Copyright Amazon.com, Inc. or its affiliates. All Rights Reserved.
SPDX-License-Identifier: CC-BY-SA-4.0
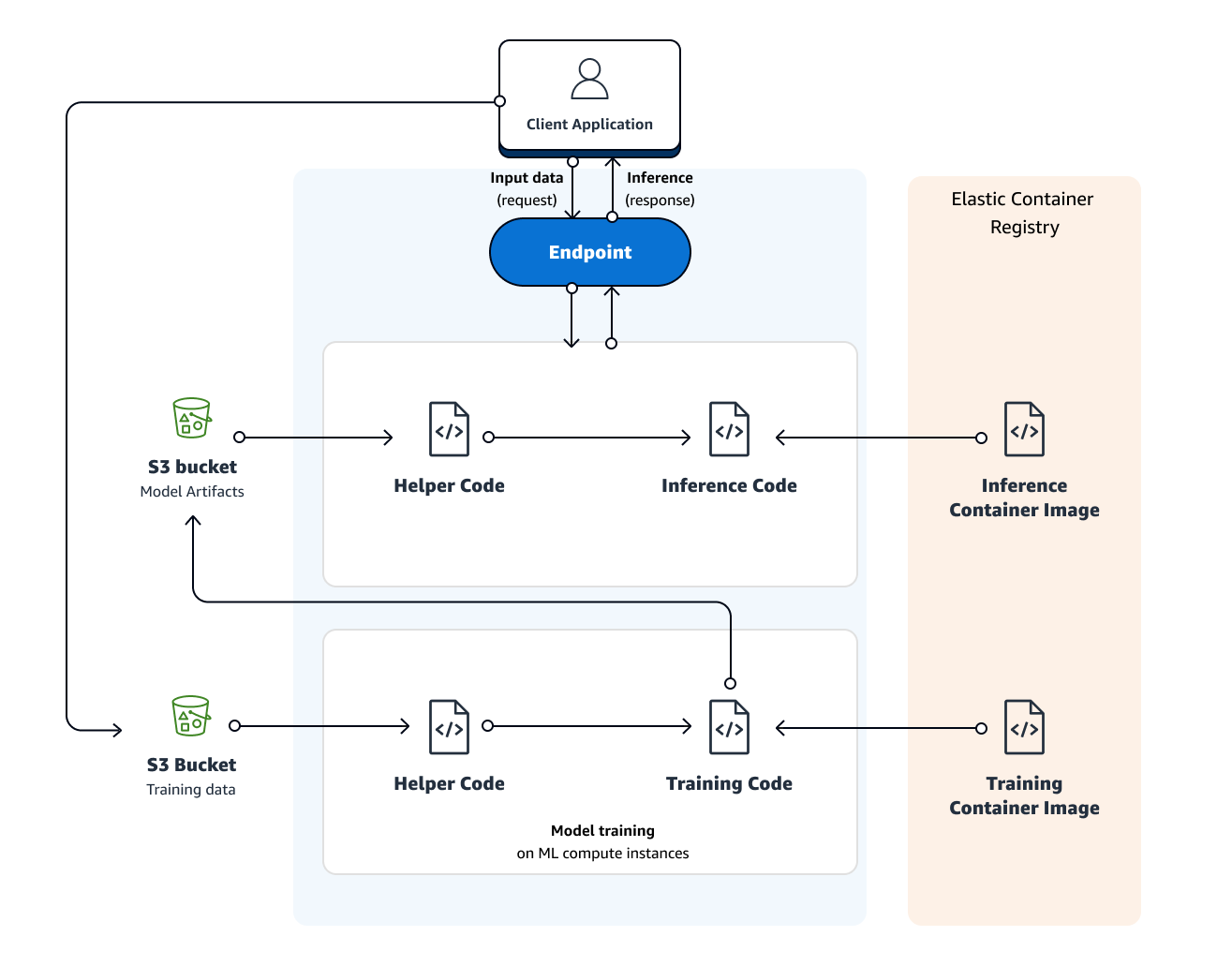
The following diagram shows how you train and deploy a model with Amazon SageMaker:
The area labeled Amazon SageMaker highlights the two components of Amazon SageMaker: model training and model deployment.
To train a model in Amazon SageMaker, you create a training job. The training job includes the following information: + The URL of the Amazon Simple Storage Service (Amazon S3) bucket where you’ve stored the training data. + The compute resources that you want Amazon SageMaker to use for model training. Compute resources are ML compute instances that are managed by Amazon SageMaker. + The URL of the S3 bucket where you want to store the output of the job. + The Amazon Elastic Container Registry path where the training code is stored. For more information, see Common Parameters for Built-In Algorithms.
You have the following options for a training algorithm: + Use an algorithm provided by Amazon SageMaker—Amazon SageMaker provides training algorithms. If one of these meets your needs, it’s a great out-of-the-box solution for quick model training. For a list of algorithms provided by Amazon SageMaker, see Use Amazon SageMaker Built-in Algorithms. To try an exercise that uses an algorithm provided by Amazon SageMaker, see Get Started. + Use Apache Spark with Amazon SageMaker—Amazon SageMaker provides a library that you can use in Apache Spark to train models with Amazon SageMaker. Using the library provided by Amazon SageMaker is similar to using Apache Spark MLLib. For more information, see Use Apache Spark with Amazon SageMaker. + Submit custom code to train with deep learning frameworks—You can submit custom Python code that uses TensorFlow or Apache MXNet for model training. For more information, see Use TensorFlow with Amazon SageMaker and Use Apache MXNet with Amazon SageMaker. + Use your own custom algorithms—Put your code together as a Docker image and specify the registry path of the image in an Amazon SageMaker CreateTrainingJob API call. For more information, see Use Your Own Algorithms or Models with Amazon SageMaker. + Use an algorithm that you subscribe to from AWS Marketplace—For information, see Find and Subscribe to Algorithms and Model Packages on AWS Marketplace.
After you create the training job, Amazon SageMaker launches the ML compute instances and uses the training code and the training dataset to train the model. It saves the resulting model artifacts and other output in the S3 bucket you specified for that purpose.
You can create a training job with the Amazon SageMaker console or the API. For information about creating a training job with the API, see the CreateTrainingJob API.
When you create a training job with the API, Amazon SageMaker replicates the entire dataset on ML compute instances by default. To make Amazon SageMaker replicate a subset of the data on each ML compute instance, you must set the S3DataDistributionType field to ShardedByS3Key. You can set this field using the low-level SDK. For more information, see S3DataDistributionType in S3DataSource.
Important
To prevent your algorithm container from contending for memory, you should reserve some memory for Amazon SageMaker critical system processes on your ML compute instances. If the algorithm container is allowed to use memory needed for system processes, it can trigger a system failure.
