{
"cells": [
{
"cell_type": "markdown",
"id": "03611fc5-1066-4449-923d-6402459a64ab",
"metadata": {},
"source": [
"## Introduction\n",
"\n",
"This is our second notebook which will explore the model training stage of the ML workflow.\n",
"\n",
"Here, we will put on the hat of the `Data Scientist` and will perform the task of modeling which includes training a model, performing hyperparameter tuning, evaluating the model and registering high performing candidate models in a model registry. This task is highly iterative in nature and hence we also need to track our experimentation until we reach desired results.\n",
"\n",
"We will learn how to bring scale to model development tasks using managed SageMaker training and experiment tracking capabilities combined with curated feature data pulled from SageMaker Feature Store. You'll also perform tuning at scale using SageMaker's automatic hyperparameter tuning capabilities. Then, finally register the best performing model in SageMaker Model Registry. \n",
"\n",
"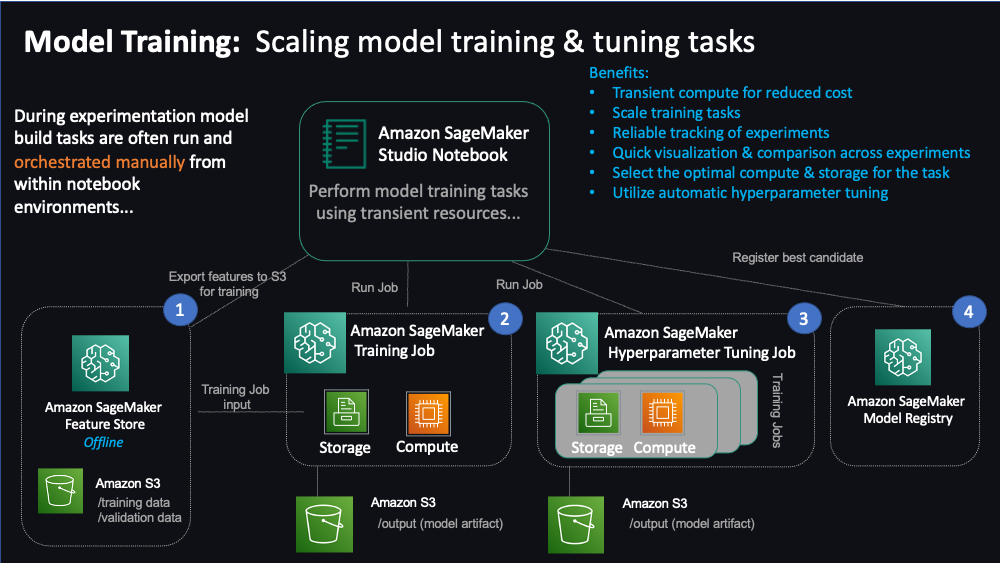\n",
"\n",
"\n",
"\n",
"Let's get started!\n",
"\n",
"**Important:** for this example, we will use XGBoost-Ray. XGBoost-Ray integrates well with the Ray Tune hyperparameter optimization library and implements advanced fault tolerance handling mechanisms. We will use ray.data to load training, validation and testind data (in parquet format) from the offline data store of the Feature Store. Then we will run a hyperparamter optimization job to find the best HPs. Finally we will register the best performing model to the Model registry. "
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "c2b1c64f-277a-47ea-adeb-fc3491f4d83c",
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"%store -r"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "e6c22424-be2a-472e-ac30-4dab9a73e716",
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"feature_group_name"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "b4c71dd6-df12-4fb2-95e8-4c5714dfe79e",
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"!pip install -U sagemaker ray==2.5.0 modin[ray]==0.22.1 pydantic==1.10.10 xgboost_ray tensorboardx"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "52456197-19fc-4a0f-a44e-4c48d167c684",
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"from sagemaker.feature_store.feature_group import FeatureGroup\n",
"from sagemaker.sklearn.estimator import SKLearn\n",
"from sagemaker.sklearn.model import SKLearnModel\n",
"from time import gmtime, strftime\n",
"import boto3\n",
"import sys\n",
"import sagemaker\n",
"import json\n",
"import os\n",
"\n",
"from sagemaker.model_metrics import ModelMetrics, MetricsSource\n",
"from sagemaker.analytics import ExperimentAnalytics\n",
"from sagemaker.tuner import IntegerParameter, ContinuousParameter, HyperparameterTuner\n",
"# SageMaker Experiments\n",
"from sagemaker.experiments.run import Run\n",
"from sagemaker.utils import unique_name_from_base\n",
"\n",
"from sagemaker.feature_store.feature_group import FeatureGroup\n",
"from sagemaker import image_uris\n",
"from sagemaker.inputs import TrainingInput"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "e2bcb783-f30b-4149-8843-51917d7b10cc",
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"# Useful SageMaker variables\n",
"sess = sagemaker.Session()\n",
"bucket = sess.default_bucket()\n",
"role_arn= sagemaker.get_execution_role()\n",
"region = sess.boto_region_name\n",
"s3_client = boto3.client('s3', region_name=region)\n",
"sagemaker_client = boto3.client('sagemaker')\n",
"\n",
"enable_local_mode_training = False\n",
"model_name = 'xgboost-model-synth-house-price'\n",
"\n",
"experiment_name = unique_name_from_base('synthetic-housing-XGB-regression')\n",
"\n",
"run_name = unique_name_from_base('XGBoost-run')\n",
"\n",
"model_path = f's3://{bucket}/{s3_prefix}/output/model/xgb'"
]
},
{
"cell_type": "markdown",
"id": "8ca98fd9-6cf8-4fd7-9d15-1ac33f912ed7",
"metadata": {},
"source": [
"**Get the `ResolvedOutputS3Uri` of the Feature Group**\n",
"\n",
"We can obtain the location where each Feature Group is storing data in parquet format."
]
},
{
"cell_type": "markdown",
"id": "9d90e91c-05ee-4a49-bf9c-84158fa026e2",
"metadata": {},
"source": [
"## SageMaker Training\n",
"\n",
"Now that we've prepared our training and test data, we can move on to use SageMaker's hosted training functionality - [SageMaker Training](https://docs.aws.amazon.com/sagemaker/latest/dg/train-model.html). Hosted training is preferred for doing actual training, especially large-scale, distributed training. Unlike training a model on a local computer or server, SageMaker hosted training will spin up a separate cluster of machines managed by SageMaker to train your model. Before starting hosted training, the data must be in S3, or an EFS or FSx for Lustre file system. We uploaded to S3 in the previous notebook, so we're good to go here."
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "6ee80286-2472-40e6-836d-cd69be678897",
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"%%writefile ./pipeline_scripts/train/script.py\n",
"import subprocess\n",
"import sys\n",
"# subprocess.check_call([sys.executable, '-m', 'pip', 'install', 'pandas==1.5.2', 'sagemaker','ray[all]==2.4.0', 'modin[ray]==0.18.0', 'xgboost_ray', 'pyarrow >= 6.0.1','pydantic==1.10.10', 'gpustat==1.0.0'])\n",
"\n",
"import os\n",
"import time\n",
"from glob import glob\n",
"import argparse\n",
"import json\n",
"import logging\n",
"import boto3\n",
"import sagemaker\n",
"import numpy as np\n",
"import modin.pandas as pd\n",
"\n",
"# Experiments\n",
"from sagemaker.session import Session\n",
"from sagemaker.experiments.run import load_run\n",
"\n",
"import ray\n",
"from xgboost_ray import RayDMatrix, RayParams, train\n",
"\n",
"from ray.air.config import ScalingConfig\n",
"from ray.data import Dataset\n",
"from ray.air.result import Result\n",
"from ray.air.checkpoint import Checkpoint\n",
"from sagemaker_ray_helper import RayHelper \n",
"\n",
"logger = logging.getLogger(__name__)\n",
"logger.setLevel(logging.DEBUG)\n",
"logger.addHandler(logging.StreamHandler(sys.stdout))\n",
"\n",
"def read_parameters():\n",
" parser = argparse.ArgumentParser()\n",
"\n",
" # Hyperparameters are described here.\n",
" parser.add_argument('--max_depth', type=int, default=os.environ.get('SM_HP_MAX_DEPTH'))\n",
" parser.add_argument('--eta', type=float, default=os.environ.get('SM_HP_ETA'))\n",
" parser.add_argument('--min_child_weight', type=int, default=os.environ.get('SM_HP_MIN_CHILD_WEIGHT'))\n",
" parser.add_argument('--subsample', type=float, default=os.environ.get('SM_HP_SUBSAMPLE'))\n",
" parser.add_argument('--verbosity', type=int)\n",
" parser.add_argument('--num_round', type=int)\n",
" parser.add_argument('--tree_method', type=str, default=\"auto\")\n",
" parser.add_argument('--predictor', type=str, default=\"auto\")\n",
"\n",
" # Sagemaker specific arguments. Defaults are set in the environment variables.\n",
" parser.add_argument('--output_data_dir', type=str, default=os.environ.get('SM_OUTPUT_DATA_DIR'))\n",
" parser.add_argument('--model_dir', type=str, default=os.environ.get('SM_MODEL_DIR'))\n",
" parser.add_argument('--train', type=str, default=os.environ.get('SM_CHANNEL_TRAIN'))\n",
" parser.add_argument('--validation', type=str, default=os.environ.get('SM_CHANNEL_VALIDATION'))\n",
" parser.add_argument('--sm_hosts', type=str, default=os.environ.get('SM_HOSTS'))\n",
" parser.add_argument('--sm_current_host', type=str, default=os.environ.get('SM_CURRENT_HOST'))\n",
" \n",
" parser.add_argument('--num_ray_workers', type=int,default=6)\n",
" parser.add_argument('--use_gpu', type=bool, default=False)\n",
" # parse region\n",
" parser.add_argument('--region', type=str, default='us-east-1')\n",
" \n",
" parser.add_argument('--target_col', type=str, default='price')\n",
" \n",
" try:\n",
" from sagemaker_training import environment\n",
" env = environment.Environment()\n",
" parser.add_argument('--n_jobs', type=int, default=env.num_cpus)\n",
" except:\n",
" parser.add_argument('--n_jobs', type=int, default=4)\n",
"\n",
" args, _ = parser.parse_known_args()\n",
" return args\n",
"\n",
"def load_dataset(path, num_workers, target_col=\"price\"):\n",
" \"\"\"\n",
" Loads the data as a ray dataset from the offline featurestore S3 location\n",
" Args:\n",
" feature_group_name (str): name of the feature group\n",
" target_col (str): the target columns (will be used only for the test set).\n",
" Returns:\n",
" ds (ray.data.dataset): Ray dataset the contains the requested dat from the feature store\n",
" \"\"\"\n",
" \"\"\"\n",
" cols_to_drop=[]\n",
" # A simple check is this is test data\n",
" # If True add the target column to the columns list to be dropped\n",
" if '/test/' in path:\n",
" cols_to_drop.append(target_col)\n",
" \"\"\"\n",
" csv_files = glob(os.path.join(path, \"*.csv\"))\n",
" print(f\"found {len(csv_files)} files at {path}\")\n",
" ds = ray.data.read_csv(path)\n",
" # ds = ds.drop_columns(cols_to_drop)\n",
" print(f\"{path} count is {ds.count()}\")\n",
"\n",
" return ds.repartition(num_workers)\n",
"\n",
"def train_xgboost(ds_train, ds_val, params, num_workers, target_col = \"price\") -> Result:\n",
" \"\"\"\n",
" Creates a XGBoost trainer, train it, and return the result. \n",
" Args:\n",
" ds_train (ray.data.dataset): Training dataset\n",
" ds_val (ray.data.dataset): Validation dataset\n",
" params (dict): Hyperparameters\n",
" num_workers (int): number of workers to distribute the training across\n",
" target_col (str): target column\n",
" Returns:\n",
" result (ray.air.result.Result): Result of the training job\n",
" \"\"\"\n",
" \n",
" train_set = RayDMatrix(ds_train, 'PRICE')\n",
" val_set = RayDMatrix(ds_val, 'PRICE')\n",
" \n",
" evals_result = {}\n",
" \n",
" trainer = train(\n",
" params=params,\n",
" dtrain=train_set,\n",
" evals_result=evals_result,\n",
" evals=[(val_set, \"validation\")],\n",
" verbose_eval=False,\n",
" num_boost_round=100,\n",
" ray_params=RayParams(num_actors=num_workers, cpus_per_actor=1),\n",
" )\n",
" \n",
" output_path=os.path.join(args.model_dir, 'model.xgb')\n",
" \n",
" trainer.save_model(output_path)\n",
" \n",
" valMAE = evals_result[\"validation\"][\"mae\"][-1]\n",
" valRMSE = evals_result[\"validation\"][\"rmse\"][-1]\n",
" \n",
" print('[3] #011validation-mae:{}'.format(valMAE))\n",
" print('[4] #011validation-rmse:{}'.format(valRMSE))\n",
" \n",
" local_testing = False\n",
" try:\n",
" load_run(sagemaker_session=sess)\n",
" except:\n",
" local_testing = True\n",
" if not local_testing: # Track experiment if using SageMaker Training\n",
" with load_run(sagemaker_session=sess) as run:\n",
" run.log_metric('validation-mae', valMAE)\n",
" run.log_metric('validation-rmse', valRMSE)\n",
"\n",
"def main():\n",
" # Get SageMaker host information from runtime environment variables\n",
" sm_hosts = json.loads(args.sm_hosts)\n",
" sm_current_host = args.sm_current_host\n",
" \n",
" hyperparams = {\n",
" 'max_depth': args.max_depth,\n",
" 'min_child_weight': args.min_child_weight,\n",
" 'eta': args.eta,\n",
" 'subsample': args.subsample,\n",
" \"tree_method\": \"approx\",\n",
" \"objective\": \"reg:squarederror\",\n",
" \"eval_metric\": [\"mae\", \"rmse\"],\n",
" \"num_round\": 100,\n",
" \"seed\": 47\n",
" }\n",
"\n",
" ds_train = load_dataset(args.train, args.num_ray_workers, args.target_col)\n",
" ds_validation = load_dataset(args.validation, args.num_ray_workers, args.target_col)\n",
" \n",
" trainer = train_xgboost(ds_train, ds_validation, hyperparams, args.num_ray_workers, args.target_col)\n",
"\n",
" \n",
"if __name__ == '__main__':\n",
" ray_helper = RayHelper()\n",
" \n",
" ray_helper.start_ray()\n",
" args = read_parameters()\n",
" sess = sagemaker.Session(boto3.Session(region_name=args.region))\n",
"\n",
" start = time.time()\n",
" main()\n",
" taken = time.time() - start\n",
" print(f\"TOTAL TIME TAKEN: {taken:.2f} seconds\")\n",
" \n",
" \n",
" "
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "3109f55f-686b-46a9-b74f-bbba2eb66be4",
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"!cp -r ./common/* ./pipeline_scripts/train/"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "e3a4812b-e374-41e6-a8fd-77eeb047d623",
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"hyperparams = {\n",
" \"max_depth\": \"5\",\n",
" \"eta\": \"0.2\",\n",
" \"min_child_weight\": \"6\",\n",
" \"subsample\": \"0.7\",\n",
" # \"objective\": \"reg:squarederror\",\n",
"}\n",
"\n",
"train_instance_type = 'ml.c5.xlarge'\n",
"\n",
"estimator_parameters = {\n",
" 'source_dir': './pipeline_scripts/train/',\n",
" 'entry_point': 'script.py',\n",
" 'framework_version': '1.7-1',\n",
" 'instance_type': train_instance_type,\n",
" 'instance_count': 2,\n",
" 'hyperparameters': hyperparams,\n",
" 'role': role_arn,\n",
" 'base_job_name': 'XGBoost-model',\n",
" 'output_path': model_path,\n",
" 'image_scope': 'training',\n",
" 'env': {\n",
" 'MODIN_AUTOIMPORT_PANDAS': '1', \n",
" 'SAGEMAKER_REQUIREMENTS': 'requirements.txt', # path relative to `source_dir` below.\n",
" }\n",
"}\n",
"\n",
"inputs = {'train': TrainingInput(train_s3_destination), 'validation': TrainingInput(val_s3_destination)}\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "412d4011-c870-4258-9f01-5eb7e257169f",
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"from IPython.core.display import display, HTML\n",
"from sagemaker.xgboost.estimator import XGBoost\n",
"# from sagemaker.sklearn.estimator import SKLearn\n",
"\n",
"display(\n",
" HTML(\n",
" '<b>Review the <a target=\"blank\" href=\"https://console.aws.amazon.com/sagemaker/home?region={}#/jobs/{}\">Training Job</a> After About 5 Minutes</b>'.format(\n",
" region, experiment_name\n",
" )\n",
" )\n",
")\n",
"\n",
"with Run(experiment_name=experiment_name, run_name=run_name) as run:\n",
" estimator = XGBoost(**estimator_parameters)\n",
" estimator.fit(inputs)"
]
},
{
"cell_type": "markdown",
"id": "de3f097f-abaf-4bf2-9bec-f8cbf5c395b6",
"metadata": {},
"source": [
"### Verify Ray Cluster\n",
"In the output from the previous step, right after the ray head is initialized you should see the `ray.cluster_resources()` output. This will look like\n",
"\n",
"<span style=\"color:#208ffb\">All workers present and accounted for <br/>\n",
"{'CPU': 8.0, 'memory': xxxx, 'object_store_memory': xxxx, 'node:10.2.xxx.xxx': 1.0, 'node:10.2.xxx.xxx': 1.0}</span>\n",
"<br></br>\n",
"This confirms the there were 2 instance of `ml.c5.xlarge` with a total of 8 CPUs in the Ray cluster that processed this training job"
]
},
{
"cell_type": "markdown",
"id": "eb1cce14-4233-45bd-8b7b-92815c79bd8c",
"metadata": {},
"source": [
"## Hyper Parameter Tuning\n",
"\n",
"Instead of maunally configuring your hyper parameter values and training with SageMaker Training, you could also train with Amazon SageMaker Automatic Model Tuning. AMT, also known as hyperparameter tuning, finds the best version of a model by running many training jobs on your dataset using the algorithm and ranges of hyperparameters that you specify. It then chooses the hyperparameter values that result in a model that performs the best, as measured by a metric that you choose."
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "26f9fb4e-f6eb-44e4-a305-58e03eef3475",
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"hyperparameter_ranges = {\n",
" \"max_depth\": IntegerParameter(1, 8),\n",
" \"eta\": ContinuousParameter(0.1, 0.5),\n",
" \"min_child_weight\": IntegerParameter(0, 120),\n",
" \"subsample\": ContinuousParameter(0.2, 1),\n",
"}\n",
"\n",
"objective_metric_name = 'validation:rmse'\n",
"objective_type = 'Minimize'"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "0ecf73a3-11a9-4944-afd7-d5e5ae6c02cd",
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"tuner_parameters = {\n",
" 'estimator': estimator,\n",
" 'objective_metric_name': objective_metric_name,\n",
" 'hyperparameter_ranges': hyperparameter_ranges,\n",
" # 'metric_definitions': metric_definitions,\n",
" 'max_jobs': 10,\n",
" 'max_parallel_jobs': 5,\n",
" 'objective_type': objective_type\n",
" }\n",
" \n",
"tuner = HyperparameterTuner(**tuner_parameters)\n",
"\n",
"tuning_job_name = f'xgb-model-tuning-{strftime(\"%d-%H-%M-%S\", gmtime())}'\n",
"display(\n",
" HTML(\n",
" '<b>Review the <a target=\"blank\" href=\"https://console.aws.amazon.com/sagemaker/home?region={}#/hyper-tuning-jobs/{}\">Tuning Job</a> After About 5 Minutes</b>'.format(\n",
" region, tuning_job_name\n",
" )\n",
" )\n",
")\n",
"tuner.fit(inputs, job_name=tuning_job_name)\n",
"tuner.wait()"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "e2057a48-10cd-44b4-966f-60ba94ec6065",
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"tuner_metrics = sagemaker.HyperparameterTuningJobAnalytics(tuning_job_name)\n",
"tuner_metrics.dataframe().sort_values(['FinalObjectiveValue'], ascending=True).head(5)"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "14bc00a2-a8f7-4167-8c92-0b2e01c00c8d",
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"%%writefile ./pipeline_scripts/inference/script.py\n",
"\n",
"import json\n",
"import os\n",
"import pickle as pkl\n",
"\n",
"import numpy as np\n",
"import tarfile\n",
"import xgboost as xgb\n",
"import sagemaker_xgboost_container.encoder as xgb_encoder\n",
"\n",
"\n",
"def model_fn(model_dir):\n",
" \"\"\"\n",
" Deserialize and return fitted model.\n",
" \"\"\"\n",
" booster = xgb.Booster()\n",
" booster.load_model(os.path.join(model_dir, 'model.xgb'))\n",
" return booster\n",
"\n",
"\n",
"def input_fn(request_body, request_content_type):\n",
" \"\"\"\n",
" The SageMaker XGBoost model server receives the request data body and the content type,\n",
" and invokes the `input_fn`.\n",
"\n",
" Return a DMatrix (an object that can be passed to predict_fn).\n",
" \"\"\"\n",
" print(f'Incoming format type is {request_content_type}')\n",
" if request_content_type == \"text/csv\":\n",
" decoded_payload = request_body.strip()\n",
" return xgb_encoder.csv_to_dmatrix(decoded_payload, dtype=np.float)\n",
" if request_content_type == \"text/libsvm\":\n",
" return xgb_encoder.libsvm_to_dmatrix(request_body)\n",
" else:\n",
" raise ValueError(\n",
" \"Content type {} is not supported.\".format(request_content_type)\n",
" )\n",
"\n",
"\n",
"def predict_fn(input_data, model):\n",
" \"\"\"\n",
" SageMaker XGBoost model server invokes `predict_fn` on the return value of `input_fn`.\n",
"\n",
" Return a two-dimensional NumPy array where the first columns are predictions\n",
" and the remaining columns are the feature contributions (SHAP values) for that prediction.\n",
" \"\"\"\n",
" prediction = model.predict(input_data)\n",
" feature_contribs = model.predict(input_data, pred_contribs=True, validate_features=False)\n",
" output = np.hstack((prediction[:, np.newaxis], feature_contribs))\n",
" return output\n",
"\n",
"\n",
"def output_fn(predictions, content_type):\n",
" \"\"\"\n",
" After invoking predict_fn, the model server invokes `output_fn`.\n",
" \"\"\"\n",
" print(f'outgoing format type is {content_type}')\n",
" print (predictions)\n",
" if content_type == \"text/csv\":\n",
" return ','.join(str(x[0]) for x in predictions)\n",
" else:\n",
" raise ValueError(\"Content type {} is not supported.\".format(content_type))"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "8bf3f3c1-e8d8-4f2f-9f75-8690e35cb742",
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"from helper_library import *\n",
"# Register model\n",
"best_estimator = tuner.best_estimator()\n",
"#best_estimator = estimator\n",
"model_metrics = create_training_job_metrics(best_estimator, s3_prefix, region, bucket)"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "61167130-646f-4797-90f0-16662f9e48a4",
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"#model_package_group_name = 'synthetic-housing-models-ray'\n",
"model_package_group_name = unique_name_from_base('synthetic-housing-models-ray-')"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "df9a7b71-757d-49c1-b8e4-9338a3d472e9",
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"sagemaker_client.create_model_package_group(ModelPackageGroupName=model_package_group_name,\n",
" ModelPackageGroupDescription='Models predicting synthetic housing prices') "
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "756c60df-676a-4494-b8af-fa39a47178be",
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"from sagemaker.xgboost.model import XGBoostModel\n",
"# print(model_data_path)\n",
"xgb_inference_model = XGBoostModel(\n",
" model_data=best_estimator.model_data,\n",
" role=role_arn,\n",
" name = model_name,\n",
" entry_point=\"./pipeline_scripts/inference/script.py\",\n",
" framework_version=\"1.7-1\"\n",
")"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "fc8a87d6-7caa-4b39-8279-278c96de6cf2",
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"xgb_model_package = xgb_inference_model.register(content_types=['text/csv'],\n",
" response_types=['application/json'],\n",
" inference_instances=['ml.t2.medium', 'ml.m5.xlarge'],\n",
" transform_instances=['ml.m5.xlarge'],\n",
" image_uri=best_estimator.image_uri,\n",
" model_package_group_name=model_package_group_name,\n",
" model_metrics=model_metrics,\n",
" approval_status='PendingManualApproval',\n",
" description='XGBoost model to predict synthetic housing prices',\n",
" # model_package_name=model_name,\n",
" )"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "219b6dff-7890-4fc3-aab1-bfed93e1a78f",
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"model_package_arn = xgb_model_package.model_package_arn"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "5ab31bb3-ed22-4f5b-b51a-4070d4980ea6",
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"%store model_package_arn\n",
"%store model_name\n",
"%store model_package_group_name\n",
"%store model_metrics\n",
"# %store model_data_path"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "3f2815de-5d7d-4fa3-97e7-2f1b5b3d3c14",
"metadata": {
"tags": []
},
"outputs": [],
"source": []
},
{
"cell_type": "code",
"execution_count": null,
"id": "d20cd38b-52b7-40d5-b84a-0f9291a4e2d2",
"metadata": {},
"outputs": [],
"source": []
}
],
"metadata": {
"availableInstances": [
{
"_defaultOrder": 0,
"_isFastLaunch": true,
"category": "General purpose",
"gpuNum": 0,
"memoryGiB": 4,
"name": "ml.t3.medium",
"vcpuNum": 2
},
{
"_defaultOrder": 1,
"_isFastLaunch": false,
"category": "General purpose",
"gpuNum": 0,
"memoryGiB": 8,
"name": "ml.t3.large",
"vcpuNum": 2
},
{
"_defaultOrder": 2,
"_isFastLaunch": false,
"category": "General purpose",
"gpuNum": 0,
"memoryGiB": 16,
"name": "ml.t3.xlarge",
"vcpuNum": 4
},
{
"_defaultOrder": 3,
"_isFastLaunch": false,
"category": "General purpose",
"gpuNum": 0,
"memoryGiB": 32,
"name": "ml.t3.2xlarge",
"vcpuNum": 8
},
{
"_defaultOrder": 4,
"_isFastLaunch": true,
"category": "General purpose",
"gpuNum": 0,
"memoryGiB": 8,
"name": "ml.m5.large",
"vcpuNum": 2
},
{
"_defaultOrder": 5,
"_isFastLaunch": false,
"category": "General purpose",
"gpuNum": 0,
"memoryGiB": 16,
"name": "ml.m5.xlarge",
"vcpuNum": 4
},
{
"_defaultOrder": 6,
"_isFastLaunch": false,
"category": "General purpose",
"gpuNum": 0,
"memoryGiB": 32,
"name": "ml.m5.2xlarge",
"vcpuNum": 8
},
{
"_defaultOrder": 7,
"_isFastLaunch": false,
"category": "General purpose",
"gpuNum": 0,
"memoryGiB": 64,
"name": "ml.m5.4xlarge",
"vcpuNum": 16
},
{
"_defaultOrder": 8,
"_isFastLaunch": false,
"category": "General purpose",
"gpuNum": 0,
"memoryGiB": 128,
"name": "ml.m5.8xlarge",
"vcpuNum": 32
},
{
"_defaultOrder": 9,
"_isFastLaunch": false,
"category": "General purpose",
"gpuNum": 0,
"memoryGiB": 192,
"name": "ml.m5.12xlarge",
"vcpuNum": 48
},
{
"_defaultOrder": 10,
"_isFastLaunch": false,
"category": "General purpose",
"gpuNum": 0,
"memoryGiB": 256,
"name": "ml.m5.16xlarge",
"vcpuNum": 64
},
{
"_defaultOrder": 11,
"_isFastLaunch": false,
"category": "General purpose",
"gpuNum": 0,
"memoryGiB": 384,
"name": "ml.m5.24xlarge",
"vcpuNum": 96
},
{
"_defaultOrder": 12,
"_isFastLaunch": false,
"category": "General purpose",
"gpuNum": 0,
"memoryGiB": 8,
"name": "ml.m5d.large",
"vcpuNum": 2
},
{
"_defaultOrder": 13,
"_isFastLaunch": false,
"category": "General purpose",
"gpuNum": 0,
"memoryGiB": 16,
"name": "ml.m5d.xlarge",
"vcpuNum": 4
},
{
"_defaultOrder": 14,
"_isFastLaunch": false,
"category": "General purpose",
"gpuNum": 0,
"memoryGiB": 32,
"name": "ml.m5d.2xlarge",
"vcpuNum": 8
},
{
"_defaultOrder": 15,
"_isFastLaunch": false,
"category": "General purpose",
"gpuNum": 0,
"memoryGiB": 64,
"name": "ml.m5d.4xlarge",
"vcpuNum": 16
},
{
"_defaultOrder": 16,
"_isFastLaunch": false,
"category": "General purpose",
"gpuNum": 0,
"memoryGiB": 128,
"name": "ml.m5d.8xlarge",
"vcpuNum": 32
},
{
"_defaultOrder": 17,
"_isFastLaunch": false,
"category": "General purpose",
"gpuNum": 0,
"memoryGiB": 192,
"name": "ml.m5d.12xlarge",
"vcpuNum": 48
},
{
"_defaultOrder": 18,
"_isFastLaunch": false,
"category": "General purpose",
"gpuNum": 0,
"memoryGiB": 256,
"name": "ml.m5d.16xlarge",
"vcpuNum": 64
},
{
"_defaultOrder": 19,
"_isFastLaunch": false,
"category": "General purpose",
"gpuNum": 0,
"memoryGiB": 384,
"name": "ml.m5d.24xlarge",
"vcpuNum": 96
},
{
"_defaultOrder": 20,
"_isFastLaunch": true,
"category": "Compute optimized",
"gpuNum": 0,
"memoryGiB": 4,
"name": "ml.c5.large",
"vcpuNum": 2
},
{
"_defaultOrder": 21,
"_isFastLaunch": false,
"category": "Compute optimized",
"gpuNum": 0,
"memoryGiB": 8,
"name": "ml.c5.xlarge",
"vcpuNum": 4
},
{
"_defaultOrder": 22,
"_isFastLaunch": false,
"category": "Compute optimized",
"gpuNum": 0,
"memoryGiB": 16,
"name": "ml.c5.2xlarge",
"vcpuNum": 8
},
{
"_defaultOrder": 23,
"_isFastLaunch": false,
"category": "Compute optimized",
"gpuNum": 0,
"memoryGiB": 32,
"name": "ml.c5.4xlarge",
"vcpuNum": 16
},
{
"_defaultOrder": 24,
"_isFastLaunch": false,
"category": "Compute optimized",
"gpuNum": 0,
"memoryGiB": 72,
"name": "ml.c5.9xlarge",
"vcpuNum": 36
},
{
"_defaultOrder": 25,
"_isFastLaunch": false,
"category": "Compute optimized",
"gpuNum": 0,
"memoryGiB": 96,
"name": "ml.c5.12xlarge",
"vcpuNum": 48
},
{
"_defaultOrder": 26,
"_isFastLaunch": false,
"category": "Compute optimized",
"gpuNum": 0,
"memoryGiB": 144,
"name": "ml.c5.18xlarge",
"vcpuNum": 72
},
{
"_defaultOrder": 27,
"_isFastLaunch": false,
"category": "Compute optimized",
"gpuNum": 0,
"memoryGiB": 192,
"name": "ml.c5.24xlarge",
"vcpuNum": 96
},
{
"_defaultOrder": 28,
"_isFastLaunch": true,
"category": "Accelerated computing",
"gpuNum": 1,
"memoryGiB": 16,
"name": "ml.g4dn.xlarge",
"vcpuNum": 4
},
{
"_defaultOrder": 29,
"_isFastLaunch": false,
"category": "Accelerated computing",
"gpuNum": 1,
"memoryGiB": 32,
"name": "ml.g4dn.2xlarge",
"vcpuNum": 8
},
{
"_defaultOrder": 30,
"_isFastLaunch": false,
"category": "Accelerated computing",
"gpuNum": 1,
"memoryGiB": 64,
"name": "ml.g4dn.4xlarge",
"vcpuNum": 16
},
{
"_defaultOrder": 31,
"_isFastLaunch": false,
"category": "Accelerated computing",
"gpuNum": 1,
"memoryGiB": 128,
"name": "ml.g4dn.8xlarge",
"vcpuNum": 32
},
{
"_defaultOrder": 32,
"_isFastLaunch": false,
"category": "Accelerated computing",
"gpuNum": 4,
"memoryGiB": 192,
"name": "ml.g4dn.12xlarge",
"vcpuNum": 48
},
{
"_defaultOrder": 33,
"_isFastLaunch": false,
"category": "Accelerated computing",
"gpuNum": 1,
"memoryGiB": 256,
"name": "ml.g4dn.16xlarge",
"vcpuNum": 64
},
{
"_defaultOrder": 34,
"_isFastLaunch": false,
"category": "Accelerated computing",
"gpuNum": 1,
"memoryGiB": 61,
"name": "ml.p3.2xlarge",
"vcpuNum": 8
},
{
"_defaultOrder": 35,
"_isFastLaunch": false,
"category": "Accelerated computing",
"gpuNum": 4,
"memoryGiB": 244,
"name": "ml.p3.8xlarge",
"vcpuNum": 32
},
{
"_defaultOrder": 36,
"_isFastLaunch": false,
"category": "Accelerated computing",
"gpuNum": 8,
"memoryGiB": 488,
"name": "ml.p3.16xlarge",
"vcpuNum": 64
},
{
"_defaultOrder": 37,
"_isFastLaunch": false,
"category": "Accelerated computing",
"gpuNum": 8,
"memoryGiB": 768,
"name": "ml.p3dn.24xlarge",
"vcpuNum": 96
},
{
"_defaultOrder": 38,
"_isFastLaunch": false,
"category": "Memory Optimized",
"gpuNum": 0,
"memoryGiB": 16,
"name": "ml.r5.large",
"vcpuNum": 2
},
{
"_defaultOrder": 39,
"_isFastLaunch": false,
"category": "Memory Optimized",
"gpuNum": 0,
"memoryGiB": 32,
"name": "ml.r5.xlarge",
"vcpuNum": 4
},
{
"_defaultOrder": 40,
"_isFastLaunch": false,
"category": "Memory Optimized",
"gpuNum": 0,
"memoryGiB": 64,
"name": "ml.r5.2xlarge",
"vcpuNum": 8
},
{
"_defaultOrder": 41,
"_isFastLaunch": false,
"category": "Memory Optimized",
"gpuNum": 0,
"memoryGiB": 128,
"name": "ml.r5.4xlarge",
"vcpuNum": 16
},
{
"_defaultOrder": 42,
"_isFastLaunch": false,
"category": "Memory Optimized",
"gpuNum": 0,
"memoryGiB": 256,
"name": "ml.r5.8xlarge",
"vcpuNum": 32
},
{
"_defaultOrder": 43,
"_isFastLaunch": false,
"category": "Memory Optimized",
"gpuNum": 0,
"memoryGiB": 384,
"name": "ml.r5.12xlarge",
"vcpuNum": 48
},
{
"_defaultOrder": 44,
"_isFastLaunch": false,
"category": "Memory Optimized",
"gpuNum": 0,
"memoryGiB": 512,
"name": "ml.r5.16xlarge",
"vcpuNum": 64
},
{
"_defaultOrder": 45,
"_isFastLaunch": false,
"category": "Memory Optimized",
"gpuNum": 0,
"memoryGiB": 768,
"name": "ml.r5.24xlarge",
"vcpuNum": 96
},
{
"_defaultOrder": 46,
"_isFastLaunch": false,
"category": "Accelerated computing",
"gpuNum": 1,
"memoryGiB": 16,
"name": "ml.g5.xlarge",
"vcpuNum": 4
},
{
"_defaultOrder": 47,
"_isFastLaunch": false,
"category": "Accelerated computing",
"gpuNum": 1,
"memoryGiB": 32,
"name": "ml.g5.2xlarge",
"vcpuNum": 8
},
{
"_defaultOrder": 48,
"_isFastLaunch": false,
"category": "Accelerated computing",
"gpuNum": 1,
"memoryGiB": 64,
"name": "ml.g5.4xlarge",
"vcpuNum": 16
},
{
"_defaultOrder": 49,
"_isFastLaunch": false,
"category": "Accelerated computing",
"gpuNum": 1,
"memoryGiB": 128,
"name": "ml.g5.8xlarge",
"vcpuNum": 32
},
{
"_defaultOrder": 50,
"_isFastLaunch": false,
"category": "Accelerated computing",
"gpuNum": 1,
"memoryGiB": 256,
"name": "ml.g5.16xlarge",
"vcpuNum": 64
},
{
"_defaultOrder": 51,
"_isFastLaunch": false,
"category": "Accelerated computing",
"gpuNum": 4,
"memoryGiB": 192,
"name": "ml.g5.12xlarge",
"vcpuNum": 48
},
{
"_defaultOrder": 52,
"_isFastLaunch": false,
"category": "Accelerated computing",
"gpuNum": 4,
"memoryGiB": 384,
"name": "ml.g5.24xlarge",
"vcpuNum": 96
},
{
"_defaultOrder": 53,
"_isFastLaunch": false,
"category": "Accelerated computing",
"gpuNum": 8,
"memoryGiB": 768,
"name": "ml.g5.48xlarge",
"vcpuNum": 192
}
],
"instance_type": "ml.t3.medium",
"kernelspec": {
"display_name": "Python 3 (Data Science 3.0)",
"language": "python",
"name": "python3__SAGEMAKER_INTERNAL__arn:aws:sagemaker:us-east-1:081325390199:image/sagemaker-data-science-310-v1"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.10.6"
}
},
"nbformat": 4,
"nbformat_minor": 5
}