# LATAM Containers Roadshow - Workshop de Amazon EKS
Neste workshop, exploraremos várias maneiras de configurar VPC, ALB, EC2 Kubernetes DataPlane Nodes e Amazon Elastic Kubernetes Service (EKS).
# Módulos
- Provisionando seu cluster EKS
- Cluster Autoscaler
- Melhor estratégia de escala com Karpenter
- Uso de instâncias Graviton e Spot para reduzir custos
- Observabilidade com o Amazon CloudWatch Container Insights
- Pipelines CI/CD
# Começando
Utilize o terminal integrado do ambiente AWS Cloud9 para executar as etapas a seguir:
### Desabilite as credenciais temporárias gerenciadas pela AWS
```bash
aws cloud9 update-environment --environment-id $C9_PID --managed-credentials-action DISABLE
rm -vf ${HOME}/.aws/credentials
```
### Crie uma Spot Linked Role
```bash
aws iam create-service-linked-role --aws-service-name spot.amazonaws.com
```
### Exporte variáveis que serão utilizadas pelo workshop.
```bash
export ACCOUNT_ID=$(aws sts get-caller-identity --output text --query Account)
export AWS_REGION=$(curl -s 169.254.169.254/latest/dynamic/instance-identity/document | jq -r '.region')
export AZS=($(aws ec2 describe-availability-zones --query 'AvailabilityZones[].ZoneName' --output text --region $AWS_REGION))
export CLUSTER_NAME='latam-containers-roadshow'
export TF_VAR_aws_region="${AWS_REGION}"
```
Exporte as variáveis no perfil do bash
```bash
echo "export ACCOUNT_ID=${ACCOUNT_ID}" | tee -a ~/.bash_profile
echo "export AWS_REGION=${AWS_REGION}" | tee -a ~/.bash_profile
echo "export AZS=(${AZS[@]})" | tee -a ~/.bash_profile
echo "export CLUSTER_NAME=${CLUSTER_NAME}" | tee -a ~/.bash_profile
echo "export TF_VAR_aws_region=${TF_VAR_aws_region}" | tee -a ~/.bash_profile
aws configure set default.region ${AWS_REGION}
aws configure get default.region
```
# Provisionando seu cluster EKS
Para o provisionamento do cluster, vamos usar o [**EKS Blueprints**](https://aws.amazon.com/blogs/containers/bootstrapping-clusters-with-eks-blueprints/). EKS Blueprints é uma coleção de módulos de infraestrutura como código (IaC) que ajuda a configurar e implantar clusters EKS consistentes e com addons instalados. Você pode usar EKS Blueprints para inicializar facilmente um cluster EKS com addons do Amazon EKS, bem como uma ampla variedade de addons populares de código aberto, incluindo Prometheus, Karpenter, Nginx, Traefik, AWS Load Balancer Controller, Fluent Bit, Keda , Argo CD e muito mais. O EKS Blueprints também ajuda a implementar controles de segurança relevantes necessários para operar cargas de trabalho de várias equipes no mesmo cluster.
### Etapa 1: clone o repositório usando o comando abaixo
```bash
git clone https://github.com/aws-samples/latam-containers-roadshow.git
```
### Etapa 2: execute o Terraform INIT
Inicialize um diretório de trabalho com arquivos de configuração
```bash
cd ~/environment/latam-containers-roadshow/workshops/eks/terraform/
terraform init
```
### Etapa 3: executar o Terraform PLAN
Verifique os recursos criados por esta execução
```bash
terraform plan
```
### Passo 4: Finalmente, Terraform APPLY
para criar recursos
```bash
terraform apply --auto-approve
```
## Configurar o kubectl e testar o cluster
Os detalhes do cluster EKS podem ser extraídos da saída do terraform ou do Console AWS para obter o nome do cluster. O comando a seguir atualiza o kubeconfig em sua máquina local onde você executa comandos kubectl para interagir com seu cluster EKS.
### Etapa 5: execute o comando update-kubeconfig
`~/.kube/config`arquivo é atualizado com detalhes do cluster:
```bash
aws eks --region ${AWS_REGION} update-kubeconfig --name ${CLUSTER_NAME}
```
### Etapa 6: Liste todos os worker nodes executando o comando abaixo
```bash
kubectl get nodes
```
# Cluster Autoscaler
Neste módulo, mostraremos padrões para dimensionar seus worker nodes e implementações de aplicativos automaticamente.
O dimensionamento automático no K8s vem em duas formas:
- **Horizontal Pod Autoscaling (HPA)** dimensiona os pods em uma implantação ou conjunto de réplicas. Ele é implementado como um recurso de API K8s e um controlador. O gerenciador do controlador consulta a utilização do recurso em relação às métricas especificadas em cada definição do HorizontalPodAutoscaler. Ele obtém as métricas da API de métricas de recursos (para métricas de recursos por pod) ou da API de métricas personalizadas (para todas as outras métricas).
- **Cluster AutoScaler (CA)** é um componente que ajusta automaticamente o tamanho de um cluster Kubernetes para que todos os pods tenham um local para execução e não haja nós desnecessários.
## Instalar kube-ops-view
Antes de começar a aprender sobre as várias opções de dimensionamento automático para seu cluster EKS, vamos instalar o [Kube-ops-view](https://github.com/hjacobs/kube-ops-view) a partir de [Henning Jacobs](https://github.com/hjacobs).
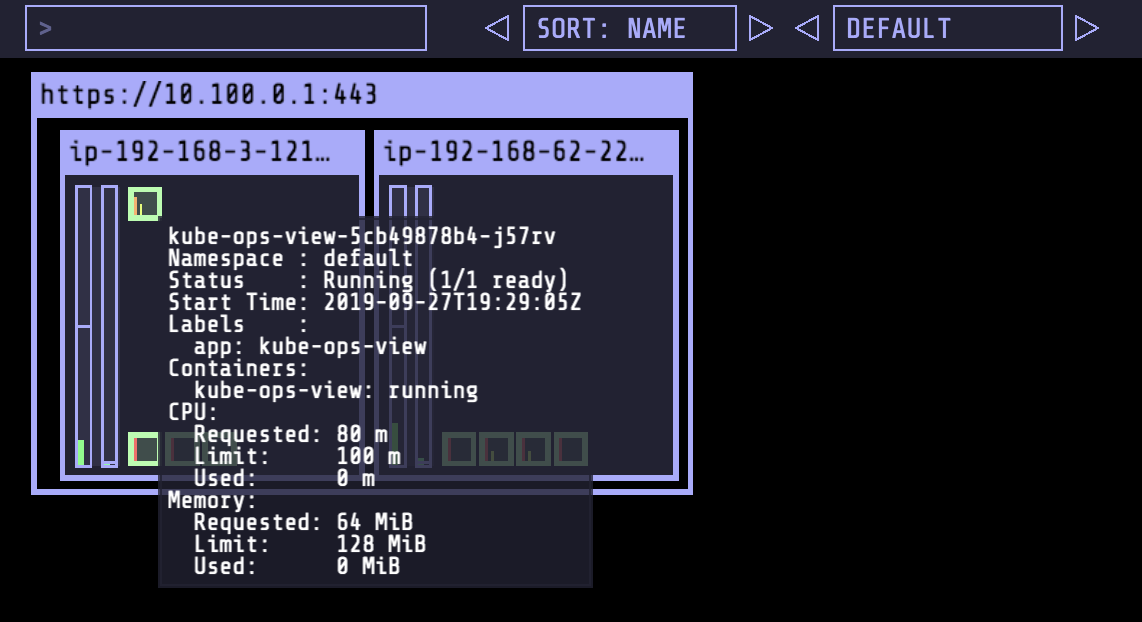
Kube-ops-view fornece uma imagem operacional comum para um cluster Kubernetes que ajuda a entender nossa configuração de cluster de maneira visual.
```bash
helm repo add stable https://charts.helm.sh/stable
helm install kube-ops-view \
stable/kube-ops-view \
--set service.type=LoadBalancer \
--set rbac.create=True
```
Para verificar se o chart foi instalado com sucesso:
```bash
helm list
```
deve exibir:
```output
NAME REVISION UPDATED STATUS CHART APP VERSION NAMESPACE
kube-ops-view 1 Sun Sep 22 11:47:31 2019 DEPLOYED kube-ops-view-1.1.0 0.11 default
```
Com isso, podemos explorar a saída do kube-ops-view verificando os detalhes sobre o serviço recém-criado.
```bash
kubectl get svc kube-ops-view | tail -n 1 | awk '{ print "Kube-ops-view URL = http://"$4 }'
```
Isso exibirá uma linha semelhante a Kube-ops-view URL = http://<URL_PREFIX_ELB>.amazonaws.com Abrir a URL em seu navegador fornecerá o estado atual de nosso cluster.
## Dimensionar um aplicativo com HPA
Para aplicativos de escalabilidade com HPA, precisaremos do servidor de métricas instalado em nosso cluster. Ele já foi instalado usando os blueprints EKS com terraform conforme mostrado abaixo:
```terraform
# Add-ons
enable_aws_load_balancer_controller = true
enable_metrics_server = true
```
### Implantar um aplicativo de exemplo
Vamos implantar um aplicativo e expor como um serviço na porta TCP 80.
O aplicativo é uma imagem personalizada com base na imagem php-apache. A página index.php realiza cálculos para gerar carga da CPU.
```bash
kubectl create deployment php-apache --image=us.gcr.io/k8s-artifacts-prod/hpa-example
kubectl set resources deploy php-apache --requests=cpu=200m
kubectl expose deploy php-apache --port 80
kubectl get pod -l app=php-apache
```
### Criar um recurso HPA
Esse HPA aumenta quando a CPU excede 50% do recurso de contêiner alocado.
```bash
kubectl autoscale deployment php-apache `#The target average CPU utilization` \
--cpu-percent=50 \
--min=1 `#The lower limit for the number of pods that can be set by the autoscaler` \
--max=10 `#The upper limit for the number of pods that can be set by the autoscaler`
```
Visualize o HPA usando kubectl. Você provavelmente vai ver`/50%`por 1-2 minutos e então você poderá ver`0%/50%`
```bash
kubectl get hpa
```
## Gerar carga para acionar o dimensionamento
Abra um novo terminal no ambiente Cloud9 e execute o comando a seguir para entrar em um shell em um novo contêiner
```bash
kubectl run -i --tty load-generator --image=busybox /bin/sh
```
Execute um loop while para continuar obtendo http:///php-apache
```bash
while true; do wget -q -O - http://php-apache; done
```
Na aba anterior, observe o HPA com o seguinte comando
```bash
kubectl get hpa -w
```
Você verá o HPA dimensionar os pods de 1 até o máximo configurado (10) até que a média da CPU esteja abaixo do nosso objetivo (50%)
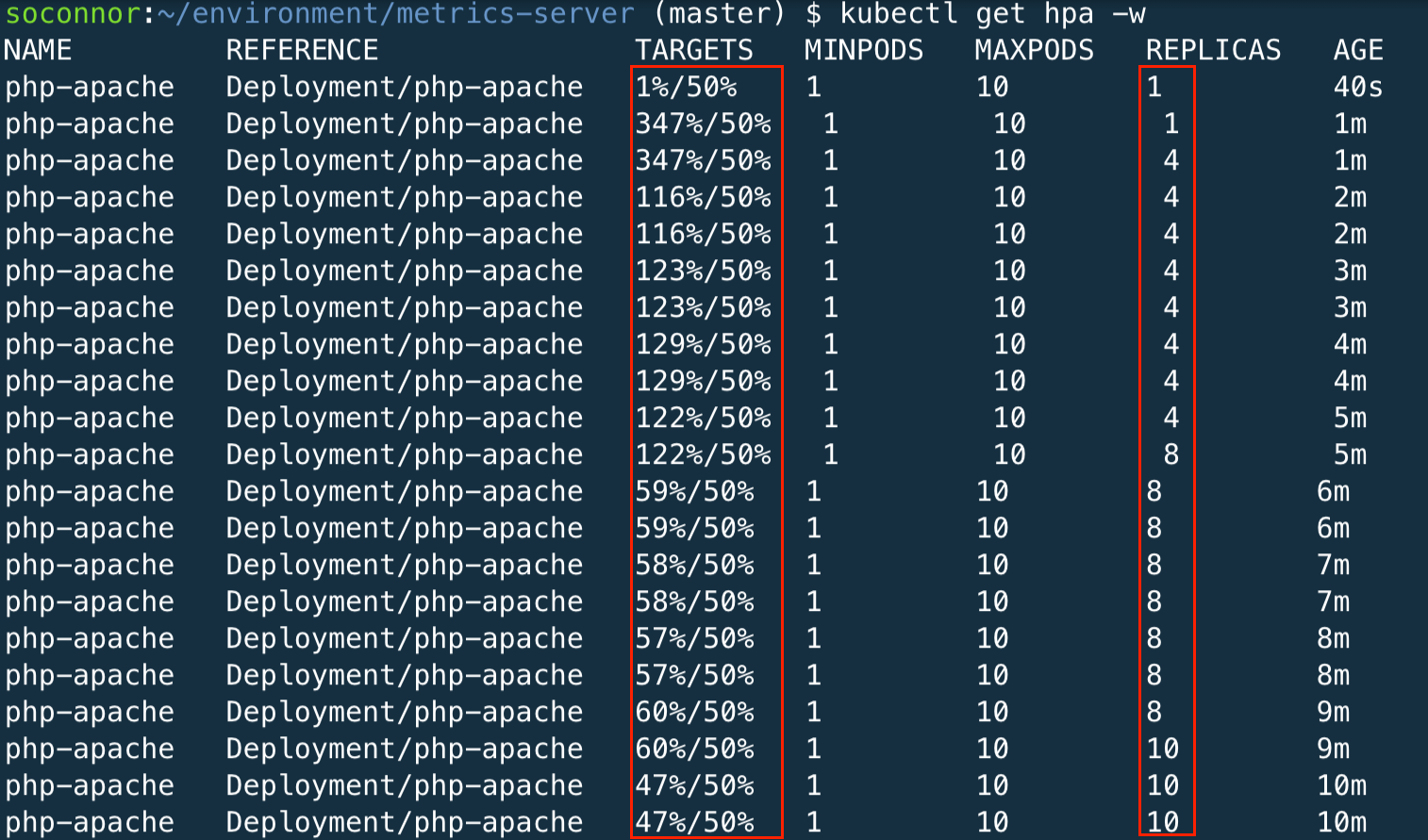
Agora você pode parar (Ctrl + C) o teste de carga que estava sendo executado no outro terminal. Você notará que o HPA trará lentamente a contagem de réplicas para o número mínimo com base em sua configuração. Você também deve sair do aplicativo de teste de carga pressionando Ctrl + D.
## Configurar o escalonador automático de cluster (CA)
O Cluster Autoscaler para AWS oferece integração com grupos de Auto Scaling. Ele permite que os usuários escolham entre quatro opções diferentes de implantação:
One Auto Scaling group
Multiple Auto Scaling groups
Auto-Discovery
Control-plane Node setup
A descoberta automática é o método preferencial para configurar o dimensionador automático de cluster.
O Cluster Autoscaler tentará determinar os recursos de CPU, memória e GPU fornecidos por um Auto Scaling Group com base no tipo de instância especificado em sua configuração de execução ou modelo de execução.
### Configurar o ASG
Você configura o tamanho do seu grupo de Auto Scaling definindo a capacidade mínima, máxima e desejada. Quando criamos o cluster, definimos essas configurações como 2 no manifesto do terraform.
```terraform
managed_node_groups = {
mg_5 = {
node_group_name = "managed-ondemand"
instance_types = ["m5.large"]
desired_size = 2
max_size = 2
min_size = 2
subnet_ids = module.vpc.private_subnets
}
}
```
Agora, aumente a capacidade máxima para 4 instâncias. Abra o`latam-containers-roadshow/workshops/eks/terraform/main.tf`arquivo e atualize o`max_size`de 2 a 4, você terá seu manifesto assim:
```terraform
managed_node_groups = {
mg_5 = {
node_group_name = "managed-ondemand"
instance_types = ["m5.large"]
desired_size = 2
max_size = 4
min_size = 2
subnet_ids = module.vpc.private_subnets
}
}
```
Vamos habilitar também o`Cluster-Autoscaler`na seção de complementos do nosso manifesto do terraform. Abra o`latam-containers-roadshow/workshops/eks/terraform/main.tf`e mude o`enable_cluster_autoscaler`a partir de`false`para`true`.
```terraform
module "eks_blueprints_kubernetes_addons" {
source = "github.com/aws-ia/terraform-aws-eks-blueprints//modules/kubernetes-addons?ref=v4.0.7"
eks_cluster_id = module.eks_blueprints.eks_cluster_id
# EKS Managed Add-ons
enable_amazon_eks_vpc_cni = true
enable_amazon_eks_coredns = true
enable_amazon_eks_kube_proxy = true
# Add-ons
enable_aws_load_balancer_controller = true
enable_metrics_server = true
enable_cluster_autoscaler = true
enable_karpenter = false
enable_aws_cloudwatch_metrics = false
enable_aws_for_fluentbit = false
tags = local.tags
depends_on = [module.eks_blueprints.managed_node_groups]
}
```
### Executar o PLAN do Terraform
Verifique os recursos criados por esta execução
```bash
cd ~/environment/latam-containers-roadshow/workshops/eks/terraform/
terraform plan
```
### Por fim, o Terraform APPLY
para criar recursos
```bash
terraform apply --auto-approve
```
Observe os logs para verificar se o Cluster Autoscaler foi implantado com êxito.
```bash
kubectl -n kube-system logs -f deployment/cluster-autoscaler-aws-cluster-autoscaler
```
## Crie um aplicativo de exemplo para testar o CA
Implantaremos um aplicativo nginx de exemplo com um ReplicaSet de 1 pod.
```bash
cat < ~/environment/nginx.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-to-scaleout
spec:
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
service: nginx
app: nginx
spec:
containers:
- image: nginx
name: nginx-to-scaleout
resources:
limits:
cpu: 500m
memory: 512Mi
requests:
cpu: 500m
memory: 512Mi
EoF
kubectl apply -f ~/environment/nginx.yaml
kubectl get deployment/nginx-to-scaleout
```
### Dimensione nosso ReplicaSet
```bash
kubectl scale --replicas=10 deployment/nginx-to-scaleout
```
Alguns pods estarão no estado `Pending`, que aciona o cluster-autoscaler para expandir a frota do EC2.
```bash
kubectl get pods -l app=nginx -o wide --watch
```
Verifique a [Console de gerenciamento EC2 AWS](https://console.aws.amazon.com/ec2/home?#Instances:sort=instanceId)para confirmar se os grupos do Auto Scaling estão aumentando para atender à demanda. Isso pode levar alguns minutos. Você também pode acompanhar a implantação do pod na linha de comando. Você deve ver a transição dos pods de pendente para execução à medida que os nós são criados.
Ou verifique usando`kubectl`
```bash
kubectl get nodes
```
A saída será semelhante a esta:
```output
ip-192-168-12-114.us-east-2.compute.internal Ready 3d6h v1.17.7-eks-bffbac
ip-192-168-29-155.us-east-2.compute.internal Ready 63s v1.17.7-eks-bffbac
ip-192-168-55-187.us-east-2.compute.internal Ready 3d6h v1.17.7-eks-bffbac
ip-192-168-82-113.us-east-2.compute.internal Ready 8h v1.17.7-eks-bffbac
```
### Limpe o ambiente
```bash
kubectl delete -f ~/environment/nginx.yaml
kubectl delete hpa,svc php-apache
kubectl delete deployment php-apache
kubectl delete pod load-generator
helm uninstall kube-ops-view
export ASG_NAME=$(aws autoscaling describe-auto-scaling-groups --query "AutoScalingGroups[? Tags[? (Key=='eks:cluster-name') && Value=='latam-containers-roadshow']].AutoScalingGroupName" --output text)
aws autoscaling \
update-auto-scaling-group \
--auto-scaling-group-name ${ASG_NAME} \
--min-size 2 \
--desired-capacity 2 \
--max-size 2
```
# Computação Flexível com Karpenter
[Karpenter](https://karpenter.sh/)é um projeto de escalonamento automático de código aberto criado para Kubernetes. O Karpenter foi projetado para fornecer os recursos de computação certos para atender às necessidades do seu aplicativo em segundos, em vez de minutos, observando as solicitações de recursos agregados de pods não programáveis e tomando decisões para iniciar e encerrar nós para minimizar as latências de agendamento.
Vamos habilitar o Karpenter e desabilitar o Cluster Autoscaler em nosso cluster EKS usando o terraform. Abra o arquivo `latam-containers-roadshow/workshops/eks/terraform/main.tf` e altere o campo `enable_cluster_autoscale` de `true` para `false`, e também altere o atributo `enable_karpenter` de `false` para `true`:
```terraform
module "eks_blueprints_kubernetes_addons" {
source = "github.com/aws-ia/terraform-aws-eks-blueprints//modules/kubernetes-addons?ref=v4.0.7"
eks_cluster_id = module.eks_blueprints.eks_cluster_id
# EKS Managed Add-ons
enable_amazon_eks_vpc_cni = true
enable_amazon_eks_coredns = true
enable_amazon_eks_kube_proxy = true
# Add-ons
enable_aws_load_balancer_controller = true
enable_metrics_server = true
enable_cluster_autoscaler = false # Disable Cluster Autoscaler
enable_karpenter = true # Enable Karpenter
enable_aws_cloudwatch_metrics = false
enable_aws_for_fluentbit = false
tags = local.tags
depends_on = [module.eks_blueprints.managed_node_groups]
}
```
Agora, diminua a capacidade máxima para 2 instâncias. Abra o`latam-containers-roadshow/workshops/eks/terraform/main.tf`arquivo e atualize o `max_size` de 4 para 2, você terá seu manifesto assim:
```terraform
managed_node_groups = {
mg_5 = {
node_group_name = "managed-ondemand"
instance_types = ["m5.large"]
desired_size = 2
max_size = 2
min_size = 2
subnet_ids = module.vpc.private_subnets
}
}
```
### Execute o PLAN do Terraform
Verifique os recursos criados por esta execução
```bash
cd ~/environment/latam-containers-roadshow/workshops/eks/terraform/
terraform plan
```
### Por fim, o Terraform APPLY
para criar recursos
```bash
terraform apply --auto-approve
```
Fazer isso removerá o Cluster Autoscaler e todos os recursos relacionados do nosso cluster e instalará o Karpenter com todos os recursos.
## Configurar o Provisionador
A configuração do Karpenter vem na forma de um Provisioner CRD (Custom Resource Definition). Um único provisionador Karpenter é capaz de lidar com vários formatos de pods diferentes. O Karpenter toma decisões de agendamento e provisionamento com base em atributos de pod, como labels e afinidade. Um cluster pode ter mais de um Provisioner, mas no momento vamos declarar apenas um: o Provisioner padrão.
Um dos principais objetivos da Karpenter é simplificar a gestão da capacidade. Se você estiver familiarizado com outros Auto Scalers, notará que o Karpenter adota uma abordagem diferente. Você pode ter ouvido a abordagem referida como dimensionamento automático sem grupo. Outras soluções têm tradicionalmente usado o conceito de um grupo de nós como o elemento de controle que define as características da capacidade fornecida (ou seja: On-Demand, EC2 Spot, GPU Nodes, etc) e que controla a escala desejada do grupo no conjunto. Na AWS, a implementação de um grupo de nós corresponde a [Grupos de Auto Scaling](https://docs.aws.amazon.com/autoscaling/ec2/userguide/AutoScalingGroup.html). Com o tempo, os clusters que usam esse paradigma, que executam diferentes tipos de aplicativos que exigem diferentes tipos de capacidade, acabam com uma configuração e um modelo operacional complexos, onde os grupos de nós devem ser definidos e fornecidos com antecedência.
Vamos implantar o seguinte provisionador:
```bash
cat < ~/environment/provisioner.yaml
apiVersion: karpenter.sh/v1alpha5
kind: Provisioner
metadata:
name: default
spec:
labels:
intent: apps
requirements:
- key: karpenter.sh/capacity-type
operator: In
values: ["spot"]
- key: kubernetes.io/arch
operator: In
values:
- amd64
- arm64
limits:
resources:
cpu: 1000
provider:
instanceProfile: ${CLUSTER_NAME}-managed-ondemand
subnetSelector:
Name: "${CLUSTER_NAME}-private*"
securityGroupSelector:
karpenter.sh/discovery/${CLUSTER_NAME}: ${CLUSTER_NAME}
ttlSecondsAfterEmpty: 30
EOF
kubectl apply -f ~/environment/provisioner.yaml
```
A configuração para este provisionador é bastante simples. Por enquanto, vamos nos concentrar em algumas das configurações usadas.
**Seção de Requisitos:** o [Provisioner CRD](https://karpenter.sh/docs/provisioner-crd/)suporta a definição de propriedades de nó como tipo de instância e zona. Por exemplo, em resposta a um label de `topology.kubernetes.io/zone=us-east-1c`, o Karpenter provisionará nós nessa zona de disponibilidade. Neste exemplo estamos configurando o`karpenter.sh/capacity-type` para pesquisar instâncias Spot do EC2. Você pode saber quais outras propriedades estão [disponíveis aqui](https://karpenter.sh/v0.7.2/aws/provisioning/).
**Seção de limites:** Os provisionadores podem definir um limite no número de CPUs e memória alocados para esse provisionador específico e parte do cluster.
**Seção do provisioner:** Este provisioner usa `securityGroupSelector` e subnetSelector para descobrir recursos usados para iniciar nós. Ele usa as tags que o Karpenter anexou às sub-redes.
**ttlSecondsAfterEmpty:** configura o Karpenter para encerrar nós vazios. Este comportamento pode ser desabilitado deixando o valor indefinido. Neste caso, configuramos para uma demonstração rápida um valor de 30 segundos.
**Tags:** Os provisionadores também podem definir um conjunto de tags que as instâncias do EC2 terão na criação. Isso ajuda a habilitar a contabilidade e a governança no nível do EC2.
## Exibindo Logs do Karpenter
Para ler os logs do Karpenter no console, você pode executar o seguinte comando.
```bash
kubectl logs -f deployment/karpenter -c controller -n karpenter
```
## Provisionando novos nós com o Karpenter
Com o Karpenter agora ativo, podemos começar a explorar como o Karpenter provisiona os nós. Nesta seção, vamos criar alguns pods usando uma implantação em que observaremos os nós de provisionamento do Karpenter em resposta.
Para este workshop, usaremos um contêiner nginx simples com **mais solicitações de recursos do que o necessário**, e veja como Karpenter lida com isso.
```bash
cat < ~/environment/karpenter-nginx.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-scale-karpenter
spec:
replicas: 3
selector:
matchLabels:
app: nginx-scale-karpenter
template:
metadata:
labels:
service: nginx-scale-karpenter
app: nginx-scale-karpenter
spec:
containers:
- image: nginx
name: nginx-scale-karpenter
resources:
limits:
cpu: 1000m
memory: 1000Mi
requests:
cpu: 1000m
memory: 1000Mi
EoF
kubectl apply -f ~/environment/karpenter-nginx.yaml
```
Liste todos os pods disponíveis no namespace padrão:
```bash
kubectl get pods
```
Observe que 2 pods estão com status`Pending`. O motivo é que o cluster não possui nenhum nó disponível exigido pela solicitação de recurso do pod.
Karpenter está monitorando o cluster e provisionando um novo nó. Observe a criação do nó até que o status seja `Ready`:
```bash
watch kubectl get nodes
```
Quando o novo nó estiver `Ready`, liste os pods para validar se o aplicativo está em execução:
```bash
kubectl get pods
```
## Desimplantar o aplicativo
Agora que entendemos como o Karpenter funciona, vamos remover a implantação do aplicativo nginx:
```bash
kubectl delete -f ~/environment/karpenter-nginx.yaml
```
Como o novo nó não possui pods em execução, o Karpenter removerá o nó. Observe a lista de nós até que o novo nó seja removido:
```bash
watch kubectl get nodes
```
## Implantar um aplicativo baseado em ARM
Quando um provisionador não especifica a arquitetura e também os tipos de instância em que pode criar novos nós, por padrão todas as instâncias e todas as arquiteturas (amd64 e arm64) serão usadas. Isso significa que uma instância [Graviton](https://aws.amazon.com/pm/ec2-graviton/) pode ser criada e, com isso, a aplicação a ser executada pode não suportar a arquitetura da instância, o que pode causar erros em tempo de execução.
É possível utilizar o [label conhecido](https://kubernetes.io/docs/reference/labels-annotations-taints/)kubernetes.io/arch no manifesto do aplicativo com um_seletor de nó_. Dessa forma, o Karpenter levará em consideração o seletor e provisionará o nó específico para esse caso de uso.
Vamos implantar uma aplicação `arm` com um seletor de nó `arm64`:
```bash
cat < ~/environment/karpenter-arm64.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: hello-world-arm
spec:
replicas: 1
selector:
matchLabels:
app: hello-world-arm
template:
metadata:
labels:
service: hello-world-arm
app: hello-world-arm
spec:
containers:
- image: public.ecr.aws/nginx/nginx:1.21-arm64v8
name: hello-world-arm
resources:
limits:
cpu: 500m
memory: 512Mi
requests:
cpu: 500m
memory: 512Mi
nodeSelector:
kubernetes.io/arch: arm64
EoF
kubectl apply -f ~/environment/karpenter-arm64.yaml
```
Liste todos os pods disponíveis no namespace padrão:
```bash
kubectl get pods
```
Observe que o pod está com o status Pendente. O motivo é que o cluster não possui nenhum nó disponível exigido pelo nodeSelector do Pod (kubernetes.io/arch: arm64).
Karpenter está monitorando o cluster e provisionando um novo nó. Observe a criação do nó até que o status seja`Ready`:
```bash
watch kubectl get nodes
```
Uma vez que o nó esteja `Ready`, vamos obter o nome do nó que o Pod está executando:
```bash
export ARM_NODE=$(kubectl get pods -owide | awk '{print $7}' | grep -vi node)
```
Agora vamos verificar os labels do Node, com os labels podemos ver se o nó foi provisionado na arquitetura correta.
```bash
kubectl get node $ARM_NODE --show-labels
```
O resultado será parecido com o abaixo:
```output
NAME STATUS ROLES AGE VERSION LABELS
ip-10-0-11-211.ec2.internal Ready 15m v1.21.12-eks-5308cf7 beta.kubernetes.io/arch=arm64,beta.kubernetes.io/instance-type=t4g.small,beta.kubernetes.io/os=linux,failure-domain.beta.kubernetes.io/region=us-east-1,failure-domain.beta.kubernetes.io/zone=us-east-1b,intent=apps,karpenter.sh/capacity-type=spot,karpenter.sh/provisioner-name=default,kubernetes.io/arch=arm64,kubernetes.io/hostname=ip-10-0-11-211.ec2.internal,kubernetes.io/os=linux,node.kubernetes.io/instance-type=t4g.small,topology.kubernetes.io/region=us-east-1,topology.kubernetes.io/zone=us-east-1b
```
Como você pode ver este Node tem o label `kubernetes.io/arch=arm64`, mostrando que é um nó com processador por Graviton.
## Desimplantar o aplicativo ARM
```bash
kubectl delete -f ~/environment/karpenter-arm64.yaml
```
Como o novo nó não possui pods em execução, o Karpenter removerá o nó. Observe a lista de nós até que o novo nó seja removido:
```bash
watch kubectl get nodes
```
## Desimplantar o Karpenter
Vamos desabilitar o Karpenter em nosso cluster EKS usando o terraform. Abra o arquivo `latam-containers-roadshow/workshops/eks/terraform/main.tf` e altere a propriedade `enable_karpenter` de `true` para`false`:
```terraform
module "eks_blueprints_kubernetes_addons" {
source = "github.com/aws-ia/terraform-aws-eks-blueprints//modules/kubernetes-addons?ref=v4.0.7"
eks_cluster_id = module.eks_blueprints.eks_cluster_id
# EKS Managed Add-ons
enable_amazon_eks_vpc_cni = true
enable_amazon_eks_coredns = true
enable_amazon_eks_kube_proxy = true
# Add-ons
enable_aws_load_balancer_controller = true
enable_metrics_server = true
enable_cluster_autoscaler = false
enable_karpenter = false # Disable Karpenter
enable_aws_cloudwatch_metrics = false
enable_aws_for_fluentbit = false
tags = local.tags
depends_on = [module.eks_blueprints.managed_node_groups]
}
```
### Execute o PLAN do Terraform
Verifique os recursos criados por esta execução
```bash
cd ~/environment/latam-containers-roadshow/workshops/eks/terraform/
terraform plan
```
### Por fim, o Terraform APPLY
para remover o Karpenter
```bash
terraform apply --auto-approve
```
Fazer isso removerá o Karpenter e todos os recursos relacionados do nosso cluster.
# Observabilidade com o Amazon Cloudwatch Container Insights
Neste módulo, aprenderemos e aproveitaremos o novo CloudWatch Container Insights para ver como você pode usar os recursos nativos do CloudWatch para monitorar o desempenho do seu cluster EKS.
Você pode usar o CloudWatch Container Insights para coletar, agregar e resumir métricas e logs de seus aplicativos e microsserviços em contêiner. O Container Insights está disponível para plataformas Amazon Elastic Container Service, Amazon Elastic Kubernetes Service e Kubernetes no Amazon EC2. As métricas incluem a utilização de recursos como CPU, memória, disco e rede. O Container Insights também fornece informações de diagnóstico, como falhas de reinicialização de contêiner, para ajudá-lo a isolar problemas e resolvê-los rapidamente.
Vamos primeiro habilitar os complementos CloudWatch e Fluent-bit no arquivo `latam-containers-roadshow/workshops/eks/terraform/main.tf`. Altere o atributo `enable_aws_cloudwatch_metrics` `false` para `true`, o atributo `enable_aws_for_fluentbit` de `false`para`true` e o atributo `enable_karpenter` de `true`para`false`:
```terraform
module "eks_blueprints_kubernetes_addons" {
source = "github.com/aws-ia/terraform-aws-eks-blueprints//modules/kubernetes-addons?ref=v4.0.7"
eks_cluster_id = module.eks_blueprints.eks_cluster_id
# EKS Managed Add-ons
enable_amazon_eks_vpc_cni = true
enable_amazon_eks_coredns = true
enable_amazon_eks_kube_proxy = true
# Add-ons
enable_aws_load_balancer_controller = true
enable_metrics_server = true
enable_cluster_autoscaler = false
enable_karpenter = false # Disable Karpenter
enable_aws_cloudwatch_metrics = true # Enable CloudWatch metrics
enable_aws_for_fluentbit = true # Enable fluent-bit
tags = local.tags
depends_on = [module.eks_blueprints.managed_node_groups]
}
```
### Executar o PLAN do Terraform
Verifique os recursos criados por esta execução
```bash
cd ~/environment/latam-containers-roadshow/workshops/eks/terraform/
terraform plan
```
### Por fim, o Terraform APPLY
para criar recursos
```bash
terraform apply --auto-approve
```
Fazer isso criará o `amazon-cloudwatch` namespace em nosso cluster com os recursos do Container Insights e o `logging` namespace com os recursos de bits fluentes.
## Verifique se o CloudWatch Container Insights está funcionando
Para verificar se os dados estão sendo coletados no CloudWatch, inicie a IU do CloudWatch Containers em seu navegador usando o link gerado pelo comando abaixo:
```bash
echo "
Use the URL below to access Cloudwatch Container Insights in $AWS_REGION:
https://${AWS_REGION}.console.aws.amazon.com/cloudwatch/home?region=${AWS_REGION}#container-insights:infrastructure
"
```
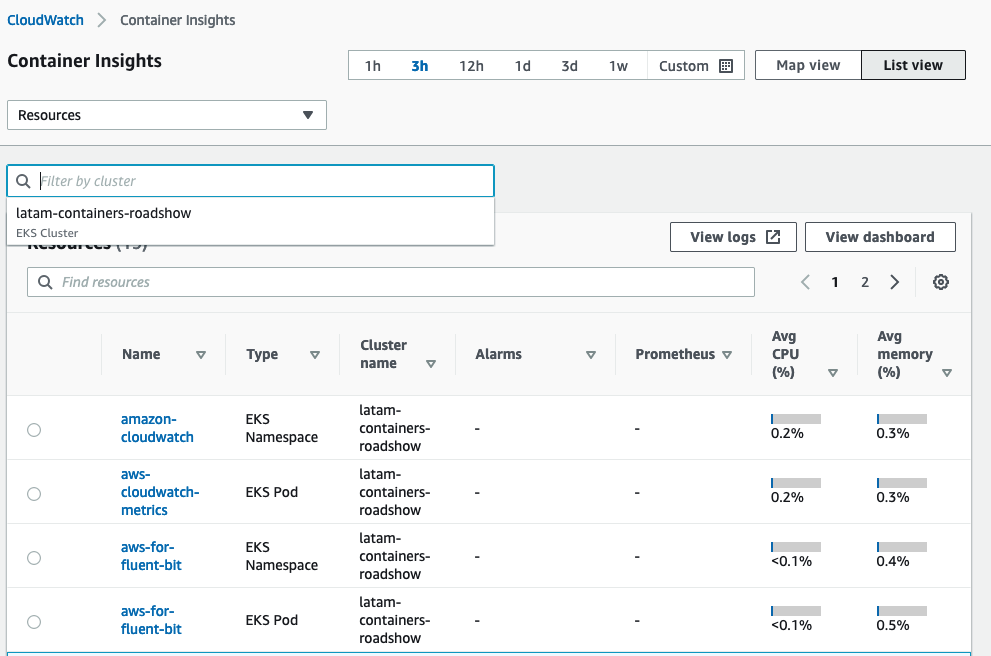
A partir daqui você pode ver que as métricas estão sendo coletadas e apresentadas para`CloudWatch`. Você pode alternar entre vários menus suspensos para ver EKS Services, EKS Cluster e muito mais.
## Verificando os logs do aplicativo
Para verificar os logs do aplicativo usando o Container Insights, você só precisa selecionar o aplicativo que deseja inspecionar no`List View`:
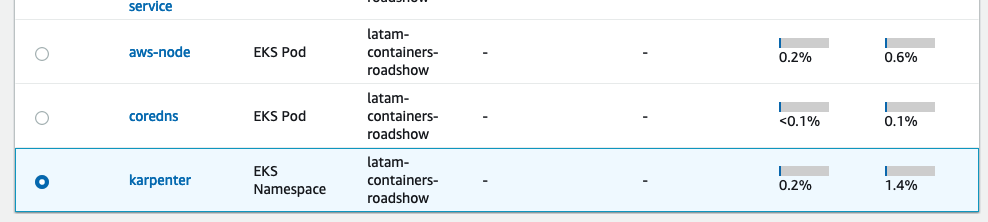
Neste caso selecionamos o Karpenter, após clicar no Karpenter será apresentado um painel do CloudWatch, com todas as métricas coletadas pelo agente CW em nosso cluster:
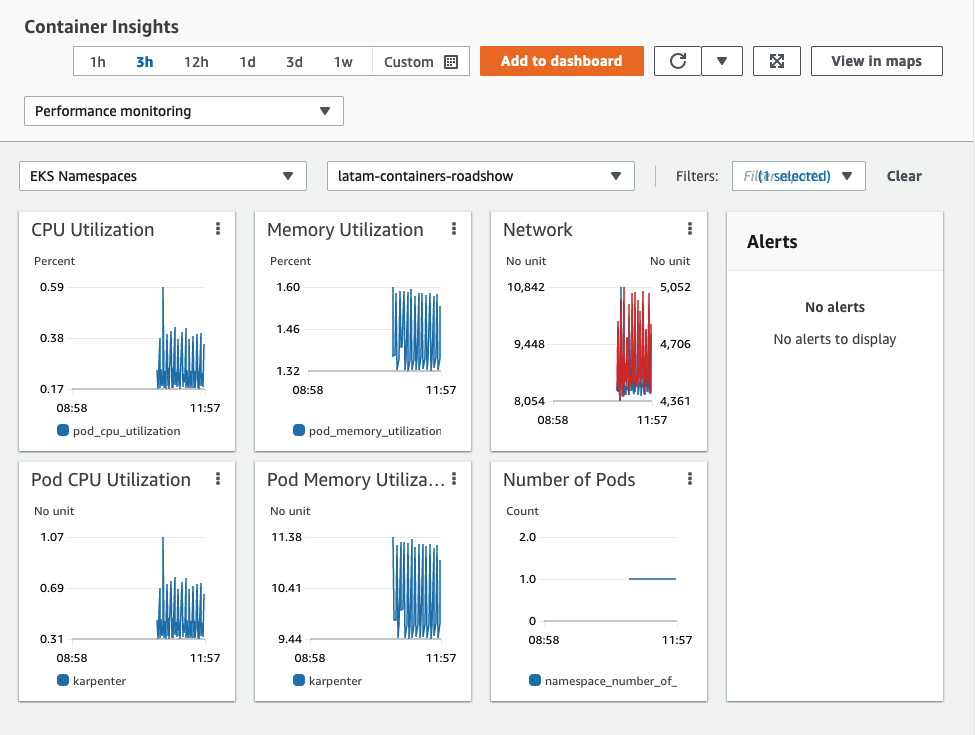
Para verificar os logs, role a página para baixo e sob `Pod performance`, selecione os`karpenter-xxx`debaixo:
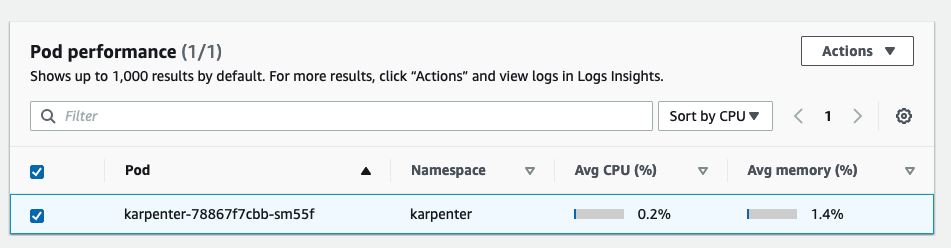
Em seguida, clique em`Actions`>`View application logs`e clique em`Run query`:
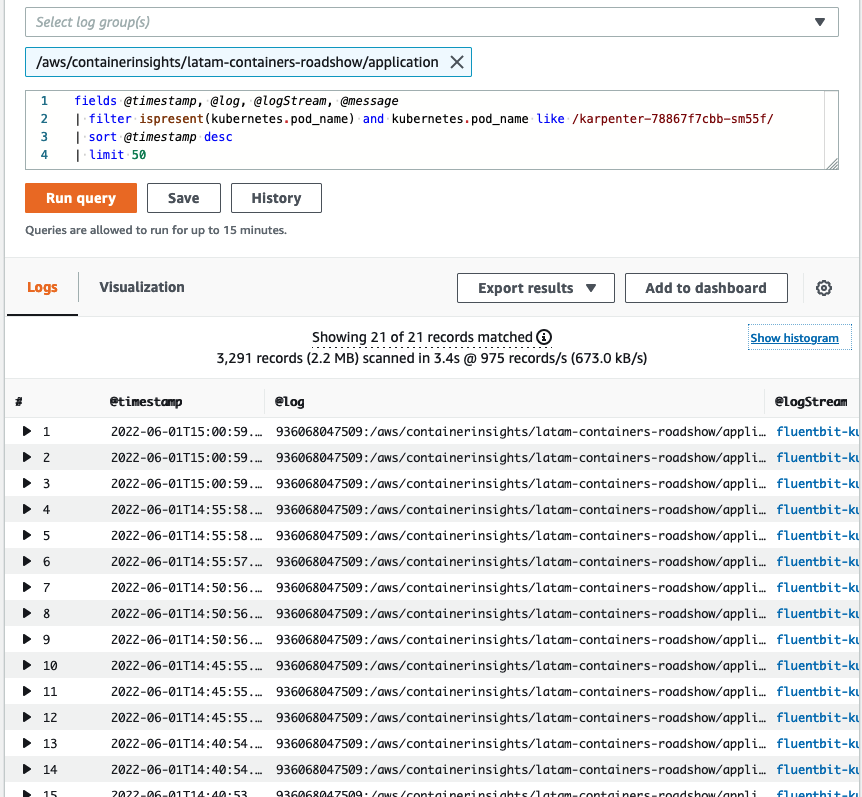
Pronto, agora podemos ver os logs gerados pelo pod do aplicativo Karpenter.
# GitOps com Flux
GitOps, um termo cunhado pela [Weave](https://www.weave.works/), é uma forma de fazer[entrega contínua](https://aws.amazon.com/devops/continuous-delivery/). O Git é usado como fonte única de verdade para implantação em seu cluster.**Isso é fácil para uma equipe de desenvolvimento, pois eles já estão familiarizados com o git e não precisam conhecer outras ferramentas.**
Neste módulo do workshop vamos configurar o [CD do Flux](https://fluxcd.io) em nosso cluster EKS e implementar um aplicativo de exemplo usando o Flux.
1. Faça o Fork do repositório do GitHub para sua conta do GitHub. Se você não tiver uma conta do GitHub, crie uma usando[esse link](https://github.com/).
2. Exporte seu token de acesso pessoal e nome de usuário do GitHub:
```bash
export GITHUB_TOKEN=
export GITHUB_USER=
echo "export GITHUB_TOKEN=${GITHUB_TOKEN}" | tee -a ~/.bash_profile
echo "export GITHUB_USER=${GITHUB_USER}" | tee -a ~/.bash_profile
```
> **_NOTA:_** Para criar seu token de acesso pessoal do GitHub, siga as instruções de[esse link](https://docs.github.com/en/authentication/keeping-your-account-and-data-secure/creating-a-personal-access-token).
3. Instale o Flux CLI:
```bash
curl -s https://fluxcd.io/install.sh | sudo bash
```
4. Verifique se você tem tudo o que é necessário para executar o Flux executando o seguinte comando:
```bash
flux check --pre
```
A saída é semelhante a:
```output
► checking prerequisites
✔ kubernetes 1.22.2 >=1.20.6
✔ prerequisites checks passed
```
5. Faça o Bootstrap, usando o comando `flux bootstrap` você pode instalar o Flux em um cluster Kubernetes e configurá-lo para se gerenciar a partir de um repositório Git.
```bash
flux bootstrap github \
--owner=${GITHUB_USER} \
--repository=latam-containers-roadshow \
--path=./workshops/eks/fluxcd-examples/clusters/my-cluster/ \
--read-write-key \
--branch=main \
--namespace=flux-system \
--components-extra=image-reflector-controller,image-automation-controller
```
O comando acima gerará uma chave SSH (o padrão é RSA 2048, mas pode ser alterado com --ssh-key-algorithm) e solicitará que você adicione a chave pública SSH como uma chave de implantação ao seu repositório.
A saída é semelhante a:
```output
► connecting to github.com
✔ repository created
✔ repository cloned
✚ generating manifests
✔ components manifests pushed
► installing components in flux-system namespace
deployment "source-controller" successfully rolled out
deployment "kustomize-controller" successfully rolled out
deployment "helm-controller" successfully rolled out
deployment "notification-controller" successfully rolled out
✔ install completed
► configuring deploy key
✔ deploy key configured
► generating sync manifests
✔ sync manifests pushed
► applying sync manifests
◎ waiting for cluster sync
✔ bootstrap finished
```
6. Para verificar se o fluxo fez a reconciliação com sucesso execute o comando abaixo:
```bash
flux get all
```
A saída terá a seguinte aparência:
```output
NAME REVISION SUSPENDED READY MESSAGE
gitrepository/flux-system main/2b3ef06 False True stored artifact for revision 'main/2b3ef069e9730074e4c48584228d6bfd1390b591'
NAME REVISION SUSPENDED READY MESSAGE
helmrepository/sample-chart 2df73a274124471769e659912cf88d9faae18f6307193bff262bc3eab75f52c7 False True stored artifact for revision '2df73a274124471769e659912cf88d9faae18f6307193bff262bc3eab75f52c7'
NAME REVISION SUSPENDED READY MESSAGE
helmchart/flux-system-app1 0.1.0 False True pulled 'hello-world' chart with version '0.1.0'
NAME REVISION SUSPENDED READY MESSAGE
helmrelease/app1 0.1.0 False True Release reconciliation succeeded
NAME REVISION SUSPENDED READY MESSAGE
kustomization/apps main/2b3ef06 False True Applied revision: main/2b3ef06
kustomization/flux-system main/2b3ef06 False True Applied revision: main/2b3ef06
kustomization/infrastructure False False kustomization path not found: stat /tmp/kustomization-1526705579/infrastructure: no such file or directory
```
## Estrutura do repositório do Flux
Use o [Kustomize Controller](https://fluxcd.io/docs/components/kustomize/) para fazer referência a manifestos no repositório.
Um objeto Kustomization define a origem dos manifestos do Kubernetes fazendo referência a um objeto gerenciado pelo [controlador de origem](https://github.com/fluxcd/source-controller), o caminho para o arquivo Kustomization dentro dessa origem e o intervalo no qual a saída da compilação kustomize é aplicada no cluster.
```output
├── apps
│ ├── app1.yaml
│ ├── kustomization.yaml
│ ├── sample-app.yaml
│ └── sources
│ ├── kustomization.yaml
│ └── sample-chart.yaml
├── clusters
│ └── my-cluster
│ ├── apps.yaml
│ └── infrastructure.yaml
└── infrastructure
├── add-ons
│ ├── cluster-autoscaler.yaml
│ ├── kustomization.yaml
│ ├── load-balancer-controller.yaml
│ └── metric-server.yaml
├── kustomization.yaml
└── sources
├── bitnami.yaml
├── cluster-autoscaler.yaml
├── eks-charts.yaml
└── kustomization.yaml
```
**apps:** A pasta onde vamos criar nossos manifestos de aplicação para implantação do Flux.
**infrastructure:** Pasta onde colocaremos seus complementos e manifestos de componentes de infraestrutura.
**clusters/meu-cluster:** Pasta onde o Flux coloca os arquivos bootstrap apontando para o nosso`Kustomizations manifests`.
### Manifesto de exemplo de customização
Vamos verificar um manifesto de Kustomization para ver como é, vamos abrir o`apps/kustomization.yaml`
```yaml
apiVersion: kustomize.config.k8s.io/v1beta1
kind: Kustomization
resources:
- app1.yaml
- sources
```
Como você pode ver acima, o objeto Kustomization é responsável por referenciar todos os outros manifestos que temos no repositório, dessa forma o Flux sabe qual manifesto aplicar em nosso cluster.
## Alterando um manifesto de aplicativo existente
Vamos alterar o `replicaCount`no aplicativo nginx que foi implantado pelo flux.
1. Verifique quantas réplicas existem em`app1`namespace com o comando abaixo:
```bash
kubectl get pods -napp1
```
> **_NOTA:_** Este aplicativo é um exemplo de nginx implantado pelo flux, o manifesto deste aplicativo já está em nosso repositório bifurcado.
2. Altere a contagem de réplicas do nosso aplicativo, vamos clonar nosso novo repositório GitHub bifurcado:
```bash
git clone https://${GITHUB_USER}:${GITHUB_TOKEN}@github.com/${GITHUB_USER}/latam-containers-roadshow ~/environment/latam-containers-roadshow-${GITHUB_USER}
```
3. Agora que o repositório está clonado, vamos alterar a quantidade de réplicas no manifesto da nossa aplicação:
```bash
cd ~/environment/latam-containers-roadshow-${GITHUB_USER}/workshops/eks/fluxcd-examples/apps/
```
4. Abrir`app1.yaml`arquivo e altere o`replicaCount`a partir de`2`para`1`:
```yaml
values:
replicaCount: 2 # Change here
image:
repository: nginx
pullPolicy: IfNotPresent
# Overrides the image tag whose default is the chart appVersion.
tag: ""
install: {}
```
```yaml
values:
replicaCount: 1 # Change here
image:
repository: nginx
pullPolicy: IfNotPresent
# Overrides the image tag whose default is the chart appVersion.
tag: ""
install: {}
```
5. Depois de editar o arquivo, vamos confirmar as alterações:
```bash
cd ~/environment/latam-containers-roadshow-${GITHUB_USER}/
git add .
git commit -m "Changed amount of replicas in app1"
git push origin main
```
6. Para verificar o processo de reconciliação, abra um novo terminal no Cloud9 e execute o comando abaixo:
```bash
watch flux get all
```
Na saída verifique o hash de commit em seu repositório e veja se ele corresponde ao`Applied revision:`
```output
kustomization/apps main/b92120e False True Applied revision: main/b92120e
```
7. Vamos verificar agora a quantidade de réplicas em nosso`app1`namespace:
```bash
kubectl get pods -napp1
```
A saída terá a seguinte aparência:
```output
NAME READY STATUS RESTARTS AGE
app1-hello-world-b75b989b-tgf5z 1/1 Running 0 22m
```
O Flux fez o **loop de reconciliação e garante o estado**que mudamos em nosso`app1`manifesto do aplicativo.
## Criando um novo aplicativo e implantando-o usando o Flux
Para exemplificar o deploy de uma nova aplicação vamos utilizar um[exemplo de aplicativo hello-world](https://gallery.ecr.aws/amazon-lightsail/hello-world)desenvolvido pela equipe do Amazon Lightsail.
1. Criando os manifestos Namespace, Deployment e Service:
```bash
cat < ~/environment/latam-containers-roadshow-${GITHUB_USER}/workshops/eks/fluxcd-examples/apps/hello-world-flux.yaml
apiVersion: v1
kind: Namespace
metadata:
name: hello-world
---
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: hello-world
name: hello-world
namespace: hello-world
spec:
replicas: 1
selector:
matchLabels:
app: hello-world
strategy: {}
template:
metadata:
labels:
app: hello-world
spec:
containers:
- image: public.ecr.aws/amazon-lightsail/hello-world:hello-world
name: hello-world
ports:
- containerPort: 80
resources: {}
---
apiVersion: v1
kind: Service
metadata:
labels:
app: hello-world
name: hello-world
namespace: hello-world
spec:
ports:
- port: 80
protocol: TCP
targetPort: 80
selector:
app: hello-world
type: LoadBalancer
EoF
```
3. Agora que criamos o arquivo, vamos enviá-lo:
```bash
cd ~/environment/latam-containers-roadshow-${GITHUB_USER}/
git add .
git commit -m "Created new hello-world application"
git push origin main
```
> **_NOTA:_** O Flux ainda não fará o loop de reconciliação, precisamos primeiro referenciar o novo arquivo criado em um manifesto de customização.
4. Adicione a referência do novo arquivo criado em nosso`kustomization.yaml`:
```bash
cd ~/environment/latam-containers-roadshow-${GITHUB_USER}/workshops/eks/fluxcd-examples/apps/
```
Adicione a linha`hello-world-flux.yaml`em`kustomization.yaml`manifest, deve ficar como abaixo:
```yaml
apiVersion: kustomize.config.k8s.io/v1beta1
kind: Kustomization
resources:
- app1.yaml
- sources
```
```yaml
apiVersion: kustomize.config.k8s.io/v1beta1
kind: Kustomization
resources:
- app1.yaml
- sources
- hello-world-flux.yaml # Add it here
```
5. Finalmente vamos confirmar as alterações.
```bash
cd ~/environment/latam-containers-roadshow-${GITHUB_USER}/
git add .
git commit -m "Added hello-world.yaml into Kustomization manifest"
git push origin main
```
## Verificando o aplicativo hello-world Implantado pelo Flux
Vamos verificar se nosso aplicativo foi implantado com sucesso, em nosso`hello-world`manifesto do aplicativo, definimos um Namespace, Deployment e um Service.
1. Vamos descrever os namespaces:
```bash
kubectl get ns
```
A saída terá a seguinte aparência:
```output
NAME STATUS AGE
amazon-cloudwatch Active 25h
app1 Active 73m
default Active 2d22h
flux-system Active 76m
hello-world Active 2m56s
karpenter Active 27h
kube-node-lease Active 2d22h
kube-public Active 2d22h
kube-system Active 2d22h
logging Active 25h
```
Como você pode ver, um`hello-world`namespace foi criado.
2. Verificando os objetos dentro do`hello-world`namespace:
```bash
kubectl get all -nhello-world
```
A saída terá a seguinte aparência:
```output
NAME READY STATUS RESTARTS AGE
pod/hello-world-654bd9b767-jd8hl 1/1 Running 0 4m2s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/hello-world LoadBalancer 172.20.47.89 a8a1c4a36beed41fb9b40106bcc79f4e-373990773.us-east-1.elb.amazonaws.com 80:30578/TCP 4m2s
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/hello-world 1/1 1 1 4m2s
NAME DESIRED CURRENT READY AGE
replicaset.apps/hello-world-654bd9b767 1 1 1 4m2s
```
Então o Flux fez o loop de reconciliação com sucesso.
3. Execute o comando abaixo para obter a URL do aplicativo:
```bash
echo HELLO_WORLD_URL=$(kubectl get svc -nhello-world | awk '{print $4}' | grep -vi exter)
```
Em seguida, abra-o no navegador, se tudo correu bem, você poderá ver o exemplo do aplicativo hello-world lightsail implantado pelo Flux.

# Limpando os recursos
## Executar Terraform Destroy
```bash
cd latam-containers-roadshow/workshops/eks/terraform/
terraform destroy --auto-approve
```