{
"cells": [
{
"cell_type": "markdown",
"id": "0b086e7b",
"metadata": {},
"source": [
"# Amazon SageMaker Neo でコンパイルしたモデルを AWS IoT Greengrass V2 を使ってデバイスにデプロイする\n",
"\n",
"このサンプルノートブックは、エッジ推論を行うために学習済みモデルを Amazon SageMaker Neo でコンパイルして AWS Iot Greengrass V2 を使ってデバイスにデプロイするパイプラインを AWS Step Functions を使って自動化する方法をご紹介します。このノートブックを Amazon SageMaker のノートブックインスタンスで使用する場合は、`conda_tensorflow_p36` のカーネルをご利用ください。\n",
"\n",
"このノートブックでは、デプロイしたいモデルや Greengrass アーティファクトファイルに関する情報を yaml 形式の設定ファイルで作成し、ワークフロー実行時にその設定ファイルを入力パラメタとすることで、以下のことを実現しています。\n",
"\n",
"- いつ何をどのデバイスにデプロイしたのかの記録(トレーサビリティ)\n",
"- 同じ設定ファイルを使用することで同じワークフローを実行可能(再現性)\n",
"\n",
"Python コードでワークフローを構築するために、AWS Step Functions Data Science SDK を使用します。詳しい情報は以下のドキュメントをご参照ください。\n",
"\n",
"- [AWS Step Functions](https://aws.amazon.com/step-functions/)\n",
"- [AWS Step Functions Developer Guide](https://docs.aws.amazon.com/step-functions/latest/dg/welcome.html)\n",
"- [AWS Step Functions Data Science SDK](https://aws-step-functions-data-science-sdk.readthedocs.io/)\n",
"\n",
"このノートブックの大まかな流れは以下の通りです。\n",
"\n",
"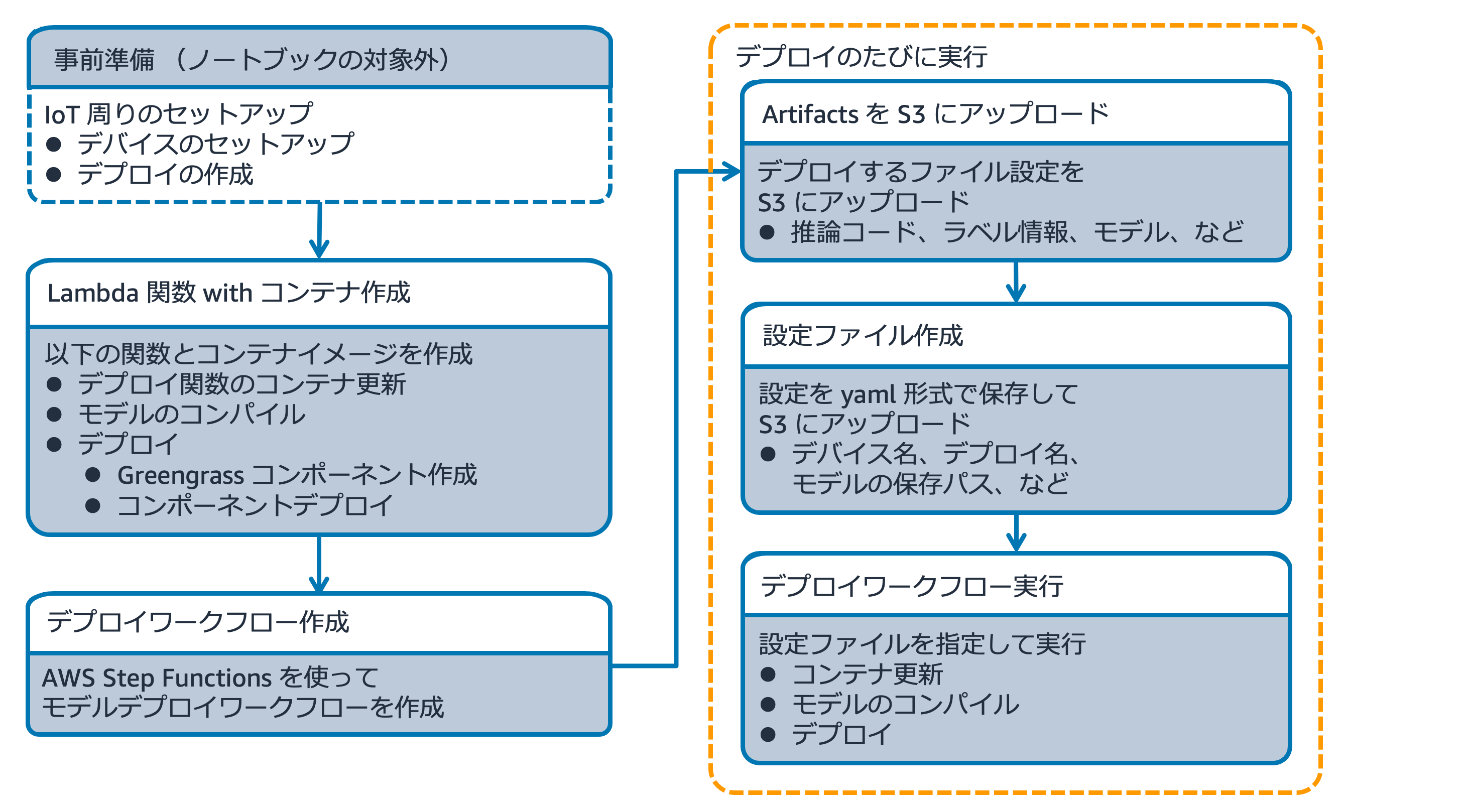\n",
"\n",
"1. 3つの Lambda 関数を作成\n",
" - デプロイしたいコンポーネントに対応するコンテナイメージをデプロイ用 Lambda 関数に適用する Lambda 関数\n",
" - 必要に応じて機械学習モデルを Amazon SageMaker Neo でコンパイルする Lambda 関数\n",
" - 指定されたアーティファクトをコンポーネント化して AWS IoT Greengrass デバイスにデプロイする Lambda 関数\n",
"1. 作成した Lambda 関数を順に実行するような AWS Step Functions Data Science SDK ワークフローを作成\n",
"1. デプロイに関する情報が記載された設定ファイルを作成\n",
"1. Step Functions ワークフローを実行してファイルをデバイスにデプロイ\n",
"1. デプロイ関連情報を一覧表示\n",
"1. リソースの削除\n",
"\n"
]
},
{
"cell_type": "markdown",
"id": "aa058f76",
"metadata": {
"toc": true
},
"source": [
"Table of Contents
\n",
""
]
},
{
"cell_type": "markdown",
"id": "7cbf6f9f",
"metadata": {},
"source": [
"## [事前準備] AWS IoT サービスとデバイス(AWS Cloud9)のセットアップ\n",
"\n",
"このノートブックでは、デバイスとして AWS Cloud9 を使用します。[こちらのワークショップコンテンツ](https://greengrassv2.workshop.aws/ja/) の、以下の部分を、このノートブックの実行を始める前に実施してください。\n",
"\n",
"1. 「1. GREENGRASSを動かす環境の用意」すべてを実施\n",
" - 「ディスク容量の拡張」の部分でディスク容量拡張コマンドを実行した際にエラーが出た場合、1、2分待ってから再度実行するとうまくいくことがあります\n",
"1. 「2. GREENGRASSのセットアップ」すべてを実施\n",
" - (同一アカウントの複数名で本ノートブックを実行する場合)「2.2 GREENGRASSのセットアップ」の初めにある「Greengrassコアデバイスのセットアップ」の手順を以下のとおり変更してください\n",
" - 「ステップ 1: Greengrass コアデバイスを登録する」のコアデバイスにご自身の名前など他のデバイスと区別可能な文字列を入れる\n",
" - 「ステップ 2: モノのグループに追加して継続的なデプロイを適用する」の「モノのグループ」で「グループなし」を選択する\n",
" - 「2.2 GREENGRASSのセットアップ」で環境変数を設定する手順では、ご自身の IAM ユーザの認証情報をご利用ください\n",
" - AWS マネジメントコンソールの左上にあるサービスの検索欄にIAMと入力し、IAM サービスを選択します\n",
" - IAM ダッシュボード画面にて、左のペインにあるユーザーをクリックします\n",
" - お客様が用いている IAM ユーザー名をクリックします (IAM アカウントが無い場合はこちらを参考に作成してください)\n",
" - ユーザー管理画面から認証情報タブを開きます\n",
" - アクセスキーの作成をクリックします\n",
" - アクセスキー ID とシークレットアクセスキーをコピーし、ローカルに保存します。こちらがお客様の IAM アカウントの認証情報です。\n",
"1. 「5.1 (CASE1) コンポーネントの作成とデプロイの準備」の「S3バケットの作成」までを実施\n",
" - 同一アカウントの複数名で本ノートブックを実行する場合、バケットをひとつのみ作成しそれを共有する形でも構いません\n",
"1. (追加手順)IAM のコンソールの左側のメニューから「アクセス管理」->「ロール」をクリックし、検索窓に「GreengrassV2TokenExchangeRole」と入力して「GreengrassV2TokenExchangeRole」を開く\n",
"1. (追加手順)「ポリシーをアタッチします」をクリックして `AmazonS3FullAccess` をアタッチ\n",
"---\n",
"\n",
"\n",
"## ノートブックインスタンスの IAM ロールに権限を追加\n",
"\n",
"以下の手順を実行して、ノートブックインスタンスに紐づけられた IAM ロールに、AWS Step Functions のワークフローを作成して実行するための権限と Amazon ECR にイメージを push するための権限を追加してください。\n",
"\n",
"1. [Amazon SageMaker console](https://console.aws.amazon.com/sagemaker/) を開く\n",
"1. **ノートブックインスタンス** を開いて現在使用しているノートブックインスタンスを選択する\n",
"1. **アクセス許可と暗号化** の部分に表示されている IAM ロールへのリンクをクリックする\n",
"1. IAM ロールの ARN は後で使用するのでメモ帳などにコピーしておく\n",
"1. **ポリシーをアタッチします** をクリックして `AWSStepFunctionsFullAccess` を検索する\n",
"1. `AWSStepFunctionsFullAccess` の横のチェックボックスをオンにする\n",
"1. 同様の手順で以下のポリシーのチェックボックスをオンにして **ポリシーのアタッチ** をクリックする\n",
" - `AmazonEC2ContainerRegistryFullAccess`\n",
" - `AWSGreengrassFullAccess`\n",
" - `AWSIoTFullAccess`\n",
" - `IAMFullAccess`\n",
" - `AWSLambda_FullAccess`\n",
"\n",
"もしこのノートブックを SageMaker のノートブックインスタンス以外で実行している場合、その環境で AWS CLI 設定を行ってください。詳細は [Configuring the AWS CLI](https://docs.aws.amazon.com/cli/latest/userguide/cli-chap-configure.html) をご参照ください。\n",
"\n",
"---\n",
"以下のセルの下から二番目の行の `` に事前準備で作成した S3 バケット名(ggv2-workshop-xxx)を記載してから実行してください。同一アカウントで複数人でこのノートブックを実行する場合は一番下の行の `user_name` を各自のお名前で置き換えてください。"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "46e4faa1",
"metadata": {},
"outputs": [],
"source": [
"import boto3\n",
"import yaml\n",
"import pandas as pd\n",
"from dateutil import tz\n",
"import sagemaker\n",
"import os\n",
"JST = tz.gettz('Asia/Tokyo')\n",
"\n",
"region = boto3.session.Session().region_name\n",
"s3_client = boto3.client('s3', region_name=region)\n",
"account_id = boto3.client('sts').get_caller_identity().get('Account')\n",
"ggv2_client = boto3.client('greengrassv2', region_name=region)\n",
"iot_client = boto3.client('iot', region_name=region)\n",
"lambda_client = boto3.client('lambda', region_name=region)\n",
"ecr_client = boto3.client('ecr', region_name=region)\n",
"s3 = boto3.resource('s3')\n",
"sagemaker_session = sagemaker.Session()\n",
"sagemaker_role = sagemaker.get_execution_role()\n",
"bucket_name = ''\n",
"user_name = 'sample'"
]
},
{
"cell_type": "markdown",
"id": "77381847",
"metadata": {},
"source": [
"## Lambda 関数が使用するコンテナイメージを作成\n",
"\n",
"ここからは、3つのコンテナイメージを作成していきます。\n",
"\n",
"それぞれの Lambda 関数では、デフォルトの Lambda 環境にないライブラリなどを使用するため、コンテナイメージごとソースコードを Lambda 関数にデプロイします。\n",
"\n",
"### コンテナイメージ更新用 Lambda 関数\n",
"\n",
"まずは、コンテナイメージ更新用 Lambda 関数が使用するコンテナイメージを作成します。この関数は、デプロイ用の Lambda 関数で使用するコンテナイメージを、ワークフロー実行時に設定したパラメタに応じて切り替えるためので、デプロイ用 Lambda 関数が使用するコンテナイメージを変えることのないユースケースであれば不要です。\n",
"\n",
"Dockerfile と、Lambda 内で動かすスクリプトファイルを作成します。"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "2ec2effe",
"metadata": {},
"outputs": [],
"source": [
"!mkdir -p docker/lambda-update/app"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "dbd0ac46",
"metadata": {},
"outputs": [],
"source": [
"%%writefile ./docker/lambda-update/Dockerfile\n",
"\n",
"FROM public.ecr.aws/lambda/python:3.8\n",
"\n",
"RUN pip3 install --upgrade pip\n",
"RUN pip3 install -qU boto3 pyyaml\n",
"\n",
"COPY app/app.py ./\n",
"CMD [\"app.handler\"] "
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "804ed089",
"metadata": {},
"outputs": [],
"source": [
"%%writefile ./docker/lambda-update/app/app.py\n",
"\n",
"import json\n",
"import boto3\n",
"import yaml\n",
"\n",
"def handler(event, context):\n",
" config_path = event['configPath']\n",
" bucket_name = config_path.split('/')[2]\n",
" object_key = config_path[len(bucket_name)+6:]\n",
" s3 = boto3.resource('s3')\n",
"\n",
" bucket = s3.Bucket(bucket_name)\n",
" obj = bucket.Object(object_key)\n",
"\n",
" response = obj.get() \n",
" body = response['Body'].read()\n",
" \n",
" config = yaml.safe_load(body)\n",
" \n",
" container_image = config['lambda-container']\n",
" function_name = config['lambda-deploy-function']\n",
" \n",
" lambda_client = boto3.client('lambda')\n",
" \n",
" response = lambda_client.update_function_code(\n",
" FunctionName=function_name,\n",
" ImageUri=container_image\n",
" )\n",
" return {\n",
" 'statusCode': 200,\n",
" 'configPath': config_path,\n",
" 'response': response\n",
" }"
]
},
{
"cell_type": "markdown",
"id": "96cd9b6f",
"metadata": {},
"source": [
"必要なファイルを作成できたので、コンテナイメージをビルドして Amazon ECR にプッシュします。"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "7d2a4b70",
"metadata": {
"scrolled": true
},
"outputs": [],
"source": [
"import datetime\n",
"\n",
"ecr_repository_lambda_update = 'lambda-update-continer-' + user_name\n",
"uri_suffix = 'amazonaws.com'\n",
"\n",
"tag = ':' + datetime.datetime.now(datetime.timezone(datetime.timedelta(hours=9))).strftime('%Y%m%d-%H%M%S')\n",
"lambda_update_repository_uri = '{}.dkr.ecr.{}.{}/{}'.format(account_id, region, uri_suffix, ecr_repository_lambda_update + tag)\n",
"print(lambda_update_repository_uri)\n",
"\n",
"# Create ECR repository and push docker image\n",
"!docker build -t {ecr_repository_lambda_update + tag} docker/lambda-update\n",
"!aws ecr get-login-password --region {region} | docker login --username AWS --password-stdin {account_id}.dkr.ecr.{region}.amazonaws.com\n",
"!aws ecr create-repository --repository-name $ecr_repository_lambda_update\n",
"!docker tag {ecr_repository_lambda_update + tag} $lambda_update_repository_uri\n",
"!docker push $lambda_update_repository_uri"
]
},
{
"cell_type": "markdown",
"id": "15cf8717",
"metadata": {},
"source": [
"### モデルコンパイル用 Lambda 関数\n",
"\n",
"次に、学習済みモデルを Amazon SageMaker Neo でコンパイルする Lambda 関数用のコンテナイメージを作成します。流れは先ほどと同様です。"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "23385a9e",
"metadata": {},
"outputs": [],
"source": [
"!mkdir -p docker/lambda-compile/app"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "89ab6208",
"metadata": {},
"outputs": [],
"source": [
"%%writefile ./docker/lambda-compile/Dockerfile\n",
"\n",
"FROM public.ecr.aws/lambda/python:3.8\n",
"\n",
"RUN pip3 install --upgrade pip\n",
"RUN pip3 install -qU boto3 pyyaml\n",
"\n",
"COPY app/app.py ./\n",
"CMD [\"app.handler\"] "
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "8e0b333f",
"metadata": {},
"outputs": [],
"source": [
"%%writefile ./docker/lambda-compile/app/app.py\n",
"\n",
"import json\n",
"import boto3\n",
"import yaml\n",
"import datetime\n",
"import time\n",
"import os\n",
"\n",
"def handler(event, context):\n",
" print(event)\n",
" config_path = event['configPath']\n",
" \n",
" bucket_name = config_path.split('/')[2]\n",
" object_key = config_path[len(bucket_name)+6:]\n",
" s3 = boto3.resource('s3')\n",
" region = boto3.session.Session().region_name\n",
" sagemaker_client = boto3.client('sagemaker', region_name=region)\n",
" lambda_client = boto3.client('lambda')\n",
"\n",
" bucket = s3.Bucket(bucket_name)\n",
" obj = bucket.Object(object_key)\n",
"\n",
" response = obj.get() \n",
" body = response['Body'].read()\n",
" \n",
" config = yaml.safe_load(body)\n",
" \n",
" if config['model-information']['compile-model']:\n",
" \n",
" framework = config['model-information']['framework']\n",
"\n",
" timestamp = datetime.datetime.now(datetime.timezone(datetime.timedelta(hours=9))).strftime('%Y%m%d-%H%M%S')\n",
" job_name = framework + '-compile-' + timestamp\n",
" model_s3_path = config['model-information']['original-model-path']\n",
" input_name = config['model-information']['input-name']\n",
" input_shape = config['model-information']['input-shape']\n",
" output_location = config['model-information']['compiled-model-path']\n",
" target_device = config['model-information']['target-device']\n",
"\n",
" response = lambda_client.get_function(\n",
" FunctionName=os.environ['AWS_LAMBDA_FUNCTION_NAME']\n",
" )\n",
" role = response['Configuration']['Role']\n",
" data_input_config = '{\"' + input_name + '\":'+input_shape + '}'\n",
"\n",
" response = sagemaker_client.create_compilation_job(\n",
" CompilationJobName=job_name,\n",
" RoleArn=role,\n",
" InputConfig={\n",
" 'S3Uri': model_s3_path,\n",
" 'DataInputConfig':data_input_config,\n",
" 'Framework': framework\n",
" },\n",
" OutputConfig={\n",
" 'S3OutputLocation': output_location,\n",
" 'TargetDevice':target_device\n",
" },\n",
" StoppingCondition={ 'MaxRuntimeInSeconds': 9000 } \n",
" )\n",
" \n",
" time.sleep(60)\n",
" return {\n",
" 'statusCode': 200,\n",
" 'configPath': config_path,\n",
" 'compileJobName': job_name,\n",
" 'response': response\n",
" }\n",
" else:\n",
" return {\n",
" 'statusCode': 200,\n",
" 'configPath': config_path\n",
" }"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "78e35488",
"metadata": {
"scrolled": true
},
"outputs": [],
"source": [
"import datetime\n",
"\n",
"ecr_repository_lambda_compile = 'lambda-compile-model-' + user_name\n",
"uri_suffix = 'amazonaws.com'\n",
"\n",
"tag = ':' + datetime.datetime.now(datetime.timezone(datetime.timedelta(hours=9))).strftime('%Y%m%d-%H%M%S')\n",
"lambda_compile_repository_uri = '{}.dkr.ecr.{}.{}/{}'.format(account_id, region, uri_suffix, ecr_repository_lambda_compile + tag)\n",
"print(lambda_compile_repository_uri)\n",
"\n",
"# Create ECR repository and push docker image\n",
"!docker build -t {ecr_repository_lambda_compile + tag} docker/lambda-compile\n",
"!$(aws ecr get-login --region $region --registry-ids $account_id --no-include-email)\n",
"!aws ecr create-repository --repository-name $ecr_repository_lambda_compile\n",
"!docker tag {ecr_repository_lambda_compile + tag} $lambda_compile_repository_uri\n",
"!docker push $lambda_compile_repository_uri"
]
},
{
"cell_type": "markdown",
"id": "836392d2",
"metadata": {},
"source": [
"### デプロイ用 Lambda 関数\n",
"\n",
"最後に、デプロイ用 Lambda 関数が使用するコンテナイメージを作成します。"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "10500e80",
"metadata": {},
"outputs": [],
"source": [
"!mkdir -p docker/lambda/app"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "2fac2070",
"metadata": {},
"outputs": [],
"source": [
"%%writefile ./docker/lambda/Dockerfile\n",
"\n",
"FROM public.ecr.aws/lambda/python:3.8\n",
"\n",
"RUN pip3 install --upgrade pip\n",
"RUN pip3 install -qU boto3 pyyaml\n",
"\n",
"COPY app/app.py ./\n",
"CMD [\"app.handler\"] "
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "cde992a5",
"metadata": {},
"outputs": [],
"source": [
"%%writefile ./docker/lambda/app/app.py\n",
"\n",
"import json\n",
"import boto3\n",
"import yaml\n",
"import os\n",
"import time\n",
"\n",
"region = boto3.session.Session().region_name\n",
"sagemaker_client = boto3.client('sagemaker', region_name=region)\n",
"ggv2_client = boto3.client('greengrassv2', region_name=region)\n",
" \n",
"def generate_recipe(artifact_files, component_name, component_version, \n",
" model_name, entrypoint_script_name, pip_libraries, model_input_shape):\n",
" # create artifact list\n",
" artifacts = ''\n",
" for f in artifact_files:\n",
" artifacts += f' - URI: {f}\\n'\n",
"\n",
" # define recipe\n",
" artifacts_path = '{artifacts:path}'\n",
" recipe = f\"\"\"---\n",
"RecipeFormatVersion: '2020-01-25'\n",
"ComponentName: {component_name}\n",
"ComponentVersion: {component_version}\n",
"ComponentType: \"aws.greengrass.generic\"\n",
"ComponentDescription: Publish MQTT message to AWS IoT Core in Docker image.\n",
"ComponentPublisher: Amazon\n",
"ComponentConfiguration:\n",
" DefaultConfiguration:\n",
" accessControl:\n",
" aws.greengrass.ipc.pubsub:\n",
" com.example.Publisher:pubsub:1:\n",
" policyDescription: \"Allows access to publish to all topics.\"\n",
" operations:\n",
" - \"aws.greengrass#PublishToTopic\"\n",
" resources:\n",
" - \"*\"\n",
"Manifests:\n",
" - Platform:\n",
" os: \"linux\"\n",
" architecture: \"amd64\"\n",
" Name: \"Linux\"\n",
" Lifecycle:\n",
" Install:\n",
" RequiresPrivilege: true\n",
" Script: \"pip3 install --upgrade pip\\\\n\\\n",
" pip3 install {pip_libraries}\\\\n\\\n",
" pip3 install awsiotsdk numpy\\\\n\\\n",
" apt-get install -y libgl1-mesa-dev\\\\n\\\n",
" mkdir {artifacts_path}/model\\\\n\\\n",
" tar xf {artifacts_path}/{model_name} -C {artifacts_path}/model\"\n",
" Run: \"python3 {artifacts_path}/{entrypoint_script_name} {artifacts_path} '{model_input_shape}'\"\n",
" Artifacts:\n",
"{artifacts}\n",
" \"\"\"\n",
" return recipe\n",
"\n",
"def deploy_component(target_arn, deployment_name, components):\n",
" response = ggv2_client.create_deployment(\n",
" targetArn=target_arn, # デプロイ先のIoT thing か group\n",
" deploymentName=deployment_name, # デプロイの名前\n",
" components=components,\n",
" iotJobConfiguration={\n",
" 'timeoutConfig': {'inProgressTimeoutInMinutes': 600}\n",
" },\n",
" deploymentPolicies={\n",
" 'failureHandlingPolicy': 'ROLLBACK',\n",
" 'componentUpdatePolicy': {\n",
" 'timeoutInSeconds': 600,\n",
" 'action': 'NOTIFY_COMPONENTS'\n",
" },\n",
" 'configurationValidationPolicy': {\n",
" 'timeoutInSeconds': 600\n",
" }\n",
" },\n",
" tags={\n",
" 'Name': deployment_name\n",
" }\n",
" )\n",
" return response\n",
"\n",
"def get_deployment_info(deployment_name):\n",
" deployments = ggv2_client.list_deployments()['deployments']\n",
"\n",
" deployment_id = ''\n",
" group_id = ''\n",
" for d in deployments:\n",
" if d['deploymentName'] == deployment_name:\n",
" deployment_id = d['deploymentId']\n",
" group_arn = d['targetArn']\n",
" return deployment_id, group_arn\n",
" \n",
" return -1, -1\n",
"\n",
"def run_deployment(group_arn, deployment_name, component_name, component_version):\n",
" components={\n",
" component_name: { # コンポーネントの名前\n",
" 'componentVersion': component_version,\n",
" 'runWith': {\n",
" 'posixUser': 'root'\n",
" }\n",
" },\n",
" # 'aws.greengrass.Cli': { # コンポーネントの名前\n",
" # 'componentVersion': '2.3.0',\n",
" # },\n",
"\n",
" }\n",
"\n",
" response = deploy_component(group_arn, deployment_name, components)\n",
" \n",
" return response\n",
"\n",
"def handler(event, context):\n",
" print(event)\n",
" config_path = event['Payload']['Payload']['configPath']\n",
" bucket_name = config_path.split('/')[2]\n",
" object_key = config_path[len(bucket_name)+6:]\n",
" s3 = boto3.resource('s3')\n",
"\n",
" bucket = s3.Bucket(bucket_name)\n",
" obj = bucket.Object(object_key)\n",
"\n",
" response = obj.get() \n",
" body = response['Body'].read()\n",
" \n",
" config = yaml.safe_load(body)\n",
" \n",
" component_name = config['component-name']\n",
" component_version = config['component-version']\n",
" deployment_name = config['deployment-name']\n",
" entrypoint_script_name = config['entrypoint-script-name']\n",
" pip_libraries = config['pip-libraries']\n",
" model_path = config['model-information']['original-model-path']\n",
" compile_model = config['model-information']['compile-model']\n",
" artifact_files = config['artifact-files']\n",
" \n",
" if compile_model:\n",
" compile_job_name = event['Payload']['Payload']['compileJobName']\n",
" print(compile_job_name)\n",
"\n",
" while True:\n",
" status = sagemaker_client.describe_compilation_job(CompilationJobName=compile_job_name)['CompilationJobStatus']\n",
" if status == 'COMPLETED' or status == 'FAILED':\n",
" print(status)\n",
" break\n",
" time.sleep(30)\n",
" \n",
" model_path = sagemaker_client.describe_compilation_job(CompilationJobName=compile_job_name)['ModelArtifacts']['S3ModelArtifacts']\n",
" \n",
" model_name = os.path.basename(model_path)\n",
" artifact_files.append(model_path)\n",
" recipe = generate_recipe(artifact_files, component_name, component_version,\n",
" model_name, entrypoint_script_name, pip_libraries, config['model-information']['input-shape'])\n",
" print(recipe)\n",
" print(type(recipe.encode()))\n",
" \n",
" # コンポーネント作成\n",
" response = ggv2_client.create_component_version(\n",
" inlineRecipe=recipe.encode('utf-8')\n",
" )\n",
" component_vesrion_arn = response['arn']\n",
" \n",
" deployment_id, group_arn = get_deployment_info(deployment_name)\n",
"\n",
" response = run_deployment(group_arn, deployment_name, component_name, component_version)\n",
"\n",
" return {\n",
" 'statusCode' : 200,\n",
" 'component-name': component_name,\n",
" 'response': response\n",
" }"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "28965c0f",
"metadata": {
"scrolled": true
},
"outputs": [],
"source": [
"import datetime\n",
"\n",
"ecr_repository_lambda_deploy = 'lambda-deploy-gg-' + user_name\n",
"uri_suffix = 'amazonaws.com'\n",
"\n",
"deploy_lambda_container_tag = ':' + datetime.datetime.now(datetime.timezone(datetime.timedelta(hours=9))).strftime('%Y%m%d-%H%M%S')\n",
"lambda_deploy_repository_uri = '{}.dkr.ecr.{}.{}/{}'.format(account_id, region, uri_suffix, ecr_repository_lambda_deploy + deploy_lambda_container_tag)\n",
"print(lambda_deploy_repository_uri)\n",
"\n",
"# Create ECR repository and push docker image\n",
"!docker build -t {ecr_repository_lambda_deploy + deploy_lambda_container_tag} docker/lambda\n",
"!aws ecr get-login-password --region {region} | docker login --username AWS --password-stdin {account_id}.dkr.ecr.{region}.amazonaws.com\n",
"!aws ecr create-repository --repository-name $ecr_repository_lambda_deploy\n",
"!docker tag {ecr_repository_lambda_deploy + deploy_lambda_container_tag} $lambda_deploy_repository_uri\n",
"!docker push $lambda_deploy_repository_uri"
]
},
{
"cell_type": "markdown",
"id": "ac602f42",
"metadata": {},
"source": [
"## Lambda 関数の作成と権限の設定\n",
"\n",
"コンテナ更新用 (update-container)、モデルコンパイル用 (compile-model)、コンポーネントのデプロイ用 (deploy-components-to-device) の Lambda 関数をそれぞれ作成します。下にある2つのセルでは、関数の作成と以下の操作を API を使って行なっています。\n",
"\n",
"### タイムアウト時間の設定\n",
"\n",
"全ての処理が終わるまで関数がタイムアウトしないように、それぞれの関数のタイムアウト時間をすべて 5分に設定します。\n",
"\n",
"### アクセス権限の設定\n",
"\n",
"それぞれの関数の権限を以下のように設定します。
**今回は AmazonS3FullAccess など強い権限を付与していますが、実際の環境で使用する場合は必要最小限の権限のみを追加するようにしてください。**\n",
"\n",
"**update-container 関数**\n",
"- ロールに以下のポリシーを追加\n",
" - AmazonS3FullAccess\n",
" - AWSLambda_FullAccess\n",
" \n",
"**compile-model 関数**\n",
"- ロールに以下のポリシーを追加\n",
" - AmazonS3FullAccess\n",
" - AWSLambda_FullAccess\n",
" - AmazonSageMakerFullAccess\n",
"- 「信頼関係」に以下を設定\n",
"```\n",
"\"Service\": [\n",
" \"sagemaker.amazonaws.com\",\n",
" \"lambda.amazonaws.com\"\n",
" ]\n",
"```\n",
"\n",
"\n",
"**deploy-components-to-device 関数**\n",
"- ロールに以下のポリシーを追加\n",
" - AmazonS3FullAccess\n",
" - AmazonSageMakerFullAccess\n",
" - AWSIoTFullAccess\n",
" - AWSGreengrassFullAccess\n",
"- 「信頼関係」に以下を設定\n",
"```\n",
"\"Service\": [\n",
" \"sagemaker.amazonaws.com\",\n",
" \"lambda.amazonaws.com\"\n",
" ]\n",
"```\n",
"\n",
"---"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "a2c1e076",
"metadata": {},
"outputs": [],
"source": [
"import boto3\n",
"import json\n",
"from datetime import datetime\n",
"from dateutil import tz\n",
"from time import sleep\n",
"JST = tz.gettz('Asia/Tokyo')\n",
"\n",
"\n",
"iam_client = boto3.client('iam')\n",
"\n",
"def create_container_lambda_function(function_name, image_uri, policy_list, trust_service_list=[]):\n",
"\n",
" timestamp = datetime.now(tz=JST).strftime('%Y%m%d-%H%M%S')\n",
" lambda_function_name = function_name\n",
" lambda_inference_policy_name = lambda_function_name + '-policy-'+timestamp\n",
" lambda_inference_role_name = lambda_function_name + '-role-'+timestamp\n",
"\n",
" inline_policy = {\n",
" 'Version': '2012-10-17',\n",
" 'Statement': [\n",
" {\n",
" 'Effect': 'Allow',\n",
" 'Action': 'logs:CreateLogGroup',\n",
" 'Resource': f'arn:aws:logs:{region}:{account_id}:*'\n",
" },\n",
" {\n",
" 'Effect': 'Allow',\n",
" 'Action': [\n",
" 'logs:CreateLogStream',\n",
" 'logs:PutLogEvents'\n",
" ],\n",
" 'Resource': [\n",
" f'arn:aws:logs:{region}:{account_id}:log-group:/aws/lambda/{lambda_function_name}:*'\n",
" ]\n",
" }\n",
" ]\n",
" }\n",
"\n",
" response = iam_client.create_policy(\n",
" PolicyName=lambda_inference_policy_name,\n",
" PolicyDocument=json.dumps(inline_policy),\n",
" )\n",
"\n",
" policy_arn = response['Policy']['Arn']\n",
"\n",
" service_list = [\"lambda.amazonaws.com\"]\n",
" for t in trust_service_list:\n",
" service_list.append(t)\n",
" \n",
" assume_role_policy = {\n",
" \"Version\": \"2012-10-17\",\n",
" \"Statement\": [{\"Sid\": \"\",\"Effect\": \"Allow\",\"Principal\": {\"Service\":service_list},\"Action\": \"sts:AssumeRole\"}]\n",
" }\n",
" response = iam_client.create_role(\n",
" Path = '/service-role/',\n",
" RoleName = lambda_inference_role_name,\n",
" AssumeRolePolicyDocument = json.dumps(assume_role_policy),\n",
" MaxSessionDuration=3600*12 # 12 hours\n",
" )\n",
" \n",
" lambda_role_arn = response['Role']['Arn']\n",
" lambda_role_name = response['Role']['RoleName']\n",
" \n",
" response = iam_client.attach_role_policy(\n",
" RoleName=lambda_inference_role_name,\n",
" PolicyArn=policy_arn\n",
" )\n",
" \n",
" for p in policy_list:\n",
" arn = 'arn:aws:iam::aws:policy/' + p\n",
" response = iam_client.attach_role_policy(\n",
" RoleName=lambda_inference_role_name,\n",
" PolicyArn=arn\n",
" )\n",
" \n",
" sleep(20) # wait until IAM is created\n",
" \n",
" response = lambda_client.create_function(\n",
" FunctionName=function_name,\n",
" Role=lambda_role_arn,\n",
" Code={\n",
" 'ImageUri':image_uri\n",
" },\n",
" Timeout=60*5, # 5 minutes\n",
" MemorySize=128, # 128 MB\n",
" Publish=True,\n",
" PackageType='Image',\n",
" )\n",
" \n",
" return lambda_role_name, policy_arn"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "7518653f",
"metadata": {},
"outputs": [],
"source": [
"lambda_policies = []\n",
"lambda_roles = []\n",
"\n",
"lambda_function_name_update = 'update-container-' + user_name\n",
"policy_list = ['AmazonS3FullAccess', 'AWSLambda_FullAccess']\n",
"r, p = create_container_lambda_function(lambda_function_name_update, lambda_update_repository_uri, policy_list)\n",
"lambda_policies.append(p)\n",
"lambda_roles.append(r)\n",
"\n",
"lambda_function_name_compile = 'compile-model-' + user_name\n",
"policy_list = ['AmazonS3FullAccess', 'AWSLambda_FullAccess', 'AmazonSageMakerFullAccess']\n",
"trust_list = [\"sagemaker.amazonaws.com\"]\n",
"r, p = create_container_lambda_function(lambda_function_name_compile, lambda_compile_repository_uri, policy_list, trust_list)\n",
"lambda_policies.append(p)\n",
"lambda_roles.append(r)\n",
"\n",
"lambda_function_name_deploy = 'deploy-components-to-device-' + user_name\n",
"policy_list = ['AmazonS3FullAccess', 'AWSIoTFullAccess', 'AmazonSageMakerFullAccess', 'AWSGreengrassFullAccess']\n",
"r, p = create_container_lambda_function(lambda_function_name_deploy, lambda_deploy_repository_uri, policy_list, trust_list)\n",
"lambda_policies.append(p)\n",
"lambda_roles.append(r)"
]
},
{
"cell_type": "markdown",
"id": "7a32c258",
"metadata": {},
"source": [
"## Step Functions Data Science SDK でワークフローを作成\n",
"\n",
"Step Functions で使用する実行ロールを作成します。\n",
"\n",
"### Step Functions の実行ロールの作成\n",
"\n",
" 作成した Step Functions ワークフローは、AWS の他のサービスと連携するための IAM ロールを必要とします。以下のセルを実行して、必要な権限を持つ IAM Policy を作成し、それを新たに作成した IAM Role にアタッチします。\n",
" \n",
"なお、今回は広めの権限を持つ IAM Policy を作成しますが、ベストプラクティスとしては必要なリソースのアクセス権限と必要なアクションのみを有効にします。"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "f2567d15",
"metadata": {},
"outputs": [],
"source": [
"step_functions_policy_name = 'AmazonSageMaker-StepFunctionsWorkflowExecutionPolicy-' + user_name\n",
"inline_policy ={\n",
" \"Version\": \"2012-10-17\",\n",
" \"Statement\": [\n",
" {\n",
" \"Sid\": \"VisualEditor0\",\n",
" \"Effect\": \"Allow\",\n",
" \"Action\": [\n",
" \"events:PutTargets\",\n",
" \"events:DescribeRule\",\n",
" \"events:PutRule\"\n",
" ],\n",
" \"Resource\": [\n",
" \"arn:aws:events:*:*:rule/StepFunctionsGetEventsForSageMakerTrainingJobsRule\",\n",
" \"arn:aws:events:*:*:rule/StepFunctionsGetEventsForSageMakerTransformJobsRule\",\n",
" \"arn:aws:events:*:*:rule/StepFunctionsGetEventsForSageMakerTuningJobsRule\",\n",
" \"arn:aws:events:*:*:rule/StepFunctionsGetEventsForECSTaskRule\",\n",
" \"arn:aws:events:*:*:rule/StepFunctionsGetEventsForBatchJobsRule\"\n",
" ]\n",
" },\n",
" {\n",
" \"Sid\": \"VisualEditor1\",\n",
" \"Effect\": \"Allow\",\n",
" \"Action\": \"iam:PassRole\",\n",
" \"Resource\": sagemaker_role,\n",
" \"Condition\": {\n",
" \"StringEquals\": {\n",
" \"iam:PassedToService\": \"sagemaker.amazonaws.com\"\n",
" }\n",
" }\n",
" },\n",
" {\n",
" \"Sid\": \"VisualEditor2\",\n",
" \"Effect\": \"Allow\",\n",
" \"Action\": [\n",
" \"batch:DescribeJobs\",\n",
" \"batch:SubmitJob\",\n",
" \"batch:TerminateJob\",\n",
" \"dynamodb:DeleteItem\",\n",
" \"dynamodb:GetItem\",\n",
" \"dynamodb:PutItem\",\n",
" \"dynamodb:UpdateItem\",\n",
" \"ecs:DescribeTasks\",\n",
" \"ecs:RunTask\",\n",
" \"ecs:StopTask\",\n",
" \"glue:BatchStopJobRun\",\n",
" \"glue:GetJobRun\",\n",
" \"glue:GetJobRuns\",\n",
" \"glue:StartJobRun\",\n",
" \"lambda:InvokeFunction\",\n",
" \"sagemaker:CreateEndpoint\",\n",
" \"sagemaker:CreateEndpointConfig\",\n",
" \"sagemaker:CreateHyperParameterTuningJob\",\n",
" \"sagemaker:CreateModel\",\n",
" \"sagemaker:CreateProcessingJob\",\n",
" \"sagemaker:CreateTrainingJob\",\n",
" \"sagemaker:CreateTransformJob\",\n",
" \"sagemaker:DeleteEndpoint\",\n",
" \"sagemaker:DeleteEndpointConfig\",\n",
" \"sagemaker:DescribeHyperParameterTuningJob\",\n",
" \"sagemaker:DescribeProcessingJob\",\n",
" \"sagemaker:DescribeTrainingJob\",\n",
" \"sagemaker:DescribeTransformJob\",\n",
" \"sagemaker:ListProcessingJobs\",\n",
" \"sagemaker:ListTags\",\n",
" \"sagemaker:StopHyperParameterTuningJob\",\n",
" \"sagemaker:StopProcessingJob\",\n",
" \"sagemaker:StopTrainingJob\",\n",
" \"sagemaker:StopTransformJob\",\n",
" \"sagemaker:UpdateEndpoint\",\n",
" \"sns:Publish\",\n",
" \"sqs:SendMessage\"\n",
" ],\n",
" \"Resource\": \"*\"\n",
" }\n",
" ]\n",
"}\n",
"\n",
"response = iam_client.create_policy(\n",
" PolicyName=step_functions_policy_name,\n",
" PolicyDocument=json.dumps(inline_policy),\n",
")\n",
"\n",
"step_functions_policy_arn = response['Policy']['Arn']"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "18dae92e",
"metadata": {},
"outputs": [],
"source": [
"step_functions_role_name = 'AmazonSageMaker-StepFunctionsWorkflowExecutionRole-' + user_name\n",
"assume_role_policy = {\n",
" \"Version\": \"2012-10-17\",\n",
" \"Statement\": [{\"Sid\": \"\",\"Effect\": \"Allow\",\"Principal\": {\"Service\":\"states.amazonaws.com\"},\"Action\": \"sts:AssumeRole\"}]\n",
" }\n",
"response = iam_client.create_role(\n",
" Path = '/service-role/',\n",
" RoleName = step_functions_role_name,\n",
" AssumeRolePolicyDocument = json.dumps(assume_role_policy),\n",
" MaxSessionDuration=3600*12 # 12 hours\n",
")\n",
"\n",
"step_functions_role_arn = response['Role']['Arn']\n",
"\n",
"response = iam_client.attach_role_policy(\n",
" RoleName=step_functions_role_name,\n",
" PolicyArn=step_functions_policy_arn\n",
")\n",
"\n",
"response = iam_client.attach_role_policy(\n",
" RoleName=step_functions_role_name,\n",
" PolicyArn='arn:aws:iam::aws:policy/CloudWatchEventsFullAccess'\n",
")\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "2f36ca25",
"metadata": {},
"outputs": [],
"source": [
"workflow_execution_role = step_functions_role_arn"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "083bbfbf",
"metadata": {},
"outputs": [],
"source": [
"import sys\n",
"!{sys.executable} -m pip install -qU \"stepfunctions==2.1.0\""
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "92d660a5",
"metadata": {},
"outputs": [],
"source": [
"import stepfunctions\n",
"from stepfunctions import steps\n",
"from stepfunctions.inputs import ExecutionInput\n",
"from stepfunctions.steps import (\n",
" Chain,\n",
" ChoiceRule,\n",
" ModelStep,\n",
" ProcessingStep,\n",
" TrainingStep,\n",
" TransformStep,\n",
")\n",
"# from stepfunctions.template import TrainingPipeline\n",
"from stepfunctions.template.utils import replace_parameters_with_jsonpath\n",
"from stepfunctions.workflow import Workflow"
]
},
{
"cell_type": "markdown",
"id": "554e3eec",
"metadata": {},
"source": [
"### AWS Step Functions ワークフローの作成\n",
"\n",
"まずは、AWS Step Functions ワークフロー実行時に指定するパラメタの定義をします。"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "ff057278",
"metadata": {},
"outputs": [],
"source": [
"execution_input = ExecutionInput(\n",
" schema={\n",
" \"ConfigFilePath\": str,\n",
" }\n",
")"
]
},
{
"cell_type": "markdown",
"id": "0a44dae6",
"metadata": {},
"source": [
"ここからは、先ほど作成した 3つの Lambda 関数を順に実行するようなワークフローを作成していきます。"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "c9f495ba",
"metadata": {},
"outputs": [],
"source": [
"from stepfunctions.steps.states import Retry\n",
"lambda_update_step = stepfunctions.steps.compute.LambdaStep(\n",
" \"Update Container Image\",\n",
" parameters={\n",
" \"FunctionName\": lambda_function_name_update,\n",
" \"Payload\": {\n",
" \"configPath\": execution_input[\"ConfigFilePath\"],\n",
" },\n",
" },\n",
")\n",
"\n",
"lambda_compile_step = stepfunctions.steps.compute.LambdaStep(\n",
" \"Compile Model\",\n",
" parameters={\n",
" \"FunctionName\": lambda_function_name_compile,\n",
" \"Payload\": {\n",
" \"configPath\": execution_input[\"ConfigFilePath\"],\n",
" },\n",
" },\n",
")\n",
"\n",
"lambda_deploy_step = stepfunctions.steps.compute.LambdaStep(\n",
" \"Deploy components\",\n",
" parameters={\n",
" \"FunctionName\": lambda_function_name_deploy,\n",
" \"Payload\": {\n",
" \"Payload.$\": \"$\"\n",
" },\n",
" },\n",
")\n",
"lambda_update_step.add_retry(\n",
" Retry(error_equals=[\"States.TaskFailed\"], interval_seconds=15, max_attempts=2, backoff_rate=4.0)\n",
")\n",
"lambda_compile_step.add_retry(\n",
" Retry(error_equals=[\"States.TaskFailed\"], interval_seconds=15, max_attempts=2, backoff_rate=4.0)\n",
")\n",
"lambda_deploy_step.add_retry(\n",
" Retry(error_equals=[\"States.TaskFailed\"], interval_seconds=15, max_attempts=2, backoff_rate=4.0)\n",
")"
]
},
{
"cell_type": "markdown",
"id": "fd886290",
"metadata": {},
"source": [
"### Choice State と Wait State の作成\n",
"\n",
"設定ファイルの `neo-compile` が True か False かによって、モデルコンパイル用 Lambda 関数実行後の待ち時間を調整するために、Choice State と Wait State を使用します。"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "c14394cf",
"metadata": {},
"outputs": [],
"source": [
"wait_5_step = stepfunctions.steps.states.Wait(\n",
" \"Wait for five minutes\",\n",
" seconds = 300,\n",
")\n",
"\n",
"wait_2_step = stepfunctions.steps.states.Wait(\n",
" \"Wait for two minutes\",\n",
" seconds = 120,\n",
")\n",
"\n",
"wait_choice_step = stepfunctions.steps.states.Choice(\n",
" \"Compile enable\"\n",
")\n",
"wait_choice_step.add_choice(\n",
" rule=ChoiceRule.IsPresent(variable=lambda_compile_step.output()[\"Payload\"][\"response\"], value=True),\n",
" next_step=wait_5_step\n",
")\n",
"wait_choice_step.default_choice(\n",
" next_step=wait_2_step\n",
")\n",
"wait_2_step.next(lambda_deploy_step)\n",
"wait_5_step.next(lambda_deploy_step)"
]
},
{
"cell_type": "markdown",
"id": "f8527a60",
"metadata": {},
"source": [
"### Fail 状態の作成\n",
"いずれかのステップが失敗したときにワークフローが失敗だとわかるように Fail 状態を作成します。\n",
"\n",
"エラーハンドリングのために [Catch Block](https://aws-step-functions-data-science-sdk.readthedocs.io/en/stable/states.html#stepfunctions.steps.states.Catch) を使用します。もし いずれかの Step が失敗したら、Fail 状態に遷移します。"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "be31a740",
"metadata": {},
"outputs": [],
"source": [
"failed_state_sagemaker_processing_failure = stepfunctions.steps.states.Fail(\n",
" \"ML Workflow failed\", cause=\"Failed\"\n",
")\n",
"catch_state_processing = stepfunctions.steps.states.Catch(\n",
" error_equals=[\"States.TaskFailed\"],\n",
" next_step=failed_state_sagemaker_processing_failure,\n",
")\n",
"\n",
"lambda_update_step.add_catch(catch_state_processing)\n",
"lambda_compile_step.add_catch(catch_state_processing)\n",
"lambda_deploy_step.add_catch(catch_state_processing)"
]
},
{
"cell_type": "markdown",
"id": "302000ef",
"metadata": {},
"source": [
"### Workflow の作成\n",
"\n",
"ここまでで Step Functions のワークフローを作成する準備が完了しました。`branching_workflow.create()` を実行することで、ワークフローが作成されます。一度作成したワークフローを更新する場合は `branching_workflow.update()` を実行します。\n",
"\n",
"Chain を使って各 Step を連結してワークフローを作成します。既存のワークフローを変更する場合は、update() を実行します。ログに ERROR が表示された場合は、以下のセルを再度実行してください。"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "026ae5eb",
"metadata": {},
"outputs": [],
"source": [
"import time\n",
"workflow_graph = Chain([lambda_update_step, lambda_compile_step, wait_choice_step])\n",
"\n",
"branching_workflow = Workflow(\n",
" name=\"gg-deploy-workflow-\" + user_name,\n",
" definition=workflow_graph,\n",
" role=workflow_execution_role,\n",
")\n",
"\n",
"branching_workflow.create()\n",
"branching_workflow.update(workflow_graph)\n",
"time.sleep(5)\n",
"branching_workflow.render_graph(portrait=False)"
]
},
{
"cell_type": "markdown",
"id": "65de8185",
"metadata": {},
"source": [
"ここまででモデルデプロイワークフローが作成できました。ワークフローは初めにいったん作成してしまえば、あとは実行するだけです。\n",
"\n",
"ここからの手順は、新しいモデルをエッジデバイスにデプロイするたびに実行する想定です。"
]
},
{
"cell_type": "markdown",
"id": "88603925",
"metadata": {},
"source": [
"---\n",
"\n",
"## エッジ推論で使用する学習済みモデルの準備\n",
"\n",
"このノートブックでは、Keras の学習済みの MobileNet モデルを使用します。Amazon SageMaker Neo で動作確認済みのモデルは [こちらのドキュメント](https://docs.aws.amazon.com/sagemaker/latest/dg/neo-supported-edge-tested-models.html) で確認できます。また、サポートされているフレームワークのバージョンは [こちらのドキュメント](https://docs.aws.amazon.com/sagemaker/latest/dg/neo-supported-devices-edge-frameworks.html) で確認できます。\n",
"\n",
"以下のセルを実行して、学習済みの MobileNet モデルをダウンロードし、`mobilenet.h5` として保存します。また、`model.summary()` を実行して、入力レイヤ名を確認します。Keras の MobileNet であればたいてい `input_1` となります。この名前を後ほど設定ファイルに記載するので覚えておいてください。\n",
"\n",
"自分で学習したモデルをデプロイする場合は、この手順は不要です。"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "4f26268c",
"metadata": {
"scrolled": true
},
"outputs": [],
"source": [
"import tensorflow as tf\n",
"\n",
"model = tf.keras.applications.MobileNet()\n",
"model.save('mobilenet.h5')\n",
"model.summary()"
]
},
{
"cell_type": "markdown",
"id": "0627a1d7",
"metadata": {},
"source": [
"---\n",
"\n",
"## デプロイ設定ファイルのセットアップ\n",
"\n",
"このノートブックの構成では、作成した AWS Step Functions ワークフローを実行する際に、デプロイに関する情報を記載した設定ファイル(yaml 形式)を入力パラメタとして指定します。モデルを学習した際の学習ジョブの情報など、他に記録しておきたい情報があれば、この yaml ファイルに記述を追加してください。ここからは、設定ファイルを作成していきます。\n",
"\n",
"### ユーティリティ関数の定義\n",
"\n",
"まずは設定ファイルの作成に必要な関数を準備します。"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "a9fa3d9e",
"metadata": {},
"outputs": [],
"source": [
"import boto3\n",
"# region = boto3.session.Session().region_name\n",
"# ggv2_client = boto3.client('greengrassv2', region_name=region)\n",
"\n",
"def get_latest_component_version(component_name):\n",
" component_list = ggv2_client.list_components()['components']\n",
" for c in component_list:\n",
" if c['componentName'] == component_name:\n",
" return c['latestVersion']['componentVersion']\n",
" \n",
"def get_target_group_arn(deployment_name):\n",
" deployments = ggv2_client.list_deployments()['deployments']\n",
"\n",
" deployment_id = ''\n",
" group_id = ''\n",
" for d in deployments:\n",
" if d['deploymentName'] == deployment_name:\n",
" return d['targetArn']\n",
"\n",
" return -1\n",
" \n",
"def increment_version(current_version, target='revision'):\n",
" # target: major, minor, revision\n",
" \n",
" if current_version == None:\n",
" return '0.0.1'\n",
" major, minor, revision = list(map(int, current_version.split('.')))\n",
" \n",
" if target == 'revision':\n",
" revision += 1\n",
" elif target == 'minor':\n",
" minor += 1\n",
" revision = 0\n",
" elif target == 'major':\n",
" major += 1\n",
" minor = 0\n",
" revision = 0\n",
" else:\n",
" print('[ERROR] invalid target value')\n",
" return current_version\n",
" \n",
" return '{}.{}.{}'.format(major, minor, revision)"
]
},
{
"cell_type": "markdown",
"id": "5dee3427",
"metadata": {},
"source": [
"### デプロイ関連情報の定義\n",
"\n",
"以下のセルに、デプロイしたいコンポーネントの情報を入力して実行します。**必ず以下の変数をご自身の環境に合わせて書き換えてください。**\n",
"\n",
"- `deployment_name`: [事前準備]の手順で作成したデバイスに紐づいたデプロイメント名\n",
"\n",
"\n",
"前の手順で確認したモデルの入力名が `input_1` でなかった場合は、`model_input_name` の値も書き換えてください。必要に応じて以下の変数を書き換えてください。\n",
"\n",
"- Amazon SageMaker Neo 用の設定\n",
" - `model_input_name`: 学習済みモデルの入力名。Keras の場合、model.summary() で確認する\n",
" - `model_input_shape`: 学習済みモデルの入力サイズ。Keras の場合、model.summary() で確認する\n",
" - `model_framework`: 学習済みモデルのフレームワーク\n",
" - `target_device`: コンパイルターゲットデバイスの種類\n",
"- AWS IoT Greengrass V2 用の設定\n",
" - `gg_s3_path`: 設定ファイルやアーティファクトを保存する S3 パス(このノートブックを実行するのと同じリージョンのバケットにしてください)\n",
" - `component_name`: コンポーネントの名前(任意の名前)\n",
" - `target_group_arm`: デプロイ先のターゲットグループの ARN\n",
" - `pip_libraries`: Greengrass レシピに記載する、エッジ推論に必要なライブラリ名(複数ある場合はスペース区切り)\n",
"- その他の設定\n",
" - `deploy_lambda_container`: デプロイ用 Lambda 関数で使用するコンテナイメージの URI(コンテナイメージ作成手順の中で Amazon ECR にプッシュしたイメージ)\n",
"\n",
"このノートブックでは、`gg_s3_path` で設定した S3 パス以下に必要なファイルをアップロードします。また、モデルを SageMaker Neo でコンパイルするので、Greengrass コンポーネントに `pip install` するライブラリを指定するための `pip_libraries` を用意しています。"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "843c9e16",
"metadata": {},
"outputs": [],
"source": [
"gg_s3_path = 's3://'+bucket_name+'/gg/' + user_name # 設定ファイル、アーティファクトファイルなどを保存する S3 パス\n",
"component_name = 'com.example.IoTPublisher.' + user_name\n",
"deployment_name = 'Deployment for GreengrassQuickStartGroup'\n",
"target_group_arm = get_target_group_arn(deployment_name)\n",
"target_device = 'ml_m5'\n",
"model_input_name = 'input_1'\n",
"model_input_shape = '[1, 3, 224, 224]'\n",
"model_framework = 'KERAS'\n",
"deploy_lambda_container = lambda_deploy_repository_uri\n",
"pip_libraries = 'dlr pillow opencv-python opencv-contrib-python'"
]
},
{
"cell_type": "markdown",
"id": "e5db5811",
"metadata": {},
"source": [
"### 学習済みモデルとアーティファクトファイルを S3 にアップロード\n",
"\n",
"デバイスにデプロイするサンプルとして用意したファイルを S3 にアップロードします。アーティファクトファイルは、`bucket_name`/gg/artifacts/コンポーネント名/コンポーネントバージョン にアップロードされます。\n",
"\n",
"このサンプルノートブックでは、アーティファクトファイルに変更がなくても必ずコンポーネントバージョンごとにファイルを S3 に保存する構成になっています。"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "8372980f",
"metadata": {},
"outputs": [],
"source": [
"\n",
"!tar zcvf mobilenet.tar.gz mobilenet.h5\n",
"\n",
"latest_version = get_latest_component_version( component_name)\n",
"component_version = increment_version(latest_version)\n",
"\n",
"path = os.path.join('gg', user_name, 'artifacts', component_name, component_version, 'data')\n",
"artifacts_s3_path = sagemaker_session.upload_data(path='artifacts', bucket=bucket_name, key_prefix=path)\n",
"\n",
"path = os.path.join('gg', user_name, 'models')\n",
"model_s3_path = sagemaker_session.upload_data(path='mobilenet.tar.gz', bucket=bucket_name, key_prefix=path)\n",
"\n",
"print('new component version:', component_version)"
]
},
{
"cell_type": "markdown",
"id": "e2963d9e",
"metadata": {},
"source": [
"### 設定ファイル(yaml 形式)をファイルに保存\n",
"\n",
"以下のセルを実行して、設定ファイルを作成します。Greengrass コンポーネントのバージョンは、最新のバージョンのリビジョン番号を 1インクリメントしたものが自動的にセットされます。メジャー番号やマイナー番号をインクリメントしたい場合は、`get_latest_component_version` の引数に `target='major'` などを指定してください。\n",
"\n",
"以下のセルでは、学習済みモデルが `{gg_s3_path}/models` という S3 パスに保存されている想定で設定ファイル(yaml 形式)を作成して保存しています。SageMaker 学習ジョブが出力したファイルを直接指定したい場合は、以下のセルの `original-model-path` にモデルが保存されているフルパスを設定してください。また、SageMaker Neo でコンパイル済みのモデルを指定する場合は、`compile-model:` に `False` を設定し、`compiled-model-path` にはコンパイル済みのモデルが保存されている S3 パスを設定してください。"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "14921a1d",
"metadata": {},
"outputs": [],
"source": [
"import datetime\n",
"\n",
"timestamp = datetime.datetime.now(datetime.timezone(datetime.timedelta(hours=9))).strftime('%Y%m%d-%H%M%S')\n",
"\n",
"config_string = f\"\"\"\n",
"component-name: {component_name}\n",
"component-version: {component_version}\n",
"deployment-name: {deployment_name}\n",
"target-group-arn: {target_group_arm}\n",
"entrypoint-script-name: 'run.py'\n",
"pip-libraries: {pip_libraries}\n",
"model-information:\n",
" original-model-path: {model_s3_path}\n",
" compile-model: True\n",
" compiled-model-path: {gg_s3_path}/compiled-models/\n",
" target-device: {target_device}\n",
" input-name: {model_input_name}\n",
" input-shape: '{model_input_shape}'\n",
" framework: {model_framework}\n",
"lambda-container: {deploy_lambda_container}\n",
"lambda-deploy-function: 'deploy-components-to-device-{user_name}'\n",
"artifact-files: \n",
" - {artifacts_s3_path}/run.py\n",
" - {artifacts_s3_path}/inference.py\n",
" - {artifacts_s3_path}/classification-demo.png\n",
" - {artifacts_s3_path}/image_net_labels.json\n",
"\"\"\"\n",
"config_name = timestamp + '-' + component_version + '.yaml'\n",
"with open(config_name, 'w') as f:\n",
" f.write(config_string)"
]
},
{
"cell_type": "markdown",
"id": "a4c26842",
"metadata": {},
"source": [
"### 設定ファイルを S3 にアップロード\n",
"\n",
"作成した設定ファイルを S3 にアップロードします。アップロート先の S3 パスが `upload_path` に保存されます。AWS Step Functions ワークフローを実行する際に、このファイルパスを入力パラメタとして指定します。"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "984ac540",
"metadata": {},
"outputs": [],
"source": [
"import yaml\n",
"import os\n",
"\n",
"with open(config_name) as file:\n",
" config = yaml.safe_load(file)\n",
" component_name = config['component-name']\n",
"\n",
"upload_path = os.path.join(gg_s3_path, 'config', component_name, component_version, config_name)\n",
" \n",
"!aws s3 cp $config_name $upload_path"
]
},
{
"cell_type": "markdown",
"id": "7f0452fe",
"metadata": {},
"source": [
"## AWS Step Functions ワークフローの実行\n",
"\n",
"それではいよいよ、ワークフローを実行して ML モデルやスクリプトをエッジにデプロイします。ワークフローの実行方法は 2通りあります。このノートブックを初めて使用した場合は、1の方法をご利用ください。\n",
"\n",
"1. ワークフローを作成し、続けて実行する\n",
"1. 既存のワークフローを呼び出して実行する\n",
"\n",
"### ワークフローの実行\n",
"以下のセルを実行してワークフローを開始します。引数の `ConfigFilePath` に設定ファイルが置いてある S3 パスが指定されています。このセルを実行した場合は、次のセルを実行する必要はありません。\n",
"\n",
"過去に作成した設定ファイルを指定してワークフローを実行すれば、当時と同じ処理を実行することができます。"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "fea28a1a",
"metadata": {},
"outputs": [],
"source": [
"execution = branching_workflow.execute(\n",
" inputs={\n",
" 'ConfigFilePath': upload_path\n",
" }\n",
")"
]
},
{
"cell_type": "markdown",
"id": "87f6fda0",
"metadata": {},
"source": [
"### 既存のワークフローを呼び出して実行\n",
"\n",
"すでに作成してあるワークフローを実行する場合は以下のセルの `workflow_arn` にワークフローの ARN を入力し、コメントアウトを解除してから実行してください。ワークフローの ARN は [AWS Step Functions のコンソール](https://ap-northeast-1.console.aws.amazon.com/states/home?region=ap-northeast-1#/statemachines) から確認できます。"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "58fec941",
"metadata": {},
"outputs": [],
"source": [
"# from stepfunctions.workflow import Workflow\n",
"\n",
"# workflow_arn = 'arn:aws:states:ap-northeast-1:420964472730:stateMachine:gg-deploy-workflow'\n",
"# existing_workflow = Workflow.attach(workflow_arn)\n",
"\n",
"# execution = existing_workflow.execute(\n",
"# inputs={\n",
"# 'ConfigFilePath': upload_path\n",
"# }\n",
"# )"
]
},
{
"cell_type": "markdown",
"id": "9b52eb4e",
"metadata": {},
"source": [
"以下のセルを実行すると、ワークフローの実行状況を確認できます。"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "4666ff62",
"metadata": {},
"outputs": [],
"source": [
"execution.render_progress()"
]
},
{
"cell_type": "markdown",
"id": "b04a3edd",
"metadata": {},
"source": [
"デプロイが完了したら、Cloud9 のターミナルで以下のコマンドを実行してログを表示します。うまくデプロイできていれば、5秒ごとに推論結果が表示されます。なお、常に同じ画像を使って推論しているため、常に同じ結果が表示されます。\n",
"\n",
"> tail -f /tmp/Greengrass_HelloWorld.log"
]
},
{
"cell_type": "markdown",
"id": "252008aa",
"metadata": {},
"source": [
"## デプロイされたモデルの情報を一覧表示\n",
"\n",
"どのデバイスにどのモデルがデプロイされたかを知りたいことがあります。その場合は、Greengrass の deployments のリストから各種情報を API やワークフロー実行時の設定ファイルを使って情報を一覧表示することができます。\n",
"\n",
"まずは必要な関数を定義します。"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "74f3c586",
"metadata": {},
"outputs": [],
"source": [
"# import boto3\n",
"# import yaml\n",
"# import pandas as pd\n",
"# from dateutil import tz\n",
"# JST = tz.gettz('Asia/Tokyo')\n",
"\n",
"# region = boto3.session.Session().region_name\n",
"# s3_client = boto3.client('s3', region_name=region)\n",
"# ggv2_client = boto3.client('greengrassv2', region_name=region)\n",
"# iot_client = boto3.client('iot', region_name=region)\n",
"# s3 = boto3.resource('s3')\n",
"\n",
"def get_device_in_deployment_list():\n",
" deployments = ggv2_client.list_deployments()['deployments']\n",
"\n",
" device_list = []\n",
" for d in deployments:\n",
"\n",
" thing_group_name = d['targetArn'].split('/')[-1]\n",
" \n",
" try:\n",
" response = iot_client.list_things_in_thing_group(\n",
" thingGroupName=thing_group_name\n",
" )\n",
" things = response['things']\n",
" except:\n",
" things = [thing_group_name]\n",
" for thing in things:\n",
" response = ggv2_client.get_core_device(\n",
" coreDeviceThingName=thing\n",
" )\n",
"\n",
" device_list.append({\n",
" 'deployment-name': d['deploymentName'],\n",
" 'target-arn': d['targetArn'],\n",
" 'thing-group-name': thing_group_name,\n",
" 'thing-name': thing,\n",
" 'status': response['status'],\n",
" 'last-status-updated': response['lastStatusUpdateTimestamp'].astimezone(JST)\n",
" })\n",
" \n",
" return device_list\n",
"\n",
"def get_installed_component_list(device_name):\n",
" response = ggv2_client.list_installed_components(\n",
" coreDeviceThingName=device_name\n",
" )\n",
"\n",
" component_list = []\n",
" for d in response['installedComponents']:\n",
" component_list.append([d['componentName'], d['componentVersion']])\n",
" \n",
" return component_list\n",
"\n",
"def get_config_file_name(bucket_name, prefix):\n",
"\n",
" prefix = prefix + '/'\n",
" \n",
" def search_component(latest, start_after):\n",
" objects = s3_client.list_objects_v2(Bucket=bucket_name, Prefix=prefix, StartAfter=start_after)\n",
"\n",
" if \"Contents\" in objects:\n",
" keys = [content[\"Key\"][len(prefix):] for content in objects[\"Contents\"]]\n",
" for k in keys:\n",
" if k > latest:\n",
" latest = k\n",
" if objects.get(\"isTruncated\"):\n",
" return search_component(latest=latest, start_after=keys[-1])\n",
" return latest\n",
" \n",
" return search_component('0', '')\n",
"\n",
"def get_config_info_as_yaml(config_file_path, component_info):\n",
" component_name, component_version = component_info\n",
" bucket_name = config_file_path.split('/')[2]\n",
" prefix = os.path.join(config_file_path[len(bucket_name)+6:] , 'config', component_name, component_version)\n",
" config_file_name = os.path.join(prefix, get_config_file_name(bucket_name, prefix))\n",
"\n",
" bucket = s3.Bucket(bucket_name)\n",
" obj = bucket.Object(config_file_name)\n",
" try:\n",
" response = obj.get() \n",
" except:\n",
" return None\n",
" \n",
" body = response['Body'].read()\n",
" config = yaml.safe_load(body)\n",
" \n",
" return config\n",
"\n",
"\n",
"def show_deployed_model_info(config_file_path):\n",
" device_list = get_device_in_deployment_list()\n",
"\n",
" column_name = [\n",
" 'deployment-name',#0\n",
" 'target-group-arn', \n",
" 'thing-name',\n",
" 'thing-status',\n",
" 'thing-last-status-updated',#5\n",
" 'component-name', \n",
" 'deployed-component-version',\n",
" 'model-name', \n",
" 'model-fullpath',\n",
" 'model-framework',#10\n",
" 'neo-compile']\n",
" df = pd.DataFrame(None,\n",
" columns=column_name,\n",
" index=None)\n",
" \n",
" for d in device_list:\n",
" print('Device \"', d['thing-name'], '\" has these ML components: ')\n",
" component_list = get_installed_component_list(d['thing-name'])\n",
" \n",
" for c in component_list:\n",
" config = get_config_info_as_yaml(config_file_path, c)\n",
" if config == None:\n",
" print('\\t No ML components.')\n",
" continue\n",
" component_name, component_version = c\n",
" print('\\t component-name:', component_name, '-- version:', component_version)\n",
" config = get_config_info_as_yaml(config_file_path, c)\n",
"\n",
" thing_group_name = d['thing-group-name']\n",
"\n",
" df = df.append({\n",
" column_name[0]: config['deployment-name'],\n",
" column_name[1]: config['target-group-arn'],\n",
" column_name[2]: d['thing-name'],\n",
" column_name[3]: d['status'],\n",
" column_name[4]: d['last-status-updated'],\n",
" column_name[5]: config['component-name'], \n",
" column_name[6]: config['component-version'], \n",
" column_name[7]: config['model-information']['original-model-path'].split('/')[-1],\n",
" column_name[8]: config['model-information']['original-model-path'], \n",
" column_name[9]: config['model-information']['framework'], \n",
" column_name[10]: config['model-information']['compile-model']}, ignore_index=True)\n",
" \n",
" return df"
]
},
{
"cell_type": "markdown",
"id": "c476a1a8",
"metadata": {},
"source": [
"以下のセルを実行すると、デプロイパイプラインを使って ML モデルをデプロイしたデバイスの一覧が Pandas の DataFrame 形式で表示されます。作成した Step Functions ワークフローを使わず直接 Greengrass のコンソールからコンポーネントをデプロイした場合は、こちらの一覧には表示されないのでご注意ください。実際のワークロードでは必ずワークフローを使ってデプロイすることをルールとすることをおすすめします。\n",
"\n",
"`config_file_path_list` には、デプロイ設定ファイルが保存されている S3 パスのリストを設定します。"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "b2356a4f",
"metadata": {},
"outputs": [],
"source": [
"config_file_path_list = [gg_s3_path]\n",
"info = None\n",
"for config_file_path in config_file_path_list:\n",
" df = show_deployed_model_info(config_file_path)\n",
" if info is None:\n",
" info = df\n",
" else:\n",
" info = pd.concat([info, df])\n",
"info"
]
},
{
"cell_type": "markdown",
"id": "54fecf38",
"metadata": {},
"source": [
"[おまけ] DataFrame を html ファイルとして保存することもできます。"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "020bf378",
"metadata": {},
"outputs": [],
"source": [
"pd.set_option('colheader_justify', 'center') \n",
"\n",
"html_string = '''\n",
"\n",
" Device Status\n",
" \n",
" {table}\n",
" \n",
".\n",
"'''\n",
"\n",
"# OUTPUT AN HTML FILE\n",
"with open('index.html', 'w') as f:\n",
" f.write(html_string.format(table=df.to_html()))"
]
},
{
"cell_type": "markdown",
"id": "613c2c17",
"metadata": {},
"source": [
"Jupyter ノートブックで以下のセルを実行すると、html ファイルの中身が表示されます。Jupyter Lab や SageMaker Studio では `HTML` が機能しないので、以下のセルを実行するのではなく直接 html ファイルを開いてください。"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "9bd101cb",
"metadata": {},
"outputs": [],
"source": [
"from IPython.display import HTML\n",
"HTML('index.html')"
]
},
{
"cell_type": "markdown",
"id": "0276d796",
"metadata": {},
"source": [
"## [重要] リソースの削除\n",
"\n",
"\n",
"不要な課金を避けるために、以下のリソースを削除してください。特に Amazon SageMaker ノートブックインスタンスは削除しない限りコンピュートリソースとストレージの利用料金が継続するので、不要な場合は必ず削除してください。\n",
"\n",
"- [必須] Amazon SageMaker ノートブックインスタンス\n",
"- 事前準備で作成した Cloud9 環境\n",
"- IoT Greengrass リソース\n",
"- S3 に保存したデータ\n",
"- AWS Step Functions ワークフロー\n",
"- Lambda 関数\n",
"\n",
"### AWS Step Functions ワークフロー関連のリソース削除\n",
"\n",
"以下のセルを実行して、作成したワークフローと IAM role, IAM policy を削除します。"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "2307a8ed",
"metadata": {},
"outputs": [],
"source": [
"branching_workflow.delete()\n",
"\n",
"def detach_role_policies(role_name):\n",
" response = iam_client.list_attached_role_policies(\n",
" RoleName=role_name,\n",
" )\n",
" policies = response['AttachedPolicies']\n",
"\n",
" for p in policies:\n",
" response = iam_client.detach_role_policy(\n",
" RoleName=role_name,\n",
" PolicyArn=p['PolicyArn']\n",
" )\n",
" \n",
"detach_role_policies(step_functions_role_name)\n",
"iam_client.delete_role(RoleName=step_functions_role_name)\n",
"iam_client.delete_policy(PolicyArn=step_functions_policy_arn)"
]
},
{
"cell_type": "markdown",
"id": "835520af",
"metadata": {},
"source": [
"### Lambda 関数関連のリソース削除\n",
"\n",
"以下のセルを実行して、作成した Lambda 関数と IAM role, IAM policy, ECR repository を削除します。"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "9adf044c",
"metadata": {},
"outputs": [],
"source": [
"\n",
"for l in lambda_roles:\n",
" detach_role_policies(l)\n",
" iam_client.delete_role(RoleName=l)\n",
" \n",
"for p in lambda_policies:\n",
" iam_client.delete_policy(PolicyArn=p)\n",
" \n",
"lambda_client.delete_function(FunctionName=lambda_function_name_update)\n",
"lambda_client.delete_function(FunctionName=lambda_function_name_compile)\n",
"lambda_client.delete_function(FunctionName=lambda_function_name_deploy)\n",
"\n",
"ecr_client.delete_repository(\n",
" repositoryName=ecr_repository_lambda_update,\n",
" force=True\n",
")\n",
"ecr_client.delete_repository(\n",
" repositoryName=ecr_repository_lambda_compile,\n",
" force=True\n",
")\n",
"ecr_client.delete_repository(\n",
" repositoryName=ecr_repository_lambda_deploy,\n",
" force=True\n",
")"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "ddd651d4",
"metadata": {},
"outputs": [],
"source": []
}
],
"metadata": {
"kernelspec": {
"display_name": "conda_tensorflow_p36",
"language": "python",
"name": "conda_tensorflow_p36"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.6.13"
},
"toc": {
"base_numbering": 1,
"nav_menu": {},
"number_sections": true,
"sideBar": true,
"skip_h1_title": true,
"title_cell": "Table of Contents",
"title_sidebar": "Contents",
"toc_cell": true,
"toc_position": {},
"toc_section_display": true,
"toc_window_display": true
}
},
"nbformat": 4,
"nbformat_minor": 5
}