# Manage AutoML workflows with AWS StepFunctions and AutoGluon on Amazon SageMaker
In this repository, we present a deployement-ready AWS stack which uses [AWS Step Functions](https://aws.amazon.com/step-functions) to orchestrate AutoML workflows using [AutoGluon](https://auto.gluon.ai/stable/index.html#) on [Amazon SageMaker](https://aws.amazon.com/sagemaker/).
A complete description can be found in the corresponding [blog post]().
Main State Machine | Training State Machine | Deployment State Machine
:-------------------------:|:-------------------------:|:-------------------------:
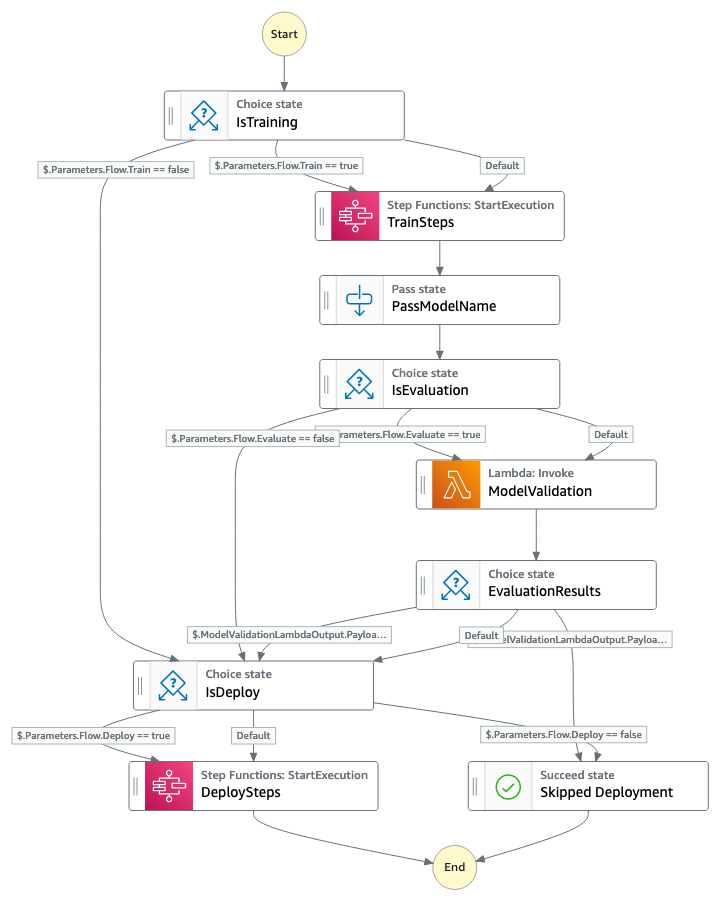 | | 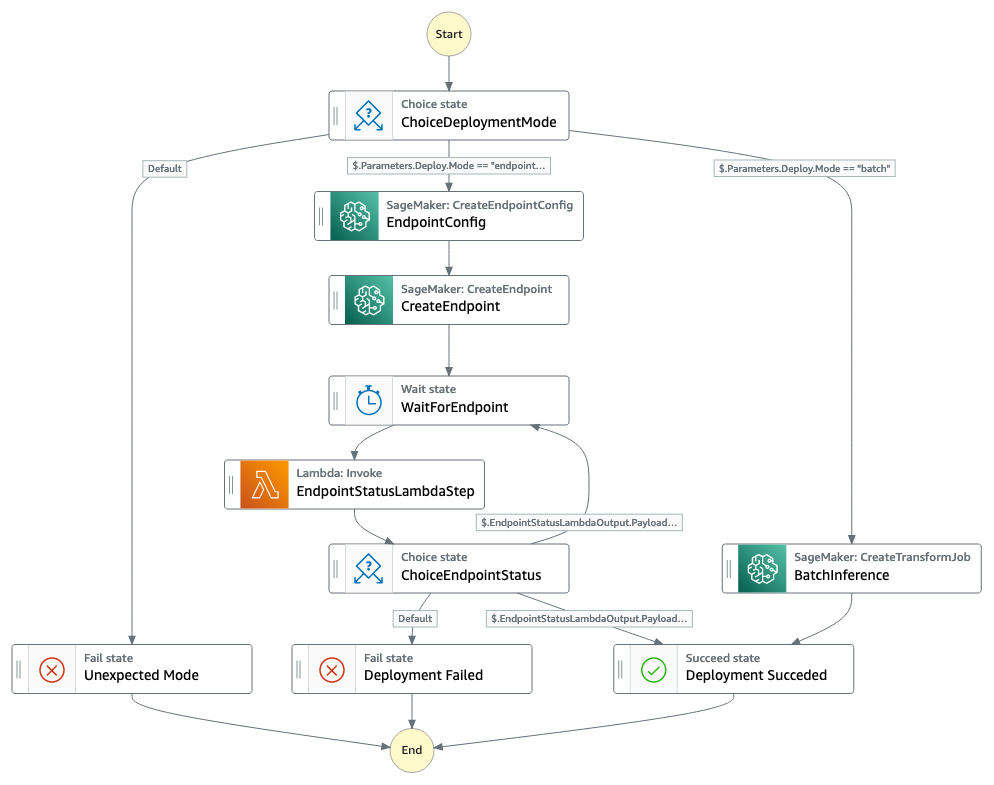|
## Outline
- [Installation](#install)
- [Notebook Walktrough](#walktrough)
- [Documentation](#doc)
- [Repo structure](#structure)
- [Clean-up](#cleanup)
- [CDK Cheat-sheet](#cdk)
## Installation
### Prerequisites
- Node.js `16.13.1`
- Python `3.7.10`
### Step-by-step setup
1) Clone this repository to your cloud environment of choice (Cloud9, EC2 instance, local aws environemnt, ...)
2) Create IAM role needed to deploy the stack (skip to 3. if you already have a role with sufficient permissions and trust relationship).
- Using AWS CLI
1. Configure AWS CLI profile that you would like to use, if not configured yet with `aws configure` and follow the [instructions](https://docs.aws.amazon.com/cli/latest/userguide/cli-configure-quickstart.html)
2. Create a new IAM role which can be used by Cloud Formation with `aws iam create-role --role-name {YOUR_ROLE_NAME} --assume-role-policy-document file://trust_policy.json`
3. Attach permissions policy to the new role `aws iam put-role-policy --role-name {YOUR_ROLE_NAME} --policy-name {YOUR_POLICY_NAME} --policy-document file://permissions_policy.json`
- Alternatevily, you can create the role using AWS IAM Management Console. Once created, make sure to update *Trust Relationship* with `trust_policy.json` and attach a customer *Permissions Policy* based on `permissions_policy.json`
3) Create a new python virtual environment `python3 -m venv .venv`
4) Activate the environment `source .venv/bin/activate`
5) Install AWS CDK `npm install -g aws-cdk@2.8.0`
6) Install requirements `pip install -r requirements.txt`
7) Bootstrap AWS CDK for your aws account `cdk bootstrap aws://{AWS_ACCOUNT_ID}/{REGION}`. If your account has been bootstrapped already with `cdk@1.X`, you may need to manually delete `CDKToolkit` stack from AWS CloudFormation console to avoid compatibility issues with `cdk@2.X`. Once de-bootstrapped, proceed by re-bootstrapping.
8) Deploy the stack with `cdk deploy -r {NEW_ROLE_ARN}`
## Notebook Walkthrough (SUGGESTED)
Once the stack is deployed, you can familiarize with the resources using the tutorial `notebooks/AutoML Walkthrough.ipynb`.
## State Machines Input Documentation
Action flows defined using AWS Step Functions are called State Machine.
Each machine has parameters that can be defined at runtime (i.e. execution-specific) which are specified through an input json object. Some exemples of input parameters are presented in `notebooks/input/`. Despite being meant to be used during the notebook tutorial, you can also copy/paste them directly into the AWS Console.
__Request Syntax__
```
{
"Parameters": {
"Flow": {
"Train": true|false,
"Evaluate": true|false,
"Deploy": true|false
},
"PretrainedModel":{
"Name": "string"
},
"Train": {
"TrainDataPath": "string",
"TestDataPath": "string",
"TrainingOutput": "string",
"InstanceCount": int,
"InstanceType": "string",
"FitArgs": "string"",
"InitArgs": "string"
},
"Evaluation": {
"Threshold": flaot,
"Metric": "string"
},
"Deploy": {
"InstanceCount": int,
"InstanceType": "string",
"Mode": "endpoint"|"batch",
"BatchInputDataPath": "string",
"BatchOutputDataPath": "string"
}
}
}
```
__Parameters__
- __Flow__
- __Train__ *(bool)* - (REQUIRED) indicates if a new AutoGluon SageMaker Training Job is required. Set to `false` to deploy a pretrained model.
- __Evaluation__ *(bool)* - set to `true` if evaluation is required. If selected, a AWS Lambda will retreive model performances on test set and evaluate them agains user-defined threshold. If model performances are not satisfactory, deployment is skipped.
- __Deploy__ *(bool)* - (REQUIRED) indicates if model has to be deployed.
- __PretrainedModel__
- __Name__ *(string)* - indicates which pre-trained model to be used for deployment. Models are referenced through their SageMaker Model Name. If `Flow.Train = true` this field is ignored, otherwise it's required.
- __Train__ (REQUIRED if `Flow.Train = true`)
- __TrainDataPath__ *(string)* - S3 URI where train `csv` is stored. Header and target variable are required. AutoGluon will perform holdout split for validation automatically.
- __TestDataPath__ *(string)* - S3 URI where test `csv` is stored. Header and target variable are required. Dataset is used to evaluate model performances on samples not seen during training.
- __TrainingOutput__ *(string)* - S3 URI where to store model artifacts at the end of training job.
- __InstanceCount__ *(int)* - Number of instances to be used for training.
- __InstanceType__ *(string)* - AWS instance type to be used for training (e.g. `ml.m4.2xlarge`). See full list [here](https://aws.amazon.com/ec2/instance-types/).
- __FitArgs__ *(string)* - double JSON-encoded dictionary containing parameters to be used during model `.fit()`. List of available parameters [here](https://auto.gluon.ai/stable/api/autogluon.task.html#autogluon.tabular.TabularPredictor). Dictionary needs to be encoded twice because it will be decoded both by State Machine and SageMaker Training Job.
- __InitArgs__ *(string)* - double JSON-encoded dictionary containing parameters to be used when model is initiated `TabularPredictor()`. List of available parameters [here](https://auto.gluon.ai/stable/api/autogluon.task.html#autogluon.tabular.TabularPredictor). Dictionary needs to be encoded twice because it will be decoded both by State Machine and SageMaker Training Job. Common parameters are `label`, `problem_type` and `eval_metric`.
- __Evaluation__ (REQUIRED if `Flow.Evaluate = true`)
- __Threshold__ *(float)* - Metric threshold to consider model performance satisfactory. All metrics are maximized (e.g. losses are repesented as negative losses).
- __Metric__ *(string)* - Metric name used for evaluation. Accepted metrics correspond to avaiable [`eval_metric`](https://auto.gluon.ai/stable/api/autogluon.task.html#autogluon.tabular.TabularPredictor) from AutoGluon.
- __Deploy__ (REQUIRED if `Flow.Deploy = true`)
- __InstanceCount__ *(int)* - Number of instances to be used for training.
- __InstanceType__ *(string)* - AWS instance type to be used for training (e.g. `ml.m4.2xlarge`). See full list [here](https://aws.amazon.com/ec2/instance-types/).
- __Mode__ *(string)* - Model deployment mode. Supported modes are `batch` for SageMaker Batch Transform Job and `endpoint` for SageMaker Endpoint.
- __BatchInputDataPath__ *(string)* - (REQUIRED if `mode=batch`) S3 URI of dataset against which predictions are generated. Data must be store in `csv` format, without header and with same columns order of training dataset.
- __BatchOutputDataPath__ *(string)* - (REQUIRED if `mode=batch`) S3 URI to where to store batch predictions.
## Repo structure
* `app.py` entrypoint
* `stepfunctions_automl_workflow/lambdas/` AWS Lambda source scripts
* `stepfunctions_automl_workflow/utils/` utils functions used across for stack generation
* `stepfunctions_automl_workflow/stack.py` CDK stack definition
* `notebooks/` Jupyter Notebooks to familiarise with the artifacts
* `notebooks/input/` Input examples to be fed in State Machines
## Clean-up
WARNING: While you'll still be able to keep SageMaker artifacts, the AWS Step Functions State Machines will be deleted along with their execution history.
Clean-up all resources with `cdk destroy`.
## CDK cheatsheet
* `cdk ls` list all stacks in the app
* `cdk synth` emits the synthesized CloudFormation template
* `cdk deploy` deploy this stack to your default AWS account/region
* `cdk diff` compare deployed stack with current state
* `cdk docs` open CDK documentation
## Enjoy!