Transformations
This lab covers a few examples for cleaning, transforming and partitioning yoour data before putting the final results to your data lake. You may or may not need them depending on your data structure.
The code snippets shared here are examples and may require modification, trial and error for each dataset. It is a good idea to use either your local environment or Glue Development Endpoint to develop and debug your code before deploying to production.
Open the notebook
If you are using Jupyter Pyspark container on your local machine as we explained in the first lab:
Open the notebook on your browser with the url given from the terminal. Go to New -> Python 3
If you are using Glue Development Endpoint:
From the Glue console, click “Notebooks” on the left menu and open the Notebook created. This will launch Jupyter Notebook. Go to New -> Sparkmagic (PySpark)
Development endpoints incur costs whether or not you are using them. Please delete the endpoints AND notebooks after usage.
The rest of the lab is same for each environment.
Initial script setup
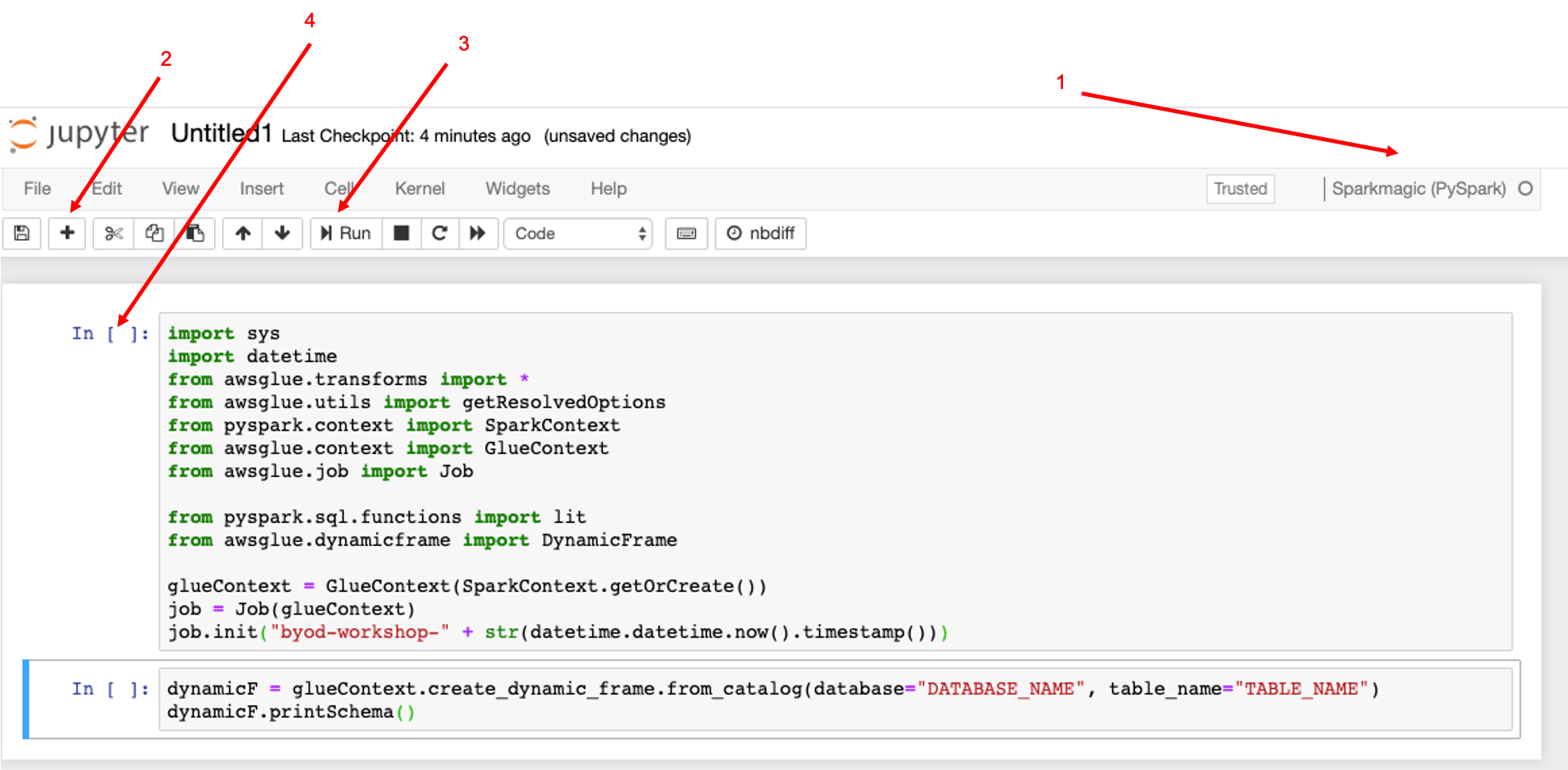
- Make sure that the notebook is running pyspark
- This is the plus button for adding new lines - In this image I have added two lines of code
- Once you add a line of code, then click Run
- Once it has run, then you should see a number here
Click plus [2] - We will start by importing all the libraries we need
import sys
import datetime
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
from pyspark.sql.functions import lit
from awsglue.dynamicframe import DynamicFrame
glueContext = GlueContext(SparkContext.getOrCreate())
job = Job(glueContext)
job.init("byod-workshop-" + str(datetime.datetime.now().timestamp()))
Then click Run
DynamicFrame vs Spark DataFrames One of the major abstractions in Apache Spark is the SparkSQL DataFrame, which is similar to the DataFrame construct found in R and Pandas. A DataFrame is similar to a table and supports functional-style (map/reduce/filter/etc.) operations and SQL operations (select, project, aggregate).
DataFrames are powerful and widely used, but they have limitations with respect to extract, transform, and load (ETL) operations. Most significantly, they require a schema to be specified before any data is loaded. To address these limitations, AWS Glue introduces the DynamicFrame. A DynamicFrame is similar to a DataFrame, except that each record is self-describing, so no schema is required initially. Instead, AWS Glue computes a schema on-the-fly when required, and explicitly encodes schema inconsistencies using a choice (or union) type.
It is possible to convert a DataFrame to a DynamicFrame and vice versa with toDF() and fromDF() methods.
We are going to use the curated data we transformed to parquet in previous steps. For that, we create a dynamic frame pointing to the database and table that our crawler inferred, then we are going to show the schema
If you do not remember the database/table names, just go to Databases/ Table tab in Glue and copy its names.
Click plus [2] and add the following code in a separate line
dynamicF = glueContext.create_dynamic_frame.from_catalog(database="DATABASE_NAME", table_name="TABLE_NAME")
dynamicF.printSchema()
Then click Run
Transformations
You probably have a large number of columns and some of them can have complicated names. To analyze the data, perhaps we may not need all the columns, just a small set of them, and to make easier to recall, we may want to change the name of the columns. Therefore, we are going to select only the columns we are interested in, drop the rest of them and we are going to rename them.
Drop Columns
There are two different ways to drop columns
- You use the select_fields method to drop all the columns and keep just the ones you need
dynamicF= dynamicF.select_fields(['COLUMN1_TO_KEEP','COLUMN2_TO_KEEP']).rename_field('COLUMN1_TO_RENAME', 'NEW_COLUMN_NAME').rename_field('COLUMN2_TO_RENAME', 'NEW_COLUMN_NAME')
dynamicF.printSchema()
- You use the drop_fields method to keep all the columns and just drop the ones you do not need.
dynamicF = dynamicF.drop_fields(['COLUMN1_TO_DROP','COLUMN2_TO_DROP']).rename_field('COLUMN1_TO_RENAME', 'NEW_COLUMN_NAME').rename_field('COLUMN2_TO_RENAME', 'NEW_COLUMN_NAME')
dynamicF.printSchema()
For the rename part, we are using the rename_field() method. This should be invoked for each column you want to rename
Example NY Taxis dataset
dynamicF = dynamicF.select_fields(['tpep_pickup_datetime','trip_distance']).rename_field('tpep_pickup_datetime', 'pickup_datetime')
dynamicF.printSchema()
Convert to Time stamp
Please check the datetime column schema, from the previous step. It may be string or another type different than what we may need it to be. Therefore, we are going to do some transformations.
First, let’s add the libraries we need to make this conversion:
from pyspark.sql.functions import date_format
from pyspark.sql.functions import to_date
from pyspark.sql.types import DateType
from pyspark.sql.functions import year, month, dayofmonth, date_format
Then, depending on the format of our current field, we may want to convert it into another format that contains year and month only. This will allow us later to partition our data according to year and month easily. Select which line of code you will use according to your date type format.
First, we need to change the format from dynamic frame to dataframe (If you do not remember the difference between dynamic frame and data frame, you can read again the explanation above). This will allow us to use some the libraries previously imported:
df = dynamicF.toDF()
df.show()
ISO 8601 TIMESTAMP Below is example code that can be used to do the conversion from ISO 8601 date format. Please substitute your own date-format in place of yyyy-MM-dd
## Adding trx_date date column with y-M format converting a current timestamp/unix date format
df = df.withColumn('trx_date', to_date("trx-date", "yyyy-MM-dd").cast(DateType()))
If you do not get an error but the date column is full of NULL, then probably you didn’t substitute your own date-format in yyyy-MM-dd If you still have errors, then please go to the other date formats section.
Example NY Taxis dataset
## Adding pickup_datetime date column with yyyy-MM-dd format converting a current timestamp/unix date format
df = df.withColumn('pickup_datetime', to_date("pickup_datetime", "yyyy-MM-dd")).cast(DateType())
df.show()
Other time formats
Now, depending on the time format, please select which line of code you will use according to your date type format.
UNIX TIMESTAMP
## Adding trx_date date column with yyyy-MM-dd format converting a current timestamp/unix date format
df = df.withColumn('trx_date', date_format(from_unixtime(df['{YOUR_DATE_COL_NAME}']), "yyyy-MM-dd").cast(DateType()))
OTHER DATE FORMATS
To convert unique data formats, we use to_date() function to specify how to parse your value specifying date literals in second attribute (Look at resources section for more information).
## Adding trx_date date column with yyyy-MM-dd format converting a current timestamp/unix date format
df = df.withColumn('trx_date', date_format(to_date(df['{YOUR_DATE_COL_NAME}'], {DATE_LITERALS}), "yyyy-MM-dd").cast(DateType()))
Partitioning
Partitioning the data greatly increases the performance of your queries and reduce costs. For example, if you only need last month’s data from a large dataset, if the data is partitioned by day, month and year, then you can use a “where” clause in your query and Athena will only use relevant folders and will not scan the unnecessary ones.
In order to partition our data, we will first create extra columns for year, month and day. Then when writing the data into S3, we will partition it by year, month and day. So, our final folder structure will be like:
/curated/TABLE-NAME-1/year=YYYY/month=MM/day=DD/file1.parquet
You can also add additional partitions if you know you will often use those fields to filter data. For example, if you will often filter your data on product types, you can add a column for that field and also partition by that column additionally.
Add this code at the end of your script:
df = df.withColumn('year', year(df.trx_date)).withColumn('month', month(df.trx_date)).withColumn('day', dayofmonth(df.trx_date))
df.show()
See that there are three extra fields for year, month and day - If you want, you can also drop the “trx_date” column using df.drop('trx_date') - Please note that since we are using data frame instead of dynamic frame, we can not use the same method drop_fields introduced earlier.
Run this in a Glue Job
Please add these lines to the end of your notebook
## DONT FORGET TO PUT IN YOUR BUCKET NAME.
output_location = "s3://YOUR-BUCKET/curated"
df.write.mode("overwrite").partitionBy("year","month","day").parquet(output_location)
job.commit()
Now, let’s export our job and move it into a glue job.
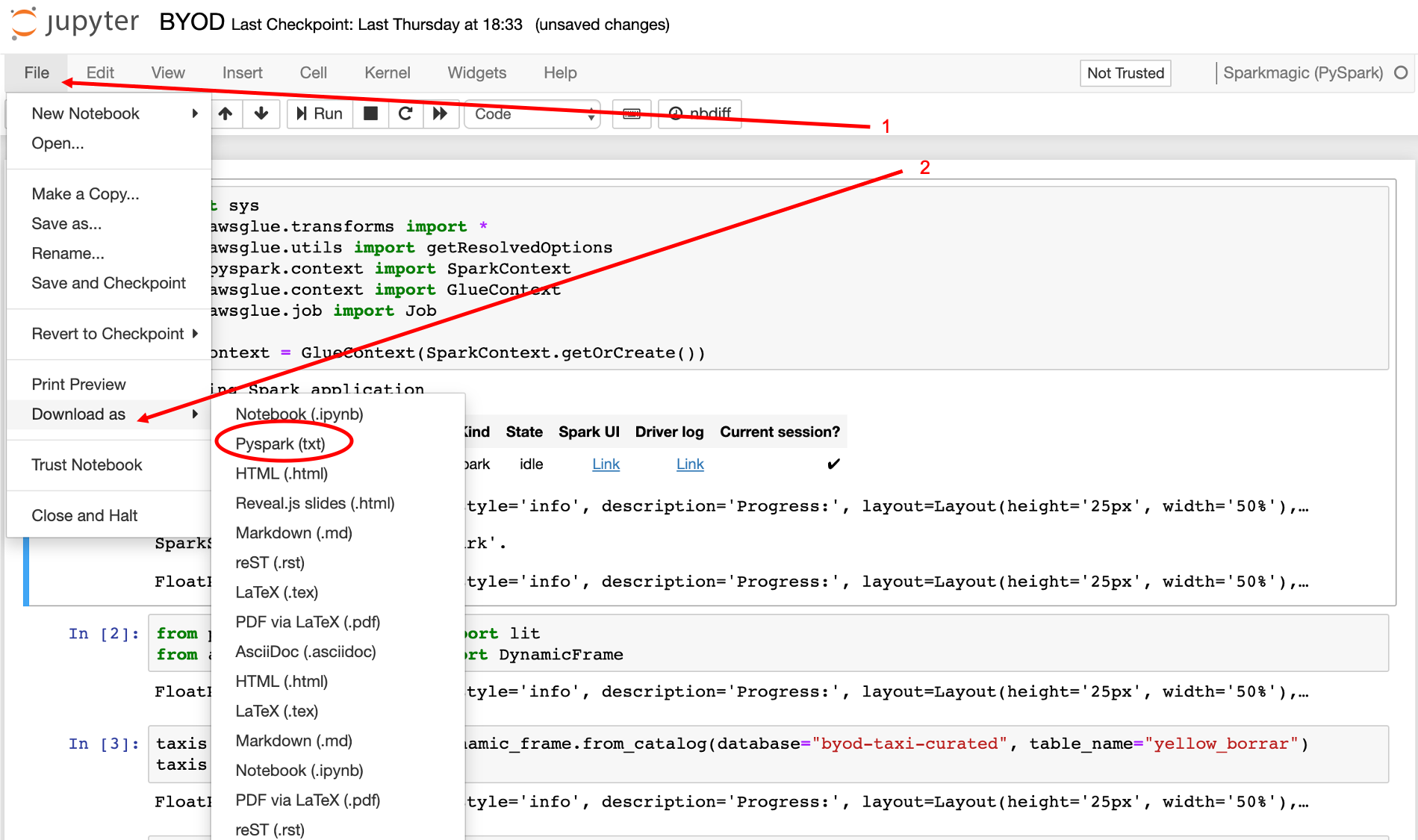
- Click File
- Download as > Pyspark (txt)
Please open the txt file, Remove any line containing:
.show()
.printSchema()
and copy it. In the AWS Glue Console (https://console.aws.amazon.com/glue/), click on Jobs, and Add Job
- Name:
byod-data-transformation - IAM Role: glue-processor-role
- This job runs: A new script to be authored by you
- Monitoring - Job metrics
- Connections - Save job and edit script
- Now, paste the txt downloaded from the notebook
- Save and Run