{
"cells": [
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Retail Demo Store - Personalization Workshop - Lab 4\n",
"\n",
"In this lab we are going to build on the [prior lab](./Lab-2-Prepare-Personalize-and-import-data.ipynb) by creating Amazon Personalize domain recommenders and custom solutions for additional use cases.\n",
"\n",
"## Lab 4 Objectives\n",
"\n",
"In this lab we will accomplish the following steps.\n",
"\n",
"- Evaluate the recommendations from the e-commerce recommenders created in the last lab.\n",
"- Evaluate the recommendations from the custom solutions and campaigns created in the last lab.\n",
"- Activate the recommenders and campaigns in the Retail Demo Store storefront by setting their ARNs in the System Manager Parameter Store.\n",
"- Real-time events:\n",
" - Create a Amazon Personalize Event Tracker that can be used to stream real-time events in the storefront to Personalize so Personalize can learn from user bahvior in real-time.\n",
" - Evaluate the effect of the event tracker on real-time recommendations.\n",
" - Configure and deploy the Retail Demo Store web app to pick up the event tracker so it can start streaming events.\n",
"- Create and evaluate how to use filters to apply business rules to recommendations and to promote a specific set of items while maintaining relevance.\n",
"\n",
"This lab should take 30-45 minutes to complete."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Setup\n",
"\n",
"Just as in the previous labs, we have to prepare our environment by importing dependencies and creating clients.\n",
"\n",
"### Import dependencies\n",
"\n",
"The following libraries are needed for this lab."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"import boto3\n",
"import json\n",
"import time\n",
"import requests\n",
"import random\n",
"import uuid\n",
"import pandas as pd\n",
"from IPython.display import Image, HTML\n",
"\n",
"from botocore.exceptions import ClientError"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Create clients\n",
"\n",
"We will need the following AWS service clients in this lab. Notice that we are creating some new Personalize clients with the service name of `personalize-runtime` and `personalize-events`. We'll be using these clients in this lab to get recommendations from our recommenders and campaigns and sending events to Personalize."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"personalize = boto3.client('personalize')\n",
"personalize_runtime = boto3.client('personalize-runtime')\n",
"personalize_events = boto3.client('personalize-events')\n",
"servicediscovery = boto3.client('servicediscovery')\n",
"ssm = boto3.client('ssm')"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Load variables saved in prior labs\n",
"\n",
"At the end of Lab 1 we saved some variables that we'll need in this lab. The following cell will load those variables into this lab environment."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"%store -r"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Lookup IP addresses of Products and Users microservices\n",
"\n",
"In this lab we will need to lookup details on recommended products and users. We'll do this by making RESTful API calls to these services. In the cells below, we will lookup the IP addresses of these microservices using [AWS Cloud Map](https://aws.amazon.com/cloud-map/)'s Service Discovery."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"response = servicediscovery.discover_instances(\n",
" NamespaceName='retaildemostore.local',\n",
" ServiceName='products',\n",
" MaxResults=1,\n",
" HealthStatus='HEALTHY'\n",
")\n",
"\n",
"assert len(response['Instances']) > 0, 'Products service instance not found; check ECS to ensure it launched cleanly'\n",
"\n",
"products_service_instance = response['Instances'][0]['Attributes']['AWS_INSTANCE_IPV4']\n",
"print('Products Service Instance IP: {}'.format(products_service_instance))"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"response = requests.get('http://{}/products/all'.format(products_service_instance))\n",
"products = response.json()\n",
"products_df = pd.DataFrame(products)\n",
"products_df.head(5)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"response = servicediscovery.discover_instances(\n",
" NamespaceName='retaildemostore.local',\n",
" ServiceName='users',\n",
" MaxResults=1,\n",
" HealthStatus='HEALTHY'\n",
")\n",
"\n",
"assert len(response['Instances']) > 0, 'Users service instance not found; check ECS to ensure it launched cleanly'\n",
"\n",
"users_service_instance = response['Instances'][0]['Attributes']['AWS_INSTANCE_IPV4']\n",
"print('Users Service Instance IP: {}'.format(users_service_instance))"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"response = requests.get('http://{}/users/all?count=10000'.format(users_service_instance))\n",
"users = response.json()\n",
"users_df = pd.DataFrame(users)\n",
"users_df.head(5)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Load interactions dataset\n",
"\n",
"Next let's load the interaction dataset (the CSV created in Lab 1) so we can query it to see what historical interactions were used to train the model for each user. This will help us better understand why certain products are being recommended."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"interactions_df = pd.read_csv(interactions_filename)\n",
"interactions_df['USER_ID'] = interactions_df.USER_ID.astype(str)\n",
"interactions_df['TIMESTAMP'] = pd.to_datetime(interactions_df['TIMESTAMP'],unit='s')\n",
"interactions_df.head(10)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Next let's create a couple utility functions that we can use later in the notebook to lookup recent interactions and product details for past interactions.\n",
"\n",
"The first function will lookup the most recent interactions for a user and return them in a dataframe."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Update DF rendering\n",
"pd.set_option('display.max_rows', 30)\n",
"pd.set_option('display.max_colwidth', None)\n",
"\n",
"def lookup_historical_interactions(user_id, max_count = 10):\n",
" recent_df = interactions_df.loc[interactions_df['USER_ID'] == str(user_id)]\n",
" recent_df = recent_df.sort_values(by = 'TIMESTAMP', ascending = False)\n",
" recent_df = recent_df[:max_count]\n",
" \n",
" rows = []\n",
" columns_to_keep = ['id', 'name', 'category', 'style', 'price', 'image']\n",
" for index, interaction in recent_df.iterrows():\n",
" product = products_df.loc[products_df['id'] == interaction['ITEM_ID']]\n",
" if product.empty:\n",
" continue\n",
" product = product.iloc[0]\n",
" row = {}\n",
" row['TIMESTAMP'] = interaction['TIMESTAMP']\n",
" row['EVENT_TYPE'] = interaction['EVENT_TYPE']\n",
" for col in columns_to_keep:\n",
" if col == 'image':\n",
" row[col] = ' '\n",
" elif col == 'name':\n",
" row[col] = '' + product[col] + ''\n",
" else:\n",
" row[col] = product[col]\n",
" rows.append(row)\n",
" \n",
" return pd.DataFrame(rows)\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Finally, let's test the interaction history lookup function for a random user."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"scrolled": false
},
"outputs": [],
"source": [
"# Randomly select a user.\n",
"user = users_df.sample(1).iloc[0]\n",
"user_id = user['id']\n",
"# Lookup recent interactions and product details for user.\n",
"df = lookup_historical_interactions(user_id, 20)\n",
"# Display info on user and recent interactions\n",
"header = f'
'\n",
" elif col == 'name':\n",
" row[col] = '' + product[col] + ''\n",
" else:\n",
" row[col] = product[col]\n",
" rows.append(row)\n",
" \n",
" return pd.DataFrame(rows)\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Finally, let's test the interaction history lookup function for a random user."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"scrolled": false
},
"outputs": [],
"source": [
"# Randomly select a user.\n",
"user = users_df.sample(1).iloc[0]\n",
"user_id = user['id']\n",
"# Lookup recent interactions and product details for user.\n",
"df = lookup_historical_interactions(user_id, 20)\n",
"# Display info on user and recent interactions\n",
"header = f'Recent interactions for {user[\"first_name\"]} {user[\"last_name\"]} (#{user_id})
'\n",
"header += f'Persona: {\", \".join(user[\"persona\"].split(\"_\"))}
'\n",
"HTML(header + df.to_html(escape=False))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Evaluate Recommenders\n",
"\n",
"Now let's evaluate the product recommendations from the recommenders we created in the last lab for our random user.\n",
"\n",
"### Recommended For You recommender\n",
"\n",
"We'll start with the \"Recommended For You\" recommender that we created in the last lab. This recommender provides personalized product recommendations for a specific user. We'll use the same random user selected above."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Taking note of the recent interactions and shopper persona above, let's retrieve recommendations for this user from the Recommended For You recommender.\n",
"\n",
"> As a reminder, the shopper persona was used to generate interaction history for the user by creating interactions (clicks, purchases, etc) against products in the categories represented in the persona. Since the model is trained based on these interactions we should expect to see recommendations that are consistent with the persona."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"get_recommendations_response = personalize_runtime.get_recommendations(\n",
" recommenderArn = rfy_recommender_arn,\n",
" userId = str(user_id),\n",
" numResults = 10\n",
")\n",
"\n",
"item_list = get_recommendations_response['itemList']\n",
"print(json.dumps(item_list, indent=4))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"As you can see, Personalize only returns an `itemId` for each recommended item. Since the `itemId` alone doesn't tell us much about each product, let's enhance the notebook display output to include more details about each product.\n",
"\n",
"The following code cell declares a helper function that will call `GetRecommendations` on a recommender or campaign, lookup details on each recommended item by calling the Products microservice, and return a dataframe that we can use to display the results. Be sure to execute the cell below so the function is created."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"def get_recommendations_as_df(inference_arn, user_id = None, item_id = None, num_results = 15, filter_arn = None, \n",
" filter_values = None, promotion = None):\n",
" params = {\n",
" 'numResults': num_results\n",
" }\n",
" if user_id:\n",
" params['userId'] = user_id\n",
" if item_id:\n",
" params['itemId'] = item_id\n",
" if filter_arn:\n",
" params['filterArn'] = filter_arn\n",
" if filter_values:\n",
" params['filterValues'] = filter_values\n",
" if promotion:\n",
" params['promotions'] = [ promotion ]\n",
" \n",
" is_recommender = inference_arn.split(':')[5].startswith('recommender/')\n",
" if is_recommender:\n",
" params['recommenderArn'] = inference_arn\n",
" else:\n",
" params['campaignArn'] = inference_arn\n",
"\n",
" get_recommendations_response = personalize_runtime.get_recommendations(**params)\n",
" \n",
" item_list = get_recommendations_response['itemList']\n",
" columns_to_keep = ['id', 'name', 'category', 'style', 'price', 'image', 'description', 'promoted', 'gender_affinity']\n",
" recommendation_list = []\n",
" for item in item_list:\n",
" product = products_df.loc[products_df['id'] == item['itemId']]\n",
" if product.empty:\n",
" continue\n",
" product = product.iloc[0]\n",
" row = {}\n",
" for col in columns_to_keep:\n",
" if col == 'image':\n",
" row[col] = ''\n",
" elif col == 'name':\n",
" row[col] = '' + product[col] + ''\n",
" else:\n",
" row[col] = product[col]\n",
" recommendation_list.append(row)\n",
"\n",
" return pd.DataFrame(recommendation_list)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Now let's test the function by fetching recommendations for the same user again and displaying the dataframe as HTML."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"scrolled": false
},
"outputs": [],
"source": [
"df = get_recommendations_as_df(rfy_recommender_arn, user_id = user[\"id\"], num_results = 15)\n",
"header = f'Recommended-For-You recommendations for {user[\"first_name\"]} {user[\"last_name\"]} (#{user[\"id\"]})
'\n",
"header += f'Persona: {\", \".join(user[\"persona\"].split(\"_\"))}
'\n",
"HTML(header + df.to_html(escape=False))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Are the recommended products consistent with the shopper's interaction history and persona?"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Most Viewed recommender\n",
"\n",
"Next let's take a look at the recommendations from the \"Most Viewed\" recommender. This recommender looks at product view interactions across all users to find the most popular products. Therefore, items recommended by this recommender will be the same across all users. In other words, they're not personalized to the user but rather a representation of what's popular based on all user behavior. This recommender will be used in the storefront to make recommendations of popular items to brand new/cold users."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"get_recommendations_response = personalize_runtime.get_recommendations(\n",
" recommenderArn = most_viewed_recommender_arn,\n",
" userId = str(user_id),\n",
" numResults = 10\n",
")\n",
"\n",
"item_list = get_recommendations_response['itemList']\n",
"print(json.dumps(item_list, indent=4))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"As before, let's lookup details on each of the products to provide a better sense of what's popular for the storefront."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"scrolled": false
},
"outputs": [],
"source": [
"df = get_recommendations_as_df(most_viewed_recommender_arn, user_id = user[\"id\"], num_results = 15)\n",
"header = f'Most Viewed recommendations for {user[\"first_name\"]} {user[\"last_name\"]} (#{user[\"id\"]})
'\n",
"header += f'Persona: {\", \".join(user[\"persona\"].split(\"_\"))}
'\n",
"HTML(header + df.to_html(escape=False))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Notice how the recommendations are completely different. This is because the Most Viewed recipe makes recommendations based on popularity of items across all users. Therefore, the Most Viewed recommendations are not personalized to the individual user and will be the same for all users. This makes it useful for use cases such as getting cold users engaged with your products. For this retail demo scenario, the convenience store products (pizza, soda, chips, etc) are actuall the most popular items across the diverse catalog. We'll see later in this lab how filters can be used to constrain recommendations to a portion of the catalog or based on the current user's interaction history. "
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Evaluate custom campaigns\n",
"\n",
"As you may recall from the prior lab, we created custom solutions for the related items and personalized ranking use cases. Let's evaluate the recommendations from the campaigns for those solutions below."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Similar items custom campaign\n",
"\n",
"The [Similar-Items](https://docs.aws.amazon.com/personalize/latest/dg/native-recipe-similar-items.html) recipe is designed to balance co-interactions across all users and thematic similarity between items to make relevant related items recommendations. Since the input for related items recommendations is an item ID, let's select a product from the catalog to use as our source item."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"product = products_df.sample(1)\n",
"product"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Now let's get some related item recommendations from the Similar Items based campaign for the above product. Notice that we're using the same `GetRecommendation` API as the recommenders above but this time we're specifying a `campaignArn` rather than a `recommenderArn`."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"product_id = product.iloc[0]['id']\n",
"\n",
"get_recommendations_response = personalize_runtime.get_recommendations(\n",
" campaignArn = similar_items_campaign_arn,\n",
" itemId = str(product_id),\n",
" numResults = 10\n",
")\n",
"\n",
"item_list = get_recommendations_response['itemList']\n",
"print(json.dumps(item_list, indent=4))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"As before, we'll lookup the product details for each recommended product."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"scrolled": false
},
"outputs": [],
"source": [
"df = get_recommendations_as_df(similar_items_campaign_arn, item_id = product_id, num_results = 15)\n",
"header = f'Similar Items for {product.iloc[0][\"name\"]} in {product.iloc[0][\"category\"]} (#{product.iloc[0][\"id\"]})
'\n",
"HTML(header + df.to_html(escape=False))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"How are the related item recommendations? Is there room for improvement in keeping them thematically similar? Since the Similar-Items recipe is looking at co-interactions as well as item metadata, this recipe naturally provides recommendations of items that you may also like rather than purely similar items. Later in this lab we'll see how filters can be used to setup thematic guardrails for similar items."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Personalized Ranking campaign\n",
"\n",
"Next let's evaluate the results of the personalized ranking campaign. As a reminder, given a list of items and a user, this campaign will rerank the items based on the preferences of the user. For the Retail Demo Store, we will use this campaign to rerank the products listed for each category and the featured products list as well as reranking catalog search results displayed in the search widget."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Get Featured Products List\n",
"\n",
"First let's get the list of featured products from the Products microservice and display the raw JSON response."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"scrolled": false
},
"outputs": [],
"source": [
"response = requests.get('http://{}/products/featured'.format(products_service_instance))\n",
"featured_products = response.json()\n",
"print(json.dumps(featured_products, indent = 4))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### ReRank Featured Products\n",
"\n",
"Using the featured products list just retrieved above, we'll isolate the item IDs so we can use them to test reranking for a user. We'll also prepare a dataframe that we we can use to compare the the rerank list. This reranking will allow us to provide ranked products based on the user's behavior. These behaviors should be consistent the same persona that was mentioned above (since we're going to use the same `user_id`)."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"pycharm": {
"name": "#%%\n"
},
"scrolled": false
},
"outputs": [],
"source": [
"unranked_product_ids = []\n",
"unranked_products = []\n",
"\n",
"for product in featured_products:\n",
" unranked_product_ids.append(product['id'])\n",
" unranked_products.append(f'{product[\"name\"]}
{product[\"category\"]}/{product[\"style\"]}
{product[\"id\"]}
 ')\n",
"\n",
"unranked_products_df = pd.DataFrame(unranked_products, columns = [\"Unranked products\"])\n",
"HTML(unranked_products_df.to_html(escape=False))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Now let's have Personalize rank the featured product IDs based on our random user. We'll first display the raw response from the GetPersonalizedRanking API."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"pycharm": {
"name": "#%%\n"
},
"scrolled": true
},
"outputs": [],
"source": [
"response = personalize_runtime.get_personalized_ranking(\n",
" campaignArn=ranking_campaign_arn,\n",
" inputList=unranked_product_ids,\n",
" userId=str(user[\"id\"])\n",
")\n",
"reranked = response['personalizedRanking']\n",
"print(json.dumps(response['personalizedRanking'], indent = 4))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"To make the unranked and rerank list of products easier to compare, let's create another dataframe of the reranked items and dispay the two dataframes side by side."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"scrolled": false
},
"outputs": [],
"source": [
"reranked_products = []\n",
"\n",
"for item in reranked:\n",
" product = products_df.loc[products_df['id'] == item['itemId']]\n",
" if product.empty:\n",
" continue\n",
" product = product.iloc[0]\n",
" reranked_products.append(f'{product[\"name\"]}
')\n",
"\n",
"unranked_products_df = pd.DataFrame(unranked_products, columns = [\"Unranked products\"])\n",
"HTML(unranked_products_df.to_html(escape=False))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Now let's have Personalize rank the featured product IDs based on our random user. We'll first display the raw response from the GetPersonalizedRanking API."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"pycharm": {
"name": "#%%\n"
},
"scrolled": true
},
"outputs": [],
"source": [
"response = personalize_runtime.get_personalized_ranking(\n",
" campaignArn=ranking_campaign_arn,\n",
" inputList=unranked_product_ids,\n",
" userId=str(user[\"id\"])\n",
")\n",
"reranked = response['personalizedRanking']\n",
"print(json.dumps(response['personalizedRanking'], indent = 4))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"To make the unranked and rerank list of products easier to compare, let's create another dataframe of the reranked items and dispay the two dataframes side by side."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"scrolled": false
},
"outputs": [],
"source": [
"reranked_products = []\n",
"\n",
"for item in reranked:\n",
" product = products_df.loc[products_df['id'] == item['itemId']]\n",
" if product.empty:\n",
" continue\n",
" product = product.iloc[0]\n",
" reranked_products.append(f'{product[\"name\"]}
{product[\"category\"]}/{product[\"style\"]}
{product[\"id\"]}
')\n",
"\n",
"reranked_products_df = pd.DataFrame(reranked_products, columns = [ 'Reranked products' ])\n",
"\n",
"df = pd.concat([unranked_products_df, reranked_products_df], axis=1)\n",
"\n",
"header = f'Unranked and Reranked products for {user[\"first_name\"]} {user[\"last_name\"]} (#{user[\"id\"]})
'\n",
"header += f'Persona: {\", \".join(user[\"persona\"].split(\"_\"))}
'\n",
"HTML(header + df.to_html(escape=False))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Are the reranked results for our user different than the original results from the Products service? Does the reranked list more closely reflect the interests in the user's persona? Experiment with a different user in the cells above to see how the item ranking changes."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Pick products for discount - contextual recommendations\n",
"\n",
"Using the featured products list we'll pick some products for discount from the featured products.\n",
"\n",
"We'll get the ranking when discount context is applied for comparison. This is a using the \"contextual metadata\" feature of Amazon Personalize."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"response = personalize_runtime.get_personalized_ranking(\n",
" campaignArn=ranking_campaign_arn,\n",
" inputList=unranked_product_ids,\n",
" userId=str(user_id),\n",
" context={'DISCOUNT': 'Yes'} # Here we provide the context for the ranking\n",
")\n",
"discount_reranked = response['personalizedRanking']\n",
"print('Discount context ranking:', json.dumps(discount_reranked, indent = 4))\n",
"print('Discount:', [item['itemId'] for item in discount_reranked[:2]])"
]
},
{
"cell_type": "markdown",
"metadata": {
"pycharm": {
"name": "#%% md\n"
}
},
"source": [
"We could use the discount-context ranking directly, but what we might be more interested in seeing is those products that benefit from having a discount shown. In our simulated data, certain products are more likely to see purchases with discount (to be precise, the less expensive ones). Let us find out which products benefit most. We also make use of the scores returned by Personalize when it returns the ranking."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"pycharm": {
"name": "#%%\n"
}
},
"outputs": [],
"source": [
"eps = 0.00001 # \"epsilon\" - a number slightly more than zero so we don't get division by zero\n",
"non_discount_rerank_scores = {item['itemId']: max(item['score'], eps) for item in reranked}\n",
"discount_rerank_scores = {item['itemId']: item['score'] for item in discount_reranked}\n",
"score_increases_with_discount = {item_id: discount_rerank_scores[item_id]/non_discount_rerank_scores[item_id]\n",
" for item_id in discount_rerank_scores}\n",
"# Let us get the sorted items:\n",
"discount_improve_sorted_items = sorted(score_increases_with_discount.keys(),\n",
" key=lambda key: score_increases_with_discount[key])\n",
"\n",
"print('Improvement ranking:', discount_improve_sorted_items)\n",
"# Let us pick the two items that respond best to discounts\n",
"print('Discount:', discount_improve_sorted_items[:2])"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Has the ranking changed?"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Enable recommenders and campaigns in Retail Demo Store Recommendations service\n",
"\n",
"Now that we've tested our campaigns and can get related product, product recommendations, and reranked items for our users, we need to enable the recommenders and campaigns in the Retail Demo Store's [Recommendations service](https://github.com/aws-samples/retail-demo-store/tree/master/src/recommendations). The Recommendations service is called by the Retail Demo Store Web UI when a user visits a page with personalized content capabilities (home page, product detail page, and category page). The Recommendations service checks Systems Manager Parameter values to determine the Personalize recommender and campaign ARNs to use for each of our personalization use-cases.\n",
"\n",
"Let's set the recommender and campaign ARNs in the expected parameter names.\n",
"\n",
"### Update SSM Parameters to enable recommenders"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"response = ssm.put_parameter(\n",
" Name='/retaildemostore/personalize/recommended-for-you-arn',\n",
" Description='Retail Demo Store Recommended For You Recommender/Campaign Arn Parameter',\n",
" Value='{}'.format(rfy_recommender_arn),\n",
" Type='String',\n",
" Overwrite=True\n",
")"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"response = ssm.put_parameter(\n",
" Name='/retaildemostore/personalize/popular-items-arn',\n",
" Description='Retail Demo Store Most Viewed Recommender/Campaign Arn Parameter',\n",
" Value='{}'.format(most_viewed_recommender_arn),\n",
" Type='String',\n",
" Overwrite=True\n",
")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Update SSM Parameter to enable campaigns"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"response = ssm.put_parameter(\n",
" Name='/retaildemostore/personalize/related-items-arn',\n",
" Description='Retail Demo Store Also Viewed Recommender/Campaign Arn Parameter',\n",
" Value='{}'.format(similar_items_campaign_arn),\n",
" Type='String',\n",
" Overwrite=True\n",
")"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"response = ssm.put_parameter(\n",
" Name='/retaildemostore/personalize/personalized-ranking-arn',\n",
" Description='Retail Demo Store Personalized Ranking Campaign Arn Parameter',\n",
" Value='{}'.format(ranking_campaign_arn),\n",
" Type='String',\n",
" Overwrite=True\n",
")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Evaluate Personalization in Retail Demo Store's Web UI\n",
"\n",
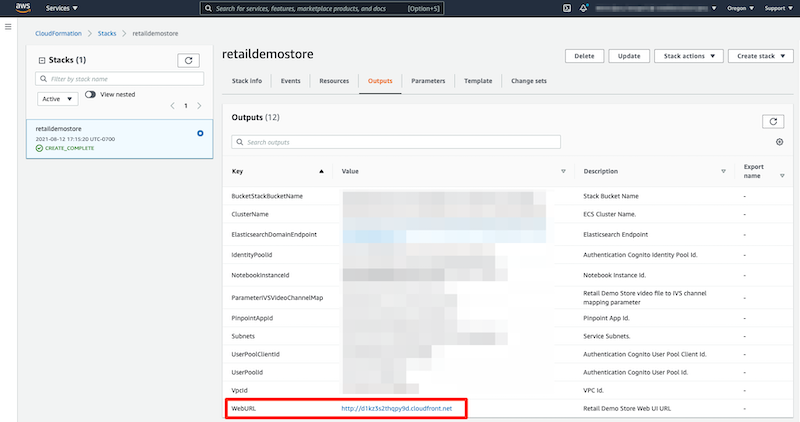
"Now that you've enabled each personalization feature by setting the respective recommender and campaign ARN, you can test these personalization features through the Retail Demo Store's Web App UI. If you haven't already opened a browser window/tab to the Retail Demo Store Web UI, navigate to the CloudFormation console in this AWS account and check the Outputs section of the stack used to launch the Retail Demo Store. Make sure you're checking the base/root stack and not the nested stacks that were created. In the Outputs section look for the output named: WebURL and browse to the URL provided.\n",
"\n",
"\n",
"\n",
"If you haven't already created a user account in your Retail Demo Store instance, let's create one now. When you access the Retail Demo Store Web UI for the first time, you will be prompted to create an account or sign in to an existing account. Click the \"**Create an account**\" button. If you skipped the account creation process, click the \"**Sign In**\" button and then click the \"**No account? Create account**\" link to create an account. Follow the prompts and enter the required data. You will need to provide a valid email address in order to receive an email with the confirmation code to validate your account.\n",
"\n",
"Once you've created and validated your account, click on the Sign In button again and sign in with the account you created."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Emulate Shopper\n",
"\n",
"To confirm product recommendations are personalized, you can emulate one of the many ficticious shoppers loaded into the system. You can also switch between shoppers by clicking the shopper profile name and details in the top navigation. You can have a shopper auto-selected for you or you can choose your own. In the shopper selection modal dialog, specify an age range and a primary shopping interest. Click Submit and a closely matching shopper is shown, confirm your choice or try again. Product recommendations should match the persona of the shopper you've selected."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Viewing Related Product Recommendations\n",
"\n",
"Let's start with the Related Product Recommendations use-case.\n",
"This recommender for this use-case is based on the [Similar-Items](https://docs.aws.amazon.com/personalize/latest/dg/native-recipe-similar-items.html)\n",
"custom solution recipe which uses item-to-item co-interactions and thematic item similarity (based on item metadata) to determine item similarity.\n",
"\n",
"Browse to a [product detail page](https://github.com/aws-samples/retail-demo-store/blob/master/src/web-ui/src/public/ProductDetail.vue)\n",
"and evaluate the products listed in the **Compare similar items** section.\n",
"You should see the Personalize service icon displayed to the right of the section header.\n",
"This tells you that results are actually coming from a recommender or campaign.\n",
"If you don't see the Personalize service icon and recipe name, the page is using default behavior of displaying products from the same category\n",
"(verify that the campaign was created successfully above **and** the campaign ARN is set as an SSM parameter).\n",
"\n",
""
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Viewing Product Recommendations\n",
"\n",
"With the user emulation saved, browse to the Retail Demo Store\n",
"[home page](https://github.com/aws-samples/retail-demo-store/blob/master/src/web-ui/src/public/Main.vue) and evaluate\n",
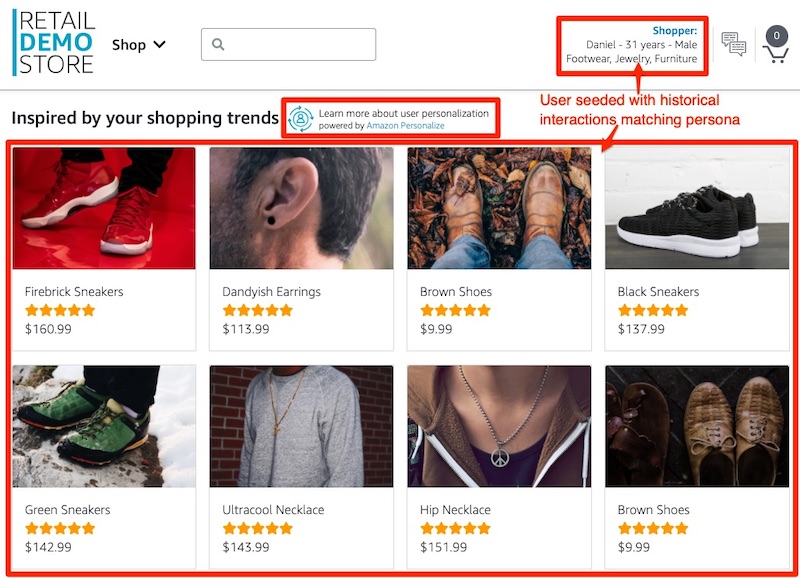
"the products listed in the **Inspired by your shopping trends** section.\n",
"Do they appear consistent with the shopping persona you're emulating? For the screenshots listed here,\n",
"the user was trained with historical data based primarily on products from the \"Footwear\" category, then to a lesser degree on products from the \"Jewelry\" category, and slightly on products from the \"Furniture\" category.\n",
"\n",
"\n",
"\n",
"Note that if the section is titled **Featured** or you don't see the Personalize service icon and recipe name displayed, this indicates that either you are not signed in as a user or the recommender ARN is not set as the appropriate SSM parameter. Double check that the recommender was created successfully in the prior lab and that the recommender ARN is set in SSM."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Personalized Ranking\n",
"\n",
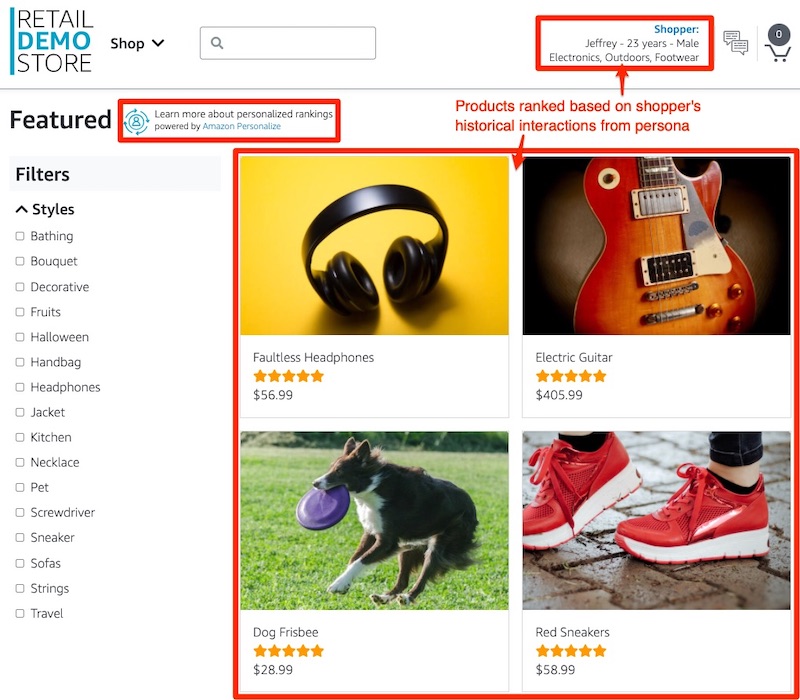
"Finally, let's evaluate the personalizated ranking use-case.\n",
"There are two places where personalized ranking is implemented in the Retail Demo Store.\n",
"With a user emulated, browse to the featured product category list by clicking on \"Featured\" from the Retail Demo Store home page.\n",
"Note how for the emulated user with a persona of \"Electronics, Outdoors, Footwear\" has the headphones, frisbee, and pair of shoes sorted to the top of the list.\n",
"(See [CategoryDetail.vue](https://github.com/aws-samples/retail-demo-store/blob/master/src/web-ui/src/public/CategoryDetail.vue)).\n",
"\n",
"\n",
"\n",
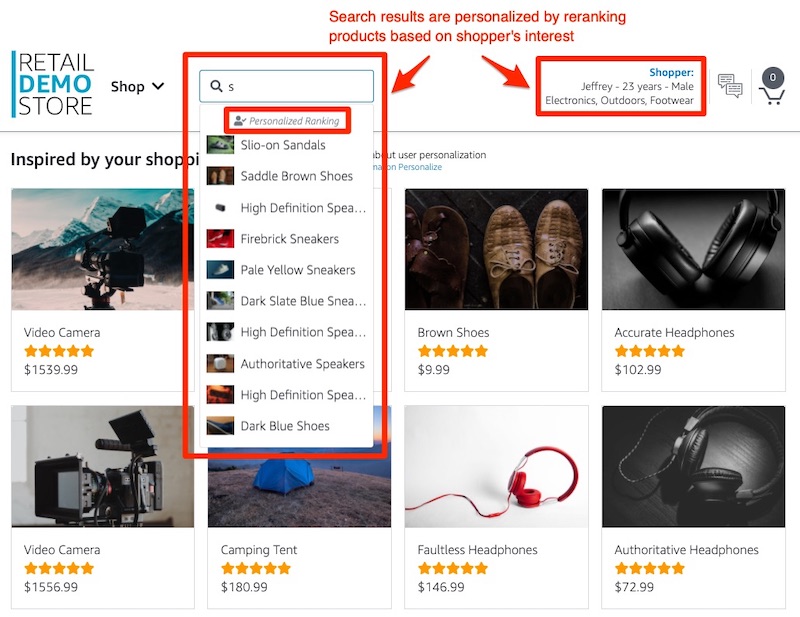
"The other feature where personalized ranking is implemented is in\n",
"[search results](https://github.com/aws-samples/retail-demo-store/blob/master/src/web-ui/src/public/Search.vue).\n",
"Start typing a word in the search box and a search result widget will be displayed.\n",
"If the results were reranked by Personalize, you will see a \"Personalize Ranking\" annotation in the search box.\n",
"For the emulated user with a historical affinity for electronics, outdoors, and footwear,\n",
"notice that a search for product keywords starting with \"s\" will move _shoes_ and _speakers_ to the top of the results.\n",
"\n",
"\n",
"\n",
"If the search functionality is not working at all for you, make sure that you\n",
"completed the [Search workshop](../0-StartHere/Search.ipynb)."
]
},
{
"cell_type": "markdown",
"metadata": {
"pycharm": {
"name": "#%% md\n"
}
},
"source": [
"### Personalized Discounts\n",
"\n",
"The Personalized Discounts are enabled against the [Amazon Interactive Video Service](https://aws.amazon.com/ivs/) (IVS) demo. You can access this page from the \"Shop\" dropdown and then select \"Live Streams\" in the navigation bar. Discounted products are chosen over the current set of products streamed from the IVS live stream:\n",
"\n",
"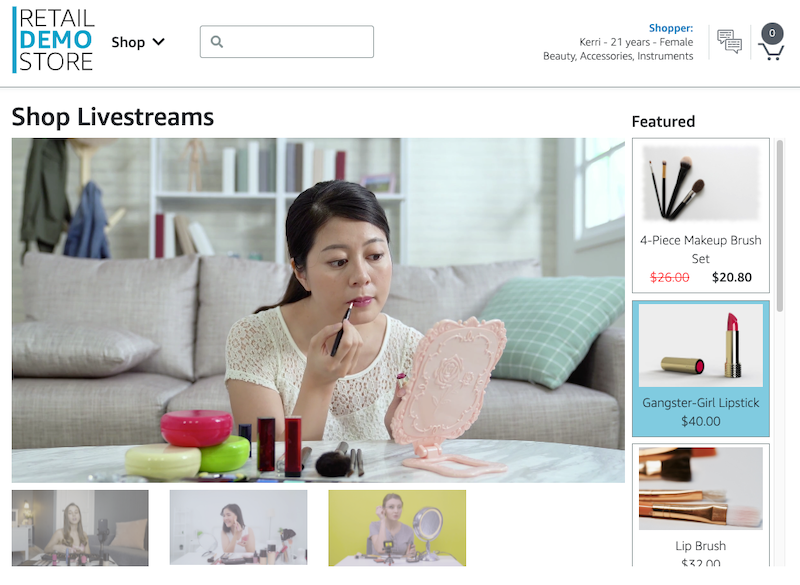\n",
"\n",
"Currently 2 products are selected for each video to be offered a discount.\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Event Tracking - Keeping up with evolving user intent\n",
"\n",
"Up to this point we have trained and deployed Amazon Personalize recommenders and campaigns based on historical data that we generated in this workshop. This allows us to make related product, user recommendations, and rerank product lists based on already observed behavior of our users. However, user intent often changes in real-time such that what products the user is interested in now may be different than what they were interested in a week ago, a day ago, or even a few minutes ago. Making recommendations that keep up with evolving user intent is one of the more difficult challenges with personalization. Fortunately, Amazon Personalize has a mechanism for this exact issue.\n",
"\n",
"Amazon Personalize supports the ability to send real-time user events (i.e. clickstream) data into the service.\n",
"Personalize uses this event data to adjust recommendations. It will also save these events and automatically\n",
"include them when recommenders and solutions for the same dataset group are re-trained.\n",
"\n",
"The Retail Demo Store's Web UI already has\n",
"[logic to send events](https://github.com/aws-samples/retail-demo-store/blob/master/src/web-ui/src/analytics/AnalyticsHandler.js)\n",
"such as 'View', 'AddToCart', 'Purchase', and others as they occur in real-time to a Personalize Event Tracker.\n",
"These are the same event types we used to initially create the recommenders, solutions, and campaigns for our personalization use-cases.\n",
"All we need to do is create an event tracker in Personalize, set the tracking Id for the tracker in an SSM parameter,\n",
"and rebuild the Web UI service to pick up the change."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Create Personalize Event Tracker\n",
"\n",
"Let's start by creating an event tracker for our dataset group."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"try:\n",
" event_tracker_response = personalize.create_event_tracker(\n",
" datasetGroupArn=dataset_group_arn,\n",
" name='retaildemostore-event-tracker'\n",
" )\n",
"\n",
" event_tracker_arn = event_tracker_response['eventTrackerArn']\n",
" event_tracking_id = event_tracker_response['trackingId']\n",
"except personalize.exceptions.ResourceAlreadyExistsException:\n",
" print('You aready created an event tracker for this dataset group, seemingly')\n",
" paginator = personalize.get_paginator('list_event_trackers')\n",
" for paginate_result in paginator.paginate(datasetGroupArn = dataset_group_arn):\n",
" for event_tracker in paginate_result['eventTrackers']:\n",
" if event_tracker['name'] == 'retaildemostore-event-tracker':\n",
" event_tracker_arn = event_tracker['eventTrackerArn']\n",
" \n",
" response = personalize.describe_event_tracker(eventTrackerArn = event_tracker_arn)\n",
" event_tracking_id = response['eventTracker']['trackingId']\n",
" break\n",
"\n",
"print('Event Tracker ARN: ' + event_tracker_arn)\n",
"print('Event Tracking ID: ' + event_tracking_id)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Wait for Event Tracker Status to Become ACTIVE\n",
"\n",
"The event tracker should take a minute or so to become active."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"status = None\n",
"max_time = time.time() + 60*60 # 1 hours\n",
"while time.time() < max_time:\n",
" describe_event_tracker_response = personalize.describe_event_tracker(\n",
" eventTrackerArn = event_tracker_arn\n",
" )\n",
" status = describe_event_tracker_response[\"eventTracker\"][\"status\"]\n",
" print(\"EventTracker: {}\".format(status))\n",
" \n",
" if status == \"ACTIVE\" or status == \"CREATE FAILED\":\n",
" break\n",
" \n",
" time.sleep(15)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Update SSM Parameter To Enable Event Tracking\n",
"\n",
"The Retail Demo Store's Web UI service just needs a Personalize Event Tracking Id to be able to send events to Personalize. The CodeBuild configuration for the Web UI service will pull the event tracking ID from an SSM parameter. \n",
"\n",
"Let's set our tracking ID in an SSM parameter."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"response = ssm.put_parameter(\n",
" Name='/retaildemostore/personalize/event-tracker-id',\n",
" Description='Retail Demo Store Personalize Event Tracker ID Parameter',\n",
" Value='{}'.format(event_tracking_id),\n",
" Type='String',\n",
" Overwrite=True\n",
")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Trigger Web UI Service Release\n",
"\n",
"Next let's trigger a new release of the Retail Demo Store's Web UI service so that it will pick up our SSM parameter change.\n",
"\n",
"In the AWS console, browse to the AWS Code Pipeline service. Find the pipeline with **WebUIPipeline** in the name. Click on the pipeline name.\n",
"\n",
"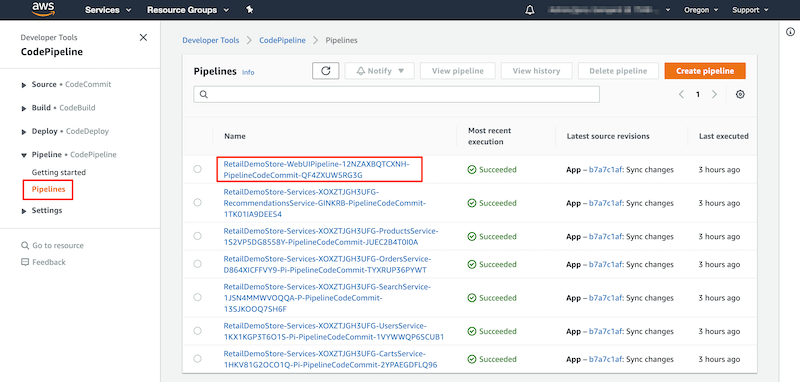"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Trigger Release\n",
"\n",
"To manually trigger a new release, click the **Release change** button, click the **Release** button on the popup dialog window, and then wait for the pipeline to build and deploy. This will rebuild the web app, deploy it to the web UI S3 bucket, and invalidate the CloudFront distribution to force browsers to load from the origin rather than from their local cache.\n",
"\n",
"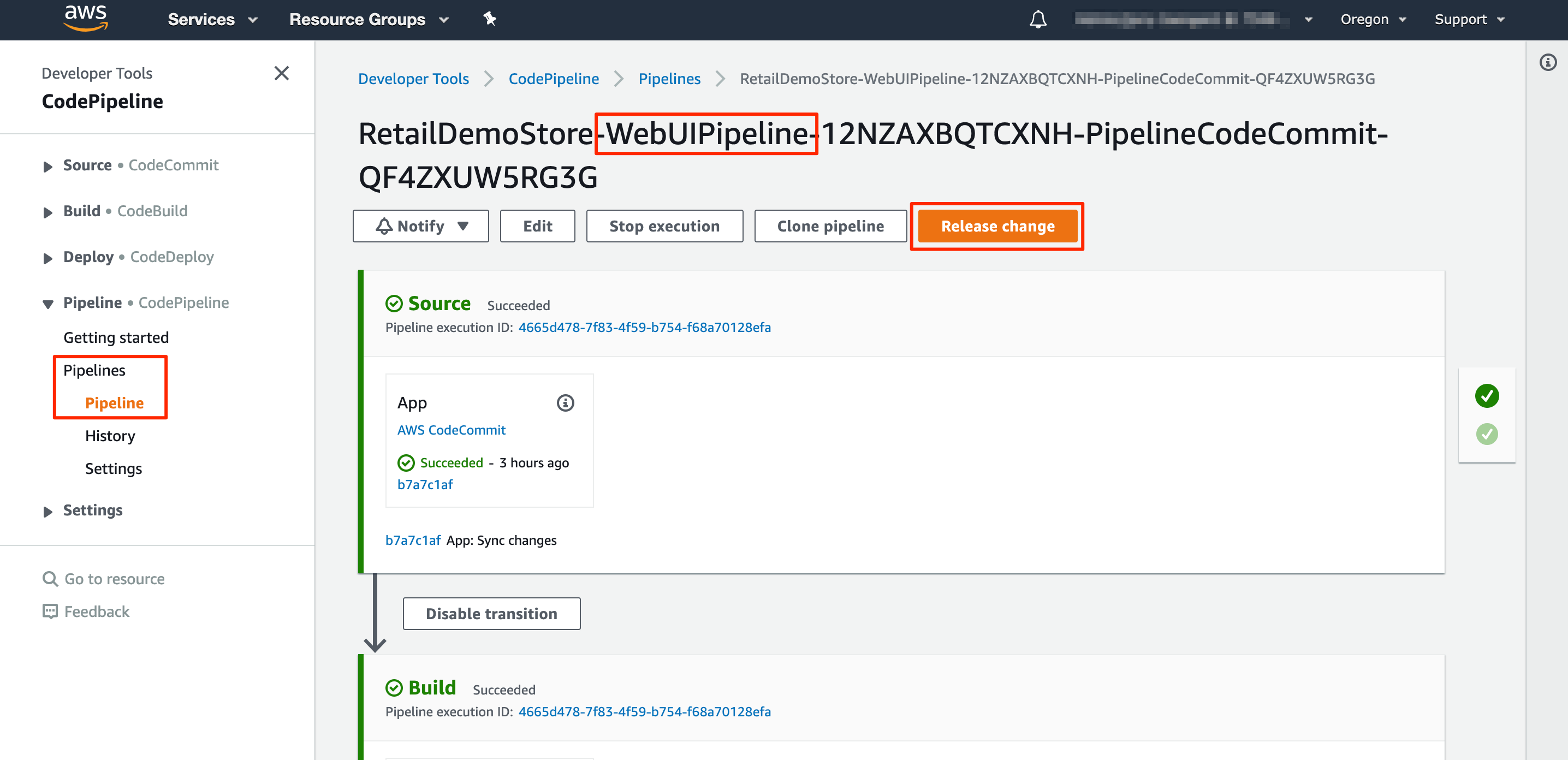"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Verify Event Tracking\n",
"\n",
"Return to your web browser tab/window where the Retail Demo Store Web UI is loaded and **reload the web app/page**. **Reloading the page is important so that the web app is reloaded in your browser and the new event tracking configuration is loaded as well.**\n",
"\n",
"There are a couple ways to verify that events are being sent to the Event Tracker. First, you can use your browser's Developer Tools to monitor the network calls made by the Retail Demo Store Web UI when you're browsing to product detail pages, adding items to carts, and completing orders. The other way you can verify that events are being received by the event tracker is in CloudWatch metrics for Personalize.\n",
"\n",
"1. If you have done so, **reload the web app by refreshing/reloading your browser page.** This is important so you browser session picks up the Event Tracker change released above.\n",
"2. If not already signed in as a storefront user, sign in as (or create) a user. \n",
"3. In the Retail Demo Store Web app, view product detail pages, add items to your cart, complete an order.\n",
"4. Verify that the Web UI is making \"events\" calls to the Personalize Event Tracker.\n",
"5. In the AWS console, browse to CloudWatch and then Metrics.\n",
"\n",
"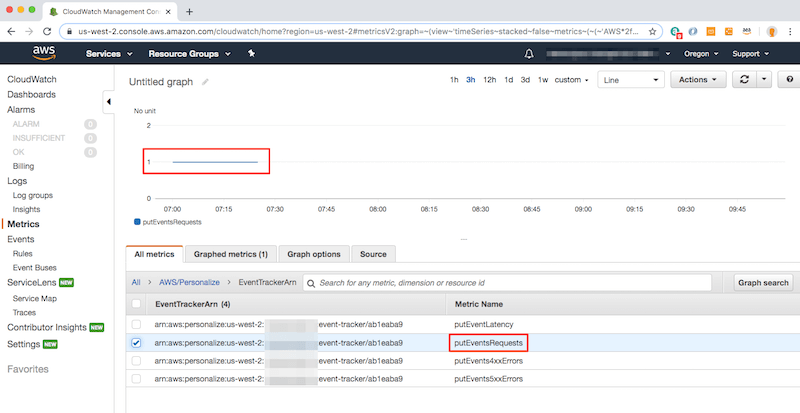\n",
"\n",
"If events are not being sent to the event tracker, make sure that the WebUIPipeline pipeline was built and deployed successfully and that you reloaded the web app in your browser. Note that it make take a minute or so before events are reflected in CloudWatch.\n",
"\n",
"To assess the impact of real-time event tracking in recommendations made by the user recommendations on the home page, follow these steps.\n",
"\n",
"1. Sign in as (or create) a storefront user.\n",
"2. View the product recommendations displayed on the home page under the \"Inspired by your shopping trends\" header. Take note of the products being recommended.\n",
"3. View products from categories that are not being recommended by clicking on their product images to take you to the product detail view. When you view the details for a product, an event is fired and sent to the Personalize event tracker.\n",
"4. Return to the home page and you should see product recommendations subtly changing to reflect the products you've engaged with. Repeat this process with other products and return to home page to see how recommendations are shifting."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Cold User Recommendations\n",
"\n",
"One of the key features of Personalize is being able to cold start users. Cold users are typically those who are new to your site or application and cold starting a user is getting from no personalization to making personalized recommendations in real-time. \n",
"\n",
"Personalize accomplishes cold starting users via the Event Tracker, just as we saw above with existing users. However, since new users are typically anonymous for a period of time before they create an account or may choose to transact as a guest, personalization is a valuable tool to help convert those anonymous users to transacting users. \n",
"\n",
"The challenge here is that Personalize needs a `userId` for anonymous users before it can make personalized recommendations. The Retail Demo Store solves this challenge by creating a provisional user ID the moment an anonymous user first hits the site. This provisional user ID is then used when streaming events to the Event Tracker and when retrieving recommendations from the Recommendations service. This allows the Retail Demo Store to start serving personalized recommendations after the first couple events are streamed to Personalize. Before recommendations can be personalized, Personalize will provide recommendations for popular items as a fallback.\n",
"\n",
"To see this behavior in action, browse to the Retail Demo Store storefront using a different browser, an Incognito/Private window, or sign out of your existing account. What you should see on the home page is that instead of **\"Inspired by your shopping behavior\"**, the section is **\"Popular products\"**. After you click on a couple provide detail pages, return to the home page and see that the section title and recommendations have changed. This indicates that recommendations are now being personalized and will continue to become more relevant as you engage with products.\n",
"\n",
"Similarly, the category pages will rerank products at first based on popularity and then become more and more personalized.\n",
"\n",
"There are some challenges with this approach, though. First is the question of what to do with the provisional user ID when the user creates an account. To maintain continuity of the user's interaction history, the Retail Demo Store passes the provisional user ID to the Users microservice when creating a new user account. The Users service then uses this ID as the user's ID going forward. Another challenge is how to handle a user that anonymously browses the site using multiple devices such as on the mobile device and then on a desktop/laptop. In this case, separate provisional user IDs are generated for sessions on each device. However, once the user creates an account on one device and then signs in with that account on the other device, both devices will starting using the same user ID going forward. A side effect here is that the interaction history from one of the devices will be orphaned. This is an acceptable tradeoff given the benefit of cold starting users earlier and is functionally the same UX without this scheme. Additional logic could be added to merge the interaction history from both prior anonymous sessions when the user creates an account. Also, customer data platforms can be used to help manage this for you."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Apply business rules to recommendations using filters\n",
"\n",
"Often times recommendations need to be post-processed to apply business rules. For example, exclude products from being recommended that are no longer in stock or that the current user has recently purchased. Or creating a \"Buy Again\" user experience that only recommends products that the current user has recently purchased. Amazon Personalize provides this capability with a feature called [filters](https://docs.aws.amazon.com/personalize/latest/dg/filter.html). Below we will create a few filters for the Retail Demo Store that are used with different use-cases."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Create/lookup filter utility function\n",
"\n",
"The following python function will be used to create/lookup each of our filters. It uses the [CreateFilter](https://docs.aws.amazon.com/personalize/latest/dg/API_CreateFilter.html) API to attempt to create the filter and, if the filter already exists, it uses the [ListFilters](https://docs.aws.amazon.com/personalize/latest/dg/API_ListFilters.html) API to lookup the filter's ARN."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"def create_filter(filter_name: str, filter_expression: str) -> str:\n",
" \"\"\" Utility function that conditionally creates/looks up a Personalize filter \"\"\"\n",
" filter_arn = None\n",
" \n",
" max_time = time.time() + 60*60 # 1 hours\n",
" while time.time() < max_time and filter_arn is None:\n",
" try:\n",
" response = personalize.create_filter(\n",
" name = filter_name,\n",
" datasetGroupArn = dataset_group_arn,\n",
" filterExpression = filter_expression\n",
" )\n",
"\n",
" filter_arn = response['filterArn']\n",
" except personalize.exceptions.ResourceAlreadyExistsException:\n",
" print(f'You aready created a filter named \"{filter_name}\" for this dataset group, seemingly')\n",
" paginator = personalize.get_paginator('list_filters')\n",
" for paginate_result in paginator.paginate(datasetGroupArn = dataset_group_arn):\n",
" for filter in paginate_result['Filters']:\n",
" if filter['name'] == filter_name:\n",
" filter_arn = filter['filterArn']\n",
" break\n",
" if not filter_arn:\n",
" raise Exception(f'Filter {filter_name} not found for dataset group; does it already exist in another dataset group')\n",
" except ClientError as e:\n",
" if e.response['Error']['Code'] == 'LimitExceededException':\n",
" print('Too many filters being created; pausing and retrying...')\n",
" time.sleep(15) \n",
" continue\n",
" else:\n",
" raise e\n",
" \n",
" print(f'Filter \"{filter_name} ARN = {filter_arn}')\n",
" return filter_arn"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Exclude purchased products filter\n",
"\n",
"Depending on the products being sold, it can be a poor user experience to recommend products that a user has already purchased. For a case like this we will create a filter that excludes recently purchased products. We'll do this by creating a filter expression that excludes items that have an interaction with an event type of `Purchase` for the user.\n",
"\n",
"> As noted earlier, the Retail Demo Store web application streams clickstream events to Personalize when the user performs various actions such as viewing and purchasing products. The filter created below allows us to use those events as exclusion criteria. See the [AnalyticsHandler.js](https://github.com/aws-samples/retail-demo-store/blob/master/src/web-ui/src/analytics/AnalyticsHandler.js) file for the code that sends clickstream events."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"exclude_purchased_filter_arn = create_filter(\n",
" 'retaildemostore-filter-exclude-purchased-products',\n",
" 'EXCLUDE itemId WHERE INTERACTIONS.event_type in (\"Purchase\")'\n",
")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Convenience store products filters\n",
"\n",
"The Alexa curbside pickup use case provided by the Retail Demo Store is focused on convenience store style products (soda, pizza, chips, etc). In order to recommend convenience store products only, we will use filters that exclude products based on categories. Notice that the second convenience store filter uses a compound or multi-expression filter."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"exclude_non_cstore_filter_arn = create_filter(\n",
" 'retaildemostore-filter-cstore-products',\n",
" 'EXCLUDE ItemID WHERE ITEMS.CATEGORY_L1 NOT IN (\"cold dispensed\", \"hot dispensed\", \"salty snacks\", \"food service\")'\n",
")\n",
"\n",
"exclude_non_cstore_purchased_filter_arn = create_filter(\n",
" 'retaildemostore-filter-exclude-purchased-cstore-products',\n",
" 'EXCLUDE ItemID WHERE INTERACTIONS.event_type IN (\"Purchase\") | EXCLUDE ItemID WHERE ITEMS.CATEGORY_L1 IN (\"cold dispensed\", \"hot dispensed\", \"salty snacks\", \"food service\")'\n",
")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Include by category filter\n",
"\n",
"The next filter that we will create is one that excludes purchased products and only includes products within one or more categories. This filter illustrates a dynamic filter where the values in the filter expression are passed in at inference-time."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"include_category_filter_arn = create_filter(\n",
" 'retaildemostore-filter-include-categories',\n",
" 'EXCLUDE ItemID WHERE INTERACTIONS.event_type IN (\"Purchase\") | INCLUDE ItemID WHERE ITEMS.CATEGORY_L1 IN ($CATEGORIES)'\n",
")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Promotional filters\n",
"\n",
"The last filters that we will create will be used to surface promotional products in recommendations for popular products and personalized products."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"promoted_items_filter_arn = create_filter(\n",
" 'retaildemostore-filter-promoted-items',\n",
" 'EXCLUDE ItemID WHERE INTERACTIONS.event_type IN (\"Purchase\") | INCLUDE ItemID WHERE ITEMS.PROMOTED IN (\"Y\")'\n",
")\n",
"\n",
"promoted_items_no_cstore_filter_arn = create_filter(\n",
" 'retaildemostore-filter-promoted-items-no-cstore',\n",
" 'EXCLUDE ItemID WHERE INTERACTIONS.event_type IN (\"Purchase\") | INCLUDE ItemID WHERE ITEMS.PROMOTED IN (\"Y\") AND ITEMS.CATEGORY_L1 NOT IN (\"cold dispensed\", \"hot dispensed\", \"salty snacks\", \"food service\")'\n",
")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Wait for filters to be created\n",
"\n",
"The following cell will wait for our filters to be fully created and active. This should only take a minute or so."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"%%time\n",
"\n",
"filter_arns = [ \n",
" exclude_purchased_filter_arn, \n",
" exclude_non_cstore_filter_arn, \n",
" exclude_non_cstore_purchased_filter_arn,\n",
" include_category_filter_arn,\n",
" promoted_items_filter_arn,\n",
" promoted_items_no_cstore_filter_arn\n",
"]\n",
"\n",
"max_time = time.time() + 60*60 # 1 hour\n",
"while time.time() < max_time:\n",
" for filter_arn in reversed(filter_arns):\n",
" response = personalize.describe_filter(\n",
" filterArn = filter_arn\n",
" )\n",
" status = response[\"filter\"][\"status\"]\n",
"\n",
" if status == \"ACTIVE\":\n",
" print(f'Filter {filter_arn} successfully created')\n",
" filter_arns.remove(filter_arn)\n",
" elif status == \"CREATE FAILED\":\n",
" print(f'Filter {filter_arn} failed')\n",
" if response['filter'].get('failureReason'):\n",
" print(' Reason: ' + response['filter']['failureReason'])\n",
" filter_arns.remove(filter_arn)\n",
"\n",
" if len(filter_arns) > 0:\n",
" print('At least one filter is still in progress')\n",
" time.sleep(15)\n",
" else:\n",
" print(\"All filters have completed\")\n",
" break"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Test Purchased Products Filter\n",
"\n",
"To test our purchased products filter, we will request recommendations for a random user. Then we will send an `Purchase` event for one of the recommended products to Personalize using the event tracker created above. Finally, we will request recommendations again for the same user but this time specify our filter."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Pick a user ID in the range of test users and fetch 5 recommendations.\n",
"user_id = '456'\n",
"get_recommendations_response = personalize_runtime.get_recommendations(\n",
" recommenderArn = rfy_recommender_arn,\n",
" userId = user_id,\n",
" numResults = 5\n",
")\n",
"\n",
"item_list = get_recommendations_response['itemList']\n",
"print(json.dumps(item_list, indent=2))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Next let's randomly select an item from the returned list of recommendations to be our product to purchase."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"product_id_to_purchase = random.choice(item_list)['itemId']\n",
"print(f'Product to simulate purchasing: {product_id_to_purchase}')"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Next let's send an `Purchase` event to Personalize to simulate that the product was just purchased.\n",
"This will match the criteria for our filter.\n",
"In the Retail Demo Store web application, this event is sent for each product in the order after the order is completed."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"response = personalize_events.put_events(\n",
" trackingId = event_tracking_id,\n",
" userId = user_id,\n",
" sessionId = str(uuid.uuid4()),\n",
" eventList = [\n",
" {\n",
" 'eventId': str(uuid.uuid4()),\n",
" 'eventType': 'Purchase',\n",
" 'itemId': str(product_id_to_purchase),\n",
" 'sentAt': int(time.time()),\n",
" 'properties': '{\"discount\": \"No\"}'\n",
" }\n",
" ]\n",
")\n",
"\n",
"# Wait for Purchase event to become consistent.\n",
"time.sleep(10)\n",
"\n",
"print(json.dumps(response, indent=2))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Finally, let's retrieve recommendations for the user again but this time specifying the filter to exclude recently\n",
"purchased items. We do this by passing the filter's ARN via the `filterArn` parameter.\n",
"In the Retail Demo Store, this is done in the\n",
"[Recommendations](https://github.com/aws-samples/retail-demo-store/tree/master/src/recommendations) service."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"get_recommendations_response = personalize_runtime.get_recommendations(\n",
" recommenderArn = rfy_recommender_arn,\n",
" userId = user_id,\n",
" numResults = 5,\n",
" filterArn = filter_arn\n",
")\n",
"\n",
"item_list = get_recommendations_response['itemList']\n",
"print(json.dumps(item_list, indent=2))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"The following code will raise an assertion error if the product we just purchased is still recommended."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"found_item = next((item for item in item_list if item['itemId'] == product_id_to_purchase), None)\n",
"if found_item:\n",
" assert found_item == False, 'Purchased item found unexpectedly in recommendations'\n",
"else:\n",
" print('Purchased item filtered from recommendations for user!')"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Test Promotional filter\n",
"\n",
"Next, let's test one of the promotional filters to see how they can be used to ensure that product meeting a specific filter are represented as a percentage of recommended products.\n",
"\n",
"For this demo application, you may remember that the Items dataset (from Lab 1) has a column named `PROMOTED` that has a value `Y` or `N` for each product. One of the promotional filters that we created above will include products where `Items.PROMOTED IN (\"Y\")`. Let's see how we can use this promotional filter with the Recommended-For-You recommender.\n",
"\n",
"Take note of the `promotions` parameter and the values passed in the `GetRecommendations` API call below. The name of the promotion (`promotions[].name`) is user-defined and will be echoed back in the response for promoted items. The `promotions[].filterArn` is the ARN for the promotional filter. And `promotions[].percentPromotedItems` indicates the percentage of recommended items should be the result of the promotional filter."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"get_recommendations_response = personalize_runtime.get_recommendations(\n",
" recommenderArn = rfy_recommender_arn,\n",
" userId = user_id,\n",
" numResults = 10,\n",
" promotions = [\n",
" {\n",
" 'name': 'my-promo',\n",
" 'filterArn': promoted_items_filter_arn,\n",
" 'percentPromotedItems': 30\n",
" }\n",
" ]\n",
")\n",
"\n",
"item_list = get_recommendations_response['itemList']\n",
"print(json.dumps(item_list, indent=2))"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"scrolled": false
},
"outputs": [],
"source": [
"promotion = {\n",
" 'name': 'my-promo',\n",
" 'filterArn': promoted_items_filter_arn,\n",
" 'percentPromotedItems': 30\n",
"}\n",
"df = get_recommendations_as_df(rfy_recommender_arn, user_id = user[\"id\"], num_results = 15, promotion = promotion)\n",
"header = f'Recommended-For-You recommendations with Promotions for {user[\"first_name\"]} {user[\"last_name\"]} (#{user[\"id\"]})
'\n",
"header += f'Persona: {\", \".join(user[\"persona\"].split(\"_\"))}
'\n",
"HTML(header + df.to_html(escape=False))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Update filter SSM parameters\n",
"\n",
"With our filters created and one of them tested, the last step is to update the SSM parameters that is used throughout the Retail Demo Store project to detect and use the filter ARNs.\n",
"\n",
"The [Recommendations](https://github.com/aws-samples/retail-demo-store/tree/master/src/recommendations) service already has logic to look for these filter ARNs in SSM and use them when fetching recommendations. All we have to do is set the filter ARNs in SSM."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"ssm.put_parameter(\n",
" Name='/retaildemostore/personalize/filters/filter-purchased-arn',\n",
" Description='Retail Demo Store Personalize Filter Purchased Products Arn Parameter',\n",
" Value=exclude_purchased_filter_arn,\n",
" Type='String',\n",
" Overwrite=True\n",
")"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"ssm.put_parameter(\n",
" Name='/retaildemostore/personalize/filters/filter-cstore-arn',\n",
" Description='Retail Demo Store Filter C-Store Products Arn Parameter',\n",
" Value=exclude_non_cstore_filter_arn,\n",
" Type='String',\n",
" Overwrite=True\n",
")"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"ssm.put_parameter(\n",
" Name='/retaildemostore/personalize/filters/filter-purchased-and-cstore-arn',\n",
" Description='Retail Demo Store Filter Purchased and C-Store Products Arn Parameter',\n",
" Value=exclude_non_cstore_purchased_filter_arn,\n",
" Type='String',\n",
" Overwrite=True\n",
")"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"ssm.put_parameter(\n",
" Name='/retaildemostore/personalize/filters/filter-include-categories-arn',\n",
" Description='Retail Demo Store Filter to Include by Categories Arn Parameter',\n",
" Value=include_category_filter_arn,\n",
" Type='String',\n",
" Overwrite=True\n",
")"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"ssm.put_parameter(\n",
" Name='/retaildemostore/personalize/filters/promoted-items-filter-arn',\n",
" Description='Retail Demo Store Promotional Filter to Include Promoted Items Arn Parameter',\n",
" Value=promoted_items_filter_arn,\n",
" Type='String',\n",
" Overwrite=True\n",
")"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"ssm.put_parameter(\n",
" Name='/retaildemostore/personalize/filters/promoted-items-no-cstore-filter-arn',\n",
" Description='Retail Demo Store Promotional Filter to Include Promoted Non-CStore Items Arn Parameter',\n",
" Value=promoted_items_no_cstore_filter_arn,\n",
" Type='String',\n",
" Overwrite=True\n",
")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Now if you test completing an order for one or more items in the Retail Demo Store web application for a user,\n",
"those products should no longer be included in recommendations for that user.\n",
"\n",
"Test it out by purchasing a recommended product from the \"Inspired by your shopping trends\"\n",
"section of the home page and then verifying that the product is no longer recommended.\n",
"\n",
"Also be sure to test the \"Compare similar items\" recommendations on the product detail page for a few products. How have the recommendations been improved with the addition of the filter? Are they consistently more thematically similar?\n",
"\n",
"Finally, check the recommendations on the homepage for \"Promoted\" items in both the \"Popular products\" (cold user) and \"Inspired by your shopping trends\" (warm/existing user) grid controls."
]
},
{
"cell_type": "markdown",
"metadata": {
"pycharm": {
"name": "#%% md\n"
}
},
"source": [
"## Workshop Complete\n",
"\n",
"Congratulations! You have completed the Retail Demo Store Personalization Workshop.\n",
"\n",
"### Cleanup\n",
"\n",
"If you launched the Retail Demo Store in your personal AWS account **AND** you're done with all workshops, you can follow the [Personalize workshop cleanup](./1.3-Personalize-Cleanup.ipynb) notebook to delete all of the Amazon Personalize resources created by this workshop. **IMPORTANT: since the Personalize resources were created by this notebook and not CloudFormation, deleting the CloudFormation stack for the Retail Demo Store will not remove the Personalize resources. You MUST run the [Personalize workshop cleanup](./1.3-Personalize-Cleanup.ipynb) notebook or manually clean up these resources.**\n",
"\n",
"If you are participating in an AWS managed event such as a workshop and using an AWS provided temporary account, you can skip the cleanup workshop unless otherwise instructed."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": []
}
],
"metadata": {
"kernelspec": {
"display_name": "conda_python3",
"language": "python",
"name": "conda_python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.8.12"
},
"vscode": {
"interpreter": {
"hash": "d2ca6edb7b84bab06ec39f802df7b8f7871770e31471df2cbe4279e0e7265b83"
}
}
},
"nbformat": 4,
"nbformat_minor": 4
}