{
"cells": [
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Notebook 1: Ingesting Data into the Feature Store\n",
"\n",
"Specify \"Python 3\" Kernel, \"Data Science\" Image."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
" 💡 Quick Start \n",
"This notebook will take ~10 minutes to run, so go ahead and click on \"Run\" in the toolbar, then \"Run All Cells\". This will run all the cells and begin to ingest data into SageMaker Feature Store which we'll need to call upon in the next few notebooks. As the cells are running, do look through the code and explanations as this will be the foundation for other notebooks.\n",
"
"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Background\n",
"\n",
"Amazon SageMaker Feature Store is a centralized store for features and associated metadata so features can be easily discovered and reused. You can create an online or an offline store. The online store is used for low latency real-time inference use cases, and the offline store is used for training and batch inference.\n",
"\n",
"The online store is primarily designed for supporting real-time predictions that need low millisecond latency reads and high throughput writes. Offline store is primarily intended for batch predictions and model training. Offline store is an append only store and can be used to store and access historical feature data. The offline store can help you store and serve features for exploration and model training. The online store retains only the latest feature data. Feature Group definitions are immutable after they are created.\n",
"\n",
"There are 5 sets of data about our online grocery use case. Each dataset will have its own Feature Group in SageMaker Feature Store, as described in the image below:\n",
"\n",
"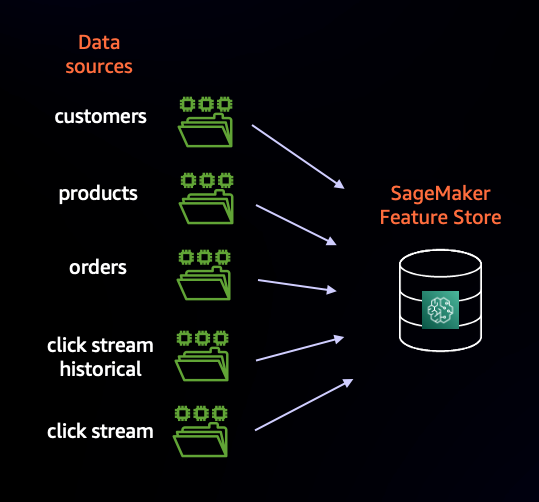\n",
"\n",
"We'll be using most Feature Groups to get our data to train our recommendation engine models as well as capture click stream data to influence real-time predictions.\n",
"\n",
"The `click stream historical` Feature Group will be used to initially train our ranking model. As we'll see in later notebooks, the `click stream` Feature Group will be populated by incoming data being streamed via Amazon Kinesis Data Streams (simulating a user interacting with the e-commerce website) and this data will directly influence our recommendation at the time of inference."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Imports"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"import sagemaker\n",
"from sagemaker.feature_store.feature_group import FeatureGroup\n",
"import boto3\n",
"import json\n",
"import pandas as pd\n",
"from time import gmtime, strftime, time\n",
"import time\n",
"from parameter_store import ParameterStore\n",
"from utils import *\n",
"from IPython.core.display import HTML"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Session variables"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"role = sagemaker.get_execution_role()\n",
"sagemaker_session = sagemaker.Session()\n",
"default_bucket = sagemaker_session.default_bucket()\n",
"region = sagemaker_session.boto_region_name\n",
"s3_client = boto3.client('s3', region_name=region)\n",
"\n",
"# ParameterStore is a custom utility to save local variable values\n",
"# for use across all notebooks\n",
"ps = ParameterStore(verbose=False)\n",
"ps.set_namespace('feature-store-workshop')"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"prefix = 'recsys-feature-store'\n",
"\n",
"# Feature Store variables\n",
"fs_prefix = 'recsys-'\n",
"current_timestamp = strftime('%m-%d-%H-%M', gmtime())\n",
"customers_feature_group_name = f'{fs_prefix}customers-fg-{current_timestamp}'\n",
"products_feature_group_name = f'{fs_prefix}products-fg-{current_timestamp}'\n",
"orders_feature_group_name = f'{fs_prefix}orders-fg-{current_timestamp}'\n",
"click_stream_historical_feature_group_name = f'{fs_prefix}click-stream-historical-fg-{current_timestamp}'\n",
"click_stream_feature_group_name = f'{fs_prefix}click-stream-fg-{current_timestamp}'\n",
"\n",
"ps.create({'customers_feature_group_name': customers_feature_group_name,\n",
" 'products_feature_group_name': products_feature_group_name,\n",
" 'orders_feature_group_name': orders_feature_group_name,\n",
" 'click_stream_historical_feature_group_name': click_stream_historical_feature_group_name,\n",
" 'click_stream_feature_group_name': click_stream_feature_group_name})"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"print(f'Using SageMaker version: {sagemaker.__version__}')\n",
"print(f'Using SageMaker Role: {role}')\n",
"print(f'Using S3 Bucket: {default_bucket}')"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"print('Feature groups names:\\n')\n",
"print(customers_feature_group_name)\n",
"print(products_feature_group_name)\n",
"print(orders_feature_group_name)\n",
"print(click_stream_historical_feature_group_name)\n",
"print(click_stream_feature_group_name)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Load and explore datasets"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Customers dataset"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"df_customers = pd.read_csv('data/customers.csv')\n",
"df_customers.head()"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Products dataset"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"df_products = pd.read_csv('data/products.csv')\n",
"df_products.head()"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Orders dataset"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"df_orders = pd.read_csv('data/orders.csv')\n",
"df_orders.head()"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Click stream historical dataset"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"df_click_stream_historical = pd.read_csv('data/click_stream_historical.csv')\n",
"df_click_stream_historical.head()"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Click stream"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Read a sample in order to have a schema for Feature Group creation\n",
"df_click_stream = pd.read_csv('data/click_stream.csv')\n",
"df_click_stream.head()"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Create feature definitions and feature groups"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"In order to create a Feature Group, you must first create a Feature Definition. A Feature Definition is a schema that describes your data's columns and data types. We'll be inferring this information from the Pandas dataframe itself.\n",
"\n",
"A Feature Group is the main Feature Store resource that contains the metadata for all the data stored in Amazon SageMaker Feature Store. A feature group is a logical grouping of features, defined in the feature store, to describe records. A feature group’s definition is composed of a list of feature definitions, a record identifier name, and configurations for its online and offline store. For our purposes, we'll be using both online and offline stores for our Feature Groups.\n",
"\n",
"For more information, see [Feature Store Concepts](https://docs.aws.amazon.com/sagemaker/latest/dg/feature-store-getting-started.html#feature-store-concepts) and [these docs](https://docs.aws.amazon.com/sagemaker/latest/dg/feature-store-create-feature-group.html)."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"customers_feature_group = create_feature_group(df_customers, customers_feature_group_name,\n",
" 'customer_id', prefix, sagemaker_session)\n",
"products_feature_group = create_feature_group(df_products, products_feature_group_name, 'product_id',\n",
" prefix, sagemaker_session)\n",
"orders_feature_group = create_feature_group(df_orders, orders_feature_group_name, 'order_id', prefix,\n",
" sagemaker_session)\n",
"click_stream_historical_feature_group = create_feature_group(df_click_stream_historical,\n",
" click_stream_historical_feature_group_name,\n",
" 'click_stream_id', prefix, sagemaker_session)\n",
"click_stream_feature_group = create_feature_group(df_click_stream, click_stream_feature_group_name, 'customer_id',\n",
" prefix, sagemaker_session)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"When feature data is ingested and updated, Feature Store stores historical data for all features in the offline store, whose data is located in S3. You can actually query this offline data using Athena so long as you have the Feature Group's AWS Glue Data Catalog table name. Fortunately, this table name is stored in the metadata for each Feature Group.\n",
"\n",
"Let's go ahead and store our Feature Group table names for later use."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"customers_table = get_feature_group_table_name(customers_feature_group)\n",
"products_table = get_feature_group_table_name(products_feature_group)\n",
"orders_table = get_feature_group_table_name(orders_feature_group)\n",
"click_stream_historical_table = get_feature_group_table_name(click_stream_historical_feature_group)\n",
"click_stream_table = get_feature_group_table_name(click_stream_feature_group)\n",
"\n",
"# Store table names locally to be used in other notebooks\n",
"ps.add({'customers_table': customers_table,\n",
" 'products_table': products_table,\n",
" 'orders_table': orders_table,\n",
" 'click_stream_historical_table': click_stream_historical_table,\n",
" 'click_stream_table': click_stream_table})"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Ingest data into feature groups"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Now let's take the data from our Pandas dataframes and ingest them into the Feature Groups we created above."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"ingest_data_into_feature_group(df_customers, customers_feature_group)\n",
"customers_count = df_customers.shape[0]\n",
"\n",
"ingest_data_into_feature_group(df_products, products_feature_group)\n",
"products_count = df_products.shape[0]\n",
"\n",
"ingest_data_into_feature_group(df_orders, orders_feature_group)\n",
"orders_count = df_orders.shape[0]\n",
"\n",
"ingest_data_into_feature_group(df_click_stream_historical, click_stream_historical_feature_group)\n",
"click_stream_historical_count = df_click_stream_historical.shape[0]\n",
"\n",
"# Add Feature Group counts for later use\n",
"ps.add({'customers_count': customers_count,\n",
" 'products_count': products_count,\n",
" 'orders_count': orders_count,\n",
" 'click_stream_historical_count': click_stream_historical_count,\n",
" 'click_stream_count': 0})"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"This ingestion process is using parallelism but will still take a few minutes for our data to be ingested into each respective Feature Group."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
" 💡 Feature Store Ingestion \n",
"In the above code, we were waiting on data to ingest to the online store. When we ingest data into a Feature Group that has the online store enabled, it first gets ingested into the online store so that it can be used in a real-time setting. That ingested data then automatically syncs to the offline store, a process that takes anywhere from 5 to 10 minutes. Below, we're waiting on that data to be written to the offline store so that we can use it in the next notebook.\n",
"
"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"wait_for_offline_data(customers_feature_group_name, df_customers, sagemaker_session)\n",
"wait_for_offline_data(products_feature_group_name, df_products, sagemaker_session)\n",
"wait_for_offline_data(orders_feature_group_name, df_orders, sagemaker_session)\n",
"wait_for_offline_data(click_stream_historical_feature_group_name, df_click_stream_historical, sagemaker_session)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"If you click on the link below, you can actually see where this offline data is stored for each Feature Group."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"account_id = default_bucket.split('-')[-1]\n",
"offline_store_url = f'https://s3.console.aws.amazon.com/s3/buckets/{default_bucket}?region={region}&prefix={prefix}/{account_id}/sagemaker/{region}/offline-store/&showversions=false'\n",
"display(HTML(f\"Offline Feature Store S3 Link\"))"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Save all our local params\n",
"ps.store()"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Go back to Workshop Studio and click on \"Next\"."
]
}
],
"metadata": {
"instance_type": "ml.m5.4xlarge",
"interpreter": {
"hash": "fea7262dfaa662dc7ea8f1b256cf975fd886d2f868152164ef15877318a1e322"
},
"kernelspec": {
"display_name": "Python 3 (Data Science)",
"language": "python",
"name": "python3__SAGEMAKER_INTERNAL__arn:aws:sagemaker:us-west-2:236514542706:image/datascience-1.0"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.7.10"
}
},
"nbformat": 4,
"nbformat_minor": 4
}