python", "name": "conda_tensorflow_p36" }, "language_info": { "codemirror_mode": { "name": "ipython", "version": 3 }, "file_extension": ".py", "mimetype": "text/x-python", "name": "python", "nbconvert_exporter": "python", "pygments_lexer": "ipython3", "version": "3.6.10" }, "pycharm": { "stem_cell": { "cell_type": "raw", "metadata": { "collapsed": false }, "source": [] } } }, "nbformat": 4, "nbformat_minor": 4 }