{
"cells": [
{
"cell_type": "markdown",
"id": "0eb05b54",
"metadata": {},
"source": [
"# Lab 3: MLOps with SageMaker Pipelines\n",
"\n",
"\n",
"## Prerequisites\n",
"---\n",
"\n",
"본 ëª¨ë“ˆì€ ì—¬ëŸ¬ë¶„ì´ SageMaker와 SageMaker Pipelinesì— ëŒ€í•œ 기본 ì»¨ì…‰ì„ ì•Œê³ ìžˆë‹¤ê³ ê°€ì •í•©ë‹ˆë‹¤. 만약 기본 ì»¨ì…‰ì— ëŒ€í•œ ì´í•´ì™€ step-by-step í•¸ì¦ˆì˜¨ì´ í•„ìš”í•˜ë©´ 아래 ë§í¬ë“¤ì„ 통해 세션 ì‹œì² í›„, í•¸ì¦ˆì˜¨ì„ í•´ 보시는 ê²ƒì„ ê¶Œìž¥ë“œë¦½ë‹ˆë‹¤.\n",
"\n",
"- SageMaker Pipelines 세션 (AWS Builders 300)\n",
" - Part 1: https://www.youtube.com/watch?v=7IL_0-OjZWk\n",
" - Part 2: https://www.youtube.com/watch?v=z_l2aNJswWQ\n",
"- SageMaker Pipelines Step-by-step 핸즈온\n",
" - 입문 ê³¼ì •: https://github.com/gonsoomoon-ml/SageMaker-Pipelines-Step-By-Step\n",
" - (optionally) ê³ ê¸‰ ê³¼ì • 1: https://github.com/gonsoomoon-ml/SageMaker-Pipelines-Step-By-Step/tree/main/phase01\n",
" - (optionally) ê³ ê¸‰ ê³¼ì • 2: https://github.com/gonsoomoon-ml/SageMaker-Pipelines-Step-By-Step/tree/main/phase02\n",
"\n",
"\n",
"## Introduction\n",
"---\n",
"\n",
"본 모듈ì—서는 SageMaker Pipelines를 사용하여 간단한 ë¨¸ì‹ ëŸ¬ë‹ íŒŒì´í”„ë¼ì¸ì„ 구축합니다. SageMaker Pipelinesì€ re:Invent 2020 서비스 ëŸ°ì¹ ì´í›„ 지ì†ì 으로 ì—…ë°ì´íŠ¸ë˜ê³ 있으며, 2021ë…„ 8ì›” ì—…ë°ì´íŠ¸ëœ 주요 ê¸°ëŠ¥ì¸ Lambda Stepì„ ì‚¬ìš©í•˜ë©´ 호스팅 엔드í¬ì¸íŠ¸ ëª¨ë¸ ë°°í¬ë¥¼ 비롯한 서버리스 ìž‘ì—…ë“¤ì„ ì‰½ê²Œ ìˆ˜í–‰í• ìˆ˜ 있습니다. ë˜í•œ ìºì‹±(caching) ê¸°ëŠ¥ì„ ì‚¬ìš©í•˜ë©´ ëª¨ë“ íŒŒì´í”„ë¼ì¸ì„ 처ìŒë¶€í„° ìž¬ì‹œìž‘í• í•„ìš” ì—†ì´ ë³€ê²½ëœ íŒŒë¼ë©”í„°ì— ëŒ€í•´ì„œë§Œ ë¹ ë¥´ê²Œ 실험해볼 수 있습니다. Lambda Stepê³¼ ìºì‹±ì— 대한 ìžì„¸í•œ ë‚´ìš©ì€ ì•„ëž˜ ë§í¬ë“¤ì„ 참조해 주세요.\n",
"\n",
"Reference: \n",
"- SageMaker Pipelines SDK: https://docs.aws.amazon.com/sagemaker/latest/dg/pipelines-sdk.html\n",
"- Caching Pipeline Steps: https://docs.aws.amazon.com/sagemaker/latest/dg/pipelines-caching.html\n",
"- AWS AIML Blog: Use a SageMaker Pipeline Lambda step for lightweight model deployments: https://aws.amazon.com/de/blogs/machine-learning/use-a-sagemaker-pipeline-lambda-step-for-lightweight-model-deployments/\n",
"\n",
"Note:\n",
"- 본 노트ë¶ì„ ì‹¤í–‰í•˜ë ¤ë©´ `AmazonSageMakerFullAccess`와 `AmazonSageMakerPipelinesIntegrations` policy를 추가해야 합니다.\n",
"- ë¹ ë¥¸ í•¸ì¦ˆì˜¨ì„ ìœ„í•´ 1000ê±´ì˜ ìƒ˜í”Œ ë°ì´í„°ì™€ 1 epoch으로 ì „ì²˜ë¦¬ ë° í›ˆë ¨ì„ ìˆ˜í–‰í•©ë‹ˆë‹¤. ì‚¬ì „ì— ì´ë¯¸ 파ì¸íŠœë‹ì´ ì™„ë£Œëœ ëª¨ë¸ì„ í›ˆë ¨í•˜ë¯€ë¡œ ë†’ì€ ì •í™•ë„를 보입니다."
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "47e800e8",
"metadata": {},
"outputs": [],
"source": [
"import boto3\n",
"import os\n",
"import numpy as np\n",
"import sagemaker\n",
"import sys\n",
"import time\n",
"\n",
"import sagemaker\n",
"import sagemaker.huggingface\n",
"from sagemaker.huggingface import HuggingFace, HuggingFaceModel\n",
"\n",
"from sagemaker.workflow.parameters import ParameterInteger, ParameterFloat, ParameterString\n",
"\n",
"from sagemaker.lambda_helper import Lambda\n",
"\n",
"from sagemaker.sklearn.processing import SKLearnProcessor\n",
"from sagemaker.huggingface.processing import HuggingFaceProcessor\n",
"\n",
"from sagemaker.processing import ProcessingInput, ProcessingOutput\n",
"from sagemaker.workflow.steps import CacheConfig, ProcessingStep\n",
"\n",
"from sagemaker.inputs import TrainingInput\n",
"from sagemaker.workflow.steps import TrainingStep\n",
"\n",
"from sagemaker.processing import ScriptProcessor\n",
"from sagemaker.workflow.properties import PropertyFile\n",
"from sagemaker.workflow.step_collections import CreateModelStep, RegisterModel\n",
"\n",
"from sagemaker.workflow.conditions import ConditionLessThanOrEqualTo,ConditionGreaterThanOrEqualTo\n",
"from sagemaker.workflow.condition_step import ConditionStep\n",
"from sagemaker.workflow.functions import JsonGet\n",
"\n",
"from sagemaker.workflow.pipeline import Pipeline, PipelineExperimentConfig\n",
"from sagemaker.workflow.execution_variables import ExecutionVariables"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "6c88b740",
"metadata": {},
"outputs": [],
"source": [
"sess = sagemaker.Session()\n",
"region = sess.boto_region_name\n",
"\n",
"# sagemaker session bucket -> used for uploading data, models and logs\n",
"# sagemaker will automatically create this bucket if it not exists\n",
"sagemaker_session_bucket=None\n",
"if sagemaker_session_bucket is None and sess is not None:\n",
" # set to default bucket if a bucket name is not given\n",
" sagemaker_session_bucket = sess.default_bucket()\n",
"\n",
"role = sagemaker.get_execution_role()\n",
"sagemaker_session = sagemaker.Session(default_bucket=sagemaker_session_bucket)\n",
"\n",
"print(f\"sagemaker role arn: {role}\")\n",
"print(f\"sagemaker bucket: {sagemaker_session.default_bucket()}\")\n",
"print(f\"sagemaker session region: {sagemaker_session.boto_region_name}\")"
]
},
{
"cell_type": "markdown",
"id": "3cf3461c",
"metadata": {},
"source": [
"\n",
"<br>\n",
"\n",
"## 1. Defining the Pipeline\n",
"---\n",
"\n",
"### 1.1. Pipeline parameters\n",
"\n",
"기본ì ì¸ íŒŒì´í”„ë¼ì¸ 파ë¼ë©”í„°ë“¤ì„ ì •ì˜í•©ë‹ˆë‹¤. ìžì„¸í•œ ë‚´ìš©ì€ ì•„ëž˜ ë§í¬ë¥¼ 참조해 주세요.\n",
"\n",
"References: \n",
"- ê°œë°œìž ê°€ì´ë“œ: https://docs.aws.amazon.com/sagemaker/latest/dg/build-and-manage-parameters.html"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "1696421d",
"metadata": {},
"outputs": [],
"source": [
"# S3 prefix where every assets will be stored\n",
"s3_prefix = \"hf-kornlp-mlops-demo\"\n",
"\n",
"# s3 bucket used for storing assets and artifacts\n",
"bucket = sagemaker_session.default_bucket()\n",
"\n",
"# aws region used\n",
"region = sagemaker_session.boto_region_name\n",
"\n",
"# base name prefix for sagemaker jobs (training, processing, inference)\n",
"base_job_prefix = s3_prefix\n",
"\n",
"# Cache configuration for workflow\n",
"cache_config = CacheConfig(enable_caching=True, expire_after=\"7d\")\n",
"\n",
"# package versions\n",
"transformers_version = \"4.11.0\"\n",
"pytorch_version = \"1.9.0\"\n",
"py_version = \"py38\"\n",
"\n",
"model_id_ = \"daekeun-ml/koelectra-small-v3-nsmc\"\n",
"tokenizer_id_ = \"daekeun-ml/koelectra-small-v3-nsmc\"\n",
"dataset_name_ = \"nsmc\"\n",
"\n",
"model_id = ParameterString(name=\"ModelId\", default_value=model_id_)\n",
"tokenizer_id = ParameterString(name=\"TokenizerId\", default_value=tokenizer_id_)\n",
"dataset_name = ParameterString(name=\"DatasetName\", default_value=dataset_name_)"
]
},
{
"cell_type": "markdown",
"id": "31677317",
"metadata": {},
"source": [
"### 1.2. Processing Step\n",
"\n",
"ë¹ŒíŠ¸ì¸ `SKLearnProcessor`를 통해 ì „ì²˜ë¦¬ 스í…ì„ ì •ì˜í•©ë‹ˆë‹¤. \n",
"\n",
"최근 PyTorch, TensorFlow, MXNet, XGBoost, Hugging Faceë„ ë¹ŒíŠ¸ì¸ìœ¼ë¡œ 지ì›ë˜ê¸° 시작했습니다. `HuggingFaceProcessor` 사용 예시는 아래 코드 snippetì„ ì°¸ì¡°í•´ 주세요. 단, `HuggingFaceProcessor`는 현 ì‹œì (2022ë…„ 1ì›”)ì—서는 GPU ì¸ìŠ¤í„´ìŠ¤ë§Œ 지ì›í•˜ê¸° ë•Œë¬¸ì— GPU 리소스가 필요하지 ì•Šì€ ê²½ìš°ëŠ” `SKLearnProcessor` ì‚¬ìš©ì„ ê¶Œìž¥ë“œë¦½ë‹ˆë‹¤.\n",
"\n",
"\n",
"```python\n",
"from sagemaker.huggingface.processing import HuggingFaceProcessor\n",
"\n",
"hf_processor = HuggingFaceProcessor(\n",
" instance_type=processing_instance_type, \n",
" instance_count=processing_instance_count,\n",
" pytorch_version=pytorch_version,\n",
" transformers_version=transformers_version,\n",
" py_version=py_version,\n",
" base_job_name=base_job_prefix + \"-preprocessing\",\n",
" sagemaker_session=sagemaker_session, \n",
" role=role\n",
")\n",
"\n",
"```\n",
"\n",
"References: \n",
"- AWS AIML Blog: https://aws.amazon.com/ko/blogs/machine-learning/use-deep-learning-frameworks-natively-in-amazon-sagemaker-processing/\n",
"- ê°œë°œìž ê°€ì´ë“œ: https://docs.aws.amazon.com/ko_kr/sagemaker/latest/dg/build-and-manage-steps.html#step-type-processing"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "ae10defb",
"metadata": {},
"outputs": [],
"source": [
"processing_instance_type = ParameterString(name=\"ProcessingInstanceType\", default_value=\"ml.c5.xlarge\")\n",
"processing_instance_count = ParameterInteger(name=\"ProcessingInstanceCount\", default_value=1)\n",
"processing_script = ParameterString(name=\"ProcessingScript\", default_value=\"./src/processing_sklearn.py\")"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "76708670",
"metadata": {},
"outputs": [],
"source": [
"processing_output_destination = f\"s3://{bucket}/{s3_prefix}/data\"\n",
"\n",
"sklearn_processor = SKLearnProcessor(\n",
" instance_type=processing_instance_type, \n",
" instance_count=processing_instance_count,\n",
" framework_version=\"0.23-1\", \n",
" base_job_name=base_job_prefix + \"-preprocessing\",\n",
" sagemaker_session=sagemaker_session, \n",
" role=role\n",
")\n",
"\n",
"step_process = ProcessingStep(\n",
" name=\"ProcessDataForTraining\",\n",
" cache_config=cache_config,\n",
" processor=sklearn_processor,\n",
" job_arguments=[\"--model_id\", model_id_,\n",
" \"--tokenizer_id\", tokenizer_id_,\n",
" \"--dataset_name\", dataset_name_,\n",
" \"--transformers_version\", transformers_version,\n",
" \"--pytorch_version\", pytorch_version\n",
" ],\n",
" outputs=[\n",
" ProcessingOutput(\n",
" output_name=\"train\",\n",
" destination=f\"{processing_output_destination}/train\",\n",
" source=\"/opt/ml/processing/train\",\n",
" ),\n",
" ProcessingOutput(\n",
" output_name=\"validation\",\n",
" destination=f\"{processing_output_destination}/test\",\n",
" source=\"/opt/ml/processing/validation\",\n",
" ),\n",
" ProcessingOutput(\n",
" output_name=\"test\",\n",
" destination=f\"{processing_output_destination}/test\",\n",
" source=\"/opt/ml/processing/test\",\n",
" ) \n",
" ],\n",
" code=processing_script\n",
")"
]
},
{
"cell_type": "markdown",
"id": "e008ef40",
"metadata": {},
"source": [
"### 1.3. Model Training Step\n",
"\n",
"ì´ì „ ëž©ì—ì„œ 진행한 í›ˆë ¨ 스í¬ë¦½íŠ¸ë¥¼ 그대로 활용하여 í›ˆë ¨ 스í…ì„ ì •ì˜í•©ë‹ˆë‹¤. SageMaker Pipelinesì— ì 용하기 위해 워í¬í”Œë¡œ 파ë¼ë©”í„°(`ParameterInteger, ParameterFloat, ParameterString`)ë„ ê°™ì´ ì •ì˜í•©ë‹ˆë‹¤.\n",
"\n",
"í›ˆë ¨, ê²€ì¦ ë° í…ŒìŠ¤íŠ¸ ë°ì´í„°ì— 대한 S3 경로는 ì´ì „ 랩처럼 수ë™ìœ¼ë¡œ ì§€ì •í•˜ëŠ” ê²ƒì´ ì•„ë‹ˆë¼ ì²´ì¸ìœ¼ë¡œ ì—°ê²°ë˜ëŠ” ê°œë…ì´ê¸°ì—, 아래 예시처럼 ì „ì²˜ë¦¬ ìŠ¤í… ê²°ê´ê°’(`step_process`)ì˜ í”„ë¡œí¼í‹°(`properties`)를 참조하여 ì§€ì •í•´ì•¼ 합니다.\n",
"```python\n",
"\"train\": TrainingInput(\n",
" s3_data=step_process.properties.ProcessingOutputConfig.Outputs[\"train\"].S3Output.S3Uri\n",
")\n",
"```"
]
},
{
"cell_type": "markdown",
"id": "34221b76",
"metadata": {},
"source": [
"#### Training Parameter"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "a7867b16",
"metadata": {},
"outputs": [],
"source": [
"# training step parameters\n",
"training_entry_point = ParameterString(name=\"TrainingEntryPoint\", default_value=\"train.py\")\n",
"training_source_dir = ParameterString(name=\"TrainingSourceDir\", default_value=\"./src\")\n",
"training_instance_type = ParameterString(name=\"TrainingInstanceType\", default_value=\"ml.p3.2xlarge\")\n",
"training_instance_count = ParameterInteger(name=\"TrainingInstanceCount\", default_value=1)\n",
"\n",
"# hyperparameters, which are passed into the training job\n",
"n_gpus = ParameterString(name=\"NumGPUs\", default_value=\"1\")\n",
"epochs = ParameterString(name=\"Epochs\", default_value=\"1\")\n",
"seed = ParameterString(name=\"Seed\", default_value=\"42\")\n",
"train_batch_size = ParameterString(name=\"TrainBatchSize\", default_value=\"32\")\n",
"eval_batch_size = ParameterString(name=\"EvalBatchSize\", default_value=\"64\") \n",
"learning_rate = ParameterString(name=\"LearningRate\", default_value=\"5e-5\") \n",
"\n",
"# model_id = ParameterString(name=\"ModelId\", default_value=model_id_)\n",
"# tokenizer_id = ParameterString(name=\"TokenizerId\", default_value=tokenizer_id_)\n",
"# dataset_name = ParameterString(name=\"DatasetName\", default_value=dataset_name_)"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "7c19a3c4",
"metadata": {},
"outputs": [],
"source": [
"hyperparameters = {\n",
" 'n_gpus': n_gpus, # number of GPUs per instance\n",
" 'epochs': epochs, # number of training epochs\n",
" 'seed': seed, # seed\n",
" 'train_batch_size': train_batch_size, # batch size for training\n",
" 'eval_batch_size': eval_batch_size, # batch size for evaluation\n",
" 'warmup_steps': 0, # warmup steps\n",
" 'learning_rate': learning_rate, # learning rate used during training\n",
" 'tokenizer_id': model_id, # pre-trained tokenizer\n",
" 'model_id': tokenizer_id # pre-trained model\n",
"}\n",
"\n",
"chkpt_s3_path = f's3://{bucket}/{s3_prefix}/sm-processing/checkpoints'"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "e654d8cd",
"metadata": {},
"outputs": [],
"source": [
"huggingface_estimator = HuggingFace(\n",
" entry_point=training_entry_point,\n",
" source_dir=training_source_dir,\n",
" base_job_name=base_job_prefix + \"-training\",\n",
" instance_type=training_instance_type,\n",
" instance_count=training_instance_count,\n",
" role=role,\n",
" transformers_version=transformers_version,\n",
" pytorch_version=pytorch_version,\n",
" py_version=py_version,\n",
" hyperparameters=hyperparameters,\n",
" sagemaker_session=sagemaker_session, \n",
" disable_profiler=True,\n",
" debugger_hook_config=False,\n",
" checkpoint_s3_uri=chkpt_s3_path,\n",
" checkpoint_local_path='/opt/ml/checkpoints'\n",
")\n",
"\n",
"step_train = TrainingStep(\n",
" name=\"TrainHuggingFaceModel\",\n",
" estimator=huggingface_estimator,\n",
" inputs={\n",
" \"train\": TrainingInput(\n",
" s3_data=step_process.properties.ProcessingOutputConfig.Outputs[\n",
" \"train\"\n",
" ].S3Output.S3Uri\n",
" ),\n",
" \"test\": TrainingInput(\n",
" s3_data=step_process.properties.ProcessingOutputConfig.Outputs[\n",
" \"test\"\n",
" ].S3Output.S3Uri\n",
" ),\n",
" },\n",
" cache_config=cache_config,\n",
")"
]
},
{
"cell_type": "markdown",
"id": "d2609fee",
"metadata": {},
"source": [
"### 1.4. Model evaluation Step\n",
"\n",
"í›ˆë ¨ëœ ëª¨ë¸ì˜ ì„±ëŠ¥ì„ í‰ê°€í•˜ê¸° 위해 추가 `ProcessingStep`ì„ ì •ì˜í•©ë‹ˆë‹¤. í‰ê°€ ê²°ê³¼ì— ë”°ë¼ ëª¨ë¸ì´ ìƒì„±, ë“±ë¡ ë° ë°°í¬ë˜ê±°ë‚˜ 파ì´í”„ë¼ì¸ì´ 중단ë©ë‹ˆë‹¤.\n",
"í‰ê°€ 결과는 `PropertyFile`ì— ë³µì‚¬ë˜ë©°, ì´ëŠ” ì´í›„ `ConditionStep`ì—ì„œ 사용ë©ë‹ˆë‹¤."
]
},
{
"cell_type": "markdown",
"id": "90ab2765",
"metadata": {},
"source": [
"#### Evaluation Parameter"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "703b47a7",
"metadata": {},
"outputs": [],
"source": [
"evaluation_script = ParameterString(name=\"EvaluationScript\", default_value=\"./src/evaluate.py\")\n",
"evaluation_instance_type = ParameterString(name=\"EvaluationInstanceType\", default_value=\"ml.m5.xlarge\")\n",
"evaluation_instance_count = ParameterInteger(name=\"EvaluationInstanceCount\", default_value=1)"
]
},
{
"cell_type": "markdown",
"id": "bd5d0b36",
"metadata": {},
"source": [
"#### Evaluator"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "ec940dec",
"metadata": {},
"outputs": [],
"source": [
"!pygmentize ./src/evaluate.py"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "874b539e",
"metadata": {},
"outputs": [],
"source": [
"script_eval = SKLearnProcessor(\n",
" framework_version=\"0.23-1\",\n",
" instance_type=evaluation_instance_type,\n",
" instance_count=evaluation_instance_count,\n",
" base_job_name=base_job_prefix + \"-evaluation\",\n",
" sagemaker_session=sagemaker_session,\n",
" role=role,\n",
")\n",
"\n",
"evaluation_report = PropertyFile(\n",
" name=\"HuggingFaceEvaluationReport\",\n",
" output_name=\"evaluation\",\n",
" path=\"evaluation.json\",\n",
")\n",
"\n",
"step_eval = ProcessingStep(\n",
" name=\"HuggingfaceEvalLoss\",\n",
" processor=script_eval,\n",
" inputs=[\n",
" ProcessingInput(\n",
" source=step_train.properties.ModelArtifacts.S3ModelArtifacts,\n",
" destination=\"/opt/ml/processing/model\",\n",
" )\n",
" ],\n",
" outputs=[\n",
" ProcessingOutput(\n",
" output_name=\"evaluation\",\n",
" source=\"/opt/ml/processing/evaluation\",\n",
" destination=f\"s3://{bucket}/{s3_prefix}/evaluation_report\",\n",
" ),\n",
" ],\n",
" code=evaluation_script,\n",
" property_files=[evaluation_report],\n",
" cache_config=cache_config,\n",
")"
]
},
{
"cell_type": "markdown",
"id": "da6b7f5d",
"metadata": {},
"source": [
"### 1.5. Register the model\n",
"\n",
"í›ˆë ¨ëœ ëª¨ë¸ì€ ëª¨ë¸ íŒ¨í‚¤ì§€ 그룹(Model Package Group)ì˜ ëª¨ë¸ ë ˆì§€ìŠ¤íŠ¸ë¦¬(Model Registry)ì— ë“±ë¡ë©ë‹ˆë‹¤. ëª¨ë¸ ë ˆì§€ìŠ¤íŠ¸ë¦¬ëŠ” SageMaker Pipelinesì—ì„œ ì†Œê°œëœ ê°œë…으로, 기존 SageMaker 모ë¸ê³¼ 다르게 ëª¨ë¸ ë²„ì „ 관리가 가능하며 ìŠ¹ì¸ ì—¬ë¶€ë¥¼ ì§€ì •í• ìˆ˜ 있습니다. ëª¨ë¸ ìŠ¹ì¸ì€ `ConditionStep`ì˜ ì¡°ê±´ì„ ë§Œì¡±í• ë•Œì—만 가능하게 í• ìˆ˜ 있습니다. (예: ì •í™•ë„ê°€ 80% ì´ìƒì¸ 경우ì—만 ëª¨ë¸ ë°°í¬)"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "e860717a",
"metadata": {},
"outputs": [],
"source": [
"model = HuggingFaceModel(\n",
" model_data=step_train.properties.ModelArtifacts.S3ModelArtifacts,\n",
" role=role,\n",
" transformers_version=transformers_version,\n",
" pytorch_version=pytorch_version,\n",
" py_version=py_version,\n",
" sagemaker_session=sagemaker_session,\n",
")\n",
"model_package_group_name = \"HuggingFaceModelPackageGroup\"\n",
"step_register = RegisterModel(\n",
" name=\"HuggingFaceRegisterModel\",\n",
" model=model,\n",
" content_types=[\"application/json\"],\n",
" response_types=[\"application/json\"],\n",
" inference_instances=[\"ml.m5.xlarge\", \"ml.g4dn.xlarge\"],\n",
" transform_instances=[\"ml.m5.xlarge\", \"ml.g4dn.xlarge\"],\n",
" model_package_group_name=model_package_group_name,\n",
" approval_status=\"Approved\",\n",
")"
]
},
{
"cell_type": "markdown",
"id": "219b6810",
"metadata": {},
"source": [
"### 1.6. Model Deployment\n",
"\n",
"\n",
"`LambdaStep`ì—ì„œ 파ìƒëœ 커스텀 단계 `ModelDeployment`를 ìƒì„±í•©ë‹ˆë‹¤. LambdaStepì—ì„œ ì •ì˜í•œ Lambda 함수를 통해 호스팅 리얼타임 엔드í¬ì¸íŠ¸ë¥¼ ë°°í¬í•©ë‹ˆë‹¤."
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "5aec1574",
"metadata": {},
"outputs": [],
"source": [
"!pygmentize utils/deploy_step.py"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "d3f838d5",
"metadata": {},
"outputs": [],
"source": [
"# custom Helper Step for ModelDeployment\n",
"from utils.deploy_step import ModelDeployment\n",
"\n",
"# we will use the iam role from the notebook session for the created endpoint\n",
"# this role will be attached to our endpoint and need permissions, e.g. to download assets from s3\n",
"sagemaker_endpoint_role=sagemaker.get_execution_role()\n",
"model_name = f\"{model_id_.split('/')[-1]}-{time.strftime('%Y-%m-%d-%H-%M-%S', time.localtime())}\"\n",
"\n",
"step_deployment = ModelDeployment(\n",
" model_name=model_name,\n",
" registered_model=step_register.steps[0],\n",
" endpoint_instance_type=\"ml.m5.xlarge\",\n",
" sagemaker_endpoint_role=sagemaker_endpoint_role,\n",
" autoscaling_policy=None,\n",
")"
]
},
{
"cell_type": "markdown",
"id": "ed2bb0b5",
"metadata": {},
"source": [
"### 1.7. Condition for deployment\n",
"\n",
"`ConditionStep`ì„ í†µí•´ ëª¨ë¸ í‰ê°€ 결과를 검사합니다. ì •í™•ë„ê°€ ì¼ì • ì´ìƒì¼ ë•Œ(accuracy > 0.8) ëª¨ë¸ ë“±ë¡ ë° ë°°í¬ íŒŒì´í”„ë¼ì¸ì„ 진행합니다."
]
},
{
"cell_type": "markdown",
"id": "4a0a78f6",
"metadata": {},
"source": [
"#### Condition Parameter"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "1052caf6",
"metadata": {},
"outputs": [],
"source": [
"threshold_accuracy = ParameterFloat(name=\"ThresholdAccuracy\", default_value=0.8)"
]
},
{
"cell_type": "markdown",
"id": "7d30042d",
"metadata": {},
"source": [
"#### Condition"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "a4411610",
"metadata": {},
"outputs": [],
"source": [
"cond_gte = ConditionGreaterThanOrEqualTo(\n",
" left=JsonGet(\n",
" step_name=step_eval.name,\n",
" property_file=evaluation_report,\n",
" json_path=\"eval_accuracy\",\n",
" ),\n",
" right=threshold_accuracy,\n",
")\n",
"\n",
"step_cond = ConditionStep(\n",
" name=\"CheckHuggingfaceEvalAccuracy\",\n",
" conditions=[cond_gte],\n",
" if_steps=[step_register, step_deployment],\n",
" else_steps=[],\n",
")"
]
},
{
"cell_type": "markdown",
"id": "8a734ad7",
"metadata": {},
"source": [
"<br>\n",
"\n",
"## 2. Pipeline definition and execution\n",
"\n",
"---\n",
"\n",
"ëª¨ë“ ìŠ¤í…ì„ ì •ì˜í•˜ì˜€ë‹¤ë©´ 파ì´í”„ë¼ì¸ì„ ì •ì˜í•©ë‹ˆë‹¤. \n",
"\n",
"파ì´í”„ë¼ì¸ ì¸ìŠ¤í„´ìŠ¤ëŠ” ì´ë¦„(`name`), 파ë¼ë©”í„°(`parameters`), ë° ìŠ¤í…(`steps`)으로 구성ë©ë‹ˆë‹¤. \n",
"- 파ì´í”„ë¼ì¸ ì´ë¦„: (AWS ê³„ì •, ë¦¬ì „) ìŒ ë‚´ì—ì„œ ê³ ìœ í•´ì•¼ 합니다 \n",
"- 파ë¼ë©”í„°: ìŠ¤í… ì •ì˜ì— ì‚¬ìš©í–ˆë˜ ëª¨ë“ íŒŒë¼ë©”í„°ë“¤ì„ íŒŒì´í”„ë¼ì¸ì—ì„œ ì •ì˜í•´ì•¼ 합니다. \n",
"- 스í…: 리스트 형태로 ì´ì „ 스í…ë“¤ì„ ì •ì˜í•©ë‹ˆë‹¤. 내부ì 으로 ë°ì´í„° 종ì†ì„±ì„ 사용하여 ê° ìŠ¤í… ê°„ì˜ ê´€ê³„ë¥¼ DAG으로 ì •ì˜í•˜ê¸° ë•Œë¬¸ì— ì‹¤í–‰ 순서대로 ë‚˜ì—´í• í•„ìš”ëŠ” 없습니다."
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "443d6b52",
"metadata": {},
"outputs": [],
"source": [
"pipeline = Pipeline(\n",
" name=f\"HuggingFaceDemoPipeline\",\n",
" parameters=[\n",
" model_id,\n",
" tokenizer_id, \n",
" dataset_name,\n",
" processing_instance_type,\n",
" processing_instance_count,\n",
" processing_script,\n",
" training_entry_point,\n",
" training_source_dir,\n",
" training_instance_type,\n",
" training_instance_count,\n",
" evaluation_script,\n",
" evaluation_instance_type,\n",
" evaluation_instance_count,\n",
" threshold_accuracy,\n",
" n_gpus,\n",
" epochs,\n",
" seed,\n",
" eval_batch_size,\n",
" train_batch_size,\n",
" learning_rate,\n",
" ],\n",
" steps=[step_process, step_train, step_eval, step_cond],\n",
" sagemaker_session=sagemaker_session,\n",
")"
]
},
{
"cell_type": "markdown",
"id": "c65baea5",
"metadata": {},
"source": [
"#### Check the pipeline definition\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "4ce7e899",
"metadata": {},
"outputs": [],
"source": [
"import json\n",
"\n",
"definition = json.loads(pipeline.definition())\n",
"definition"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "b928bbcb",
"metadata": {},
"outputs": [],
"source": [
"pipeline.upsert(role_arn=role)"
]
},
{
"cell_type": "markdown",
"id": "3c7c3357",
"metadata": {},
"source": [
"#### Run the pipeline\n",
"\n",
"파ì´í”„ë¼ì¸ì„ 실행합니다."
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "2265a690",
"metadata": {},
"outputs": [],
"source": [
"execution = pipeline.start()"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "86a497cc",
"metadata": {},
"outputs": [],
"source": [
"execution.describe()"
]
},
{
"cell_type": "markdown",
"id": "4d8faa49",
"metadata": {},
"source": [
"파ì´í”„ë¼ì¸ ì‹¤í–‰ì´ ì™„ë£Œë 때까지 기다립니다. SageMaker Studio ì½˜ì†”ì„ í†µí•´ 진행 ìƒí™©ì„ 확ì¸í• ìˆ˜ë„ ìžˆìŠµë‹ˆë‹¤.\n",
"\n",
"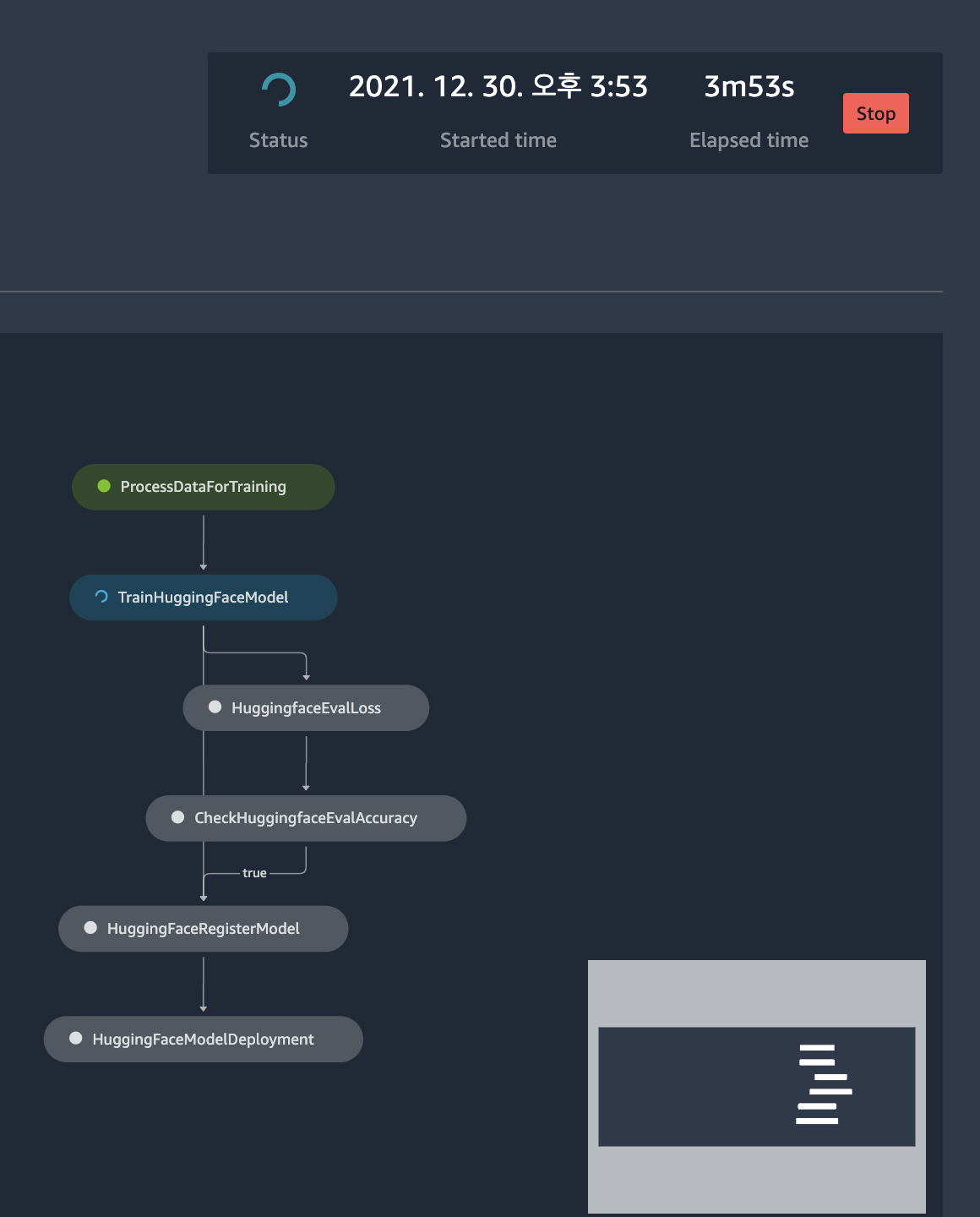"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "815c45d8",
"metadata": {},
"outputs": [],
"source": [
"execution.wait()"
]
},
{
"cell_type": "markdown",
"id": "61d1db77",
"metadata": {},
"source": [
"ì‹¤í–‰ëœ ìŠ¤í…ë“¤ì„ ë¦¬ìŠ¤íŠ¸ì—…í•©ë‹ˆë‹¤."
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "421ab6aa",
"metadata": {},
"outputs": [],
"source": [
"execution.list_steps()"
]
},
{
"cell_type": "markdown",
"id": "6f35313d",
"metadata": {},
"source": [
"<br>\n",
"\n",
"## 3. Getting predictions from the endpoint\n",
"---\n",
"\n",
"파ì´í”„ë¼ì¸ì˜ ëª¨ë“ ë‹¨ê³„ê°€ ì •ìƒì 으로 실행ë˜ì—ˆë‹¤ë©´ ë°°í¬ëœ 엔드í¬ì¸íŠ¸ë¥¼ 통해 실시간 ì¶”ë¡ ì„ ìˆ˜í–‰í• ìˆ˜ 있습니다."
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "7674b919",
"metadata": {},
"outputs": [],
"source": [
"from sagemaker.huggingface import HuggingFacePredictor\n",
"endpoint_name = model_name\n",
"\n",
"# check if endpoint is up and running\n",
"print(f\"https://console.aws.amazon.com/sagemaker/home?region={region}#/endpoints/{endpoint_name}\")\n",
"hf_predictor = HuggingFacePredictor(endpoint_name,sagemaker_session=sagemaker_session)"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "2eeb64c5",
"metadata": {},
"outputs": [],
"source": [
"# example request, you always need to define \"inputs\"\n",
"data = {\n",
" \"inputs\": [\n",
" \"ì •ë§ ìž¬ë¯¸ìžˆìŠµë‹ˆë‹¤. 세 번 ë´ë„ 질리지 ì•Šì•„ìš”.\",\n",
" \"ì‹œê°„ì´ ì•„ê¹ìŠµë‹ˆë‹¤. 다른 ì˜í™”를 보세요.\"\n",
" ]\n",
"}\n",
"hf_predictor.predict(data)"
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "c8d0beeb",
"metadata": {},
"outputs": [],
"source": [
"data = {\n",
" \"inputs\": [\n",
" \"10ì 만ì ì— 1ì 만 줄께요.\",\n",
" \"ë‚´ìš©ì´ ë„ˆë¬´ ì•„ë¥¸ê±°ë ¤ì„œ ìž ì„ ì´ë£° 수가 없었어요. ê°ë™ì˜ 향연!\",\n",
" \"액션광ì´ê¸°ì— ë‚´ìš©ì„ ê¸°ëŒ€í–ˆì§€ë§Œ 앙꼬없는 ì°ë¹µì´ë‹¤\"\n",
" ]\n",
"}\n",
"hf_predictor.predict(data)"
]
},
{
"cell_type": "markdown",
"id": "46d8821d",
"metadata": {},
"source": [
"<br>\n",
"\n",
"## Clean up\n",
"---\n",
"\n",
"ê³¼ê¸ˆì„ ë°©ì§€í•˜ê¸° 위해 사용하지 않는 리소스를 ì‚ì œí•©ë‹ˆë‹¤. 아래 ì½”ë“œì…€ì€ Lambda 함수와 엔드í¬ì¸íŠ¸ë¥¼ ì‚ì œí•©ë‹ˆë‹¤. "
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "491afc1c",
"metadata": {},
"outputs": [],
"source": [
"sm_client = boto3.client(\"sagemaker\")\n",
"\n",
"# Delete the Lambda function\n",
"step_deployment.func.delete()\n",
"\n",
"# Delete the endpoint\n",
"hf_predictor.delete_endpoint()"
]
}
],
"metadata": {
"kernelspec": {
"display_name": "conda_pytorch_latest_p37",
"language": "python",
"name": "conda_pytorch_latest_p37"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.7.12"
}
},
"nbformat": 4,
"nbformat_minor": 5
}