 \n",
"\n",
"You can click on that to see and check the details of the image, kernel, and instance type.\n",
"\n",
"
\n",
"\n",
"You can click on that to see and check the details of the image, kernel, and instance type.\n",
"\n",
" "
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# NOTE: THIS NOTEBOOK WILL TAKE ABOUT 30 MINUTES TO COMPLETE.\n",
"\n",
"# PLEASE BE PATIENT."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# SageMaker Pipelines\n",
"\n",
"Amazon SageMaker Pipelines support the following:\n",
"\n",
"* **Pipelines** - A Directed Acyclic Graph of steps and conditions to orchestrate SageMaker jobs and resource creation.\n",
"* **Processing Job Steps** - A simplified, managed experience on SageMaker to run data processing workloads, such as feature engineering, data validation, model evaluation, and model interpretation.\n",
"* **Training Job Steps** - An iterative process that teaches a model to make predictions by presenting examples from a training dataset.\n",
"* **Conditional Steps** - Provides conditional execution of branches in a pipeline.\n",
"* **Registering Models** - Creates a model package resource in the Model Registry that can be used to create deployable models in Amazon SageMaker.\n",
"* **Parameterized Executions** - Allows pipeline executions to vary by supplied parameters.\n",
"* **Transform Job Steps** - A batch transform to preprocess datasets to remove noise or bias that interferes with training or inference from your dataset, get inferences from large datasets, and run inference when you don't need a persistent endpoint.\n",
"\n",
"# Our Pipeline\n",
"\n",
"In the Processing Step, we perform Feature Engineering to tokenizer our dialogue inputs using the `transformer` library from HuggingFace/\n",
"\n",
"In the Training Step, we fine-tune the model to summarize dialogue effectively on the `diagsum` dataset.\n",
"\n",
"In the Evaluation Step, we take the fine-tuned model and a test dataset as input, and produce a JSON file containing evaluation metrics based on the ROUGE metric for summarization.\n",
"\n",
"In the Condition Step, we decide whether to register this model if the metrics of the model, as determined by our evaluation step, exceeded some value. "
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"import psutil\n",
"\n",
"notebook_memory = psutil.virtual_memory()\n",
"print(notebook_memory)\n",
"\n",
"if notebook_memory.total < 32 * 1000 * 1000 * 1000:\n",
" print('*******************************************') \n",
" print('YOU ARE NOT USING THE CORRECT INSTANCE TYPE')\n",
" print('PLEASE CHANGE INSTANCE TYPE TO m5.2xlarge ')\n",
" print('*******************************************')\n",
"else:\n",
" correct_instance_type=True"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"from botocore.exceptions import ClientError\n",
"\n",
"import os\n",
"import sagemaker\n",
"import logging\n",
"import boto3\n",
"import sagemaker\n",
"import pandas as pd\n",
"\n",
"sess = sagemaker.Session()\n",
"bucket = sess.default_bucket()\n",
"region = boto3.Session().region_name\n",
"\n",
"import botocore.config\n",
"\n",
"config = botocore.config.Config(\n",
" user_agent_extra='dsoaws/2.0'\n",
")\n",
"\n",
"sm = boto3.Session().client(service_name=\"sagemaker\", \n",
" region_name=region,\n",
" config=config)\n",
"s3 = boto3.Session().client(service_name=\"s3\", \n",
" region_name=region,\n",
" config=config)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"%store -r role"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Set S3 Source Location"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"%store -r raw_input_data_s3_uri"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"try:\n",
" raw_input_data_s3_uri\n",
"except NameError:\n",
" print(\"++++++++++++++++++++++++++++++++++++++++++++++\")\n",
" print(\"[ERROR] YOU HAVE TO RUN THE PREVIOUS NOTEBOOK \")\n",
" print(\"You did not have the required datasets. \")\n",
" print(\"++++++++++++++++++++++++++++++++++++++++++++++\")"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"print(raw_input_data_s3_uri)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"if not raw_input_data_s3_uri:\n",
" print(\"++++++++++++++++++++++++++++++++++++++++++++++\")\n",
" print(\"[ERROR] YOU HAVE TO RUN THE PREVIOUS NOTEBOOK \")\n",
" print(\"You did not have the required datasets. \")\n",
" print(\"++++++++++++++++++++++++++++++++++++++++++++++\")\n",
"else:\n",
" print(\"[OK]\")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Track the Pipeline as an `Experiment`"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"import time"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"running_executions = 0\n",
"completed_executions = 0\n",
"\n",
"try:\n",
" existing_pipeline_executions_response = sm.list_pipeline_executions(\n",
" PipelineName=pipeline_name,\n",
" SortOrder=\"Descending\",\n",
" )\n",
"\n",
" if \"PipelineExecutionSummaries\" in existing_pipeline_executions_response.keys():\n",
" if len(existing_pipeline_executions_response[\"PipelineExecutionSummaries\"]) > 0:\n",
" execution = existing_pipeline_executions_response[\"PipelineExecutionSummaries\"][0]\n",
" if \"PipelineExecutionStatus\" in execution:\n",
" if execution[\"PipelineExecutionStatus\"] == \"Executing\":\n",
" running_executions = running_executions + 1\n",
" else:\n",
" completed_executions = completed_executions + 1\n",
"\n",
" print(\n",
" \"[INFO] You have {} Pipeline execution(s) currently running and {} execution(s) completed.\".format(\n",
" running_executions, completed_executions\n",
" )\n",
" )\n",
" else:\n",
" print(\"[OK] Please continue.\")\n",
"except:\n",
" pass\n",
"\n",
"if running_executions == 0:\n",
" timestamp = int(time.time())\n",
" pipeline_name = \"dialogue-summary-pipeline-{}\".format(timestamp)\n",
" print(\"Created Pipeline Name: \" + pipeline_name)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"print(pipeline_name)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"%store pipeline_name"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"%store -r pipeline_experiment_name\n",
"\n",
"from smexperiments.experiment import Experiment\n",
"\n",
"pipeline_experiment = Experiment.create(\n",
" experiment_name=pipeline_name,\n",
" description=\"Dialogue Summarization Pipeline Experiment\",\n",
" sagemaker_boto_client=sm,\n",
")\n",
"pipeline_experiment_name = pipeline_experiment.experiment_name\n",
"print(\"Created Pipeline Experiment Name: {}\".format(pipeline_experiment_name))"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"print(pipeline_experiment_name)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"%store pipeline_experiment_name"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Create the `Trial`"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"from smexperiments.trial import Trial"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"%store -r pipeline_trial_name\n",
"\n",
"timestamp = int(time.time())\n",
"pipeline_trial = Trial.create(\n",
" trial_name=\"trial-{}\".format(timestamp), experiment_name=pipeline_experiment_name, sagemaker_boto_client=sm\n",
")\n",
"pipeline_trial_name = pipeline_trial.trial_name\n",
"print(\"Created Trial Name: {}\".format(pipeline_trial_name))"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"print(pipeline_trial_name)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"%store pipeline_trial_name"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Define Parameters to Parametrize Pipeline Execution\n",
"\n",
"We define Workflow Parameters by which we can parametrize our Pipeline and vary the values injected and used in Pipeline executions and schedules without having to modify the Pipeline definition.\n",
"\n",
"The supported parameter types include:\n",
"\n",
"* `ParameterString` - representing a `str` Python type\n",
"* `ParameterInteger` - representing an `int` Python type\n",
"* `ParameterFloat` - representing a `float` Python type\n",
"\n",
"These parameters support providing a default value, which can be overridden on pipeline execution. The default value specified should be an instance of the type of the parameter."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"from sagemaker.workflow.parameters import (\n",
" ParameterString,\n",
" ParameterInteger,\n",
" ParameterFloat\n",
")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Feature Engineering Step"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"%store -r raw_input_data_s3_uri"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"print(raw_input_data_s3_uri)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"!aws s3 ls $raw_input_data_s3_uri"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Setup Pipeline Parameters\n",
"These parameters are used by the entire pipeline."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"%store -r model_checkpoint"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"try:\n",
" model_checkpoint\n",
"except NameError:\n",
" print(\"++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++\")\n",
" print(\"[ERROR] Please run the notebooks in the PREPARE section before you continue.\")\n",
" print(\"++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++\")"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"print(model_checkpoint)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"model_checkpoint = ParameterString(\n",
" name=\"ModelCheckpoint\",\n",
" default_value=model_checkpoint,\n",
")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Setup Processing Parameters"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"input_data = ParameterString(\n",
" name=\"InputData\",\n",
" default_value=raw_input_data_s3_uri,\n",
")\n",
"\n",
"processing_instance_count = ParameterInteger(\n",
" name=\"ProcessingInstanceCount\",\n",
" default_value=1,\n",
")\n",
"\n",
"processing_instance_type = ParameterString(\n",
" name=\"ProcessingInstanceType\",\n",
" default_value=\"ml.c5.2xlarge\",\n",
")\n",
"\n",
"train_split_percentage = ParameterFloat(\n",
" name=\"TrainSplitPercentage\",\n",
" default_value=0.90,\n",
")\n",
"\n",
"validation_split_percentage = ParameterFloat(\n",
" name=\"ValidationSplitPercentage\",\n",
" default_value=0.05,\n",
")\n",
"\n",
"test_split_percentage = ParameterFloat(\n",
" name=\"TestSplitPercentage\",\n",
" default_value=0.05,\n",
")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"We create an instance of an `SKLearnProcessor` processor and we use that in our `ProcessingStep`."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"from sagemaker.sklearn.processing import SKLearnProcessor\n",
"\n",
"processor = SKLearnProcessor(\n",
" framework_version=\"0.23-1\",\n",
" role=role,\n",
" instance_type=processing_instance_type,\n",
" instance_count=processing_instance_count,\n",
" env={\"AWS_DEFAULT_REGION\": region},\n",
" max_runtime_in_seconds=432000,\n",
")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### _Ignore any `WARNING` ^^ above ^^._"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Setup Pipeline Step Caching\n",
"Cache pipeline steps for a duration of time using [ISO 8601](https://en.wikipedia.org/wiki/ISO_8601#Durations) format. \n",
"\n",
"More details on SageMaker Pipeline step caching here: https://docs.aws.amazon.com/sagemaker/latest/dg/pipelines-caching.html"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"from sagemaker.workflow.steps import CacheConfig\n",
"\n",
"cache_config = CacheConfig(enable_caching=True, expire_after=\"PT1H\")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Finally, we use the processor instance to construct a `ProcessingStep`, along with the input and output channels and the code that will be executed when the pipeline invokes pipeline execution. This is very similar to a processor instance's `run` method, for those familiar with the existing Python SDK.\n",
"\n",
"Note the `input_data` parameters passed into `ProcessingStep` as the input data of the step itself. This input data will be used by the processor instance when it is run.\n",
"\n",
"Also, take note the `\"train\"`, `\"validation\"` and `\"test\"` named channels specified in the output configuration for the processing job. Such step `Properties` can be used in subsequent steps and will resolve to their runtime values at execution. In particular, we'll call out this usage when we define our training step."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"from sagemaker.processing import ProcessingInput, ProcessingOutput\n",
"from sagemaker.workflow.steps import ProcessingStep\n",
"\n",
"processing_inputs = [\n",
" ProcessingInput(\n",
" input_name=\"raw-input-data\",\n",
" source=input_data,\n",
" destination=\"/opt/ml/processing/input/data/\",\n",
" s3_data_distribution_type=\"ShardedByS3Key\",\n",
" )\n",
"]\n",
"\n",
"processing_outputs = [\n",
" ProcessingOutput(\n",
" output_name=\"train\",\n",
" s3_upload_mode=\"EndOfJob\",\n",
" source=\"/opt/ml/processing/output/data/train\",\n",
" ),\n",
" ProcessingOutput(\n",
" output_name=\"validation\",\n",
" s3_upload_mode=\"EndOfJob\",\n",
" source=\"/opt/ml/processing/output/data/validation\",\n",
" ),\n",
" ProcessingOutput(\n",
" output_name=\"test\",\n",
" s3_upload_mode=\"EndOfJob\",\n",
" source=\"/opt/ml/processing/output/data/test\",\n",
" ),\n",
"]\n",
"\n",
"processing_step = ProcessingStep(\n",
" name=\"Processing\",\n",
" code=\"preprocess.py\",\n",
" processor=processor,\n",
" inputs=processing_inputs,\n",
" outputs=processing_outputs,\n",
" job_arguments=[\n",
" \"--train-split-percentage\",\n",
" str(train_split_percentage.default_value),\n",
" \"--validation-split-percentage\",\n",
" str(validation_split_percentage.default_value),\n",
" \"--test-split-percentage\",\n",
" str(test_split_percentage.default_value),\n",
" \"--model-checkpoint\",\n",
" str(model_checkpoint.default_value),\n",
" ],\n",
" cache_config=cache_config\n",
")\n",
"\n",
"print(processing_step)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Train Step"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Setup Training Hyper-Parameters"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"train_instance_type = ParameterString(name=\"TrainInstanceType\", default_value=\"ml.c5.9xlarge\")\n",
"train_instance_count = ParameterInteger(name=\"TrainInstanceCount\", default_value=1)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"epochs = ParameterInteger(name=\"Epochs\", default_value=1)\n",
"learning_rate = ParameterFloat(name=\"LearningRate\", default_value=0.00001)\n",
"weight_decay = ParameterFloat(name=\"WeightDecay\", default_value=0.01)\n",
"train_batch_size = ParameterInteger(name=\"TrainBatchSize\", default_value=4)\n",
"validation_batch_size = ParameterInteger(name=\"ValidationBatchSize\", default_value=4)\n",
"test_batch_size = ParameterInteger(name=\"TestBatchSize\", default_value=4)\n",
"train_volume_size = ParameterInteger(name=\"TrainVolumeSize\", default_value=1024)\n",
"input_mode = ParameterString(name=\"InputMode\", default_value=\"FastFile\")\n",
"train_sample_percentage = ParameterFloat(name=\"TrainSamplePercentage\", default_value=0.01)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Setup Metrics To Track Model Performance"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"metrics_definitions = [\n",
" {\"Name\": \"train:loss\", \"Regex\": \"'train_loss': ([0-9\\\\.]+)\"},\n",
" {\"Name\": \"validation:loss\", \"Regex\": \"'eval_loss': ([0-9\\\\.]+)\"},\n",
"]"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Create the Estimator\n",
"\n",
"We configure an Estimator and the input dataset. A typical training script loads data from the input channels, configures training with hyperparameters, trains a model, and saves a model to `model_dir` so that it can be hosted later.\n",
"\n",
"We also specify the model path where the models from training will be saved.\n",
"\n",
"Note the `train_instance_type` parameter passed may be also used and passed into other places in the pipeline. In this case, the `train_instance_type` is passed into the estimator."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"from sagemaker.pytorch import PyTorch\n",
"import uuid\n",
"\n",
"checkpoint_s3_prefix = \"checkpoints/{}\".format(str(uuid.uuid4()))\n",
"checkpoint_s3_uri = \"s3://{}/{}/\".format(bucket, checkpoint_s3_prefix)\n",
"\n",
"estimator = PyTorch(\n",
" entry_point=\"train.py\",\n",
" source_dir=\"src\",\n",
" role=role,\n",
" instance_count=train_instance_count,\n",
" instance_type=train_instance_type,\n",
" volume_size=train_volume_size,\n",
" py_version=\"py39\",\n",
" framework_version=\"1.13\",\n",
" hyperparameters={\n",
" \"epochs\": epochs,\n",
" \"learning_rate\": learning_rate,\n",
" \"weight_decay\": weight_decay, \n",
" \"train_batch_size\": train_batch_size,\n",
" \"validation_batch_size\": validation_batch_size,\n",
" \"test_batch_size\": test_batch_size,\n",
" \"model_checkpoint\": model_checkpoint,\n",
" \"train_sample_percentage\": train_sample_percentage,\n",
" },\n",
" input_mode=input_mode,\n",
" metric_definitions=metrics_definitions,\n",
")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Configure Training Step\n",
"\n",
"Finally, we use the estimator instance to construct a `TrainingStep` as well as the `Properties` of the prior `ProcessingStep` used as input in the `TrainingStep` inputs and the code that will be executed when the pipeline invokes pipeline execution. This is very similar to an estimator's `fit` method, for those familiar with the existing Python SDK.\n",
"\n",
"In particular, we pass in the `S3Uri` of the `\"train\"`, `\"validation\"` and `\"test\"` output channel to the `TrainingStep`. The `properties` attribute of a Workflow step match the object model of the corresponding response of a describe call. These properties can be referenced as placeholder values and are resolved, or filled in, at runtime. For example, the `ProcessingStep` `properties` attribute matches the object model of the [DescribeProcessingJob](https://docs.aws.amazon.com/sagemaker/latest/APIReference/API_DescribeProcessingJob.html) response object."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"from sagemaker.inputs import TrainingInput\n",
"from sagemaker.workflow.steps import TrainingStep\n",
"\n",
"training_step = TrainingStep(\n",
" name=\"Train\",\n",
" estimator=estimator,\n",
" inputs={\n",
" \"train\": TrainingInput(\n",
" s3_data=processing_step.properties.ProcessingOutputConfig.Outputs[\"train\"].S3Output.S3Uri,\n",
" ),\n",
" \"validation\": TrainingInput(\n",
" s3_data=processing_step.properties.ProcessingOutputConfig.Outputs[\"validation\"].S3Output.S3Uri,\n",
" ),\n",
" \"test\": TrainingInput(\n",
" s3_data=processing_step.properties.ProcessingOutputConfig.Outputs[\"test\"].S3Output.S3Uri,\n",
" ),\n",
" },\n",
" cache_config=cache_config,\n",
")\n",
"\n",
"print(training_step)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Evaluation Step\n",
"\n",
"First, we develop an evaluation script that will be specified in a Processing step that will perform the model evaluation.\n",
"\n",
"The evaluation script `evaluate_model_metrics.py` takes the trained model and the test dataset as input, and produces a JSON file containing evaluation metrics.\n",
"\n",
"After pipeline execution, we will examine the resulting `evaluation.json` for analysis.\n",
"\n",
"The evaluation script:\n",
"\n",
"* loads in the model\n",
"* reads in the test data\n",
"* issues a bunch of predictions against the test data\n",
"* builds an evaluation report\n",
"* saves the evaluation report to the evaluation directory\n",
"\n",
"Next, we create an instance of a `SKLearnProcessor` and we use that in our `ProcessingStep`.\n",
"\n",
"Note the `processing_instance_type` parameter passed into the processor."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"scrolled": true,
"tags": []
},
"outputs": [],
"source": [
"from sagemaker.sklearn.processing import SKLearnProcessor\n",
"\n",
"evaluation_processor = SKLearnProcessor(\n",
" framework_version=\"0.23-1\",\n",
" role=role,\n",
" instance_type=processing_instance_type,\n",
" instance_count=processing_instance_count,\n",
" env={\"AWS_DEFAULT_REGION\": region},\n",
" max_runtime_in_seconds=432000,\n",
")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### _Ignore any `WARNING` ^^ above ^^._"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"We use the processor instance to construct a `ProcessingStep`, along with the input and output channels and the code that will be executed when the pipeline invokes pipeline execution. This is very similar to a processor instance's `run` method, for those familiar with the existing Python SDK.\n",
"\n",
"The `TrainingStep` and `ProcessingStep` `properties` attribute matches the object model of the [DescribeTrainingJob](https://docs.aws.amazon.com/sagemaker/latest/APIReference/API_DescribeTrainingJob.html) and [DescribeProcessingJob](https://docs.aws.amazon.com/sagemaker/latest/APIReference/API_DescribeProcessingJob.html) response objects, respectively."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"from sagemaker.workflow.properties import PropertyFile\n",
"\n",
"evaluation_report = PropertyFile(name=\"EvaluationReport\", output_name=\"metrics\", path=\"evaluation.json\")"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"evaluation_step = ProcessingStep(\n",
" name=\"EvaluateModel\",\n",
" processor=evaluation_processor,\n",
" code=\"evaluate_model_metrics.py\",\n",
" inputs=[\n",
" ProcessingInput(\n",
" source=training_step.properties.ModelArtifacts.S3ModelArtifacts,\n",
" destination=\"/opt/ml/processing/input/model\" \n",
" \n",
" ),\n",
" ProcessingInput(\n",
" source=processing_step.properties.ProcessingOutputConfig.Outputs[\"test\"].S3Output.S3Uri,\n",
" destination=\"/opt/ml/processing/input/data\" \n",
" ),\n",
" ],\n",
" outputs=[\n",
" ProcessingOutput(\n",
" source=\"/opt/ml/processing/output/metrics/\",\n",
" output_name=\"metrics\", \n",
" s3_upload_mode=\"EndOfJob\" \n",
" ),\n",
" ],\n",
" property_files=[evaluation_report],\n",
")"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"from sagemaker.model_metrics import MetricsSource, ModelMetrics\n",
"\n",
"model_metrics = ModelMetrics(\n",
" model_statistics=MetricsSource(\n",
" s3_uri=\"{}/evaluation.json\".format(\n",
" evaluation_step.arguments[\"ProcessingOutputConfig\"][\"Outputs\"][0][\"S3Output\"][\"S3Uri\"]\n",
" ),\n",
" content_type=\"application/json\",\n",
" )\n",
")\n",
"\n",
"print(model_metrics)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Register Model Step\n",
"\n",
"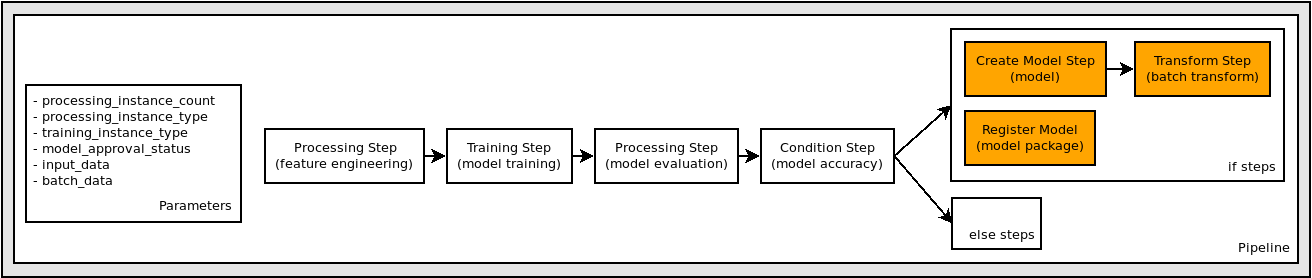\n",
"\n",
"We use the estimator instance that was used for the training step to construct an instance of `RegisterModel`. The result of executing `RegisterModel` in a pipeline is a Model Package. A Model Package is a reusable model artifacts abstraction that packages all ingredients necessary for inference. Primarily, it consists of an inference specification that defines the inference image to use along with an optional model weights location.\n",
"\n",
"A Model Package Group is a collection of Model Packages. You can create a Model Package Group for a specific ML business problem, and you can keep adding versions/model packages into it. Typically, we expect customers to create a ModelPackageGroup for a SageMaker Workflow Pipeline so that they can keep adding versions/model packages to the group for every Workflow Pipeline run.\n",
"\n",
"The construction of `RegisterModel` is very similar to an estimator instance's `register` method, for those familiar with the existing Python SDK.\n",
"\n",
"In particular, we pass in the `S3ModelArtifacts` from the `TrainingStep`, `step_train` properties. The `TrainingStep` `properties` attribute matches the object model of the [DescribeTrainingJob](https://docs.aws.amazon.com/sagemaker/latest/APIReference/API_DescribeTrainingJob.html) response object.\n",
"\n",
"Of note, we provided a specific model package group name which we will use in the Model Registry and CI/CD work later on."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"model_approval_status = ParameterString(name=\"ModelApprovalStatus\", default_value=\"PendingManualApproval\")\n",
"\n",
"deploy_instance_type = ParameterString(name=\"DeployInstanceType\", default_value=\"ml.m5.4xlarge\")\n",
"\n",
"deploy_instance_count = ParameterInteger(name=\"DeployInstanceCount\", default_value=1)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"import time\n",
"\n",
"timestamp = int(time.time())\n",
"\n",
"model_package_group_name = f\"Summarization-{timestamp}\"\n",
"\n",
"print(model_package_group_name)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"inference_image_uri = sagemaker.image_uris.retrieve(\n",
" framework=\"pytorch\",\n",
" region=region,\n",
" version=\"1.13\",\n",
" instance_type=deploy_instance_type,\n",
" image_scope=\"inference\",\n",
")\n",
"print(inference_image_uri)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"from sagemaker.workflow.step_collections import RegisterModel\n",
"\n",
"register_step = RegisterModel(\n",
" name=\"Summarization\",\n",
" estimator=estimator,\n",
" image_uri=inference_image_uri, # we have to specify, by default it's using training image\n",
" model_data=training_step.properties.ModelArtifacts.S3ModelArtifacts,\n",
" content_types=[\"application/jsonlines\"],\n",
" response_types=[\"application/jsonlines\"],\n",
" inference_instances=[deploy_instance_type],\n",
" transform_instances=[deploy_instance_type],\n",
" model_package_group_name=model_package_group_name,\n",
" approval_status=model_approval_status,\n",
" model_metrics=model_metrics,\n",
")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Create Model for Deployment Step"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"from sagemaker.model import Model\n",
"\n",
"model_name = \"model-{}\".format(timestamp)\n",
"\n",
"model = Model(\n",
" name=model_name,\n",
" image_uri=inference_image_uri,\n",
" model_data=training_step.properties.ModelArtifacts.S3ModelArtifacts,\n",
" sagemaker_session=sess,\n",
" role=role,\n",
")"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"from sagemaker.inputs import CreateModelInput\n",
"\n",
"create_inputs = CreateModelInput(\n",
" instance_type=deploy_instance_type,\n",
")"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"from sagemaker.workflow.steps import CreateModelStep\n",
"\n",
"create_step = CreateModelStep(\n",
" name=\"CreateModel\",\n",
" model=model,\n",
" inputs=create_inputs,\n",
")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Conditional Deployment Step\n",
"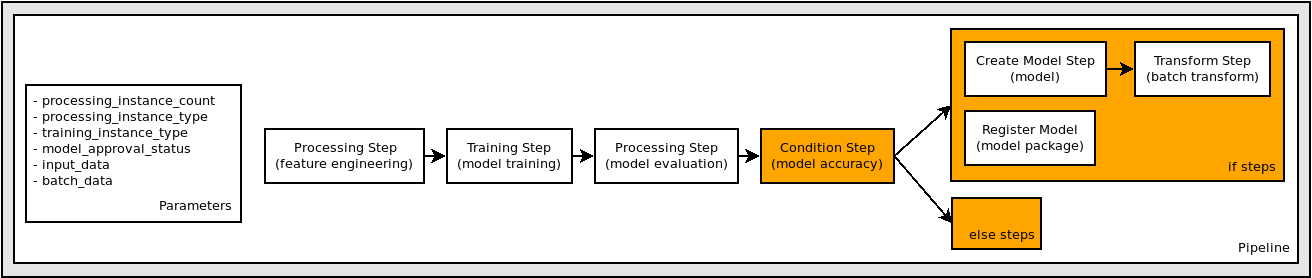\n",
"\n",
"Finally, we'd like to only register this model if the metrics of the model, as determined by our evaluation step, exceeded a given threshold. A `ConditionStep` allows for pipelines to support conditional execution in the pipeline DAG based on conditions of step properties.\n",
"\n",
"Below, we do the following:\n",
"* define a condition on the evaluation metrics found in the output of the evaluation step\n",
"* use the condition in the list of conditions in a `ConditionStep`\n",
"* pass the `RegisterModel` step collection into the `if_steps` of the `ConditionStep`"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"from sagemaker.workflow.conditions import ConditionGreaterThanOrEqualTo\n",
"from sagemaker.workflow.condition_step import (\n",
" ConditionStep,\n",
" JsonGet,\n",
")\n",
"\n",
"min_rouge_value = ParameterFloat(name=\"MinRouge1Value\", default_value=0.005)\n",
"\n",
"min_rouge_condition = ConditionGreaterThanOrEqualTo(\n",
" left=JsonGet(\n",
" step=evaluation_step,\n",
" property_file=evaluation_report,\n",
" json_path=\"metrics.eval_rouge1.value\",\n",
" ),\n",
" right=min_rouge_value, # eval_loss\n",
")\n",
"\n",
"min_rouge_condition_step = ConditionStep(\n",
" name=\"EvaluationCondition\",\n",
" conditions=[min_rouge_condition],\n",
" if_steps=[register_step, create_step], # success, continue with model registration\n",
" else_steps=[], # fail, end the pipeline\n",
")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Define a Pipeline of Parameters, Steps, and Conditions\n",
"\n",
"Let's tie it all up into a workflow pipeline so we can execute it, and even schedule it.\n",
"\n",
"A pipeline requires a `name`, `parameters`, and `steps`. Names must be unique within an `(account, region)` pair so we tack on the timestamp to the name.\n",
"\n",
"Note:\n",
"\n",
"* All the parameters used in the definitions must be present.\n",
"* Steps passed into the pipeline need not be in the order of execution. The SageMaker Workflow service will resolve the _data dependency_ DAG as steps the execution complete.\n",
"* Steps must be unique to either pipeline step list or a single condition step if/else list."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Submit the Pipeline to SageMaker for Execution \n",
"\n",
"Let's submit our pipeline definition to the workflow service. The role passed in will be used by the workflow service to create all the jobs defined in the steps."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Create Pipeline"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### _Ignore any `WARNING` below._"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"from sagemaker.workflow.pipeline import Pipeline\n",
"\n",
"existing_pipelines = 0\n",
"\n",
"existing_pipelines_response = sm.list_pipelines(\n",
" PipelineNamePrefix=pipeline_name,\n",
" SortOrder=\"Descending\",\n",
")\n",
"\n",
"if \"PipelineSummaries\" in existing_pipelines_response.keys():\n",
" if len(existing_pipelines_response[\"PipelineSummaries\"]) > 0:\n",
" existing_pipelines = existing_pipelines + 1\n",
" print(\"[INFO] You already have created {} pipeline with name {}.\".format(existing_pipelines, pipeline_name))\n",
" else:\n",
" pass\n",
"\n",
"if existing_pipelines == 0: # Only create the pipeline one time\n",
" pipeline = Pipeline(\n",
" name=pipeline_name,\n",
" parameters=[\n",
" input_data,\n",
" processing_instance_count,\n",
" processing_instance_type,\n",
" train_split_percentage,\n",
" validation_split_percentage,\n",
" test_split_percentage,\n",
" train_instance_type,\n",
" train_instance_count,\n",
" epochs,\n",
" learning_rate,\n",
" weight_decay,\n",
" train_sample_percentage,\n",
" train_batch_size,\n",
" validation_batch_size,\n",
" test_batch_size,\n",
" train_volume_size,\n",
" input_mode,\n",
" min_rouge_value,\n",
" model_approval_status,\n",
" deploy_instance_type,\n",
" deploy_instance_count,\n",
" model_checkpoint.to_string(),\n",
" ],\n",
" steps=[processing_step, training_step, evaluation_step, min_rouge_condition_step],\n",
" sagemaker_session=sess,\n",
" )\n",
"\n",
" pipeline.upsert(role_arn=role)[\"PipelineArn\"]\n",
" print(\"Created pipeline with name {}\".format(pipeline_name))\n",
"else:\n",
" print(\n",
" \"****************************************************************************************************************\"\n",
" )\n",
" print(\n",
" \"You have already create a pipeline with the name {}. This is OK. Please continue to the next cell.\".format(\n",
" pipeline_name\n",
" )\n",
" )\n",
" print(\n",
" \"****************************************************************************************************************\"\n",
" )"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### _Ignore any `WARNING` ^^ above ^^._"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Start Pipeline"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### _Ignore any `WARNING` below._"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"running_executions = 0\n",
"completed_executions = 0\n",
"\n",
"if existing_pipelines > 0:\n",
" existing_pipeline_executions_response = sm.list_pipeline_executions(\n",
" PipelineName=pipeline_name,\n",
" SortOrder=\"Descending\",\n",
" )\n",
"\n",
" if \"PipelineExecutionSummaries\" in existing_pipeline_executions_response.keys():\n",
" if len(existing_pipeline_executions_response[\"PipelineExecutionSummaries\"]) > 0:\n",
" execution = existing_pipeline_executions_response[\"PipelineExecutionSummaries\"][0]\n",
" if \"PipelineExecutionStatus\" in execution:\n",
" if execution[\"PipelineExecutionStatus\"] == \"Executing\":\n",
" running_executions = running_executions + 1\n",
" else:\n",
" completed_executions = completed_executions + 1\n",
"\n",
" print(\n",
" \"[INFO] You have {} Pipeline execution(s) currently running and {} execution(s) completed.\".format(\n",
" running_executions, completed_executions\n",
" )\n",
" )\n",
" else:\n",
" pass\n",
"else:\n",
" pass\n",
"\n",
"if running_executions == 0: # Only allow 1 pipeline execution at a time to limit the resources needed\n",
" execution = pipeline.start()\n",
" running_executions = running_executions + 1\n",
" print(\"Started pipeline {}. Ignore any warnings above.\".format(pipeline_name))\n",
" print(execution.arn)\n",
"else:\n",
" print(\n",
" \"********************************************************************************************************************\"\n",
" )\n",
" print(\n",
" \"You have already launched {} pipeline execution(s). This is OK. Please continue to see the next cell.\".format(\n",
" running_executions\n",
" )\n",
" )\n",
" print(\n",
" \"********************************************************************************************************************\"\n",
" )"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### _Ignore any `WARNING` ^^ above ^^._"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Wait for the Pipeline to Complete\n",
"\n",
"### _This next cell takes about 40 mins. Please be patient._"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"%%time\n",
"\n",
"import time\n",
"from pprint import pprint\n",
"\n",
"executions_response = sm.list_pipeline_executions(PipelineName=pipeline_name)[\"PipelineExecutionSummaries\"]\n",
"pipeline_execution_status = executions_response[0][\"PipelineExecutionStatus\"]\n",
"print(pipeline_execution_status)\n",
"\n",
"while pipeline_execution_status == \"Executing\":\n",
" try:\n",
" executions_response = sm.list_pipeline_executions(PipelineName=pipeline_name)[\"PipelineExecutionSummaries\"]\n",
" pipeline_execution_status = executions_response[0][\"PipelineExecutionStatus\"]\n",
" except Exception as e:\n",
" print(\"Please wait...\")\n",
" time.sleep(30)\n",
"\n",
"pprint(executions_response)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### _Wait for the Pipeline ^^ Above ^^ to Complete_"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# List Pipeline Execution Steps and Statuses After Completion"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"pipeline_execution_status = executions_response[0][\"PipelineExecutionStatus\"]\n",
"pipeline_execution_arn = executions_response[0][\"PipelineExecutionArn\"]\n",
"\n",
"print(\"Pipeline execution status {}\".format(pipeline_execution_status))\n",
"print(\"Pipeline execution arn {}\".format(pipeline_execution_arn))"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"from pprint import pprint\n",
"\n",
"steps = sm.list_pipeline_execution_steps(PipelineExecutionArn=pipeline_execution_arn)\n",
"\n",
"pprint(steps)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# List All Artifacts Generated by the Pipeline"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"processing_job_name = None\n",
"training_job_name = None"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"import time\n",
"from sagemaker.lineage.visualizer import LineageTableVisualizer\n",
"\n",
"viz = LineageTableVisualizer(sagemaker.session.Session())\n",
"\n",
"for execution_step in reversed(steps[\"PipelineExecutionSteps\"]):\n",
" print(execution_step)\n",
" # We are doing this because there appears to be a bug of this LineageTableVisualizer handling the Processing Step\n",
" if execution_step[\"StepName\"] == \"Processing\":\n",
" processing_job_name = execution_step[\"Metadata\"][\"ProcessingJob\"][\"Arn\"].split(\"/\")[-1]\n",
" print(processing_job_name)\n",
" display(viz.show(processing_job_name=processing_job_name))\n",
" elif execution_step[\"StepName\"] == \"Train\":\n",
" training_job_name = execution_step[\"Metadata\"][\"TrainingJob\"][\"Arn\"].split(\"/\")[-1]\n",
" print(training_job_name)\n",
" display(viz.show(training_job_name=training_job_name))\n",
" else:\n",
" display(viz.show(pipeline_execution_step=execution_step))\n",
" time.sleep(5)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Add Execution Run as Trial to Experiments"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# -aws-processing-job is the default name assigned by ProcessingJob\n",
"processing_job_tc = \"{}-aws-processing-job\".format(processing_job_name)\n",
"print(processing_job_tc)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"response = sm.associate_trial_component(TrialComponentName=processing_job_tc, TrialName=pipeline_trial_name)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# -aws-training-job is the default name assigned by TrainingJob\n",
"training_job_tc = \"{}-aws-training-job\".format(training_job_name)\n",
"print(training_job_tc)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"response = sm.associate_trial_component(TrialComponentName=training_job_tc, TrialName=pipeline_trial_name)"
]
},
{
"cell_type": "markdown",
"metadata": {
"tags": []
},
"source": [
"# Release Resources"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"%%html\n",
"\n",
"
"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# NOTE: THIS NOTEBOOK WILL TAKE ABOUT 30 MINUTES TO COMPLETE.\n",
"\n",
"# PLEASE BE PATIENT."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# SageMaker Pipelines\n",
"\n",
"Amazon SageMaker Pipelines support the following:\n",
"\n",
"* **Pipelines** - A Directed Acyclic Graph of steps and conditions to orchestrate SageMaker jobs and resource creation.\n",
"* **Processing Job Steps** - A simplified, managed experience on SageMaker to run data processing workloads, such as feature engineering, data validation, model evaluation, and model interpretation.\n",
"* **Training Job Steps** - An iterative process that teaches a model to make predictions by presenting examples from a training dataset.\n",
"* **Conditional Steps** - Provides conditional execution of branches in a pipeline.\n",
"* **Registering Models** - Creates a model package resource in the Model Registry that can be used to create deployable models in Amazon SageMaker.\n",
"* **Parameterized Executions** - Allows pipeline executions to vary by supplied parameters.\n",
"* **Transform Job Steps** - A batch transform to preprocess datasets to remove noise or bias that interferes with training or inference from your dataset, get inferences from large datasets, and run inference when you don't need a persistent endpoint.\n",
"\n",
"# Our Pipeline\n",
"\n",
"In the Processing Step, we perform Feature Engineering to tokenizer our dialogue inputs using the `transformer` library from HuggingFace/\n",
"\n",
"In the Training Step, we fine-tune the model to summarize dialogue effectively on the `diagsum` dataset.\n",
"\n",
"In the Evaluation Step, we take the fine-tuned model and a test dataset as input, and produce a JSON file containing evaluation metrics based on the ROUGE metric for summarization.\n",
"\n",
"In the Condition Step, we decide whether to register this model if the metrics of the model, as determined by our evaluation step, exceeded some value. "
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"import psutil\n",
"\n",
"notebook_memory = psutil.virtual_memory()\n",
"print(notebook_memory)\n",
"\n",
"if notebook_memory.total < 32 * 1000 * 1000 * 1000:\n",
" print('*******************************************') \n",
" print('YOU ARE NOT USING THE CORRECT INSTANCE TYPE')\n",
" print('PLEASE CHANGE INSTANCE TYPE TO m5.2xlarge ')\n",
" print('*******************************************')\n",
"else:\n",
" correct_instance_type=True"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"from botocore.exceptions import ClientError\n",
"\n",
"import os\n",
"import sagemaker\n",
"import logging\n",
"import boto3\n",
"import sagemaker\n",
"import pandas as pd\n",
"\n",
"sess = sagemaker.Session()\n",
"bucket = sess.default_bucket()\n",
"region = boto3.Session().region_name\n",
"\n",
"import botocore.config\n",
"\n",
"config = botocore.config.Config(\n",
" user_agent_extra='dsoaws/2.0'\n",
")\n",
"\n",
"sm = boto3.Session().client(service_name=\"sagemaker\", \n",
" region_name=region,\n",
" config=config)\n",
"s3 = boto3.Session().client(service_name=\"s3\", \n",
" region_name=region,\n",
" config=config)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"%store -r role"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Set S3 Source Location"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"%store -r raw_input_data_s3_uri"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"try:\n",
" raw_input_data_s3_uri\n",
"except NameError:\n",
" print(\"++++++++++++++++++++++++++++++++++++++++++++++\")\n",
" print(\"[ERROR] YOU HAVE TO RUN THE PREVIOUS NOTEBOOK \")\n",
" print(\"You did not have the required datasets. \")\n",
" print(\"++++++++++++++++++++++++++++++++++++++++++++++\")"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"print(raw_input_data_s3_uri)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"if not raw_input_data_s3_uri:\n",
" print(\"++++++++++++++++++++++++++++++++++++++++++++++\")\n",
" print(\"[ERROR] YOU HAVE TO RUN THE PREVIOUS NOTEBOOK \")\n",
" print(\"You did not have the required datasets. \")\n",
" print(\"++++++++++++++++++++++++++++++++++++++++++++++\")\n",
"else:\n",
" print(\"[OK]\")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Track the Pipeline as an `Experiment`"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"import time"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"running_executions = 0\n",
"completed_executions = 0\n",
"\n",
"try:\n",
" existing_pipeline_executions_response = sm.list_pipeline_executions(\n",
" PipelineName=pipeline_name,\n",
" SortOrder=\"Descending\",\n",
" )\n",
"\n",
" if \"PipelineExecutionSummaries\" in existing_pipeline_executions_response.keys():\n",
" if len(existing_pipeline_executions_response[\"PipelineExecutionSummaries\"]) > 0:\n",
" execution = existing_pipeline_executions_response[\"PipelineExecutionSummaries\"][0]\n",
" if \"PipelineExecutionStatus\" in execution:\n",
" if execution[\"PipelineExecutionStatus\"] == \"Executing\":\n",
" running_executions = running_executions + 1\n",
" else:\n",
" completed_executions = completed_executions + 1\n",
"\n",
" print(\n",
" \"[INFO] You have {} Pipeline execution(s) currently running and {} execution(s) completed.\".format(\n",
" running_executions, completed_executions\n",
" )\n",
" )\n",
" else:\n",
" print(\"[OK] Please continue.\")\n",
"except:\n",
" pass\n",
"\n",
"if running_executions == 0:\n",
" timestamp = int(time.time())\n",
" pipeline_name = \"dialogue-summary-pipeline-{}\".format(timestamp)\n",
" print(\"Created Pipeline Name: \" + pipeline_name)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"print(pipeline_name)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"%store pipeline_name"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"%store -r pipeline_experiment_name\n",
"\n",
"from smexperiments.experiment import Experiment\n",
"\n",
"pipeline_experiment = Experiment.create(\n",
" experiment_name=pipeline_name,\n",
" description=\"Dialogue Summarization Pipeline Experiment\",\n",
" sagemaker_boto_client=sm,\n",
")\n",
"pipeline_experiment_name = pipeline_experiment.experiment_name\n",
"print(\"Created Pipeline Experiment Name: {}\".format(pipeline_experiment_name))"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"print(pipeline_experiment_name)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"%store pipeline_experiment_name"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Create the `Trial`"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"from smexperiments.trial import Trial"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"%store -r pipeline_trial_name\n",
"\n",
"timestamp = int(time.time())\n",
"pipeline_trial = Trial.create(\n",
" trial_name=\"trial-{}\".format(timestamp), experiment_name=pipeline_experiment_name, sagemaker_boto_client=sm\n",
")\n",
"pipeline_trial_name = pipeline_trial.trial_name\n",
"print(\"Created Trial Name: {}\".format(pipeline_trial_name))"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"print(pipeline_trial_name)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"%store pipeline_trial_name"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Define Parameters to Parametrize Pipeline Execution\n",
"\n",
"We define Workflow Parameters by which we can parametrize our Pipeline and vary the values injected and used in Pipeline executions and schedules without having to modify the Pipeline definition.\n",
"\n",
"The supported parameter types include:\n",
"\n",
"* `ParameterString` - representing a `str` Python type\n",
"* `ParameterInteger` - representing an `int` Python type\n",
"* `ParameterFloat` - representing a `float` Python type\n",
"\n",
"These parameters support providing a default value, which can be overridden on pipeline execution. The default value specified should be an instance of the type of the parameter."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"from sagemaker.workflow.parameters import (\n",
" ParameterString,\n",
" ParameterInteger,\n",
" ParameterFloat\n",
")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Feature Engineering Step"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"%store -r raw_input_data_s3_uri"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"print(raw_input_data_s3_uri)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"!aws s3 ls $raw_input_data_s3_uri"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Setup Pipeline Parameters\n",
"These parameters are used by the entire pipeline."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"%store -r model_checkpoint"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"try:\n",
" model_checkpoint\n",
"except NameError:\n",
" print(\"++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++\")\n",
" print(\"[ERROR] Please run the notebooks in the PREPARE section before you continue.\")\n",
" print(\"++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++\")"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"print(model_checkpoint)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"model_checkpoint = ParameterString(\n",
" name=\"ModelCheckpoint\",\n",
" default_value=model_checkpoint,\n",
")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Setup Processing Parameters"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"input_data = ParameterString(\n",
" name=\"InputData\",\n",
" default_value=raw_input_data_s3_uri,\n",
")\n",
"\n",
"processing_instance_count = ParameterInteger(\n",
" name=\"ProcessingInstanceCount\",\n",
" default_value=1,\n",
")\n",
"\n",
"processing_instance_type = ParameterString(\n",
" name=\"ProcessingInstanceType\",\n",
" default_value=\"ml.c5.2xlarge\",\n",
")\n",
"\n",
"train_split_percentage = ParameterFloat(\n",
" name=\"TrainSplitPercentage\",\n",
" default_value=0.90,\n",
")\n",
"\n",
"validation_split_percentage = ParameterFloat(\n",
" name=\"ValidationSplitPercentage\",\n",
" default_value=0.05,\n",
")\n",
"\n",
"test_split_percentage = ParameterFloat(\n",
" name=\"TestSplitPercentage\",\n",
" default_value=0.05,\n",
")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"We create an instance of an `SKLearnProcessor` processor and we use that in our `ProcessingStep`."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"from sagemaker.sklearn.processing import SKLearnProcessor\n",
"\n",
"processor = SKLearnProcessor(\n",
" framework_version=\"0.23-1\",\n",
" role=role,\n",
" instance_type=processing_instance_type,\n",
" instance_count=processing_instance_count,\n",
" env={\"AWS_DEFAULT_REGION\": region},\n",
" max_runtime_in_seconds=432000,\n",
")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### _Ignore any `WARNING` ^^ above ^^._"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Setup Pipeline Step Caching\n",
"Cache pipeline steps for a duration of time using [ISO 8601](https://en.wikipedia.org/wiki/ISO_8601#Durations) format. \n",
"\n",
"More details on SageMaker Pipeline step caching here: https://docs.aws.amazon.com/sagemaker/latest/dg/pipelines-caching.html"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"from sagemaker.workflow.steps import CacheConfig\n",
"\n",
"cache_config = CacheConfig(enable_caching=True, expire_after=\"PT1H\")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Finally, we use the processor instance to construct a `ProcessingStep`, along with the input and output channels and the code that will be executed when the pipeline invokes pipeline execution. This is very similar to a processor instance's `run` method, for those familiar with the existing Python SDK.\n",
"\n",
"Note the `input_data` parameters passed into `ProcessingStep` as the input data of the step itself. This input data will be used by the processor instance when it is run.\n",
"\n",
"Also, take note the `\"train\"`, `\"validation\"` and `\"test\"` named channels specified in the output configuration for the processing job. Such step `Properties` can be used in subsequent steps and will resolve to their runtime values at execution. In particular, we'll call out this usage when we define our training step."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"from sagemaker.processing import ProcessingInput, ProcessingOutput\n",
"from sagemaker.workflow.steps import ProcessingStep\n",
"\n",
"processing_inputs = [\n",
" ProcessingInput(\n",
" input_name=\"raw-input-data\",\n",
" source=input_data,\n",
" destination=\"/opt/ml/processing/input/data/\",\n",
" s3_data_distribution_type=\"ShardedByS3Key\",\n",
" )\n",
"]\n",
"\n",
"processing_outputs = [\n",
" ProcessingOutput(\n",
" output_name=\"train\",\n",
" s3_upload_mode=\"EndOfJob\",\n",
" source=\"/opt/ml/processing/output/data/train\",\n",
" ),\n",
" ProcessingOutput(\n",
" output_name=\"validation\",\n",
" s3_upload_mode=\"EndOfJob\",\n",
" source=\"/opt/ml/processing/output/data/validation\",\n",
" ),\n",
" ProcessingOutput(\n",
" output_name=\"test\",\n",
" s3_upload_mode=\"EndOfJob\",\n",
" source=\"/opt/ml/processing/output/data/test\",\n",
" ),\n",
"]\n",
"\n",
"processing_step = ProcessingStep(\n",
" name=\"Processing\",\n",
" code=\"preprocess.py\",\n",
" processor=processor,\n",
" inputs=processing_inputs,\n",
" outputs=processing_outputs,\n",
" job_arguments=[\n",
" \"--train-split-percentage\",\n",
" str(train_split_percentage.default_value),\n",
" \"--validation-split-percentage\",\n",
" str(validation_split_percentage.default_value),\n",
" \"--test-split-percentage\",\n",
" str(test_split_percentage.default_value),\n",
" \"--model-checkpoint\",\n",
" str(model_checkpoint.default_value),\n",
" ],\n",
" cache_config=cache_config\n",
")\n",
"\n",
"print(processing_step)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Train Step"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Setup Training Hyper-Parameters"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"train_instance_type = ParameterString(name=\"TrainInstanceType\", default_value=\"ml.c5.9xlarge\")\n",
"train_instance_count = ParameterInteger(name=\"TrainInstanceCount\", default_value=1)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"epochs = ParameterInteger(name=\"Epochs\", default_value=1)\n",
"learning_rate = ParameterFloat(name=\"LearningRate\", default_value=0.00001)\n",
"weight_decay = ParameterFloat(name=\"WeightDecay\", default_value=0.01)\n",
"train_batch_size = ParameterInteger(name=\"TrainBatchSize\", default_value=4)\n",
"validation_batch_size = ParameterInteger(name=\"ValidationBatchSize\", default_value=4)\n",
"test_batch_size = ParameterInteger(name=\"TestBatchSize\", default_value=4)\n",
"train_volume_size = ParameterInteger(name=\"TrainVolumeSize\", default_value=1024)\n",
"input_mode = ParameterString(name=\"InputMode\", default_value=\"FastFile\")\n",
"train_sample_percentage = ParameterFloat(name=\"TrainSamplePercentage\", default_value=0.01)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Setup Metrics To Track Model Performance"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"metrics_definitions = [\n",
" {\"Name\": \"train:loss\", \"Regex\": \"'train_loss': ([0-9\\\\.]+)\"},\n",
" {\"Name\": \"validation:loss\", \"Regex\": \"'eval_loss': ([0-9\\\\.]+)\"},\n",
"]"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Create the Estimator\n",
"\n",
"We configure an Estimator and the input dataset. A typical training script loads data from the input channels, configures training with hyperparameters, trains a model, and saves a model to `model_dir` so that it can be hosted later.\n",
"\n",
"We also specify the model path where the models from training will be saved.\n",
"\n",
"Note the `train_instance_type` parameter passed may be also used and passed into other places in the pipeline. In this case, the `train_instance_type` is passed into the estimator."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"from sagemaker.pytorch import PyTorch\n",
"import uuid\n",
"\n",
"checkpoint_s3_prefix = \"checkpoints/{}\".format(str(uuid.uuid4()))\n",
"checkpoint_s3_uri = \"s3://{}/{}/\".format(bucket, checkpoint_s3_prefix)\n",
"\n",
"estimator = PyTorch(\n",
" entry_point=\"train.py\",\n",
" source_dir=\"src\",\n",
" role=role,\n",
" instance_count=train_instance_count,\n",
" instance_type=train_instance_type,\n",
" volume_size=train_volume_size,\n",
" py_version=\"py39\",\n",
" framework_version=\"1.13\",\n",
" hyperparameters={\n",
" \"epochs\": epochs,\n",
" \"learning_rate\": learning_rate,\n",
" \"weight_decay\": weight_decay, \n",
" \"train_batch_size\": train_batch_size,\n",
" \"validation_batch_size\": validation_batch_size,\n",
" \"test_batch_size\": test_batch_size,\n",
" \"model_checkpoint\": model_checkpoint,\n",
" \"train_sample_percentage\": train_sample_percentage,\n",
" },\n",
" input_mode=input_mode,\n",
" metric_definitions=metrics_definitions,\n",
")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Configure Training Step\n",
"\n",
"Finally, we use the estimator instance to construct a `TrainingStep` as well as the `Properties` of the prior `ProcessingStep` used as input in the `TrainingStep` inputs and the code that will be executed when the pipeline invokes pipeline execution. This is very similar to an estimator's `fit` method, for those familiar with the existing Python SDK.\n",
"\n",
"In particular, we pass in the `S3Uri` of the `\"train\"`, `\"validation\"` and `\"test\"` output channel to the `TrainingStep`. The `properties` attribute of a Workflow step match the object model of the corresponding response of a describe call. These properties can be referenced as placeholder values and are resolved, or filled in, at runtime. For example, the `ProcessingStep` `properties` attribute matches the object model of the [DescribeProcessingJob](https://docs.aws.amazon.com/sagemaker/latest/APIReference/API_DescribeProcessingJob.html) response object."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"from sagemaker.inputs import TrainingInput\n",
"from sagemaker.workflow.steps import TrainingStep\n",
"\n",
"training_step = TrainingStep(\n",
" name=\"Train\",\n",
" estimator=estimator,\n",
" inputs={\n",
" \"train\": TrainingInput(\n",
" s3_data=processing_step.properties.ProcessingOutputConfig.Outputs[\"train\"].S3Output.S3Uri,\n",
" ),\n",
" \"validation\": TrainingInput(\n",
" s3_data=processing_step.properties.ProcessingOutputConfig.Outputs[\"validation\"].S3Output.S3Uri,\n",
" ),\n",
" \"test\": TrainingInput(\n",
" s3_data=processing_step.properties.ProcessingOutputConfig.Outputs[\"test\"].S3Output.S3Uri,\n",
" ),\n",
" },\n",
" cache_config=cache_config,\n",
")\n",
"\n",
"print(training_step)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Evaluation Step\n",
"\n",
"First, we develop an evaluation script that will be specified in a Processing step that will perform the model evaluation.\n",
"\n",
"The evaluation script `evaluate_model_metrics.py` takes the trained model and the test dataset as input, and produces a JSON file containing evaluation metrics.\n",
"\n",
"After pipeline execution, we will examine the resulting `evaluation.json` for analysis.\n",
"\n",
"The evaluation script:\n",
"\n",
"* loads in the model\n",
"* reads in the test data\n",
"* issues a bunch of predictions against the test data\n",
"* builds an evaluation report\n",
"* saves the evaluation report to the evaluation directory\n",
"\n",
"Next, we create an instance of a `SKLearnProcessor` and we use that in our `ProcessingStep`.\n",
"\n",
"Note the `processing_instance_type` parameter passed into the processor."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"scrolled": true,
"tags": []
},
"outputs": [],
"source": [
"from sagemaker.sklearn.processing import SKLearnProcessor\n",
"\n",
"evaluation_processor = SKLearnProcessor(\n",
" framework_version=\"0.23-1\",\n",
" role=role,\n",
" instance_type=processing_instance_type,\n",
" instance_count=processing_instance_count,\n",
" env={\"AWS_DEFAULT_REGION\": region},\n",
" max_runtime_in_seconds=432000,\n",
")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### _Ignore any `WARNING` ^^ above ^^._"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"We use the processor instance to construct a `ProcessingStep`, along with the input and output channels and the code that will be executed when the pipeline invokes pipeline execution. This is very similar to a processor instance's `run` method, for those familiar with the existing Python SDK.\n",
"\n",
"The `TrainingStep` and `ProcessingStep` `properties` attribute matches the object model of the [DescribeTrainingJob](https://docs.aws.amazon.com/sagemaker/latest/APIReference/API_DescribeTrainingJob.html) and [DescribeProcessingJob](https://docs.aws.amazon.com/sagemaker/latest/APIReference/API_DescribeProcessingJob.html) response objects, respectively."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"from sagemaker.workflow.properties import PropertyFile\n",
"\n",
"evaluation_report = PropertyFile(name=\"EvaluationReport\", output_name=\"metrics\", path=\"evaluation.json\")"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"evaluation_step = ProcessingStep(\n",
" name=\"EvaluateModel\",\n",
" processor=evaluation_processor,\n",
" code=\"evaluate_model_metrics.py\",\n",
" inputs=[\n",
" ProcessingInput(\n",
" source=training_step.properties.ModelArtifacts.S3ModelArtifacts,\n",
" destination=\"/opt/ml/processing/input/model\" \n",
" \n",
" ),\n",
" ProcessingInput(\n",
" source=processing_step.properties.ProcessingOutputConfig.Outputs[\"test\"].S3Output.S3Uri,\n",
" destination=\"/opt/ml/processing/input/data\" \n",
" ),\n",
" ],\n",
" outputs=[\n",
" ProcessingOutput(\n",
" source=\"/opt/ml/processing/output/metrics/\",\n",
" output_name=\"metrics\", \n",
" s3_upload_mode=\"EndOfJob\" \n",
" ),\n",
" ],\n",
" property_files=[evaluation_report],\n",
")"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"from sagemaker.model_metrics import MetricsSource, ModelMetrics\n",
"\n",
"model_metrics = ModelMetrics(\n",
" model_statistics=MetricsSource(\n",
" s3_uri=\"{}/evaluation.json\".format(\n",
" evaluation_step.arguments[\"ProcessingOutputConfig\"][\"Outputs\"][0][\"S3Output\"][\"S3Uri\"]\n",
" ),\n",
" content_type=\"application/json\",\n",
" )\n",
")\n",
"\n",
"print(model_metrics)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Register Model Step\n",
"\n",
"\n",
"\n",
"We use the estimator instance that was used for the training step to construct an instance of `RegisterModel`. The result of executing `RegisterModel` in a pipeline is a Model Package. A Model Package is a reusable model artifacts abstraction that packages all ingredients necessary for inference. Primarily, it consists of an inference specification that defines the inference image to use along with an optional model weights location.\n",
"\n",
"A Model Package Group is a collection of Model Packages. You can create a Model Package Group for a specific ML business problem, and you can keep adding versions/model packages into it. Typically, we expect customers to create a ModelPackageGroup for a SageMaker Workflow Pipeline so that they can keep adding versions/model packages to the group for every Workflow Pipeline run.\n",
"\n",
"The construction of `RegisterModel` is very similar to an estimator instance's `register` method, for those familiar with the existing Python SDK.\n",
"\n",
"In particular, we pass in the `S3ModelArtifacts` from the `TrainingStep`, `step_train` properties. The `TrainingStep` `properties` attribute matches the object model of the [DescribeTrainingJob](https://docs.aws.amazon.com/sagemaker/latest/APIReference/API_DescribeTrainingJob.html) response object.\n",
"\n",
"Of note, we provided a specific model package group name which we will use in the Model Registry and CI/CD work later on."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"model_approval_status = ParameterString(name=\"ModelApprovalStatus\", default_value=\"PendingManualApproval\")\n",
"\n",
"deploy_instance_type = ParameterString(name=\"DeployInstanceType\", default_value=\"ml.m5.4xlarge\")\n",
"\n",
"deploy_instance_count = ParameterInteger(name=\"DeployInstanceCount\", default_value=1)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"import time\n",
"\n",
"timestamp = int(time.time())\n",
"\n",
"model_package_group_name = f\"Summarization-{timestamp}\"\n",
"\n",
"print(model_package_group_name)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"inference_image_uri = sagemaker.image_uris.retrieve(\n",
" framework=\"pytorch\",\n",
" region=region,\n",
" version=\"1.13\",\n",
" instance_type=deploy_instance_type,\n",
" image_scope=\"inference\",\n",
")\n",
"print(inference_image_uri)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"from sagemaker.workflow.step_collections import RegisterModel\n",
"\n",
"register_step = RegisterModel(\n",
" name=\"Summarization\",\n",
" estimator=estimator,\n",
" image_uri=inference_image_uri, # we have to specify, by default it's using training image\n",
" model_data=training_step.properties.ModelArtifacts.S3ModelArtifacts,\n",
" content_types=[\"application/jsonlines\"],\n",
" response_types=[\"application/jsonlines\"],\n",
" inference_instances=[deploy_instance_type],\n",
" transform_instances=[deploy_instance_type],\n",
" model_package_group_name=model_package_group_name,\n",
" approval_status=model_approval_status,\n",
" model_metrics=model_metrics,\n",
")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Create Model for Deployment Step"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"from sagemaker.model import Model\n",
"\n",
"model_name = \"model-{}\".format(timestamp)\n",
"\n",
"model = Model(\n",
" name=model_name,\n",
" image_uri=inference_image_uri,\n",
" model_data=training_step.properties.ModelArtifacts.S3ModelArtifacts,\n",
" sagemaker_session=sess,\n",
" role=role,\n",
")"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"from sagemaker.inputs import CreateModelInput\n",
"\n",
"create_inputs = CreateModelInput(\n",
" instance_type=deploy_instance_type,\n",
")"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"from sagemaker.workflow.steps import CreateModelStep\n",
"\n",
"create_step = CreateModelStep(\n",
" name=\"CreateModel\",\n",
" model=model,\n",
" inputs=create_inputs,\n",
")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Conditional Deployment Step\n",
"\n",
"\n",
"Finally, we'd like to only register this model if the metrics of the model, as determined by our evaluation step, exceeded a given threshold. A `ConditionStep` allows for pipelines to support conditional execution in the pipeline DAG based on conditions of step properties.\n",
"\n",
"Below, we do the following:\n",
"* define a condition on the evaluation metrics found in the output of the evaluation step\n",
"* use the condition in the list of conditions in a `ConditionStep`\n",
"* pass the `RegisterModel` step collection into the `if_steps` of the `ConditionStep`"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"from sagemaker.workflow.conditions import ConditionGreaterThanOrEqualTo\n",
"from sagemaker.workflow.condition_step import (\n",
" ConditionStep,\n",
" JsonGet,\n",
")\n",
"\n",
"min_rouge_value = ParameterFloat(name=\"MinRouge1Value\", default_value=0.005)\n",
"\n",
"min_rouge_condition = ConditionGreaterThanOrEqualTo(\n",
" left=JsonGet(\n",
" step=evaluation_step,\n",
" property_file=evaluation_report,\n",
" json_path=\"metrics.eval_rouge1.value\",\n",
" ),\n",
" right=min_rouge_value, # eval_loss\n",
")\n",
"\n",
"min_rouge_condition_step = ConditionStep(\n",
" name=\"EvaluationCondition\",\n",
" conditions=[min_rouge_condition],\n",
" if_steps=[register_step, create_step], # success, continue with model registration\n",
" else_steps=[], # fail, end the pipeline\n",
")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Define a Pipeline of Parameters, Steps, and Conditions\n",
"\n",
"Let's tie it all up into a workflow pipeline so we can execute it, and even schedule it.\n",
"\n",
"A pipeline requires a `name`, `parameters`, and `steps`. Names must be unique within an `(account, region)` pair so we tack on the timestamp to the name.\n",
"\n",
"Note:\n",
"\n",
"* All the parameters used in the definitions must be present.\n",
"* Steps passed into the pipeline need not be in the order of execution. The SageMaker Workflow service will resolve the _data dependency_ DAG as steps the execution complete.\n",
"* Steps must be unique to either pipeline step list or a single condition step if/else list."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Submit the Pipeline to SageMaker for Execution \n",
"\n",
"Let's submit our pipeline definition to the workflow service. The role passed in will be used by the workflow service to create all the jobs defined in the steps."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Create Pipeline"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### _Ignore any `WARNING` below._"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"from sagemaker.workflow.pipeline import Pipeline\n",
"\n",
"existing_pipelines = 0\n",
"\n",
"existing_pipelines_response = sm.list_pipelines(\n",
" PipelineNamePrefix=pipeline_name,\n",
" SortOrder=\"Descending\",\n",
")\n",
"\n",
"if \"PipelineSummaries\" in existing_pipelines_response.keys():\n",
" if len(existing_pipelines_response[\"PipelineSummaries\"]) > 0:\n",
" existing_pipelines = existing_pipelines + 1\n",
" print(\"[INFO] You already have created {} pipeline with name {}.\".format(existing_pipelines, pipeline_name))\n",
" else:\n",
" pass\n",
"\n",
"if existing_pipelines == 0: # Only create the pipeline one time\n",
" pipeline = Pipeline(\n",
" name=pipeline_name,\n",
" parameters=[\n",
" input_data,\n",
" processing_instance_count,\n",
" processing_instance_type,\n",
" train_split_percentage,\n",
" validation_split_percentage,\n",
" test_split_percentage,\n",
" train_instance_type,\n",
" train_instance_count,\n",
" epochs,\n",
" learning_rate,\n",
" weight_decay,\n",
" train_sample_percentage,\n",
" train_batch_size,\n",
" validation_batch_size,\n",
" test_batch_size,\n",
" train_volume_size,\n",
" input_mode,\n",
" min_rouge_value,\n",
" model_approval_status,\n",
" deploy_instance_type,\n",
" deploy_instance_count,\n",
" model_checkpoint.to_string(),\n",
" ],\n",
" steps=[processing_step, training_step, evaluation_step, min_rouge_condition_step],\n",
" sagemaker_session=sess,\n",
" )\n",
"\n",
" pipeline.upsert(role_arn=role)[\"PipelineArn\"]\n",
" print(\"Created pipeline with name {}\".format(pipeline_name))\n",
"else:\n",
" print(\n",
" \"****************************************************************************************************************\"\n",
" )\n",
" print(\n",
" \"You have already create a pipeline with the name {}. This is OK. Please continue to the next cell.\".format(\n",
" pipeline_name\n",
" )\n",
" )\n",
" print(\n",
" \"****************************************************************************************************************\"\n",
" )"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### _Ignore any `WARNING` ^^ above ^^._"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Start Pipeline"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### _Ignore any `WARNING` below._"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"running_executions = 0\n",
"completed_executions = 0\n",
"\n",
"if existing_pipelines > 0:\n",
" existing_pipeline_executions_response = sm.list_pipeline_executions(\n",
" PipelineName=pipeline_name,\n",
" SortOrder=\"Descending\",\n",
" )\n",
"\n",
" if \"PipelineExecutionSummaries\" in existing_pipeline_executions_response.keys():\n",
" if len(existing_pipeline_executions_response[\"PipelineExecutionSummaries\"]) > 0:\n",
" execution = existing_pipeline_executions_response[\"PipelineExecutionSummaries\"][0]\n",
" if \"PipelineExecutionStatus\" in execution:\n",
" if execution[\"PipelineExecutionStatus\"] == \"Executing\":\n",
" running_executions = running_executions + 1\n",
" else:\n",
" completed_executions = completed_executions + 1\n",
"\n",
" print(\n",
" \"[INFO] You have {} Pipeline execution(s) currently running and {} execution(s) completed.\".format(\n",
" running_executions, completed_executions\n",
" )\n",
" )\n",
" else:\n",
" pass\n",
"else:\n",
" pass\n",
"\n",
"if running_executions == 0: # Only allow 1 pipeline execution at a time to limit the resources needed\n",
" execution = pipeline.start()\n",
" running_executions = running_executions + 1\n",
" print(\"Started pipeline {}. Ignore any warnings above.\".format(pipeline_name))\n",
" print(execution.arn)\n",
"else:\n",
" print(\n",
" \"********************************************************************************************************************\"\n",
" )\n",
" print(\n",
" \"You have already launched {} pipeline execution(s). This is OK. Please continue to see the next cell.\".format(\n",
" running_executions\n",
" )\n",
" )\n",
" print(\n",
" \"********************************************************************************************************************\"\n",
" )"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### _Ignore any `WARNING` ^^ above ^^._"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Wait for the Pipeline to Complete\n",
"\n",
"### _This next cell takes about 40 mins. Please be patient._"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"%%time\n",
"\n",
"import time\n",
"from pprint import pprint\n",
"\n",
"executions_response = sm.list_pipeline_executions(PipelineName=pipeline_name)[\"PipelineExecutionSummaries\"]\n",
"pipeline_execution_status = executions_response[0][\"PipelineExecutionStatus\"]\n",
"print(pipeline_execution_status)\n",
"\n",
"while pipeline_execution_status == \"Executing\":\n",
" try:\n",
" executions_response = sm.list_pipeline_executions(PipelineName=pipeline_name)[\"PipelineExecutionSummaries\"]\n",
" pipeline_execution_status = executions_response[0][\"PipelineExecutionStatus\"]\n",
" except Exception as e:\n",
" print(\"Please wait...\")\n",
" time.sleep(30)\n",
"\n",
"pprint(executions_response)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### _Wait for the Pipeline ^^ Above ^^ to Complete_"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# List Pipeline Execution Steps and Statuses After Completion"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"pipeline_execution_status = executions_response[0][\"PipelineExecutionStatus\"]\n",
"pipeline_execution_arn = executions_response[0][\"PipelineExecutionArn\"]\n",
"\n",
"print(\"Pipeline execution status {}\".format(pipeline_execution_status))\n",
"print(\"Pipeline execution arn {}\".format(pipeline_execution_arn))"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"from pprint import pprint\n",
"\n",
"steps = sm.list_pipeline_execution_steps(PipelineExecutionArn=pipeline_execution_arn)\n",
"\n",
"pprint(steps)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# List All Artifacts Generated by the Pipeline"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"processing_job_name = None\n",
"training_job_name = None"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"import time\n",
"from sagemaker.lineage.visualizer import LineageTableVisualizer\n",
"\n",
"viz = LineageTableVisualizer(sagemaker.session.Session())\n",
"\n",
"for execution_step in reversed(steps[\"PipelineExecutionSteps\"]):\n",
" print(execution_step)\n",
" # We are doing this because there appears to be a bug of this LineageTableVisualizer handling the Processing Step\n",
" if execution_step[\"StepName\"] == \"Processing\":\n",
" processing_job_name = execution_step[\"Metadata\"][\"ProcessingJob\"][\"Arn\"].split(\"/\")[-1]\n",
" print(processing_job_name)\n",
" display(viz.show(processing_job_name=processing_job_name))\n",
" elif execution_step[\"StepName\"] == \"Train\":\n",
" training_job_name = execution_step[\"Metadata\"][\"TrainingJob\"][\"Arn\"].split(\"/\")[-1]\n",
" print(training_job_name)\n",
" display(viz.show(training_job_name=training_job_name))\n",
" else:\n",
" display(viz.show(pipeline_execution_step=execution_step))\n",
" time.sleep(5)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Add Execution Run as Trial to Experiments"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# -aws-processing-job is the default name assigned by ProcessingJob\n",
"processing_job_tc = \"{}-aws-processing-job\".format(processing_job_name)\n",
"print(processing_job_tc)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"response = sm.associate_trial_component(TrialComponentName=processing_job_tc, TrialName=pipeline_trial_name)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# -aws-training-job is the default name assigned by TrainingJob\n",
"training_job_tc = \"{}-aws-training-job\".format(training_job_name)\n",
"print(training_job_tc)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"response = sm.associate_trial_component(TrialComponentName=training_job_tc, TrialName=pipeline_trial_name)"
]
},
{
"cell_type": "markdown",
"metadata": {
"tags": []
},
"source": [
"# Release Resources"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"%%html\n",
"\n",
"Shutting down your kernel for this notebook to release resources.
\n", "\n", " \n", "" ] }, { "cell_type": "code", "execution_count": null, "metadata": {}, "outputs": [], "source": [] } ], "metadata": { "availableInstances": [ { "_defaultOrder": 0, "_isFastLaunch": true, "category": "General purpose", "gpuNum": 0, "hideHardwareSpecs": false, "memoryGiB": 4, "name": "ml.t3.medium", "vcpuNum": 2 }, { "_defaultOrder": 1, "_isFastLaunch": false, "category": "General purpose", "gpuNum": 0, "hideHardwareSpecs": false, "memoryGiB": 8, "name": "ml.t3.large", "vcpuNum": 2 }, { "_defaultOrder": 2, "_isFastLaunch": false, "category": "General purpose", "gpuNum": 0, "hideHardwareSpecs": false, "memoryGiB": 16, "name": "ml.t3.xlarge", "vcpuNum": 4 }, { "_defaultOrder": 3, "_isFastLaunch": false, "category": "General purpose", "gpuNum": 0, "hideHardwareSpecs": false, "memoryGiB": 32, "name": "ml.t3.2xlarge", "vcpuNum": 8 }, { "_defaultOrder": 4, "_isFastLaunch": true, "category": "General purpose", "gpuNum": 0, "hideHardwareSpecs": false, "memoryGiB": 8, "name": "ml.m5.large", "vcpuNum": 2 }, { "_defaultOrder": 5, "_isFastLaunch": false, "category": "General purpose", "gpuNum": 0, "hideHardwareSpecs": false, "memoryGiB": 16, "name": "ml.m5.xlarge", "vcpuNum": 4 }, { "_defaultOrder": 6, "_isFastLaunch": false, "category": "General purpose", "gpuNum": 0, "hideHardwareSpecs": false, "memoryGiB": 32, "name": "ml.m5.2xlarge", "vcpuNum": 8 }, { "_defaultOrder": 7, "_isFastLaunch": false, "category": "General purpose", "gpuNum": 0, "hideHardwareSpecs": false, "memoryGiB": 64, "name": "ml.m5.4xlarge", "vcpuNum": 16 }, { "_defaultOrder": 8, "_isFastLaunch": false, "category": "General purpose", "gpuNum": 0, "hideHardwareSpecs": false, "memoryGiB": 128, "name": "ml.m5.8xlarge", "vcpuNum": 32 }, { "_defaultOrder": 9, "_isFastLaunch": false, "category": "General purpose", "gpuNum": 0, "hideHardwareSpecs": false, "memoryGiB": 192, "name": "ml.m5.12xlarge", "vcpuNum": 48 }, { "_defaultOrder": 10, "_isFastLaunch": false, "category": "General purpose", "gpuNum": 0, "hideHardwareSpecs": false, "memoryGiB": 256, "name": "ml.m5.16xlarge", "vcpuNum": 64 }, { "_defaultOrder": 11, "_isFastLaunch": false, "category": "General purpose", "gpuNum": 0, "hideHardwareSpecs": false, "memoryGiB": 384, "name": "ml.m5.24xlarge", "vcpuNum": 96 }, { "_defaultOrder": 12, "_isFastLaunch": false, "category": "General purpose", "gpuNum": 0, "hideHardwareSpecs": false, "memoryGiB": 8, "name": "ml.m5d.large", "vcpuNum": 2 }, { "_defaultOrder": 13, "_isFastLaunch": false, "category": "General purpose", "gpuNum": 0, "hideHardwareSpecs": false, "memoryGiB": 16, "name": "ml.m5d.xlarge", "vcpuNum": 4 }, { "_defaultOrder": 14, "_isFastLaunch": false, "category": "General purpose", "gpuNum": 0, "hideHardwareSpecs": false, "memoryGiB": 32, "name": "ml.m5d.2xlarge", "vcpuNum": 8 }, { "_defaultOrder": 15, "_isFastLaunch": false, "category": "General purpose", "gpuNum": 0, "hideHardwareSpecs": false, "memoryGiB": 64, "name": "ml.m5d.4xlarge", "vcpuNum": 16 }, { "_defaultOrder": 16, "_isFastLaunch": false, "category": "General purpose", "gpuNum": 0, "hideHardwareSpecs": false, "memoryGiB": 128, "name": "ml.m5d.8xlarge", "vcpuNum": 32 }, { "_defaultOrder": 17, "_isFastLaunch": false, "category": "General purpose", "gpuNum": 0, "hideHardwareSpecs": false, "memoryGiB": 192, "name": "ml.m5d.12xlarge", "vcpuNum": 48 }, { "_defaultOrder": 18, "_isFastLaunch": false, "category": "General purpose", "gpuNum": 0, "hideHardwareSpecs": false, "memoryGiB": 256, "name": "ml.m5d.16xlarge", "vcpuNum": 64 }, { "_defaultOrder": 19, "_isFastLaunch": false, "category": "General purpose", "gpuNum": 0, "hideHardwareSpecs": false, "memoryGiB": 384, "name": "ml.m5d.24xlarge", "vcpuNum": 96 }, { "_defaultOrder": 20, "_isFastLaunch": false, "category": "General purpose", "gpuNum": 0, "hideHardwareSpecs": true, "memoryGiB": 0, "name": "ml.geospatial.interactive", "supportedImageNames": [ "sagemaker-geospatial-v1-0" ], "vcpuNum": 0 }, { "_defaultOrder": 21, "_isFastLaunch": true, "category": "Compute optimized", "gpuNum": 0, "hideHardwareSpecs": false, "memoryGiB": 4, "name": "ml.c5.large", "vcpuNum": 2 }, { "_defaultOrder": 22, "_isFastLaunch": false, "category": "Compute optimized", "gpuNum": 0, "hideHardwareSpecs": false, "memoryGiB": 8, "name": "ml.c5.xlarge", "vcpuNum": 4 }, { "_defaultOrder": 23, "_isFastLaunch": false, "category": "Compute optimized", "gpuNum": 0, "hideHardwareSpecs": false, "memoryGiB": 16, "name": "ml.c5.2xlarge", "vcpuNum": 8 }, { "_defaultOrder": 24, "_isFastLaunch": false, "category": "Compute optimized", "gpuNum": 0, "hideHardwareSpecs": false, "memoryGiB": 32, "name": "ml.c5.4xlarge", "vcpuNum": 16 }, { "_defaultOrder": 25, "_isFastLaunch": false, "category": "Compute optimized", "gpuNum": 0, "hideHardwareSpecs": false, "memoryGiB": 72, "name": "ml.c5.9xlarge", "vcpuNum": 36 }, { "_defaultOrder": 26, "_isFastLaunch": false, "category": "Compute optimized", "gpuNum": 0, "hideHardwareSpecs": false, "memoryGiB": 96, "name": "ml.c5.12xlarge", "vcpuNum": 48 }, { "_defaultOrder": 27, "_isFastLaunch": false, "category": "Compute optimized", "gpuNum": 0, "hideHardwareSpecs": false, "memoryGiB": 144, "name": "ml.c5.18xlarge", "vcpuNum": 72 }, { "_defaultOrder": 28, "_isFastLaunch": false, "category": "Compute optimized", "gpuNum": 0, "hideHardwareSpecs": false, "memoryGiB": 192, "name": "ml.c5.24xlarge", "vcpuNum": 96 }, { "_defaultOrder": 29, "_isFastLaunch": true, "category": "Accelerated computing", "gpuNum": 1, "hideHardwareSpecs": false, "memoryGiB": 16, "name": "ml.g4dn.xlarge", "vcpuNum": 4 }, { "_defaultOrder": 30, "_isFastLaunch": false, "category": "Accelerated computing", "gpuNum": 1, "hideHardwareSpecs": false, "memoryGiB": 32, "name": "ml.g4dn.2xlarge", "vcpuNum": 8 }, { "_defaultOrder": 31, "_isFastLaunch": false, "category": "Accelerated computing", "gpuNum": 1, "hideHardwareSpecs": false, "memoryGiB": 64, "name": "ml.g4dn.4xlarge", "vcpuNum": 16 }, { "_defaultOrder": 32, "_isFastLaunch": false, "category": "Accelerated computing", "gpuNum": 1, "hideHardwareSpecs": false, "memoryGiB": 128, "name": "ml.g4dn.8xlarge", "vcpuNum": 32 }, { "_defaultOrder": 33, "_isFastLaunch": false, "category": "Accelerated computing", "gpuNum": 4, "hideHardwareSpecs": false, "memoryGiB": 192, "name": "ml.g4dn.12xlarge", "vcpuNum": 48 }, { "_defaultOrder": 34, "_isFastLaunch": false, "category": "Accelerated computing", "gpuNum": 1, "hideHardwareSpecs": false, "memoryGiB": 256, "name": "ml.g4dn.16xlarge", "vcpuNum": 64 }, { "_defaultOrder": 35, "_isFastLaunch": false, "category": "Accelerated computing", "gpuNum": 1, "hideHardwareSpecs": false, "memoryGiB": 61, "name": "ml.p3.2xlarge", "vcpuNum": 8 }, { "_defaultOrder": 36, "_isFastLaunch": false, "category": "Accelerated computing", "gpuNum": 4, "hideHardwareSpecs": false, "memoryGiB": 244, "name": "ml.p3.8xlarge", "vcpuNum": 32 }, { "_defaultOrder": 37, "_isFastLaunch": false, "category": "Accelerated computing", "gpuNum": 8, "hideHardwareSpecs": false, "memoryGiB": 488, "name": "ml.p3.16xlarge", "vcpuNum": 64 }, { "_defaultOrder": 38, "_isFastLaunch": false, "category": "Accelerated computing", "gpuNum": 8, "hideHardwareSpecs": false, "memoryGiB": 768, "name": "ml.p3dn.24xlarge", "vcpuNum": 96 }, { "_defaultOrder": 39, "_isFastLaunch": false, "category": "Memory Optimized", "gpuNum": 0, "hideHardwareSpecs": false, "memoryGiB": 16, "name": "ml.r5.large", "vcpuNum": 2 }, { "_defaultOrder": 40, "_isFastLaunch": false, "category": "Memory Optimized", "gpuNum": 0, "hideHardwareSpecs": false, "memoryGiB": 32, "name": "ml.r5.xlarge", "vcpuNum": 4 }, { "_defaultOrder": 41, "_isFastLaunch": false, "category": "Memory Optimized", "gpuNum": 0, "hideHardwareSpecs": false, "memoryGiB": 64, "name": "ml.r5.2xlarge", "vcpuNum": 8 }, { "_defaultOrder": 42, "_isFastLaunch": false, "category": "Memory Optimized", "gpuNum": 0, "hideHardwareSpecs": false, "memoryGiB": 128, "name": "ml.r5.4xlarge", "vcpuNum": 16 }, { "_defaultOrder": 43, "_isFastLaunch": false, "category": "Memory Optimized", "gpuNum": 0, "hideHardwareSpecs": false, "memoryGiB": 256, "name": "ml.r5.8xlarge", "vcpuNum": 32 }, { "_defaultOrder": 44, "_isFastLaunch": false, "category": "Memory Optimized", "gpuNum": 0, "hideHardwareSpecs": false, "memoryGiB": 384, "name": "ml.r5.12xlarge", "vcpuNum": 48 }, { "_defaultOrder": 45, "_isFastLaunch": false, "category": "Memory Optimized", "gpuNum": 0, "hideHardwareSpecs": false, "memoryGiB": 512, "name": "ml.r5.16xlarge", "vcpuNum": 64 }, { "_defaultOrder": 46, "_isFastLaunch": false, "category": "Memory Optimized", "gpuNum": 0, "hideHardwareSpecs": false, "memoryGiB": 768, "name": "ml.r5.24xlarge", "vcpuNum": 96 }, { "_defaultOrder": 47, "_isFastLaunch": false, "category": "Accelerated computing", "gpuNum": 1, "hideHardwareSpecs": false, "memoryGiB": 16, "name": "ml.g5.xlarge", "vcpuNum": 4 }, { "_defaultOrder": 48, "_isFastLaunch": false, "category": "Accelerated computing", "gpuNum": 1, "hideHardwareSpecs": false, "memoryGiB": 32, "name": "ml.g5.2xlarge", "vcpuNum": 8 }, { "_defaultOrder": 49, "_isFastLaunch": false, "category": "Accelerated computing", "gpuNum": 1, "hideHardwareSpecs": false, "memoryGiB": 64, "name": "ml.g5.4xlarge", "vcpuNum": 16 }, { "_defaultOrder": 50, "_isFastLaunch": false, "category": "Accelerated computing", "gpuNum": 1, "hideHardwareSpecs": false, "memoryGiB": 128, "name": "ml.g5.8xlarge", "vcpuNum": 32 }, { "_defaultOrder": 51, "_isFastLaunch": false, "category": "Accelerated computing", "gpuNum": 1, "hideHardwareSpecs": false, "memoryGiB": 256, "name": "ml.g5.16xlarge", "vcpuNum": 64 }, { "_defaultOrder": 52, "_isFastLaunch": false, "category": "Accelerated computing", "gpuNum": 4, "hideHardwareSpecs": false, "memoryGiB": 192, "name": "ml.g5.12xlarge", "vcpuNum": 48 }, { "_defaultOrder": 53, "_isFastLaunch": false, "category": "Accelerated computing", "gpuNum": 4, "hideHardwareSpecs": false, "memoryGiB": 384, "name": "ml.g5.24xlarge", "vcpuNum": 96 }, { "_defaultOrder": 54, "_isFastLaunch": false, "category": "Accelerated computing", "gpuNum": 8, "hideHardwareSpecs": false, "memoryGiB": 768, "name": "ml.g5.48xlarge", "vcpuNum": 192 }, { "_defaultOrder": 55, "_isFastLaunch": false, "category": "Accelerated computing", "gpuNum": 8, "hideHardwareSpecs": false, "memoryGiB": 1152, "name": "ml.p4d.24xlarge", "vcpuNum": 96 }, { "_defaultOrder": 56, "_isFastLaunch": false, "category": "Accelerated computing", "gpuNum": 8, "hideHardwareSpecs": false, "memoryGiB": 1152, "name": "ml.p4de.24xlarge", "vcpuNum": 96 } ], "instance_type": "ml.m5.2xlarge", "kernelspec": { "display_name": "Python 3 (Data Science)", "language": "python", "name": "python3__SAGEMAKER_INTERNAL__arn:aws:sagemaker:us-east-1:081325390199:image/datascience-1.0" }, "language_info": { "codemirror_mode": { "name": "ipython", "version": 3 }, "file_extension": ".py", "mimetype": "text/x-python", "name": "python", "nbconvert_exporter": "python", "pygments_lexer": "ipython3", "version": "3.7.10" } }, "nbformat": 4, "nbformat_minor": 4 }