{
"cells": [
{
"cell_type": "markdown",
"metadata": {
"pycharm": {
"name": "#%% md\n"
}
},
"source": [
"# Visual image search\n",
"_**Using a Convolutional Neural Net and OpenSearch k-Nearest Neighbors Index to retrieve visually similar images**_\n",
"\n",
"---\n",
"\n",
"---\n",
"\n",
"## Contents\n",
"\n",
"\n",
"1. [Background](#Background)\n",
"1. [Setup](#Setup)\n",
"1. [TensorFlow Model Preparation](#TensorFlow-Model-Preparation)\n",
"1. [SageMaker Model Hosting](#SageMaker-Model-Hosting)\n",
"1. [Build a KNN Index in OpenSearch](#Build-a-KNN-Index-in-OpenSearch)\n",
"1. [Evaluate Index Search Results](#Evaluate-Index-Search-Results)\n",
"1. [Demo application](#Configuring-our-full-stack-visual-search-application)\n",
"1. [Extensions](#Extensions)\n",
"1. [Cleanup](#Cleanup)\n",
"\n",
"## Background\n",
"\n",
"In this notebook, we'll build the core components of a visual image search application. Visual image search is used in interfaces where instead of asking for something by voice or text, you show a photographic example of what you are looking for.\n",
"\n",
"One of the core components of visual image search is a convolutional neural net (CNN) model that generates “feature vectors” representing both a query image and the reference item images to be compared against the query. The reference item feature vectors typically are generated offline and must be stored in a database of some sort, so they can be efficiently searched. For small reference item datasets, it is possible to use a brute force search that compares the query against every reference item. However, this is not feasible for large data sets where brute force search would become prohibitively slow. \n",
"\n",
"To enable efficient searches for visually similar images, we'll use Amazon SageMaker to generate “feature vectors” from images and use KNN algorithm in Amazon OpenSearch Service. KNN for Amazon OpenSearch Service lets you search for points in a vector space and find the \"nearest neighbors\" for those points by Euclidean distance or cosine similarity(default is Euclidean distance). Use cases include recommendations (for example, an \"other songs you might like\" feature in a music application), image recognition, and fraud detection.\n",
"\n",
"Here are the steps we'll follow to build the visual image search: After some initial setup, we'll prepare a model using TensorFlow for generating feature vectors, then generate feature vectors of Fashion Images from *__feidegger__*, a *__zalandoresearch__* dataset. Those feature vectors will be imported in Amazon Elasticsearch KNN Index. Next, we'll explore some test image queries, and visualize the results.\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"pycharm": {
"name": "#%% md\n"
}
},
"source": [
"## Setup"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"pycharm": {
"name": "#%%\n"
}
},
"outputs": [],
"source": [
"#Install tqdm to have progress bar\n",
"!pip install tqdm\n",
"\n",
"#install necessary pkg to make connection with opensearch domain\n",
"!pip install opensearch-py\n",
"!pip install requests\n",
"!pip install retry"
]
},
{
"cell_type": "code",
"execution_count": null,
"outputs": [],
"source": [
"import boto3\n",
"import re\n",
"import sagemaker\n",
"from sagemaker import get_execution_role\n",
"\n",
"role = get_execution_role()\n",
"\n",
"s3_resource = boto3.resource(\"s3\")\n",
"s3 = boto3.client('s3')"
],
"metadata": {
"collapsed": false,
"pycharm": {
"name": "#%%\n"
}
}
},
{
"cell_type": "code",
"execution_count": null,
"outputs": [],
"source": [
"cfn = boto3.client('cloudformation')\n",
"\n",
"def get_cfn_outputs(stackname):\n",
" outputs = {}\n",
" for output in cfn.describe_stacks(StackName=stackname)['Stacks'][0]['Outputs']:\n",
" outputs[output['OutputKey']] = output['OutputValue']\n",
" return outputs\n",
"\n",
"## Setup variables to use for the rest of the demo\n",
"cloudformation_stack_name = \"VisualSearchEngineInfraStack\"\n",
"\n",
"outputs = get_cfn_outputs(cloudformation_stack_name)\n",
"\n",
"bucket = outputs['S3TrainingBucketOutput']\n",
"oss_host = outputs['OpenSearchHostName']\n",
"backend_lambda_arn = outputs[\"PostFetchSimilarPhotosLambda\"]\n",
"api = outputs[\"ImageSimilarityApi\"]\n",
"website_url = outputs[\"S3WebsiteURLOutput\"]\n",
"\n",
"outputs"
],
"metadata": {
"collapsed": false,
"pycharm": {
"name": "#%%\n"
}
}
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"pycharm": {
"name": "#%%\n"
}
},
"outputs": [],
"source": [
"cfn = boto3.client('cloudformation')\n",
"\n",
"def get_cfn_outputs(stackname):\n",
" outputs = {}\n",
" for output in cfn.describe_stacks(StackName=stackname)['Stacks'][0]['Outputs']:\n",
" outputs[output['OutputKey']] = output['OutputValue']\n",
" return outputs\n",
"\n",
"## Setup variables to use for the rest of the demo\n",
"cloudformation_stack_name = \"VisualSearchEngineInfraStack\"\n",
"\n",
"outputs = get_cfn_outputs(cloudformation_stack_name)\n",
"\n",
"bucket = outputs['S3TrainingBucketOutput']\n",
"oss_host = outputs['OpenSearchHostName']\n",
"backend_lambda_arn = outputs[\"PostFetchSimilarPhotosLambda\"]\n",
"api = outputs[\"ImageSimilarityApi\"]\n",
"website_url = outputs[\"S3WebsiteURLOutput\"]\n",
"\n",
"outputs"
]
},
{
"cell_type": "markdown",
"metadata": {
"pycharm": {
"name": "#%% md\n"
}
},
"source": [
"## Zalando Research data\n",
"\n",
"The dataset itself consists of 8732 high-resolution images, each depicting a dress from the available on the Zalando shop against a white-background. \n",
"\n",
"**Downloading Zalando Research data** - https://github.com/zalandoresearch/feidegger\n",
"\n",
"### For simplicity, we've already downloaded and copied it under the S3 Training Bucket. You can explore it using the S3 console if you wish!\n",
"\n",
" **Citation:**
\n",
" *@inproceedings{lefakis2018feidegger,*
\n",
" *title={FEIDEGGER: A Multi-modal Corpus of Fashion Images and Descriptions in German},*
\n",
" *author={Lefakis, Leonidas and Akbik, Alan and Vollgraf, Roland},*
\n",
" *booktitle = {{LREC} 2018, 11th Language Resources and Evaluation Conference},*
\n",
" *year = {2018}*
\n",
" *}*"
]
},
{
"cell_type": "markdown",
"metadata": {
"pycharm": {
"name": "#%% md\n"
}
},
"source": [
"## TensorFlow Model Preparation\n",
"\n",
"We'll use TensorFlow backend to prepare a model for \"featurizing\" images into feature vectors. TensorFlow has a native Module API, as well as a higher level Keras API. \n",
"\n",
"We will start with a pretrained model, avoiding spending time and money training a model from scratch. Accordingly, as a first step in preparing the model, we'll import a pretrained model from Keras application. Researchers have experimented with various pretrained CNN architectures with different numbers of layers, discovering that there are several good possibilities.\n",
"\n",
"In this notebook, we'll select a model based on the ResNet architecture, a commonly used choice. Of the various choices for number of layers, ranging from 18 to 152, we'll use 50 layers. This also is a common choice that balances the expressiveness of the resulting feature vectors (embeddings) against computational efficiency (lower number of layers means greater efficiency at the cost of less expressiveness)."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"pycharm": {
"name": "#%%\n"
}
},
"outputs": [],
"source": [
"import os\n",
"import json\n",
"import time\n",
"import tensorflow as tf\n",
"from tensorflow.keras.preprocessing import image\n",
"from tensorflow.keras.applications.resnet50 import ResNet50, preprocess_input\n",
"import sagemaker\n",
"from PIL import Image\n",
"from sagemaker.tensorflow import TensorFlow"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"pycharm": {
"name": "#%%\n"
}
},
"outputs": [],
"source": [
"# Set the channel first for better performance\n",
"from tensorflow.keras import backend\n",
"backend.set_image_data_format('channels_first')\n",
"print(backend.image_data_format())"
]
},
{
"cell_type": "markdown",
"metadata": {
"pycharm": {
"name": "#%% md\n"
}
},
"source": [
"Now we'll get a reference Xception model which is trained on Imagenet dataset to extract the feature without the actual classifier. Xception is a convolutional neural network that is 71 layers deep. More specifically, we'll use that layer to generate a row vector of floating point numbers as an \"embedding\" or representation of the features of the image. We'll also save the model as *SavedModel* format under **export/Servo/1** to serve from SageMaker TensorFlow serving API."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"pycharm": {
"name": "#%%\n"
}
},
"outputs": [],
"source": [
"# Import Xception model\n",
"model = tf.keras.applications.Xception(weights='imagenet', include_top=False,input_shape=(3, 224, 224),pooling='avg')\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"pycharm": {
"name": "#%%\n"
}
},
"outputs": [],
"source": [
"model.summary()"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"pycharm": {
"name": "#%%\n"
}
},
"outputs": [],
"source": [
"# Creating the directory strcture with model version\n",
"dirName = 'export/Xception/1'\n",
"if not os.path.exists(dirName):\n",
" os.makedirs(dirName)\n",
" print(\"Directory \" , dirName , \" Created \")\n",
"else: \n",
" print(\"Directory \" , dirName , \" already exists\") "
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"pycharm": {
"name": "#%%\n"
}
},
"outputs": [],
"source": [
"# Save the model in SavedModel format\n",
"model.save('./export/Xception/1/', save_format='tf')"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"pycharm": {
"name": "#%%\n"
}
},
"outputs": [],
"source": [
"# Check the model Signature\n",
"!saved_model_cli show --dir ./export/Xception/1/ --tag_set serve --signature_def serving_default"
]
},
{
"cell_type": "markdown",
"metadata": {
"pycharm": {
"name": "#%% md\n"
}
},
"source": [
"## SageMaker Model Hosting\n",
"\n",
"After saving the feature extractor model we will deploy the model using Sagemaker Tensorflow Serving api which is a flexible, high-performance serving system for machine learning models, designed for production environments.TensorFlow Serving makes it easy to deploy new algorithms and experiments, while keeping the same server architecture and APIs. TensorFlow Serving provides out-of-the-box integration with TensorFlow models, but can be easily extended to serve other types of models and data. We will define **inference.py** to customize the input data to TensorFlow serving API. We also need to add **requirements.txt** file for aditional libraby in the tensorflow serving container."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"pycharm": {
"name": "#%%\n"
}
},
"outputs": [],
"source": [
"# check the actual content of inference.py\n",
"!pygmentize src/inference.py"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"pycharm": {
"name": "#%%\n"
}
},
"outputs": [],
"source": [
"import tarfile\n",
"\n",
"# zip the model .gz format\n",
"model_version = '1'\n",
"export_dir = 'export/Xception/' + model_version\n",
"with tarfile.open('model.tar.gz', mode='w:gz') as archive:\n",
" archive.add('export', recursive=True)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"pycharm": {
"name": "#%%\n"
}
},
"outputs": [],
"source": [
"# Upload the model to S3\n",
"sagemaker_session = sagemaker.Session()\n",
"inputs = sagemaker_session.upload_data(path='model.tar.gz', key_prefix='model')\n",
"inputs"
]
},
{
"cell_type": "markdown",
"metadata": {
"pycharm": {
"name": "#%% md\n"
}
},
"source": [
"After we upload the model to S3 we will use TensorFlow serving container to host the model. We are using ml.m5.xlarge instance type with gpu acceleration of ml.eia1.medium. We will use this endpoint to generate features and import into ElasticSearch. You can also choose to use p3 type gpu instances for better performance."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"pycharm": {
"name": "#%%\n"
}
},
"outputs": [],
"source": [
"# Deploy the model in Sagemaker Endpoint. This process will take ~10 min. We'll be using GPU accelerated inference.\n",
"\n",
"from sagemaker.tensorflow import TensorFlowModel\n",
"\n",
"sagemaker_model = TensorFlowModel(entry_point='inference.py', model_data = 's3://' + sagemaker_session.default_bucket() + '/model/model.tar.gz',\n",
" role = role, framework_version='2.3', source_dir='./src' )\n",
"\n",
"predictor = sagemaker_model.deploy(initial_instance_count=5, instance_type='ml.m5.xlarge', accelerator_type=\"ml.eia1.medium\")\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"pycharm": {
"name": "#%%\n"
}
},
"outputs": [],
"source": [
"%%time\n",
"# get the features for a sample image\n",
"from sagemaker.serializers import IdentitySerializer\n",
"payload = s3.get_object(Bucket=bucket,Key='data/feidegger/fashion/0000723855b24fbe806c20a1abd9d5dc.jpg')['Body'].read()\n",
"predictor.serializer = IdentitySerializer(content_type='application/x-image')\n",
"features = predictor.predict(payload)['predictions'][0]\n",
"\n",
"# Here are the features extracted from the second last layer of the network\n",
"features\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"pycharm": {
"name": "#%% md\n"
}
},
"source": [
"## Build a KNN Index in OpenSearch\n",
"\n",
"KNN for Amazon OpenSearch Service lets you search for points in a vector space and find the \"nearest neighbors\" for those points by Euclidean distance or cosine similarity (default is Euclidean distance). Use cases include recommendations (for example, an \"other songs you might like\" feature in a music application), image recognition, and fraud detection.\n",
"\n",
"Full documentation for the OpenSearch feature, including descriptions of settings and statistics, is available here - https://docs.aws.amazon.com/opensearch-service/latest/developerguide/knn.html\n",
"\n",
"In this step we'll get all the features zalando images and import those features into OpenSearch 1.2 domain."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"pycharm": {
"name": "#%%\n"
}
},
"outputs": [],
"source": [
"# Define some utility function\n",
"\n",
"# return all s3 keys\n",
"def get_all_s3_keys(bucket):\n",
" \"\"\"Get a list of all keys in an S3 bucket.\"\"\" \n",
" keys = []\n",
"\n",
" kwargs = {'Bucket': bucket}\n",
" while True:\n",
" resp = s3.list_objects_v2(**kwargs)\n",
" for obj in resp['Contents']:\n",
" keys.append('s3://' + bucket + '/' + obj['Key'])\n",
"\n",
" try:\n",
" kwargs['ContinuationToken'] = resp['NextContinuationToken']\n",
" except KeyError:\n",
" break\n",
"\n",
" return keys"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"pycharm": {
"name": "#%%\n"
}
},
"outputs": [],
"source": [
"# get all the zalando images keys from the bucket make a list\n",
"s3_uris = get_all_s3_keys(bucket)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"pycharm": {
"name": "#%%\n"
}
},
"outputs": [],
"source": [
"# define a function to extract image features\n",
"from time import sleep\n",
"\n",
"sm_client = boto3.client('sagemaker-runtime')\n",
"ENDPOINT_NAME = predictor.endpoint_name\n",
"\n",
"def get_predictions(payload):\n",
" return sm_client.invoke_endpoint(EndpointName=ENDPOINT_NAME,\n",
" ContentType='application/x-image',\n",
" Body=payload)\n",
"\n",
"def extract_features(s3_uri):\n",
" key = s3_uri.replace(f's3://{bucket}/', '')\n",
" payload = s3.get_object(Bucket=bucket,Key=key)['Body'].read()\n",
" try:\n",
" response = get_predictions(payload)\n",
" except:\n",
" sleep(0.1)\n",
" response = get_predictions(payload)\n",
"\n",
" del payload\n",
" response_body = json.loads((response['Body'].read()))\n",
" feature_lst = response_body['predictions'][0]\n",
" \n",
" return key, feature_lst\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"pycharm": {
"name": "#%% md\n"
}
},
"source": [
"*** Next step will take ~ 5-10 min. It will extract the features using the sagemaker inference endpoint from all the images in our training bucket. You can choose to skip this step and move directly to the next one by using a saved pickle file. ***"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"pycharm": {
"name": "#%%\n"
}
},
"outputs": [],
"source": [
"# This process cell will take approximately 24-25 minutes on a t3.medium notebook instance\n",
"# with 3 m5.xlarge SageMaker Hosted Endpoint instances\n",
"from multiprocessing import cpu_count\n",
"from tqdm.contrib.concurrent import process_map\n",
"import pickle\n",
"\n",
"workers = 2 * cpu_count()\n",
"extraction_result = process_map(extract_features, s3_uris, max_workers=workers)\n",
"with open('extraction_result_file.pkl', 'wb') as extraction_result_file:\n",
" pickle.dump(extraction_result, extraction_result_file, protocol=pickle.HIGHEST_PROTOCOL)\n",
" extraction_result_file.close()"
]
},
{
"cell_type": "markdown",
"metadata": {
"pycharm": {
"name": "#%% md\n"
}
},
"source": [
"If you skipped the last step, please execute the next cell to unpickle the extraction results from the saved file.\n",
"\n",
"**Note: If you get an Unpickling Error in the next step, please run the skipped step. As the data file is corrupted and needs to be rebuilt.**"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"pycharm": {
"name": "#%%\n"
}
},
"outputs": [],
"source": [
"import pickle\n",
"\n",
"with open('extraction_result_file.pkl', 'rb') as extraction_result_file:\n",
" extraction_result = pickle.load(extraction_result_file)\n",
" extraction_result_file.close()"
]
},
{
"cell_type": "markdown",
"metadata": {
"pycharm": {
"name": "#%% md\n"
}
},
"source": [
"### Creating an OpenSearch KNN index and loading our extracted features for all the images into that"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"pycharm": {
"name": "#%%\n"
}
},
"outputs": [],
"source": [
"# setting up the Elasticsearch connection\n",
"from opensearchpy import OpenSearch, RequestsHttpConnection, AWSV4SignerAuth\n",
"region = boto3.Session().region_name # e.g. us-east-1\n",
"credentials = boto3.Session().get_credentials()\n",
"auth = AWSV4SignerAuth(credentials, region)\n",
"\n",
"oss = OpenSearch(\n",
" hosts = [{'host': oss_host, 'port': 443}],\n",
" http_auth = auth,\n",
" use_ssl = True,\n",
" verify_certs = True,\n",
" connection_class = RequestsHttpConnection\n",
")"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"pycharm": {
"name": "#%%\n"
}
},
"outputs": [],
"source": [
"# Define KNN OpenSearch index maping\n",
"knn_index = {\n",
" \"settings\": {\n",
" \"index.knn\": True\n",
" },\n",
" \"mappings\": {\n",
" \"properties\": {\n",
" \"zalando_img_vector\": {\n",
" \"type\": \"knn_vector\",\n",
" \"dimension\": 2048\n",
" }\n",
" }\n",
" }\n",
"}"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"pycharm": {
"name": "#%%\n"
}
},
"outputs": [],
"source": [
"# Creating the OpenSearch index\n",
"oss.indices.create(index=\"idx_zalando\",body=knn_index,ignore=400)\n",
"oss.indices.get(index=\"idx_zalando\")"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"pycharm": {
"name": "#%%\n"
}
},
"outputs": [],
"source": [
"# defining a function to import the feature vectors corresponds to each S3 URI into OpenSearch KNN index\n",
"# This process will take around ~3 min.\n",
"\n",
"\n",
"def oss_import(i):\n",
" oss.index(index='idx_zalando',\n",
" body={\"zalando_img_vector\": i[1], \n",
" \"image\": i[0]}\n",
" )\n",
" \n",
"result = process_map(oss_import, extraction_result, max_workers=workers)"
]
},
{
"cell_type": "markdown",
"metadata": {
"pycharm": {
"name": "#%% md\n"
}
},
"source": [
"## Evaluate Index Search Results\n",
"\n",
"In this step we will use SageMaker SDK as well as Boto3 SDK to query the OpenSearch to retrive the nearest neighbours. One thing to mention **zalando** dataset has pretty good similarity with Imagenet dataset. Now if you hav a very domain specific problem then then you need to train that dataset on top of pretrained feature extractor model such as VGG, Resnet, Mobilenet etc and build a new feature extractor model."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"pycharm": {
"name": "#%%\n"
}
},
"outputs": [],
"source": [
"# define display_image function\n",
"def display_image(bucket, key):\n",
" response = s3.get_object(Bucket=bucket,Key=key)['Body']\n",
" img = Image.open(response)\n",
" return display(img)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"pycharm": {
"name": "#%%\n"
}
},
"outputs": [],
"source": [
"import requests\n",
"import random\n",
"from PIL import Image\n",
"import io\n",
"url = \"https://www.77onlineshop.eu/$WS/77onlineshop/websale8_shop-77onlineshop/produkte/medien/bilder/gross/21031469.jpg\"\n",
"\n",
"img_bytes = requests.get(url).content\n",
"query_img = Image.open(io.BytesIO(img_bytes))\n",
"query_img"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"pycharm": {
"name": "#%%\n"
}
},
"outputs": [],
"source": [
"# Get image features through the SageMaker SDK by calling our SageMaker inference endpoint\n",
"from sagemaker.serializers import IdentitySerializer\n",
"predictor.serializer = IdentitySerializer(content_type='application/x-image')\n",
"features = predictor.predict(img_bytes)['predictions'][0]"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"pycharm": {
"name": "#%%\n"
}
},
"outputs": [],
"source": [
"import json\n",
"k = 3 # Set to the number of nearest matches\n",
"idx_name = 'idx_zalando'\n",
"res = oss.search(request_timeout=30, index=idx_name,\n",
" body={'size': k, \n",
" 'query': {'knn': {'zalando_img_vector': {'vector': features, 'k': k}}}})"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"pycharm": {
"name": "#%%\n"
}
},
"outputs": [],
"source": [
"for i in range(k):\n",
" key = res['hits']['hits'][i]['_source']['image']\n",
" img = display_image(bucket,key)"
]
},
{
"cell_type": "markdown",
"metadata": {
"pycharm": {
"name": "#%% md\n"
}
},
"source": [
"# Configuring our full-stack visual search application"
]
},
{
"cell_type": "markdown",
"metadata": {
"pycharm": {
"name": "#%% md\n"
}
},
"source": [
"Updating our lambda function with sagemaker endpoint created during the lab"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"pycharm": {
"name": "#%%\n"
}
},
"outputs": [],
"source": [
"lambda_client = boto3.client('lambda')\n",
"response = lambda_client.update_function_configuration(\n",
" FunctionName=backend_lambda_arn,\n",
" Environment={\n",
" \"Variables\": {\n",
" \"SM_ENDPOINT\": ENDPOINT_NAME,\n",
" \"OSS_ENDPOINT\": oss_host,\n",
" \"S3_TRAINING_BUCKET\": bucket\n",
" }\n",
" }\n",
")"
]
},
{
"cell_type": "markdown",
"metadata": {
"pycharm": {
"name": "#%% md\n"
}
},
"source": [
"Now that you have a working Amazon SageMaker endpoint for extracting image features and a KNN index on OpenSearch, you are ready to build a real-world full-stack ML-powered web app. Amazon API Gateway and AWS Lambda function were created as part of the infra setup before the lab using cdk. The Lambda function runs your code in response to HTTP requests that are sent to the API Gateway."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"pycharm": {
"name": "#%%\n"
}
},
"outputs": [],
"source": [
"# Review the content of the Lambda function code.\n",
"!pygmentize backend/index.py"
]
},
{
"cell_type": "markdown",
"metadata": {
"pycharm": {
"name": "#%% md\n"
}
},
"source": [
"### And that's it, you're ready to play around with the app"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"pycharm": {
"name": "#%%\n"
}
},
"outputs": [],
"source": [
"print('Click the URL below:\\n')\n",
"print(website_url + '/index.html')"
]
},
{
"cell_type": "markdown",
"metadata": {
"pycharm": {
"name": "#%% md\n"
}
},
"source": [
"You should see the following page:\n",
"\n",
"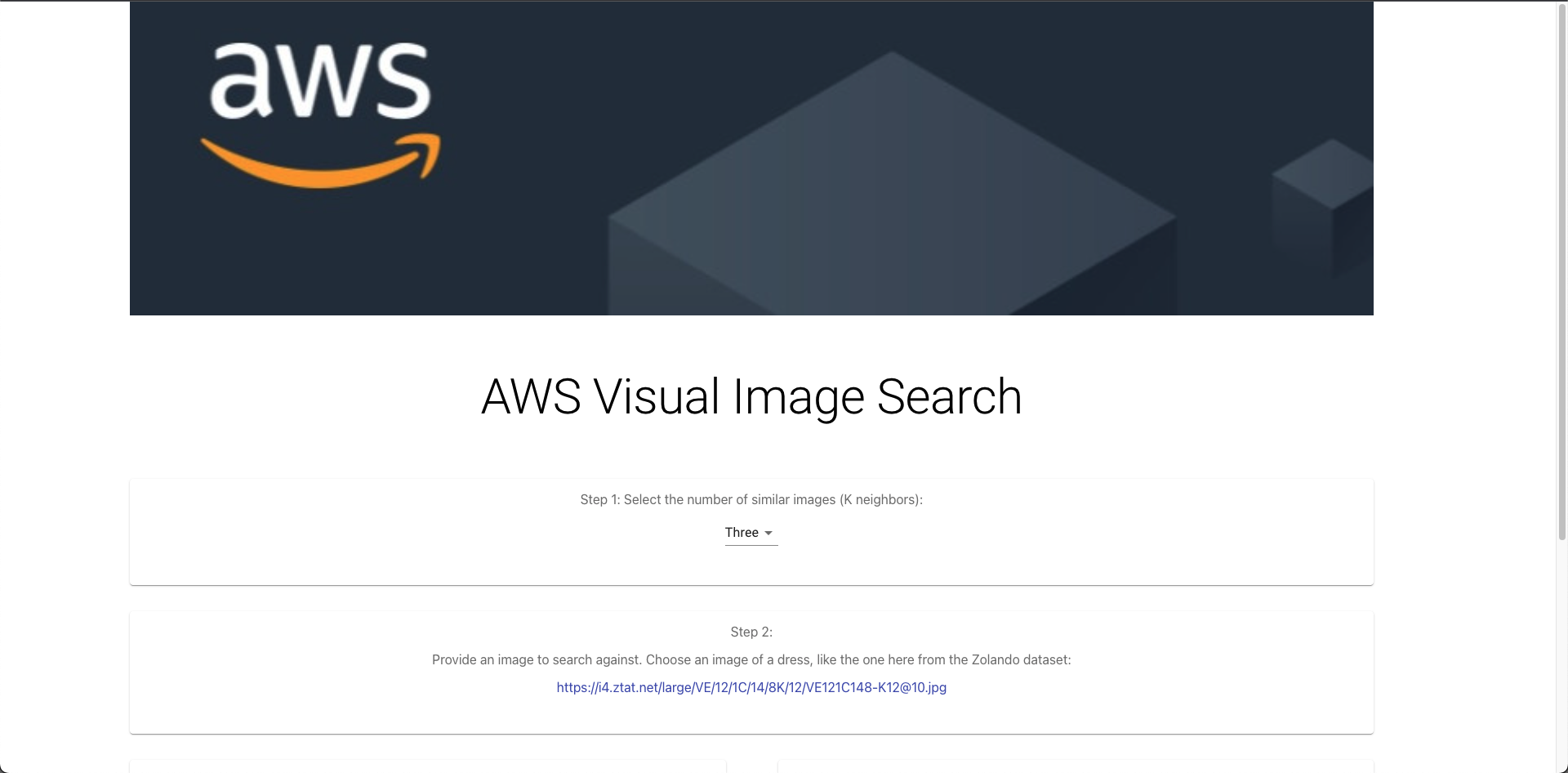\n",
"\n",
"On the website, try pasting the following URL in the URL text field.\n",
"\n",
"`https://www.77onlineshop.eu/$WS/77onlineshop/websale8_shop-77onlineshop/produkte/medien/bilder/gross/21031469.jpg`"
]
},
{
"cell_type": "markdown",
"metadata": {
"pycharm": {
"name": "#%% md\n"
}
},
"source": [
"## Extensions\n",
"\n",
"We have used pretrained Xception model which is trained on Imagenet dataset. Now based on your use-case you can fine tune any pre-trained models, such as VGG, Resnet, and MobileNet with your own dataset and host the model in Amazon SageMaker.\n",
"\n",
"You can also use Amazon SageMaker Batch transform job to have a bulk feaures extracted from your stored S3 images and then you can use AWS Glue to import that data into Elasticeearch domain.\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"pycharm": {
"name": "#%% md\n"
}
},
"source": [
"### Cleanup\n",
"\n",
"Make sure that you delete the Amazon SageMaker endpoint and delete the features form the Elasticsearch domain to prevent any additional charges."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"pycharm": {
"name": "#%%\n"
}
},
"outputs": [],
"source": [
"# Delete the endpoint\n",
"predictor.delete_endpoint()"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"pycharm": {
"name": "#%%\n"
}
},
"outputs": [],
"source": [
"# Delete the OpenSearch index that holds the image features\n",
"oss.indices.delete(index = \"idx_zalando\")"
]
}
],
"metadata": {
"instance_type": "ml.m5.2xlarge",
"kernelspec": {
"display_name": "Python 3 (TensorFlow 2.6 Python 3.8 CPU Optimized)",
"language": "python",
"name": "python3__SAGEMAKER_INTERNAL__arn:aws:sagemaker:us-east-1:081325390199:image/tensorflow-2.6-cpu-py38-ubuntu20.04-v1"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.8.2"
}
},
"nbformat": 4,
"nbformat_minor": 4
}