{
"cells": [
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
"\n",
"# Architect and Build a Music Recommender System across the Entire ML-Lifecycle with Amazon SageMaker\n",
"\n",
"## Overview\n",
"\n",
"----\n",
"\n",
"Welcome of the Music Recommender use-case with Amazon SageMaker. In this series of notebooks we will go through the ML Lifecycle and show how we can build a Music Recommender System using a combination of SageMaker Services and features. IN each phase, we will have relevant notebooks that show you how easy it is to implement that phase of the lifecycle.\n",
"\n",
"\n",
"----\n",
"\n",
"### Contents\n",
"\n",
"- [Overview](00_overview_arch_data.ipynb)\n",
" - [Architecture](#arch-overview)\n",
" - [Get the Data](#get-the-data)\n",
" - [Update the data sources](#update-data-sources)\n",
" - [Explore the Data](#explore-data)\n",
"- [Part 1: Data Prep using SageMaker Processing Job](01_music_rec_data_prep.ipynb)\n",
"- [Part 2: Model Training and Hyperparameter Tuning](02_music_rec_model_training.ipynb)\n",
"- [Part 3: SageMaker Pipelines](03_music_rec_pipelines.ipynb)\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
"\n",
"## Architecture\n",
"\n",
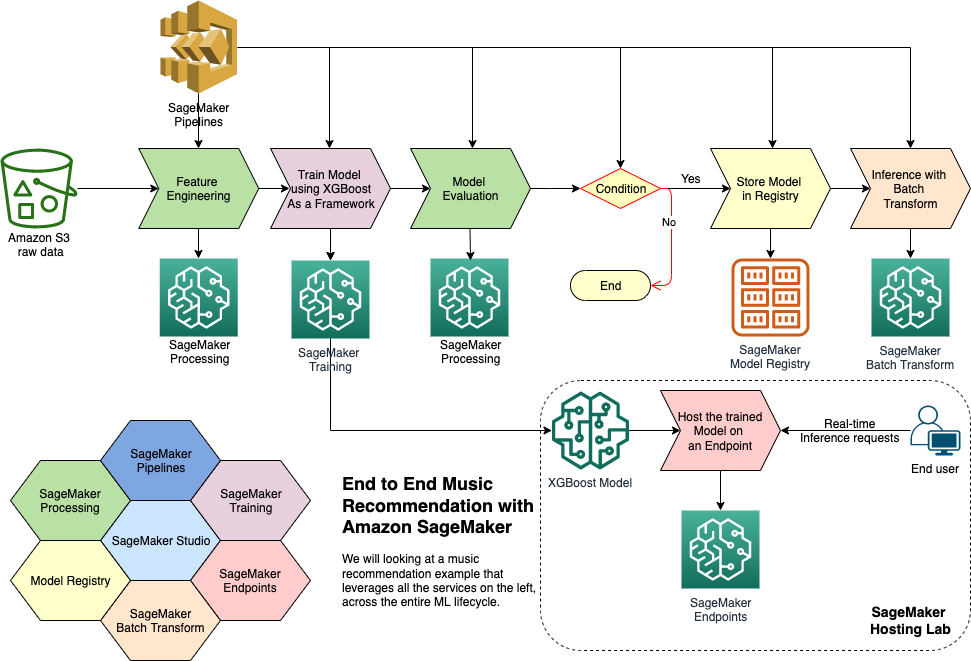
"Let's look at the overall solution architecure for this use case. We will start by doing each of these tasks within the exploratory phase of the ML Lifecycle, then when we are done with Experimentation and Trials, we can develop an automated pipeline such as the one depicted here to prepare data, train and tune the model, deposit it in the registry, then deploy it to a SageMaker hosted endpoint, and run batch transform based on the trained model.\n",
"\n",
"##### [back to top](#00-nb)\n",
"\n",
"----\n",
"\n",
""
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"import sys\n",
"import pprint\n",
"sys.path.insert(1, './code')\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# update pandas to avoid data type issues in older 1.0 version\n",
"!pip install pandas --upgrade --quiet\n",
"import pandas as pd\n",
"print(pd.__version__)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# create data folder\n",
"!mkdir data"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"import pandas as pd\n",
"import matplotlib.pyplot as plt\n",
"%matplotlib inline\n",
"\n",
"import json\n",
"import sagemaker \n",
"import boto3\n",
"import os\n",
"from awscli.customizations.s3.utils import split_s3_bucket_key\n",
"\n",
"# Sagemaker session\n",
"sess = sagemaker.Session()\n",
"# get session bucket name\n",
"bucket = sess.default_bucket()\n",
"# bucket prefix or the subfolder for everything we produce\n",
"prefix='music-recommendation-workshop'\n",
"# s3 client\n",
"s3_client = boto3.client(\"s3\")\n",
"\n",
"print(f\"this is your default SageMaker Studio bucket name: {bucket}\") "
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"def get_data(public_s3_data, to_bucket, sample_data=1):\n",
" new_paths = []\n",
" for f in public_s3_data:\n",
" bucket_name, key_name = split_s3_bucket_key(f)\n",
" filename = f.split('/')[-1]\n",
" new_path = \"s3://{}/{}/input/{}\".format(to_bucket, prefix, filename)\n",
" new_paths.append(new_path)\n",
" \n",
" # only download if not already downloaded\n",
" if not os.path.exists('./data/{}'.format(filename)):\n",
" # download s3 data\n",
" print(\"Downloading file from {}\".format(f))\n",
" s3_client.download_file(bucket_name, key_name, './data/{}'.format(filename))\n",
" \n",
" # subsample the data to create a smaller datatset for this demo\n",
" new_df = pd.read_csv('./data/{}'.format(filename))\n",
" new_df = new_df.sample(frac=sample_data)\n",
" new_df.to_csv('./data/{}'.format(filename), index=False)\n",
" \n",
" # upload s3 data to our default s3 bucket for SageMaker Studio\n",
" print(\"Uploading {} to {}\\n\".format(filename, new_path))\n",
" s3_client.upload_file('./data/{}'.format(filename), to_bucket, os.path.join(prefix, 'input', filename))\n",
" \n",
" return new_paths\n",
"\n",
"\n",
" \n",
"\n",
"def update_data_sources(flow_path, tracks_data_source, ratings_data_source):\n",
" with open(flow_path) as flowf:\n",
" flow = json.load(flowf)\n",
" \n",
" for node in flow['nodes']:\n",
" # if the key exists for our s3 endpoint\n",
" try:\n",
" if node['parameters']['dataset_definition']['name'] == 'tracks.csv':\n",
" # reset the s3 data source for tracks data\n",
" old_source = node['parameters']['dataset_definition']['s3ExecutionContext']['s3Uri']\n",
" print(\"Changed {} to {}\".format(old_source, tracks_data_source))\n",
" node['parameters']['dataset_definition']['s3ExecutionContext']['s3Uri'] = tracks_data_source\n",
" elif node['parameters']['dataset_definition']['name'] == 'ratings.csv':\n",
" # reset the s3 data source for ratings data\n",
" old_source = node['parameters']['dataset_definition']['s3ExecutionContext']['s3Uri']\n",
" print(\"Changed {} to {}\".format(old_source, ratings_data_source))\n",
" node['parameters']['dataset_definition']['s3ExecutionContext']['s3Uri'] = ratings_data_source\n",
" except:\n",
" continue\n",
" # write out the updated json flow file\n",
" with open(flow_path, 'w') as outfile:\n",
" json.dump(flow, outfile)\n",
" \n",
" return flow"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
"\n",
"## Prereqs: Get Data \n",
"\n",
"##### [back to top](#00-nb)\n",
"\n",
"----\n",
"\n",
"Here we will download the music data from a public S3 bucket that we'll be using for this demo and uploads it to your default S3 bucket that was created for you when you initially created a SageMaker Studio workspace. "
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# public S3 bucket that contains our music data\n",
"s3_bucket_music_data = \"s3://sagemaker-sample-files/datasets/tabular/synthetic-music\""
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"new_data_paths = get_data([f\"{s3_bucket_music_data}/tracks.csv\", f\"{s3_bucket_music_data}/ratings.csv\"], bucket, sample_data=0.70)\n",
"print(new_data_paths)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# these are the new file paths located on your SageMaker Studio default s3 storage bucket\n",
"tracks_data_source = f's3://{bucket}/{prefix}/input/tracks.csv'\n",
"ratings_data_source = f's3://{bucket}/{prefix}/input/ratings.csv'\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
"\n",
"## Explore the Data\n",
"\n",
"\n",
"##### [back to top](#00-nb)\n",
"\n",
"\n",
"----"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"tracks = pd.read_csv('./data/tracks.csv')\n",
"ratings = pd.read_csv('./data/ratings.csv')"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"tracks.head()"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"ratings.head()"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"print(\"{:,} different songs/tracks\".format(tracks['trackId'].nunique()))\n",
"print(\"{:,} users\".format(ratings['userId'].nunique()))\n",
"print(\"{:,} user rating events\".format(ratings['ratingEventId'].nunique()))"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"tracks.groupby('genre')['genre'].count().plot.bar(title=\"Tracks by Genre\");"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"ratings[['ratingEventId','userId']].plot.hist(by='userId', bins=50, title=\"Distribution of # of Ratings by User\");"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"----\n",
"\n",
"# Music Recommender Lab 1: Data Prep using SageMaker Processing\n",
"\n",
"After you completed running this notebook, you can open the next notebook."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": []
}
],
"metadata": {
"instance_type": "ml.t3.medium",
"kernelspec": {
"display_name": "Python 3 (Data Science)",
"language": "python",
"name": "python3__SAGEMAKER_INTERNAL__arn:aws:sagemaker:us-east-1:081325390199:image/datascience-1.0"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.7.10"
}
},
"nbformat": 4,
"nbformat_minor": 4
}