{
"cells": [
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Amazon SageMaker Asynchronous Inference\n",
"_**A new near real-time Inference option for generating machine learning model predictions**_"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"**Table of Contents**\n",
"\n",
"* [Background](#background)\n",
"* [Notebook Scope](#scope)\n",
"* [Overview and sample end to end flow](#overview)\n",
"* [Section 1 - Setup](#setup) \n",
" * [Create Model](#createmodel)\n",
" * [Create EndpointConfig](#endpoint-config)\n",
" * [Create Endpoint](#create-endpoint)\n",
" * [Setup AutoScaling policy (Optional)](#setup-autoscaling)\n",
"* [Section 2 - Using the Endpoint](#endpoint) \n",
" * [Invoke Endpoint](#invoke-endpoint)\n",
" * [Check Output Location](#check-output)\n",
" * [Multiple Invocations](#multiple-invoke) \n",
"* [Section 3 - Clean up](#clean)\n",
"\n",
"### Background \n",
"Amazon SageMaker Asynchronous Inference is a new capability in SageMaker that queues incoming requests and processes them asynchronously. SageMaker currently offers two inference options for customers to deploy machine learning models: 1) a real-time option for low-latency workloads 2) Batch transform, an offline option to process inference requests on batches of data available upfront. Real-time inference is suited for workloads with payload sizes of less than 6 MB and require inference requests to be processed within 60 seconds. Batch transform is suitable for offline inference on batches of data. \n",
"\n",
"Asynchronous inference is a new inference option for near real-time inference needs. Requests can take up to 15 minutes to process and have payload sizes of up to 1 GB. Asynchronous inference is suitable for workloads that do not have sub-second latency requirements and have relaxed latency requirements. For example, you might need to process an inference on a large image of several MBs within 5 minutes. In addition, asynchronous inference endpoints let you control costs by scaling down endpoints instance count to zero when they are idle, so you only pay when your endpoints are processing requests. \n",
"\n",
"### Notebook scope \n",
"This notebook provides an introduction to the SageMaker Asynchronous inference capability. This notebook will cover the steps required to create an asynchronous inference endpoint and test it with some sample requests. \n",
"\n",
"### Overview and sample end to end flow \n",
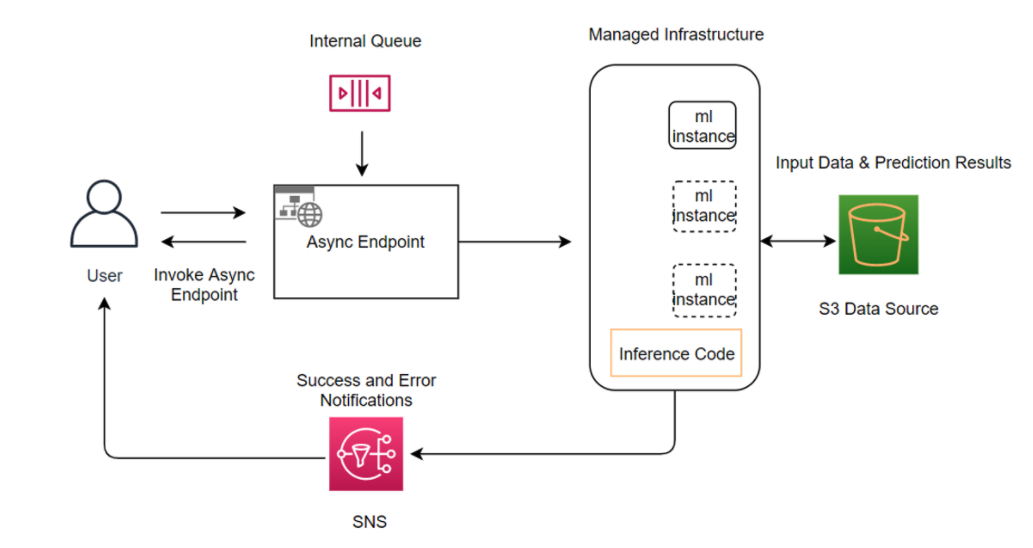
"Asynchronous inference endpoints have many similarities (and some key differences) compared to real-time endpoints. The process to create asynchronous endpoints is similar to real-time endpoints. You need to create: a model, an endpoint configuration, and then an endpoint. However, there are specific configuration parameters specific to asynchronous inference endpoints which we will explore below. \n",
"\n",
"Invocation of asynchronous endpoints differ from real-time endpoints. Rather than pass request payload inline with the request, you upload the payload to Amazon S3 and pass an Amazon S3 URI as a part of the request. Upon receiving the request, SageMaker provides you with a token with the output location where the result will be placed once processed. Internally, SageMaker maintains a queue with these requests and processes them. During endpoint creation, you can optionally specify an Amazon SNS topic to receive success or error notifications. Once you receive the notification that your inference request has been successfully processed, you can access the result in the output Amazon S3 location. \n",
"\n",
"The diagram below provides a visual overview of the end-to-end flow with Asynchronous inference endpoint."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
""
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Dataset"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"We're about to work with the [Titanic dataset](https://www.openml.org/d/40945)[1]. From the dataset documentation:\n",
"\n",
"> The original Titanic dataset, describing the survival status of individual passengers on the Titanic. The titanic data does not contain information from the crew, but it does contain actual ages of half of the passengers. The principal source for data about Titanic passengers is the Encyclopedia Titanica. The datasets used here were begun by a variety of researchers. One of the original sources is Eaton & Haas (1994) Titanic: Triumph and Tragedy, Patrick Stephens Ltd, which includes a passenger list created by many researchers and edited by Michael A. Findlay.\n",
">\n",
"> Thomas Cason of UVa has greatly updated and improved the Titanic data frame using the Encyclopedia Titanica and created the dataset here. Some duplicate passengers have been dropped, many errors corrected, many missing ages filled in, and new variables created.\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"---\n",
"## 1. Setup "
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"First we ensure we have an updated version of boto3, which includes the latest SageMaker features:"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Import the required python libraries:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"!python -m pip install --upgrade pip --quiet\n",
"!pip install -U awscli --quiet"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"import sagemaker\n",
"import boto3\n",
"from time import gmtime, strftime\n",
"from datetime import datetime\n",
"\n",
"boto_session = boto3.session.Session()\n",
"sm_session = sagemaker.session.Session()\n",
"sm_client = boto_session.client(\"sagemaker\")\n",
"sm_runtime = boto_session.client(\"sagemaker-runtime\")\n",
"region = boto_session.region_name"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Specify your IAM role. Go the AWS IAM console (https://console.aws.amazon.com/iam/home) and add the following policies to your IAM Role:\n",
"\n",
" * SageMakerFullAccessPolicy\n",
"\n",
"\n",
" * (Optional) Amazon SNS access: Add `sns:Publish` on the topics you define. Apply this if you plan to use Amazon SNS to receive notifications.\n",
"\n",
"```json\n",
"{\n",
" \"Version\": \"2012-10-17\",\n",
" \"Statement\": [\n",
" {\n",
" \"Action\": [\n",
" \"sns:Publish\"\n",
" ],\n",
" \"Effect\": \"Allow\",\n",
" \"Resource\": \"arn:aws:sns:::\"\n",
" }\n",
" ]\n",
"}\n",
"```\n",
"\n",
"* (Optional) KMS decrypt, encrypt if your Amazon S3 bucket is encrypte."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Download the Input files and model from S3 bucket\n",
"!aws s3 cp --recursive s3://sagemaker-sample-files/models/async-inference/input-files/ input/\n",
"!aws s3 cp s3://sagemaker-sample-files/models/async-inference/demo-xgboost-model.tar.gz model/"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Specify your SageMaker IAM Role (`sm_role`) and Amazon S3 bucket (`s3_bucket`). You can optionally use a default SageMaker Session IAM Role and Amazon S3 bucket. Make sure the role you use has the necessary permissions for SageMaker, Amazon S3, and optionally Amazon SNS."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"sm_role = sagemaker.get_execution_role()\n",
"# Feel free to use your own role here\n",
"# sm_role = \"arn:aws:iam::123456789012:role/sagemaker-custom-role\"\n",
"print(f\"Using Role: {sm_role}\")\n",
"s3_bucket = sm_session.default_bucket()\n",
"print(f\"Will use bucket '{s3_bucket}' for storing all resources related to this notebook\")"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"bucket_prefix = \"async-inference-demo\"\n",
"resource_name = \"AsyncInferenceDemo-{}-{}\""
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Next, you will create a model with `CreateModel`, an endpoint configuration with `CreateEndpointConfig`, and then an endpoint with the `CreateEndpoint` API.\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### 1.1 Create Model \n",
"Specify the location of the pre-trained model stored in Amazon S3. This example uses a pre-trained XGBoost model name demo-xgboost-model.tar.gz. The full Amazon S3 URI is stored in a string variable `model_url`. "
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"model_s3_key = f\"{bucket_prefix}/demo-xgboost-model.tar.gz\"\n",
"model_url = f\"s3://{s3_bucket}/{model_s3_key}\"\n",
"print(f\"Uploading Model to {model_url}\")\n",
"\n",
"with open(\"model/demo-xgboost-model.tar.gz\", \"rb\") as model_file:\n",
" boto_session.resource(\"s3\").Bucket(s3_bucket).Object(model_s3_key).upload_fileobj(model_file)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Specify a primary container. For the primary container, you specify the Docker image that contains inference code, artifacts (from prior training), and a custom environment map that the inference code uses when you deploy the model for predictions. In this example, we specify an XGBoost built-in algorithm container image."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"from sagemaker import image_uris\n",
"\n",
"# Specify an AWS container image and region as desired\n",
"container = image_uris.retrieve(region=region, framework=\"xgboost\", version=\"0.90-1\")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Create a model by specifying the `ModelName`, the `ExecutionRoleARN` (the ARN of the IAM role that Amazon SageMaker can assume to access model artifacts/ docker images for deployment), and the `PrimaryContainer`."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"model_name = resource_name.format(\"Model\", datetime.now().strftime(\"%Y-%m-%d-%H-%M-%S\"))\n",
"create_model_response = sm_client.create_model(\n",
" ModelName=model_name,\n",
" ExecutionRoleArn=sm_role,\n",
" PrimaryContainer={\n",
" \"Image\": container,\n",
" \"ModelDataUrl\": model_url,\n",
" },\n",
")\n",
"\n",
"print(f\"Created Model: {create_model_response['ModelArn']}\")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### 1.2 Create EndpointConfig "
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Once you have a model, create an endpoint configuration with `CreateEndpointConfig`. Amazon SageMaker hosting services uses this configuration to deploy models. In the configuration, you identify one or more model that were created using with `CreateModel` API, to deploy the resources that you want Amazon SageMaker to provision. Specify the `AsyncInferenceConfig` object and provide an output Amazon S3 location for `OutputConfig`. You can optionally specify Amazon SNS topics on which to send notifications about prediction results."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"endpoint_config_name = resource_name.format(\n",
" \"EndpointConfig\", datetime.now().strftime(\"%Y-%m-%d-%H-%M-%S\")\n",
")\n",
"create_endpoint_config_response = sm_client.create_endpoint_config(\n",
" EndpointConfigName=endpoint_config_name,\n",
" ProductionVariants=[\n",
" {\n",
" \"VariantName\": \"variant1\",\n",
" \"ModelName\": model_name,\n",
" \"InstanceType\": \"ml.m5.xlarge\",\n",
" \"InitialInstanceCount\": 1,\n",
" }\n",
" ],\n",
" AsyncInferenceConfig={\n",
" \"OutputConfig\": {\n",
" \"S3OutputPath\": f\"s3://{s3_bucket}/{bucket_prefix}/output\",\n",
" # Optionally specify Amazon SNS topics\n",
" # \"NotificationConfig\": {\n",
" # \"SuccessTopic\": \"arn:aws:sns:::\",\n",
" # \"ErrorTopic\": \"arn:aws:sns:::\",\n",
" # }\n",
" },\n",
" \"ClientConfig\": {\"MaxConcurrentInvocationsPerInstance\": 4},\n",
" },\n",
")\n",
"print(f\"Created EndpointConfig: {create_endpoint_config_response['EndpointConfigArn']}\")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### 1.3 Create Endpoint "
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Once you have your model and endpoint configuration, use the `CreateEndpoint` API to create your endpoint. The endpoint name must be unique within an AWS Region in your AWS account."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"endpoint_name = resource_name.format(\"Endpoint\", datetime.now().strftime(\"%Y-%m-%d-%H-%M-%S\"))\n",
"\n",
"create_endpoint_response = sm_client.create_endpoint(\n",
" EndpointName=endpoint_name, EndpointConfigName=endpoint_config_name\n",
")\n",
"print(f\"Created Endpoint: {create_endpoint_response['EndpointArn']}\")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Validate that the endpoint is created before invoking it:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"waiter = sm_client.get_waiter(\"endpoint_in_service\")\n",
"print(\"Waiting for endpoint to create...\")\n",
"waiter.wait(EndpointName=endpoint_name)\n",
"resp = sm_client.describe_endpoint(EndpointName=endpoint_name)\n",
"print(f\"Endpoint Status: {resp['EndpointStatus']}\")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### 1.4 Setup AutoScaling policy (Optional) "
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"This section describes how to configure autoscaling on your asynchronous endpoint using Application Autoscaling. You need to first register your endpoint variant with Application Autoscaling, define a scaling policy, and then apply the scaling policy. In this configuration, we use a custom metric, `CustomizedMetricSpecification`, called `ApproximateBacklogSizePerInstance`. Please refer to the SageMaker Developer guide for a detailed list of metrics available with your asynchronous inference endpoint."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"client = boto3.client(\n",
" \"application-autoscaling\"\n",
") # Common class representing Application Auto Scaling for SageMaker amongst other services\n",
"\n",
"resource_id = (\n",
" \"endpoint/\" + endpoint_name + \"/variant/\" + \"variant1\"\n",
") # This is the format in which application autoscaling references the endpoint\n",
"\n",
"# Configure Autoscaling on asynchronous endpoint down to zero instances\n",
"response = client.register_scalable_target(\n",
" ServiceNamespace=\"sagemaker\",\n",
" ResourceId=resource_id,\n",
" ScalableDimension=\"sagemaker:variant:DesiredInstanceCount\",\n",
" MinCapacity=0,\n",
" MaxCapacity=5,\n",
")\n",
"\n",
"response = client.put_scaling_policy(\n",
" PolicyName=\"Invocations-ScalingPolicy\",\n",
" ServiceNamespace=\"sagemaker\", # The namespace of the AWS service that provides the resource.\n",
" ResourceId=resource_id, # Endpoint name\n",
" ScalableDimension=\"sagemaker:variant:DesiredInstanceCount\", # SageMaker supports only Instance Count\n",
" PolicyType=\"TargetTrackingScaling\", # 'StepScaling'|'TargetTrackingScaling'\n",
" TargetTrackingScalingPolicyConfiguration={\n",
" \"TargetValue\": 5.0, # The target value for the metric. - here the metric is - SageMakerVariantInvocationsPerInstance\n",
" \"CustomizedMetricSpecification\": {\n",
" \"MetricName\": \"ApproximateBacklogSizePerInstance\",\n",
" \"Namespace\": \"AWS/SageMaker\",\n",
" \"Dimensions\": [{\"Name\": \"EndpointName\", \"Value\": endpoint_name}],\n",
" \"Statistic\": \"Average\",\n",
" },\n",
" \"ScaleInCooldown\": 600, # The cooldown period helps you prevent your Auto Scaling group from launching or terminating\n",
" # additional instances before the effects of previous activities are visible.\n",
" # You can configure the length of time based on your instance startup time or other application needs.\n",
" # ScaleInCooldown - The amount of time, in seconds, after a scale in activity completes before another scale in activity can start.\n",
" \"ScaleOutCooldown\": 300 # ScaleOutCooldown - The amount of time, in seconds, after a scale out activity completes before another scale out activity can start.\n",
" # 'DisableScaleIn': True|False - ndicates whether scale in by the target tracking policy is disabled.\n",
" # If the value is true , scale in is disabled and the target tracking policy won't remove capacity from the scalable resource.\n",
" },\n",
")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"The endpoint is now ready for invocation."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"--- \n",
"## 2. Using the Endpoint \n",
"\n",
"### 2.1 Uploading the Request Payload "
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"First, you need to upload the request to Amazon S3. We define a function called, `upload_file`, to make it easier to make multiple invocations in a later step."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"import os\n",
"\n",
"\n",
"def upload_file(input_location):\n",
" prefix = f\"{bucket_prefix}/input\"\n",
" return sm_session.upload_data(\n",
" input_location,\n",
" bucket=sm_session.default_bucket(),\n",
" key_prefix=prefix,\n",
" extra_args={\"ContentType\": \"text/libsvm\"},\n",
" )"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"input_1_location = \"input/test_point_0.libsvm\"\n",
"input_1_s3_location = upload_file(input_1_location)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### 2.1 Invoke Endpoint "
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Get inferences from the model hosted at your asynchronous endpoint with `InvokeEndpointAsync`. Specify the location of your inference data in the `InputLocation` field and the name of your endpoint for `EndpointName`. The response payload contains the output Amazon S3 location where the result will be placed. "
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"response = sm_runtime.invoke_endpoint_async(\n",
" EndpointName=endpoint_name, InputLocation=input_1_s3_location\n",
")\n",
"output_location = response[\"OutputLocation\"]\n",
"print(f\"OutputLocation: {output_location}\")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### 2.2 Check Output Location "
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Check the output location to see if the inference has been processed. We make multiple requests (beginning of the `while True` statement in the `get_output` function) every two seconds until there is an output of the inference request: "
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"import urllib, time\n",
"from botocore.exceptions import ClientError\n",
"\n",
"\n",
"def get_output(output_location):\n",
" output_url = urllib.parse.urlparse(output_location)\n",
" bucket = output_url.netloc\n",
" key = output_url.path[1:]\n",
" while True:\n",
" try:\n",
" return sm_session.read_s3_file(bucket=output_url.netloc, key_prefix=output_url.path[1:])\n",
" except ClientError as e:\n",
" if e.response[\"Error\"][\"Code\"] == \"NoSuchKey\":\n",
" print(\"waiting for output...\")\n",
" time.sleep(2)\n",
" continue\n",
" raise"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"output = get_output(output_location)\n",
"print(f\"Output: {output}\")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### 2.3 Multiple Invocations "
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"The following shows how you can invoke the endpoint with multiple requests:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"inferences = []\n",
"for i in range(25):\n",
" input_file = f\"input/test_point_{i}.libsvm\"\n",
" input_file_s3_location = upload_file(input_file)\n",
" print(f\"Invoking Endpoint with {input_file}\")\n",
" response = sm_runtime.invoke_endpoint_async(\n",
" EndpointName=endpoint_name, InputLocation=input_file_s3_location\n",
" )\n",
" output_location = response[\"OutputLocation\"]\n",
" inferences += [(input_file, output_location)]\n",
" time.sleep(0.5)\n",
"\n",
"for input_file, output_location in inferences:\n",
" output = get_output(output_location)\n",
" print(f\"Input File: {input_file}, Output: {output}\")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### 3. Clean up "
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"If you enabled auto-scaling for your endpoint, ensure you deregister the endpoint as a scalable target before deleting the endpoint. To do this, run the following:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"\n",
"# response = client.deregister_scalable_target(\n",
"# ServiceNamespace=\"sagemaker\",\n",
"# ResourceId=resource_id,\n",
"# ScalableDimension=\"sagemaker:variant:DesiredInstanceCount\",\n",
"# )"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Remember to delete your endpoint after use as you will be charged for the instances used in this Demo. "
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# sm_client.delete_endpoint(EndpointName=endpoint_name)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"You may also want to delete any other resources you might have created such as SNS topics, S3 objects, etc."
]
}
],
"metadata": {
"instance_type": "ml.t3.medium",
"kernelspec": {
"display_name": "Python 3 (Data Science)",
"language": "python",
"name": "python3__SAGEMAKER_INTERNAL__arn:aws:sagemaker:us-west-2:236514542706:image/datascience-1.0"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.7.10"
}
},
"nbformat": 4,
"nbformat_minor": 4
}