{
"cells": [
{
"attachments": {},
"cell_type": "markdown",
"metadata": {},
"source": [
"# Leverage deployment guardrails to update a SageMaker Inference endpoint using linear traffic shifting\n"
]
},
{
"attachments": {},
"cell_type": "markdown",
"metadata": {},
"source": [
"---\n",
"\n",
"This notebook's CI test result for us-west-2 is as follows. CI test results in other regions can be found at the end of the notebook. \n",
"\n",
"\n",
"\n",
"---"
]
},
{
"attachments": {},
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
"SageMaker Studio Kernel: Data Science"
]
},
{
"attachments": {},
"cell_type": "markdown",
"metadata": {},
"source": [
"# Contents\n",
"\n",
" - [Introduction](#Introduction)\n",
" - [Setup](#Setup)\n",
" - [Step 1: Create and deploy the pre-trained models](#Step1)\n",
" - [Step 2: Invoke Endpoint](#Step2)\n",
" - [Step 3: Create CloudWatch alarms to monitor Endpoint performance](#Step3)\n",
" - [Step 4: Update Endpoint with deployment configurations- Linear Traffic Shifting](#Step4)\n",
" - [Cleanup](#Clenup)"
]
},
{
"attachments": {},
"cell_type": "markdown",
"metadata": {},
"source": [
"# Introduction \n",
"\n",
"Deployment guardrails are a set of model deployment options in Amazon SageMaker Inference to update your machine learning models in production. Using the fully managed deployment guardrails options, you can control the switch from the current model in production to a new one. Traffic shifting modes, such as canary and linear, give you granular control over the traffic shifting process from your current model to the new one during the course of the update. There are also built-in safeguards such as auto-rollbacks that help you catch issues early and take corrective action before they impact production.\n",
"\n",
"We support blue-green deployment with multiple traffic shifting modes. A traffic shifting mode is a configuration that specifies how endpoint traffic is routed to a new fleet containing your updates. The following traffic shifting modes provide you with different levels of control over the endpoint update process:\n",
"\n",
"* **All-At-Once Traffic Shifting** : shifts all of your endpoint traffic from the blue fleet to the green fleet. Once the traffic has shifted to the green fleet, your pre-specified Amazon CloudWatch alarms begin monitoring the green fleet for a set amount of time (the “baking period”). If no alarms are triggered during the baking period, then the blue fleet is terminated.\n",
"* **Canary Traffic Shifting** : lets you shift one small portion of your traffic (a “canary”) to the green fleet and monitor it for a baking period. If the canary succeeds on the green fleet, then the rest of the traffic is shifted from the blue fleet to the green fleet before terminating the blue fleet.\n",
"* **Linear Traffic Shifting** : provides even more customization over how many traffic-shifting steps to make and what percentage of traffic to shift for each step. While canary shifting lets you shift traffic in two steps, linear shifting extends this to n number of linearly spaced steps.\n",
"\n",
"\n",
"The Deployment guardrails for Amazon SageMaker Inference endpoints feature also allows customers to specify conditions/alarms based on Endpoint invocation metrics from CloudWatch to detect model performance regressions and trigger automatic rollback.\n",
"\n",
"In this notebook we'll update endpoint with following deployment configurations:\n",
" * Blue/Green update policy with **Linear traffic shifting option**\n",
" * Configure CloudWatch alarms to monitor model performance and trigger auto-rollback action.\n",
" \n",
"To demonstrate Linear deployments and the auto-rollback feature, we will update an Endpoint with an incompatible model version and deploy it as a Linear fleet, taking a small percentage of the traffic. Requests sent to this Linear fleet will result in errors, which will be used to trigger a rollback using pre-specified CloudWatch alarms. Finally, we will also demonstrate a success scenario where no alarms are tripped and the update succeeds. \n",
"\n",
"This notebook is organized in 4 steps -\n",
"* Step 1 creates the models and Endpoint Configurations required for the 3 scenarios - the baseline, the update containing the incompatible model version and the update containing the correct model version. \n",
"* Step 2 invokes the baseline Endpoint prior to the update. \n",
"* Step 3 specifies the CloudWatch alarms used to trigger the rollbacks. \n",
"* Finally in step 4, we update the endpoint to trigger a rollback and demonstrate a successful update. "
]
},
{
"attachments": {},
"cell_type": "markdown",
"metadata": {},
"source": [
"# Setup \n",
"\n",
"First we ensure we have an updated version of boto3, which includes the latest SageMaker features:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"!pip install -U awscli\n",
"!pip install sagemaker"
]
},
{
"attachments": {},
"cell_type": "markdown",
"metadata": {},
"source": [
"Let's set up some required imports and basic initial variables:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"%matplotlib inline\n",
"\n",
"import time\n",
"import os\n",
"import boto3\n",
"import botocore\n",
"import re\n",
"import json\n",
"from datetime import datetime, timedelta, timezone\n",
"from sagemaker import get_execution_role, session\n",
"from sagemaker.s3 import S3Downloader, S3Uploader\n",
"\n",
"region = boto3.Session().region_name\n",
"\n",
"# You can use a different IAM role with SageMakerFullAccess policy for this notebook\n",
"role = get_execution_role()\n",
"print(f\"Execution role: {role}\")\n",
"\n",
"sm_session = session.Session(boto3.Session())\n",
"sm = boto3.Session().client(\"sagemaker\")\n",
"sm_runtime = boto3.Session().client(\"sagemaker-runtime\")\n",
"\n",
"# You can use a different bucket, but make sure the role you chose for this notebook\n",
"# has the s3:PutObject permissions. This is the bucket into which the model artifacts will be uploaded\n",
"bucket = sm_session.default_bucket()\n",
"prefix = \"sagemaker/DEMO-Deployment-Guardrails-Linear\""
]
},
{
"attachments": {},
"cell_type": "markdown",
"metadata": {},
"source": [
"Download the Input files and pre-trained model from S3 bucket"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"!mkdir model\n",
"s3 = boto3.client(\"s3\")\n",
"s3.download_file(\n",
" f\"sagemaker-example-files-prod-{region}\",\n",
" \"models/xgb-churn/xgb-churn-prediction-model.tar.gz\",\n",
" \"model/xgb-churn-prediction-model.tar.gz\",\n",
")\n",
"s3.download_file(\n",
" f\"sagemaker-example-files-prod-{region}\",\n",
" \"models/xgb-churn/xgb-churn-prediction-model2.tar.gz\",\n",
" \"model/xgb-churn-prediction-model2.tar.gz\",\n",
")\n",
"\n",
"!mkdir test_data\n",
"s3.download_file(\n",
" f\"sagemaker-example-files-prod-{region}\",\n",
" \"datasets/tabular/xgb-churn/test-dataset.csv\",\n",
" \"test_data/test-dataset.csv\",\n",
")\n",
"s3.download_file(\n",
" f\"sagemaker-example-files-prod-{region}\",\n",
" \"datasets/tabular/xgb-churn/test-dataset-input-cols.csv\",\n",
" \"test_data/test-dataset-input-cols.csv\",\n",
")"
]
},
{
"attachments": {},
"cell_type": "markdown",
"metadata": {},
"source": [
"# Step 1: Create and deploy the models \n",
"\n",
"### First, we upload our pre-trained models to Amazon S3\n",
"This code uploads two pre-trained XGBoost models that are ready for you to deploy. These models were trained using the [XGB Churn Prediction Notebook](https://github.com/aws/amazon-sagemaker-examples/blob/master/introduction_to_applying_machine_learning/xgboost_customer_churn/xgboost_customer_churn.ipynb) in SageMaker. You can also use your own pre-trained models in this step. If you already have a pretrained model in Amazon S3, you can add it by specifying the s3_key.\n",
"\n",
"The models in this example are used to predict the probability of a mobile customer leaving their current mobile operator. The dataset we use is publicly available and was mentioned in the book [Discovering Knowledge in Data](https://www.amazon.com/dp/0470908742/) by Daniel T. Larose. It is attributed by the author to the University of California Irvine Repository of Machine Learning Datasets."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"model_url = S3Uploader.upload(\n",
" local_path=\"model/xgb-churn-prediction-model.tar.gz\",\n",
" desired_s3_uri=f\"s3://{bucket}/{prefix}\",\n",
")\n",
"model_url2 = S3Uploader.upload(\n",
" local_path=\"model/xgb-churn-prediction-model2.tar.gz\",\n",
" desired_s3_uri=f\"s3://{bucket}/{prefix}\",\n",
")\n",
"\n",
"print(f\"Model URI 1: {model_url}\")\n",
"print(f\"Model URI 2: {model_url2}\")"
]
},
{
"attachments": {},
"cell_type": "markdown",
"metadata": {},
"source": [
"### Next, we create our model definitions\n",
"Start with deploying the pre-trained churn prediction models. Here, you create the model objects with the image and model data."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"from sagemaker import image_uris\n",
"\n",
"image_uri = image_uris.retrieve(\"xgboost\", boto3.Session().region_name, \"0.90-1\")\n",
"\n",
"# Using newer version of XGBoost which is incompatible, in order to simulate model faults\n",
"image_uri2 = image_uris.retrieve(\"xgboost\", boto3.Session().region_name, \"1.2-1\")\n",
"image_uri3 = image_uris.retrieve(\"xgboost\", boto3.Session().region_name, \"0.90-2\")\n",
"\n",
"print(f\"Model Image 1: {image_uri}\")\n",
"print(f\"Model Image 2: {image_uri2}\")\n",
"print(f\"Model Image 3: {image_uri3}\")"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"model_name = f\"DEMO-xgb-churn-pred-{datetime.now():%Y-%m-%d-%H-%M-%S}\"\n",
"model_name2 = f\"DEMO-xgb-churn-pred2-{datetime.now():%Y-%m-%d-%H-%M-%S}\"\n",
"model_name3 = f\"DEMO-xgb-churn-pred3-{datetime.now():%Y-%m-%d-%H-%M-%S}\"\n",
"\n",
"print(f\"Model Name 1: {model_name}\")\n",
"print(f\"Model Name 2: {model_name2}\")\n",
"print(f\"Model Name 3: {model_name3}\")\n",
"\n",
"resp = sm.create_model(\n",
" ModelName=model_name,\n",
" ExecutionRoleArn=role,\n",
" Containers=[{\"Image\": image_uri, \"ModelDataUrl\": model_url}],\n",
")\n",
"print(f\"Created Model: {resp}\")\n",
"\n",
"resp = sm.create_model(\n",
" ModelName=model_name2,\n",
" ExecutionRoleArn=role,\n",
" Containers=[{\"Image\": image_uri2, \"ModelDataUrl\": model_url2}],\n",
")\n",
"print(f\"Created Model: {resp}\")\n",
"\n",
"resp = sm.create_model(\n",
" ModelName=model_name3,\n",
" ExecutionRoleArn=role,\n",
" Containers=[{\"Image\": image_uri3, \"ModelDataUrl\": model_url2}],\n",
")\n",
"print(f\"Created Model: {resp}\")"
]
},
{
"attachments": {},
"cell_type": "markdown",
"metadata": {},
"source": [
"### Create Endpoint Configs\n",
"\n",
"We now create three EndpointConfigs, each with its own different model (these could also have different instance types).\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"ep_config_name = f\"DEMO-EpConfig-1-{datetime.now():%Y-%m-%d-%H-%M-%S}\"\n",
"ep_config_name2 = f\"DEMO-EpConfig-2-{datetime.now():%Y-%m-%d-%H-%M-%S}\"\n",
"ep_config_name3 = f\"DEMO-EpConfig-3-{datetime.now():%Y-%m-%d-%H-%M-%S}\"\n",
"\n",
"print(f\"Endpoint Config 1: {ep_config_name}\")\n",
"print(f\"Endpoint Config 2: {ep_config_name2}\")\n",
"print(f\"Endpoint Config 3: {ep_config_name3}\")\n",
"\n",
"resp = sm.create_endpoint_config(\n",
" EndpointConfigName=ep_config_name,\n",
" ProductionVariants=[\n",
" {\n",
" \"VariantName\": \"AllTraffic\",\n",
" \"ModelName\": model_name,\n",
" \"InstanceType\": \"ml.m5.xlarge\",\n",
" \"InitialInstanceCount\": 3,\n",
" }\n",
" ],\n",
")\n",
"print(f\"Created Endpoint Config: {resp}\")\n",
"time.sleep(5)\n",
"\n",
"resp = sm.create_endpoint_config(\n",
" EndpointConfigName=ep_config_name2,\n",
" ProductionVariants=[\n",
" {\n",
" \"VariantName\": \"AllTraffic\",\n",
" \"ModelName\": model_name2,\n",
" \"InstanceType\": \"ml.m5.xlarge\",\n",
" \"InitialInstanceCount\": 3,\n",
" }\n",
" ],\n",
")\n",
"print(f\"Created Endpoint Config: {resp}\")\n",
"time.sleep(5)\n",
"\n",
"resp = sm.create_endpoint_config(\n",
" EndpointConfigName=ep_config_name3,\n",
" ProductionVariants=[\n",
" {\n",
" \"VariantName\": \"AllTraffic\",\n",
" \"ModelName\": model_name3,\n",
" \"InstanceType\": \"ml.m5.xlarge\",\n",
" \"InitialInstanceCount\": 3,\n",
" }\n",
" ],\n",
")\n",
"print(f\"Created Endpoint Config: {resp}\")\n",
"time.sleep(5)"
]
},
{
"attachments": {},
"cell_type": "markdown",
"metadata": {},
"source": [
"### Create Endpoint\n",
"\n",
"Let's go ahead and deploy the model to a SageMaker endpoint:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"endpoint_name = f\"DEMO-Deployment-Guardrails-Linear-{datetime.now():%Y-%m-%d-%H-%M-%S}\"\n",
"print(f\"Endpoint Name: {endpoint_name}\")\n",
"\n",
"# creating endpoint with the first endpoint config (ep_config_name)\n",
"resp = sm.create_endpoint(EndpointName=endpoint_name, EndpointConfigName=ep_config_name)\n",
"print(f\"\\nCreated Endpoint: {resp}\")"
]
},
{
"attachments": {},
"cell_type": "markdown",
"metadata": {},
"source": [
"Wait for the endpoint creation to complete."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"def wait_for_endpoint_in_service(endpoint_name):\n",
" print(\"Waiting for endpoint in service\")\n",
" while True:\n",
" details = sm.describe_endpoint(EndpointName=endpoint_name)\n",
" status = details[\"EndpointStatus\"]\n",
" if status in [\"InService\", \"Failed\"]:\n",
" print(\"\\nDone!\")\n",
" break\n",
" print(\".\", end=\"\", flush=True)\n",
" time.sleep(30)\n",
"\n",
"\n",
"wait_for_endpoint_in_service(endpoint_name)\n",
"\n",
"sm.describe_endpoint(EndpointName=endpoint_name)"
]
},
{
"attachments": {},
"cell_type": "markdown",
"metadata": {},
"source": [
"# Step 2: Invoke Endpoint \n",
"\n",
"You can now send data to this endpoint to get inferences in real time.\n",
"\n",
"This step invokes the endpoint with included sample data with maximum invocations count and waiting intervals. "
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"def invoke_endpoint(\n",
" endpoint_name, max_invocations=600, wait_interval_sec=1, should_raise_exp=False\n",
"):\n",
" print(f\"Sending test traffic to the endpoint {endpoint_name}. \\nPlease wait...\")\n",
"\n",
" count = 0\n",
" with open(\"test_data/test-dataset-input-cols.csv\", \"r\") as f:\n",
" for row in f:\n",
" payload = row.rstrip(\"\\n\")\n",
" try:\n",
" response = sm_runtime.invoke_endpoint(\n",
" EndpointName=endpoint_name, ContentType=\"text/csv\", Body=payload\n",
" )\n",
" response[\"Body\"].read()\n",
" print(\".\", end=\"\", flush=True)\n",
" except Exception as e:\n",
" print(\"E\", end=\"\", flush=True)\n",
" if should_raise_exp:\n",
" raise e\n",
" count += 1\n",
" if count > max_invocations:\n",
" break\n",
" time.sleep(wait_interval_sec)\n",
"\n",
" print(\"\\nDone!\")\n",
"\n",
"\n",
"invoke_endpoint(endpoint_name, max_invocations=100)"
]
},
{
"attachments": {},
"cell_type": "markdown",
"metadata": {},
"source": [
"### Invocations Metrics\n",
"\n",
"Amazon SageMaker emits metrics such as Latency and Invocations (full list of metrics [here](https://docs.aws.amazon.com/sagemaker/latest/dg/monitoring-cloudwatch.html)) per variant and endpoint configuration in Amazon CloudWatch.\n",
"\n",
"Let’s query CloudWatch to get number of Invocations and latency metrics per variant and endpoint configuration."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"import pandas as pd\n",
"\n",
"cw = boto3.Session().client(\"cloudwatch\", region_name=region)\n",
"\n",
"\n",
"def get_sagemaker_metrics(\n",
" endpoint_name,\n",
" endpoint_config_name,\n",
" variant_name,\n",
" metric_name,\n",
" statistic,\n",
" start_time,\n",
" end_time,\n",
"):\n",
" dimensions = [\n",
" {\"Name\": \"EndpointName\", \"Value\": endpoint_name},\n",
" {\"Name\": \"VariantName\", \"Value\": variant_name},\n",
" ]\n",
" if endpoint_config_name is not None:\n",
" dimensions.append({\"Name\": \"EndpointConfigName\", \"Value\": endpoint_config_name})\n",
" metrics = cw.get_metric_statistics(\n",
" Namespace=\"AWS/SageMaker\",\n",
" MetricName=metric_name,\n",
" StartTime=start_time,\n",
" EndTime=end_time,\n",
" Period=60,\n",
" Statistics=[statistic],\n",
" Dimensions=dimensions,\n",
" )\n",
" rename = endpoint_config_name if endpoint_config_name is not None else \"ALL\"\n",
" if len(metrics[\"Datapoints\"]) == 0:\n",
" return\n",
" return (\n",
" pd.DataFrame(metrics[\"Datapoints\"])\n",
" .sort_values(\"Timestamp\")\n",
" .set_index(\"Timestamp\")\n",
" .drop([\"Unit\"], axis=1)\n",
" .rename(columns={statistic: rename})\n",
" )\n",
"\n",
"\n",
"def plot_endpoint_invocation_metrics(\n",
" endpoint_name,\n",
" endpoint_config_name,\n",
" variant_name,\n",
" metric_name,\n",
" statistic,\n",
" start_time=None,\n",
"):\n",
" start_time = start_time or datetime.now(timezone.utc) - timedelta(minutes=60)\n",
" end_time = datetime.now(timezone.utc)\n",
" metrics_variants = get_sagemaker_metrics(\n",
" endpoint_name,\n",
" endpoint_config_name,\n",
" variant_name,\n",
" metric_name,\n",
" statistic,\n",
" start_time,\n",
" end_time,\n",
" )\n",
" if metrics_variants is None:\n",
" return\n",
" metrics_variants.plot(title=f\"{metric_name}-{statistic}\")\n",
" return metrics_variants"
]
},
{
"attachments": {},
"cell_type": "markdown",
"metadata": {},
"source": [
"### Plot endpoint invocation metrics:\n",
"\n",
"Below, we are going to plot graphs to show the Invocations,Invocation4XXErrors,Invocation5XXErrors,ModelLatency and OverheadLatency against the Endpoint.\n",
"\n",
"You will observe that there should be a flat line for Invocation4XXErrors and Invocation5XXErrors as we are using the correct model version and configs. \n",
"Additionally, ModelLatency and OverheadLatency will start decreasing over time."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"invocation_metrics = plot_endpoint_invocation_metrics(\n",
" endpoint_name, ep_config_name, \"AllTraffic\", \"Invocations\", \"Sum\"\n",
")\n",
"invocation_4xx_metrics = plot_endpoint_invocation_metrics(\n",
" endpoint_name, None, \"AllTraffic\", \"Invocation4XXErrors\", \"Sum\"\n",
")\n",
"invocation_5xx_metrics = plot_endpoint_invocation_metrics(\n",
" endpoint_name, None, \"AllTraffic\", \"Invocation5XXErrors\", \"Sum\"\n",
")\n",
"model_latency_metrics = plot_endpoint_invocation_metrics(\n",
" endpoint_name, None, \"AllTraffic\", \"ModelLatency\", \"Average\"\n",
")\n",
"overhead_latency_metrics = plot_endpoint_invocation_metrics(\n",
" endpoint_name, None, \"AllTraffic\", \"OverheadLatency\", \"Average\"\n",
")"
]
},
{
"attachments": {},
"cell_type": "markdown",
"metadata": {},
"source": [
"# Step 3: Create CloudWatch alarms to monitor Endpoint performance \n",
"\n",
"In this step we're going to create CloudWatch alarms to monitor Endpoint performance with following metrics:\n",
"* Invocation5XXErrors\n",
"* ModelLatency\n",
"\n",
"Following metric dimensions are used to select the metric per Endpoint config and variant:\n",
"* EndpointName\n",
"* VariantName\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"def create_auto_rollback_alarm(\n",
" alarm_name, endpoint_name, variant_name, metric_name, statistic, threshold\n",
"):\n",
" cw.put_metric_alarm(\n",
" AlarmName=alarm_name,\n",
" AlarmDescription=\"Test SageMaker endpoint deployment auto-rollback alarm\",\n",
" ActionsEnabled=False,\n",
" Namespace=\"AWS/SageMaker\",\n",
" MetricName=metric_name,\n",
" Statistic=statistic,\n",
" Dimensions=[\n",
" {\"Name\": \"EndpointName\", \"Value\": endpoint_name},\n",
" {\"Name\": \"VariantName\", \"Value\": variant_name},\n",
" ],\n",
" Period=60,\n",
" EvaluationPeriods=1,\n",
" Threshold=threshold,\n",
" ComparisonOperator=\"GreaterThanOrEqualToThreshold\",\n",
" TreatMissingData=\"notBreaching\",\n",
" )"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"error_alarm = f\"TestAlarm-5XXErrors-{endpoint_name}\"\n",
"latency_alarm = f\"TestAlarm-ModelLatency-{endpoint_name}\"\n",
"\n",
"# alarm on 1% 5xx error rate for 1 minute\n",
"create_auto_rollback_alarm(\n",
" error_alarm, endpoint_name, \"AllTraffic\", \"Invocation5XXErrors\", \"Average\", 1\n",
")\n",
"# alarm on model latency >= 10 ms for 1 minute\n",
"create_auto_rollback_alarm(\n",
" latency_alarm, endpoint_name, \"AllTraffic\", \"ModelLatency\", \"Average\", 10000\n",
")"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"cw.describe_alarms(AlarmNames=[error_alarm, latency_alarm])\n",
"time.sleep(60)"
]
},
{
"attachments": {},
"cell_type": "markdown",
"metadata": {},
"source": [
"# Step 4: Update Endpoint with deployment configurations \n",
"\n",
"Now we try to update the endpoint with deployment configurations and monitor the performance from CloudWatch metrics.\n"
]
},
{
"attachments": {},
"cell_type": "markdown",
"metadata": {},
"source": [
"### BlueGreen update policy with Linear traffic shifting\n",
"\n",
"We define the following deployment configuration to perform Blue/Green update strategy with Linear traffic shifting from old to new stack. The Linear traffic shifting option can reduce the blast ratio of a regressive update to the endpoint. In contrast, for the All-At-Once traffic shifting option, the invocation requests start failing at 100% after flipping the traffic. In the Linear mode, invocation requests are shifted to the new version of the model gradually, with a controlled percentage of traffic shifting for each step. You can use the auto-rollback alarms to monitor the metrics during the linear traffic shifting stage."
]
},
{
"attachments": {},
"cell_type": "markdown",
"metadata": {},
"source": [
"### Rollback Case\n",
"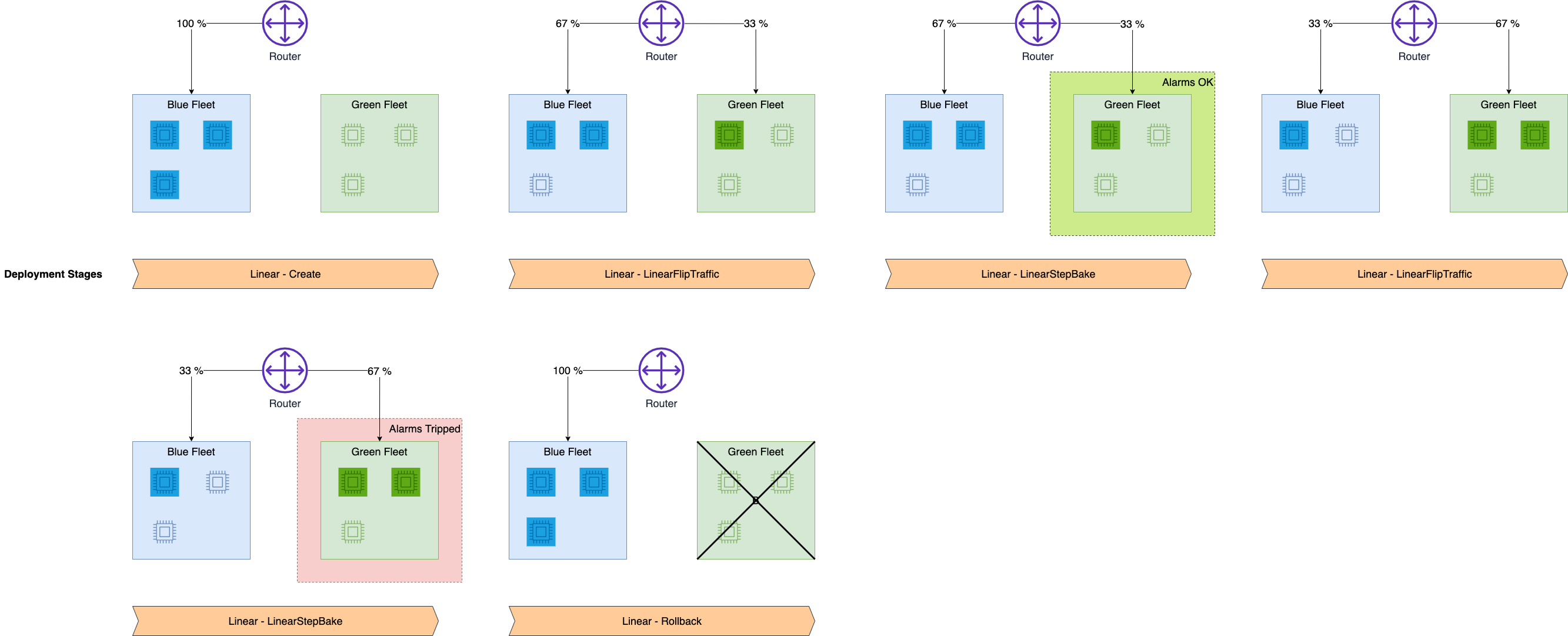\n",
"\n",
"Update the Endpoint with an incompatible model version to simulate errors and trigger a rollback."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"linear_deployment_config = {\n",
" \"BlueGreenUpdatePolicy\": {\n",
" \"TrafficRoutingConfiguration\": {\n",
" \"Type\": \"LINEAR\",\n",
" \"LinearStepSize\": {\n",
" \"Type\": \"CAPACITY_PERCENT\",\n",
" \"Value\": 33, # 33% of whole fleet capacity (33% * 3 = 1 instance)\n",
" },\n",
" \"WaitIntervalInSeconds\": 180, # wait for 3 minutes before enabling traffic on the rest of fleet\n",
" },\n",
" \"TerminationWaitInSeconds\": 120, # wait for 2 minutes before terminating the old stack\n",
" \"MaximumExecutionTimeoutInSeconds\": 1800, # maximum timeout for deployment\n",
" },\n",
" \"AutoRollbackConfiguration\": {\n",
" \"Alarms\": [{\"AlarmName\": error_alarm}, {\"AlarmName\": latency_alarm}],\n",
" },\n",
"}\n",
"\n",
"# update endpoint request with new DeploymentConfig parameter\n",
"sm.update_endpoint(\n",
" EndpointName=endpoint_name,\n",
" EndpointConfigName=ep_config_name2,\n",
" DeploymentConfig=linear_deployment_config,\n",
")"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"sm.describe_endpoint(EndpointName=endpoint_name)"
]
},
{
"attachments": {},
"cell_type": "markdown",
"metadata": {},
"source": [
"### We invoke the endpoint during the update operation is in progress.\n",
"\n",
"**Note : Invoke endpoint in this notebook is in single thread mode, to stop the invoke requests please stop the cell execution**\n",
"\n",
"The E's denote the errors generated from the incompatible model version in the linear fleet.\n",
"\n",
"The purpose of the below cell is to simulate errors in the linear fleet. Since the nature of traffic shifting to the linear fleet is probabilistic, you should wait until you start seeing errors. Then, you may proceed to stop the execution of the below cell. If not aborted, cell will run for 600 invocations."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"invoke_endpoint(endpoint_name)"
]
},
{
"attachments": {},
"cell_type": "markdown",
"metadata": {},
"source": [
"Wait for the update operation to complete and verify the automatic rollback."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"wait_for_endpoint_in_service(endpoint_name)\n",
"\n",
"sm.describe_endpoint(EndpointName=endpoint_name)"
]
},
{
"attachments": {},
"cell_type": "markdown",
"metadata": {},
"source": [
"Collect the endpoint metrics during the deployment:\n",
"\n",
"Below, we are going to plot graphs to show the Invocations,Invocation5XXErrors and ModelLatency against the Endpoint.\n",
"\n",
"You can expect to see as the new endpoint config-2 (erroneous due to model version) starts getting deployed, it encounters failure and leads to the rollback to endpoint config-1. This can be seen in the graphs below as the Invocation5XXErrors and ModelLatency increases during this rollback phase\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"invocation_metrics = plot_endpoint_invocation_metrics(\n",
" endpoint_name, None, \"AllTraffic\", \"Invocations\", \"Sum\"\n",
")\n",
"metrics_epc_1 = plot_endpoint_invocation_metrics(\n",
" endpoint_name, ep_config_name, \"AllTraffic\", \"Invocations\", \"Sum\"\n",
")\n",
"metrics_epc_2 = plot_endpoint_invocation_metrics(\n",
" endpoint_name, ep_config_name2, \"AllTraffic\", \"Invocations\", \"Sum\"\n",
")\n",
"\n",
"metrics_all = invocation_metrics.join([metrics_epc_1, metrics_epc_2], how=\"outer\")\n",
"metrics_all.plot(title=\"Invocations-Sum\")\n",
"\n",
"invocation_5xx_metrics = plot_endpoint_invocation_metrics(\n",
" endpoint_name, None, \"AllTraffic\", \"Invocation5XXErrors\", \"Sum\"\n",
")\n",
"model_latency_metrics = plot_endpoint_invocation_metrics(\n",
" endpoint_name, None, \"AllTraffic\", \"ModelLatency\", \"Average\"\n",
")"
]
},
{
"attachments": {},
"cell_type": "markdown",
"metadata": {},
"source": [
"Let's take a look at the Success case where we use the same Linear deployment configuration but a valid endpoint configuration.\n",
"\n",
"### Success Case\n",
"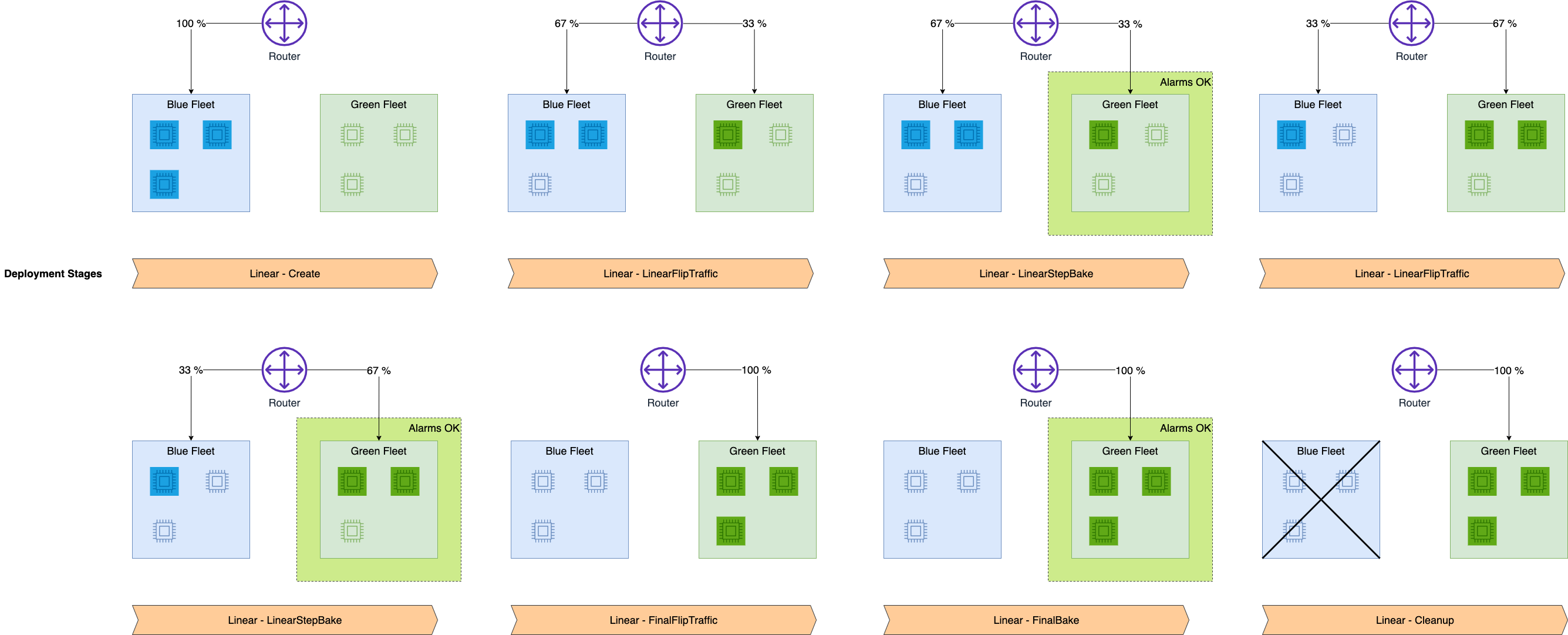"
]
},
{
"attachments": {},
"cell_type": "markdown",
"metadata": {},
"source": [
"Now let's update the endpoint to a valid endpoint configuration version with the same Linear deployment configuration:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# update endpoint with a valid version of DeploymentConfig\n",
"\n",
"sm.update_endpoint(\n",
" EndpointName=endpoint_name,\n",
" EndpointConfigName=ep_config_name3,\n",
" RetainDeploymentConfig=True,\n",
")"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"sm.describe_endpoint(EndpointName=endpoint_name)"
]
},
{
"attachments": {},
"cell_type": "markdown",
"metadata": {},
"source": [
"We invoke the endpoint during the update operation is in progress:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"invoke_endpoint(endpoint_name, max_invocations=500)"
]
},
{
"attachments": {},
"cell_type": "markdown",
"metadata": {},
"source": [
"Wait for the update operation to complete:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"wait_for_endpoint_in_service(endpoint_name)\n",
"\n",
"sm.describe_endpoint(EndpointName=endpoint_name)"
]
},
{
"attachments": {},
"cell_type": "markdown",
"metadata": {},
"source": [
"Collect the endpoint metrics during the deployment:\n",
"\n",
"Below, we are going to plot graphs to show the Invocations,Invocation5XXErrors and ModelLatency against the Endpoint.\n",
"\n",
"You can expect to see that, as the new endpoint config-3 (correct model version) starts getting deployed, it takes over endpoint config-2 (erroneous due to model version) without any errors. This can be seen in the graphs below as the Invocation5XXErrors and ModelLatency decreases during this transition phase\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"invocation_metrics = plot_endpoint_invocation_metrics(\n",
" endpoint_name, None, \"AllTraffic\", \"Invocations\", \"Sum\"\n",
")\n",
"metrics_epc_1 = plot_endpoint_invocation_metrics(\n",
" endpoint_name, ep_config_name, \"AllTraffic\", \"Invocations\", \"Sum\"\n",
")\n",
"metrics_epc_2 = plot_endpoint_invocation_metrics(\n",
" endpoint_name, ep_config_name2, \"AllTraffic\", \"Invocations\", \"Sum\"\n",
")\n",
"metrics_epc_3 = plot_endpoint_invocation_metrics(\n",
" endpoint_name, ep_config_name3, \"AllTraffic\", \"Invocations\", \"Sum\"\n",
")\n",
"\n",
"metrics_all = invocation_metrics.join([metrics_epc_1, metrics_epc_2, metrics_epc_3], how=\"outer\")\n",
"metrics_all.plot(title=\"Invocations-Sum\")\n",
"\n",
"invocation_5xx_metrics = plot_endpoint_invocation_metrics(\n",
" endpoint_name, None, \"AllTraffic\", \"Invocation5XXErrors\", \"Sum\"\n",
")\n",
"model_latency_metrics = plot_endpoint_invocation_metrics(\n",
" endpoint_name, None, \"AllTraffic\", \"ModelLatency\", \"Average\"\n",
")"
]
},
{
"attachments": {},
"cell_type": "markdown",
"metadata": {},
"source": [
"The Amazon CloudWatch metrics for the total invocations for each endpoint config shows how invocation requests are shifted from the old version to the new version during deployment.\n",
"\n",
"You can now safely update your endpoint and monitor model regressions during deployment and trigger auto-rollback action."
]
},
{
"attachments": {},
"cell_type": "markdown",
"metadata": {},
"source": [
"# Cleanup \n",
"\n",
"If you do not plan to use this endpoint further, you should delete the endpoint to avoid incurring additional charges.\n",
"\n",
"You should also clean up the other resources created in this notebook: endpoint configurations, models, and CloudWatch alarms."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"scrolled": true
},
"outputs": [],
"source": [
"sm.delete_endpoint(EndpointName=endpoint_name)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"sm.delete_endpoint_config(EndpointConfigName=ep_config_name)\n",
"sm.delete_endpoint_config(EndpointConfigName=ep_config_name2)\n",
"sm.delete_endpoint_config(EndpointConfigName=ep_config_name3)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"sm.delete_model(ModelName=model_name)\n",
"sm.delete_model(ModelName=model_name2)\n",
"sm.delete_model(ModelName=model_name3)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"cw.delete_alarms(AlarmNames=[error_alarm, latency_alarm])"
]
},
{
"attachments": {},
"cell_type": "markdown",
"metadata": {},
"source": [
"## Notebook CI Test Results\n",
"\n",
"This notebook was tested in multiple regions. The test results are as follows, except for us-west-2 which is shown at the top of the notebook.\n",
"\n",
"\n",
"\n",
"\n",
"\n",
"\n",
"\n",
"\n",
"\n",
"\n",
"\n",
"\n",
"\n",
"\n",
"\n",
"\n",
"\n",
"\n",
"\n",
"\n",
"\n",
"\n",
"\n",
"\n",
"\n",
"\n",
"\n",
"\n",
"\n",
"\n"
]
}
],
"metadata": {
"anaconda-cloud": {},
"instance_type": "ml.t3.medium",
"kernelspec": {
"display_name": "Python 3 (Data Science 3.0)",
"language": "python",
"name": "python3__SAGEMAKER_INTERNAL__arn:aws:sagemaker:us-east-1:081325390199:image/sagemaker-data-science-310-v1"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.10.6"
},
"notice": "Copyright 2017 Amazon.com, Inc. or its affiliates. All Rights Reserved. Licensed under the Apache License, Version 2.0 (the \"License\"). You may not use this file except in compliance with the License. A copy of the License is located at http://aws.amazon.com/apache2.0/ or in the \"license\" file accompanying this file. This file is distributed on an \"AS IS\" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License."
},
"nbformat": 4,
"nbformat_minor": 4
}