---
title: "Fluentd から Kinesis Data Streams へサイズが大きいデータを転送する"
slug: fluentd-kds
tags: [fluentd, kinesis data streams, kinesis]
authors: [statefb]
---
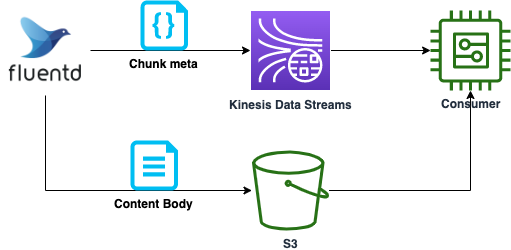
[Kinesis Data Streams](https://aws.amazon.com/jp/kinesis/data-streams/) には、1 レコードのサイズは 1MB 以下でなければならない制約があり、サイズの大きいデータを転送するには工夫が必要となります。また利用料金はストリームに読み書きされるデータ量に基づいて決定されるため、サイズが大きいと課金額も増えてしまいます。本記事では Publisher が Fluentd の場合において、上記課題を解決する方法についてご紹介します。メッセージをメタデータと本体に分割し、本体は S3 経由で Consumer に渡し、メタデータのみを Kinesis Data Streams へ送ることで実現します。
## Kinesis Data Streams について
Kinesis Data Streams (以降 KDS と呼称) は、フルマネージドのサーバレスストリーミングサービスです。シンプルな従量制課金を採用しており、シャードの稼働時間に応じて料金は計算されます。シャードは基本的なスループットの単位であり、スループット要件に応じて必要なシャード数を決定します。なおオンデマンドモードを利用した場合、読み書きのデータ量に応じて自動的にシャード数のスケールが行われます。詳細は[Amazon Kinesis Data Streams の料金](https://aws.amazon.com/jp/kinesis/data-streams/pricing/)をご覧ください。
また KDS では 1 レコードのサイズが 1MB 以下である必要があります。詳細は[Quotas and Limits](https://docs.aws.amazon.com/streams/latest/dev/service-sizes-and-limits.html)をご確認ください。
## 方針
各レコードにユニークな ID を割り当て、KDS では ID のみを、S3 バケットへはレコードの本体をそれぞれ送信します。バケットのオブジェクトキーに ID を含ませておけば、Consumer 側で ID を元にバケットから本体のデータを取得し処理することができます。これにより KDS で取り扱うレコードのサイズを削減することが可能です。本記事では、Fluentd を用いた場合について具体的に解説します。
## 想定するレコード例
サイズの大きなレコードの例を示します。
```record.json
[
{
"metrics_name": "metrics1",
"metrics_value": 24.1,
...
},
{
"metrics_name": "metrics2",
"metrics_value": 312.56,
...
},
...以降続く
]
```
上記の配列を「1 レコード」として取り扱うことを想定しています。この例の場合、各`metrics`を別々のレコードとして取り扱えばサイズを 1MB に抑えることも可能でしょう。しかし Fluentd の入力側の都合や (技術的な課題や組織的な事情)、個々の`metrics`間に依存関係があるため Consumer 側ではまとめて処理した方が見通しが良い等の事情により、分割することが困難または妥当でないケースがあります。また上記の配列単位で順序性が担保されれば良い場合、KDS にすべて送信すると前述のコスト体系により予算面で厳しいケースも考えれます。このような課題を前述の方針により解決を図ります。
## Fluentd のバッファリング
Fluentd ではレコードをバッファリングし、まとめて送信する機能があります。これによりログの欠損防止や流量の制御が可能です。本記事ではバッファリングの利用を前提とします。
Fluentd のバッファの仕組みを下記に示します。
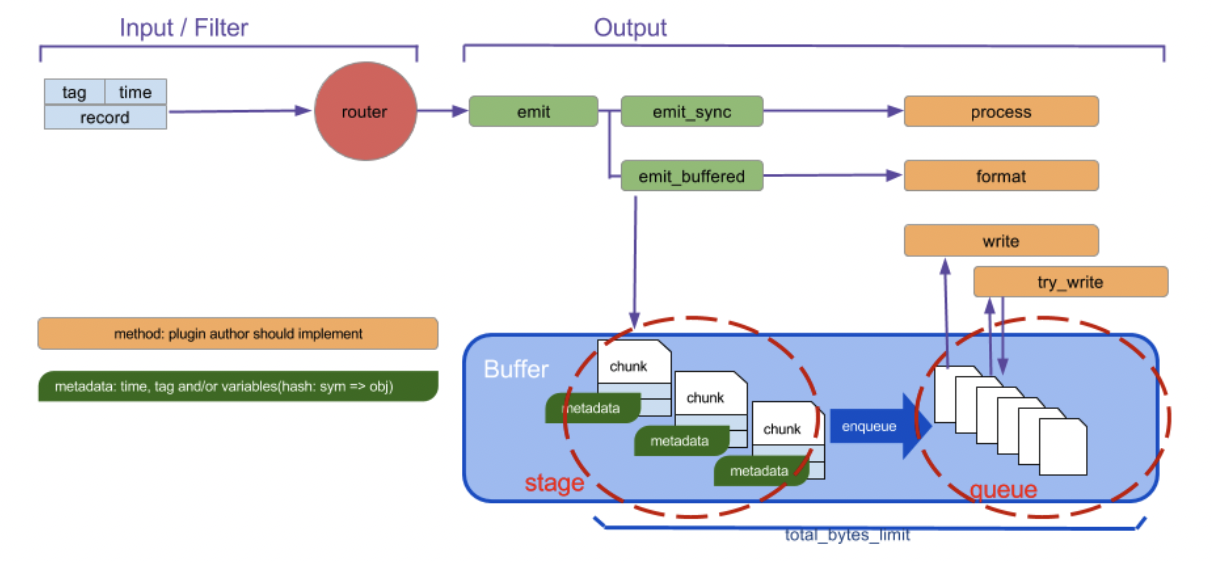
[引用先](https://docs.fluentd.org/buffer)
バッファリングには stage と queue の 2 ステップが存在します。stage の段階でイベントの塊であるチャンク (chunk) を作成し、時間経過とともにエンキューされ、Output Plugin の指定する宛先へ送信されます。なおイベントはレコード (送信したいデータ本体)、タグ、タイムスタンプの 3 つの要素から構成されます。タグは Fluentd の備える主要な要素であり、Fluentd の内部でのルーティングに利用されます。Fluentd へデータを投入する Input Plugin はレコードにタグをつけ、Fluentd はそのタグにマッチする`match`ディレクティブを検索し、対応する Output Plugin へルーティングします。
たとえば下記のような 2 つのダミーのデータソースがあるとします。それぞれタグは`example.hello`, `example.hoge`です。
```
@type dummy
dummy {"hello": "world"}
tag example.hello
@type dummy
dummy {"hoge": "hoge"}
tag example.hoge
```
上記両方ともに`example_bucket`という名前の S3 バケットへ転送したい場合、対応する match ディレクティブは下記のようになります。
```
@type s3
s3_bucket example_bucket
```
それぞれ別のバケット (`hello_bucket`, `hoge_bucket`)へ転送したい場合は下記のように記述します。
```
@type s3
s3_bucket hello_bucket
@type s3
s3_bucket hoge_bucket
```
詳細は[Config File Syntax](https://docs.fluentd.org/configuration/config-file)をご覧ください。
### チャンク
チャンクを作成するとき、[Chunk key](https://docs.fluentd.org/configuration/buffer-section#chunk-keys)と呼ばれるキーを指定しグルーピングすることができます。キーにはタグの他、タイムキーなどを含めることができます。
例えば下記のように記述した場合、イベントは 60 秒ごと、かつタグごとにグルーピングされチャンクが作られます。
```fluent.conf
timekey 60
```
チャンクを S3 へ転送する際、上記のチャンクに付与されたユニークな ID を KDS へ転送すれば Consumer 側で S3 のオブジェクトを取得できます。ユニークな ID は Output Plugin の[chunk.unique_id](https://docs.fluentd.org/plugin-development/api-plugin-output#chunk.unique_id)、Chunk key で利用したタグやタイムキーは[chunk.metadata](https://docs.fluentd.org/plugin-development/api-plugin-output#chunk.metadata)から取得することが可能です。
## Fluentd 自身のログをキャプチャする
チャンクのユニークな ID を KDS へ転送するには、Fluentd への入力として`chunk.unique_id`および`chunk.metadata`を与える必要があります。ここでは [Fluentd 自身のログをキャプチャする](https://docs.fluentd.org/deployment/logging#capture-fluentd-logs)方法を利用します。
Fluentd は Fluentd 自身のログを`fluent`タグをつけて管理しています。このログは`