{
"cells": [
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Lab 1-2: Train Hugging Face Transformers on Amazon SageMaker\n",
"\n",
"### Multi-Class Classification with Naver Movie dataset and Hugging Face `Trainer` \n",
"---"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Introduction\n",
"---\n",
"\n",
"바로 이전 모듈에서 기존에 온프레미스에서 개발했던 환경과 동일한 환경으로 모델을 빌드하고 훈련했습니다. 하지만 아래와 같은 상황들에서도 기존 환경을 사용하는 것이 바람직할까요?\n",
"\n",
"- 온프레미스의 GPU는 총 1장으로 훈련 시간이 너무 오래 소요됨\n",
"- 가용 서버 대수가 2대인데 10개의 딥러닝 모델을 동시에 훈련해야 함\n",
"- 필요한 상황에만 GPU를 활용 \n",
"- 기타 등등\n",
"\n",
"Amazon SageMaker는 **데이터 과학자들 및 머신 러닝 엔지니어들을 위한 완전 관리형 머신 러닝 서비스**로 훈련 및 추론 수행 시 인프라 설정에 대한 추가 작업이 필요하지 있기에, 단일 GPU 기반의 딥러닝 훈련을 포함한 멀티 GPU 및 멀티 인스턴스 분산 훈련을 보다 쉽고 빠르게 수행할 수 있습니다. SageMaker는 다양한 유즈케이스들에 적합한 예제들을 지속적으로 업데이트하고 있으며, 한국어 세션 및 자료들도 제공되고 있습니다.\n",
"\n",
"_**Note**_\n",
"- 이미 기본적인 Hugging Face 용법 및 자연어 처리에 익숙하신 분들은 앞 모듈을 생략하고 이 모듈부터 핸즈온을 시작하셔도 됩니다.\n",
"- 이 노트북은 SageMaker 기본 API를 참조하므로, SageMaker Studio, SageMaker 노트북 인스턴스 또는 AWS CLI가 설정된 로컬 시스템에서 실행해야 합니다. SageMaker Studio 또는 SageMaker 노트북 인스턴스를 사용하는 경우 PyTorch 기반 커널을 선택하세요.\n",
"- 훈련 job 수행 시 최소 `ml.p3.2xlarge` 이상의 훈련 인스턴스가 필요하며, `ml.p3.8xlarge`나 `ml.p3.16xlarge` 인스턴스를 권장합니다. 만약 인스턴스 사용에 제한이 걸려 있다면 [Request a service quota increase for SageMaker resources](https://docs.aws.amazon.com/sagemaker/latest/dg/regions-quotas.html#service-limit-increase-request-procedure)를 참조하여 인스턴스 제한을 해제해 주세요.\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Development Environment and Permissions "
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Installation\n",
"\n",
"이 예제 노트북은 **SageMaker Python SDK v2.70.0** 이상과 **transformers v4.11.0** 이상이 필요합니다.\n",
"\n",
"이 노트북을 처음 실행하신다면, 아래 코드 셀에서 `install_needed = True`로 변경 후, 코드 셀을 실행하세요. 패키지 인스톨 이후 노트북 커널이 재시작되며, `install_needed = False`로 변경 후, 코드 셀을 다시 실행합니다. 이 작업은 한 번만 수행하면 됩니다."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"%load_ext autoreload\n",
"%autoreload 2\n",
"import sys\n",
"import IPython\n",
"\n",
"#install_needed = True\n",
"install_needed = False\n",
"\n",
"if install_needed:\n",
" print(\"===> Installing deps and restarting kernel. Please change 'install_needed = False' and run this code cell again.\")\n",
" !{sys.executable} -m pip install -U \"sagemaker>=2.70.0\" \"transformers>=4.11.0\" \"s3fs\"\n",
" IPython.Application.instance().kernel.do_shutdown(True)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"import boto3\n",
"import sagemaker\n",
"import sagemaker.huggingface\n",
"\n",
"sess = sagemaker.Session()\n",
"# sagemaker session bucket -> used for uploading data, models and logs\n",
"# sagemaker will automatically create this bucket if it not exists\n",
"sagemaker_session_bucket=None\n",
"if sagemaker_session_bucket is None and sess is not None:\n",
" # set to default bucket if a bucket name is not given\n",
" sagemaker_session_bucket = sess.default_bucket()\n",
"\n",
"role = sagemaker.get_execution_role()\n",
"region = boto3.Session().region_name\n",
"sess = sagemaker.Session(default_bucket=sagemaker_session_bucket)\n",
"\n",
"print(f\"sagemaker role arn: {role}\")\n",
"print(f\"sagemaker bucket: {sess.default_bucket()}\")\n",
"print(f\"sagemaker session region: {sess.boto_region_name}\")"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"import os\n",
"import sys\n",
"import logging\n",
"\n",
"logging.basicConfig(\n",
" level=logging.INFO, \n",
" format='[{%(filename)s:%(lineno)d} %(levelname)s - %(message)s',\n",
" handlers=[\n",
" logging.StreamHandler(sys.stdout)\n",
" ]\n",
")\n",
"logger = logging.getLogger(__name__)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"
\n",
"\n",
"## 1. Preparation\n",
"---"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"from datasets import load_dataset\n",
"from transformers import ElectraModel, ElectraTokenizer\n",
"\n",
"# Define the model repo\n",
"tokenizer_id = 'monologg/koelectra-small-v3-discriminator'\n",
"model_id = 'monologg/koelectra-small-v3-discriminator'\n",
"\n",
"# dataset used\n",
"dataset_name = 'nsmc'\n",
"\n",
"# s3 key prefix for the data\n",
"s3_prefix = 'samples/datasets/nsmc'"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Dataset\n",
"\n",
"본 핸즈온에서 사용할 말뭉치 데이터셋은 네이버 영화 리뷰 데이터(https://github.com/e9t/nsmc/) 공개 데이터셋으로 15만 건의 훈련 데이터와 5만 건의 테스트 데이터로 구성되어 있습니다. 이 데이터셋은 한국어 자연어 처리 모델 벤치마킹에 자주 사용됩니다.\n",
"\n",
"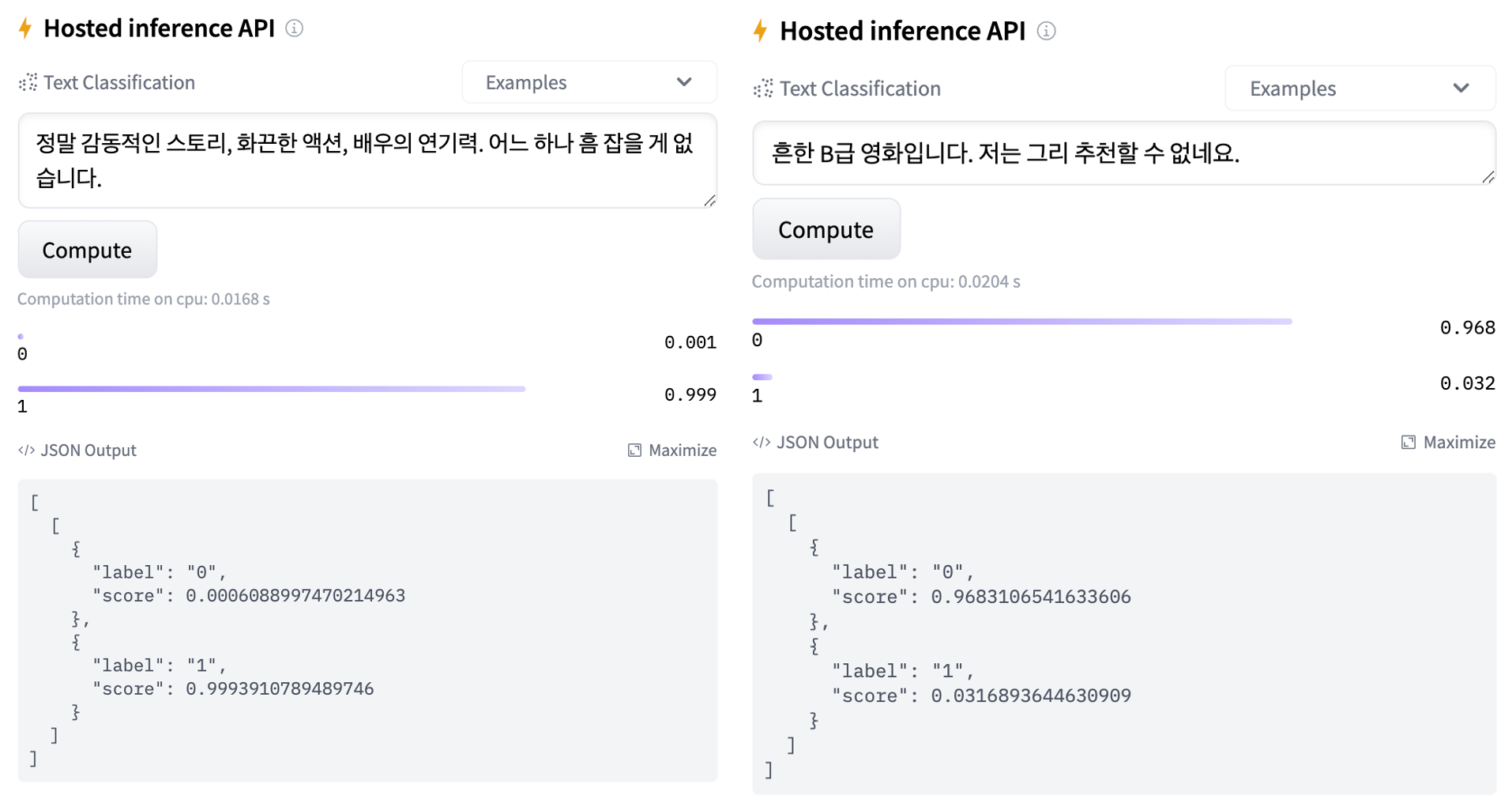"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# load dataset\n",
"train_dataset, test_dataset = load_dataset(dataset_name, split=['train', 'test'])\n",
"\n",
"# num_samples_for_debug = 2000\n",
"# train_dataset = train_dataset.shuffle(seed=42).select(range(num_samples_for_debug))\n",
"# test_dataset = test_dataset.shuffle(seed=42).select(range(num_samples_for_debug))\n",
"\n",
"logger.info(f\" loaded train_dataset length is: {len(train_dataset)}\")\n",
"logger.info(f\" loaded test_dataset length is: {len(test_dataset)}\")\n",
"logger.info(train_dataset[0])"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Tokenization\n",
"\n",
"자연어 처리 모델을 훈련하려면, 토큰화(Tokenization)를 통해 말뭉치(corpus; 자연어 처리를 위한 대량의 텍스트 데이터)를 토큰 시퀀스로 나누는 과정이 필요합니다. BERT 이전의 자연어 처리 모델은 주로 도메인 전문가들이 직접 토큰화해놓은 토크아니저(Mecab, Kkma 등)들을 사용했지만, BERT를 훈련하기 위한 토크나이저는 도메인 지식 필요 없이 말뭉치에서 자주 등장하는 서브워드(subword)를 토큰화합니다. GPT 기반 모델은 BPE(Byte-pair Encoding)라는 통계적 기법을 사용하며, BERT 및 ELECTRA 기반 모델은 BPE와 유사한 Wordpiece를 토크나이저로 사용합니다."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# download tokenizer\n",
"tokenizer = ElectraTokenizer.from_pretrained(tokenizer_id)\n",
"\n",
"# tokenizer helper function\n",
"def tokenize(batch):\n",
" return tokenizer(batch['document'], padding='max_length', truncation=True)\n",
"\n",
"# tokenize dataset\n",
"train_dataset = train_dataset.map(tokenize, batched=True)\n",
"test_dataset = test_dataset.map(tokenize, batched=True)\n",
"\n",
"# set format for pytorch\n",
"train_dataset.set_format('torch', columns=['input_ids', 'attention_mask', 'label'])\n",
"test_dataset.set_format('torch', columns=['input_ids', 'attention_mask', 'label'])"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Uploading data to Amazon S3 Bucket\n",
"\n",
"SageMaker 훈련을 위해 `FileSystem`를 사용하여 말뭉치 데이터셋을 S3로 업도르합니다. 자세한 내용은 https://huggingface.co/docs/datasets/filesystems.html 를 참조해 주세요."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": []
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"import botocore\n",
"from datasets.filesystems import S3FileSystem\n",
"\n",
"s3 = S3FileSystem() \n",
"\n",
"# save train_dataset to s3\n",
"training_input_path = f's3://{sess.default_bucket()}/{s3_prefix}/train'\n",
"train_dataset.save_to_disk(training_input_path, fs=s3)\n",
"\n",
"# save test_dataset to s3\n",
"test_input_path = f's3://{sess.default_bucket()}/{s3_prefix}/test'\n",
"test_dataset.save_to_disk(test_input_path, fs=s3)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"
\n",
"\n",
"## 2. Training with Native Hugging Face (PyTorch Framework)\n",
"\n",
"---\n",
"\n",
"### Overview and Training Script\n",
"\n",
"SageMaker에 대한 대표적인 오해가 여전히 많은 분들이 SageMaker 훈련을 위해 소스 코드를 전면적으로 수정해야 한다고 생각합니다. 하지만, 실제로는 별도의 소스 코드 수정 없이 기존 여러분이 사용했던 파이썬 스크립트에 SageMaker 훈련에 필요한 SageMaker 전용 환경 변수들만 추가하면 됩니다. \n",
"\n",
"SageMaker 훈련은 훈련 작업을 호출할 때, 1) 훈련 EC2 인스턴스 프로비저닝 - 2) 컨테이너 구동을 위한 도커 이미지 및 훈련 데이터 다운로드 - 3) 컨테이너 구동 - 4) 컨테이너 환경에서 훈련 수행 - 5) 컨테이너 환경에서 S3의 특정 버킷에 저장 - 6) 훈련 인스턴스 종료로 구성됩니다. 따라서, 훈련 수행 로직은 아래 예시와 같이 기존 개발 환경과 동일합니다.\n",
"\n",
"```python\n",
"/opt/conda/bin/python train.py --epochs 5 --train_batch_size 32 ...\n",
"```\n",
"\n",
"이 과정에서 컨테이너 환경에 필요한 환경 변수(예: 모델 경로, 훈련 데이터 경로) 들은 사전에 지정되어 있으며, 이 환경 변수들이 설정되어 있어야 훈련에 필요한 파일들의 경로를 인식할 수 있습니다. 대표적인 환경 변수들에 대한 자세한 내용은 https://github.com/aws/sagemaker-containers#important-environment-variables 을 참조하세요.\n",
"\n",
"이 과정을 다이어그램으로 나타내면 아래와 같습니다.\n",
"\n",
"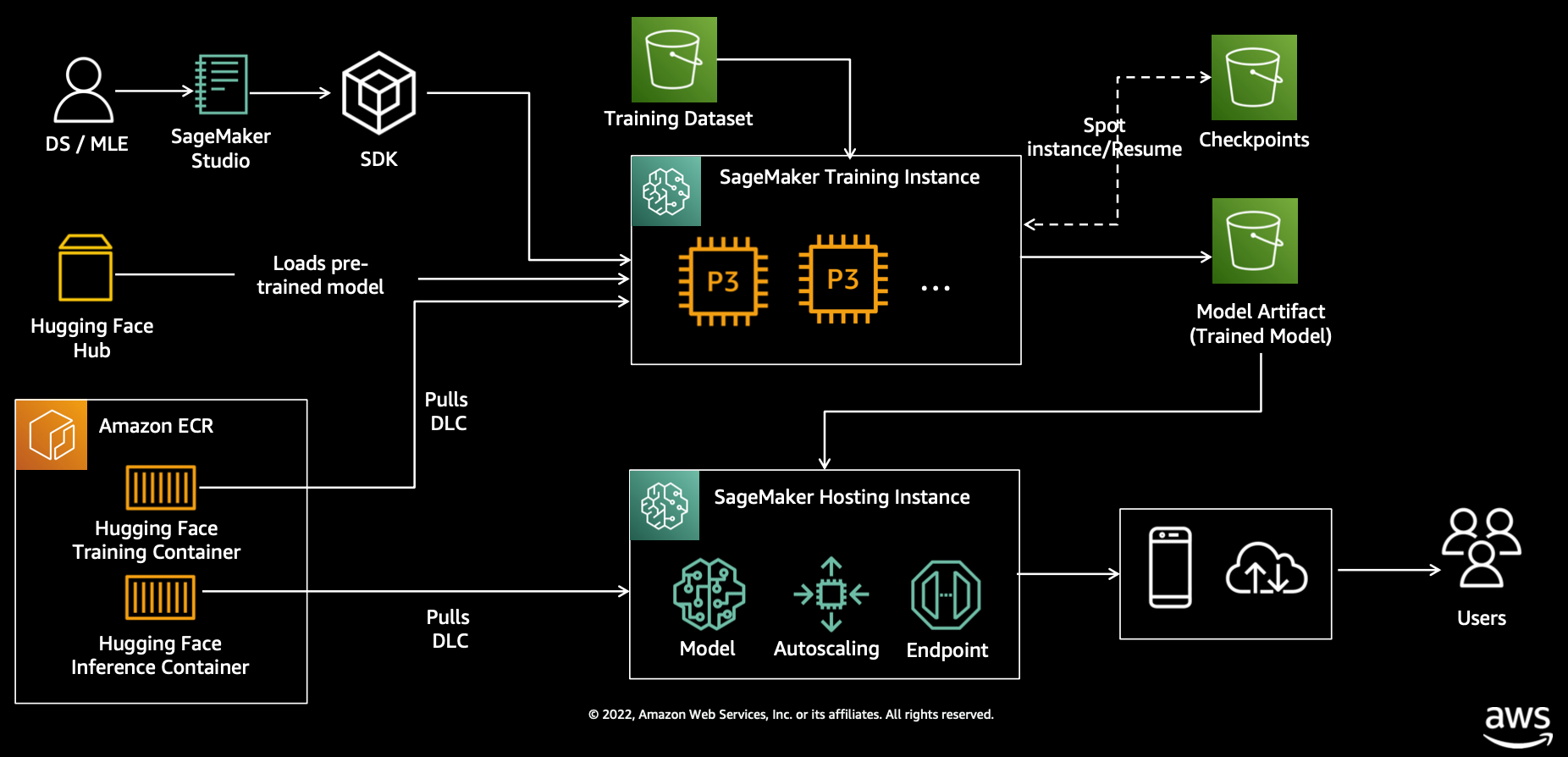\n",
"\n",
"또한, 핸즈온을 위해 미리 작성된 훈련 스크립트를 확인해 보세요. 종래 코드와 동일하다는 것을 알 수 있습니다."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# !pygmentize ./scripts/train.py"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"from sagemaker.huggingface import HuggingFace\n",
"import time\n",
"instance_type = 'ml.p3.8xlarge'\n",
"num_gpus = 4\n",
"instance_count = 1\n",
"batch_size_native = 32\n",
"learning_rate_native = float('5e-5')\n",
"batch_size = batch_size_native\n",
"learning_rate = learning_rate_native / batch_size_native * batch_size * num_gpus * instance_count\n",
"logger.info(learning_rate)\n",
"\n",
"# hyperparameters, which are passed into the training job\n",
"hyperparameters = {\n",
" 'n_gpus': num_gpus, # number of GPUs per instance\n",
" 'epochs': 3, # number of training epochs\n",
" 'seed': 42, # seed\n",
" 'train_batch_size': batch_size, # batch size for training\n",
" 'eval_batch_size': batch_size*2, # batch size for evaluation\n",
" 'warmup_steps': 0, # warmup steps\n",
" 'learning_rate': learning_rate, # learning rate used during training\n",
" 'tokenizer_id': model_id, # pre-trained tokenizer\n",
" 'model_id': model_id # pre-trained model\n",
"}"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# define Training Job Name \n",
"job_name = f'huggingface-native-pytorch-190-hol-{time.strftime(\"%Y-%m-%d-%H-%M-%S\", time.localtime())}'\n",
"chkpt_s3_path = f's3://{sess.default_bucket()}/{s3_prefix}/native/checkpoints'\n",
"\n",
"# create the Estimator\n",
"sm_estimator = HuggingFace(\n",
" entry_point = 'train.py', # fine-tuning script used in training jon\n",
" source_dir = './scripts', # directory where fine-tuning script is stored\n",
" instance_type = instance_type, # instances type used for the training job\n",
" instance_count = instance_count, # the number of instances used for training\n",
" base_job_name = job_name, # the name of the training job\n",
" role = role, # IAM role used in training job to access AWS ressources, e.g. S3\n",
" transformers_version = '4.11.0', # the transformers version used in the training job\n",
" pytorch_version = '1.9.0', # the pytorch_version version used in the training job\n",
" py_version = 'py38', # the python version used in the training job\n",
" hyperparameters = hyperparameters, # the hyperparameter used for running the training job\n",
" disable_profiler = True,\n",
" debugger_hook_config = False, \n",
" checkpoint_s3_uri = chkpt_s3_path,\n",
" checkpoint_local_path ='/opt/ml/checkpoints', \n",
")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"`fit()` 메소드를 호출하여 훈련 job을 시작합니다. `fit()` 메소드의 인자값 중 `wait=True`로 설정할 경우에는 동기(synchronous) 방식으로 동직하게 되며, `wait=False`일 경우에는 비동기(aynchronous) 방식으로 동작하여 여러 개의 훈련 job을 동시에 실행할 수 있습니다."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"scrolled": true
},
"outputs": [],
"source": [
"# define a data input dictonary with our uploaded s3 uris\n",
"data = {\n",
" 'train': training_input_path,\n",
" 'test': test_input_path\n",
"}\n",
"\n",
"# starting the train job with our uploaded datasets as input\n",
"sm_estimator.fit(data, wait=False)\n",
"train_job_name = sm_estimator.latest_training_job.job_name"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"
\n",
"\n",
"## 3. Training with Optimized Hugging Face (PyTorch Framework)\n",
"\n",
"---\n",
"\n",
"SageMaker Training Compiler는 별도의 추가 비용 없이 모델의 메모리 사용률을 감소시킴으로써(즉, 가용 미니배치 크기가 증가함으로써), GPU 인스턴스의 훈련 시간을 단축할 수 있는 신규 서비스입니다. SageMaker Training Compiler를 지원하는 AWS Deep Learning Containers(DLC)를 사용하면 코드 변경을 최소화하면서 `TrainingCompilerConfig()` 설정으로 단일 GPU부터 분산 훈련까지 편리하게 훈련 작업의 속도를 가속화할 수 있습니다.\n",
"\n",
"예를 들어, 아래 코드 셀에서 `batch_size`가 32에서 48로 변경되었습니다. Training Compiler를 적용하지 않는다면, GPU 메모리에 모델과 미니배치가 들어갈 수 없으므로 OOM(Out of Memory) 오류가 발생합니다.\n",
"\n",
"자세한 내용은 Amazon SageMaker 개발자 안내서의 SageMaker Training Compiler를 참조하세요.\n",
"\n",
"**Note: SageMaker Training Compiler 적용 시에는 추가 오버헤드를 피하기 위해 가급적 SageMaker Debugger 기능을 끄는 것을 권장합니다.**"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"from sagemaker.huggingface import HuggingFace, TrainingCompilerConfig\n",
"import time\n",
"instance_type = 'ml.p3.8xlarge'\n",
"num_gpus = 4\n",
"instance_count = 1\n",
"batch_size_native = 32\n",
"learning_rate_native = float('5e-5')\n",
"batch_size = 48\n",
"learning_rate = learning_rate_native / batch_size_native * batch_size * num_gpus * instance_count\n",
"\n",
"# hyperparameters, which are passed into the training job\n",
"hyperparameters = {\n",
" 'training_script': 'train.py', # training scripts\n",
" 'n_gpus': num_gpus, # number of GPUs per instance\n",
" 'epochs': 3, # number of training epochs\n",
" 'seed': 42, # seed\n",
" 'train_batch_size': batch_size, # batch size for training\n",
" 'eval_batch_size': batch_size*2, # batch size for evaluation\n",
" 'warmup_steps': 0, # warmup steps\n",
" 'learning_rate': learning_rate, # learning rate used during training\n",
" 'tokenizer_id': model_id, # pre-trained tokenizer\n",
" 'model_id': model_id # pre-trained model\n",
"}"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# define Training Job Name \n",
"job_name = f'huggingface-compiled-pytorch-190-hol-{time.strftime(\"%Y-%m-%d-%H-%M-%S\", time.localtime())}'\n",
"chkpt_s3_path = f's3://{sess.default_bucket()}/{s3_prefix}/compiler/checkpoints'\n",
"\n",
"# create the Estimator\n",
"sm_compiler_estimator = HuggingFace(\n",
" entry_point = 'distributed_training_launcher.py', \n",
" source_dir = './scripts', # directory where fine-tuning script is stored\n",
" instance_type = instance_type, # instances type used for the training job\n",
" instance_count = instance_count, # the number of instances used for training\n",
" base_job_name = job_name, # the name of the training job\n",
" role = role, # IAM role used in training job to access AWS ressources, e.g. S3\n",
" transformers_version = '4.11.0', # the transformers version used in the training job\n",
" pytorch_version = '1.9.0', # the pytorch_version version used in the training job\n",
" py_version = 'py38', # the python version used in the training job\n",
" hyperparameters = hyperparameters, # the hyperparameter used for running the training job,\n",
" compiler_config = TrainingCompilerConfig(),\n",
" disable_profiler = True,\n",
" debugger_hook_config = False,\n",
" checkpoint_s3_uri = chkpt_s3_path,\n",
" checkpoint_local_path= '/opt/ml/checkpoints' \n",
")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"`fit()` 메소드를 호출하여 훈련 job을 시작합니다. `fit()` 메소드의 인자값 중 `wait=True`로 설정할 경우에는 동기(synchronous) 방식으로 동직하게 되며, `wait=False`일 경우에는 비동기(aynchronous) 방식으로 동작하여 여러 개의 훈련 job을 동시에 실행할 수 있습니다."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# starting the train job with our uploaded datasets as input\n",
"sm_compiler_estimator.fit(data, wait=False)\n",
"compiler_train_job_name = sm_compiler_estimator.latest_training_job.job_name"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"train_job_name, compiler_train_job_name"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### View Training Job\n",
"SageMaker 콘솔 창에서 훈련 내역을 직접 확인할 수도 있지만, 아래 코드 셀에서 생성되는 링크를 클릭하면 더 편리하게 훈련 내역을 확인할 수 있습니다."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"from IPython.core.display import display, HTML\n",
"\n",
"def make_console_link(region, train_job_name, train_task='[Training]'):\n",
" train_job_link = f' {train_task} Review Training Job' \n",
" cloudwatch_link = f' {train_task} Review CloudWatch Logs'\n",
" return train_job_link, cloudwatch_link \n",
" \n",
"train_job_link, cloudwatch_link = make_console_link(region, train_job_name, '[Hugging Face Training - Native]')\n",
"compiler_train_job_link, compiler_cloudwatch_link = make_console_link(region, compiler_train_job_name, '[Hugging Face Training - Compiler]')\n",
"\n",
"display(HTML(train_job_link))\n",
"display(HTML(cloudwatch_link))\n",
"display(HTML(compiler_train_job_link))\n",
"display(HTML(compiler_cloudwatch_link))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Wait for the training jobs to complete\n",
"\n",
"훈련이 완료될 때까지 기다립니다. `estimator.fit(...)`에서 `wait=False`로 설정한 경우 아래 코드 셀의 주석을 해제 후 실행하여 동기 방식으로 변경할 수도 있습니다. 훈련 완료까지는 수십 분의 시간이 소요됩니다."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# sess.logs_for_job(job_name=train_job_name, wait=True)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"sess.logs_for_job(job_name=compiler_train_job_name, wait=True)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# waiter = sm_estimator.sagemaker_session.sagemaker_client.get_waiter(\n",
"# \"training_job_completed_or_stopped\"\n",
"# )\n",
"# waiter.wait(TrainingJobName=train_job_name)\n",
"# waiter2 = sm_compiler_estimator.sagemaker_session.sagemaker_client.get_waiter(\n",
"# \"training_job_completed_or_stopped\"\n",
"# )\n",
"# waiter2.wait(TrainingJobName=compiler_train_job_name)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"
\n",
"\n",
"## 4. Analysis\n",
"---\n",
"\n",
"### Create helper functions for analysis"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"from ast import literal_eval\n",
"from collections import defaultdict\n",
"from matplotlib import pyplot as plt\n",
"\n",
"# Intermediary function for processing each line of stdout captured\n",
"# Remove leading and trailing whitespace and append data in curly braces\n",
"# to final list\n",
"def _summarize(captured):\n",
" final = []\n",
" for line in captured.stdout.split(\"\\n\"):\n",
" cleaned = line.strip()\n",
" if \"{\" in cleaned and \"}\" in cleaned:\n",
" final.append(cleaned[cleaned.index(\"{\") : cleaned.index(\"}\") + 1])\n",
" return final\n",
"\n",
"\n",
"# Check input with literal_eval\n",
"# https://docs.python.org/3/library/ast.html\n",
"def make_sense(string):\n",
" try:\n",
" return literal_eval(string)\n",
" except:\n",
" pass\n",
"\n",
"\n",
"# Parse the stdout and organize by train, evaluation, and summary data\n",
"def summarize(summary):\n",
" final = {\"train\": [], \"eval\": [], \"summary\": {}}\n",
" for line in summary:\n",
" interpretation = make_sense(line)\n",
" if interpretation:\n",
" if \"loss\" in interpretation:\n",
" final[\"train\"].append(interpretation)\n",
" elif \"eval_loss\" in interpretation:\n",
" final[\"eval\"].append(interpretation)\n",
" elif \"train_runtime\" in interpretation:\n",
" final[\"summary\"].update(interpretation)\n",
" return final"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"%%capture native\n",
"\n",
"# access the logs of the native training job\n",
"sm_estimator.sagemaker_session.logs_for_job(train_job_name)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"%%capture optimized\n",
"\n",
"# access the logs of the native training job\n",
"sm_compiler_estimator.sagemaker_session.logs_for_job(compiler_train_job_name)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"native_summary = summarize(_summarize(native))\n",
"native_throughput = native_summary[\"summary\"][\"train_samples_per_second\"]\n",
"\n",
"optimized_summary = summarize(_summarize(optimized))\n",
"optimized_throughput = optimized_summary[\"summary\"][\"train_samples_per_second\"]\n",
"\n",
"avg_speedup = f\"{round((optimized_throughput/native_throughput-1)*100)}%\""
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Plot Optimized vs Native Training Throughput\n",
"\n",
"Visualize average throughputs as reported by HuggingFace and see potential savings."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Average throughput for the native PyTorch training as reported by Trainer\n",
"n = summarize(_summarize(native))\n",
"native_throughput = n[\"summary\"][\"train_samples_per_second\"]\n",
"\n",
"# Average throughput for the optimized PyTorch training as reported by Trainer\n",
"o = summarize(_summarize(optimized))\n",
"optimized_throughput = o[\"summary\"][\"train_samples_per_second\"]\n",
"\n",
"# Calculate percentage speedup of optimized PyTorch over native PyTorch\n",
"avg_speedup = f\"{round((optimized_throughput/native_throughput-1)*100)}%\""
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"%matplotlib inline\n",
"\n",
"plt.title(\"Training Throughput \\n (Higher is better)\")\n",
"plt.ylabel(\"Samples/sec\")\n",
"\n",
"plt.bar(x=[1], height=native_throughput, label=\"Baseline PT\", width=0.35)\n",
"plt.bar(x=[1.5], height=optimized_throughput, label=\"Compiler-enhanced PT\", width=0.35)\n",
"\n",
"plt.xlabel(\" ====> {} Compiler savings <====\".format(avg_speedup))\n",
"plt.xticks(ticks=[1, 1.5], labels=[\"Baseline PT\", \"Compiler-enhanced PT\"])"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"native_summary['train']"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"vanilla_loss = [i[\"loss\"] for i in n[\"train\"]]\n",
"vanilla_epochs = [i[\"epoch\"] for i in n[\"train\"]]\n",
"optimized_loss = [i[\"loss\"] for i in o[\"train\"]]\n",
"optimized_epochs = [i[\"epoch\"] for i in o[\"train\"]]\n",
"\n",
"plt.title(\"Plot of Training Loss\")\n",
"plt.xlabel(\"Epoch\")\n",
"plt.ylabel(\"Training Loss\")\n",
"plt.plot(vanilla_epochs, vanilla_loss, label=\"Baseline PT\")\n",
"plt.plot(optimized_epochs, optimized_loss, label=\"Compiler-enhanced PT\")\n",
"plt.legend()"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Training Stats\n",
"\n",
"SageMaker Training Compiler가 있는 경우와 없는 경우 다양한 훈련 메트릭을 비교해 보겠습니다. SageMaker Training Compiler는 훈련 처리량을 증가시켜 총 훈련 시간을 줄여줍니다."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"import pandas as pd\n",
"\n",
"pd.DataFrame([n[\"summary\"], o[\"summary\"]], index=[\"Native\", \"Optimized\"])"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# calculate percentage speedup from SageMaker Training Compiler in terms of total training time reported by HF\n",
"speedup = (\n",
" (n[\"summary\"][\"train_runtime\"] - o[\"summary\"][\"train_runtime\"])\n",
" * 100\n",
" / n[\"summary\"][\"train_runtime\"]\n",
")\n",
"print(\n",
" f\"SageMaker Training Compiler integrated PyTorch is about {int(speedup)}% faster in terms of total training time as reported by HF.\"\n",
")"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"avg_speedup = f\"{round((optimized_throughput/native_throughput-1)*100)}%\"\n",
"print(avg_speedup)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"def BillableTimeInSeconds(name):\n",
" describe_training_job = (\n",
" sm_compiler_estimator.sagemaker_session.sagemaker_client.describe_training_job\n",
" )\n",
" details = describe_training_job(TrainingJobName=name)\n",
" return details[\"BillableTimeInSeconds\"]\n",
"\n",
"Billable = {}\n",
"Billable[\"Native\"] = BillableTimeInSeconds(train_job_name)\n",
"Billable[\"Optimized\"] = BillableTimeInSeconds(compiler_train_job_name)\n",
"display(pd.DataFrame(Billable, index=[\"BillableSecs\"]))\n",
"\n",
"speedup = (Billable[\"Native\"] - Billable[\"Optimized\"]) * 100 / Billable[\"Native\"]\n",
"print(f\"SageMaker Training Compiler integrated PyTorch was {int(speedup)}% faster in summary.\")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"
\n",
"\n",
"## 5. Clean up\n",
"---\n",
"\n",
"훈련 작업이 아직 실행 중인 경우, 과금 방지를 위해 시작된 모든 훈련 작업을 중단합니다."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"import boto3\n",
"sm = boto3.client(\"sagemaker\")\n",
"\n",
"def stop_training_job(name):\n",
" status = sm.describe_training_job(TrainingJobName=name)[\"TrainingJobStatus\"]\n",
" if status == \"InProgress\":\n",
" sm.stop_training_job(TrainingJobName=name)\n",
"\n",
"\n",
"stop_training_job(train_job_name)\n",
"stop_training_job(compiler_train_job_name)"
]
}
],
"metadata": {
"instance_type": "ml.t3.medium",
"interpreter": {
"hash": "c281c456f1b8161c8906f4af2c08ed2c40c50136979eaae69688b01f70e9f4a9"
},
"kernelspec": {
"display_name": "conda_pytorch_latest_p37",
"language": "python",
"name": "conda_pytorch_latest_p37"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.7.12"
}
},
"nbformat": 4,
"nbformat_minor": 4
}