{
"cells": [
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# SageMaker Studioで深層学習モデルの学習を加速・コスト最適化する\n",
"\n",
"データ量が増えてきて、深層学習モデルの学習に時間がかかりすぎていませんか?\n",
"\n",
"このノートブックでは、深層学習モデルの学習にかかる時間とコストを最適化する手順を、SageMaker Data Parallel LibraryとSageMaker Debuggerを使いながらご紹介します。\n",
"\n",
"SageMaker Data Parallelism Libraryは、AWS上での分散学習実行に最適化されているため、HorovodやPyTorch DDPなどの他の分散学習フレームワークに比べて並列化効率がより高いことが実証されています。詳細は、[論文](https://www.amazon.science/publications/herring-rethinking-the-parameter-server-at-scale-for-the-cloud)を参照してください。\n",
"\n",
"今回は、例としてMask RCNNモデルに[COCO2017データセット](https://cocodataset.org/#home)を分散学習していく過程を紹介します。\n",
"なお、このノートブックはSageMaker Studio上のPython 3 (PyTorch 1.6 Python 3.6 GPU Optimized)環境で動作確認をしております。\n",
"\n",
"他のフレームワークやモデルでの分散学習のスクリプトは[こちら](https://github.com/HerringForks/DeepLearningExamples)を参照してください。\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## 目次\n",
"\n",
"* [学習時間と課金額のトレードオフでトータルコスト最適化を考える](#cost-opt)\n",
" * 分散学習すべきかを判断するには並列化効率が鍵\n",
" * トータルコストシミュレーション\n",
"\n",
"* [0. 準備と注意点](#sec-0)\n",
"\n",
"* [1. COCO2017データセットの準備](#sec-1)\n",
"\n",
"* [2. SageMakerの実行環境を準備](#sec-2)\n",
" * [2.1. Dockerイメージをビルド・ECRへプッシュ](#sec-21)\n",
" * [2.2. 学習時に収集するメトリクスを定義する](#sec-22)\n",
" \n",
"* [3. 複数GPUを持つインスタンス1つで学習する場合](#sec-3)\n",
" * [3.1 SageMaker Debuggerでプロファイリングする](#sec-31)\n",
" \n",
"* [4. 複数GPUを持つインスタンス複数で学習する場合](#sec-4)\n",
"\n",
"* [5. Amazon FSx for Lustreを使ってデータダウンロードとIOを加速する](#sec-5)\n",
"\n",
"* [最後に](#ending)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## 学習時間と課金額のトレードオフでトータルコスト最適化を考える \n",
"\n",
"SageMaker上で分散学習を実施することで、学習時間と課金額のトレードオフがコントロールできるようになります。具体的には、約11%の金額増加で約86%も学習時間を短縮できる、といった例が挙げられます。こちらのトレードオフを詳しくみてみましょう。\n",
"\n",
"インスタンスの使用料金をPドル/時、学習にかかる時間をT時間、並列化効率(インスタンス x個で学習時間がx倍にどれくらい近くなるか)をS%として、1個のインスタンス(またはGPU)からN個のインスタンス(またはGPU)に分散学習する場合を考えてみましょう。\n",
"\n",
"学習にかかる時間はT時間から(T/N)/S時間に減り、インスタンス使用料金はT * Pドルから(T/N)/S * P * N = T/S * Pドルへ(S = 1、すなわち並列化効率100%とならない限りは)増加します。並列化効率が十分高ければ、大幅な学習時間短縮を少ない金額の増加で買うことができる、というわけです。コストを時間と課金額の組み合わせと捉えると、分散学習が1つのコスト最適化のツールとなり、かつ並列化効率がそのトレードオフを決定する重要な要因であることがご理解いただけると思います。\n",
"また、学習時間に制限があり、データ量が増える中で時間内に学習を終える必要があるかもしれません。その際にも、並列化効率が鍵となり、どのくらいの課金額の増加でどのくらいの学習時間短縮が狙えるか調査することが大切になってきます。\n",
"\n",
"例えば、ml.p3.2xlargeインスタンスで24時間学習に時間を取られている場合、8つのインスタンスに90%の並列化効率で分散学習が実現できれば、時間と課金額は以下のように変化します。\n",
"\n",
"分散学習なしでは24 * 3.825 = 91.8ドル(us-west-2リージョンで[SageMaker Savings Plan](https://aws.amazon.com/about-aws/whats-new/2021/04/amazon-sagemaker-announces-a-price-reduction-in-instances-and-sagemaker-savings-plan/)を使用しない場合)の課金と24時間というコストが発生します。\n",
"\n",
"上記の条件で分散学習をすると、24/0.9 * 3.825 = 102ドルの課金と24/8/0.9 = 3.33時間というコストになります。\n",
"\n",
"この場合、最初に記載したように約11%の金額増加で約86%の学習時間短縮が期待されます。どちらのトータルコストが良いかどうかは、ビジネス上で深層学習のモデル学習時間短縮がどれくらい重要かによります。しかし、モデルを何度も再学習する必要に迫られる中で、これからデータ量が増えていくことが予測されるならば、分散学習を1つの選択肢として持っておくのは悪くないかもしれません。\n",
"\n",
"SageMaker Data Parallel Libraryを用いたベンチマークは、HorovodやPyTorch Distributed Data Parallelと比べて優れた並列化効率を実現できる可能性が高いです。\n",
"\n",
"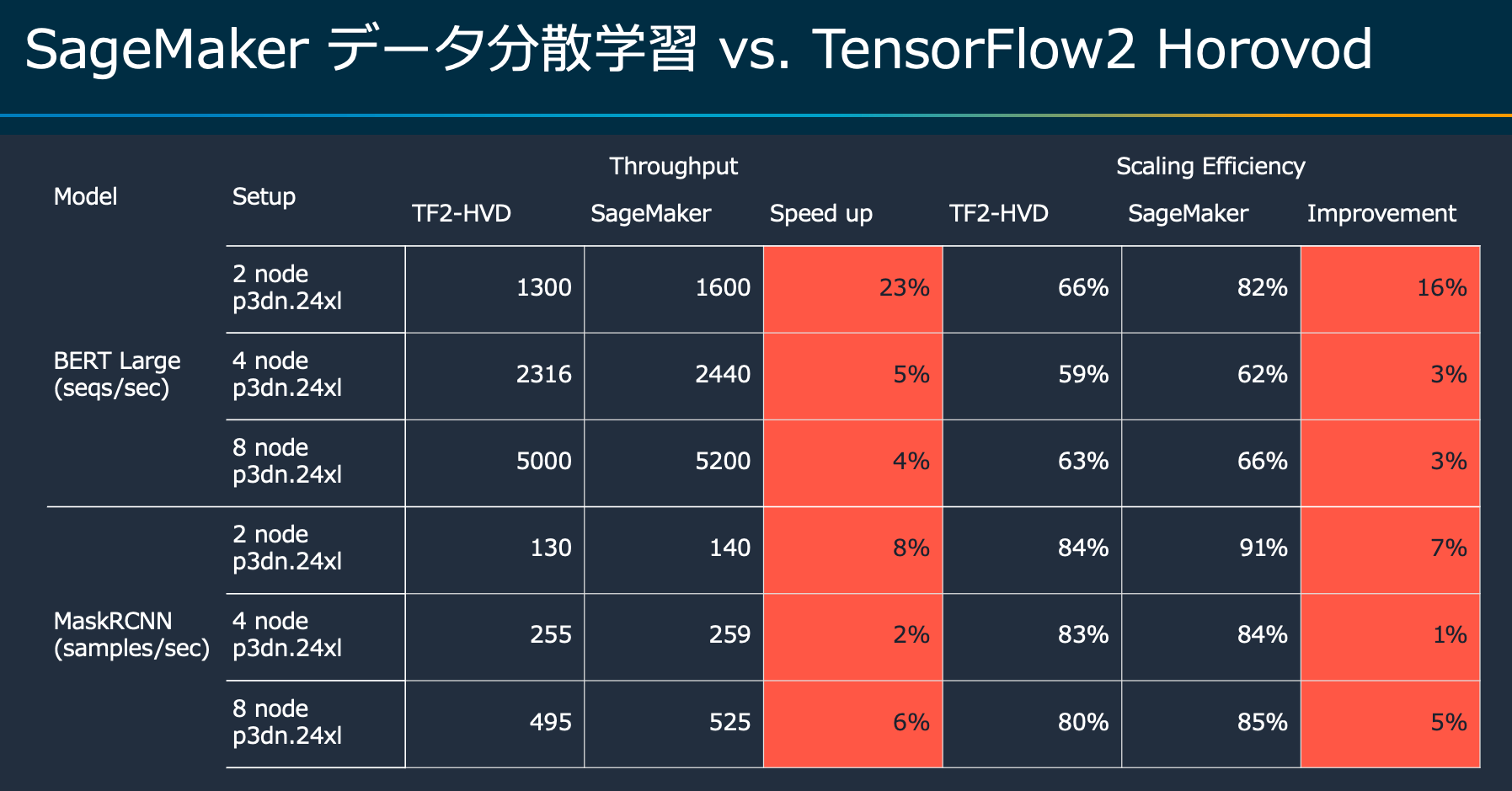\n",
"\n",
"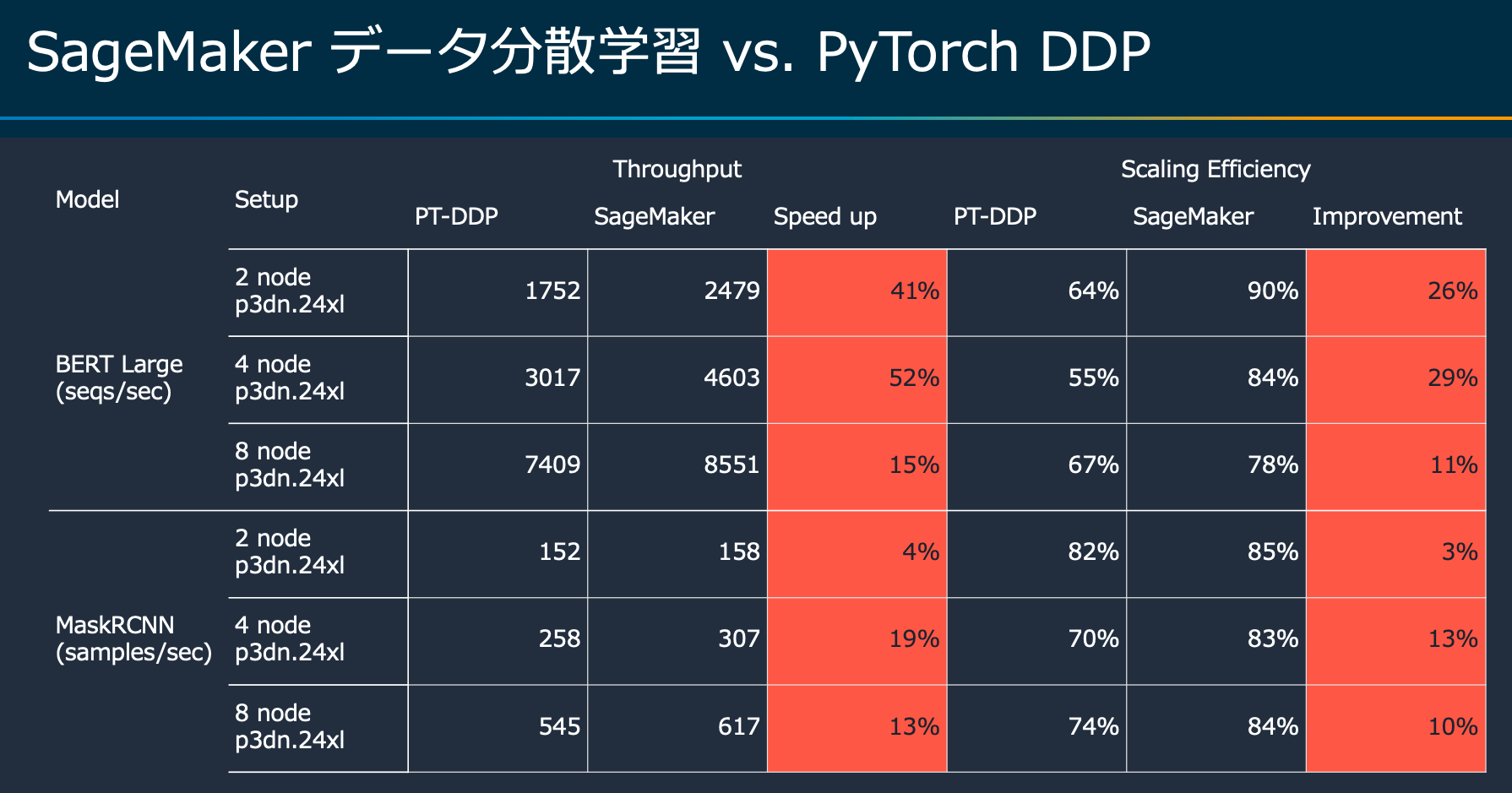\n",
"\n",
"※ SageMaker Data Parallel Libraryでサポートされているインスタンスはml.p3.16xlarge, ml.p3dn.24xlarge, ml.p4d.24xlargeです。\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### 分散学習すべきかを判断するには並列化効率が鍵\n",
"\n",
"分散学習をする上で、鍵となるのは並列化効率です。どのくらいの並列化効率があれば、トータルコストを削減できるかを把握することが重要です。\n",
"\n",
"実際に現在の深層学習モデルの学習にかかっている時間とインスタンスの料金をもとに、トータルコストをシミュレーションしてみましょう。\n",
"\n",
"SageMakerインスタンスの料金は[こちら](https://aws.amazon.com/jp/sagemaker/pricing/?nc1=h_ls)を参照してください。\n",
"\n",
"これで目指すべき並列化効率が求められます。"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"import numpy as np\n",
"import matplotlib.pyplot as plt\n",
"\n",
"def before_total_cost(T, P, weight):\n",
" # トータルコスト = お金 + 時間\n",
" return T * P + T * weight\n",
"\n",
"def after_total_cost(T, P, N, weight, S):\n",
" return T/S * P + T/N/S * weight\n",
"\n",
"def plot_simulation(T, P, N, weight):\n",
" '''\n",
" 横軸: 並列化効率\n",
" 縦軸: トータルコスト(ドル)\n",
" 分散学習をする場合、最低でもどのくらいの並列化効率が必要かをグラフから目安をつける\n",
" '''\n",
" # 並列化効率を10% ~ 100%までシミュレーション\n",
" scaling_efficiencies = list(np.arange(0.10, 1.01, 0.01))\n",
" \n",
" before = []\n",
" after = []\n",
" for S in scaling_efficiencies:\n",
" before_cost = before_total_cost(T, P, weight)\n",
" before.append(before_cost)\n",
" after_cost = after_total_cost(T, P, N, weight, S)\n",
" after.append(after_cost)\n",
" if round(S*100) % 10 == 0:\n",
" is_cost_lower = after_cost < before_cost\n",
" cost_diff = abs((after_cost - before_cost) / before_cost) * 100\n",
" up = \"上がる\"\n",
" down = \"下がる\"\n",
" print(f\"並列化効率 {S*100:.1f}%でトータルコストは{cost_diff:.3f}% {down if is_cost_lower else up}\")\n",
" print()\n",
" plt.xlabel(\"Scaling Efficiency\")\n",
" plt.ylabel(\"Total Cost ($)\")\n",
" plt.plot(scaling_efficiencies, before, label=\"before\")\n",
" plt.plot(scaling_efficiencies, after, label=\"after\")\n",
" plt.legend()"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# 学習に何時間かかっているか\n",
"TRAINING_TIME = 24\n",
"\n",
"# インスタンスに時間あたり何ドルかかっているか\n",
"INSTANCE_PRICE = 3.825\n",
"\n",
"# 何個インスタンスを使うか\n",
"NUM_INSTANCES = 8\n",
"\n",
"# 1時間学習が長くなることによる機会費用 (トータルコストをドルで統一するため)\n",
"TIME_VALUE = 3"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"plot_simulation(T=TRAINING_TIME, P=INSTANCE_PRICE, N=NUM_INSTANCES, weight=TIME_VALUE)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"1時間学習時間が長くなることで平均3ドルほどの機会費用が発生すると仮定してみる (`TIME_VALUE = 3`) と、8つのインスタンスを使って並列化効率が約60%より大きければ、トータルコスト削減に繋がります。\n",
"\n",
"以下のチュートリアルでは、SageMaker Studio上での具体的な分散学習の進め方の例を示します。SageMaker Data Parallel Libraryは高い並列化効率を実現しますが、より高い並列化効率を達成するのに必要なステップをCOCOデータセットとMaskRCNNを例として試してみましょう。"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## 0. 準備と注意点 \n",
"\n",
"* SageMaker Data Parallel Libraryを使用する場合、ml.p3.16xlarge, ml.p3dn.24xlarge [推奨], ml.p4d.24xlarge [推奨]の3種類のインスタンスに対応しています。必要に応じて、必要に応じて、[サービスクォータの引き上げ](https://docs.aws.amazon.com/ja_jp/general/latest/gr/aws_service_limits.html)をしてください。\n",
"\n",
"* このノートブックは高性能GPUを搭載したp3インスタンスを使用するため、課金が発生します。\n",
" * 参考: 1つのp3.16xlargeインスタンスを使う場合、リージョンによって20-30ドルほど\n",
" * 1000イテレーションまでの学習にとどめているため、45分以内には学習が完了する設定になっておりますが、ご注意ください。\n",
" * 継続的な課金を防ぐため、最後のセルにある、S3とFSx for Lustreのリソース削除コードを実行することをおすすめします。\n",
" \n",
"* このノートブックは準備に時間がかかります。\n",
" * 大規模データの解凍・アップロードとコンテナイメージ構築に合計3時間ほどかかります。\n",
" * 待っている間はSageMaker Studioを閉じても大丈夫です。一度構築されれば、同じリージョンであればそのまま使いまわせます。\n",
"\n",
"\n",
"* このノートブックはSageMaker Studio上での実行を想定しています。\n",
" * SageMaker Notebook Instanceからでもほとんどのステップを実行できますが、「3.1. SageMaker Debuggerでプロファイリングする」セクションでは、SageMaker Debuggerの出力をS3から取得してプロファイルの結果を可視化する手順を踏む必要があります。[こちらのレポジトリ](https://github.com/aws-samples/amazon-sagemaker-dist-data-parallel-with-debugger)を参照してください。\n",
"* リージョン\n",
" * us-west-2(オレゴン)リージョンでの動作を確認しています。"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"%%time\n",
"import sys\n",
"! {sys.executable} -m pip install --upgrade sagemaker\n",
"import sagemaker\n",
"from sagemaker import get_execution_role\n",
"from sagemaker.estimator import Estimator\n",
"import boto3\n",
"\n",
"sagemaker_session = sagemaker.Session()\n",
"bucket = sagemaker_session.default_bucket()\n",
"fsx_client = boto3.client('fsx')\n",
"\n",
"role = get_execution_role() # provide a pre-existing role ARN as an alternative to creating a new role\n",
"print(f'SageMaker Execution Role:{role}')\n",
"\n",
"client = boto3.client('sts')\n",
"account = client.get_caller_identity()['Account']\n",
"print(f'AWS account:{account}')\n",
"\n",
"session = boto3.session.Session()\n",
"region = session.region_name\n",
"print(f'AWS region:{region}')"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## 1. COCO2017データセットの準備 \n",
"\n",
"[COCO2017](https://cocodataset.org/#home)のデータセットをこのセッションに付随するS3のバケットにダウンロードします。\n",
"\n",
"このスクリプトは2時間ほど実行に時間がかかります。"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"%%time\n",
"!bash ./upload_coco2017_to_s3.sh {bucket} fsx_sync/train-coco/coco"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## 2. SageMakerの実行環境を準備 \n",
"\n",
"1. デフォルトでSageMakerは最新のPyTorch学習用イメージを[Amazon Deep Learning Container Images (DLC)](https://github.com/aws/deep-learning-containers/blob/master/available_images.md)から使用します。今回は、これをベースイメージとして、MaskRCNNモデルを学習するのに必要な追加のモジュールをインストールしていきます。\n",
"2. PyTorch-SMDataParallel MaskRCNN学習スクリプトがGitHubレポジトリ https://github.com/HerringForks/DeepLearningExamples.git からダウンロードでき、今回はこれを学習用イメージの上にインストールします。\n",
"\n",
"### 2.1. Dockerイメージをビルド・ECRへプッシュ \n",
"\n",
"以下のコマンドを実行して、DockerイメージをビルドしてECRへプッシュしてみましょう。\n",
"\n",
"SageMaker Studio上ではGPUを使ったdocker buildができないため、Dockerが使用できる別環境(SageMaker Notebook instanceなど)で以下のセクションにあるセルを実行してください。150GBのEBSボリュームをアタッチしたt3インスタンスを使うと、1時間ほどでビルドが完了します。"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"image = \"mask-rcnn-smdataparallel-demo\" # 例: mask-rcnn-smdataparallel-sagemaker\n",
"tag = \"test0.1\" # 例: pt1.8"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"!pygmentize ./Dockerfile"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"!pygmentize ./build_and_push.sh"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# %%time\n",
"! chmod +x build_and_push.sh; bash build_and_push.sh {region} {image} {tag}"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# 学習のベースとなるモデルファイルをダウンロードする\n",
"!wget https://dl.fbaipublicfiles.com/detectron/ImageNetPretrained/MSRA/R-50.pkl \n",
"!aws s3 cp R-50.pkl s3://{bucket}/pretrained_weights/R-50.pkl"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### 2.2. 学習時に収集するメトリクスを定義する \n",
"\n",
"学習ジョブの状態をよく把握するために、アルゴリズムに対するメトリクスを定義します。この定義をPyTorch Estimatorオブジェクトに渡すと、自動でメトリクスを取得します。\n",
"\n",
"以下のように正規表現でフィルターをかけ、追跡したいメトリクスを特定してください。今回はモデルの精度は確認しませんが、SageMaker Studio上で学習ジョブの詳細を確認するとこれらのメトリクスが表示されます。"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"metric_definitions=[{\n",
" \"Name\": \"loss\",\n",
" \"Regex\": \".*loss:\\s([0-9\\\\.]+)\\s*\"\n",
" },\n",
" {\n",
" \"Name\": \"loss_classifier\",\n",
" \"Regex\": \".*loss_cls:\\s([0-9\\\\.]+)\\s*\"\n",
" },\n",
" {\n",
" \"Name\": \"loss_box_reg\",\n",
" \"Regex\": \".*loss_box_reg:\\s([0-9\\\\.]+)\\s*\"\n",
" },\n",
" {\n",
" \"Name\": \"loss_mask\",\n",
" \"Regex\": \".*loss_mask:\\s([0-9\\\\.]+)\\s*\"\n",
" },\n",
" {\n",
" \"Name\": \"loss_objectness\",\n",
" \"Regex\": \".*loss_objectness:\\s([0-9\\\\.]+)\\s*\"\n",
" },\n",
" {\n",
" \"Name\": \"loss_rpn_box_reg\",\n",
" \"Regex\": \".*loss_rpn_box_reg:\\s([0-9\\\\.]+)\\s*\"\n",
" }, \n",
" {\n",
" \"Name\": \"overall_training_speed\",\n",
" \"Regex\": \".*Overall training speed:\\s([0-9\\\\.]+)\\s*\"\n",
" },\n",
" {\n",
" \"Name\": \"lr\", \n",
" \"Regex\": \".*lr:\\s([0-9\\\\.]+)\\s*\"\n",
" },\n",
" {\n",
" \"Name\": \"iter\", \n",
" \"Regex\": \".*iter:\\s([0-9\\\\.]+)\\s*\"\n",
" },\n",
" {\n",
" \"Name\": \"avg iter/s\", \n",
" \"Regex\": \".*avg iter/s:\\s([0-9\\\\.]+)\\s*\"\n",
" },\n",
"]"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## 3. 複数GPUを持つインスタンス1つで学習する場合 \n",
"\n",
"`Estimator`というクラス(を継承した`PyTorch`クラス)に対して、学習ジョブで使うインスタンスの種類と数を選びます。ここでは、まずはml.p3.16xlargeインスタンス1つ(8つのGPU)で1000イテレーションしてみて、どのくらいの時間がかかるかみてみましょう。\n",
"\n",
"学習用スクリプトは`train_pytorch_single_maskrcnn.py`ファイルを参照してください。まだ学習スクリプト内でSageMaker Distributed Data Parallel Libraryをimportする必要はありませんが、1つのインスタンスに含まれる複数GPUを活用するため`PyTorch`オブジェクトに`distribution`の引数を設定しておく必要があります。\n",
"\n",
"ここで大切なのは、ロスが収束しているかを現時点では気にしないことです。分散学習をする際は、まずは速くイテレーションを回すことができることを確認した上で、必要なモデル精度を出すためにバッチサイズや学習率などのチューニングを行ってください。これは、小さなスケールで最適なパラメータも、スケールを大きくすると別のパラメータが最適になる場合があるからです。"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"import os\n",
"import time\n",
"from sagemaker.pytorch import PyTorch\n",
"from sagemaker.debugger import ProfilerConfig"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# SageMaker Debuggerを活用するため\n",
"profiler_config = ProfilerConfig(system_monitor_interval_millis=500)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# ml.p3.16xlarge, ml.p3dn.24xlarge, ml.p4d.24xlargeのみ利用可能です\n",
"instance_type = \"ml.p3.16xlarge\"\n",
"# ここではまず1つのインスタンスで試す\n",
"instance_count = 1\n",
"# ビルドしたイメージのURIを取得します\n",
"docker_image = f\"{account}.dkr.ecr.{region}.amazonaws.com/{image}:{tag}\"\n",
"username = 'AWS'\n",
"job_name = f'single-p3-16xlarge-{int(time.time())}'\n",
"# このyamlファイルでバッチサイズやイテレーションの長さを定義しています\n",
"# YACSで設定管理をしています: https://github.com/rbgirshick/yacs\n",
"config_file = 'e2e_mask_rcnn_R_50_FPN_1x_16GPU_4bs.yaml'"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"hyperparameters = {\n",
" \"config-file\": config_file,\n",
" \"skip-test\": \"\",\n",
" \"seed\": 987,\n",
" \"dtype\": \"float16\",\n",
" \"spot_ckpt\":f\"s3://{bucket}/pretrained_weights/R-50.pkl\"\n",
"}"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"estimator = PyTorch(entry_point='train_pytorch_single_maskrcnn.py',\n",
" role=role,\n",
" image_uri=docker_image,\n",
" source_dir='.',\n",
" instance_count=instance_count,\n",
" instance_type=instance_type,\n",
" framework_version='1.8.0',\n",
" py_version='py36',\n",
" sagemaker_session=sagemaker_session,\n",
" metric_definitions = metric_definitions,\n",
" hyperparameters=hyperparameters,\n",
" # プロファイリングには必須の設定!\n",
" profiler_config=profiler_config,\n",
" # 複数GPUを持つml.p3.16xlargeを有効活用するために\n",
" # distribution戦略を設定する必要があります\n",
" distribution={'smdistributed':{\n",
" 'dataparallel':{\n",
" 'enabled': True\n",
" }\n",
" }\n",
" }\n",
" )"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"train_s3 = f's3://{bucket}/fsx_sync/train-coco/coco/'\n",
"data_channels = { 'train': train_s3 }"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"estimator.fit(inputs=data_channels, job_name=job_name, wait=False)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### 3.1 SageMaker Debuggerでプロファイリングする \n",
"\n",
"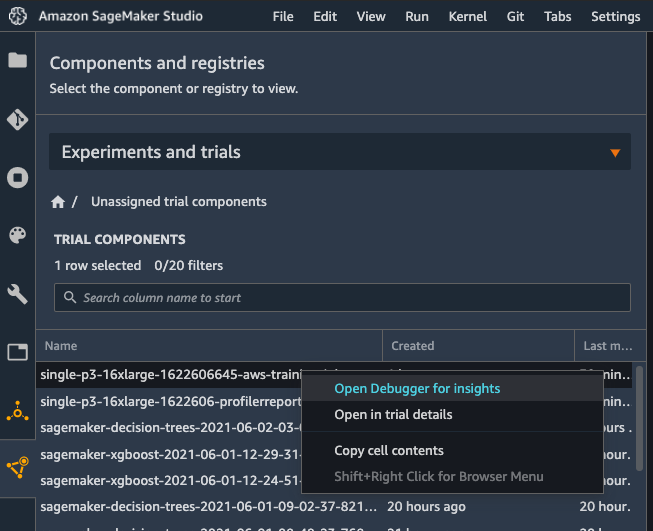\n",
"\n",
"SageMaker Studio左側のメニューにある一番下のアイコンから、該当する学習ジョブを探して、右クリックをして「Open Debugger for Insights」を選択すると、プロファイラーの(途中)結果を確認することができます。\n",
"\n",
"\n",
"\n",
"Insightsを確認すると、自動生成されたプロファイリングレポートが見れ、CPU、IO、バッチサイズ、GPUメモリなどのボトルネックを探すのに役立ちます。今回は、GPUの使用率が低かったので、バッチサイズを上げたり、GPUに待ち時間を作る他の原因がないか調査します。\n",
"\n",
"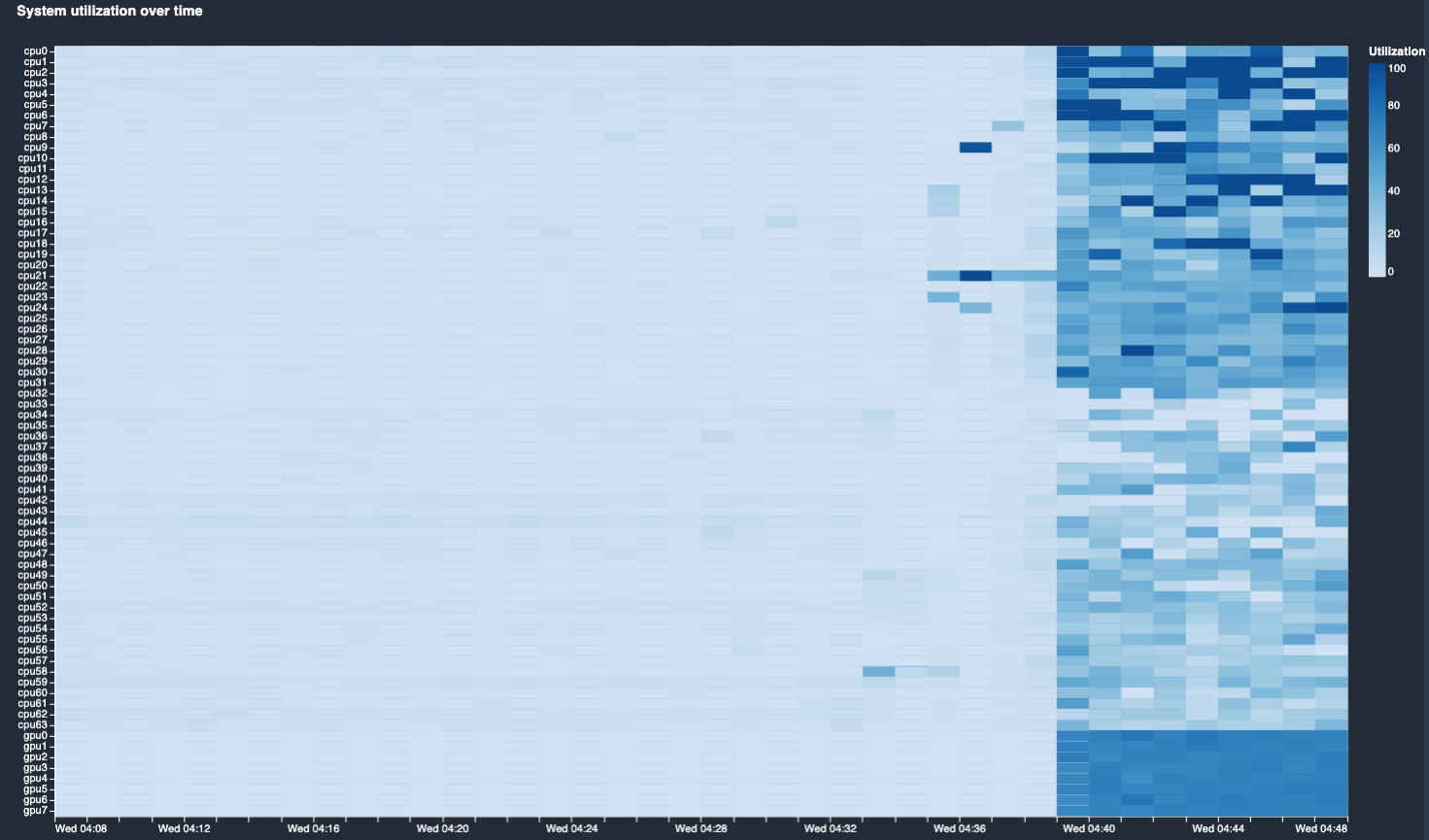\n",
"\n",
"Nodesタブをクリックすると、学習中にどれくらいCPUとGPUを使用できていたかが可視化できて便利です。今回の場合、S3からデータをダウンロードするのに待ち時間が生じて、CPUとGPUが効率的に活用できていないことが分かります。\n",
"\n",
"今回は、ファイルシステムをマウントすることで対処してみます。また、複数インスタンスをフル活用して1000イテレーションがどれくらい短縮できるか試してみましょう。"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## 4. 複数GPUを持つインスタンス複数で学習する場合 \n",
"\n",
"`train_pytorch_single_maskrcnn.py`と`train_pytorch_smdataparallel_maskrcnn.py`を比べて、通常の学習スクリプトを分散学習用に書き換える部分を確認してください。\n",
"\n",
"ポイントとしては以下の3つです。\n",
"\n",
"1. SageMaker Data Parallel Libraryをimportする\n",
"\n",
"```python\n",
"from smdistributed.dataparallel.torch.parallel.distributed import DistributedDataParallel as DDP\n",
"import smdistributed.dataparallel.torch.distributed as dist\n",
"# ここでプロセスの初期化を行います\n",
"dist.init_process_group()\n",
"```\n",
"\n",
"2. モデルを`DistributedDataParallel`に渡す\n",
"\n",
"```python\n",
"model = DDP(model, device_ids=[dist.get_local_rank()], broadcast_buffers=False)\n",
"```\n",
"\n",
"3. ログは1つのインスタンスが代表して出力する\n",
"\n",
"通常、以下のように、`rank == 0`となるインスタンスを代表として定め、ログを出力させる。\n",
"```python\n",
"if dist.get_rank() ==0:\n",
" map_results, raw_results = results[0]\n",
" bbox_map = map_results.results[\"bbox\"]['AP']\n",
" segm_map = map_results.results[\"segm\"]['AP']\n",
" else:\n",
" bbox_map = 0.\n",
" segm_map = 0.\n",
"```"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## 5. Amazon FSx for Lustreを使ってデータダウンロードとIOを加速する \n",
"\n",
"こうしたダウンロードによる待ち時間の発生を軽減させるために、AWSのファイルシステムにデータを保存して、学習インスタンスにファイルシステムをマウントすることで合計学習時間を短縮できます。Amazon Elastic File System (EFS) またはAmazon FSx for Lustreを活用できます。今回はAmazon FSx for Lustreを使います。\n",
"\n",
"これも先ほどと同様、使用料金とダウンロードにかかる時間を短縮することによるトレードオフで、ファイルシステムのマウントが必要か検討してください。\n",
"\n",
"Amazon EFSの料金は[こちら](https://aws.amazon.com/jp/efs/pricing/?nc1=h_ls)、Amazon FSx for Lustreの料金は[こちら](https://aws.amazon.com/jp/fsx/lustre/pricing/)を参照してください。\n",
"\n",
"FSx for Lustreを使用するには、VPCサブネットとセキュリティグループを設定しておく必要があります。\n",
"学習用インスタンスがファイルシステムをマウントできるように、セキュリティグループはポート988番を自身のセキュリティグループに向けて開けておく様に注意して下さい。"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"subnet=[''] # VPC内のサブネット1つ\n",
"security_group_ids=['']"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# use boto3 to create FSx\n",
"fsx_response = fsx_client.create_file_system(\n",
" FileSystemType='LUSTRE',\n",
" StorageCapacity=1200,\n",
" StorageType='SSD',\n",
" SubnetIds= subnet,\n",
" SecurityGroupIds= security_group_ids,\n",
" Tags=[\n",
" {\n",
" 'Key': 'Name',\n",
" 'Value': 'COCO-storage'\n",
" },\n",
" ],\n",
" LustreConfiguration={\n",
" 'WeeklyMaintenanceStartTime': '7:03:00',\n",
" 'ImportPath': f's3://{bucket}/fsx_sync/train-coco/coco/',\n",
" 'ImportedFileChunkSize': 1024,\n",
" 'DeploymentType': 'PERSISTENT_1', # |'SCRATCH_1' |'SCRATCH_2' # PERSISTENT means the storage in FSx will be persistent, SCRATCH indicates the storage is temporary\n",
" 'AutoImportPolicy': 'NEW', # 'NONE'| |'NEW_CHANGED' # this policy is how often data will be imported to FSx from S3\n",
" 'PerUnitStorageThroughput':200 # this is specific to PERSISTENT storage, not required for temporary\n",
" }\n",
" )\n",
"\n",
"fsx_response"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"file_system_id = fsx_response['FileSystem']['FileSystemId'] # FSx file system ID with your training dataset. Example: 'fs-0bYYYYYY'\n",
"mount_name = fsx_response['FileSystem']['LustreConfiguration']['MountName']"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"estimator = PyTorch(entry_point='train_pytorch_smdataparallel_maskrcnn.py',\n",
" role=role,\n",
" image_uri=docker_image,\n",
" source_dir='.',\n",
" instance_count=instance_count,\n",
" instance_type=instance_type,\n",
" framework_version='1.8.0',\n",
" py_version='py36',\n",
" sagemaker_session=sagemaker_session,\n",
" metric_definitions = metric_definitions,\n",
" hyperparameters=hyperparameters,\n",
" subnets=subnet,\n",
" security_group_ids=security_group_ids,\n",
" profiler_config=profiler_config,\n",
" distribution={'smdistributed':{\n",
" 'dataparallel':{\n",
" 'enabled': True\n",
" }\n",
" }\n",
" }\n",
" )"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Configure FSx Input for your SageMaker Training job\n",
"\n",
"from sagemaker.inputs import FileSystemInput\n",
"file_system_directory_path = f'/{mount_name}/fsx_sync/train-coco/coco'\n",
"file_system_access_mode = 'ro'\n",
"file_system_type = 'FSxLustre'\n",
"train_fs = FileSystemInput(file_system_id=file_system_id,\n",
" file_system_type=file_system_type,\n",
" directory_path=file_system_directory_path,\n",
" file_system_access_mode=file_system_access_mode)\n",
"data_channels = {'train': train_fs}"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Submit SageMaker training job\n",
"job_name = f'pytorch-smdataparallel-mrcnn-fsx-{int(time.time())}'\n",
"estimator.fit(inputs=data_channels, job_name=job_name, wait=False)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## 最後に \n",
"同様にSageMaker Debugger Insightsを見て、プロファイリングの結果を確認してみてください。学習時間が短縮されているのがわかるはずです。\n",
"\n",
"適宜Suggestionsに従って、バッチサイズ、学習率やインスタンスタイプとその数を調整してください。\n",
"\n",
"同時に、よりIO効率の良いTFRecordやMXNet RecordIOなどのデータフォーマットへの変換や、LARSをはじめとした分散学習時の学習率スケージュリング、Mixed Precision学習などのテクニックを用いて、最初に期待した並列化効率を達成するまで学習時間を短縮する実験を繰り返して下さい。このノートブックを通じて、SageMakerを活用することで、その実験サイクルをより早く回せるのがご理解いただけたかと思います。\n",
"\n",
"今回のノートブックでは取り上げなかったSageMaker Experimentsを併用して実験管理を行えば、一目でどの試行がうまくいったかが確認できるので、そちらも試してみて下さい。"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# リソースの削除\n",
"# fsx_client.delete_file_system(file_system_id)\n",
"# bucket.objects.filter(Prefix=\"fsx_sync/\").delete()"
]
}
],
"metadata": {
"instance_type": "ml.g4dn.xlarge",
"kernelspec": {
"display_name": "Python 3 (PyTorch 1.6 Python 3.6 GPU Optimized)",
"language": "python",
"name": "python3__SAGEMAKER_INTERNAL__arn:aws:sagemaker:ap-northeast-1:102112518831:image/pytorch-1.6-gpu-py36-cu110-ubuntu18.04-v3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.6.13"
}
},
"nbformat": 4,
"nbformat_minor": 4
}