Create data catalog from S3 files
We will be using AWS Glue Crawlers to infer the schema of the files and create data catalog. Without a crawler, you can still read data from the S3 by a Glue job, but it will not be able to determine data types (string, int, etc) for each column.
- start by navigating to the Crawlers menu on the navigation pane, then press Add crawler.
- specify the name: “byod-YOUR_TABLE_NAME-raw-crawler” and press Next;
- choose Data stores as Crawler source type and press Next;
- Choose S3 as data store. Add S3 path of the specific folder where your files for your table resides (for example: mybyodbucket/raw/orders) and press *Next. We will create a separate crawler for each table (each folder in your raw folder),so for this step just add one folder.
- At this stage we don’t add any other data source;
- Choose the glue-processor-role as IAM Role and proceed to the schedule;
- Leave the Run on demand option at the Frequency section and press Next;
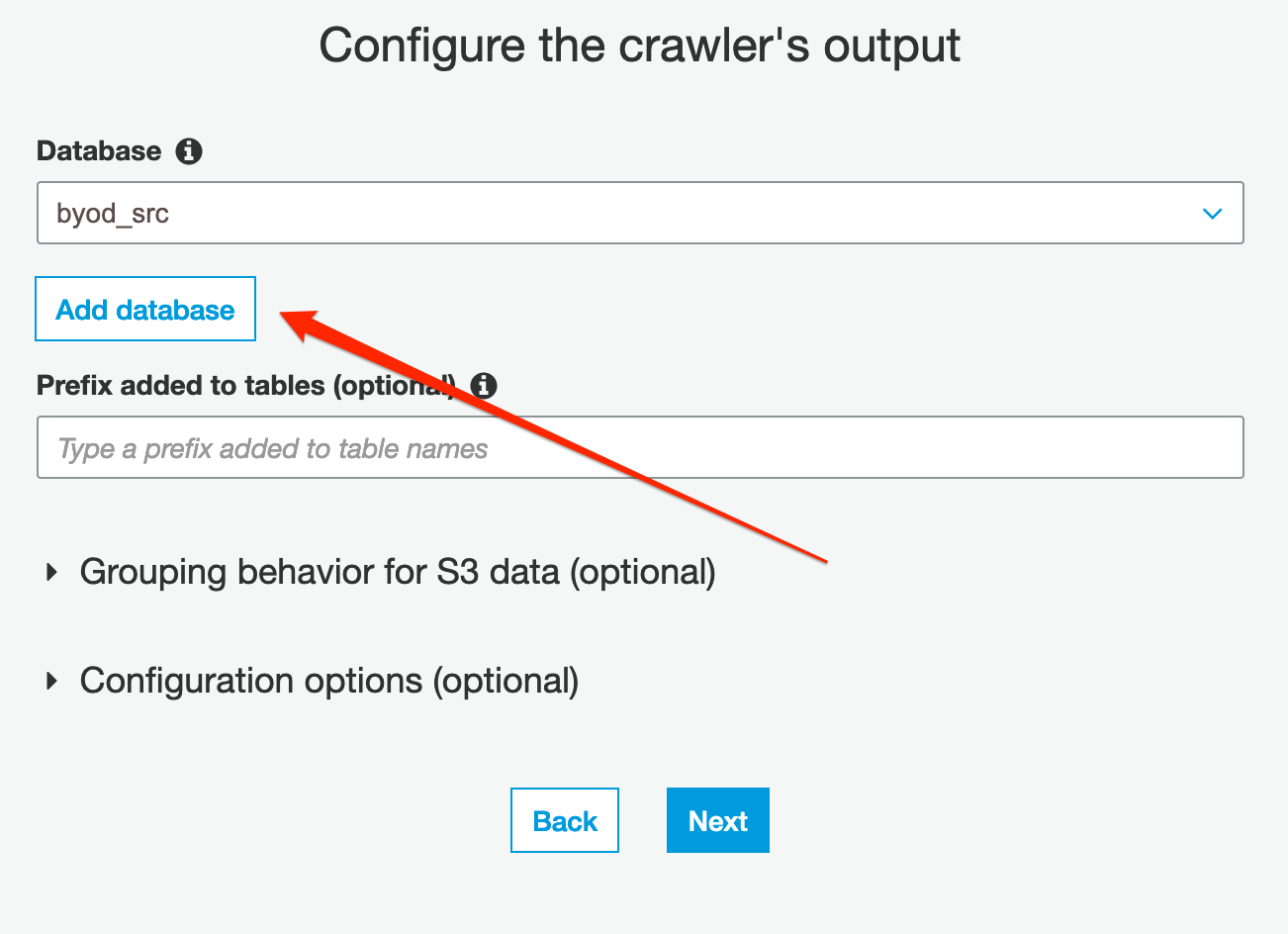
- Click on the Add database button and specify “byod_src” as database name (this will be the name representing the source database in the data catalog). Press Next and Finish;
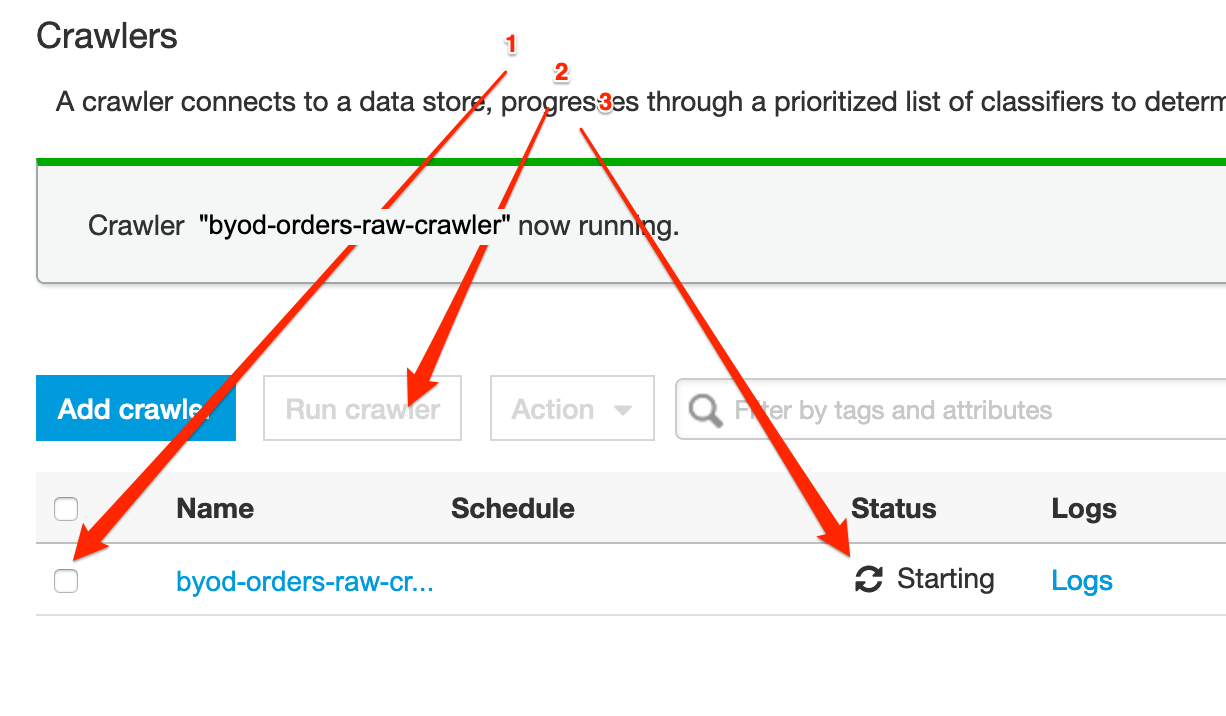
- select the newly created crawler and push the Run crawler button. It will take a few minutes until it populates the data catalog.
Validation: After the crawler finishes running, from the left menu, go to Databases, select your database, and click “Tables in