Ingestion with Glue
In this Lab we will:
- Configure the permissions for the resources that we are going to use.
- Create a data catalog from the raw files with Glue Crawler
- Transform the raw files into Apache Parquet format (https://parquet.apache.org/) using Glue jobs.
- Create a data catalog from the curated files to be used by Athena.
- EXTRA: We will run a local container for Jupyter Pyspark environment for local testing.
- OPTIONAL: We will show how to create a Development Endpoint.
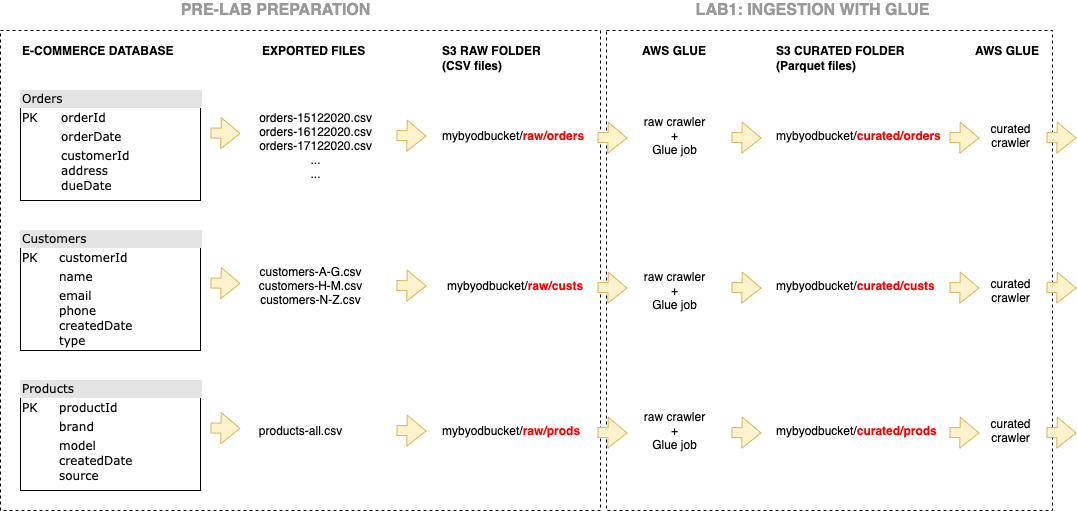
Below image shows the structure of the labs on an example. In this example, an e-commerce database is used. Three relevant tables are exported as csv files (with UTF-8 encoding) and put into an S3 bucket before the lab. In the end, we will have three separate folders under “curated” folder in our S3 bucket.
Please make sure now you select the region where your data resides. All resources to be created must be in the same region.