{
"cells": [
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Train a Scikit-Learn model in SageMaker and track with MLFlow"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Intro\n",
"\n",
"The main objective of this notebook is to show how you can integrate Amazon SageMaker and MLFlow and MLFlow with SageMaker Experiments.\n",
"\n",
"## Pre-Requisites\n",
"\n",
"In order to run successfully this notebook, you must have prepared the infrastructure using CDK, which setups up for you the MLFlow server in an isolated VPC. When running this example in the SageMaker Notebook instance provisioned via CDK, you need to have access to the URI of the MLFlow server we will use for tracking purposes. In our case, this corresponds to the `HTTP API Gateway` endpoint that exposes our MLFlow server reacheable via a `PrivateLink` and have a SageMaker execution role with permissions to access the secret in `Amazon SecretsManager` from where we retrieve the username and password to interact with the MLFlow server.\n",
"\n",
"This notebook runs on SageMaker Studio using the `Base Python 2.0` image on a `Python 3` kernel.\n",
"\n",
"## The Machine Learning Problem\n",
"\n",
"In this example, we will solve a regression problem which aims to answer the question: \"what is the expected price of a house in the California area?\". The target variable is the house value for California districts, expressed in hundreds of thousands of dollars ($100,000).\n",
"\n",
"## Install required and/or update libraries\n",
"\n",
"At the time of writing, we have used the `sagemaker` SDK version 2. The MLFlow SDK library used is the one corresponding to our MLFlow server version, i.e., `2.3.1`"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"!pip install -q --upgrade pip\n",
"!pip install sagemaker sagemaker-experiments scikit-learn==1.0.1 mlflow==2.3.1 boto3"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Let's start by specifying:\n",
"\n",
"- The S3 bucket and prefix that you want to use for training and model data. This should be within the same region as the notebook instance, training, and hosting.\n",
"- The IAM role arn used to give training and hosting access to your data. See the [documentation](https://docs.aws.amazon.com/sagemaker/latest/dg/using-identity-based-policies.html) for more details on creating these. Note, if a role not associated with the current notebook instance, or more than one role is required for training and/or hosting, please replace `sagemaker.get_execution_role()` with a the appropriate full IAM role arn string(s).\n",
"- The tracking URI where the MLFlow server runs\n",
"- The experiment name as the logical entity to keep our tests grouped and organized."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"import os\n",
"import pandas as pd\n",
"import json\n",
"import random\n",
"import boto3\n",
"\n",
"## SageMaker and SKlearn libraries\n",
"import sagemaker\n",
"from sagemaker.sklearn.estimator import SKLearn\n",
"from sagemaker.tuner import IntegerParameter, HyperparameterTuner\n",
"\n",
"## SKLearn libraries\n",
"from sklearn.datasets import fetch_california_housing\n",
"from sklearn.model_selection import train_test_split\n",
"\n",
"## MLFlow libraries\n",
"import mlflow\n",
"from mlflow.tracking.client import MlflowClient\n",
"import mlflow.sagemaker\n",
"\n",
"cloudformation_client = boto3.client('cloudformation')\n",
"\n",
"sess = sagemaker.Session()\n",
"role = sagemaker.get_execution_role()\n",
"bucket = sess.default_bucket()\n",
"region = sess.boto_region_name\n",
"account = role.split(\"::\")[1].split(\":\")[0]\n",
"tracking_uri = cloudformation_client.describe_stacks(StackName='HttpGatewayStack')['Stacks'][0]['Outputs'][0]['OutputValue']\n",
"\n",
"mlflow_secret_name = \"mlflow-server-credentials\"\n",
"experiment_name = 'DEMO-sagemaker-mlflow'\n",
"model_name = 'california-housing-model'\n",
"\n",
"print('SageMaker role: {}'.format(role.split(\"/\")[-1]))\n",
"print('bucket: {}'.format(bucket))\n",
"print('Account: {}'.format(account))\n",
"print(\"Using AWS Region: {}\".format(region))\n",
"print(\"MLflow server URI: {}\".format(tracking_uri))\n",
"print(\"MLFLOW_SECRET_NAME: {}\".format(mlflow_secret_name))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Data Preparation\n",
"We load the dataset from sklearn, then split the data in training and testing datasets, where we allocate 75% of the data to the training dataset, and the remaining 25% to the traning dataset.\n",
"\n",
"The variable `target` is what we intend to estimate, which represents the value of a house, expressed in hundreds of thousands of dollars ($100,000)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# we use the California housing dataset \n",
"data = fetch_california_housing()\n",
"\n",
"X_train, X_test, y_train, y_test = train_test_split(data.data, data.target, test_size=0.25, random_state=42)\n",
"\n",
"trainX = pd.DataFrame(X_train, columns=data.feature_names)\n",
"trainX['target'] = y_train\n",
"\n",
"testX = pd.DataFrame(X_test, columns=data.feature_names)\n",
"testX['target'] = y_test"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Finally, we save a copy of the data locally, as well as in S3. The data stored in S3 will be used SageMaker to train and test the model."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# save the data locally\n",
"trainX.to_csv('california_train.csv', index=False)\n",
"testX.to_csv('california_test.csv', index=False)\n",
"\n",
"# save the data to S3.\n",
"train_path = sess.upload_data(path='california_train.csv', bucket=bucket, key_prefix='sagemaker/sklearncontainer')\n",
"test_path = sess.upload_data(path='california_test.csv', bucket=bucket, key_prefix='sagemaker/sklearncontainer')"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Setup SageMaker Experiments\n",
"\n",
"SageMaker Experiments is an AWS service for tracking machine learning Experiments. The SageMaker Experiments Python SDK is a high-level interface to this service that helps you track Experiment information using Python.\n",
"\n",
"Conceptually, these are the following entities within `SageMaker Experiments`:\n",
"\n",
"* Experiment: A collection of related Trials. Add Trials to an Experiment that you wish to compare together.\n",
"* Trial: A description of a multi-step machine learning workflow. Each step in the workflow is described by a TrialComponent.\n",
"* TrialComponent: A description of a single step in a machine learning workflow.\n",
"* Tracker: A Python context-manager for logging information about a single TrialComponent.\n",
"\n",
"When running jobs (both training and processing ones) in the SageMaker managed infrastructure, SageMaker creates automatically a TrialComponent. TrialComponents includes by default jobs metadata and lineage information about the input and output data, models artifacts and metrics (for training jobs), and within your training script these data can be further enriched.\n",
"\n",
"We want to show how you can easily enable a two-way interaction between MLflow and SageMaker Experiments.\n",
"\n",
"Let us first create an `Experiment` and a `Trial`. These two entities are used to keep your experimentation organized."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"from smexperiments.experiment import Experiment\n",
"from smexperiments.trial import Trial\n",
"from smexperiments.trial_component import TrialComponent\n",
"from smexperiments.tracker import Tracker\n",
"\n",
"import time\n",
"\n",
"try:\n",
" my_experiment = Experiment.load(experiment_name=experiment_name)\n",
" print(\"existing experiment loaded\")\n",
"except Exception as ex:\n",
" if \"ResourceNotFound\" in str(ex):\n",
" my_experiment = Experiment.create(\n",
" experiment_name = experiment_name,\n",
" description = \"MLFlow and SageMaker integration\"\n",
" )\n",
" print(\"new experiment created\")\n",
" else:\n",
" print(f\"Unexpected {ex}=, {type(ex)}\")\n",
" print(\"Dont go forward!\")\n",
" raise\n",
"\n",
"trial_name = \"trial-v1\"\n",
"\n",
"try:\n",
" my_first_trial = Trial.load(trial_name=trial_name)\n",
" print(\"existing trial loaded\")\n",
"except Exception as ex:\n",
" if \"ResourceNotFound\" in str(ex):\n",
" my_first_trial = Trial.create(\n",
" experiment_name=experiment_name,\n",
" trial_name=trial_name,\n",
" )\n",
" print(\"new trial created\")\n",
" else:\n",
" print(f\"Unexpected {ex}=, {type(ex)}\")\n",
" print(\"Dont go forward!\")\n",
" raise\n",
"\n",
"create_date = time.strftime(\"%Y-%m-%d-%H-%M-%S\")\n",
"\n",
"experiment_config = {\n",
" \"ExperimentName\": experiment_name,\n",
" \"TrialName\": trial_name,\n",
"}"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Training\n",
"\n",
"For this example, we use the `SKlearn` framework in script mode with SageMaker. Let us explore in more details the different components we need to define.\n",
"\n",
"### Traning script and SageMaker environment\n",
"\n",
"The `./source_dir/train.py` script provides all the code we need for training a SageMaker model. The training script is very similar to a training script you might run outside of SageMaker, but you can access useful properties about the training environment through various environment variables, such as:\n",
"\n",
"* `SM_MODEL_DIR`: A string representing the path to the directory to write model artifacts to. These artifacts are uploaded to S3 for model hosting.\n",
"* `SM_CHANNEL_TRAIN`: A string representing the path to the directory containing data in the 'training' channel.\n",
"* `SM_CHANNEL_TEST`: A string representing the path to the directory containing data in the 'testing' channel.\n",
"\n",
"\n",
"For more information about training environment variables, please visit \n",
"[SageMaker Training Toolkit](https://github.com/aws/sagemaker-training-toolkit/blob/master/ENVIRONMENT_VARIABLES.md).\n",
"\n",
"We want to highlight in particular `SM_TRAINING_ENV` since it provides all the training information as a JSON-encoded dictionary (see [here](https://github.com/aws/sagemaker-training-toolkit/blob/master/ENVIRONMENT_VARIABLES.md#sm_training_env) for more details).\n",
"\n",
"#### Hyperparmeters\n",
"\n",
"We are using the `RandomForestRegressor` algorithm from the SKlearn framework. For the purpose of this exercise, we are only using a subset of hyperparameters supported by this algorithm, i.e. `n-estimators` and `min-samples-leaf`\n",
"\n",
"If you would like to know more the different hyperparmeters for this algorithm, please refer to the [`RandomForestRegressor` official documentation](https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.RandomForestRegressor.html).\n",
"\n",
"Furthermore, it is important to note that for the purpose of this excercise, we are essentially omitting completely the feature engineering step, which is an essential step in any machine learning problem.\n",
"\n",
"#### MLFlow interaction\n",
"\n",
"To interact with the MLFlow server, we use the mlflow SDK, which allows us to set the tracking URI and the experiment name. One this initial setup is completed, we can store the parameters used (`mlflow.log_params(params)`), the model that is generated (`mlflow.sklearn.log_model(model, \"model\")`) with its associated metrics (`mlflow.log_metric(f'AE-at-{str(q)}th-percentile', np.percentile(a=abs_err, q=q))`).\n",
"\n",
"TODO: explain the `mlflow.autolog()` and the System Tags (add link) and how to overwrite them to have the right reference in SageMaker\n",
"\n",
"#### SageMaker"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"!pygmentize ./source_dir/train.py"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### SKlearn container\n",
"\n",
"For this example, we use the `SKlearn` framework in script mode with SageMaker. For more information please refere to [the official documentation](https://sagemaker.readthedocs.io/en/stable/frameworks/sklearn/using_sklearn.html)\n",
"\n",
"Our training script makes use of other 3rd party libraries, i.e. `mlflow`, which are not installed by default in the `Sklearn` container SageMaker provides. However, this can be easily overcome by supplying a `requirement.txt` file in the `source_dir` folder, which then SageMaker will `pip`-install before executing the training script.\n",
"\n",
"### Metric definition\n",
"\n",
"SageMaker emits every log to CLoudWatch. Since we are using scripting mode, we need to specify a metric definition object to define the format of the metric we are interested in via regex, so that SageMaker knows how to extract this metric from the CloudWatch logs of the training job.\n",
"\n",
"In our case our custom metric is as follow\n",
"\n",
"```python\n",
"metric_definitions = [{'Name': 'median-AE', 'Regex': \"AE-at-50th-percentile: ([0-9.]+).*$\"}]\n",
"```"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"metric_definitions = [{'Name': 'median-AE', 'Regex': \"AE-at-50th-percentile: ([0-9.]+).*$\"}]\n",
"\n",
"hyperparameters = {\n",
" 'tracking_uri': tracking_uri,\n",
" 'experiment_name': experiment_name,\n",
" 'secret_name': mlflow_secret_name,\n",
" 'region': region,\n",
" 'n-estimators': 100,\n",
" 'min-samples-leaf': 3,\n",
" 'features': 'MedInc HouseAge AveRooms AveBedrms Population AveOccup',\n",
" 'target': 'target'\n",
"}\n",
"\n",
"estimator = SKLearn(\n",
" entry_point='train.py',\n",
" source_dir='source_dir',\n",
" role=role,\n",
" metric_definitions=metric_definitions,\n",
" hyperparameters=hyperparameters,\n",
" instance_count=1,\n",
" instance_type='ml.m5.large', # to run SageMaker in a managed infrastructure\n",
" framework_version='1.0-1',\n",
" base_job_name='mlflow',\n",
")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Now we are ready to execute the training locally, which in turn will save its execution data to the MLFlow server. After initializing an `SKlearn` estimator object, all we need to do is to call the `.fit` method specifying where the training and testing data are located."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"estimator.fit({'train':train_path, 'test': test_path}, experiment_config=experiment_config)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### From SageMaker to MLFlow\n",
"\n",
"Load the TrialComponent associate with the `estimator`."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"training_job_name = estimator.latest_training_job.name\n",
"\n",
"trial_component = TrialComponent.load(f\"{training_job_name}-aws-training-job\")\n",
"mlflow_run_url = trial_component.parameters[\"mlflow-run-url\"]"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"from IPython.core.display import HTML\n",
"HTML(\"link to MLFlow run\".format(mlflow_run_url))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### From MLFlow to SageMaker Experiments\n",
"\n",
"Within SageMaker Experiments, we have enriched the TrialComponent with information specific to MLFlow. For example\n",
"\n",
"* the experiment ID in MLFlow\n",
"* the MLFlow run ID corresponding to the SageMaker training job\n",
"* any additional MLFlow parameters and metrics generated by MLFlow\n",
"* the list of output artifacts generated by MLFlow (e.g., the output model) with their full path to S3\n",
"\n",
"A visual inspection of the SageMaker Studio UI for the output artifacts can be seen below\n",
"\n",
"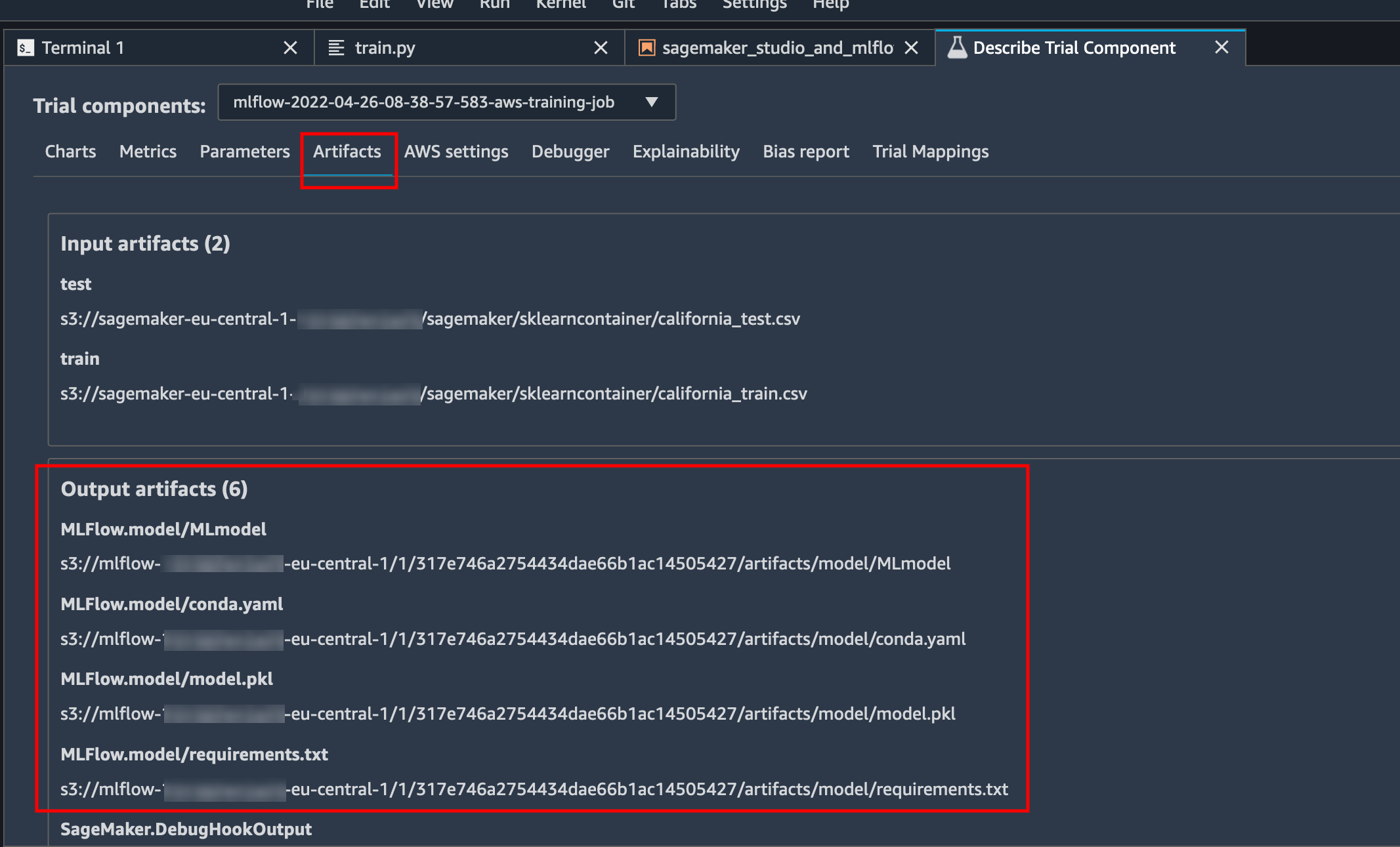"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Register the model to MLFlow\n",
"\n",
"At the end of the training, our model has been saved to the MLflow server and we are ready to register the model, i.e. assign it to a model package and create a version. Please refer to the [official MLFlow documentation](https://www.mlflow.org/docs/latest/model-registry.html) for furthe information."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"def retrieve_credentials(region_name, secret_name):\n",
" session = boto3.session.Session()\n",
" client = session.client(\n",
" service_name='secretsmanager',\n",
" region_name=region_name\n",
" )\n",
" \n",
" kwarg = {'SecretId': secret_name}\n",
" secret = client.get_secret_value(**kwarg)\n",
" credentials = {}\n",
"\n",
" credentials['username'] = json.loads(secret['SecretString'])['username']\n",
" credentials['password'] = json.loads(secret['SecretString'])['password']\n",
" \n",
" return credentials\n",
"\n",
"# set the tracking token env variable will enable the mlflow SDK to set the header \"Authentication: Basic \" to authenticate.\n",
"credentials = retrieve_credentials(region, mlflow_secret_name)\n",
"os.environ['MLFLOW_TRACKING_USERNAME'] = credentials['username']\n",
"os.environ['MLFLOW_TRACKING_PASSWORD'] = credentials['password']"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"mlflow.set_tracking_uri(tracking_uri)\n",
"mlflow.set_experiment(experiment_name)\n",
"client = MlflowClient()\n",
"\n",
"run = mlflow.get_run(run_id=trial_component.parameters[\"run_id\"])\n",
"\n",
"try:\n",
" client.create_registered_model(model_name)\n",
"except:\n",
" print(\"Registered model already exists\")\n",
"\n",
"model_version = client.create_model_version(\n",
" name=model_name,\n",
" source=\"{}/model\".format(run.info.artifact_uri),\n",
" run_id=run.info.run_uuid\n",
")\n",
"\n",
"print(\"model_version: {}\".format(model_version))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Local Predictions\n",
"\n",
"We are now ready to make predictions with our model locally for testing purposes."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# get the model URI from the MLFlow registry\n",
"model_uri = model_version.source\n",
"print(\"Model URI: {}\".format(model_uri))\n",
"\n",
"# Load model as a Sklearn model.\n",
"loaded_model = mlflow.sklearn.load_model(model_uri)\n",
"\n",
"# get a random index to test the prediction from the test data\n",
"index = random.randrange(0, len(testX))\n",
"print(\"Random index value: {}\".format(index))\n",
"\n",
"# Prepare data on a Pandas DataFrame to make a prediction.\n",
"data = testX.drop(['Latitude','Longitude','target'], axis=1).iloc[[index]]\n",
"\n",
"print(\"#######\\nData for prediction \\n{}\".format(data))\n",
"\n",
"y_hat = loaded_model.predict(data)[0]\n",
"y = y_test[index]\n",
"\n",
"print(\"Predicted value: {}\".format(y_hat))\n",
"print(\"Actual value: {}\".format(y))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Tune a Scikit-Learn model in SageMaker and track with MLFlow\n",
"\n",
"At this point, we are going to offload the training to the remote infrastructure managed by SageMaker. We want now to leverage SageMaker's hyperparameter tuning to kick off multiple training jobs with different hyperparameter combinations, to find the set with best model performance. This is an important step in the machine learning process as hyperparameter settings can have a large impact on model accuracy. In this example, we'll use the SageMaker Python SDK to create a hyperparameter tuning job for an SKlearn estimator.\n",
"\n",
"## Training\n",
"We are again using `SKlearn` in script mode, with the same training script we have used in the previous section, i.e. `./source_dir/train.py`."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"hyperparameters = {\n",
" 'tracking_uri': tracking_uri,\n",
" 'experiment_name': experiment_name,\n",
" 'secret_name': mlflow_secret_name,\n",
" 'region': region,\n",
" 'features': 'MedInc HouseAge AveRooms AveBedrms Population AveOccup',\n",
" 'target': 'target'\n",
"}\n",
"\n",
"metric_definitions = [{'Name': 'median-AE', 'Regex': \"AE-at-50th-percentile: ([0-9.]+).*$\"}]\n",
"\n",
"estimator = SKLearn(\n",
" entry_point='train.py',\n",
" source_dir='source_dir',\n",
" role=role,\n",
" instance_count=1,\n",
" instance_type='ml.m5.xlarge',\n",
" hyperparameters=hyperparameters,\n",
" metric_definitions=metric_definitions,\n",
" framework_version='1.0-1',\n",
" py_version='py3'\n",
")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Hyperparameter tuning\n",
"\n",
"Once we've defined our estimator we can specify the hyperparameters we'd like to tune and their possible values. We have three different types of hyperparameters.\n",
"- Categorical parameters need to take one value from a discrete set. We define this by passing the list of possible values to `CategoricalParameter(list)`\n",
"- Continuous parameters can take any real number value between the minimum and maximum value, defined by `ContinuousParameter(min, max)`\n",
"- Integer parameters can take any integer value between the minimum and maximum value, defined by `IntegerParameter(min, max)`\n",
"\n",
"*Note, if possible, it's almost always best to specify a value as the least restrictive type. For example, tuning `thresh` as a continuous value between 0.01 and 0.2 is likely to yield a better result than tuning as a categorical parameter with possible values of 0.01, 0.1, 0.15, or 0.2.*"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"hyperparameter_ranges = {\n",
" 'n-estimators': IntegerParameter(50, 200),\n",
" 'min-samples-leaf': IntegerParameter(1, 10)\n",
"}"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Next we'll specify the objective metric that we'd like to tune and its definition. This refers to the regular expression (Regex) needed to extract that metric from the CloudWatch logs of our training job we defined earlier, as well as whether we are looking to `Maximize` or `Minimize` the objective metric."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"objective_metric_name = 'median-AE'\n",
"objective_type = 'Minimize'"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Now, we'll create a `HyperparameterTuner` object, which we pass:\n",
"- The SKLearn estimator we created earlier\n",
"- Our hyperparameter ranges\n",
"- Objective metric name and type\n",
"- Number of training jobs to run in total and how many training jobs should be run simultaneously. More parallel jobs will finish tuning sooner, but may sacrifice accuracy. We recommend you set the parallel jobs value to less than 10% of the total number of training jobs (we'll set it higher just for this example to keep it short)."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"max_jobs = 5\n",
"max_parallel_jobs = 5\n",
"\n",
"tuner = HyperparameterTuner(estimator,\n",
" objective_metric_name,\n",
" hyperparameter_ranges,\n",
" metric_definitions,\n",
" max_jobs=max_jobs,\n",
" max_parallel_jobs=max_parallel_jobs,\n",
" objective_type=objective_type,\n",
" base_tuning_job_name='mlflow')"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"And finally, we can start our tuning job by calling `.fit()` and passing in the S3 paths to our train and test datasets."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"tuner.fit({'train':train_path, 'test': test_path})"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"We can now query the MLFlow server to see the different models and their metrics that have been stored."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Deploy an MLflow model with SageMaker\n",
"\n",
"We are finally ready to deploy a MLFlow model to a SageMaker hosted endpoint ready to be consumed for online predictions."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Build MLflow docker image to serve the model with SageMaker\n",
"\n",
"We first need to build a new MLflow Sagemaker image, assign it a name, and push to ECR.\n",
"\n",
"The `mlflow sagemaker build-and-push-container` function does exactly that. It first builds an MLflow Docker image. The image is built locally and it requires Docker to run. Then, the image is pushed to ECR under current active AWS account and to current active AWS region. More information on this command can be found in the official [MLflow CLI documentation for SageMaker](https://www.mlflow.org/docs/latest/cli.html#mlflow-sagemaker).\n",
"\n",
"Make sure that you the `mlflow-pyfunc` container has already been pushed to `ECR` from the `Cloud9` environment from where deployed the CDK stacks."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# URL of the ECR-hosted Docker image the model should be deployed into: make sure to include the tag 2.3.1\n",
"image_uri = \"{}.dkr.ecr.{}.amazonaws.com/mlflow-pyfunc:{}\".format(account, region, mlflow.__version__)\n",
"print(\"image URI: {}\".format(image_uri))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Deploy a SageMaker endpoint with our scikit-learn model\n",
"\n",
"We first need to get the best performing model stored in MLFlow. Once it has been identified, we register it to the Registry and then deploy to a SageMaker managed endpoint via the MLflow SDK. More information can be found [here](https://www.mlflow.org/docs/latest/python_api/mlflow.sagemaker.html)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"best_training_job_name = tuner.best_training_job()\n",
"\n",
"best_trial_component = TrialComponent.load(f\"{best_training_job_name}-aws-training-job\")\n",
"best_mlflow_run_url = best_trial_component.parameters[\"mlflow-run-url\"]"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"from IPython.core.display import HTML\n",
"HTML(\"MLFlow run corresponding to best training job\".format(best_mlflow_run_url))"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"experiment = mlflow.get_experiment_by_name(experiment_name)\n",
"experiment_id = experiment.experiment_id\n",
"\n",
"run = mlflow.get_run(run_id=best_trial_component.parameters[\"run_id\"])\n",
"\n",
"try:\n",
" client.create_registered_model(model_name)\n",
"except:\n",
" print(\"Registered model already exists\")\n",
"\n",
"model_version = client.create_model_version(\n",
" name=model_name,\n",
" source=\"{}/model\".format(run.info.artifact_uri),\n",
" run_id=run.info.run_uuid\n",
")\n",
"\n",
"print(\"model_version: {}\".format(model_version))"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"from mlflow.deployments import get_deploy_client\n",
"\n",
"model_uri = \"models:/{}/{}\".format(model_version.name, model_version.version)\n",
"\n",
"endpoint_name = 'california-housing'\n",
"\n",
"config={\n",
" 'execution_role_arn': role,\n",
" 'image_url': image_uri,\n",
" 'instance_type': 'ml.m5.xlarge',\n",
" 'instance_count': 1,\n",
" 'region_name': region\n",
"}\n",
"\n",
"client = get_deploy_client(\"sagemaker\")\n",
"\n",
"client.create_deployment(\n",
" name=endpoint_name,\n",
" model_uri=model_uri,\n",
" flavor='python_function',\n",
" config=config\n",
")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Predict\n",
"\n",
"We are now ready to make predictions again the endpoint."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# load california dataset\n",
"data = pd.read_csv('./california_test.csv')\n",
"df_y = data[['target']]\n",
"df = data.drop(['Latitude','Longitude','target'], axis=1)\n",
"\n",
"client = get_deploy_client(f\"sagemaker:/{region}\")\n",
"\n",
"for _ in range(0,2):\n",
" # Randomly pick a row to test the prediction\n",
" index = random.randrange(0, len(df_y))\n",
" payload = df.iloc[[index]]\n",
" y = df_y['target'][index]\n",
" print(f\"payload: {payload}\")\n",
" prediction = client.predict(endpoint_name, payload)\n",
" print(f'This is the real value of the housing we want to predict (expressed in 100.000$): {y}')\n",
" print(f\"This is the predicted value from our model (expressed in 100.000$): {prediction['predictions'][0]}\")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Delete endpoint\n",
"\n",
"In order to avoid unwanted costs, make sure you delete the endpoint."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"client.delete_deployment(endpoint_name, config=config)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Delete experiments (Optional)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"my_experiment.delete_all(action=\"--force\")"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": []
}
],
"metadata": {
"availableInstances": [
{
"_defaultOrder": 0,
"_isFastLaunch": true,
"category": "General purpose",
"gpuNum": 0,
"hideHardwareSpecs": false,
"memoryGiB": 4,
"name": "ml.t3.medium",
"vcpuNum": 2
},
{
"_defaultOrder": 1,
"_isFastLaunch": false,
"category": "General purpose",
"gpuNum": 0,
"hideHardwareSpecs": false,
"memoryGiB": 8,
"name": "ml.t3.large",
"vcpuNum": 2
},
{
"_defaultOrder": 2,
"_isFastLaunch": false,
"category": "General purpose",
"gpuNum": 0,
"hideHardwareSpecs": false,
"memoryGiB": 16,
"name": "ml.t3.xlarge",
"vcpuNum": 4
},
{
"_defaultOrder": 3,
"_isFastLaunch": false,
"category": "General purpose",
"gpuNum": 0,
"hideHardwareSpecs": false,
"memoryGiB": 32,
"name": "ml.t3.2xlarge",
"vcpuNum": 8
},
{
"_defaultOrder": 4,
"_isFastLaunch": true,
"category": "General purpose",
"gpuNum": 0,
"hideHardwareSpecs": false,
"memoryGiB": 8,
"name": "ml.m5.large",
"vcpuNum": 2
},
{
"_defaultOrder": 5,
"_isFastLaunch": false,
"category": "General purpose",
"gpuNum": 0,
"hideHardwareSpecs": false,
"memoryGiB": 16,
"name": "ml.m5.xlarge",
"vcpuNum": 4
},
{
"_defaultOrder": 6,
"_isFastLaunch": false,
"category": "General purpose",
"gpuNum": 0,
"hideHardwareSpecs": false,
"memoryGiB": 32,
"name": "ml.m5.2xlarge",
"vcpuNum": 8
},
{
"_defaultOrder": 7,
"_isFastLaunch": false,
"category": "General purpose",
"gpuNum": 0,
"hideHardwareSpecs": false,
"memoryGiB": 64,
"name": "ml.m5.4xlarge",
"vcpuNum": 16
},
{
"_defaultOrder": 8,
"_isFastLaunch": false,
"category": "General purpose",
"gpuNum": 0,
"hideHardwareSpecs": false,
"memoryGiB": 128,
"name": "ml.m5.8xlarge",
"vcpuNum": 32
},
{
"_defaultOrder": 9,
"_isFastLaunch": false,
"category": "General purpose",
"gpuNum": 0,
"hideHardwareSpecs": false,
"memoryGiB": 192,
"name": "ml.m5.12xlarge",
"vcpuNum": 48
},
{
"_defaultOrder": 10,
"_isFastLaunch": false,
"category": "General purpose",
"gpuNum": 0,
"hideHardwareSpecs": false,
"memoryGiB": 256,
"name": "ml.m5.16xlarge",
"vcpuNum": 64
},
{
"_defaultOrder": 11,
"_isFastLaunch": false,
"category": "General purpose",
"gpuNum": 0,
"hideHardwareSpecs": false,
"memoryGiB": 384,
"name": "ml.m5.24xlarge",
"vcpuNum": 96
},
{
"_defaultOrder": 12,
"_isFastLaunch": false,
"category": "General purpose",
"gpuNum": 0,
"hideHardwareSpecs": false,
"memoryGiB": 8,
"name": "ml.m5d.large",
"vcpuNum": 2
},
{
"_defaultOrder": 13,
"_isFastLaunch": false,
"category": "General purpose",
"gpuNum": 0,
"hideHardwareSpecs": false,
"memoryGiB": 16,
"name": "ml.m5d.xlarge",
"vcpuNum": 4
},
{
"_defaultOrder": 14,
"_isFastLaunch": false,
"category": "General purpose",
"gpuNum": 0,
"hideHardwareSpecs": false,
"memoryGiB": 32,
"name": "ml.m5d.2xlarge",
"vcpuNum": 8
},
{
"_defaultOrder": 15,
"_isFastLaunch": false,
"category": "General purpose",
"gpuNum": 0,
"hideHardwareSpecs": false,
"memoryGiB": 64,
"name": "ml.m5d.4xlarge",
"vcpuNum": 16
},
{
"_defaultOrder": 16,
"_isFastLaunch": false,
"category": "General purpose",
"gpuNum": 0,
"hideHardwareSpecs": false,
"memoryGiB": 128,
"name": "ml.m5d.8xlarge",
"vcpuNum": 32
},
{
"_defaultOrder": 17,
"_isFastLaunch": false,
"category": "General purpose",
"gpuNum": 0,
"hideHardwareSpecs": false,
"memoryGiB": 192,
"name": "ml.m5d.12xlarge",
"vcpuNum": 48
},
{
"_defaultOrder": 18,
"_isFastLaunch": false,
"category": "General purpose",
"gpuNum": 0,
"hideHardwareSpecs": false,
"memoryGiB": 256,
"name": "ml.m5d.16xlarge",
"vcpuNum": 64
},
{
"_defaultOrder": 19,
"_isFastLaunch": false,
"category": "General purpose",
"gpuNum": 0,
"hideHardwareSpecs": false,
"memoryGiB": 384,
"name": "ml.m5d.24xlarge",
"vcpuNum": 96
},
{
"_defaultOrder": 20,
"_isFastLaunch": false,
"category": "General purpose",
"gpuNum": 0,
"hideHardwareSpecs": true,
"memoryGiB": 0,
"name": "ml.geospatial.interactive",
"supportedImageNames": [
"sagemaker-geospatial-v1-0"
],
"vcpuNum": 0
},
{
"_defaultOrder": 21,
"_isFastLaunch": true,
"category": "Compute optimized",
"gpuNum": 0,
"hideHardwareSpecs": false,
"memoryGiB": 4,
"name": "ml.c5.large",
"vcpuNum": 2
},
{
"_defaultOrder": 22,
"_isFastLaunch": false,
"category": "Compute optimized",
"gpuNum": 0,
"hideHardwareSpecs": false,
"memoryGiB": 8,
"name": "ml.c5.xlarge",
"vcpuNum": 4
},
{
"_defaultOrder": 23,
"_isFastLaunch": false,
"category": "Compute optimized",
"gpuNum": 0,
"hideHardwareSpecs": false,
"memoryGiB": 16,
"name": "ml.c5.2xlarge",
"vcpuNum": 8
},
{
"_defaultOrder": 24,
"_isFastLaunch": false,
"category": "Compute optimized",
"gpuNum": 0,
"hideHardwareSpecs": false,
"memoryGiB": 32,
"name": "ml.c5.4xlarge",
"vcpuNum": 16
},
{
"_defaultOrder": 25,
"_isFastLaunch": false,
"category": "Compute optimized",
"gpuNum": 0,
"hideHardwareSpecs": false,
"memoryGiB": 72,
"name": "ml.c5.9xlarge",
"vcpuNum": 36
},
{
"_defaultOrder": 26,
"_isFastLaunch": false,
"category": "Compute optimized",
"gpuNum": 0,
"hideHardwareSpecs": false,
"memoryGiB": 96,
"name": "ml.c5.12xlarge",
"vcpuNum": 48
},
{
"_defaultOrder": 27,
"_isFastLaunch": false,
"category": "Compute optimized",
"gpuNum": 0,
"hideHardwareSpecs": false,
"memoryGiB": 144,
"name": "ml.c5.18xlarge",
"vcpuNum": 72
},
{
"_defaultOrder": 28,
"_isFastLaunch": false,
"category": "Compute optimized",
"gpuNum": 0,
"hideHardwareSpecs": false,
"memoryGiB": 192,
"name": "ml.c5.24xlarge",
"vcpuNum": 96
},
{
"_defaultOrder": 29,
"_isFastLaunch": true,
"category": "Accelerated computing",
"gpuNum": 1,
"hideHardwareSpecs": false,
"memoryGiB": 16,
"name": "ml.g4dn.xlarge",
"vcpuNum": 4
},
{
"_defaultOrder": 30,
"_isFastLaunch": false,
"category": "Accelerated computing",
"gpuNum": 1,
"hideHardwareSpecs": false,
"memoryGiB": 32,
"name": "ml.g4dn.2xlarge",
"vcpuNum": 8
},
{
"_defaultOrder": 31,
"_isFastLaunch": false,
"category": "Accelerated computing",
"gpuNum": 1,
"hideHardwareSpecs": false,
"memoryGiB": 64,
"name": "ml.g4dn.4xlarge",
"vcpuNum": 16
},
{
"_defaultOrder": 32,
"_isFastLaunch": false,
"category": "Accelerated computing",
"gpuNum": 1,
"hideHardwareSpecs": false,
"memoryGiB": 128,
"name": "ml.g4dn.8xlarge",
"vcpuNum": 32
},
{
"_defaultOrder": 33,
"_isFastLaunch": false,
"category": "Accelerated computing",
"gpuNum": 4,
"hideHardwareSpecs": false,
"memoryGiB": 192,
"name": "ml.g4dn.12xlarge",
"vcpuNum": 48
},
{
"_defaultOrder": 34,
"_isFastLaunch": false,
"category": "Accelerated computing",
"gpuNum": 1,
"hideHardwareSpecs": false,
"memoryGiB": 256,
"name": "ml.g4dn.16xlarge",
"vcpuNum": 64
},
{
"_defaultOrder": 35,
"_isFastLaunch": false,
"category": "Accelerated computing",
"gpuNum": 1,
"hideHardwareSpecs": false,
"memoryGiB": 61,
"name": "ml.p3.2xlarge",
"vcpuNum": 8
},
{
"_defaultOrder": 36,
"_isFastLaunch": false,
"category": "Accelerated computing",
"gpuNum": 4,
"hideHardwareSpecs": false,
"memoryGiB": 244,
"name": "ml.p3.8xlarge",
"vcpuNum": 32
},
{
"_defaultOrder": 37,
"_isFastLaunch": false,
"category": "Accelerated computing",
"gpuNum": 8,
"hideHardwareSpecs": false,
"memoryGiB": 488,
"name": "ml.p3.16xlarge",
"vcpuNum": 64
},
{
"_defaultOrder": 38,
"_isFastLaunch": false,
"category": "Accelerated computing",
"gpuNum": 8,
"hideHardwareSpecs": false,
"memoryGiB": 768,
"name": "ml.p3dn.24xlarge",
"vcpuNum": 96
},
{
"_defaultOrder": 39,
"_isFastLaunch": false,
"category": "Memory Optimized",
"gpuNum": 0,
"hideHardwareSpecs": false,
"memoryGiB": 16,
"name": "ml.r5.large",
"vcpuNum": 2
},
{
"_defaultOrder": 40,
"_isFastLaunch": false,
"category": "Memory Optimized",
"gpuNum": 0,
"hideHardwareSpecs": false,
"memoryGiB": 32,
"name": "ml.r5.xlarge",
"vcpuNum": 4
},
{
"_defaultOrder": 41,
"_isFastLaunch": false,
"category": "Memory Optimized",
"gpuNum": 0,
"hideHardwareSpecs": false,
"memoryGiB": 64,
"name": "ml.r5.2xlarge",
"vcpuNum": 8
},
{
"_defaultOrder": 42,
"_isFastLaunch": false,
"category": "Memory Optimized",
"gpuNum": 0,
"hideHardwareSpecs": false,
"memoryGiB": 128,
"name": "ml.r5.4xlarge",
"vcpuNum": 16
},
{
"_defaultOrder": 43,
"_isFastLaunch": false,
"category": "Memory Optimized",
"gpuNum": 0,
"hideHardwareSpecs": false,
"memoryGiB": 256,
"name": "ml.r5.8xlarge",
"vcpuNum": 32
},
{
"_defaultOrder": 44,
"_isFastLaunch": false,
"category": "Memory Optimized",
"gpuNum": 0,
"hideHardwareSpecs": false,
"memoryGiB": 384,
"name": "ml.r5.12xlarge",
"vcpuNum": 48
},
{
"_defaultOrder": 45,
"_isFastLaunch": false,
"category": "Memory Optimized",
"gpuNum": 0,
"hideHardwareSpecs": false,
"memoryGiB": 512,
"name": "ml.r5.16xlarge",
"vcpuNum": 64
},
{
"_defaultOrder": 46,
"_isFastLaunch": false,
"category": "Memory Optimized",
"gpuNum": 0,
"hideHardwareSpecs": false,
"memoryGiB": 768,
"name": "ml.r5.24xlarge",
"vcpuNum": 96
},
{
"_defaultOrder": 47,
"_isFastLaunch": false,
"category": "Accelerated computing",
"gpuNum": 1,
"hideHardwareSpecs": false,
"memoryGiB": 16,
"name": "ml.g5.xlarge",
"vcpuNum": 4
},
{
"_defaultOrder": 48,
"_isFastLaunch": false,
"category": "Accelerated computing",
"gpuNum": 1,
"hideHardwareSpecs": false,
"memoryGiB": 32,
"name": "ml.g5.2xlarge",
"vcpuNum": 8
},
{
"_defaultOrder": 49,
"_isFastLaunch": false,
"category": "Accelerated computing",
"gpuNum": 1,
"hideHardwareSpecs": false,
"memoryGiB": 64,
"name": "ml.g5.4xlarge",
"vcpuNum": 16
},
{
"_defaultOrder": 50,
"_isFastLaunch": false,
"category": "Accelerated computing",
"gpuNum": 1,
"hideHardwareSpecs": false,
"memoryGiB": 128,
"name": "ml.g5.8xlarge",
"vcpuNum": 32
},
{
"_defaultOrder": 51,
"_isFastLaunch": false,
"category": "Accelerated computing",
"gpuNum": 1,
"hideHardwareSpecs": false,
"memoryGiB": 256,
"name": "ml.g5.16xlarge",
"vcpuNum": 64
},
{
"_defaultOrder": 52,
"_isFastLaunch": false,
"category": "Accelerated computing",
"gpuNum": 4,
"hideHardwareSpecs": false,
"memoryGiB": 192,
"name": "ml.g5.12xlarge",
"vcpuNum": 48
},
{
"_defaultOrder": 53,
"_isFastLaunch": false,
"category": "Accelerated computing",
"gpuNum": 4,
"hideHardwareSpecs": false,
"memoryGiB": 384,
"name": "ml.g5.24xlarge",
"vcpuNum": 96
},
{
"_defaultOrder": 54,
"_isFastLaunch": false,
"category": "Accelerated computing",
"gpuNum": 8,
"hideHardwareSpecs": false,
"memoryGiB": 768,
"name": "ml.g5.48xlarge",
"vcpuNum": 192
},
{
"_defaultOrder": 55,
"_isFastLaunch": false,
"category": "Accelerated computing",
"gpuNum": 8,
"hideHardwareSpecs": false,
"memoryGiB": 1152,
"name": "ml.p4d.24xlarge",
"vcpuNum": 96
},
{
"_defaultOrder": 56,
"_isFastLaunch": false,
"category": "Accelerated computing",
"gpuNum": 8,
"hideHardwareSpecs": false,
"memoryGiB": 1152,
"name": "ml.p4de.24xlarge",
"vcpuNum": 96
}
],
"instance_type": "ml.t3.medium",
"interpreter": {
"hash": "04ffa0b675ec4736afd1210dd81a6f70b0b4fa83298b056bd6b4e16ede0b389c"
},
"kernelspec": {
"display_name": "Python 3 (Base Python 2.0)",
"language": "python",
"name": "python3__SAGEMAKER_INTERNAL__arn:aws:sagemaker:eu-west-1:470317259841:image/sagemaker-base-python-38"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.8.12"
}
},
"nbformat": 4,
"nbformat_minor": 4
}