{
"cells": [
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Train GPT-J 6B using the sharded data parallelism and tensor parallelism techniques in the SageMaker Model Parallel library\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"---\n",
"\n",
"This notebook's CI test result for us-west-2 is as follows. CI test results in other regions can be found at the end of the notebook. \n",
"\n",
"\n",
"\n",
"---"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"*Please run this notebook with Data Science-> Python 3 Kernel on SageMaker Studio Notebook or a conda_pytorch_p38 Kernel on SageMaker Notebook instances.*\n",
"\n",
"This notebook walks you through how to use [Sharded Data Parallelism](https://docs.aws.amazon.com/sagemaker/latest/dg/model-parallel-extended-features-pytorch-sharded-data-parallelism.html) and [Tensor Parallelism](https://docs.aws.amazon.com/sagemaker/latest/dg/model-parallel-extended-features-pytorch-tensor-parallelism.html) provided by the SageMaker Model Parallelism (SMP) library. You'll learn how to train the [EleutherAI's](https://www.eleuther.ai/) [GPT-J](https://arankomatsuzaki.wordpress.com/2021/06/04/gpt-j/) model with PyTorch 1.13 and [GLUE/SST2 dataset](https://huggingface.co/datasets/glue/viewer/sst2/train) on SageMaker.\n",
"\n",
"EleutherAI released GPT-J 6B, an open-source alternative to [OpenAI GPT-3](https://openai.com/blog/gpt-3-apps/). [GPT-J 6B](https://huggingface.co/EleutherAI/gpt-j-6B) is the 6 billion parameter successor to EleutherAI's GPT-NEO family, a family of transformer-based language models based on the GPT architecture for text generation.\n",
"\n",
"EleutherAI's primary goal is to train a model that is equivalent in size to GPT-3 and make it available to the public under an open license.\n",
"Over the last few months, GPT-J gained a lot of interest from Researchers, Data Scientists, and even Software Developers, but it remained very challenging to fine tune GPT-J.\n",
"\n",
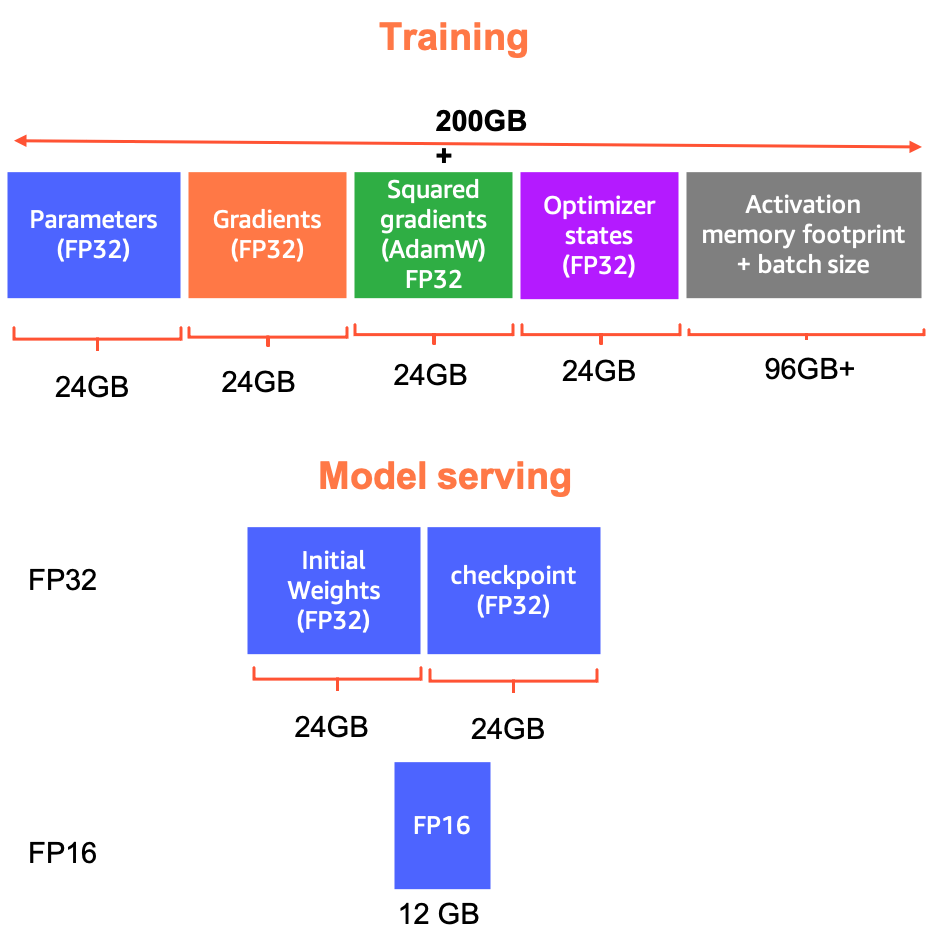
"The weights of the 6-billion-parameter model represent a ~24GB memory footprint. To load it in Float32, one would need at least 2x model size CPU RAM: 1x for initial weights and another 1x to load the checkpoint. Apart from the model parameters, there are the gradients, optimizer states, and activations taking memory, so the actual memory usage might be significantly higher than 48GB. Just as an example, with Adam optimizer and FP32 training, the use from parameters, gradients and optimizer states might be 96GB+, and activation memory footprint would be even more than this, so the total memory usage might be easily larger than 200 GB.\n",
"\n",
"\n",
"\n",
"In this notebook, you will learn how to easily train or fine-tune GPT-J using Amazon SageMaker and Amazon EC2 NVIDIA GPU instances. The notebook demonstrates the use of sharded data parallelism and tensor parallelism of the SMP library.\n",
"\n",
"This notebook consists of the following files and folders:\n",
"\n",
"1. `train.py`: This is an example training script that you'll run using the PyTorch estimator. This script is shows an end-to-end example of training the GPT-J model with SMP. The script has additional comments at places where the SMP tools are implemented.\n",
"3. `learning_rates.py`: This contains the functions for learning rate schedule.\n",
"4. `requirements.txt`: This will install the dependencies, like the right version of huggingface transformers.\n",
"5. `memory_tracker.py`: This contains a function to print the memory status.\n",
"\n",
"\n",
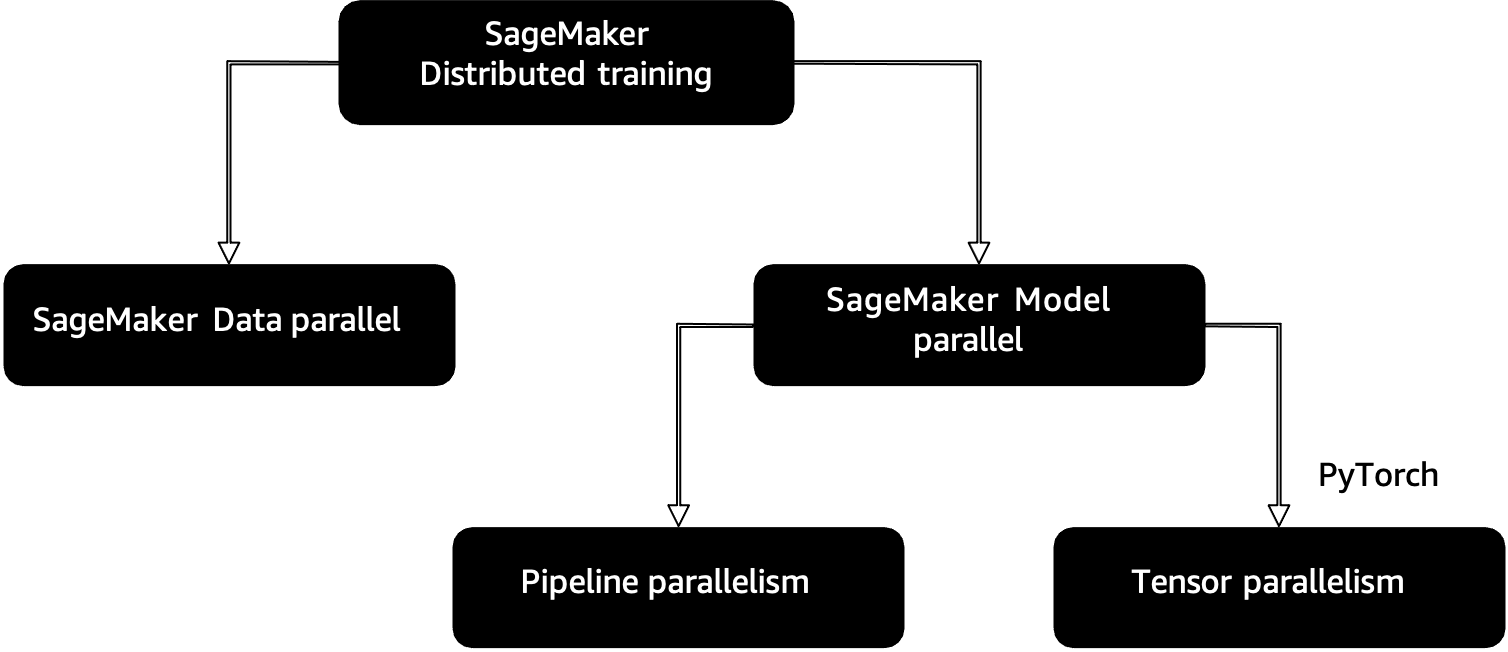
"## SageMaker Distributed Training \n",
"\n",
"SageMaker provides distributed training libraries for data parallelism and model parallelism. The libraries are optimized for the SageMaker training environment, help adapt your distributed training jobs to SageMaker, and improve training speed and throughput.\n",
"\n",
"### Approaches\n",
"\n",
"\n",
"\n",
"\n",
"### SageMaker Model Parallel\n",
"\n",
"Model parallelism is the process of splitting a model up between multiple devices or nodes (such as GPU-equipped instances) and creating an efficient pipeline to train the model across these devices to maximize GPU utilization.\n",
"\n",
"Increasing deep learning model size (layers and parameters) can result in better accuracy. However, there is a limit to the maximum model size you can fit in a single GPU. When training deep learning models, GPU memory limitations can be a bottleneck in the following ways:\n",
"\n",
"1. They can limit the size of the model you train. Given that larger models tend to achieve higher accuracy, this directly translates to trained model accuracy.\n",
"\n",
"2. They can limit the batch size you train with, leading to lower GPU utilization and slower training.\n",
"\n",
"To overcome the limitations associated with training a model on a single GPU, you can use model parallelism to distribute and train your model on multiple computing devices.\n",
"\n",
"### Core features of SageMaker Model Parallel \n",
"\n",
"The following are the core features of the SMP library.\n",
"\n",
"* [Sharded Data Parallelism](https://docs.aws.amazon.com/sagemaker/latest/dg/model-parallel-extended-features-pytorch-sharded-data-parallelism.html)\n",
"* [Pipelining a Model](https://docs.aws.amazon.com/sagemaker/latest/dg/model-parallel-core-features-pipieline-parallelism.html)\n",
"* [Tensor Parallelism](https://docs.aws.amazon.com/sagemaker/latest/dg/model-parallel-extended-features-pytorch-tensor-parallelism.html)\n",
"* [Optimizer State Sharding](https://docs.aws.amazon.com/sagemaker/latest/dg/model-parallel-extended-features-pytorch-optimizer-state-sharding.html)\n",
"* [Activation Checkpointing](https://docs.aws.amazon.com/sagemaker/latest/dg/model-parallel-extended-features-pytorch-activation-checkpointing.html)\n",
"* [Activation Offloading](https://docs.aws.amazon.com/sagemaker/latest/dg/model-parallel-extended-features-pytorch-activation-offloading.html)\n",
"* [FP16 Training with Model Parallelism](https://docs.aws.amazon.com/sagemaker/latest/dg/model-parallel-extended-features-pytorch-fp16.html)\n",
"* [Support for FlashAttention](https://docs.aws.amazon.com/sagemaker/latest/dg/model-parallel-attention-head-size-for-flash-attention.html)\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### SageMaker Model Parallel configuration\n",
"\n",
"Please refer to all the [configuration parameters](https://sagemaker.readthedocs.io/en/stable/api/training/smd_model_parallel_general.html) related to SageMaker Distributed Training.\n",
"\n",
"As we are going to use PyTorch and Hugging Face for training GPT-J, it is important to understand all the SageMaker Distributed configuration parameters specific to PyTorch [here](https://sagemaker.readthedocs.io/en/stable/api/training/smd_model_parallel_general.html#pytorch-specific-parameters).\n",
"\n",
"#### Important\n",
"\n",
"`process_per_host` must not be greater than the number of GPUs per instance and typically will be equal to the number of GPUs per instance.\n",
"\n",
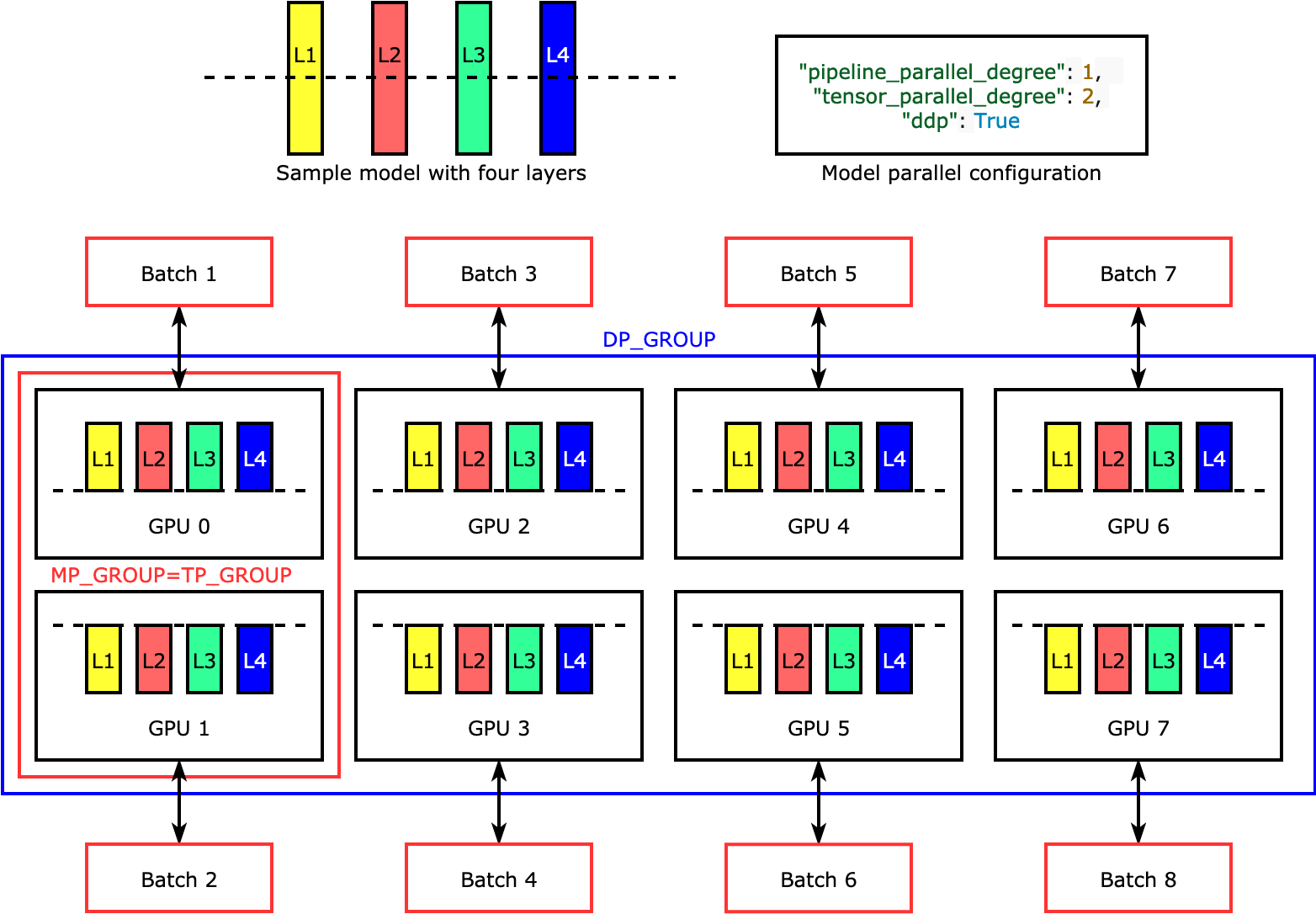
"#### SageMaker Tensor Parallel\n",
"\n",
"Tensor parallelism splits individual layers, or nn.Modules, across devices, to be run in parallel. The following figure shows the simplest example of how the library splits a model with four layers to achieve two-way tensor parallelism (\"tensor_parallel_degree\": 2). The layers of each model replica are bisected and distributed into two GPUs. In this example case, the model parallel configuration also includes \"pipeline_parallel_degree\": 1 and \"ddp\": True (uses PyTorch DistributedDataParallel package in the background), so the degree of data parallelism becomes eight. The library manages communication across the tensor-distributed model replicas.\n",
"\n",
"\n",
"\n",
"The usefulness of this feature is in the fact that you can select specific layers or a subset of layers to apply tensor parallelism. To dive deep into tensor parallelism and other memory-saving features for PyTorch, and to learn how to set a combination of pipeline and tensor parallelism, see Extended Features of the SageMaker Model Parallel Library for PyTorch.\n",
"\n",
"\n",
"\n",
"#### Additional Resources\n",
"If you are a new user of Amazon SageMaker, you may find the following helpful to learn more about SMP and using SageMaker with PyTorch.\n",
"\n",
"1. To learn more about the SageMaker model parallelism library, see [Model Parallel Distributed Training with SageMaker Distributed](https://docs.aws.amazon.com/sagemaker/latest/dg/model-parallel.html).\n",
"\n",
"2. To learn more about using the SageMaker Python SDK with PyTorch, see Using [PyTorch with the SageMaker Python SDK](https://sagemaker.readthedocs.io/en/stable/frameworks/pytorch/using_pytorch.html).\n",
"\n",
"3. To learn more about launching a training job in Amazon SageMaker with your own training image, see [Use Your Own Training Algorithms](https://docs.aws.amazon.com/sagemaker/latest/dg/your-algorithms-training-algo.html)."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Install and Upgrade Libraries\n",
"\n",
"The SageMaker model parallelism library's tensor parallelism feature requires the SageMaker Python SDK and the SageMaker Experiments library. Run the following cell to install or upgrade the libraries.\n",
"\n",
"**Note:** To finish applying the changes, you must restart the kernel."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"scrolled": true
},
"outputs": [],
"source": [
"# run once, restart kernel, then comment out this cell\n",
"! pip install -qU pip\n",
"! pip install -qU \"sagemaker>=2,<3\"\n",
"! pip install -qU sagemaker-experiments\n",
"! pip install -qU transformers datasets\n",
"! pip install -qU 'sagemaker[local]' --upgrade\n",
"\n",
"import IPython\n",
"\n",
"IPython.Application.instance().kernel.do_shutdown(True)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Important: After you run the above cell, comment it out for future runs.\n",
"\n",
"Import and check if the SageMaker Python SDK version is successfully set to the latest version"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"import sagemaker\n",
"\n",
"print(sagemaker.__version__)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Amazon SageMaker Initialization"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Run the following cell to import SageMaker modules and retrieve information of your current SageMaker work environment: your AWS account ID, the AWS Region you are using to run the notebook, and the ARN of your Amazon SageMaker execution role."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"%%time\n",
"import os\n",
"\n",
"from sagemaker import get_execution_role\n",
"from sagemaker.huggingface import HuggingFace\n",
"from smexperiments.experiment import Experiment\n",
"from smexperiments.trial import Trial\n",
"import sagemaker\n",
"import boto3\n",
"\n",
"\n",
"def get_notebook_name():\n",
" import json\n",
"\n",
" log_path = \"/opt/ml/metadata/resource-metadata.json\"\n",
" with open(log_path, \"r\") as logs:\n",
" _logs = json.load(logs)\n",
" return _logs[\"ResourceName\"]\n",
"\n",
"\n",
"role = (\n",
" get_execution_role()\n",
") # provide a pre-existing role ARN as an alternative to creating a new role\n",
"print(f\"SageMaker Execution Role:{role}\")\n",
"\n",
"client = boto3.client(\"sts\")\n",
"account = client.get_caller_identity()[\"Account\"]\n",
"print(f\"AWS account:{account}\")\n",
"\n",
"session = boto3.session.Session()\n",
"region = session.region_name\n",
"print(f\"AWS region:{region}\")\n",
"\n",
"sm_boto_client = boto3.client(\"sagemaker\")\n",
"\n",
"sagemaker_session = sagemaker.session.Session(boto_session=session)\n",
"\n",
"\n",
"# get default bucket\n",
"default_bucket = sagemaker_session.default_bucket()\n",
"print()\n",
"print(\"Default bucket for this session: \", default_bucket)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"_This completes the SageMaker setup._"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Download and prepare glue-sst2 data\n",
"Here you will download and prepare the GLUE/SST2 dataset, and then copy the files to S3. Note that the `train.py` script is prepared to use either S3 input or paths in an FSx file system as the data source."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Install and import the Hugging Face Transformers and Datasets libraries"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"! pip install -q datasets transformers==4.21.0"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"import datasets\n",
"from datasets import load_dataset, load_from_disk, load_metric"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"from sagemaker.pytorch import PyTorch\n",
"import transformers\n",
"import logging\n",
"\n",
"from transformers import (\n",
" AutoModelForCausalLM,\n",
" AutoTokenizer,\n",
")\n",
"\n",
"from transformers.testing_utils import CaptureLogger"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"logger = logging.getLogger(__name__)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Load data\n",
"This section loads the [GLUE/SST2](https://huggingface.co/datasets/glue/viewer/sst2/train) dataset and splits it to training and validation datasets."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"hyperparameters = {\n",
" \"dataset_name\": \"glue\",\n",
" \"dataset_config_name\": \"sst2\",\n",
" \"do_train\": True,\n",
" \"do_eval\": True,\n",
" \"cache_dir\": \"tmp\",\n",
"}"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"raw_datasets = load_dataset(\n",
" hyperparameters[\"dataset_name\"],\n",
" hyperparameters[\"dataset_config_name\"],\n",
")"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"if \"validation\" not in raw_datasets.keys():\n",
" raw_datasets[\"validation\"] = load_dataset(\n",
" hyperparameters[\"dataset_name\"],\n",
" hyperparameters[\"dataset_config_name\"],\n",
" split=\"train[:5%]\",\n",
" cache_dir=hyperparameters[\"cache_dir\"],\n",
" )\n",
"\n",
" raw_datasets[\"train\"] = load_dataset(\n",
" hyperparameters[\"dataset_name\"],\n",
" hyperparameters[\"dataset_config_name\"],\n",
" split=\"train[5%:]\",\n",
" cache_dir=hyperparameters[\"cache_dir\"],\n",
" )"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Load tokenizer\n",
"Nearly every NLP task begins with a tokenizer. A tokenizer converts your text data into a format (token) that can be processed by the NLP model.\n",
"The following cell loads a tokenizer for GPT-J using [AutoTokenizer.from_pretrained()](https://huggingface.co/docs/transformers/v4.19.4/en/autoclass_tutorial#autotokenizer)."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"scrolled": true
},
"outputs": [],
"source": [
"tokenizer_kwargs = {\n",
" \"cache_dir\": hyperparameters[\"cache_dir\"],\n",
"}\n",
"\n",
"tokenizer = AutoTokenizer.from_pretrained(\"EleutherAI/gpt-j-6b\", **tokenizer_kwargs)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Preprocess data\n",
"\n",
"The following two cells set up a function to run the tokenizer and group texts into chunks smaller than the block size."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"def tokenize_function(examples):\n",
" tok_logger = transformers.utils.logging.get_logger(\"transformers.tokenization_utils_base\")\n",
"\n",
" with CaptureLogger(tok_logger) as cl:\n",
" output = tokenizer(examples[text_column_name])\n",
" # clm input could be much much longer than block_size\n",
" if \"Token indices sequence length is longer than the\" in cl.out:\n",
" tok_logger.warning(\n",
" \"^^^^^^^^^^^^^^^^ Please ignore the warning above - this long input will be chunked into smaller bits before being passed to the model.\"\n",
" )\n",
" return output\n",
"\n",
"\n",
"# Main data processing function that will concatenate all texts from our dataset and generate chunks of block_size.\n",
"def group_texts(examples):\n",
" # Concatenate all texts.\n",
" concatenated_examples = {k: sum(examples[k], []) for k in examples.keys()}\n",
" total_length = len(concatenated_examples[list(examples.keys())[0]])\n",
" # We drop the small remainder, we could add padding if the model supported it instead of this drop, you can\n",
" # customize this part to your needs.\n",
" if total_length >= block_size:\n",
" total_length = (total_length // block_size) * block_size\n",
" # Split by chunks of max_len.\n",
" result = {\n",
" k: [t[i : i + block_size] for i in range(0, total_length, block_size)]\n",
" for k, t in concatenated_examples.items()\n",
" }\n",
" result[\"labels\"] = result[\"input_ids\"].copy()\n",
" return result"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"column_names = raw_datasets[\"train\"].column_names\n",
"text_column_name = \"text\" if \"text\" in column_names else column_names[0]\n",
"\n",
"# since this will be pickled to avoid _LazyModule error in Hasher force logger loading before tokenize_function\n",
"tok_logger = transformers.utils.logging.get_logger(\"transformers.tokenization_utils_base\")\n",
"\n",
"tokenized_datasets = raw_datasets.map(\n",
" tokenize_function,\n",
" batched=True,\n",
" num_proc=1,\n",
" remove_columns=column_names,\n",
" desc=\"Running tokenizer on dataset\",\n",
")\n",
"\n",
"\n",
"block_size = tokenizer.model_max_length\n",
"if block_size > 1024:\n",
" logger.warning(\n",
" f\"The tokenizer picked seems to have a very large `model_max_length` ({tokenizer.model_max_length}). \"\n",
" \"Picking 1024 instead. You can change that default value by passing --block_size xxx.\"\n",
" )\n",
" block_size = 1024\n",
"else:\n",
" if args.block_size > tokenizer.model_max_length:\n",
" logger.warning(\n",
" f\"The block_size passed ({block_size}) is larger than the maximum length for the model\"\n",
" f\"({tokenizer.model_max_length}). Using block_size={tokenizer.model_max_length}.\"\n",
" )\n",
" block_size = min(block_size, tokenizer.model_max_length)\n",
"\n",
"lm_datasets = tokenized_datasets.map(\n",
" group_texts,\n",
" batched=True,\n",
" # num_proc=args.preprocessing_num_workers,\n",
" desc=f\"Grouping texts in chunks of {block_size}\",\n",
")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Set additional hyperparameters and S3 paths for mapping the train and validation datasets properly depending on the phase (training or validation) of the training job in each epoch."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"if hyperparameters[\"do_train\"]:\n",
" if \"train\" not in tokenized_datasets:\n",
" raise ValueError(\"--do_train requires a train dataset\")\n",
" train_dataset = lm_datasets[\"train\"]\n",
"\n",
"\n",
"if hyperparameters[\"do_eval\"]:\n",
" if \"validation\" not in tokenized_datasets:\n",
" raise ValueError(\"--do_eval requires a validation dataset\")\n",
" eval_dataset = lm_datasets[\"validation\"]"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"training_dataset_location = None\n",
"validation_dataset_location = None\n",
"\n",
"\n",
"if hyperparameters[\"do_train\"]:\n",
" train_dataset.to_json(\"./training.json\")\n",
" training_dataset_location = \"s3://{}/dataset/train/\".format(default_bucket)\n",
"\n",
"if hyperparameters[\"do_eval\"]:\n",
" eval_dataset.to_json(\"./validation.json\")\n",
" validation_dataset_location = \"s3://{}/dataset/validation/\".format(default_bucket)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"if training_dataset_location is not None:\n",
" command = \"aws s3 cp ./training.json {}\".format(training_dataset_location)\n",
" os.system(command)\n",
"\n",
"if validation_dataset_location is not None:\n",
" command = \"aws s3 cp ./validation.json {}\".format(validation_dataset_location)\n",
" os.system(command)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"if hyperparameters[\"do_train\"]:\n",
" command = \"rm ./training.json\"\n",
" os.system(command)\n",
"\n",
"if hyperparameters[\"do_eval\"]:\n",
" command = \"rm ./validation.json\"\n",
" os.system(command)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"%store training_dataset_location\n",
"%store validation_dataset_location"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"%store"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Specify Amazon S3 bucket paths"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Here you need to specify the paths for training data to be used by your job. The bucket used must be in the same region as where training will run. In the cells above you downloaded the GLUE/SST2 training and validation split datasets and uploaded the json files in an S3 bucket in your account. This example will train on those json files.\n",
"\n",
"After you successfully run this example tensor parallel training job, you can modify the S3 bucket to where your own dataset is stored."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"%store -r training_dataset_location\n",
"%store -r validation_dataset_location\n",
"\n",
"# if you're bringing your own data, uncomment the following lines and specify the locations there\n",
"# training_dataset_location = YOUR_S3_BUCKET/training\n",
"# validation_dataset_location = YOUR_S3_BUCKET/validation"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"s3_train_bucket = training_dataset_location\n",
"s3_test_bucket = validation_dataset_location"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"The following S3 bucket will store the output artifacts of the training job. You can modify this as needed."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"s3_output_bucket = f\"s3://sagemaker-{region}-{account}/smp-tensorparallel-outputdir/\""
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Define data channels for SageMaker Training\n",
"\n",
"In this step, define SageMaker training data channels to the S3 buckets. "
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Set use_fsx to False by default\n",
"# Set below var to True if you want to use FSx (see next cell)\n",
"use_fsx = False\n",
"if not use_fsx:\n",
" train = sagemaker.inputs.TrainingInput(\n",
" s3_train_bucket, distribution=\"FullyReplicated\", s3_data_type=\"S3Prefix\"\n",
" )\n",
" test = sagemaker.inputs.TrainingInput(\n",
" s3_test_bucket, distribution=\"FullyReplicated\", s3_data_type=\"S3Prefix\"\n",
" )\n",
" data_channels = {\"train\": train, \"test\": test}"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## (Optional) Set up FSx and use FSx for data channels and checkpoints\n",
"\n",
"While the above option is easier to setup, using an FSx can be beneficial for performance when dealing with large input sizes and large model sizes. If you are using models with more than 13B parameters, checkpointing should be done using FSx. \n",
"\n",
"Amazon FSx for Lustre is a high performance file system optimized for workloads, such as machine learning, analytics and high performance computing. With Amazon FSx for Lustre, you can accelerate your File mode training jobs by avoiding the initial Amazon S3 download time.\n",
"\n",
"\n",
"Please see the instructions at [Distributed Training of Mask-RCNN in Amazon SageMaker using FSx](https://github.com/aws/amazon-sagemaker-examples/blob/master/advanced_functionality/distributed_tensorflow_mask_rcnn/mask-rcnn-scriptmode-fsx.ipynb), to create an Amazon FSx Lustre file-system and import data from the S3 bucket to your FSx file system. Note that the FSx must be created in a private subnet with internet gateway to ensure that training job has access to the internet. "
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Instructions obtained from:\n",
"# https://github.com/aws/amazon-sagemaker-examples/blob/master/advanced_functionality/distributed_tensorflow_mask_rcnn/mask-rcnn-scriptmode-fsx.ipynb\n",
"\n",
"if use_fsx:\n",
" from sagemaker.inputs import FileSystemInput\n",
"\n",
" # Specify FSx Lustre file system id.\n",
" file_system_id = \"\"\n",
"\n",
" # Specify the SG and subnet used by the FSx, these are passed to SM Estimator so jobs use this as well\n",
" fsx_security_group_id = \"\"\n",
" fsx_subnet = \"\"\n",
"\n",
" # Specify directory path for input data on the file system.\n",
" # You need to provide normalized and absolute path below.\n",
" # Your mount name can be provided by you when creating FSx, or generated automatically.\n",
" # You can find this mount_name on the FSx page in console.\n",
" # Example of FSx generated mount_name: \"3x8abcde\"\n",
" base_path = \"\"\n",
"\n",
" # Specify your file system type.\n",
" file_system_type = \"FSxLustre\"\n",
"\n",
" train = FileSystemInput(\n",
" file_system_id=file_system_id,\n",
" file_system_type=file_system_type,\n",
" directory_path=base_path,\n",
" file_system_access_mode=\"rw\",\n",
" )\n",
"\n",
" data_channels = {\"train\": train, \"test\": train}"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Set hyperparameters, metric definitions, and MPI options\n",
"The following `hyperparameters` dictionary is to pass arguments to the training script (`train.py`) and set the model parallel configuration when creating the training job.\n",
"\n",
"You can also add custom `mpi` flags. By default, we have `--mca btl_vader_single_copy_mechanism none` to remove unnecessary logs.\n",
"\n",
"Next, we add a base metric definitions to enable the metric upload in SageMaker. You can add any custom metric definitions."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"hyperparameters = {\n",
" \"max_steps\": 100,\n",
" \"seed\": 12345,\n",
" \"fp16\": 0,\n",
" \"bf16\": 1,\n",
" \"lr\": 2.0e-4,\n",
" \"lr_decay_iters\": 125000,\n",
" \"min_lr\": 0.00001,\n",
" \"lr-decay-style\": \"linear\",\n",
" \"warmup\": 0.01,\n",
" \"num_kept_checkpoints\": 5,\n",
" \"checkpoint_freq\": 200,\n",
" \"validation_freq\": 1000,\n",
" \"logging_freq\": 1,\n",
" \"save_final_full_model\": 0,\n",
" \"manual_partition\": 0,\n",
" \"skip_full_optimizer\": 1,\n",
" \"shard_optimizer_state\": 0,\n",
" \"activation_checkpointing\": 1,\n",
" \"activation_strategy\": \"each\",\n",
" \"optimize\": \"speed\",\n",
" \"delayed_param\": 1,\n",
" \"offload_activations\": 0,\n",
" \"zipped_data\": 0,\n",
" \"epochs\": 100,\n",
" # Specify the HF model name\n",
" \"model_name\": 'EleutherAI/gpt-j-6b',\n",
" # below flag loads model and optimizer state from checkpoint_s3_uri\n",
" # 'load_partial': 1,\n",
"}\n",
"\n",
"if use_fsx:\n",
" # make sure to update paths for training-dir and test-dir based on the paths of datasets in FSx\n",
" # If you want to resume training, set checkpoint-dir to the same path as a previous job.\n",
" SM_TRAIN_DIR = \"/opt/ml/input/data/train\"\n",
" hyperparameters[\"checkpoint-dir\"] = f\"{SM_TRAIN_DIR}/checkpointdir-job2\"\n",
" hyperparameters[\"model-dir\"] = f\"{SM_TRAIN_DIR}/modeldir-job2\"\n",
" hyperparameters[\"training-dir\"] = f\"{SM_TRAIN_DIR}/datasets/pytorch_gpt2/train_synthetic\"\n",
" hyperparameters[\"test-dir\"] = f\"{SM_TRAIN_DIR}/datasets/pytorch_gpt2/val_synthetic\"\n",
"\n",
"# The checkpoint path (hyperparameters['checkpoint-dir'] or checkpoint_s3_uri) is not unique per job.\n",
"# You need to modify as needed for different runs.\n",
"# If same path is used for unrelated runs, this may increase time when downloading unnecessary checkpoints,\n",
"# and cause conflicts when loading checkpoints.\n",
"\n",
"\n",
"mpioptions = \"-x NCCL_DEBUG=WARN -x SMDEBUG_LOG_LEVEL=ERROR \"\n",
"mpioptions += (\n",
" \"-x SMP_DISABLE_D2D=1 -x SMP_D2D_GPU_BUFFER_SIZE_BYTES=1 -x SMP_NCCL_THROTTLE_LIMIT=1 \"\n",
")\n",
"mpioptions += \"-x FI_EFA_USE_DEVICE_RDMA=1 -x FI_PROVIDER=efa -x RDMAV_FORK_SAFE=1\"\n",
"\n",
"metric_definitions = [\n",
" {\"Name\": \"base_metric\", \"Regex\": \"<><><><><><>\"}\n",
"] # Add your custom metric definitions"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Set model parameters with sharded data parllelism and tensor parallelism"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"model_config = \"gpt-j-6B\"\n",
"\n",
"if model_config == \"gpt-j-6B\":\n",
" model_params = {\n",
" \"tensor_parallel_degree\": 2,\n",
" \"pipeline_parallel_degree\": 1,\n",
" \"sharded_data_parallel_degree\": 4,\n",
" \"train_batch_size\": 30,\n",
" \"val_batch_size\": 8,\n",
" \"prescaled_batch\": 1,\n",
" \"max_context_width\": 2048,\n",
" \"hidden_width\": 4096,\n",
" \"num_heads\": 16,\n",
" \"num_layers\": 28,\n",
" }\n",
"elif model_config == \"gpt-j-xl\":\n",
" model_params = {\n",
" \"tensor_parallel_degree\": 4,\n",
" \"sharded_data_parallel_degree\": 2,\n",
" \"pipeline_parallel_degree\": 1,\n",
" \"train_batch_size\": 8,\n",
" \"val_batch_size\": 8,\n",
" \"prescaled_batch\": 1,\n",
" \"hidden_width\": 1600,\n",
" \"num_heads\": 25,\n",
" \"num_layers\": 48,\n",
" }\n",
"\n",
"for k, v in model_params.items():\n",
" hyperparameters[k] = v"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Set up SageMaker Studio Experiment\n",
"Create or load [SageMaker Experiment](https://docs.aws.amazon.com/sagemaker/latest/dg/experiments.html) for the example training job. This will create an experiment trial object in SageMaker Studio."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"from time import gmtime, strftime\n",
"\n",
"# Specify your experiment name\n",
"experiment_name = \"smp-gptj-tensor-parallel\"\n",
"# Specify your trial name\n",
"trial_name = f\"{experiment_name}-trial1\"\n",
"\n",
"all_experiment_names = [exp.experiment_name for exp in Experiment.list()]\n",
"# Load the experiment if it exists, otherwise create\n",
"if experiment_name not in all_experiment_names:\n",
" experiment = Experiment.create(\n",
" experiment_name=experiment_name, sagemaker_boto_client=sm_boto_client\n",
" )\n",
"else:\n",
" experiment = Experiment.load(\n",
" experiment_name=experiment_name, sagemaker_boto_client=sm_boto_client\n",
" )\n",
"\n",
"# Create the trial\n",
"trial = Trial.create(\n",
" trial_name=\"smp-{}-{}\".format(trial_name, strftime(\"%Y-%m-%d-%H-%M-%S\", gmtime())),\n",
" experiment_name=experiment.experiment_name,\n",
" sagemaker_boto_client=sm_boto_client,\n",
")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Specify essential parameters for a SageMaker Training job\n",
"\n",
"Next, you use the [`SageMaker Estimator class`](https://sagemaker.readthedocs.io/en/stable/api/training/estimators.html) to define a SageMaker Training Job, passing values through the following parameters for training job name, the number of EC2 instances, the instance type, and the size of the volume attached to the instances. \n",
"\n",
"* `instance_count`\n",
"* `instance_type`\n",
"* `volume_size`\n",
"* `base_job_name`\n",
"\n",
"### Update the type and the number of EC2 instance to use\n",
"\n",
"The instance type and the number of instances you specify to the `instance_type` and `instance_count` parameters, respectively, determine the total number of GPUs (world size).\n",
"\n",
"$$ \\text{(world size) = (the number of GPUs on a single instance)}\\times\\text{(the number of instances)}$$\n",
"\n",
"\n",
"Note that gpt-j-6B needs at least a single g5.48xlarge, p3dn.24xlarge, or p4d.24xlarge, or multiple nodes of smaller GPU instances. If you do not want to start an instance of this type, please use the smaller gpt-j-xl config. That model is a smaller 1.5B parameter model, which can fit on fewer or smaller GPUs in g5.24xlarge or p3 instances.\n",
""
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"#### Select one of the following instances to train the gpt-j-xl model\n",
"ml.g5.12xlarge\n",
"ml.g5.24xlarge\n",
"ml.g4dn.12xlarge\n",
"ml.p3.8xlarge\n",
"ml.p3.16xlarge\n",
"ml.p2.16xlarge
\n",
"\n",
"\n",
"#### Select one of the following instances to train the gpt-j-6B model\n",
"g5.48xlarge\n",
"p3dn.24xlarge\n",
"p4d.24xlarge
\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"instance_type = \"ml.p4d.24xlarge\"\n",
"\n",
"instance_count = 1"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"instance_type"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"if instance_type in [\n",
" \"ml.p3.16xlarge\",\n",
" \"ml.p3dn.24xlarge\",\n",
" \"ml.g5.48xlarge\",\n",
" \"ml.p4d.24xlarge\",\n",
"]:\n",
" processes_per_host = 8\n",
"elif instance_type == \"ml.p2.16xlarge\":\n",
" processes_per_host = 16\n",
"else:\n",
" processes_per_host = 4\n",
"\n",
"print(\"processes_per_host is set to:\", processes_per_host)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"To look up the number of GPUs of different instance types, see [Amazon EC2 Instance Types](https://aws.amazon.com/ec2/instance-types/). Use the section **Accelerated Computing** to see general purpose GPU instances. Note that, for example, a given instance type `p4d.24xlarge` has a corresponding instance type `ml.p4d.24xlarge` in SageMaker.\n",
"For SageMaker supported `ml` instances and cost information, see [Amazon SageMaker Pricing](https://aws.amazon.com/sagemaker/pricing/). "
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Specify a Base Job Name"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"machine_str = instance_type.split(\".\")[1] + instance_type.split(\".\")[2][:3]\n",
"pp_degree = hyperparameters[\"pipeline_parallel_degree\"]\n",
"tp_degree = hyperparameters[\"tensor_parallel_degree\"]\n",
"base_job_name = f'smp-{model_config}-{machine_str}-tp{tp_degree}-pp{pp_degree}-bs{hyperparameters[\"train_batch_size\"]}'"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"if not use_fsx:\n",
" # If you want to resume training, set checkpoint_s3_uri to the same path as a previous job.\n",
" # Previous checkpoint to load must have same model config.\n",
" checkpoint_bucket = f\"s3://sagemaker-{region}-{account}/\"\n",
" checkpoint_s3_uri = (\n",
" f\"{checkpoint_bucket}/experiments/gptj_synthetic_simpletrainer_checkpoints/{base_job_name}/\"\n",
" )"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Create a SageMaker HuggingFace 🤗 Estimator\n",
"\n",
"The following cell constructs a PyTorch estimator using the parameters defined above. To see how the SageMaker Model Parallelism modules and functions are applied to the script, look into the `train.py` file. "
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"kwargs = {}\n",
"if use_fsx:\n",
" # Use the security group and subnet that was used to create the FSx filesystem\n",
" kwargs[\"security_group_ids\"] = [fsx_security_group_id]\n",
" kwargs[\"subnets\"] = [fsx_subnet]\n",
"\n",
"smp_estimator = PyTorch(\n",
" entry_point=\"train.py\",\n",
" source_dir=os.getcwd(),\n",
" role=role,\n",
" instance_type=instance_type,\n",
" instance_count=instance_count,\n",
" sagemaker_session=sagemaker_session,\n",
" distribution={\n",
" \"mpi\": {\n",
" \"enabled\": True,\n",
" \"processes_per_host\": processes_per_host,\n",
" \"custom_mpi_options\": mpioptions,\n",
" },\n",
" \"smdistributed\": {\n",
" \"modelparallel\": {\n",
" \"enabled\": True,\n",
" \"parameters\": {\n",
" \"ddp\": True,\n",
" \"tensor_parallel_degree\": hyperparameters[\"tensor_parallel_degree\"],\n",
" # partitions is a required param in the current SM SDK so it needs to be passed,\n",
" # these two map to the same config\n",
" \"partitions\": hyperparameters[\"pipeline_parallel_degree\"],\n",
" \"shard_optimizer_state\": hyperparameters[\"shard_optimizer_state\"] > 0,\n",
" \"prescaled_batch\": hyperparameters[\"prescaled_batch\"] > 0,\n",
" \"optimize\": hyperparameters[\"optimize\"],\n",
" \"skip_tracing\": True,\n",
" \"delayed_parameter_initialization\": hyperparameters[\"delayed_param\"] > 0,\n",
" \"offload_activations\": hyperparameters[\"offload_activations\"] > 0,\n",
" \"sharded_data_parallel_degree\": hyperparameters[\"sharded_data_parallel_degree\"],\n",
" \"fp16\": hyperparameters[\"fp16\"] > 0,\n",
" \"bf16\": hyperparameters[\"bf16\"] > 0,\n",
" },\n",
" }\n",
" },\n",
" },\n",
" framework_version=\"1.13\",\n",
" py_version=\"py39\",\n",
" output_path=s3_output_bucket,\n",
" checkpoint_s3_uri=checkpoint_s3_uri if not use_fsx else None,\n",
" checkpoint_local_path=hyperparameters[\"checkpoint-dir\"] if use_fsx else None,\n",
" metric_definitions=metric_definitions,\n",
" hyperparameters=hyperparameters,\n",
" debugger_hook_config=False,\n",
" disable_profiler=True,\n",
" base_job_name=base_job_name,\n",
" **kwargs,\n",
")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Finally, run the `estimator.fit` method to launch the SageMaker training job of the GPT-J model with sharded data parallelism."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"If you receive a `ResourceLimitExceeded` error message when running the following cell, you can request an increase on the default quota by contacting [AWS support](https://console.aws.amazon.com/support). Open the [AWS Support Center](https://console.aws.amazon.com/support), and then choose Create case. Choose Service limit increase. For Limit Type choose SageMaker Training Jobs. Complete the rest of the form and submit."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"scrolled": true,
"tags": []
},
"outputs": [],
"source": [
"smp_estimator.fit(\n",
" inputs=data_channels,\n",
" experiment_config={\n",
" \"ExperimentName\": experiment.experiment_name,\n",
" \"TrialName\": trial.trial_name,\n",
" \"TrialComponentDisplayName\": \"Training\",\n",
" },\n",
" logs=True,\n",
")"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"model_location = smp_estimator.model_data"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"model_location"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Accessing the Training Logs\n",
"\n",
"You can access the training logs from [Amazon CloudWatch](https://docs.aws.amazon.com/AmazonCloudWatch/latest/monitoring/WhatIsCloudWatch.html). Make sure to look at the logs of algo-1 as that is the master node whose output stream will have the training job logs.\n",
"\n",
"You can use CloudWatch to track SageMaker GPU and memory utilization during training and inference. To view the metrics and logs that SageMaker writes to CloudWatch, see *Processing Job, Training Job, Batch Transform Job, and Endpoint Instance Metrics* in [Monitor Amazon SageMaker with Amazon CloudWatch](https://docs.aws.amazon.com/sagemaker/latest/dg/monitoring-cloudwatch.html).\n",
"\n",
"If you are a new user of CloudWatch, see [Getting Started with Amazon CloudWatch](https://docs.aws.amazon.com/AmazonCloudWatch/latest/monitoring/GettingStarted.html). \n",
"\n",
"For additional information on monitoring and analyzing Amazon SageMaker training jobs, see [Monitor and Analyze Training Jobs Using Metrics](https://docs.aws.amazon.com/sagemaker/latest/dg/training-metrics.html).\n",
"\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Notebook CI Test Results\n",
"\n",
"This notebook was tested in multiple regions. The test results are as follows, except for us-west-2 which is shown at the top of the notebook.\n",
"\n",
"\n",
"\n",
"\n",
"\n",
"\n",
"\n",
"\n",
"\n",
"\n",
"\n",
"\n",
"\n",
"\n",
"\n",
"\n",
"\n",
"\n",
"\n",
"\n",
"\n",
"\n",
"\n",
"\n",
"\n",
"\n",
"\n",
"\n",
"\n",
"\n"
]
}
],
"metadata": {
"availableInstances": [
{
"_defaultOrder": 0,
"_isFastLaunch": true,
"category": "General purpose",
"gpuNum": 0,
"memoryGiB": 4,
"name": "ml.t3.medium",
"vcpuNum": 2
},
{
"_defaultOrder": 1,
"_isFastLaunch": false,
"category": "General purpose",
"gpuNum": 0,
"memoryGiB": 8,
"name": "ml.t3.large",
"vcpuNum": 2
},
{
"_defaultOrder": 2,
"_isFastLaunch": false,
"category": "General purpose",
"gpuNum": 0,
"memoryGiB": 16,
"name": "ml.t3.xlarge",
"vcpuNum": 4
},
{
"_defaultOrder": 3,
"_isFastLaunch": false,
"category": "General purpose",
"gpuNum": 0,
"memoryGiB": 32,
"name": "ml.t3.2xlarge",
"vcpuNum": 8
},
{
"_defaultOrder": 4,
"_isFastLaunch": true,
"category": "General purpose",
"gpuNum": 0,
"memoryGiB": 8,
"name": "ml.m5.large",
"vcpuNum": 2
},
{
"_defaultOrder": 5,
"_isFastLaunch": false,
"category": "General purpose",
"gpuNum": 0,
"memoryGiB": 16,
"name": "ml.m5.xlarge",
"vcpuNum": 4
},
{
"_defaultOrder": 6,
"_isFastLaunch": false,
"category": "General purpose",
"gpuNum": 0,
"memoryGiB": 32,
"name": "ml.m5.2xlarge",
"vcpuNum": 8
},
{
"_defaultOrder": 7,
"_isFastLaunch": false,
"category": "General purpose",
"gpuNum": 0,
"memoryGiB": 64,
"name": "ml.m5.4xlarge",
"vcpuNum": 16
},
{
"_defaultOrder": 8,
"_isFastLaunch": false,
"category": "General purpose",
"gpuNum": 0,
"memoryGiB": 128,
"name": "ml.m5.8xlarge",
"vcpuNum": 32
},
{
"_defaultOrder": 9,
"_isFastLaunch": false,
"category": "General purpose",
"gpuNum": 0,
"memoryGiB": 192,
"name": "ml.m5.12xlarge",
"vcpuNum": 48
},
{
"_defaultOrder": 10,
"_isFastLaunch": false,
"category": "General purpose",
"gpuNum": 0,
"memoryGiB": 256,
"name": "ml.m5.16xlarge",
"vcpuNum": 64
},
{
"_defaultOrder": 11,
"_isFastLaunch": false,
"category": "General purpose",
"gpuNum": 0,
"memoryGiB": 384,
"name": "ml.m5.24xlarge",
"vcpuNum": 96
},
{
"_defaultOrder": 12,
"_isFastLaunch": false,
"category": "General purpose",
"gpuNum": 0,
"memoryGiB": 8,
"name": "ml.m5d.large",
"vcpuNum": 2
},
{
"_defaultOrder": 13,
"_isFastLaunch": false,
"category": "General purpose",
"gpuNum": 0,
"memoryGiB": 16,
"name": "ml.m5d.xlarge",
"vcpuNum": 4
},
{
"_defaultOrder": 14,
"_isFastLaunch": false,
"category": "General purpose",
"gpuNum": 0,
"memoryGiB": 32,
"name": "ml.m5d.2xlarge",
"vcpuNum": 8
},
{
"_defaultOrder": 15,
"_isFastLaunch": false,
"category": "General purpose",
"gpuNum": 0,
"memoryGiB": 64,
"name": "ml.m5d.4xlarge",
"vcpuNum": 16
},
{
"_defaultOrder": 16,
"_isFastLaunch": false,
"category": "General purpose",
"gpuNum": 0,
"memoryGiB": 128,
"name": "ml.m5d.8xlarge",
"vcpuNum": 32
},
{
"_defaultOrder": 17,
"_isFastLaunch": false,
"category": "General purpose",
"gpuNum": 0,
"memoryGiB": 192,
"name": "ml.m5d.12xlarge",
"vcpuNum": 48
},
{
"_defaultOrder": 18,
"_isFastLaunch": false,
"category": "General purpose",
"gpuNum": 0,
"memoryGiB": 256,
"name": "ml.m5d.16xlarge",
"vcpuNum": 64
},
{
"_defaultOrder": 19,
"_isFastLaunch": false,
"category": "General purpose",
"gpuNum": 0,
"memoryGiB": 384,
"name": "ml.m5d.24xlarge",
"vcpuNum": 96
},
{
"_defaultOrder": 20,
"_isFastLaunch": true,
"category": "Compute optimized",
"gpuNum": 0,
"memoryGiB": 4,
"name": "ml.c5.large",
"vcpuNum": 2
},
{
"_defaultOrder": 21,
"_isFastLaunch": false,
"category": "Compute optimized",
"gpuNum": 0,
"memoryGiB": 8,
"name": "ml.c5.xlarge",
"vcpuNum": 4
},
{
"_defaultOrder": 22,
"_isFastLaunch": false,
"category": "Compute optimized",
"gpuNum": 0,
"memoryGiB": 16,
"name": "ml.c5.2xlarge",
"vcpuNum": 8
},
{
"_defaultOrder": 23,
"_isFastLaunch": false,
"category": "Compute optimized",
"gpuNum": 0,
"memoryGiB": 32,
"name": "ml.c5.4xlarge",
"vcpuNum": 16
},
{
"_defaultOrder": 24,
"_isFastLaunch": false,
"category": "Compute optimized",
"gpuNum": 0,
"memoryGiB": 72,
"name": "ml.c5.9xlarge",
"vcpuNum": 36
},
{
"_defaultOrder": 25,
"_isFastLaunch": false,
"category": "Compute optimized",
"gpuNum": 0,
"memoryGiB": 96,
"name": "ml.c5.12xlarge",
"vcpuNum": 48
},
{
"_defaultOrder": 26,
"_isFastLaunch": false,
"category": "Compute optimized",
"gpuNum": 0,
"memoryGiB": 144,
"name": "ml.c5.18xlarge",
"vcpuNum": 72
},
{
"_defaultOrder": 27,
"_isFastLaunch": false,
"category": "Compute optimized",
"gpuNum": 0,
"memoryGiB": 192,
"name": "ml.c5.24xlarge",
"vcpuNum": 96
},
{
"_defaultOrder": 28,
"_isFastLaunch": true,
"category": "Accelerated computing",
"gpuNum": 1,
"memoryGiB": 16,
"name": "ml.g4dn.xlarge",
"vcpuNum": 4
},
{
"_defaultOrder": 29,
"_isFastLaunch": false,
"category": "Accelerated computing",
"gpuNum": 1,
"memoryGiB": 32,
"name": "ml.g4dn.2xlarge",
"vcpuNum": 8
},
{
"_defaultOrder": 30,
"_isFastLaunch": false,
"category": "Accelerated computing",
"gpuNum": 1,
"memoryGiB": 64,
"name": "ml.g4dn.4xlarge",
"vcpuNum": 16
},
{
"_defaultOrder": 31,
"_isFastLaunch": false,
"category": "Accelerated computing",
"gpuNum": 1,
"memoryGiB": 128,
"name": "ml.g4dn.8xlarge",
"vcpuNum": 32
},
{
"_defaultOrder": 32,
"_isFastLaunch": false,
"category": "Accelerated computing",
"gpuNum": 4,
"memoryGiB": 192,
"name": "ml.g4dn.12xlarge",
"vcpuNum": 48
},
{
"_defaultOrder": 33,
"_isFastLaunch": false,
"category": "Accelerated computing",
"gpuNum": 1,
"memoryGiB": 256,
"name": "ml.g4dn.16xlarge",
"vcpuNum": 64
},
{
"_defaultOrder": 34,
"_isFastLaunch": false,
"category": "Accelerated computing",
"gpuNum": 1,
"memoryGiB": 61,
"name": "ml.p3.2xlarge",
"vcpuNum": 8
},
{
"_defaultOrder": 35,
"_isFastLaunch": false,
"category": "Accelerated computing",
"gpuNum": 4,
"memoryGiB": 244,
"name": "ml.p3.8xlarge",
"vcpuNum": 32
},
{
"_defaultOrder": 36,
"_isFastLaunch": false,
"category": "Accelerated computing",
"gpuNum": 8,
"memoryGiB": 488,
"name": "ml.p3.16xlarge",
"vcpuNum": 64
},
{
"_defaultOrder": 37,
"_isFastLaunch": false,
"category": "Accelerated computing",
"gpuNum": 8,
"memoryGiB": 768,
"name": "ml.p3dn.24xlarge",
"vcpuNum": 96
},
{
"_defaultOrder": 38,
"_isFastLaunch": false,
"category": "Memory Optimized",
"gpuNum": 0,
"memoryGiB": 16,
"name": "ml.r5.large",
"vcpuNum": 2
},
{
"_defaultOrder": 39,
"_isFastLaunch": false,
"category": "Memory Optimized",
"gpuNum": 0,
"memoryGiB": 32,
"name": "ml.r5.xlarge",
"vcpuNum": 4
},
{
"_defaultOrder": 40,
"_isFastLaunch": false,
"category": "Memory Optimized",
"gpuNum": 0,
"memoryGiB": 64,
"name": "ml.r5.2xlarge",
"vcpuNum": 8
},
{
"_defaultOrder": 41,
"_isFastLaunch": false,
"category": "Memory Optimized",
"gpuNum": 0,
"memoryGiB": 128,
"name": "ml.r5.4xlarge",
"vcpuNum": 16
},
{
"_defaultOrder": 42,
"_isFastLaunch": false,
"category": "Memory Optimized",
"gpuNum": 0,
"memoryGiB": 256,
"name": "ml.r5.8xlarge",
"vcpuNum": 32
},
{
"_defaultOrder": 43,
"_isFastLaunch": false,
"category": "Memory Optimized",
"gpuNum": 0,
"memoryGiB": 384,
"name": "ml.r5.12xlarge",
"vcpuNum": 48
},
{
"_defaultOrder": 44,
"_isFastLaunch": false,
"category": "Memory Optimized",
"gpuNum": 0,
"memoryGiB": 512,
"name": "ml.r5.16xlarge",
"vcpuNum": 64
},
{
"_defaultOrder": 45,
"_isFastLaunch": false,
"category": "Memory Optimized",
"gpuNum": 0,
"memoryGiB": 768,
"name": "ml.r5.24xlarge",
"vcpuNum": 96
},
{
"_defaultOrder": 46,
"_isFastLaunch": false,
"category": "Accelerated computing",
"gpuNum": 1,
"memoryGiB": 16,
"name": "ml.g5.xlarge",
"vcpuNum": 4
},
{
"_defaultOrder": 47,
"_isFastLaunch": false,
"category": "Accelerated computing",
"gpuNum": 1,
"memoryGiB": 32,
"name": "ml.g5.2xlarge",
"vcpuNum": 8
},
{
"_defaultOrder": 48,
"_isFastLaunch": false,
"category": "Accelerated computing",
"gpuNum": 1,
"memoryGiB": 64,
"name": "ml.g5.4xlarge",
"vcpuNum": 16
},
{
"_defaultOrder": 49,
"_isFastLaunch": false,
"category": "Accelerated computing",
"gpuNum": 1,
"memoryGiB": 128,
"name": "ml.g5.8xlarge",
"vcpuNum": 32
},
{
"_defaultOrder": 50,
"_isFastLaunch": false,
"category": "Accelerated computing",
"gpuNum": 1,
"memoryGiB": 256,
"name": "ml.g5.16xlarge",
"vcpuNum": 64
},
{
"_defaultOrder": 51,
"_isFastLaunch": false,
"category": "Accelerated computing",
"gpuNum": 4,
"memoryGiB": 192,
"name": "ml.g5.12xlarge",
"vcpuNum": 48
},
{
"_defaultOrder": 52,
"_isFastLaunch": false,
"category": "Accelerated computing",
"gpuNum": 4,
"memoryGiB": 384,
"name": "ml.g5.24xlarge",
"vcpuNum": 96
},
{
"_defaultOrder": 53,
"_isFastLaunch": false,
"category": "Accelerated computing",
"gpuNum": 8,
"memoryGiB": 768,
"name": "ml.g5.48xlarge",
"vcpuNum": 192
}
],
"hide_input": false,
"instance_type": "ml.m5.large",
"kernelspec": {
"display_name": "conda_pytorch_p310",
"language": "python",
"name": "conda_pytorch_p310"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.10.10"
}
},
"nbformat": 4,
"nbformat_minor": 4
}