{
"cells": [
{
"attachments": {},
"cell_type": "markdown",
"id": "10cb3098",
"metadata": {},
"source": [
"# Lab 4 - Building the LLM-powered chatbot \"AWSomeChat\" with retrieval-augmented generation\n",
"\n",
"## Introduction\n",
"\n",
"Language models have recently exploded in both size and popularity. In 2018, BERT-large entered the scene and, with its 340M parameters and novel transformer architecture, set the standard on NLP task accuracy. Within just a few years, state-of-the-art NLP model size has grown by more than 500x with models such as OpenAI’s 175 billion parameter GPT-3 and similarly sized open source Bloom 176B raising the bar on NLP accuracy. This increase in the number of parameters is driven by the simple and empirically-demonstrated positive relationship between model size and accuracy: more is better. With easy access from models zoos such as HuggingFace and improved accuracy in NLP tasks such as classification and text generation, practitioners are increasingly reaching for these large models. However, deploying them can be a challenge because of their size. \n",
"\n",
"While these models are able to generalize quite well and hence are capable to perform a vast amount of different generic tasks without having specifically being trained on them, they also lack domain-specific, proprietary and recent knowledge. This however is required in most use cases across organisations. With fine-tuning, in Lab 2 we already learned an option to infuse domain-specific or proprietary knowledge into a Large Language Model. However, this option can become complex and costly, especially if carried out on a regular basis to ensure access to recent information. Luckily there are several design patterns wrapping Large Language Models into powerful applications able to overcome even these challenges with a leightweight footprint. \n",
"\n",
"In this Lab, we'll explore how to build GenAI-powered applications capable of performing tasks within a specific domain. The application we will be building in a step-by-step process leverages the retrieval-augmented generation (RAG) design pattern and consists of multiple components ranging out of the broad service portfolio of AWS. \n",
"\n",
"## Background and Details\n",
"\n",
"We have two primary [types of knowledge for LLMs](https://www.pinecone.io/learn/langchain-retrieval-augmentation/): \n",
"- **Parametric knowledge**: refers to everything the LLM learned during training and acts as a frozen snapshot of the world for the LLM. \n",
"- **Source knowledge**: covers any information fed into the LLM via the input prompt. \n",
"\n",
"When trying to infuse knowledge into a generative AI - powered application we need to choose which of these types to target. Lab 2 deals with elevating the parametric knowledge through fine-tuning. Since fine-tuning is a resouce intensive operation, this option is well suited for infusing static domain-specific information like domain-specific langauage/writing styles (medical domain, science domain, ...) or optimizing performance towards a very specific task (classification, sentiment analysis, RLHF, instruction-finetuning, ...). \n",
"\n",
"In contrast to that, targeting the source knowledge for domain-specific performance uplift is very well suited for all kinds of dynamic information, from knowledge bases in structured and unstructured form up to integration of information from live systems. This Lab is about retrieval-augmented generation, a common design pattern for ingesting domain-specific information through the source knowledge. It is particularily well suited for ingestion of information in form of unstructured text with semi-frequent update cycles. \n",
"\n",
"The application we will be building in this lab will be a LLM-powered chatbot infused with domain specific knowledge on AWS services. You will be able to chat through a chatbot frontend and receive information going beyond the parametric knowledge encoded in the model. \n",
"\n",
"\n",
"### Retrieval-augmented generation (RAG)\n",
"\n",
"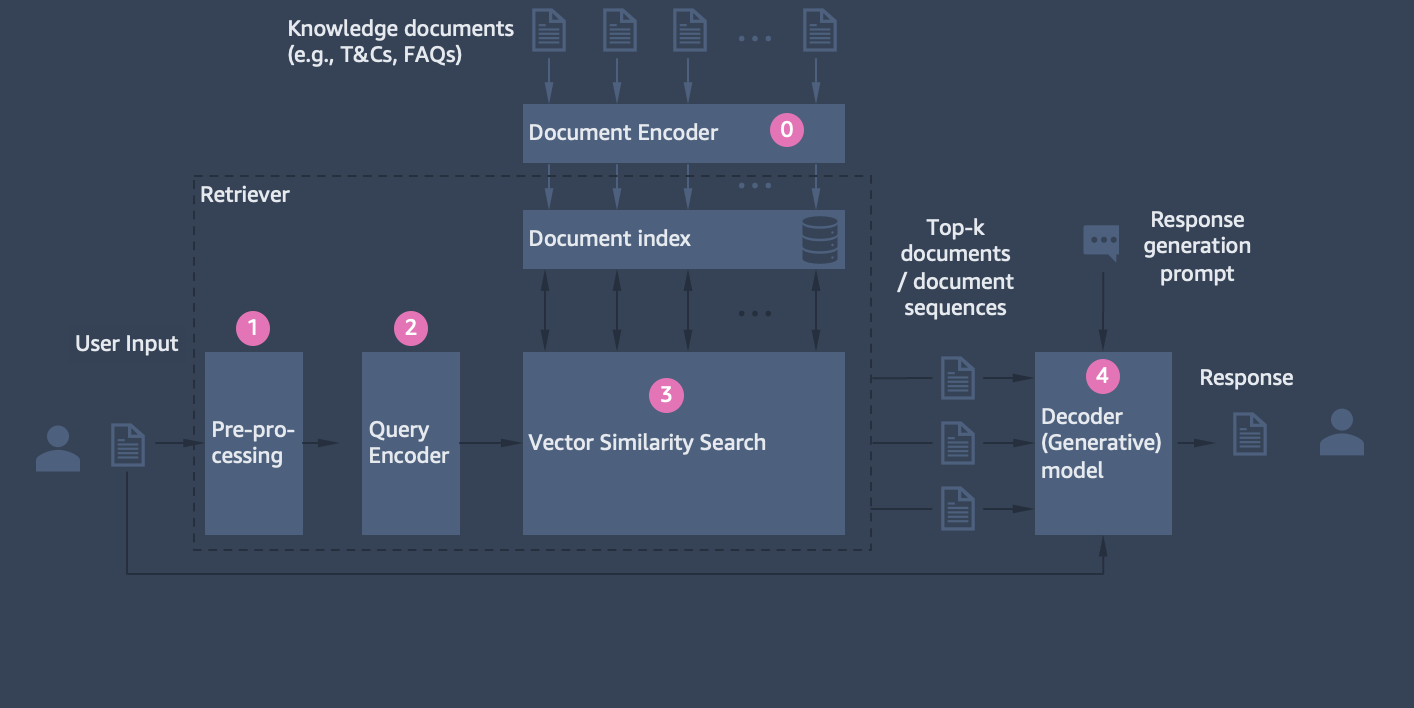\n",
"\n",
"The design pattern of retrieval-augmented generation is depicted in the above figure. It works as follows:\n",
"\n",
"- Step 0: Knowledge documents / document sequences are encoded and ingested into a vector database. \n",
"- Step 1: Customer e-mail query is pre-processed and/or tokenized\n",
"- Step 2: Tokenized input query is encoded\n",
"- Step 3: Encoded query is used to retrieve most similar text passages in document index using vector similarity search (e.g., Mixed Inner Product Search)\n",
"- Step 4: Top-k retrieved documents/text passages in combination with original customer e-mail query and e-mail generation prompt are fed into Generator model (Encoder-Decoder) to generate response e-mail\n",
"\n",
"### Architecture\n",
"\n",
"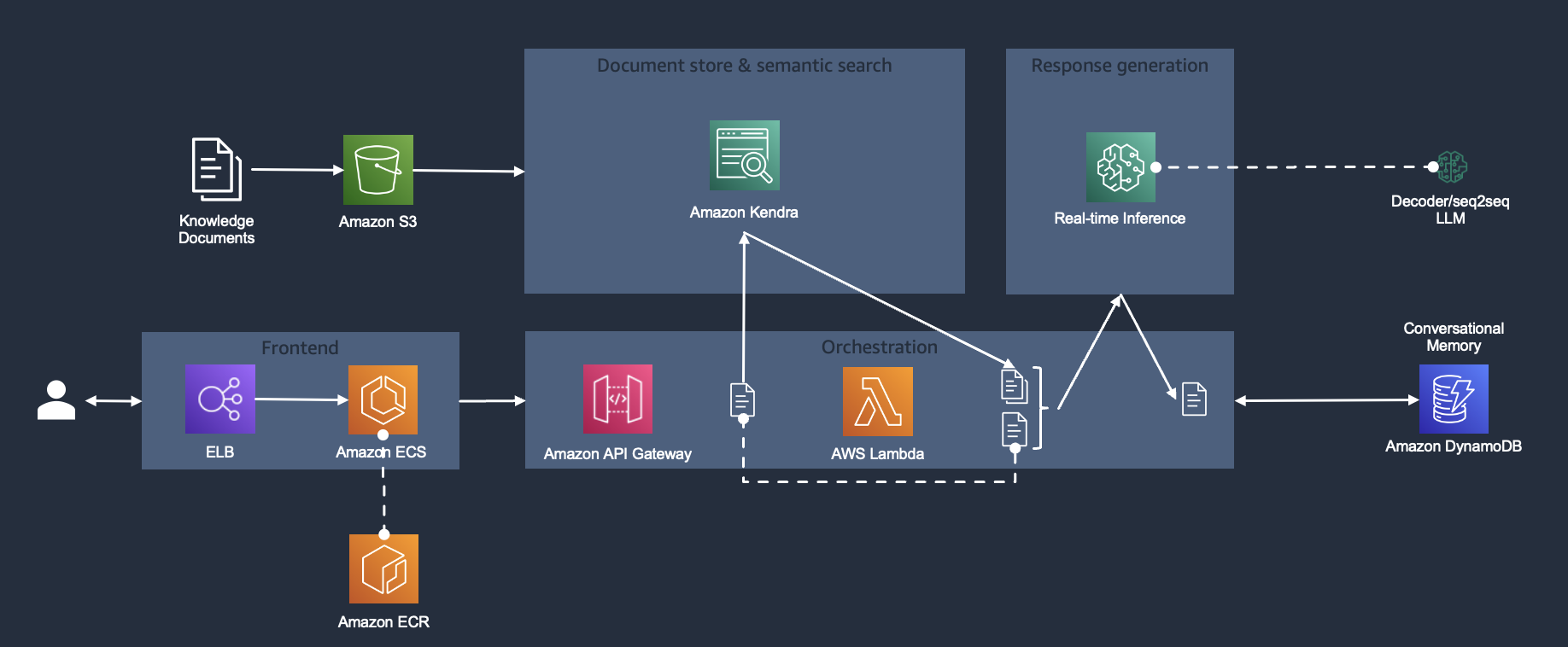\n",
"\n",
"Above figure shows the architecture for the LLM-powered chatbot with retrieval-augmented generation component we will be implementing in this lab. It consists of the following components:\n",
"- Document store & semantic search: We leverage semantic document search service Amazon Kendra as fully managed embeddings/vector store as well as for a fully managed solution for document retrieval based on questions/asks in natural language.\n",
"- Response generation: For the chatbot response generation, we use the open-source encoder-decoder model FLAN-T5-XXL conveniently deployed in a one-click fashion through Amazon SageMaker JumpStart right into your VPC.\n",
"- Orchestration layer: For hosting the orchestration layer implmented with the popular framework langchain we choose a serverless approach. The orchestration layer is exposed as RESTful API service via a Amazon API Gateway.\n",
"- Conversational Memory: In order to be able to keep track of different chatbot conversation turns while keeping the orchestration layer stateless we integrate the chatbot's memory with Amazon DynamoDB as a storage component.\n",
"- Frontend: The chatbot frontend is a web application hosted in a Docker container on Amazon ECS. For storing the container image we leverage Amazon ECR. The website is exposed through an Amazon Elastic Load Balancer. \n",
"\n",
"## Instructions\n",
"\n",
"### Prerequisites\n",
"\n",
"#### To run this workshop...\n",
"You need a computer with a web browser, preferably with the latest version of Chrome / FireFox.\n",
"Sequentially read and follow the instructions described in AWS Hosted Event and Work Environment Set Up\n",
"\n",
"#### Recommended background\n",
"It will be easier for you to run this workshop if you have:\n",
"\n",
"- Experience with Deep learning models\n",
"- Familiarity with Python or other similar programming languages\n",
"- Experience with Jupyter notebooks\n",
"- Beginners level knowledge and experience with SageMaker Hosting/Inference.\n",
"- Beginners level knowledge and experience with Large Language Models\n",
"\n",
"#### Target audience\n",
"Data Scientists, ML Engineering, ML Infrastructure, MLOps Engineers, Technical Leaders.\n",
"Intended for customers working with large Generative AI models including Language, Computer vision and Multi-modal use-cases.\n",
"Customers using EKS/EC2/ECS/On-prem for hosting or experience with SageMaker.\n",
"\n",
"Level of expertise - 400\n",
"\n",
"#### Time to complete\n",
"Approximately 1 hour."
]
},
{
"attachments": {},
"cell_type": "markdown",
"id": "037297f8",
"metadata": {},
"source": [
"# Switching the Notebook runtime to Python 3.10\n",
"\n",
"For this lab we need to run the notebook based on a Python 3.10 runtime. Therefor proceed as follows and select the \"PyTorch 2.0.0 Python 3.10 CPU Optimized\" option:\n",
"\n",
"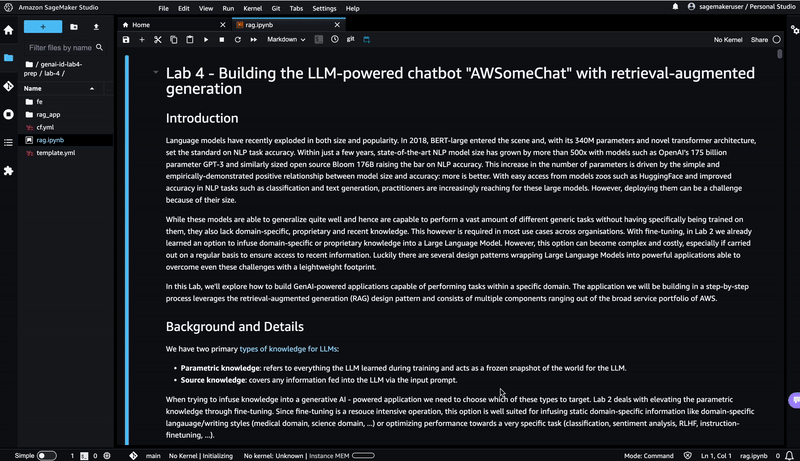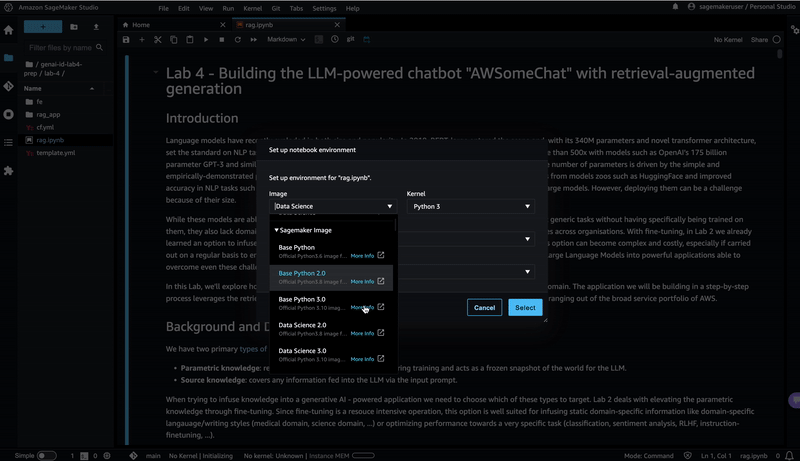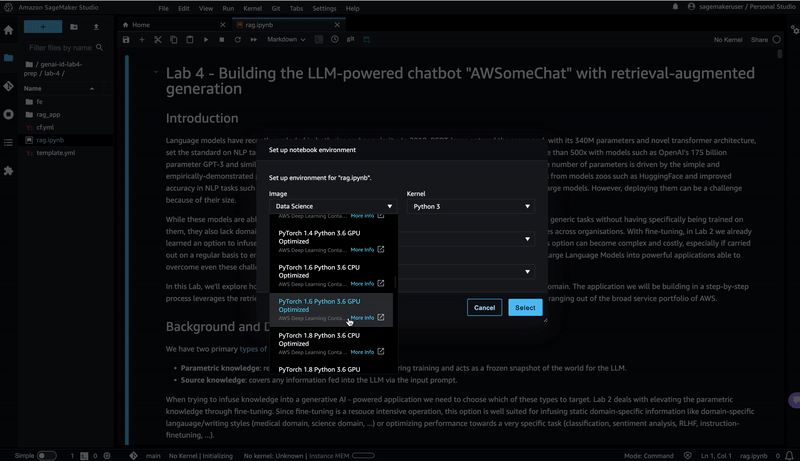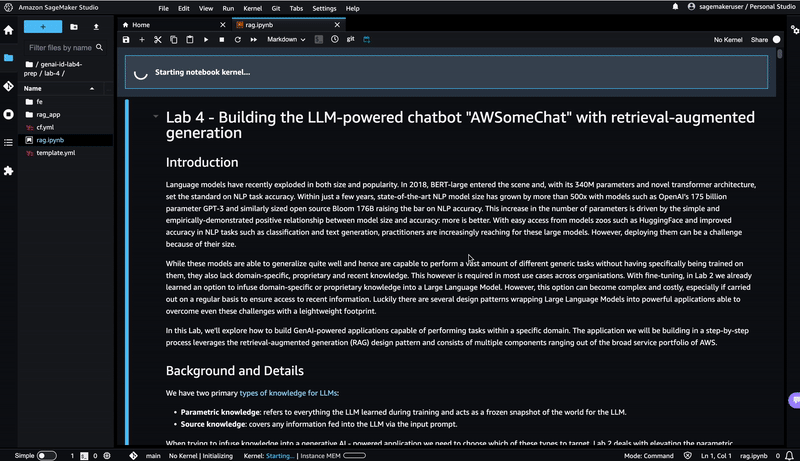\n"
]
},
{
"attachments": {},
"cell_type": "markdown",
"id": "1d33318d",
"metadata": {},
"source": [
"# Adjustment of Amazon SageMaker execution role policies\n",
"\n",
"In order to execute build Docker images and deploy infrastructure resources through AWS Serverless Application Model from SageMaker Studio , we need to adjust the SageMaker Execution Role. This is the IAM Role granting SageMaker Studio the permissions to perform actions against the AWS API. \n",
"\n",
"To adjust accordingly copy the following JSON:\n",
"\n",
"```json\n",
"{\n",
" \"Version\": \"2012-10-17\",\n",
" \"Statement\": [\n",
" {\n",
" \"Effect\": \"Allow\",\n",
" \"Action\": \"*\",\n",
" \"Resource\": \"*\"\n",
" },\n",
" {\n",
" \"Effect\": \"Allow\",\n",
" \"Action\": \"iam:PassRole\",\n",
" \"Resource\": \"arn:aws:iam::*:role/*\",\n",
" \"Condition\": {\n",
" \"StringLikeIfExists\": {\n",
" \"iam:PassedToService\": \"codebuild.amazonaws.com\"\n",
" }\n",
" }\n",
" }\n",
" ]\n",
"}\n",
"```\n",
"\n",
"We then change the Execution Role's permissions by adding the above JSON as inline policy as follows:\n",
"\n",
"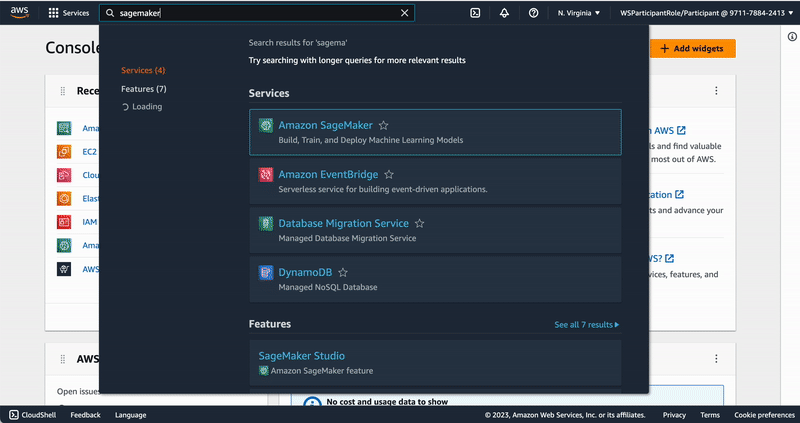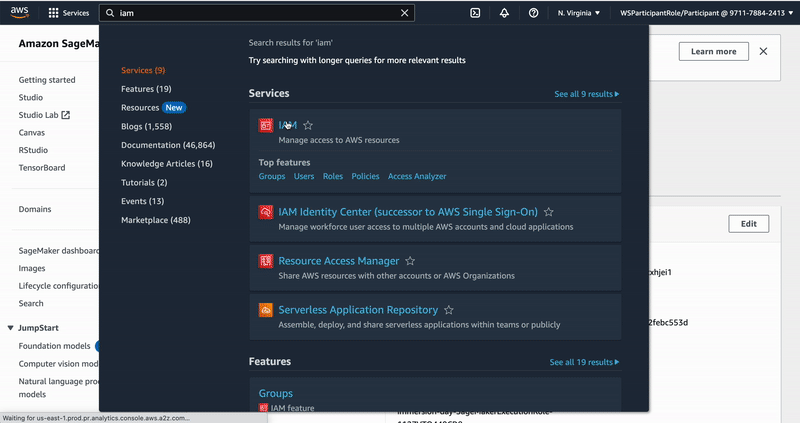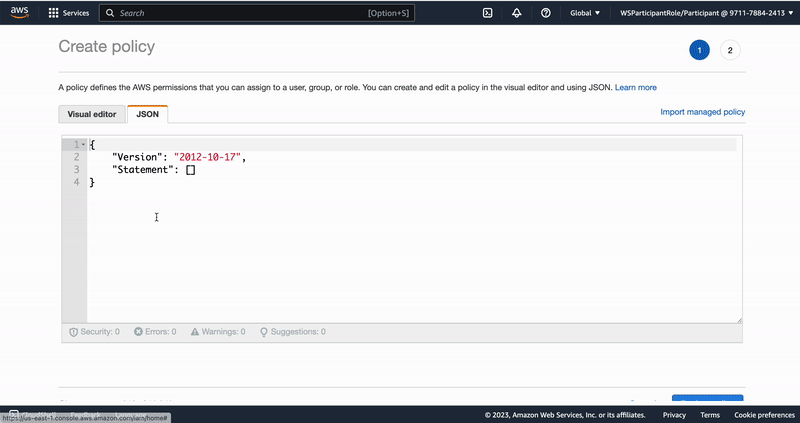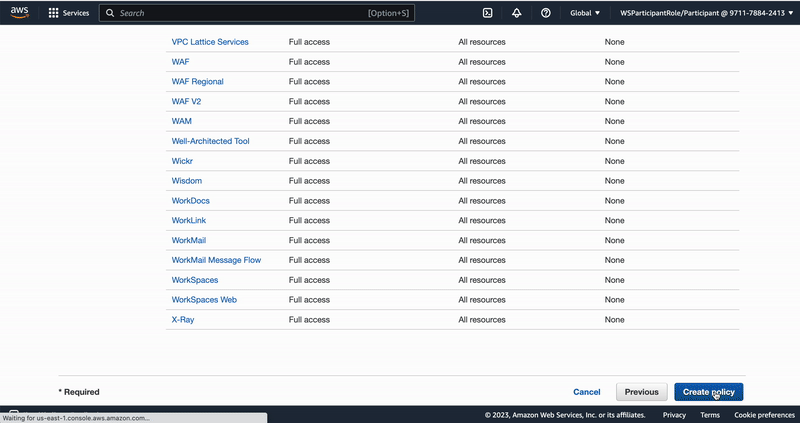\n",
"\n",
"\n",
"**CAUTION: The first statement of this policy provides very extensive permissions to this role. Outside of a lab environmentit is recommended to stick to the principle of least privilidges, requiring to restrict the permissions granted to individuals and roles the minimum required! Also, please execute DevOps related tasks like the above mentioned by leveraging our DevOps service portfolio (CodeBuild, CodeDeploy, CodePipeline, ...)!**"
]
},
{
"attachments": {},
"cell_type": "markdown",
"id": "a0dc305c",
"metadata": {},
"source": [
"# Adjustment of Amazon SageMaker execution role trust relationships\n",
"\n",
"To be able to build Docker images from SageMaker Studio we need to establish a trust relation ship between the service and the Amazon CodeBuild service (this is where the Docker build will be executed). Therefor we adjust the role's trust relationship accordingly by copying this JSON...\n",
"\n",
"```json\n",
"{\n",
" \"Version\": \"2012-10-17\",\n",
" \"Statement\": [\n",
" {\n",
" \"Effect\": \"Allow\",\n",
" \"Principal\": {\n",
" \"Service\": \"sagemaker.amazonaws.com\"\n",
" },\n",
" \"Action\": \"sts:AssumeRole\"\n",
" },\n",
" {\n",
" \"Effect\": \"Allow\",\n",
" \"Principal\": {\n",
" \"Service\": \"codebuild.amazonaws.com\"\n",
" },\n",
" \"Action\": \"sts:AssumeRole\"\n",
" }\n",
" ]\n",
"}\n",
"```\n",
"\n",
"...and subsequently performing the following steps:\n",
"\n",
"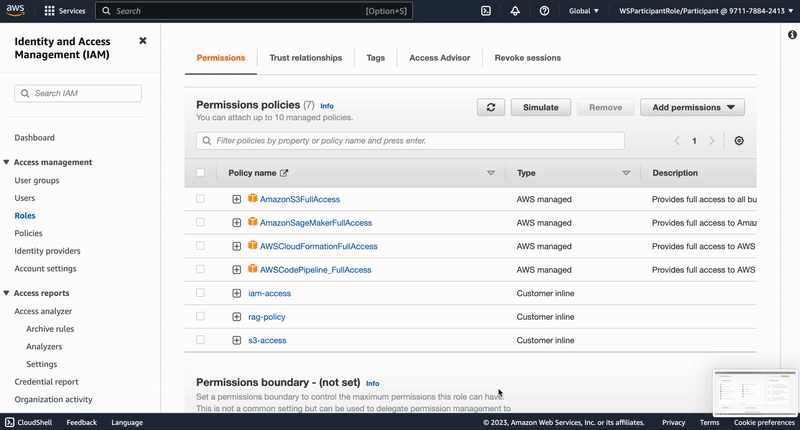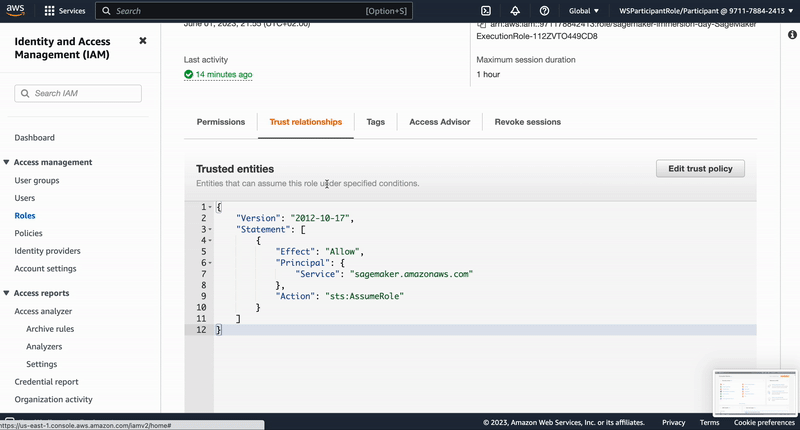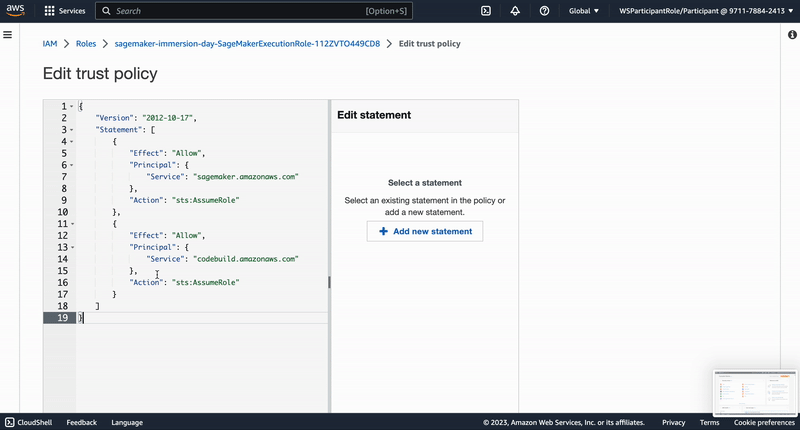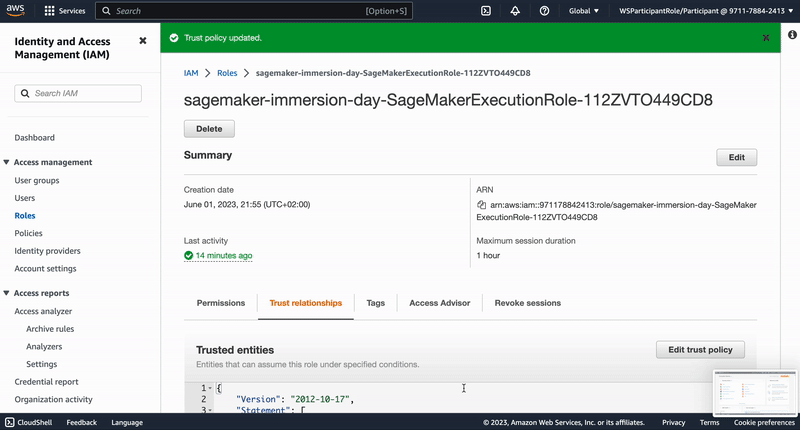\n",
"\n"
]
},
{
"attachments": {},
"cell_type": "markdown",
"id": "6c62b6bb",
"metadata": {},
"source": [
"# Installation and import of required dependencies, further setup tasks\n",
"\n",
"For this lab, we will use the following libraries:\n",
"\n",
" - sagemaker-studio-image-build, a CLI for building and pushing Docker images in SageMaker Studio using AWS CodeBuild and Amazon ECR.\n",
" - aws-sam-cli, an open-source CLI tool that helps you develop IaC-defined serverless applications into AWS.\n",
" - SageMaker SDK for interacting with Amazon SageMaker. We especially want to highlight the classes 'HuggingFaceModel' and 'HuggingFacePredictor', utilizing the built-in HuggingFace integration into SageMaker SDK. These classes are used to encapsulate functionality around the model and the deployed endpoint we will use. They inherit from the generic 'Model' and 'Predictor' classes of the native SageMaker SDK, however implementing some additional functionality specific to HuggingFace and the HuggingFace model hub.\n",
" - boto3, the AWS SDK for python\n",
" - os, a python library implementing miscellaneous operating system interfaces \n",
" - tarfile, a python library to read and write tar archive files\n",
" - io, native Python library, provides Python’s main facilities for dealing with various types of I/O.\n",
" - tqdm, a utility to easily show a smart progress meter for synchronous operations."
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "fa2eb936",
"metadata": {},
"outputs": [],
"source": [
"!pip install sagemaker==2.163.0 --upgrade"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "2f3686b1",
"metadata": {},
"outputs": [],
"source": [
"!pip install sagemaker-studio-image-build"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "1418ebd0-8d97-4acd-8443-ddf40604ae78",
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"%pip install -q sagemaker-studio-image-build aws-sam-cli"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "a8616f53",
"metadata": {},
"outputs": [],
"source": [
"import sagemaker\n",
"import boto3\n",
"import os\n",
"import tarfile\n",
"import requests\n",
"from io import BytesIO\n",
"from tqdm import tqdm\n"
]
},
{
"attachments": {},
"cell_type": "markdown",
"id": "4a59d15f",
"metadata": {},
"source": [
"# Setup of notebook environment\n",
"\n",
"Before we begin with the actual work, we need to setup the notebook environment respectively. This includes:\n",
"\n",
"- retrieval of the execution role our SageMaker Studio domain is associated with for later usage\n",
"- retrieval of our account_id for later usage\n",
"- retrieval of the chosen region for later usage"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "50c34e0d",
"metadata": {},
"outputs": [],
"source": [
"# Retrieve SM execution role\n",
"role = sagemaker.get_execution_role()"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "d281cb99",
"metadata": {},
"outputs": [],
"source": [
"# Create a new STS client\n",
"sts_client = boto3.client('sts')\n",
"\n",
"# Call the GetCallerIdentity operation to retrieve the account ID\n",
"response = sts_client.get_caller_identity()\n",
"account_id = response['Account']\n",
"account_id"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "0aae8da6",
"metadata": {},
"outputs": [],
"source": [
"# Retrieve region\n",
"region = boto3.Session().region_name\n",
"region"
]
},
{
"attachments": {},
"cell_type": "markdown",
"id": "2dbcfb82",
"metadata": {},
"source": [
"# Setup of S3 bucket for Amazon Kendra storage of knowledge documents\n",
"\n",
"Amazon Kendra provides multiple built-in adapters for integrating with data sources to build up a document index, e.g. S3, web-scraper, RDS, Box, Dropbox, ... . In this lab we will store the documents containing the knowledge to be infused into the application in S3. For this purpose, (if not already present) we create a dedicated S3 bucket."
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "db749bee",
"metadata": {},
"outputs": [],
"source": [
"# specifying bucket name for model artifact storage\n",
"prefix = 'gen-ai-immersion-day-kendra-storage'\n",
"model_bucket_name = f'{prefix}-{account_id}-{region}'\n",
"model_bucket_name"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "4e8af01c",
"metadata": {},
"outputs": [],
"source": [
"# Create S3 bucket\n",
"s3_client = boto3.client('s3', region_name=region)\n",
"location = {'LocationConstraint': region}\n",
"\n",
"bucket_name = model_bucket_name\n",
"\n",
"# Check if bucket already exists\n",
"bucket_exists = True\n",
"try:\n",
" s3_client.head_bucket(Bucket=bucket_name)\n",
"except:\n",
" bucket_exists = False\n",
"\n",
"# Create bucket if it does not exist\n",
"if not bucket_exists:\n",
" if region == 'us-east-1':\n",
" s3_client.create_bucket(Bucket=bucket_name)\n",
" else: \n",
" s3_client.create_bucket(Bucket=bucket_name,\n",
" CreateBucketConfiguration=location)\n",
" print(f\"Bucket '{bucket_name}' created successfully\")"
]
},
{
"attachments": {},
"cell_type": "markdown",
"id": "d6bd38df",
"metadata": {},
"source": [
"# Frontend\n",
"\n",
"All relevant components for building a dockerized frontend application can be found in the \"fe\" directory. It consists of the following files: \n",
"- ```app.py```: actual frontend utilizing the popular streamlit framework\n",
"- ```Dockerfile```: Dockerfile providing the blueprint for the creation of a Docker image\n",
"- ```requirements.txt```: specifying the dependencies required to be installed for hosting the frontend application\n",
"- ```setup.sh```: setup script consisting all the necessary steps to create a ECR repository, build the Docker image and push it to the respective repository we created\n",
"\n",
"## Streamlit \n",
"\n",
"[Streamlit](https://streamlit.io/) is an open-source Python library that makes it easy to create and share beautiful, custom web apps for machine learning and data science. In just a few minutes you can build and deploy powerful data apps. It is a very popular frontend development framework for rapid prototyping amongst the AI/ML space since easy to use webpages can be built in minutes without anything than Python skills.\n",
"\n",
"## UI\n",
"\n",
"The chatbot frontend web application \"AWSomeChat\" looks as follows:\n",
"\n",
"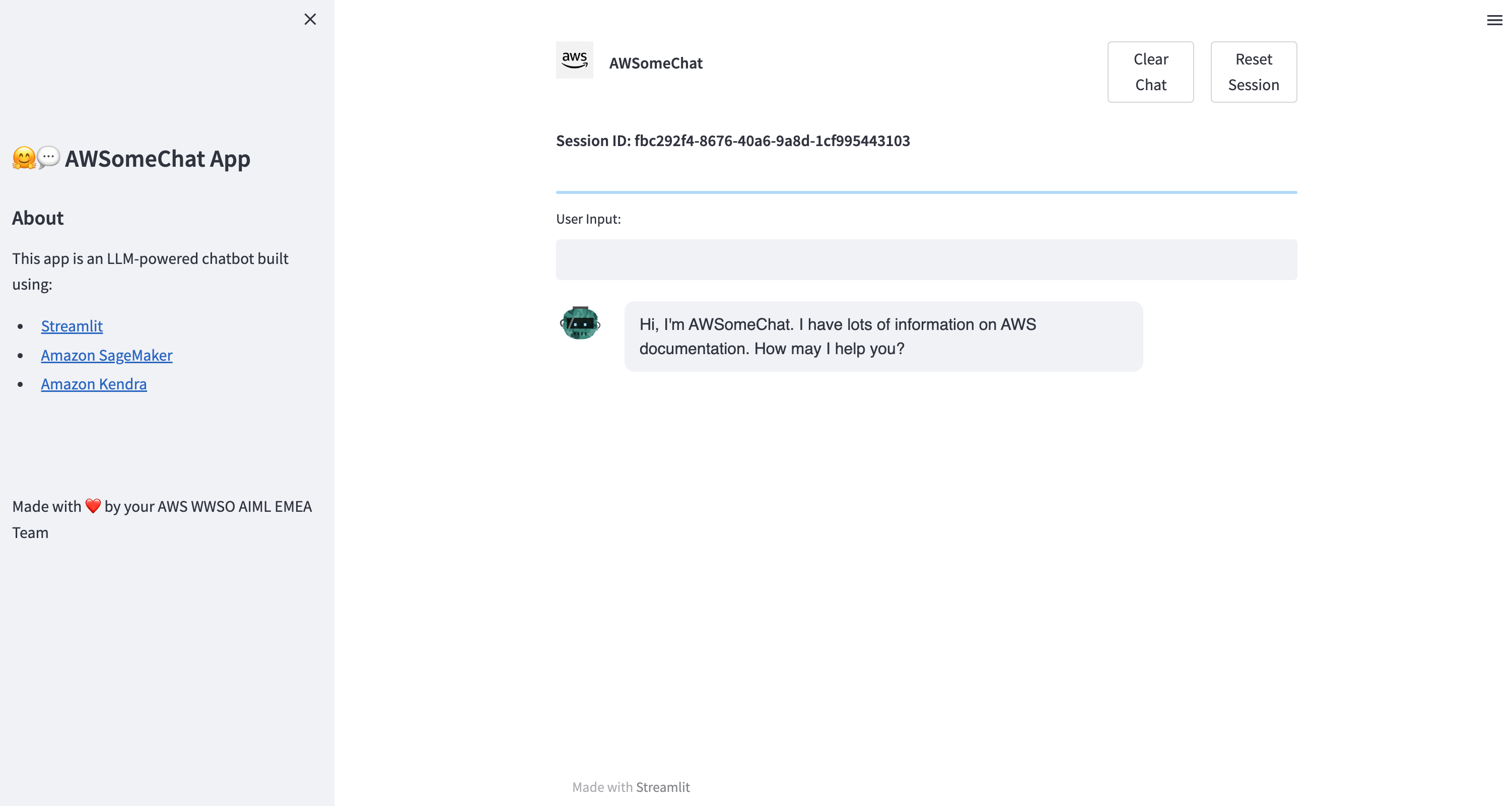\n",
"\n",
"To chat with the chatbot enter a message into the light grey input box and press ENTER. The chat conversation will appear below.\n",
"\n",
"On the top of the page you can spot the session id assigned to your chat conversation. This is used to map different conversation histories to a specific user since the chatbot backend is stateless. To start a new conversation, press the \"Clear Chat\" and \"Reset Session\" buttons on the top right of the page.\n",
"\n",
"\n",
"## Dockerization and hosting\n",
"\n",
"In order to prepare our frontend application to be hosted as a Docker container, we execute the bash script setup.sh. It looks as follows: \n",
"\n",
"```bash \n",
"#!/bin/bash\n",
"\n",
"# Get the AWS account ID\n",
"aws_account_id=$(aws sts get-caller-identity --query Account --output text)\n",
"aws_region=$(aws configure get region)\n",
"\n",
"echo \"AccountId = ${aws_account_id}\"\n",
"echo \"Region = ${aws_region}\"\n",
"\n",
"\n",
"# Create a new ECR repository\n",
"echo \"Creating ECR Repository...\"\n",
"aws ecr create-repository --repository-name rag-app\n",
"\n",
"# Get the login command for the new repository\n",
"echo \"Logging into the repository...\"\n",
"#$(aws ecr get-login --no-include-email)\n",
"aws ecr get-login-password --region ${aws_region} | docker login --username AWS --password-stdin ${aws_account_id}.dkr.ecr.${aws_region}.amazonaws.com\n",
"\n",
"# Build and push the Docker image and tag it\n",
"echo \"Building and pushing Docker image...\"\n",
"sm-docker build -t \"${aws_account_id}.dkr.ecr.us-east-1.amazonaws.com/rag-app:latest\" --repository rag-app:latest .\n",
"````\n",
"\n",
"The script performs the following steps in a sequential manner:\n",
"\n",
"1. Retrieval of the AWS account id and region\n",
"2. Create a new ECR repository with the name rag-app. Note: this operation will fail, if the repository already exists within your account. This is intended behaviour and can be ignored.\n",
"3. Login to the respective ECR repository. \n",
"4. Build the Docker image and tag it with the \"latest\" tag using the sagemaker-studio-image-build package we previously installed. The \"sm-docker build\" command will push the built image into the specified repository automatically. All compute will be carried out in AWS CodeBuild."
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "e7402e76-b8f1-4833-ba36-2dfd40e1e8ba",
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"!cd fe && bash setup.sh"
]
},
{
"attachments": {},
"cell_type": "markdown",
"id": "1c923145",
"metadata": {},
"source": [
"The frontend Docker image is now residing in the respective ECR repository and can be used for our deployment at a later point in time during the lab."
]
},
{
"attachments": {},
"cell_type": "markdown",
"id": "39ee162b-9247-47c2-8aed-207df3aa94b5",
"metadata": {},
"source": [
"# Document store and retriever component\n",
"\n",
"## Amazon Kendra\n",
"\n",
"[Amazon Kendra](https://docs.aws.amazon.com/kendra/latest/dg/what-is-kendra.html) is an intelligent search service that uses natural language processing and advanced machine learning algorithms to return specific answers to search questions from your data.\n",
"\n",
"Unlike traditional keyword-based search, Amazon Kendra uses its semantic and contextual understanding capabilities to decide whether a document is relevant to a search query. It returns specific answers to questions, giving users an experience that's close to interacting with a human expert.\n",
"\n",
"With Amazon Kendra, you can create a unified search experience by connecting multiple data repositories to an index and ingesting and crawling documents. You can use your document metadata to create a feature-rich and customized search experience for your users, helping them efficiently find the right answers to their queries.\n",
"\n",
"### Querying with Amazon Kendra\n",
"You can ask Amazon Kendra the following types of queries:\n",
"\n",
"Factoid questions — Simple who, what, when, or where questions, such as Where is the nearest service center to Seattle? Factoid questions have fact-based answers that can be returned as a single word or phrase. The answer is retrieved from a FAQ or from your indexed documents.\n",
"\n",
"Descriptive questions — Questions where the answer could be a sentence, passage, or an entire document. For example, How do I connect my Echo Plus to my network? Or, How do I get tax benefits for lower income families? \n",
"\n",
"Keyword and natural language questions — Questions that include complex, conversational content where the intended meaning may not be clear. For example, keynote address. When Amazon Kendra encounters a word like “address”—which has multiple contextual meanings—it correctly infers the intended meaning behind the search query and returns relevant information.\n",
"\n",
"## Benefits of Amazon Kendra\n",
"Amazon Kendra is highly scalable, capable of meeting performance demands, is tightly integrated with other AWS services such as Amazon S3 and Amazon Lex, and offers enterprise-grade security. Some of the benefits of using Amazon Kendra include:\n",
"\n",
"Simplicity — Amazon Kendra provides a console and API for managing the documents that you want to search. You can use a simple search API to integrate Amazon Kendra into your client applications, such as websites or mobile applications.\n",
"\n",
"Connectivity — Amazon Kendra can connect to third-party data repositories or data sources such as Microsoft SharePoint. You can easily index and search your documents using your data source.\n",
"\n",
"Accuracy — Unlike traditional search services that use keyword searches, Amazon Kendra attempts to understand the context of the question and returns the most relevant word, snippet, or document for your query. Amazon Kendra uses machine learning to improve search results over time.\n",
"\n",
"Security — Amazon Kendra delivers a highly secure enterprise search experience. Your search results reflect the security model of your organization and can be filtered based on the user or group access to documents. Customers are responsible for authenticating and authorizing user access.\n",
"\n",
"Incremental Learning - Amazon Kendra uses incremental learning to improve search results. Using feedback from queries, incremental learning improves the ranking algorithms and optimizes search results for greater accuracy.\n",
"\n",
"For example, suppose that your users search for the phrase \"health care benefits.\" If users consistently choose the second result from the list, over time Amazon Kendra boosts that result to the first place result. The boost decreases over time, so if users stop selecting a result, Amazon Kendra eventually removes it and shows another more popular result instead. This helps Amazon Kendra prioritize results based on relevance, age, and content.\n",
"\n",
"## Creation of a Kendra index\n",
"To use Kendra for retrieval-augmented generation we need to first create a Kendra index. This index will hold all the knowledge we want to infuse into our LLM-powered chatbot application. To create a Kendra index follow the following steps:\n",
"\n",
"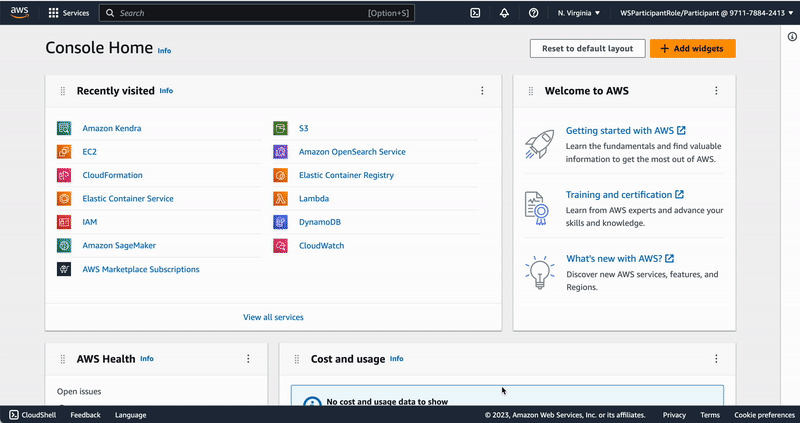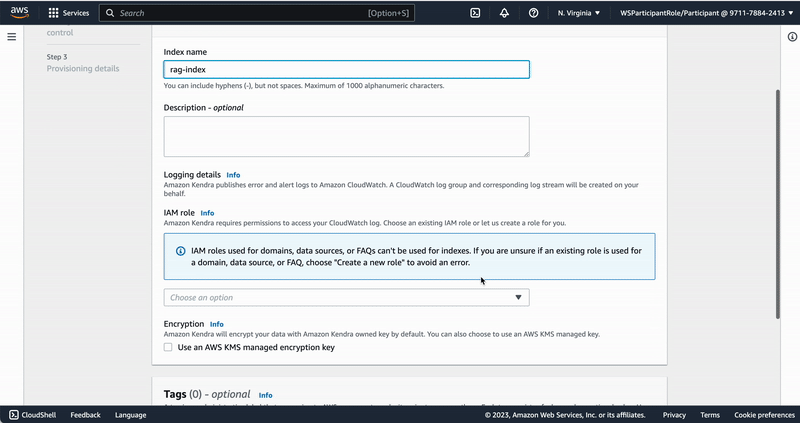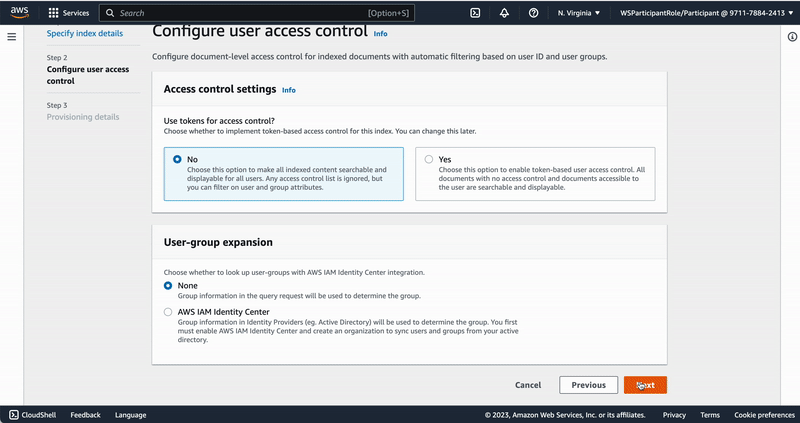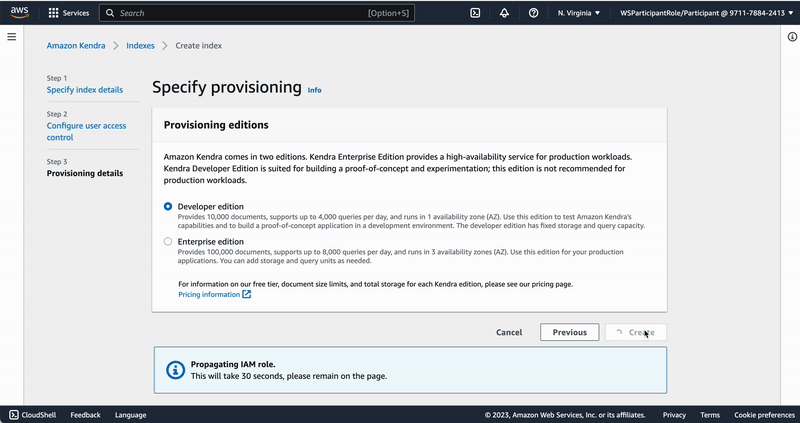\n",
"\n",
"## Using Kendra with LLMs \n",
"Now that we have a understanding of the basics of Kendra, we want to use it for the indexing of our documents. Kendra Indexing allows us to query our enterprise knowledge base, without us having to worry about how to handle different data types (pdf, xml) in S3, connectors to SaaS applications as well as webpages. \n",
"\n",
"We will use Kendra as outlined in the following architecture diagram:\n",
"
\n",
" \n",
"
\n",
"\n",
"\n",
"We use an Amazon Kendra index to ingest enterprise unstructured data from data sources such as wiki pages, MS SharePoint sites, Atlassian Confluence, and document repositories such as Amazon S3. When a user interacts with the GenAI app, the flow is as follows:\n",
"\n",
"1. The user makes a request to the GenAI app.\n",
"2. The app issues a search query to the Amazon Kendra index based on the user request.\n",
"3. The index returns search results with excerpts of relevant documents from the ingested enterprise data.\n",
"4. The app sends the user request and along with the data retrieved from the index as context in the LLM prompt.\n",
"5. The LLM returns a succinct response to the user request based on the retrieved data.\n",
"6. The response from the LLM is sent back to the user.\n",
"\n",
"With this architecture, you can choose the most suitable LLM for your use case. LLM options include our partners Hugging Face, AI21 Labs, Cohere, and others hosted on an Amazon SageMaker endpoint, as well as models by companies like Anthropic and OpenAI. With Amazon Bedrock, you will be able to choose Amazon Titan, Amazon’s own LLM, or partner LLMs such as those from AI21 Labs and Anthropic with APIs securely without the need for your data to leave the AWS ecosystem. The additional benefits that Amazon Bedrock will offer include a serverless architecture, a single API to call the supported LLMs, and a managed service to streamline the developer workflow.\n",
"\n",
"In our implementation we will be leveraging SageMaker Foundation Models based on FlanT5.\n",
"\n",
"## Uploading knowledge documents into an Amazon Kendra index\n",
"\n",
"Next we are going to add some more documents from S3 to show how easy it is to integrate different data sources to a Kendra Index. \n",
"First we are going to download some interesting pdf files from the internet, but please feel free to drop any pdf you might find interesting in it as well. "
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "6ebc4508",
"metadata": {},
"outputs": [],
"source": [
"import os\n",
"import boto3\n",
"import requests\n",
"from io import BytesIO\n",
"from tqdm import tqdm\n",
"\n",
"# Create an S3 client\n",
"s3 = boto3.client('s3')\n",
"\n",
"# Create a bucket if it doesn't exist\n",
"bucket_name = f'immersion-day-bucket-{account_id}-{region}'\n",
"if s3.list_buckets()['Buckets']:\n",
" for bucket in s3.list_buckets()['Buckets']:\n",
" if bucket['Name'] == bucket_name:\n",
" break\n",
" else:\n",
" s3.create_bucket(Bucket=bucket_name)\n",
"else:\n",
" s3.create_bucket(Bucket=bucket_name)\n",
"\n",
"# List of URLs to download PDFs from\n",
"pdf_urls = [\n",
" \"https://patentimages.storage.googleapis.com/bb/0f/5a/6ef847538a6ab5/US10606565.pdf\",\n",
" \"https://patentimages.storage.googleapis.com/f7/50/e4/81af7ddcbb2773/US9183397.pdf\",\n",
" \"https://docs.aws.amazon.com/pdfs/enclaves/latest/user/enclaves-user.pdf\",\n",
" \"https://docs.aws.amazon.com/pdfs/ec2-instance-connect/latest/APIReference/ec2-instance-connect-api.pdf\",\n",
"]\n",
"\n",
"# Download PDFs from the URLs and upload them to the S3 bucket\n",
"for url in tqdm(pdf_urls):\n",
" response = requests.get(url, stream=True)\n",
" filename = os.path.basename(url)\n",
" print(f\"Working on {filename}\")\n",
" fileobj = BytesIO()\n",
" total_size = int(response.headers.get('content-length', 0))\n",
" block_size = 1024\n",
" progress_bar = tqdm(total=total_size, unit='iB', unit_scale=True)\n",
" for data in response.iter_content(block_size):\n",
" progress_bar.update(len(data))\n",
" fileobj.write(data)\n",
" progress_bar.close()\n",
" fileobj.seek(0)\n",
" s3.upload_fileobj(fileobj, bucket_name, filename)"
]
},
{
"attachments": {},
"cell_type": "markdown",
"id": "aaae375d",
"metadata": {},
"source": [
"Lets use those documents in Kendra. First navigate to the Kendra console. \n",
"\n",
"Under \"Data Management\" you will find the tab \"Data Sources\". Navigate there and add a new data source via \"Add data source\". \n",
"Take some time to inspect all the different connectors that are there for you to use out of the box. We will use s3 as our source. \n",
"\n",
"It is worth noting that Kendra respect enterprise level access attributes. That means, that it can deny queries if a user is not authorized to retrieve a document. \n",
"\n",
"You can either add the sample bucket as a data source that has been provided on the top of the connectors, but for the sake of demonstration, we will add our downloaded pdfs as well. \n",
"\n",
"The animation below shows how to add an s3 data source to kendra to index. We are creating a new IAM role as well as setting the indexing frequncy to \"on-demand\". \n",
"\n",
"
\n",
" \n",
"
\n",
"\n",
"\n",
"After the connection has been established, you can sync your data source by clicking \"sync now\". \n",
"\n",
"It is worth noting, that the maximum file size by default in the Developer Edition of Kendra is 5Mb. \n",
"\n",
"For an improved generative AI experience, we recommend requesting a larger document excerpt to be returned. Which is not possilbe in the AWS provided workshop accounts. Otherwise, navigate in the browser window you are using for AWS Management Console navigate to [Service Quota](https://console.aws.amazon.com/servicequotas/home/services/kendra/quotas/L-196E775D) and choose Request quota increase, and change quota value to a number up to a max of 750."
]
},
{
"attachments": {},
"cell_type": "markdown",
"id": "d071c5b6",
"metadata": {},
"source": [
"# Model - Option 1: FLAN-T5-XXL via SageMaker JumpStart\n",
"\n",
"Note: Please choose only one out of Option 1, Option 2.\n",
"\n",
"For the response generation step we need a generative Model to come up with a appealing chatbot-like answer taking into account the users ask and the relevant documents retrieved from the Kendra index. For this purpose usually (instruction-fine-tuned) decoder or encoder-decoder models are used. In this lab we will be using FLAN-T5-XXL.\n",
"\n",
"## SageMaker JumpStart\n",
"\n",
"Welcome to Amazon [SageMaker JumpStart](https://docs.aws.amazon.com/sagemaker/latest/dg/studio-jumpstart.html)! You can use JumpStart to deploy many Machine Learning models in a one-click fashion. SageMaker JumpStart can be accessed through SageMaker Studio, or through [SageMaker JumpStart API](https://sagemaker.readthedocs.io/en/stable/overview.html#use-prebuilt-models-with-sagemaker-jumpstart). Further, AWS recently released SageMaker JumpStart [Foundation Model hub](https://us-east-1.console.aws.amazon.com/sagemaker/home?region=us-east-1#/foundation-models), providing marketplace-like access to both proprietary and open-source foundation models.\n",
"\n",
"SageMaker JumpStart provides one-click deployment capabilities as well as one-click deployment notebook generation for more advanced use cases. On top of this, one-click fine-tuning capabilities are constantly added to more and more models on SageMaker JumpStart. All of this happens right in your AWS account with VPC isolation capabilities if required.\n",
"\n",
"In this lab we will be using SageMaker JumpStart through SageMaker Studio to one-click deploy FLAN-T5-XXL.\n",
"\n",
"## FLAN-T5-XXL\n",
"\n",
"The FLAN-T5 model family was released in the paper [Scaling Instruction-Finetuned Language Models](https://arxiv.org/pdf/2210.11416.pdf) - it is an enhanced version of T5 that has been finetuned in a mixture of tasks. Models originating out of this model family come in different flavours, [FLAN-T5-XXL](https://huggingface.co/google/flan-t5-xxl) being the largest one amongst them. It is a encoder-decoder model with 11B parameters, achieving strong few-shot performance even compared to much larger models. While it has been fine-tuned on a huge variety of different datasets and tasks, dataset containing natural instructions being one of them turns it into an instruction-fine-tuned model. Therefor it is particularily well suited for retrieval-augmented generation use cases. \n",
"\n",
"## Deploy FLAN-T5-XXL via SageMaker JumpStart\n",
"\n",
"The FLAN-T5-XXL model can be deployed via SageMaker JumpStart as shown below. Please stick to a \"ml.g4dn.12xlarge\" instance for the deployment (if no different instructions provided by the instructor). \n",
"\n",
"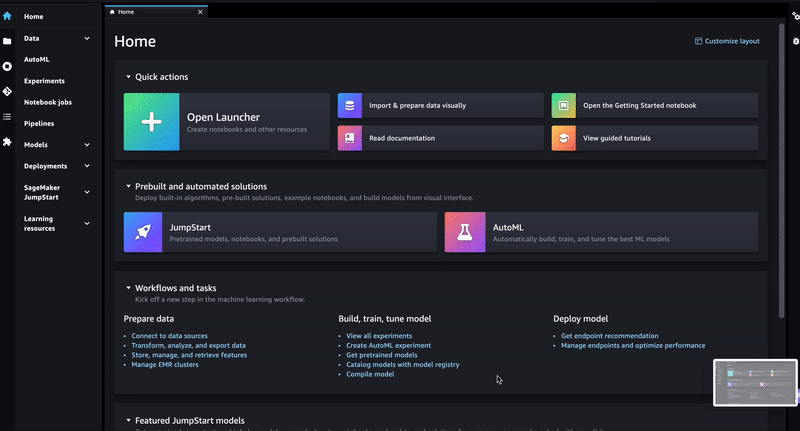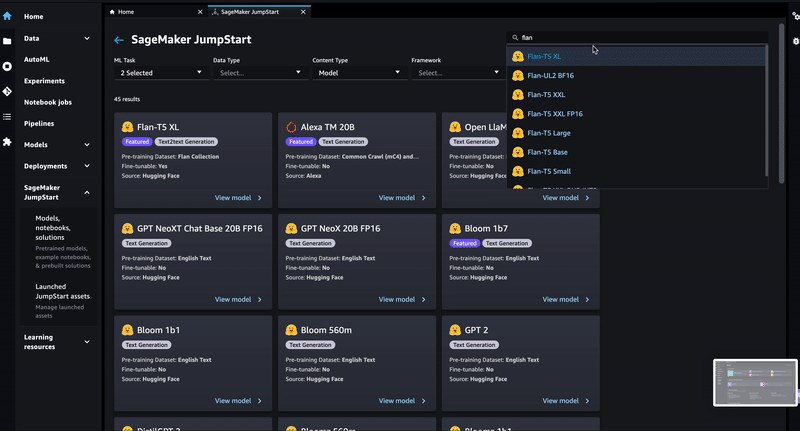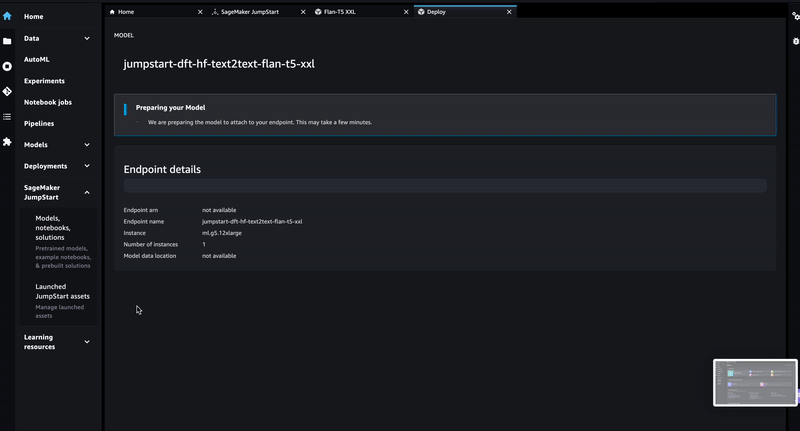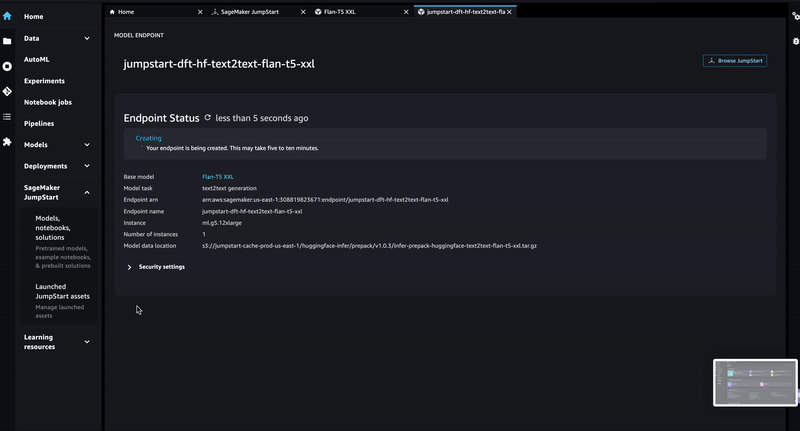\n",
"\n",
"The deployment might take a while. Feel free to move on with the following steps. Don't forget to check the model deployment progress from time to time.\n",
"\n",
"Furthermore, it is worth noting, that Kendra in its default values in the workshop accounts is set to 300 characters displayed in the Document Excerpt of a Document type result "
]
},
{
"attachments": {},
"cell_type": "markdown",
"id": "7493bad7",
"metadata": {},
"source": [
"# Model - Option 2: Falcon40b-instruct via SageMaker Real-time Endpoint with HuggingFace LLM Deep Learning Container\n",
"\n",
"Note: Please choose only one out of Option 1, Option 2. In case you have already gone through Lab 1 - Option 2 and your Falcon40b-instruct endpoint is still working, you can skip the below deployment. \n",
"\n",
"For the response generation step we need a generative Model to come up with a appealing chatbot-like answer taking into account the users ask and the relevant documents retrieved from the Kendra index. For this purpose usually (instruction-fine-tuned) decoder or encoder-decoder models are used. In this lab we will be using the Falcon40b-instruct model.\n",
"\n",
"## HuggingFace LLM Deep Learning Container\n",
"\n",
"[Hugging Face LLM DLC](https://huggingface.co/blog/sagemaker-huggingface-llm) is a new purpose-built Inference Container to easily deploy LLMs in a secure and managed environment. The DLC is powered by Text Generation Inference (TGI), an open-source, purpose-built solution for deploying and serving Large Language Models (LLMs). TGI enables high-performance text generation using Tensor Parallelism and dynamic batching for the most popular open-source LLMs, including StarCoder, BLOOM, GPT-NeoX, Llama, and T5. Text Generation Inference is already used by customers such as IBM, Grammarly, and the Open-Assistant initiative implements optimization for all supported model architectures, including:\n",
"\n",
"- Tensor Parallelism and custom cuda kernels\n",
"- Optimized transformers code for inference using flash-attention on the most popular architectures\n",
"- Quantization with bitsandbytes\n",
"- Continuous batching of incoming requests for increased total throughput\n",
"- Accelerated weight loading (start-up time) with safetensors\n",
"- Logits warpers (temperature scaling, topk, repetition penalty ...)\n",
"- Watermarking with A Watermark for Large Language Models\n",
"- Stop sequences, Log probabilities\n",
"- Token streaming using Server-Sent Events (SSE)\n",
"\n",
"Officially supported model architectures are currently:\n",
"\n",
"- BLOOM / BLOOMZ\n",
"- MT0-XXL\n",
"- Galactica\n",
"- SantaCoder\n",
"- GPT-Neox 20B (joi, pythia, lotus, rosey, chip, RedPajama, open assistant)\n",
"- FLAN-T5-XXL (T5-11B)\n",
"- Llama (vicuna, alpaca, koala)\n",
"- Starcoder / SantaCoder\n",
"- Falcon 7B / Falcon 40B\n",
"\n",
"With the new Hugging Face LLM Inference DLCs on Amazon SageMaker, AWS customers can benefit from (...) technologies that power highly concurrent, low latency LLM experiences (...).”\n",
"\n",
"In this lab we will be using the HuggingFace LLM Deep Learning Container for Amazon SageMaker to deploy Falcon40b-instruct.\n",
"\n",
"## Falcon40b-instruct \n",
"\n",
"The Falcon models were built by the [Technology Innovation Institute](https://www.tii.ae/). They come in two sizes and two flavours: 7B and 40B and raw pre-trained vs instruction-finetuned. The 40B version is and autoregressive decoder-only model trained on 1 trillion tokens and was trained on 384 GPUs on AWS over the course of two months.\n",
"\n",
"These models are grabbing attention for two main reasons. Firstly, the sizeable instruction-fine-tuned model, known as Falcon-40B-Instruct, currently holds the top spot on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard). Secondly, they come with a permissive license, the Apache-2.0, which allows for commercial use.\n",
"\n",
"## Deploy Falcon40b-instruct on Amazon SageMaker\n",
"\n",
"The Falcon40b-instruct model can be deployed to SageMaker using the HuggingFace LLM DLC as shown below. Please stick to a \"ml.g5.12xlarge\" instance for the deployment (if no different instructions provided by the instructor). Detailed instructions regarding deployment can be found in [this](https://www.philschmid.de/sagemaker-falcon-llm) and [this](https://medium.com/mlearning-ai/unlocking-the-future-of-chatbots-with-falcon-hugging-face-and-amazon-sagemaker-cf6bd8aeba54) blogpost. However, for the purpose of this lab it is sufficient to simply run the below code cells."
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "f45f98e0",
"metadata": {},
"outputs": [],
"source": [
"from sagemaker.huggingface import get_huggingface_llm_image_uri\n",
"\n",
"# retrieve the llm image uri\n",
"llm_image = get_huggingface_llm_image_uri(\n",
" \"huggingface\",\n",
" version=\"0.8.2\"\n",
")\n",
"\n",
"# print ecr image uri\n",
"print(f\"llm image uri: {llm_image}\")"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "c86b410f",
"metadata": {},
"outputs": [],
"source": [
"import json\n",
"from sagemaker.huggingface import HuggingFaceModel\n",
"\n",
"# sagemaker config\n",
"instance_type = \"ml.g5.12xlarge\"\n",
"number_of_gpu = 4\n",
"health_check_timeout = 300\n",
"\n",
"# TGI config\n",
"config = {\n",
" 'HF_MODEL_ID': \"tiiuae/falcon-40b-instruct\", # model_id from hf.co/models\n",
" 'SM_NUM_GPUS': json.dumps(number_of_gpu), # Number of GPU used per replica\n",
" 'MAX_INPUT_LENGTH': json.dumps(1024), # Max length of input text\n",
" 'MAX_TOTAL_TOKENS': json.dumps(2048), # Max length of the generation (including input text)\n",
" # 'HF_MODEL_QUANTIZE': \"bitsandbytes\", # comment in to quantize\n",
"}\n",
"\n",
"# create HuggingFaceModel\n",
"llm_model = HuggingFaceModel(\n",
" role=role,\n",
" image_uri=llm_image,\n",
" env=config\n",
")"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "eebc2db9",
"metadata": {},
"outputs": [],
"source": [
"# Deploy model to an endpoint\n",
"# https://sagemaker.readthedocs.io/en/stable/api/inference/model.html#sagemaker.model.Model.deploy\n",
"llm = llm_model.deploy(\n",
" initial_instance_count=1,\n",
" instance_type=instance_type,\n",
" container_startup_health_check_timeout=health_check_timeout, # 10 minutes to be able to load the model\n",
" )"
]
},
{
"attachments": {},
"cell_type": "markdown",
"id": "1b3ac885-d5aa-4c23-8b82-cd3acb79fbcb",
"metadata": {},
"source": [
"# Orchestration layer\n",
"\n",
"We encapsulate the execution of the single steps involved in the retrieval-augmented generation design pattern into an orchestration layer. For a convenient developer experience we utilize the popular framework langchain for this.\n",
"\n",
"## Langchain\n",
"\n",
"[LangChain](https://python.langchain.com/en/latest/) is a framework for developing applications powered by language models. We believe that the most powerful and differentiated applications will not only call out to a language model via an api, but will also:\n",
"\n",
"- Be data-aware: connect a language model to other sources of data\n",
"- Be agentic: Allow a language model to interact with its environment\n",
"\n",
"As such, the LangChain framework is designed with the objective in mind to enable those types of applications.\n",
"\n",
"There are two main value props the LangChain framework provides:\n",
"\n",
"- Components: LangChain provides modular abstractions for the components neccessary to work with language models. LangChain also has collections of implementations for all these abstractions. The components are designed to be easy to use, regardless of whether you are using the rest of the LangChain framework or not.\n",
"- Use-Case Specific Chains: Chains can be thought of as assembling these components in particular ways in order to best accomplish a particular use case. These are intended to be a higher level interface through which people can easily get started with a specific use case. These chains are also designed to be customizable.\n",
"Accordingly, we split the following documentation into those two value props. In this documentation, we go over components and use cases at high level and in a language-agnostic way. For language-specific ways of using these components and tackling these use cases, please see the language-specific sections linked at the top of the page.\n",
"\n",
"### KendraIndexRetriever\n",
"\n",
"Indexes refer to ways to structure documents so that LLMs can best interact with them. The most common way that indexes are used in chains is in a \"retrieval\" step. This step refers to taking a user's query and returning the most relevant documents. We draw this distinction because (1) an index can be used for other things besides retrieval, and (2) retrieval can use other logic besides an index to find relevant documents. We therefor have a concept of a \"Retriever\" interface - this is the interface that most chains work with.\n",
"\n",
"Most of the time when we talk about indexes and retrieval we are talking about indexing and retrieving unstructured data (like text documents). For interacting with structured data (SQL tables, etc) or APIs there is other design patterns we will not cover in this lab. The primary index and retrieval types supported by LangChain are currently centered around vector databases and document retrieval systems, Kendra being one of them.\n",
"\n",
"### ConversationalBufferWindowMemory \n",
"Memory is the concept of storing and retrieving data in the process of a conversation. There are two main methods:\n",
"\n",
"- Based on input, fetch any relevant pieces of data\n",
"- Based on the input and output, update state accordingly\n",
"\n",
"There are two main types of memory: short term and long term.\n",
"\n",
"Short term memory generally refers to how to pass data in the context of a singular conversation (generally is previous ChatMessages or summaries of them), while long term memory deals with how to fetch and update information between conversations. In this lab we will focus on short term memory in the form of the ```ConversationalBufferWindowMemory```. \n",
"\n",
"```ConversationBufferWindowMemory``` keeps a list of the interactions of the conversation over time. It only uses the last K interactions. This can be useful for keeping a sliding window of the most recent interactions, so the buffer does not get too large. \n",
"\n",
"### DynamoDBChatMessageHistory\n",
"\n",
"In their plain form, langchain's memory classes store the conversation in-memory. However this approach is not working when hosting the orchestration layer as a stateless microservice. To overcome this langchain offers ChatMessageHistory classes as memory plugins, interfacing to durable storage backends. The ```DynamoDBChatMessageHistory``` class leverages Amazon DynamoDB to store the chat message history in a durable manner. It supports session management by leveraging a session_id parameter matching the partition key in the DynamoDB schema.\n",
"\n",
"### SageMakerEndpoint\n",
"\n",
"For encapsulating funcionality around LLM inference, langchain provides the LLM class specifically designed for interfacing with LLMs. There are lots of LLM providers on the market, as well as a huge variety of hosting. This class is designed to provide a standard interface for all of them.\n",
"\n",
"Amazon SageMaker is a system that can build, train, and deploy machine learning (ML) models for any use case with fully managed infrastructure, tools, and workflows. Inheriting from the generic LLM class, the ```SageMakerEndpoint```class provides functionality specifically tied to LLMs hosted via SageMaker Endpoints through a standard interface. Thereby it uses the endpoint name as unique identifier for the targeted endpoint.\n",
"\n",
"### PromptTemplate\n",
"\n",
"The new way of programming models is through prompts. A \"prompt\" refers to the input to the model. This input is rarely hard coded, but rather is often constructed from multiple components. A PromptTemplate is responsible for the construction of this input. LangChain provides several classes and functions to make constructing and working with prompts easy, ```PromptTemplate``` being one of them.\n",
"\n",
"A PromptValue is what is eventually passed to the model. Most of the time, this value is not hardcoded but is rather dynamically created based on a combination of user input, other non-static information (often coming from multiple sources), and a fixed template string. We call the object responsible for creating the PromptValue a ```PromptTemplate```. This object exposes a method for taking in input variables and returning a PromptValue.\n",
"\n",
"### ConversationalRetrievalChain\n",
"\n",
"Chains is an incredibly generic concept which returns to a sequence of modular components (or other chains) combined in a particular way to accomplish a common use case.\n",
"\n",
"The ```ConversationalRetrievalChain``` is a special purpose chain designed for chatbot implementations infusing knowledge via retrieval-augmented generation. \n",
"This chain has two steps. First, it condenses the current question and the chat history into a standalone question. This is neccessary to create a standanlone ask to use for retrieval. After that, it does retrieval and then answers the question using retrieval-augmented generation with a separate model. Part of the power of the declarative nature of LangChain is that you can easily use a separate language model for each call. This can be useful to use a cheaper and faster model for the simpler task of condensing the question, and then a more expensive model for answering the question. However, within this lab we will be using one model for both steps.\n",
"\n",
"## Create Lambda function codebase \n",
"\n",
"We will now look into the orchestrator implementation, meant to be hosted through AWS Lambda with a Python runtime. You can find the source code in the ```rag_app```directory. It consists of the following components:\n",
"- ```kendra```directory: implementation of the Kendra retriever. This can be used as is and does not require further attention.\n",
"- ```rag_app.py```: implementation of the orchestration layer as AWS Lambda handler function.\n",
"- ```requirements.txt```: specifying the dependencies required to be installed for hosting the frontend application.\n",
"\n",
"Let's dive a bit deeper into the code of the AWS Lambda handler function ```rag_app.py```. First, we import the required libraries: \n",
"\n",
"\n",
"```python\n",
"import json\n",
"import os\n",
"from langchain.chains import ConversationalRetrievalChain\n",
"from langchain import SagemakerEndpoint\n",
"from langchain.prompts.prompt import PromptTemplate\n",
"from langchain.embeddings import SagemakerEndpointEmbeddings\n",
"from langchain.embeddings.sagemaker_endpoint import EmbeddingsContentHandler\n",
"from langchain.llms.sagemaker_endpoint import ContentHandlerBase, LLMContentHandler\n",
"from langchain.memory import ConversationBufferWindowMemory\n",
"from langchain import PromptTemplate, LLMChain\n",
"from langchain.memory.chat_message_histories import DynamoDBChatMessageHistory\n",
"from kendra.kendra_index_retriever import KendraIndexRetriever\n",
"```\n",
"\n",
"\n",
"We are using the following libraries:\n",
"- json: built-in Python package, which can be used to work with JSON data.\n",
"- os: a python library implementing miscellaneous operating system interfaces \n",
"- langchain: Several classes originating out of this framework for developing applications powered by language model. For a detailed description see above.\n",
"- kendra: Kendra retriever module, pointing to the implementation in the ```kendra``` directory.\n",
"\n",
"Then we are retrieving the AWS region and the Kendra index id from the Lambda function's environment variables. We will need them further down the implementation. \n",
"\n",
"\n",
"```python\n",
"REGION = os.environ.get('REGION')\n",
"KENDRA_INDEX_ID = os.environ.get('KENDRA_INDEX_ID')\n",
"```\n",
"\n",
"\n",
"In the next step we define the LLM we want to use through the ```SagemakerEndpoint```class. \n",
"\n",
"\n",
"```python\n",
"# Generative LLM \n",
"class ContentHandler(LLMContentHandler):\n",
" content_type = \"application/json\"\n",
" accepts = \"application/json\"\n",
"\n",
" def transform_input(self, prompt, model_kwargs):\n",
" # model specific implementation\n",
" return ...\n",
" \n",
" def transform_output(self, output):\n",
" # model specific implementation\n",
" return ...\n",
"\n",
"content_handler = ContentHandler()\n",
"\n",
"llm=SagemakerEndpoint(\n",
" endpoint_name=SM_ENDPOINT_NAME,\n",
" model_kwargs={...}, # model specific hyperparameters\n",
" region_name=REGION, \n",
" content_handler=content_handler, \n",
")\n",
"```\n",
"\n",
"\n",
"Thereby the ```ContentHandler``` is used to transform input and output of the model into the desired format. This implementation can differ from model to model. In this step we can also define model-specific parameters like temperature or max_length of the generated content. In this lab, we stick with the parameter settings provided in the code. This is also why we need to adjust our ```ContentHandler``` according to the model option we chose before. \n",
"\n",
"**Please uncomment the respective ContentHandler in the file ```rag_app/rag_app.py``` (you can search with STRG/CMD+F) depending on if you chose Option 1 - FLAN-T5XXL or Option 2 - Falcon40b-instruct as model option.** \n",
"\n",
"As described further above, the ```SageMakerEndpoint``` class requires the endpoint name to be passed. This is happening through an environment variable passed to the Lambda function. We will configure this further down the notebook.\n",
"\n",
"\n",
"As discussed before, for retrieval-augmented generation with chat memory, the first of two chain steps condenses the prompt and the chat memory into a standalone ask for retrieval. Therefor we want to adjust the prompt used in this step according to the specific model we are using. This can be achieved as shown below by using the ```PromptTemplate```class.\n",
"\n",
"\n",
"```python\n",
"_template = \"\"\"Given the following conversation and a follow up question, rephrase the follow up question to be a standalone question, in its original language. \n",
"\n",
"Chat History:\n",
"{chat_history}\n",
"Follow Up Input: {question}\n",
"Standalone question:\"\"\"\n",
"\n",
"CONDENSE_QUESTION_PROMPT = PromptTemplate.from_template(_template)\n",
"```\n",
"\n",
"\n",
"Within the Lambda handler function, executed once per chat conversation we specify the ```ConversationBufferWindowMemory``` with ```k=3```, instructing the memory to always keep track of the past 3 conversation turns. In order to ingest this data into the \"MemoryTable\" DynamoDB database, we utilize a ```DynamoDBChatMessageHistory``` with session_id matching the database's partition key.\n",
"\n",
"\n",
"```python\n",
"message_history = DynamoDBChatMessageHistory(table_name=\"MemoryTable\", session_id=uuid)\n",
"memory = ConversationBufferWindowMemory(memory_key=\"chat_history\", chat_memory=message_history, return_messages=True, k=3)\n",
"```\n",
"\n",
"\n",
"Then we initialize the ```KendraIndexRetriever```, matching the created Kendra index in the region we are operating.\n",
"\n",
"\n",
"```python\n",
"retriever = KendraIndexRetriever(kendraindex=KENDRA_INDEX_ID, awsregion=REGION, return_source_documents=True)\n",
"```\n",
"\n",
"\n",
"Finally we assemble the ```ConversationalRetrievalChain``` with all above specified components and execute it with it's ```.run()``` function.\n",
"\n",
"\n",
"```python\n",
"qa = ConversationalRetrievalChain.from_llm(llm=llm, retriever=retriever, memory=memory, condense_question_prompt=CONDENSE_QUESTION_PROMPT, verbose=True)\n",
"response = qa.run(query) \n",
"```"
]
},
{
"attachments": {},
"cell_type": "markdown",
"id": "237baf5e",
"metadata": {},
"source": [
"# Application Deployment\n",
"\n",
"Finally, we want to put all pieces together and deploy the LLM-powered chatbot application we have created throughout the lab. \n",
"\n",
"## Infrastructure as Code: CloudFormation and SAM\n",
"\n",
"Complying with AW and DevOps best practices, we will be be conducting an Infrastructure as Code deployment for the majority of the application stack. Therefor we will be using [AWS Serverless Application Model (SAM)](https://aws.amazon.com/serverless/sam/).\n",
"\n",
"The AWS Serverless Application Model (SAM) is an open-source framework for building serverless applications. It provides shorthand syntax to express functions, APIs, databases, and event source mappings. With just a few lines per resource, you can define the application you want and model it using YAML. During deployment, SAM transforms and expands the SAM syntax into AWS CloudFormation syntax, enabling you to build serverless applications faster.\n",
"\n",
"## Application stack resources\n",
"\n",
"The application stack is defined through the ```template.yml``` AWS SAM file in yaml format. Once executed, it spins up the following resources:\n",
"- AWS Lambda function for hosting the orchestration layer\n",
"- Amazon API Gateway for exposing the orchestration layer in a RESTful way\n",
"- ExecutionRole for the AWS Lambda function\n",
"- VPC including two Subnets, an InternetGateway, ElasticIp, RoutingTables for hosting the application\n",
"- ECS Service/Cluster including a TaskDefinition and SecurityGroups for hosting the Frontend\n",
"- ExecutionRole for the ECS Task\n",
"- LogGroup for Observability\n",
"- LoadBalancer for exposing the Frontend\n",
"- Amazon DynamoDB table for durable storage of the chat history\n",
"\n",
"## Deploy stack with SAM\n",
"\n",
"Before we will deploy the AWS SAM stack, we need to adjust the Lambda function's environment variable pointing to the Kendra index. \n",
"\n",
"**Please overwrite the the placeholder \\*\\*\\*KENDRA_INDEX_ID\\*\\*\\* in the file ```template.yml```(you can search with STRG/CMD+F)with the index id of the Kendra index we created.** \n",
"\n",
"Further, we need to adjust the Lambda function's environment variable pointing to the LLM we've deployed. \n",
"\n",
"**Please overwrite the the placeholder \\*\\*\\*SM_ENDPOINT_NAME\\*\\*\\* in the file ```template.yml```(you can search with STRG/CMD+F)with the endpoint name of the model we've deployed.** \n",
"\n",
"\n",
"Now we are ready for deployment. Therefor we follow these subsequent steps:\n",
"\n",
"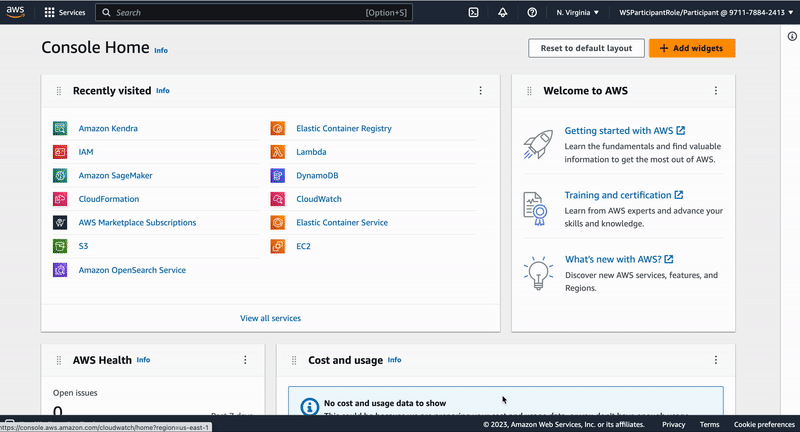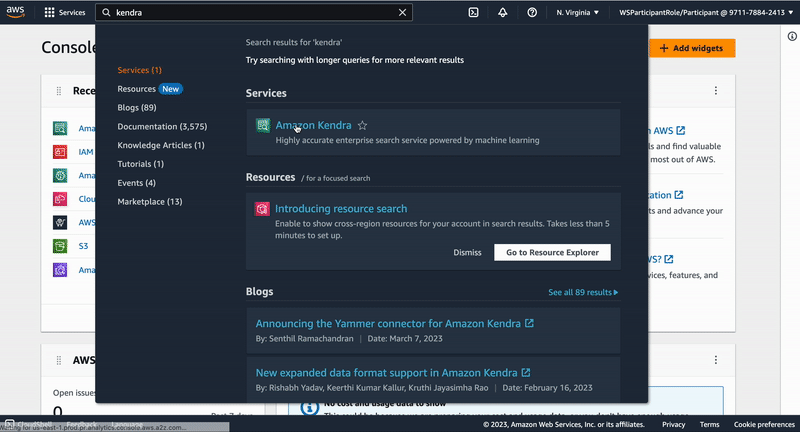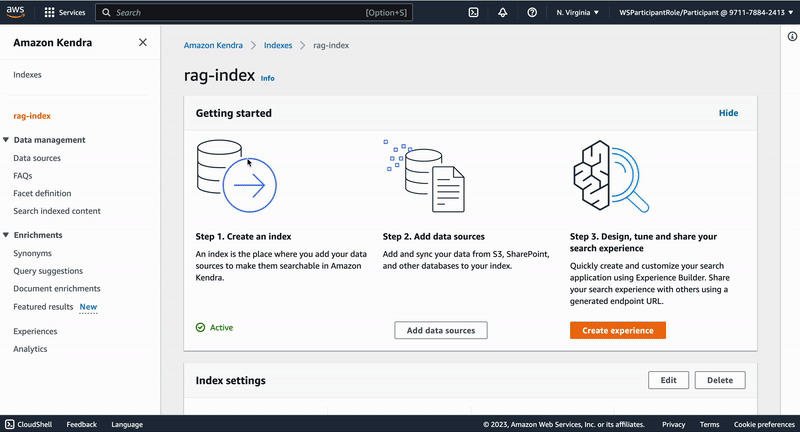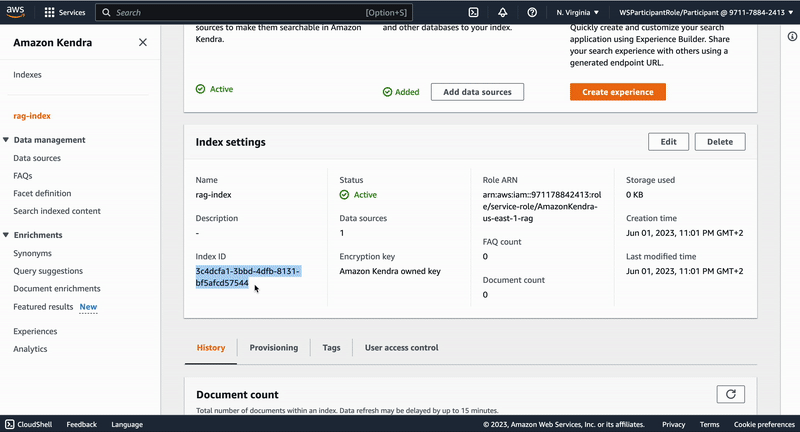\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "537ca761-8215-4149-b127-8a54790b9e87",
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"# Building the code artifacts\n",
"!sam build"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "82546710-d73d-4a22-a453-e317deaa9dcb",
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"# Deploying the stack\n",
"!sam deploy --stack-name rag-stack --resolve-s3 --capabilities CAPABILITY_IAM"
]
},
{
"attachments": {},
"cell_type": "markdown",
"id": "ff363f27",
"metadata": {},
"source": [
"Once the deployment is done, we can go ahead to the CloudFormation service and select the \"Resources\" tab of the Stack \"rag-app\". Click on the \"Physical ID\" of the LoadBalancer and copy the DNS name of the page you get forwarded to. You can now reach the web application through a browser by using this as URL.\n",
"\n",
"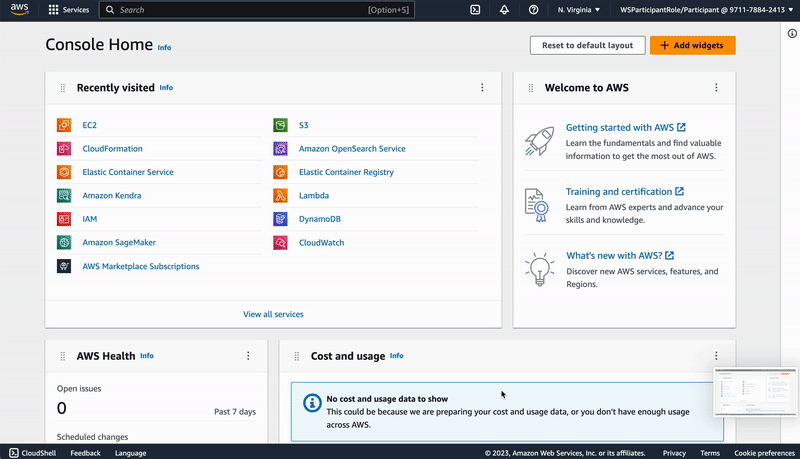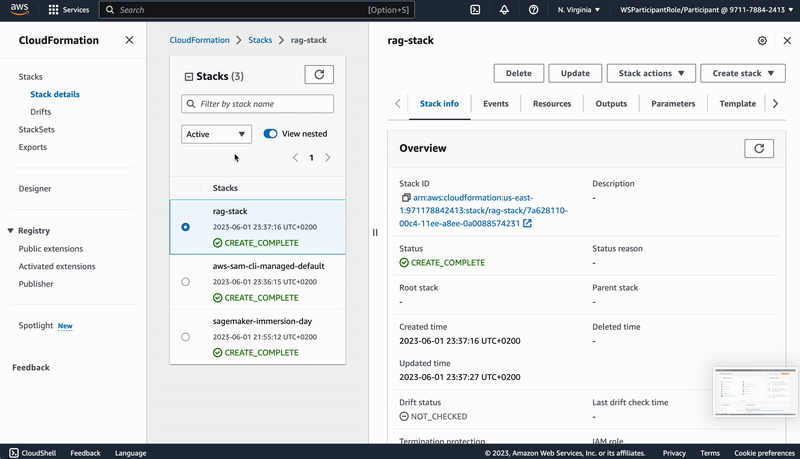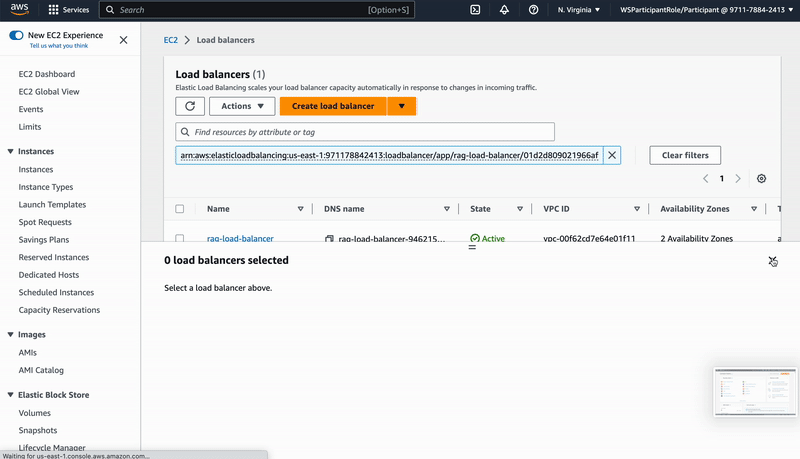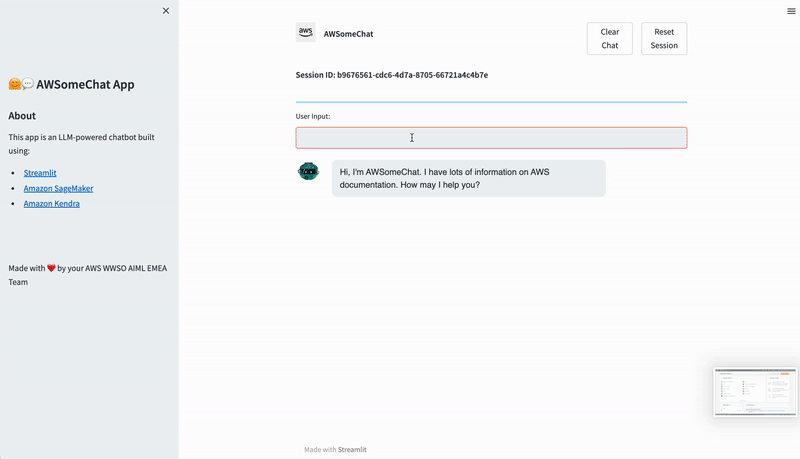"
]
},
{
"attachments": {},
"cell_type": "markdown",
"id": "cd3e52ab",
"metadata": {},
"source": [
"# Application testing\n",
"\n",
"Now that we are in the chat, let us check some things we want to ask our chatbot, while keeping in mind the resource constrains that we have in the demo accounts. \n",
"\n",
"Lets ask about Amazon EC2. What it is, how we can create one and some more information about it. \n",
"Take a look at the below conversation and try to think why the answers are structured as they are.\n",
"\n",
"
\n",
" \n",
"
\n",
"\n"
]
},
{
"attachments": {},
"cell_type": "markdown",
"id": "22572353",
"metadata": {},
"source": [
"First of all, we can see that the LLM has memory about the previous conversation turn, as we reference EC2 implicitly via \"Okay. How can I create one?\" \n",
"\n",
"Secondly, we see that the shortcoming of a low number of retrieved characters on the Kendra side. This can be solved by increasing this limit in your own account. \n"
]
},
{
"attachments": {},
"cell_type": "markdown",
"id": "3a41271b",
"metadata": {},
"source": [
"#### Discussions about the patents that we uploaded \n",
"Patents can be one of the hardest documents to find, read and investigate the claims that are made in them. After all, the claim of the patents describes exactly what has been protected. It would therefore be good way to have an easier interaction with it. \n",
"Lets see how far we can get if we would add a patent database to our system. \n",
"
\n",
" \n",
"
\n",
"\n",
"### Conclusion:\n",
"We have two main drivers for the quality of the interaction. \n",
"- The retrieval quality of our retriever. For Kendra, there are plenty of options to optimise the retrieval quality through human feedback, metadata, query optimisation and tuning search relevance to name only a few. However, this is out of scope for this workshop. We would like to point the interested reader to the [docs](https://docs.aws.amazon.com/kendra/latest/dg/tuning.html) as well as the [Kendra workshop](https://catalog.us-east-1.prod.workshops.aws/workshops/df64824d-abbe-4b0d-8b31-8752bceabade/en-US). \n",
"- The LLM that we are using for the chat interaction. Here, especially models with larger context windows can be helpful to get wider context. \n",
"\n",
"To conclude, RAG can be a very helpful approach to augment your company internal and external search. The retrieval and LLM quality are of high importance to this approach, and the generated load on the systems can be substantial. Especially here, a careful cost consideration between a token based and an infrastructure based pricing model should be done. \n"
]
},
{
"attachments": {},
"cell_type": "markdown",
"id": "f7b540f1",
"metadata": {},
"source": [
"## Extra - crawl a webpage with Kendra on the fly and investigate the langchain documentation:\n",
"Setup a Kendra connection to Langchain webpage https://python.langchain.com/en/latest/, sync it and then investigate what langchain is. \n",
"
 \n",
"
\n",
" \n",
"
\n",
" \n",
"
\n",
" \n",
"
\n",
" \n",
"
\n",
"